
Python से Google Trends डेटा कैसे स्क्रैप करें?
Senior Web Scraping Engineer
Google Trends क्या है?
Google Trends Google द्वारा उपलब्ध कराया गया एक निःशुल्क ऑनलाइन उपकरण है जो समय के साथ Google खोज इंजन में विशिष्ट कीवर्ड या खोज शब्दों की लोकप्रियता का विश्लेषण करता है।
यह आंकड़ों को चार्ट के रूप में प्रस्तुत करता है जिससे उपयोगकर्ताओं को किसी निश्चित विषय या कीवर्ड की खोज लोकप्रियता को समझने में मदद मिलती है, और मौसमी उतार-चढ़ाव, उभरते रुझान या घटती रुचि जैसे पैटर्न की पहचान करता है। Google Trends न केवल वैश्विक डेटा विश्लेषण का समर्थन करता है, बल्कि इसे विशिष्ट क्षेत्रों में भी परिष्कृत किया जा सकता है और संबंधित खोज शब्दों और विषयों के लिए सुझाव प्रदान कर सकता है।
Google Trends का व्यापक रूप से बाजार अनुसंधान, सामग्री नियोजन, SEO अनुकूलन और उपयोगकर्ता व्यवहार विश्लेषण में उपयोग किया जाता है, जिससे उपयोगकर्ताओं को डेटा के आधार पर अधिक सूचित निर्णय लेने में मदद मिलती है।
Python के साथ Google Trends डेटा कैसे स्क्रैप करें - चरण दर चरण मार्गदर्शिका
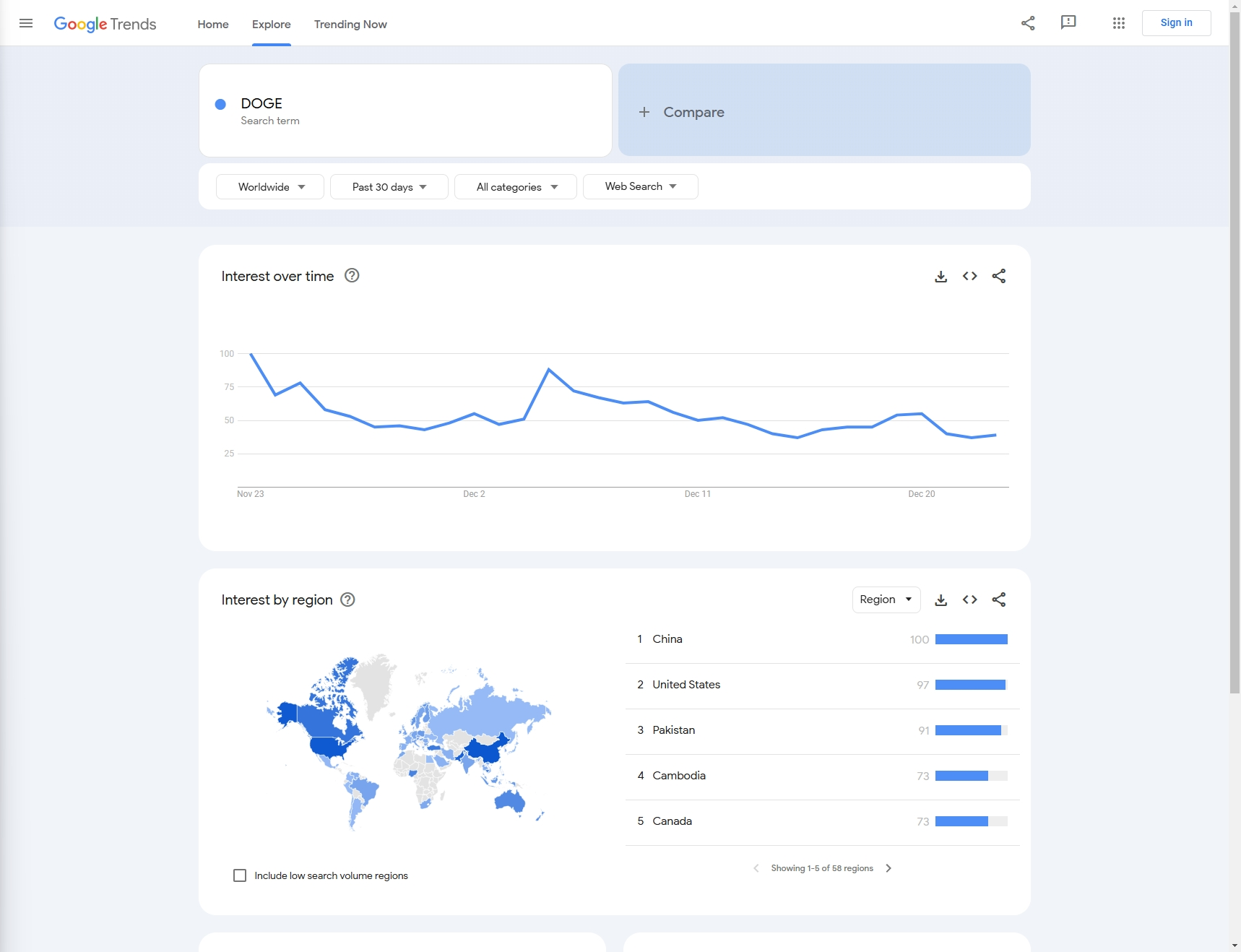
उदाहरण के लिए: इस लेख में, आइए पिछले महीने से 'DOGE' के Google खोज रुझानों को स्क्रैप करें।
चरण 1: पूर्वापेक्षाएँ
Python स्थापित करें
Windows पर
आधिकारिक Python इंस्टॉलर का उपयोग करना
-
Python इंस्टॉलर डाउनलोड करें:
- आधिकारिक Python वेबसाइट पर जाएँ।
- वेबसाइट को स्वचालित रूप से Windows के लिए नवीनतम संस्करण का सुझाव देना चाहिए। इंस्टॉलर डाउनलोड करने के लिए Download Python बटन पर क्लिक करें।
-
इंस्टॉलर चलाएँ:
- स्थापना प्रक्रिया शुरू करने के लिए डाउनलोड की गई
.exeफ़ाइल खोलें।
- स्थापना प्रक्रिया शुरू करने के लिए डाउनलोड की गई
-
स्थापना को अनुकूलित करें (वैकल्पिक):
- स्थापना विंडो की शुरुआत में "Add Python to PATH" कहने वाले बॉक्स को जांचना सुनिश्चित करें। यह कमांड लाइन (
cmdया PowerShell) से Python को सुलभ बनाता है। - आप
pip,IDLE, याdocumentationजैसी अतिरिक्त सुविधाओं को चुनने के लिए "Customize installation" पर भी क्लिक कर सकते हैं।
- स्थापना विंडो की शुरुआत में "Add Python to PATH" कहने वाले बॉक्स को जांचना सुनिश्चित करें। यह कमांड लाइन (
-
Python स्थापित करें:
- डिफ़ॉल्ट सेटिंग्स के साथ Python स्थापित करने के लिए Install Now पर क्लिक करें।
- स्थापना के बाद, आप कमांड प्रॉम्प्ट (
cmd) खोलकर और टाइप करके इसकी पुष्टि कर सकते हैं:bashpython --version
-
pip स्थापित करना (यदि आवश्यक हो):
- Pip, Python पैकेज मैनेजर, Python के आधुनिक संस्करणों के साथ डिफ़ॉल्ट रूप से स्थापित होता है। आप यह जांच सकते हैं कि क्या pip टाइप करके स्थापित है:
bash
pip --version
- Pip, Python पैकेज मैनेजर, Python के आधुनिक संस्करणों के साथ डिफ़ॉल्ट रूप से स्थापित होता है। आप यह जांच सकते हैं कि क्या pip टाइप करके स्थापित है:
आप Windows Store से सीधे Python भी स्थापित कर सकते हैं (Windows 10/11 पर उपलब्ध)। बस Microsoft Store ऐप में "Python" खोजें और अपनी ज़रूरत के संस्करण को चुनें।
macOS पर
विधि 1. Homebrew का उपयोग करना (अनुशंसित)
-
Homebrew स्थापित करें (यदि पहले से स्थापित नहीं है):
- Terminal ऐप खोलें।
- Homebrew (macOS के लिए पैकेज मैनेजर) स्थापित करने के लिए निम्न कमांड पेस्ट करें:
bash
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
-
Homebrew के साथ Python स्थापित करें:
- एक बार Homebrew स्थापित हो जाने के बाद, आप इस कमांड के साथ Python स्थापित कर सकते हैं:
bash
brew install python
- एक बार Homebrew स्थापित हो जाने के बाद, आप इस कमांड के साथ Python स्थापित कर सकते हैं:
-
स्थापना सत्यापित करें:
- स्थापना के बाद, आप निम्न कमांड के साथ Python और pip संस्करणों को सत्यापित कर सकते हैं:
bash
python3 --version pip3 --version
- स्थापना के बाद, आप निम्न कमांड के साथ Python और pip संस्करणों को सत्यापित कर सकते हैं:
विधि 2. आधिकारिक Python इंस्टॉलर का उपयोग करना
-
macOS इंस्टॉलर डाउनलोड करें:
- Python डाउनलोड पृष्ठ पर जाएँ।
- Python के लिए नवीनतम macOS इंस्टॉलर डाउनलोड करें।
-
इंस्टॉलर चलाएँ:
- स्थापना प्रक्रिया शुरू करने के लिए
.pkgफ़ाइल खोलें और निर्देशों का पालन करें।
- स्थापना प्रक्रिया शुरू करने के लिए
-
स्थापना सत्यापित करें:
- स्थापना के बाद, टर्मिनल खोलें और Python संस्करण जांचें:
bash
python3 --version pip3 --version
- स्थापना के बाद, टर्मिनल खोलें और Python संस्करण जांचें:
Linux पर
Debian/Ubuntu-आधारित वितरणों के लिए
-
पैकेज सूची अपडेट करें:
- एक टर्मिनल खोलें और पैकेज सूची को अपडेट करने के लिए निम्न कमांड चलाएँ:
bash
sudo apt update
- एक टर्मिनल खोलें और पैकेज सूची को अपडेट करने के लिए निम्न कमांड चलाएँ:
-
Python स्थापित करें:
- Python 3 (आमतौर पर Python 3.x का नवीनतम संस्करण) स्थापित करने के लिए, चलाएँ:
bash
sudo apt install python3
- Python 3 (आमतौर पर Python 3.x का नवीनतम संस्करण) स्थापित करने के लिए, चलाएँ:
-
pip स्थापित करें (यदि स्थापित नहीं है):
- यदि pip पहले से स्थापित नहीं है, तो आप इसे इस प्रकार स्थापित कर सकते हैं:
bash
sudo apt install python3-pip
- यदि pip पहले से स्थापित नहीं है, तो आप इसे इस प्रकार स्थापित कर सकते हैं:
-
स्थापना सत्यापित करें:
- स्थापित Python संस्करण की जांच करने के लिए:
bash
python3 --version pip3 --version
- स्थापित Python संस्करण की जांच करने के लिए:
Red Hat/Fedora-आधारित वितरणों के लिए
-
Python 3 स्थापित करें:
- एक टर्मिनल खोलें और चलाएँ:
bash
sudo dnf install python3
- एक टर्मिनल खोलें और चलाएँ:
-
pip स्थापित करें (यदि आवश्यक हो):
- यदि
pipडिफ़ॉल्ट रूप से स्थापित नहीं है, तो आप इसे इस प्रकार स्थापित कर सकते हैं:bashsudo dnf install python3-pip
- यदि
-
स्थापना सत्यापित करें:
- स्थापित Python संस्करण की जांच करने के लिए:
bash
python3 --version pip3 --version
- स्थापित Python संस्करण की जांच करने के लिए:
Arch Linux और Arch-आधारित डिस्ट्रो के लिए
-
Python 3 स्थापित करें:
- निम्न कमांड चलाएँ:
bash
sudo pacman -S python
- निम्न कमांड चलाएँ:
-
pip स्थापित करें:
- Pip को Python के साथ स्थापित किया जाना चाहिए, लेकिन यदि नहीं, तो आप इसे इस प्रकार स्थापित कर सकते हैं:
bash
sudo pacman -S python-pip
- Pip को Python के साथ स्थापित किया जाना चाहिए, लेकिन यदि नहीं, तो आप इसे इस प्रकार स्थापित कर सकते हैं:
-
स्थापना सत्यापित करें:
- Python और pip संस्करणों की जांच करने के लिए:
bash
python --version pip --version
- Python और pip संस्करणों की जांच करने के लिए:
Anaconda (क्रॉस-प्लेटफ़ॉर्म) के माध्यम से Python का उपयोग करना
Anaconda वैज्ञानिक कंप्यूटिंग के लिए एक लोकप्रिय वितरण है और इसमें Python, पुस्तकालय और conda पैकेज मैनेजर शामिल हैं।
-
Anaconda डाउनलोड करें:
- Anaconda डाउनलोड पृष्ठ पर जाएँ और अपने प्लेटफ़ॉर्म के लिए उपयुक्त संस्करण डाउनलोड करें।
-
Anaconda स्थापित करें:
- अपने ऑपरेटिंग सिस्टम के आधार पर स्थापना निर्देशों का पालन करें। Anaconda Windows और macOS दोनों के लिए एक ग्राफिकल इंस्टॉलर प्रदान करता है, साथ ही सभी प्लेटफ़ॉर्म के लिए कमांड-लाइन इंस्टॉलर भी प्रदान करता है।
-
स्थापना सत्यापित करें:
-
स्थापना के बाद, एक टर्मिनल (या Windows पर Anaconda प्रॉम्प्ट) खोलें और जांचें कि क्या Python काम कर रहा है:
bashpython --version -
आप
conda(Anaconda के लिए पैकेज मैनेजर) को भी सत्यापित कर सकते हैं:bashconda --version
-
Python संस्करणों का प्रबंधन करना (वैकल्पिक)
यदि आपको एक ही मशीन पर कई Python संस्करणों का प्रबंधन करने की आवश्यकता है, तो आप संस्करण प्रबंधकों का उपयोग कर सकते हैं:
-
pyenv: एक लोकप्रिय Python संस्करण प्रबंधक जो Linux और macOS पर काम करता है।
- Homebrew या GitHub (Linux और macOS के लिए) के माध्यम से स्थापित करें।
- Windows पर, आप pyenv-win का उपयोग कर सकते हैं।
bashpyenv install 3.9.0 pyenv global 3.9.0
Scrapeless API और Google trends तक पहुँच
चूँकि हमने अभी तक उपयोग के लिए कोई तृतीय-पक्ष पुस्तकालय विकसित नहीं किया है, इसलिए आपको Scrapeless API सेवा का अनुभव करने के लिए केवल अनुरोध स्थापित करने की आवश्यकता है
Shell
pip install requestsचरण 2: उन कोड क्षेत्रों को कॉन्फ़िगर करें जिनकी आवश्यकता है
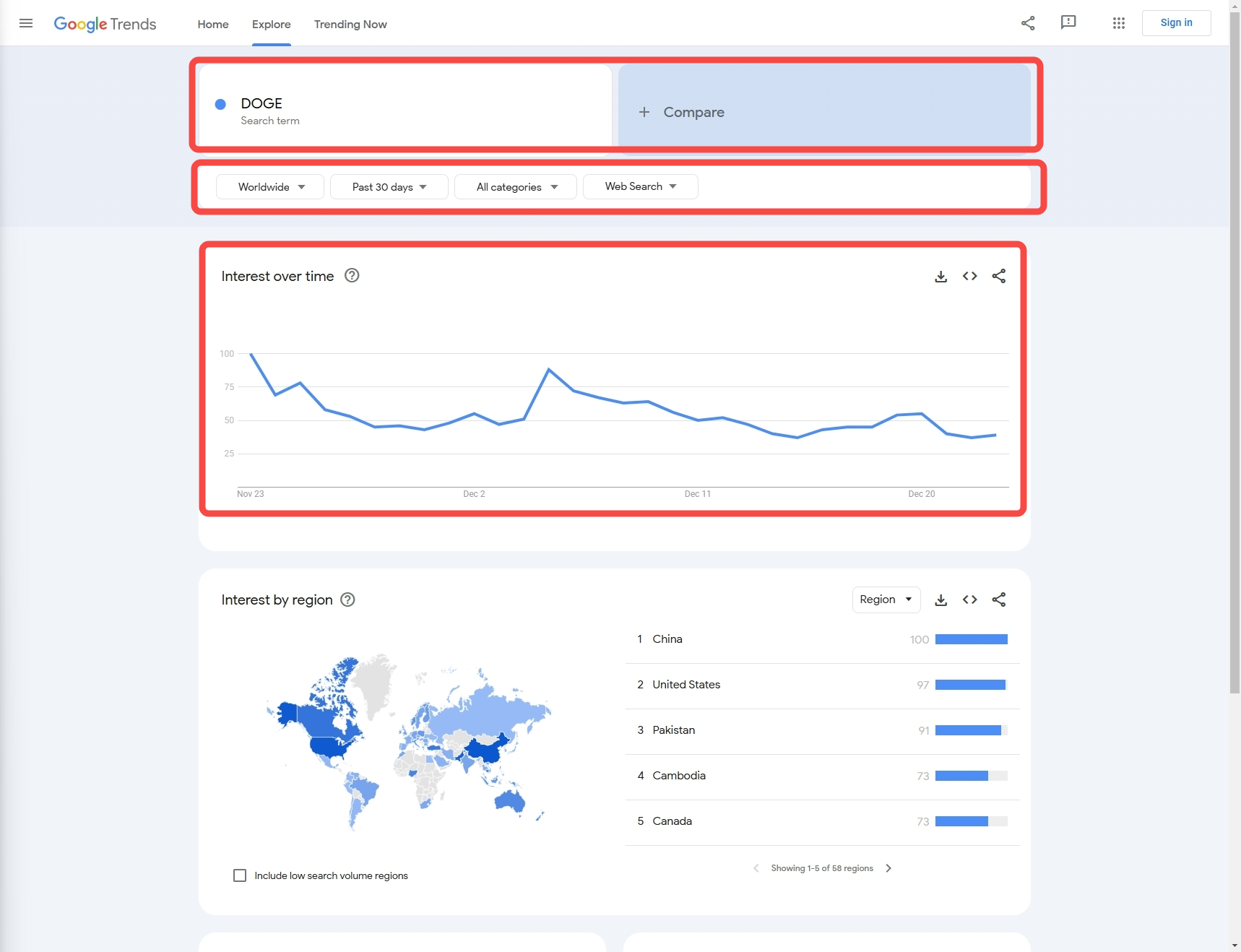
अगला, हमें यह जानने की आवश्यकता है कि कॉन्फ़िगरेशन के माध्यम से हमें जिन आंकड़ों की आवश्यकता है, उन्हें कैसे प्राप्त किया जाए:
- कीवर्ड: इस उदाहरण में, हमारा कीवर्ड 'DOGE' है (हम कई कीवर्ड तुलना डेटा के संग्रह का भी समर्थन करते हैं)
- डेटा कॉन्फ़िगरेशन:
- देश: क्वेरी देश, डिफ़ॉल्ट 'विश्वव्यापी' है
- समय: समयावधि
