
एंटी-बॉट डिटेक्शन को कैसे बायपास करें?
Senior Web Scraping Engineer
Here’s the translation of the provided text into Hindi:
स्वचालन और सुरक्षा के बीच लड़ाई में, एंटी-बॉट तंत्र वेब के द्वारपाल बन गए हैं, अनचाहे बॉट्स को अवरुद्ध करते हुए अक्सर वैध डेटा संग्रह के मार्ग में खड़े होते हैं।
लॉगिन पृष्ठों से लेकर ई-कॉमर्स साइटों तक, ये रक्षा तंत्र—विशेषकर CAPTCHA—वेब स्क्रैपर्स और ऑटोमेशन उपकरणों के लिए एक निराशाजनक अवरोध बन सकते हैं। क्या इन्हें पार करने का कोई तरीका है?
यह लेख एंटी-बॉट सिस्टम की दुनिया में गोताखोरी करता है, यह पता लगाता है कि वे स्वचालन का पता कैसे लगाते हैं, और बिना कानूनी या नैतिक सीमाएँ पार किए प्रतिबंधों को बायपास करने के नैतिक तरीकों को उजागर करता है।
आइए पढ़ना शुरू करते हैं!
एंटी-बॉट डिटेक्शन क्यों है?
ठीक है, चलो पहले एक यात्रा का आनंद लेते हैं। कल्पना करें कि एक दुकान चला रहे हैं जहाँ ग्राहक स्वतंत्र रूप सेbrowse कर सकते हैं, लेकिन हर कुछ मिनट में, एक मुखौटा पहने figura rushes in, आपके सभी उत्पादों को उठाता है और गायब हो जाता है। अब आप क्या सोचते हैं?
यही महसूस करते हैं वेबसाइटें बॉट्स के बारे में! एंटी-बॉट डिटेक्शन वास्तविक उपयोगकर्ताओं को स्वचालित स्क्रिप्ट से अलग करने के लिए मौजूद है, क्रेडेंशियल भरने, सामग्री की चोरी, और आक्रामक वेब स्क्रैपिंग से सुरक्षा प्रदान करता है।
CAPTCHAs से लेकर ब्राउज़र फिंगरप्रिंटिंग तक, ये डिजिटल बाउंसर्स tirelessly काम करते हैं बुरे बॉट्स को बाहर रखने के लिए—लेकिन कभी-कभी, वे उन अच्छे इरादों वाले डेवलपर्स को भी रोक देते हैं जो केवल अपने डेटा को प्राप्त करने की कोशिश कर रहे हैं।
तो, क्या इनसे चालाकी से निपटने का कोई तरीका है बिना नियमों को तोड़े? हम और अधिक खोज सकते हैं।
सामान्य एंटी-बॉट तंत्र
- हेडर वैलीडेशन: हेडर वेलिडेशन आने वाले HTTP हेडर का विश्लेषण करता है और यह जांचता है कि उन्हें अवरुद्ध करना है या नहीं।
- IP ब्लॉकिंग: IP पतों के आधार पर पहुंच को प्रतिबंधित करना।
- रेट लिमिटिंग: एकल IP से अनुरोधों को सीमित करना।
- ब्राउज़र फिंगरप्रिंटिंग: ब्राउज़र के गुण और व्यवहार का विश्लेषण करना।
- TLS फिंगरप्रिंटिंग: TLS फिंगरप्रिंटिंग हस्ताक्षर पैरामीटर का विश्लेषण करने के द्वारा बॉट्स का पता लगाता है और अप्रत्याशित मानों के साथ अनुरोधों को अवरुद्ध करता है।
- हनीपॉट्स: बॉट्स को लुभाने के लिए अदृश्य जाल।
- CAPTCHA चुनौतियाँ: चुनौतियाँ जो मानवों के लिए आसान होती हैं लेकिन बॉट्स के लिए कठिन होती हैं।
CAPTCHA: एक प्रमुख एंटी-बॉट तंत्र
CAPTCHA क्या है?
