
शीर्ष 5 स्क्रैपिंग ब्राउज़र 2025 | केवल रोया!
Expert Network Defense Engineer
वेब स्क्रैपिंग क्या है और इसका उपयोग कैसे किया जाता है?
वेब स्क्रैपिंग इंटरनेट से डेटा निकालने की एक तकनीक है, आमतौर पर वेबसाइट पर जानकारी को स्वचालित रूप से क्रॉल और संरचना करके। स्क्रैपिंग में आमतौर पर HTTP अनुरोध भेजकर एक वेब पेज तक पहुँचना, पृष्ठ सामग्री प्राप्त करना और फिर आवश्यक डेटा जैसे टेक्स्ट, छवियां, लिंक, तालिका डेटा आदि को पार्स और निकालना शामिल है।
स्क्रैपिंग बड़े पैमाने पर डेटा संग्रह के लिए मुख्य तकनीकों में से एक है और इसका व्यापक रूप से कई क्षेत्रों में उपयोग किया जाता है, जैसे मूल्य निगरानी, बाजार अनुसंधान, प्रतिस्पर्धा विश्लेषण, समाचार एकत्रीकरण और शैक्षणिक अनुसंधान। चूँकि कई वेबसाइटों का डेटा HTML पृष्ठों के रूप में प्रस्तुत किया जाता है, इसलिए वेब स्क्रैपिंग इन सामग्रियों को बाद के विश्लेषण और उपयोग के लिए संरचित डेटा में बदल सकता है।
वेब स्क्रैपिंग कैसे काम करता है?
चरण 1. अनुरोध भेजना: आपका वेब स्क्रैपिंग टूल पहले लक्षित वेबसाइट पर वास्तविक उपयोगकर्ताओं के ब्राउज़िंग व्यवहार का अनुकरण करने के लिए एक HTTP अनुरोध भेजता है।
चरण 2. वेब पेज सामग्री प्राप्त करना: वेबसाइट HTML पृष्ठ सामग्री वापस कर देगी, और स्क्रैपर इसे पार्स करता है।
चरण 3. डेटा पार्सिंग: यह पृष्ठ पर विशिष्ट डेटा निकालने के लिए HTML पार्सिंग टूल (जैसे BeautifulSoup, lxml, आदि) का उपयोग करता है।
चरण 4. डेटा संग्रहण: निकाले गए डेटा को बाद के प्रसंस्करण और विश्लेषण के लिए CSV, JSON या डेटाबेस जैसे स्वरूपों में संग्रहीत किया जा सकता है।
स्क्रैपिंग ब्राउज़र आमतौर पर इन चरणों को स्वचालित रूप से निष्पादित करते हैं, जिससे अधिक कुशल और विश्वसनीय स्क्रैपिंग प्रक्रिया प्रदान की जाती है।
वेब पेज स्क्रैपर कैसे चुनें
वेब डेटा तक पहुँचने के कई तरीके हैं। यहां तक कि अगर आपने वेब स्क्रैपर तक सीमित कर दिया है, तो विभिन्न भ्रामक सुविधाओं वाले उपकरण जो खोज परिणामों में दिखाई देते हैं, फिर भी निर्णय लेना मुश्किल बना सकते हैं।
वेब स्क्रैपर चुनने से पहले, आप निम्नलिखित पहलुओं पर विचार कर सकते हैं:
- डिवाइस: यदि आप Mac या Linux उपयोगकर्ता हैं, तो आपको यह सुनिश्चित करना चाहिए कि उपकरण आपके सिस्टम का समर्थन करता है क्योंकि अधिकांश वेब स्क्रैपर केवल Windows के लिए उपलब्ध हैं।
