
How to Scrape Web Pages by Using Scrapeless's Scraping Browser
Advanced Data Extraction Specialist
Why Choose Scrapeless’s Scraping Browser for Web Scraping?
Web scraping has become a vital tool for businesses to collect real-time data, from competitor pricing to market trends. A recent Statista survey found that over 70% of businesses rely on web scraping to extract valuable data, making it a crucial part of data-driven decision-making.
As the web scraping market grows, with projections to reach USD 5.4 billion by 2025 (MarketsandMarkets), businesses are increasingly adopting scraping tools for their efficiency and scalability. However, challenges like IP blocking, CAPTCHAs, and dynamic content can disrupt the scraping process.
Scrapeless solves these issues with its AI-driven solutions, ensuring seamless data extraction even in the face of common anti-scraping barriers.
Start scraping smarter today with Scrapeless's Scraping Browser! Effortlessly extract data from web pages with our user-friendly tool, designed to handle even the most complex websites. Try it now and experience seamless data extraction like never before!
Scrapeless offers an advanced AI-driven web scraping solution designed to help businesses overcome these common obstacles. The Scrapeless toolkit is tailored for those seeking high-quality, reliable, and fast data extraction from the web. Whether you want to scrape e-commerce sites, social media platforms, or news aggregators, Scrapeless offers the right tools to get the job done.
Key benefits of Scrapeless include:
- Seamless proxy management: Protect your scraping sessions with IP rotation and global coverage.
- AI-driven CAPTCHA solution: Automatically solve CAPTCHA challenges to ensure your data collection is uninterrupted.
- Advanced browser technology: Navigate complex, dynamic web pages without errors.
- Scalable solution: From small data extraction tasks to large-scale scraping operations, Scrapeless can scale to meet your needs.
Scrapeless is more than just another scraping tool. It is a comprehensive platform that solves key challenges associated with web scraping, ensuring your data collection remains fast, efficient, and reliable. Whether you are a startup or a large enterprise, Scrapeless’ flexibility allows you to customize your scraping tasks to your specific needs. From proxy management to handling complex websites with dynamic content, Scrapeless provides all the necessary tools to simplify your web scraping operations and save valuable time.
Scrapeless Scraping Browser:
At the heart of the Scrapeless web scraping solution is Scraping Browser. Scrapeless’s Scraping Browser is optimized to handle the most challenging scraping scenarios and integrates seamlessly with the Scrapeless toolkit to provide an exceptional scraping experience.
Key Features of Scrapeless Scraping Browser:
- 🌐 Dynamic Content Handling: Easily scrape websites with heavy JavaScript and dynamic content that other tools often struggle with.
- 🖥️ Headless Mode: Run scraping tasks without launching a full browser window, improving performance and reducing resource usage.
- 🛡️ Anti-Detection Technology: Prevent detection with advanced techniques like browser fingerprints and stealth mode.
- ⚡ Superior Efficiency: 10x faster than traditional browser mode, running on the server side for quicker response times and supporting large-scale concurrent access.
- ⏱️ 99.99% Uptime: Reliable, 24/7 availability ensures your scraping tasks always run on schedule.
With Scrapeless's Scraping Browser, your data extraction process becomes faster, more reliable, and easier, ensuring you can focus on extracting valuable insights rather than dealing with the technical challenges of scraping.
Getting Started with Scrapeless’s Scraping Browser
API Key (Application Programming Interface Key) is a tool used to verify identity and authorize access to an API. It is usually a unique string of letters, numbers, and symbols. API Key acts as an authentication "pass" when accessing the API, ensuring that the request is made by a legitimate user or application.
✅ You can get the API KEY by following the steps below:
- After clicking to log in to Scrapeless, you can automatically get the corresponding API KEY.
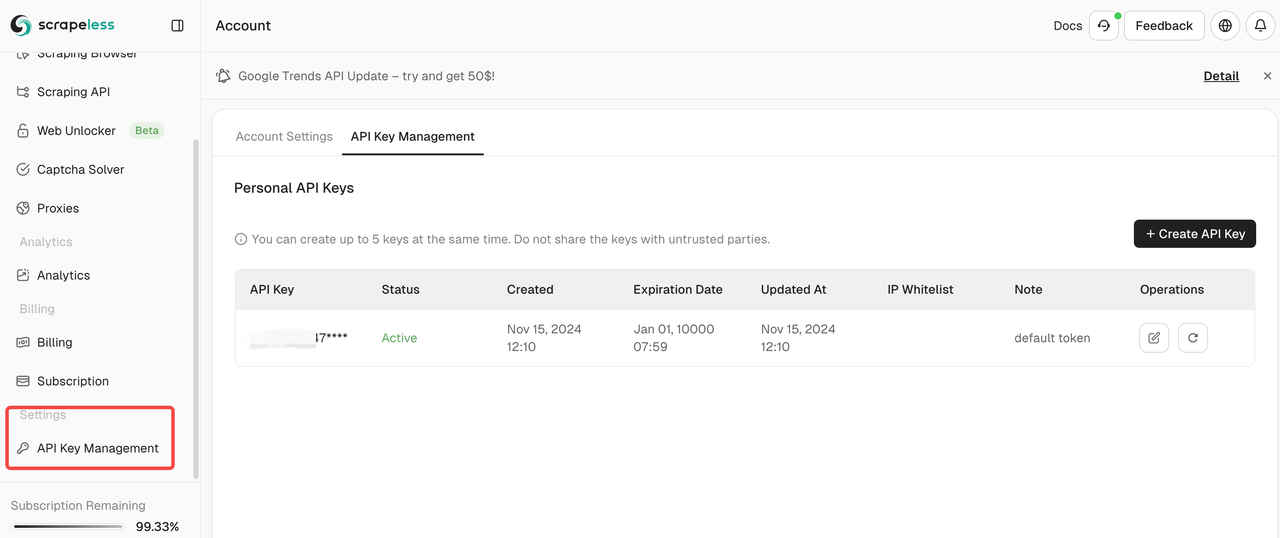
- You can see your API Key in API Key Management:
Step-by-Step Guide to Scraping Web Pages with Scrapeless
In this section, we will use scrapeless + puppeteer to demonstrate how to crawl product content in Amazon.