CAPTCHA, जिसे पूरी तरह से स्वचालित सार्वजनिक ट्यूरिंग परीक्षण के रूप में जाना जाता है जो कंप्यूटरों और मानवों के बीच भेद करता है, एक सुरक्षा तंत्र है जो वास्तविक उपयोगकर्ताओं को स्वचालित बॉट्स से अलग करने के लिए डिज़ाइन किया गया है। ऐसे चुनौतियों को प्रस्तुत करके जो मानवों के लिए आसान हैं लेकिन मशीनों के लिए कठिन हैं, CAPTCHA स्पैम, क्रेडेंशियल भरने, और स्वचालित वेब स्क्रैपिंग जैसी दुर्भावनापूर्ण गतिविधियों को रोकने में मदद करता है।
CAPTCHA के प्रकार:
- पाठ-आधारित CAPTCHA: उपयोगकर्ताओं को विकृत या अस्पष्ट पाठ की पहचान करना और उसे दर्ज करना होता है, जो बॉट्स के लिए व्याख्या करना चुनौतीपूर्ण होता है।
- चित्र-आधारित CAPTCHA: उपयोगकर्ताओं को चित्रों में वस्तुओं की पहचान करनी होती है, जैसे ट्रैफिक लाइट या स्टोरफ्रंट, यह एक कार्य है जो अधिकांश बॉट्स से परे दृश्य पहचान कौशल की आवश्यकता करता है।
- reCAPTCHA: गूगल का उन्नत CAPTCHA सिस्टम जिसमें कई प्रकार शामिल हैं—सरल चेकबॉक्स सत्यापन ("मैं रोबोट नहीं हूँ"), चित्र चयन चुनौतियां, और अदृश्य CAPTCHAs जो स्पष्ट इंटरएक्शन के बिना उपयोगकर्ता व्यवहार का विश्लेषण करते हैं।
- hCAPTCHA: reCAPTCHA का एक गोपनीयता-केंद्रित विकल्प, जिसे डेटा ट्रैकिंग को न्यूनतम करने के लिए डिज़ाइन किया गया है जबकि अभी भी प्रभावी बॉट सुरक्षा प्रदान करता है।
CAPTCHA कैसे काम करता है:
CAPTCHA एक चुनौती-प्रतिक्रिया तंत्र पर काम करता है, जहाँ उपयोगकर्ताओं को एक कार्य पूरा करना होता है जो यह साबित करता है कि वे मानव हैं। प्रणाली प्रतिक्रियाओं और व्यवहारों का मूल्यांकन करती है, जैसे माउस की गति, टाइपिंग गति, या इंटरएक्शन पैटर्न, प्रामाणिकता निर्धारित करने के लिए।
आधुनिक CAPTCHA सिस्टम मशीन लर्निंग का उपयोग करते हैं ताकि वे बॉट की क्षमताओं के विकास के आधार पर अपनी कठिनाई स्तरों को अनुकूलित कर सकें। वे व्यवहारात्मक डेटा का विश्लेषण करते हैं, जोखिम-आधारित आकलनों का उपयोग करते हैं, और यहां तक कि सटीकता और सुरक्षा को बढ़ाने के लिए जैविक संकेतों को भी समाहित करते हैं, जिससे बॉट्स के लिए इन सुरक्षा उपायों को बायपास करना और अधिक कठिन हो जाता है।
एंटी-बॉट्स को पार करने के लिए सर्वोत्तम प्रथाएँ
Scrapeless क्यों चुनें?
Scrapeless एक शक्तिशाली CAPTCHA सॉल्वर प्रदान करता है, जो CAPTCHA-सुरक्षित वेबसाइटों में निर्बाध नेविगेशन और निरंतर डेटा निकासी सुनिश्चित करता है।
- सस्ती कीमतें: Scrapeless प्रभावशीलता से समझौता किए बिना लागत प्रभावी CAPTCHA-हल करने के समाधान प्रदान करता है।
- स्थिरता और विश्वसनीयता: एक सिद्ध ट्रैक रिकॉर्ड के साथ, Scrapeless उच्च कार्यभार के तहत लगातार CAPTCHAs को हल करता है, सुचारू स्वचालन सुनिश्चित करता है।
- उच्च सफलता दर: अब CAPTCHA अवरोध नहीं—Scrapeless CAPTCHA चुनौतियों को पार करने में 99.99% सफलता दर प्राप्त करता है।
- स्केलेबिलिटी: Scrapeless के मजबूत बुनियादी ढाँचे द्वारा समर्थित, हजारों CAPTCHA-सुरक्षित अनुरोधों को आसानी से संसाधित करें।
क्या Scrapeless महंगे हैं?