- क्लाउड सेवाएँ: यदि आप किसी भी समय उपकरणों में डेटा तक पहुँचना चाहते हैं तो क्लाउड सेवाएँ महत्वपूर्ण हैं।
- API पहुँच और IP प्रॉक्सी: वेब स्क्रैपिंग की अपनी चुनौतियाँ और एंटी-स्क्रैपिंग तकनीकें हैं। IP रोटेशन और API पहुँच आपको कभी ब्लॉक होने से बचाने में मदद करेगी।
- एकीकरण: आप बाद में डेटा का उपयोग कैसे करेंगे? एकीकरण विकल्प पूरी डेटा प्रोसेसिंग प्रक्रिया को बेहतर ढंग से स्वचालित कर सकते हैं।
- प्रशिक्षण: यदि आप प्रोग्रामिंग में अच्छे नहीं हैं, तो यह सुनिश्चित करना बेहतर है कि पूरी डेटा स्क्रैपिंग प्रक्रिया में आपकी मदद करने के लिए मार्गदर्शिकाएँ और सहायता उपलब्ध हों।
- मूल्य निर्धारण: वेब पेज स्क्रैपर की लागत हमेशा विचार करने योग्य कारक होती है और यह विक्रेता से विक्रेता में बहुत भिन्न होती है।
शीर्ष 5 स्क्रैपिंग ब्राउज़र
1. स्क्रैपलेस
स्क्रैपलेस स्क्रैपिंग ब्राउज़र गतिशील वेबसाइटों से डेटा निष्कर्षण की प्रक्रिया को सरल बनाने के लिए डिज़ाइन किया गया एक उच्च-प्रदर्शन सर्वरलेस प्लेटफ़ॉर्म प्रदान करता है। पुपेटियर के साथ सहज एकीकरण के माध्यम से, डेवलपर्स समर्पित सर्वर की आवश्यकता के बिना हेडलेस ब्राउज़र चला सकते हैं, प्रबंधित कर सकते हैं और उनकी निगरानी कर सकते हैं, जिससे कुशल वेब ऑटोमेशन और डेटा संग्रह सक्षम होता है।
195 देशों और 70 मिलियन से अधिक आवासीय IP पतों को कवर करने वाले वैश्विक नेटवर्क के साथ, स्क्रैपिंग ब्राउज़र 99.9% अपटाइम और उच्च सफलता दर प्रदान करता है। यह IP ब्लॉकिंग और CAPTCHA जैसी सामान्य बाधाओं को दरकिनार करता है, जिससे यह जटिल वेब ऑटोमेशन और AI-संचालित डेटा संग्रह के लिए आदर्श बन जाता है। उन उपयोगकर्ताओं के लिए बिल्कुल सही जिन्हें विश्वसनीय, स्केलेबल वेब स्क्रैपिंग समाधान की आवश्यकता है।
इस वेब स्क्रैपिंग टूल को अपनी प्रोजेक्ट में कैसे एकीकृत करें? अब मेरे चरणों का पालन करें!
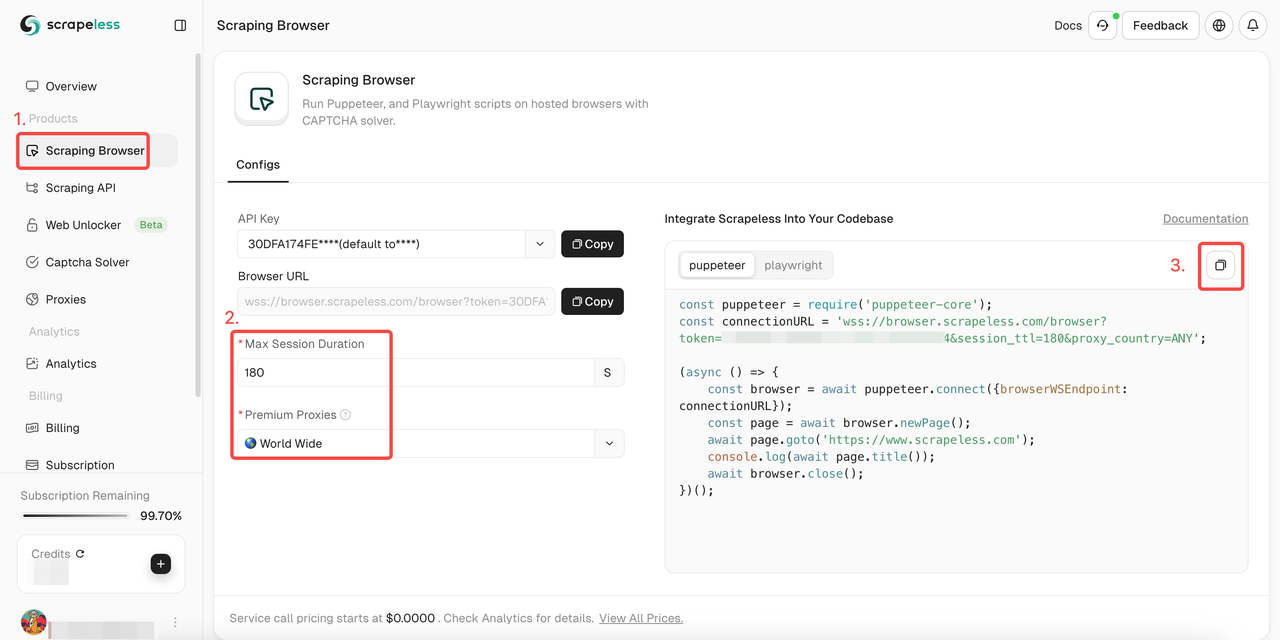
- साइन इन करें स्क्रैपलेस
- "स्क्रैपिंग ब्राउज़र" दर्ज करें
- अपनी आवश्यकताओं के अनुसार पैरामीटर सेट करें
- अपनी परियोजना में एकीकृत करने के लिए नमूना कोड कॉपी करें
- नमूना कोड:
- पुपेटियर
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //अपना टोकन इनपुट करें
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();- प्लेराइट
JavaScript
const {chromium} = require('playwright-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token='; //अपना टोकन इनपुट करें