- श्रेणी: प्रकार
- गुण: स्रोत
चरण 3: डेटा निकालना
अब, आइए Python कोड का उपयोग करके लक्ष्य डेटा प्राप्त करें:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request(data_type, search_term):
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "scrapeless-api-key" # TODO:use your api key
headers = {"x-api-token": token}
input_data = {
"q": search_term,
"date": "today 1-m",
"data_type": data_type,
"hl": "en-sg",
"tz": "-480",
"geo": "",
"cat": "",
"property": "",
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.google.trends", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request(data_type="interest_over_time", search_term="DOGE")- आउटपुट:
JSON
{"interest_over_time":{"averages":[],"timelineData":[{"formattedAxisTime":"24 Nov","formattedTime":"24 Nov 2024","formattedValue":["85"],"hasData":[true],"time":"1732406400","value":[85]},{"formattedAxisTime":"25 Nov","formattedTime":"25 Nov 2024","formattedValue":["89"],"hasData":[true],"time":"1732492800","value":[89]},{"formattedAxisTime":"26 Nov","formattedTime":"26 Nov 2024","formattedValue":["68"],"hasData":[true],"time":"1732579200","value":[68]},{"formattedAxisTime":"27 Nov","formattedTime":"27 Nov 2024","formattedValue":["60"],"hasData":[true],"time":"1732665600","value":[60]},{"formattedAxisTime":"28 Nov","formattedTime":"28 Nov 2024","formattedValue":["49"],"hasData":[true],"time":"1732752000","value":[49]},{"formattedAxisTime":"29 Nov","formattedTime":"29 Nov 2024","formattedValue":["55"],"hasData":[true],"time":"1732838400","value":[55]},{"formattedAxisTime":"30 Nov","formattedTime":"30 Nov 2024","formattedValue":["54"],"hasData":[true],"time":"1732924800","value":[54]},{"formattedAxisTime":"1 Dec","formattedTime":"1 Dec 2024","formattedValue":["55"],"hasData":[true],"time":"1733011200","value":[55]},{"formattedAxisTime":"2 Dec","formattedTime":"2 Dec 2024","formattedValue":["64"],"hasData":[true],"time":"1733097600","value":[64]},{"formattedAxisTime":"3 Dec","formattedTime":"3 Dec 2024","formattedValue":["57"],"hasData":[true],"time":"1733184000","value":[57]},{"formattedAxisTime":"4 Dec","formattedTime":"4 Dec 2024","formattedValue":["61"],"hasData":[true],"time":"1733270400","value":[61]},{"formattedAxisTime":"5 Dec","formattedTime":"5 Dec 2024","formattedValue":["100"],"hasData":[true],"time":"1733356800","value":[100]},{"formattedAxisTime":"6 Dec","formattedTime":"6 Dec 2024","formattedValue":["84"],"hasData":[true],"time":"1733443200","value":[84]},{"formattedAxisTime":"7 Dec","formattedTime":"7 Dec 