Scrapeless प्रतिस्पर्धात्मक कीमतों पर एक विश्वसनीय और स्केलेबल वेब स्क्रैपिंग प्लेटफॉर्म प्रदान करता है ( बनाम Zenrows और Apify), अपने उपयोगकर्ताओं के लिए उत्कृष्ट मूल्य सुनिश्चित करता है:
- Captcha Solver: 1k URLs के लिए $0.8 से
- स्क्रैपिंग ब्राउज़र: प्रति घंटा $0.09 से
- स्क्रैपिंग API: 1k URLs के लिए $0.8 से
- वेब अनलॉकर: 1k URLs के लिए $0.2
- प्रॉक्सी: $2.8 प्रति जीबी
फ्री ट्रायल और अधिक छूट के लिए हमारी समुदाय में शामिल हों!
एंटी बॉट डिटेक्शन को बायपास करें: Scrapeless CAPTCHA Solver गाइड
- चरण 1. Scrapeless में साइन इन करें।
- चरण 2. "CAPTCHA Solver" इंटरफेस में जाएं। reCAPTCHA अनलॉक सेवा पर क्लिक करें और आवश्यक reCAPTCHA प्रकार का चयन करें: सामान्य या उद्यम।
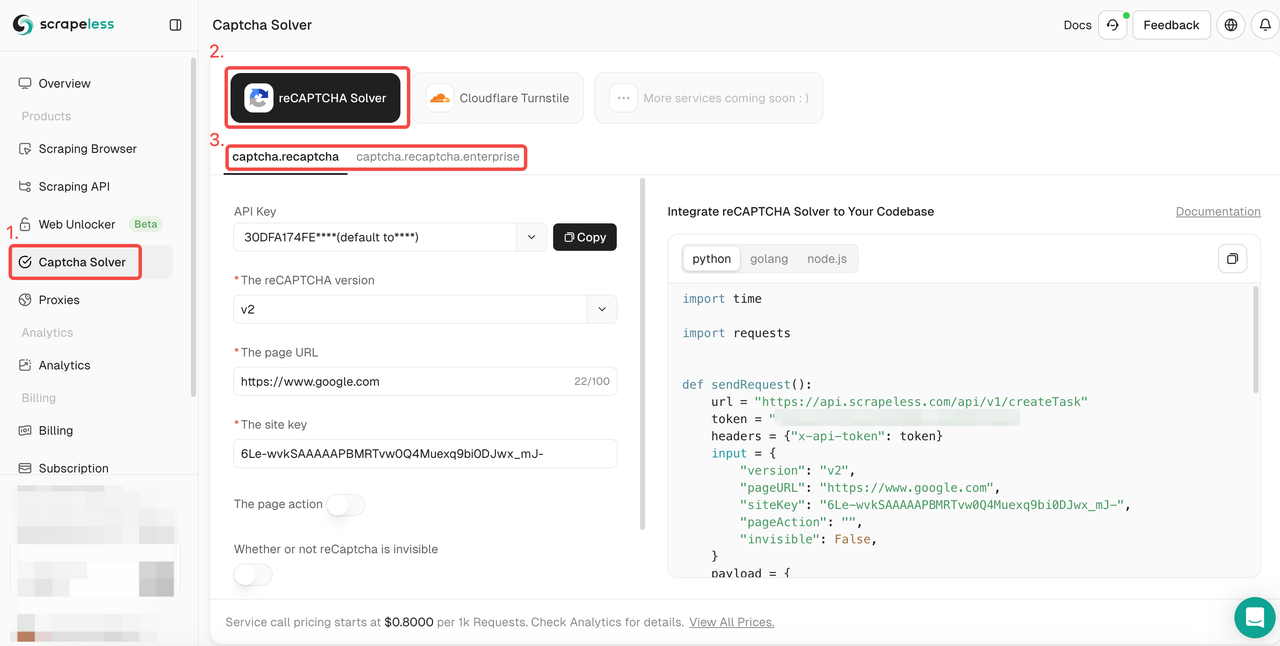
- चरण 3. बाईं ओर ऑपरेशन बॉक्स में आपको आवश्यक प्रासंगिक जानकारी को कॉन्फ़िगर करें: reCAPTCHA संस्करण, पृष्ठ URL, साइट कुंजी, क्रिया, प्रॉक्सी, आदि।
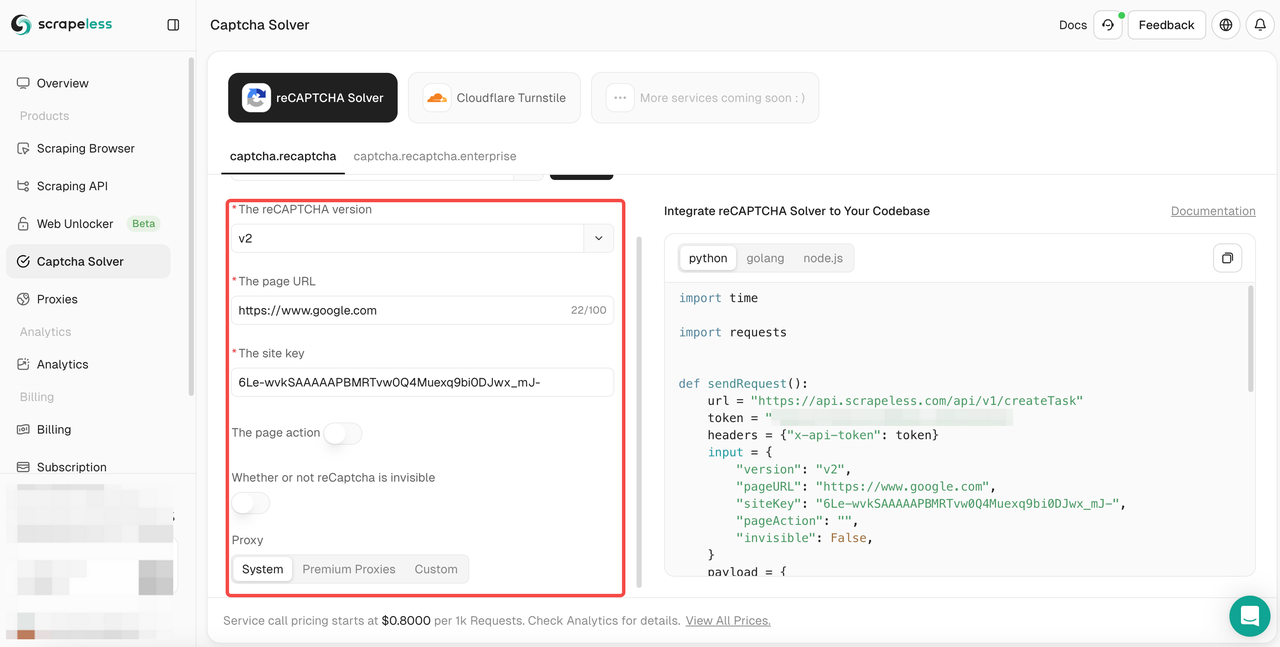
- चरण 4. कॉन्फ़िगरेशन पूरा करने के बाद, आप दाईं ओर कोड बॉक्स में प्रासंगिक कोड प्रतिक्रिया प्राप्त कर सकते हैं। आपको बस इसे कॉपी करना है और इसे अपने प्रोग्राम में एकीकृत करना है। यहाँ हम scraping scrapeless.com का उदाहरण लेते हैं। चलिए v2 reCAPTCHA को अनलॉक करते हैं, प्रीमियम प्रॉक्सी का उपयोग करते हैं और इसे "सिंगापुर" पर कॉन्फ़िगर करते हैं, और पृष्ठ क्रिया को "स्क्रैपिंग" पर सेट करते हैं। मैंने जो कोड प्रतिक्रिया प्राप्त की है, वह निम्नलिखित है:
Python
import time
import requests
def sendRequest():
url = "https://api.scrapeless.com/api/v1/createTask"
token = "xxx"
headers = {"x-api-token": token}
input = {
"version": "v2",
"pageURL": "https://www.scrapeless.com/en",
"siteKey": "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-",