(async () => {
const browser = await chromium.connectOverCDP(connectionURL);
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();- अधिक विवरण प्राप्त करना चाहते हैं? हमारा दस्तावेज़ीकरण आपको बहुत मदद करेगा!
2. पार्सहब
पार्सहब एक सामान्य वेब स्क्रैपिंग टूल है जो वेबसाइटों से डेटा एकत्र करने के लिए जावास्क्रिप्ट, AJAX तकनीक, कुकीज़ आदि का उपयोग करता है। यह Windows, Mac OS X और Linux सिस्टम का समर्थन करता है।
पार्सहब वेब दस्तावेज़ों को पढ़ने, विश्लेषण करने और उन्हें प्रासंगिक डेटा में बदलने के लिए मशीन लर्निंग तकनीक का उपयोग करता है। लेकिन यह पूरी तरह से मुफ़्त नहीं है, आप केवल पाँच स्क्रैपिंग कार्य मुफ़्त में सेट कर सकते हैं।
3. इम्पोर्ट
इम्पोर्ट.io एक अनोखा SaaS वेब डेटा एकीकरण सॉफ़्टवेयर है। यह अंतिम उपयोगकर्ताओं को डेटा संग्रह वर्कफ़्लो को डिज़ाइन करने और अनुकूलित करने के लिए एक दृश्य वातावरण प्रदान करता है।
यह एक प्लेटफ़ॉर्म पर डेटा निष्कर्षण से लेकर विश्लेषण तक संपूर्ण वेब निष्कर्षण जीवनचक्र को कवर करता है। और आप इसे आसानी से अन्य प्रणालियों में भी एकीकृत कर सकते हैं।
पूरी तरह से होस्ट किए गए स्क्रैपिंग ब्राउज़र के अलावा, हम शक्तिशाली प्लगइन्स या एक्सटेंशन का भी उपयोग कर सकते हैं:
4. वेबसक्रेपर
वेब स्क्रैपर में एक क्रोम एक्सटेंशन और एक क्लाउड एक्सटेंशन है।
क्रोम एक्सटेंशन संस्करण के लिए, आप वेबसाइट को नेविगेट करने और किन डेटा को स्क्रैप किया जाना चाहिए, इसके लिए एक साइटमैप (योजना) बना सकते हैं।
क्लाउड एक्सटेंशन बड़ी मात्रा में डेटा को स्क्रैप कर सकता है और एक साथ कई स्क्रैपिंग कार्य चला सकता है। आप डेटा को CSV में निर्यात कर सकते हैं या डेटा को Couch DB में संग्रहीत कर सकते हैं।
5. डेक्सी
डेक्सी.io कुशल प्रोग्रामिंग कौशल वाले उन्नत उपयोगकर्ताओं के लिए अधिक है। इसमें आपके लिए स्क्रैपिंग कार्य बनाने के लिए तीन प्रकार के प्रोग्राम हैं - एक्सट्रैक्टर, क्रॉलर और पाइपलाइन। यह विभिन्न प्रकार के उपकरण प्रदान करता है जो आपको डेटा को अधिक सटीक रूप से निकालने की अनुमति देते हैं। इसकी आधुनिक सुविधाओं के साथ, आप किसी भी वेबसाइट पर विस्तृत जानकारी को संभाल पाएंगे।
हालांकि, यदि आपके पास प्रोग्रामिंग कौशल नहीं है, तो वेब स्क्रैपिंग रोबोट बनाने से पहले आपको इसकी आदत डालने में कुछ समय लग सकता है।
स्क्रैपिंग ब्राउज़र आपके काम को कैसे बेहतर बना सकता है?