2024","formattedValue":["79"],"hasData":[true],"time":"1733529600","value":[79]},{"formattedAxisTime":"8 Dec","formattedTime":"8 Dec 2024","formattedValue":["72"],"hasData":[true],"time":"1733616000","value":[72]},{"formattedAxisTime":"9 Dec","formattedTime":"9 Dec 2024","formattedValue":["64"],"hasData":[true],"time":"1733702400","value":[64]},{"formattedAxisTime":"10 Dec","formattedTime":"10 Dec 2024","formattedValue":["64"],"hasData":[true],"time":"1733788800","value":[64]},{"formattedAxisTime":"11 Dec","formattedTime":"11 Dec 2024","formattedValue":["63"],"hasData":[true],"time":"1733875200","value":[63]},{"formattedAxisTime":"12 Dec","formattedTime":"12 Dec 2024","formattedValue":["59"],"hasData":[true],"time":"1733961600","value":[59]},{"formattedAxisTime":"13 Dec","formattedTime":"13 Dec 2024","formattedValue":["54"],"hasData":[true],"time":"1734048000","value":[54]},{"formattedAxisTime":"14 Dec","formattedTime":"14 Dec 2024","formattedValue":["48"],"hasData":[true],"time":"1734134400","value":[48]},{"formattedAxisTime":"15 Dec","formattedTime":"15 Dec 2024","formattedValue":["43"],"hasData":[true],"time":"1734220800","value":[43]},{"formattedAxisTime":"16 Dec","formattedTime":"16 Dec 2024","formattedValue":["48"],"hasData":[true],"time":"1734307200","value":[48]},{"formattedAxisTime":"17 Dec","formattedTime":"17 Dec 2024","formattedValue":["55"],"hasData":[true],"time":"1734393600","value":[55]},{"formattedAxisTime":"18 Dec","formattedTime":"18 Dec 2024","formattedValue":["52"],"hasData":[true],"time":"1734480000","value":[52]},{"formattedAxisTime":"19 Dec","formattedTime":"19 Dec 2024","formattedValue":["63"],"hasData":[true],"time":"1734566400","value":[63]},{"formattedAxisTime":"20 Dec","formattedTime":"20 Dec 2024","formattedValue":["64"],"hasData":[true],"time":"1734652800","value":[64]},{"formattedAxisTime":"21 Dec","formattedTime":"21 Dec 2024","formattedValue":["47"],"hasData":[true],"time":"1734739200","value":[47]},{"formattedAxisTime":"22 Dec","formattedTime":"22 Dec 2024","formattedValue":["44"],"hasData":[true],"time":"1734825600","value":[44]},{"formattedAxisTime":"23 Dec","formattedTime":"23 Dec 2024","formattedValue":["44"],"hasData":[true],"time":"1734912000","value":[44]},{"formattedAxisTime":"24 Dec","formattedTime":"24 Dec 2024","formattedValue":["46"],"hasData":[true],"isPartial":true,"time":"1734998400","value":[46]}]}}चरण 4: कोड अनुकूलित करें
- कई देशों को कॉन्फ़िगर करें
Python
country_map = {
"Worldwide": "ANY",
"Afghanistan":"AF",
"Åland Islands":"AX",
"Albania":"AL",
#...