"pageAction": "scraping",
"invisible": False,
}
payload = {
"actor": "captcha.recaptcha",
"input": input
}
# टास्क बनाएं
result = requests.post(url, json=payload, headers=headers).json()
taskId = result.get("taskId")
if not taskId:
print("कार्य बनाने में विफल:", result)
return
print(f"एक कार्य बनाया गया: {taskId}")
# परिणाम के लिए पोलिंग
for i in range(10):
time.sleep(1)
url = "https://api.scrapeless.com/api/v1/getTaskResult/" + taskId
resp = requests.get(url, headers=headers)
result = resp.json()
if resp.status_code != 200:
print("कार्य विफल:", resp.text)
return
if result.get("success"):
return result["solution"]["token"]
data = sendRequest()
print(data)actor: वर्तमान कार्य का अभिनेताstate: वर्तमान कार्य की स्थितिsuccess: क्या कार्य सफल हैtaskId: यदि कार्य सफलतापूर्वक बनाया गया है, तो आपको एक taskId प्राप्त होगा। फिर आपको परिणामों को खोजने के लिए इस taskId का उपयोग करना होगाsolution: यदि कार्य सफल है, तो आपको समाधान प्राप्त होगाmessage: यदि कार्य विफल हो जाता है, तो कृपया इस त्रुटि संदेश की जांच करें
अधिक जानकारी के लिए कृपया हमारे दस्तावेज़ ट्यूटोरियल का संदर्भ लें।
CAPTCHA Solvers के साथ एंटी बोट को बायपास करने की उन्नत रणनीतियाँ
एंटी-बॉट उपायों, जैसे कि CAPTCHAs, को बायपास करने के लिए सम्मानजनक स्क्रैपिंग और उन्नत तकनीकों का संयोजन आवश्यक है। यहाँ बताया गया है कि आप अपनी स्क्रैपिंग संचालन में कुशल और नैतिक कैसे रह सकते हैं।
सम्मानजनक स्क्रैपिंग प्रथाएँ
- robots.txt का पालन करें: हमेशा वेबसाइट के
robots.txtफ़ाइल की जांच करें ताकि यह सुनिश्चित किया जा सके कि क्या स्क्रैप किया जा सकता है। - अनुरोध दरों को सीमित करें: अनुरोधों के बीच यादृच्छिक देरी डालें ताकि मानव ब्राउज़िंग व्यवहार की नकल की जा सके, तेजी से, लगातार अनुरोधों से बचें जो ब्लॉकों को ट्रिगर करते हैं।