स्क्रैपिंग ब्राउज़र (जैसे पुपेटियर, प्लेराइट, आदि) निम्नलिखित कारणों से वेब क्रॉलिंग की दक्षता में महत्वपूर्ण सुधार कर सकते हैं:
- गतिशील सामग्री का समर्थन: पूर्ण ब्राउज़र रेंडरिंग क्षमताओं को प्रदान करके स्क्रैपिंग ब्राउज़र जावास्क्रिप्ट का उपयोग करके गतिशील रूप से उत्पन्न पृष्ठ सामग्री को संभाल सकते हैं, और अधिक मान्य डेटा क्रॉल कर सकते हैं।
- वास्तविक उपयोगकर्ता व्यवहार का अनुकरण: स्क्रैपिंग ब्राउज़र वास्तविक उपयोगकर्ता व्यवहार का अनुकरण कर सकते हैं, जैसे क्लिक करना, स्क्रॉल करना, डेटा दर्ज करना आदि, ताकि एंटी-क्रॉलिंग तंत्र द्वारा पता लगाने से बचा जा सके।
- स्थिरता में सुधार: स्क्रैपिंग ब्राउज़र प्रॉक्सी प्रबंधन, स्वचालित सत्यापन कोड समाधान और अन्य कार्यों को एकीकृत करके क्रॉलिंग की सफलता दर और स्थिरता में सुधार कर सकते हैं।
- क्रॉस-प्लेटफ़ॉर्म समर्थन: कई क्रॉलिंग ब्राउज़र क्रॉस-प्लेटफ़ॉर्म संचालन का समर्थन करते हैं और विभिन्न ऑपरेटिंग सिस्टम (Windows, Linux, MacOS, आदि) पर चल सकते हैं, जिससे अधिक लचीलापन मिलता है।
- उच्च समवर्ती समर्थन: कुछ क्रॉलिंग ब्राउज़र (जैसे ब्राउज़रलेस) क्लाउड सेवाएँ भी प्रदान करते हैं, उच्च-समवर्ती क्रॉलिंग और बड़े पैमाने पर डेटा संग्रह का समर्थन करते हैं, जो उन परिदृश्यों के लिए उपयुक्त है जिन्हें बड़ी मात्रा में डेटा को संसाधित करने की आवश्यकता होती है।
अंतिम विचार
कौन सा वेब स्क्रैपिंग टूल आपके लिए सबसे उपयुक्त है, स्क्रैपिंग ब्राउज़र या स्क्रैपिंग एक्सटेंशन? आप निश्चित रूप से तेज़ वेब स्क्रैपिंग के लिए सबसे सुविधाजनक और कुशल उपकरण का उपयोग करना चाहते हैं। अभी स्क्रैपलेस आज़माएँ!
स्क्रैपलेस स्क्रैपिंग ब्राउज़र वेब स्क्रैपिंग को सरल और कुशल बनाता है। CAPTCHA बाइपासिंग और IP स्मार्ट रोटेशन के साथ, आप वेबसाइट ब्लॉकिंग से बच सकते हैं और आसानी से डेटा स्क्रैपिंग प्राप्त कर सकते हैं।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