}- कई समयावधियों को कॉन्फ़िगर करें
Python
time_map = {
"Past hour":"now 1-H",
"Past 4 hours":"now 4-H",
"Past 7 days":"now 7-d",
"Past 30 days":"today 1-m",
# ...
}- कई श्रेणियों को कॉन्फ़िगर करें
Python
category_map = {
"All categories": 0,
"Arts & Entertainment": 3,
"Autos & Vehicles": 47,
# ...
}- कई स्रोतों को कॉन्फ़िगर करें
Python
property_map = {
"Web Search":"",
"Image Search":"images",
"Google Shopping":"froogle",
# ...
}- सुधारा हुआ कोड:
Python
import json
import requests
country_map = {
"Worldwide": "",
"Afghanistan": "AF",
"Åland Islands": "AX",
"Albania": "AL",
# ...
}
time_map = {
"Past hour": "now 1-H",
"Past 4 hours": "now 4-H",
"Past 7 days": "now 7-d",
"Past 30 days": "today 1-m",
# ...
}
category_map = {
"All categories": "",
"Arts & Entertainment": "3",
"Autos & Vehicles": "47",
# ...
}
property_map = {
"Web Search": "",
"Image Search": "images",
"Google Shopping": "froogle",
# ...
}
class Payload:
def __init__(self, actor, input_data, proxy):
self.actor = actor
self.input = input_data
self.proxy = proxy
def send_request(data_type, search_term, country, time, category, property):
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "scrapeless-api-key" # TODO:use your api key
headers = {"x-api-token": token}
input_data = {
"q": search_term, # search term
"geo": country,
"date": time,
"cat": category,
"property": property,
"hl": "en-sg",
"tz": "-480",
"data_type": data_type
}
proxy = {
"country": "ANY",
}
payload = Payload("scraper.google.trends", input_data, proxy)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload, verify=False)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