- उपयोगकर्ता एजेंटों को घुमाएँ: विभिन्न ब्राउज़रों और उपकरणों की नकल करने के लिए यथार्थवादी उपयोगकर्ता एजेंटों का एक पूल उपयोग करें, स्थैतिक उपयोगकर्ता-एजेंट स्ट्रिंग्स से पहचानने से बचें।
प्रगतिशील तकनीकें
- रेसिडेंशियल प्रॉक्सी: कई आईपी पतों के बीच अनुरोध वितरित करने के लिए रेसिडेंशियल प्रॉक्सी का उपयोग करें, जिससे वेबसाइटों के लिए आपको ब्लॉक करना कठिन हो जाता है।
- हेडलेस ब्राउज़र्स: Puppeteer और Selenium जैसे टूल वास्तविक उपयोगकर्ता इंटरैक्शन की नकल करते हैं, जिससे एंटी-बॉट सिस्टम के लिए आपकी स्क्रैपिंग गतिविधि का पता लगाना कठिन हो जाता है।
- एंटी-डिटेक्शन के लिए मशीन लर्निंग: मानव व्यवहार की नकल करने के लिए बॉट्स को प्रशिक्षित करें, ब्राउज़िंग पैटर्न का विश्लेषण करके, जिससे बॉट के रूप में फ्लैग होने की संभावनाएँ कम हो जाती हैं।
यह एक रैप है
बधाई हो! आपने एंटी-बॉट डिटेक्शन के बारे में बहुत कुछ सीखा। आप नींव से एंटी-डिटेक्शन मास्टर बनने तक पहुँच गए हैं!
अब आप जानते हैं:
- एंटी-बॉट्स क्या हैं।
- एंटी-बॉट तकनीकों को बायपास करने के लिए कुछ बेहतरीन प्रथाएँ।
- कुछ सबसे लोकप्रिय तंत्र जो एंटी-बॉट्स पर भरोसा करते हैं।
- उन्हें सभी को बायपास करने के तरीके।
आप अधिक एंटी-स्क्रैपिंग तकनीकों की खोज कर सकते हैं, लेकिन, चाहे आपका स्क्रैपर कितना भी जटिल क्यों न हो, कुछ तकनीकें आपको अभी भी रोकने में सक्षम होंगी।
इन सभी समस्याओं से Scrapeless का उपयोग करके बचा जा सकता है, जो एक वेब स्क्रैपिंग एपीआई है जिसमें उन्नत प्रॉक्सी, निर्मित आईपी रोटेशन, हेडलेस ब्राउज़र क्षमता और उन्नत एंटी-बॉट बायपास क्षमताएँ हैं। यह वेब को स्क्रैप करने का एक सरल तरीका है।
अपनी मुफ्त परीक्षण आज ही शुरू करें!
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