# one search_term
send_request(
data_type="interest_over_time",
search_term="DOGE",
country=country_map["Worldwide"],
time=time_map["Past 30 days"],
category=category_map["Arts & Entertainment"],
property=property_map["Web Search"],
)
# two search_term
send_request(
data_type="interest_over_time",
search_term="DOGE,python",
country=country_map["Worldwide"],
time=time_map["Past 30 days"],
category=category_map["Arts & Entertainment"],
property=property_map["Web Search"],
)क्रॉलिंग प्रक्रिया में समस्याएँ
- हमें कुछ नेटवर्क त्रुटियों पर निर्णय लेने की आवश्यकता है ताकि त्रुटियों को बंद होने से रोका जा सके;
- एक निश्चित पुन: प्रयास तंत्र जोड़ने से क्रॉलिंग प्रक्रिया में रुकावट को दोहराए गए/अमान्य डेटा अधिग्रहण के कारण रोका जा सकता है।
Scrapeless स्क्रैपिंग API के साथ परीक्षण - सबसे अच्छा Google Trends स्क्रैपर
- चरण 1. Scrapeless में लॉग इन करें
- चरण 2. "स्क्रैपिंग API" पर क्लिक करें
- चरण 3. हमारे "Google Trends" पैनल को ढूंढें और उसमें प्रवेश करें:
- चरण 4. बाएँ संचालन पैनल में अपना डेटा कॉन्फ़िगर करें:
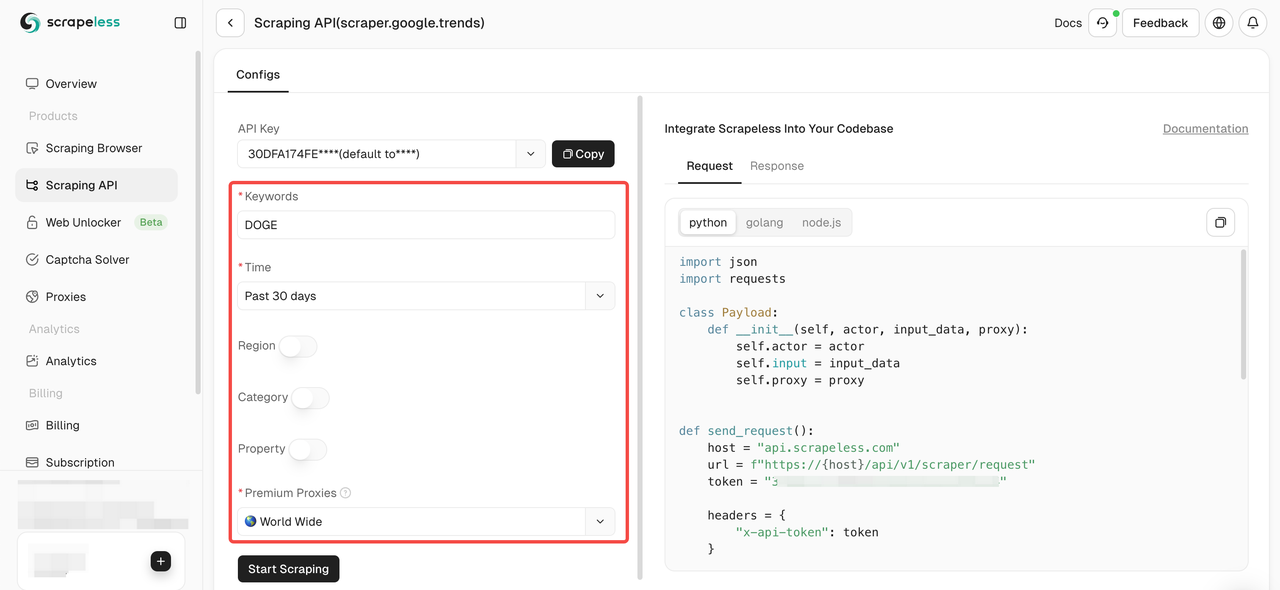
- चरण 5. "Start Scraping" बटन पर क्लिक करें और फिर आप परिणाम प्राप्त कर सकते हैं:
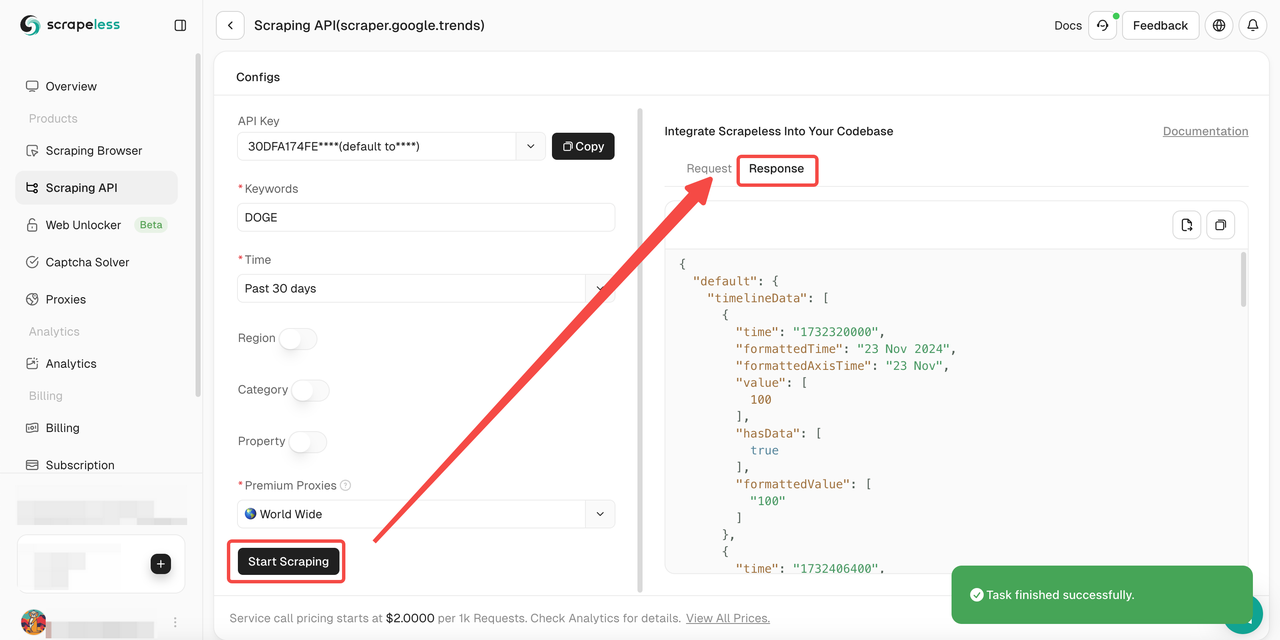
इसके अलावा, आप हमारे नमूना कोड को भी देख सकते हैं।
Scrapeless Google Trends API: संपूर्ण समझ
Scrapeless वेबसाइटों से डेटा निकालने की प्रक्रिया को सरल बनाने के लिए डिज़ाइन किया गया एक अभिनव समाधान है। हमारा API सबसे जटिल वेब वातावरणों को नेविगेट करने और गतिशील सामग्री और JavaScript प्रतिपादन को प्रभावी ढंग से प्रबंधित करने के लिए डिज़ाइन किया गया है।
Scrapeless Google Trends को स्क्रैप करने के लिए अच्छा क्यों काम करता है?
यदि हम अकेले Google Trends को क्रॉल करने के लिए Python कोडिंग का उपयोग करते हैं, तो हम आसानी से reCAPTHCA सत्यापन प्रणाली का सामना करेंगे। यह हमारी क्रॉलिंग प्रक्रिया के लिए बड़ी चुनौतियाँ लाता है।
हालांकि, Scrapeless Google Trends स्क्रैपिंग API CAPTCHA सॉल्वर और बुद्धिमान IP रोटेशन को एकीकृत करता है, इसलिए वेबसाइट द्वारा निगरानी और पहचाने जाने के बारे में चिंता करने की कोई आवश्यकता नहीं है। Scrapeless 99.9% वेबसाइट क्रॉलिंग सफलता दर की गारंटी देता है, जो आपको पूरी तरह से स्थिर और सुरक्षित डेटा क्रॉलिंग वातावरण प्रदान करता है।
Scrapeless के 4 विशिष्ट लाभ
- प्रतिस्पर्धी मूल्य
Scrapeless न केवल शक्तिशाली है, बल्कि अधिक प्रतिस्पर्धी बाजार मूल्य की भी गारंटी देता है। Scrapeless Google रुझान स्क्रैपिंग API सेवा कॉल मूल्य निर्धारण 1k सफल अनुरोधों के लिए $2 से शुरू होता है। - स्थिरता
व्यापक अनुभव और मजबूत सिस्टम उन्नत CAPTCHA-समाधान क्षमताओं के साथ विश्वसनीय, निर्बाध स्क्रैपिंग सुनिश्चित करते हैं। - गति
एक विशाल प्रॉक्सी पूल IP ब्लॉक या देरी के बिना कुशल, बड़े पैमाने पर स्क्रैपिंग की गारंटी देता है। - लागत प्रभावी
स्वामित्व तकनीक लागत को कम करती है, जिससे हम गुणवत्ता से समझौता किए बिना प्रतिस्पर्धी मूल्य निर्धारण प्रदान कर सकते हैं। - SLAS गारंटी
सेवा-स्तर समझौते उद्यम की जरूरतों के लिए लगातार प्रदर्शन और विश्वसनीयता सुनिश्चित करते हैं।
अक्सर पूछे जाने वाले प्रश्न
क्या Google Trends को स्क्रैप करना कानूनी है?
हाँ, वैश्विक, सार्वजनिक रूप से उपलब्ध Google Trends डेटा को स्क्रैप करना पूरी तरह से कानूनी है। हालाँकि, कृपया कम समय में बहुत अधिक अनुरोध भेजकर अपनी साइट को नुकसान न पहुँचाएँ।
क्या Google Trends भ्रामक है?
Google Trends खोज गतिविधि का पूर्ण प्रतिबिंब नहीं है। Google Trends कुछ प्रकार की खोजों को फ़िल्टर कर देता है, जैसे कि बहुत कम लोगों द्वारा की जाने वाली खोजें। रुझान केवल लोकप्रिय शब्दों के लिए डेटा दिखाते हैं, इसलिए कम खोज मात्रा वाले शब्द "0" के रूप में दिखाई देंगे।
क्या Google Trends एक API प्रदान करता है?
नहीं, Google Trends अभी तक कोई सार्वजनिक API प्रदान नहीं करता है। हालाँकि, आप तृतीय-पक्ष डेवलपर उपकरणों में निजी API से Google Trends डेटा तक पहुँच सकते हैं, जैसे कि Scrapeless।
अंतिम विचार
Google Trends एक मूल्यवान डेटा एकीकरण उपकरण है जो खोज इंजनों पर खोज क्वेरी का विश्लेषण करके कीवर्ड विश्लेषण और लोकप्रिय खोज विषय प्रदान करता है। इस लेख में, हम गहराई से दिखाते हैं कि Python का उपयोग करके Google Trends को कैसे स्क्रैप किया जाए।
हालांकि, पाइथन कोडिंग का उपयोग करके Google Trends को स्क्रैप करने से हमेशा CAPTCHA बाधा का सामना करना पड़ता है। यह आपके डेटा निष्कर्षण को विशेष रूप से कठिन बनाता है। हालांकि Google Trends API उपलब्ध नहीं है, Scrapeless Google Trends API आपका आदर्श उपकरण होगा!
एक शक्तिशाली Google Trends स्क्रैपिंग टूल प्राप्त करने के लिए अभी साइन अप करें!
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