Puppeteer is a Node.js library developed by Google that provides a high-level API for performing automated operations through Chromium or Chrome browsers. It can be used to operate the browser, click, input, navigate, etc. like a human user, and can also crawl page content, generate screenshots and PDFs, test web pages, etc.
First, we need to get the API Key scrapeless. You can refer to the previous section to learn how to get and view your API Key.
Step-by-Step Guide to Scraping Web Pages with Scrapeless:
- Install puppeteer through npm command
npm i puppeteer-core- Prepare the connection parameters for scrapeless. You can set the session time and proxy country configuration.
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOU_TOKEN&session_ttl=180&proxy_country=ANY';- Start preparing to crawl product data on Amazon、
- Use the browser's developer tools (F12) to get the input box and search elements, and get the selector of the element.
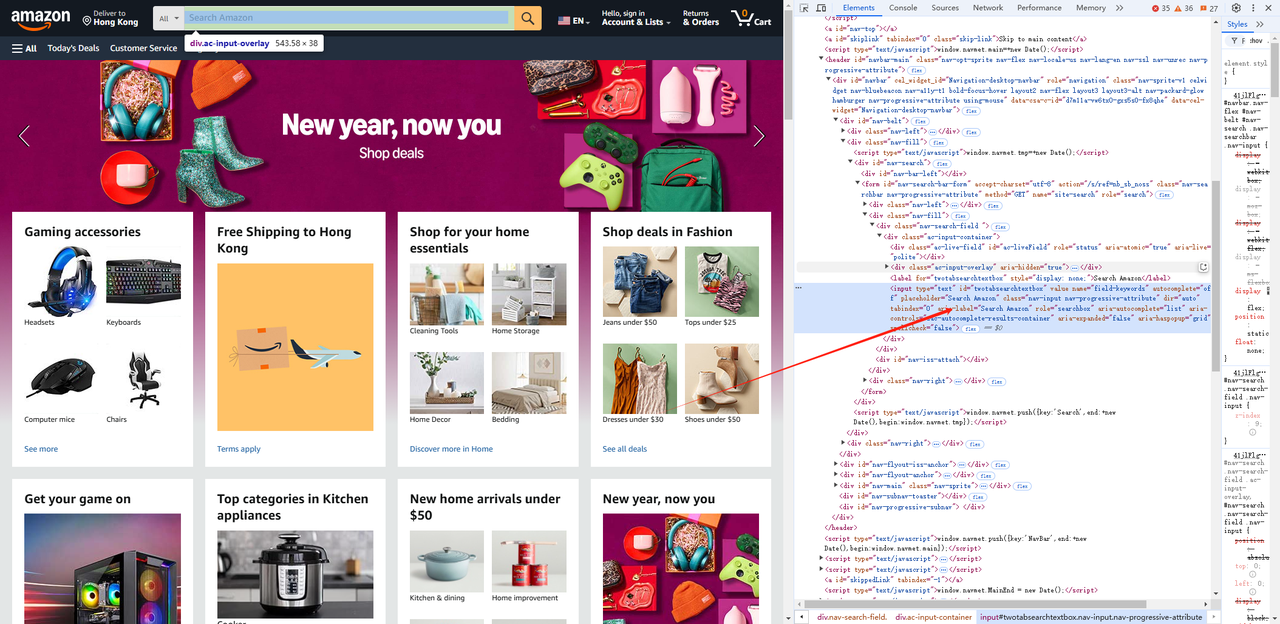
await page.waitForSelector('#twotabsearchtextbox')
await page.type('#twotabsearchtextbox', 'iphone 15', { delay: 100 })
await page.click('#nav-search-submit-button')You can replace iphone 15 with the content you want to crawl.
- Then we come to the product list page, and we get all the div elements whose role attribute is listitem.
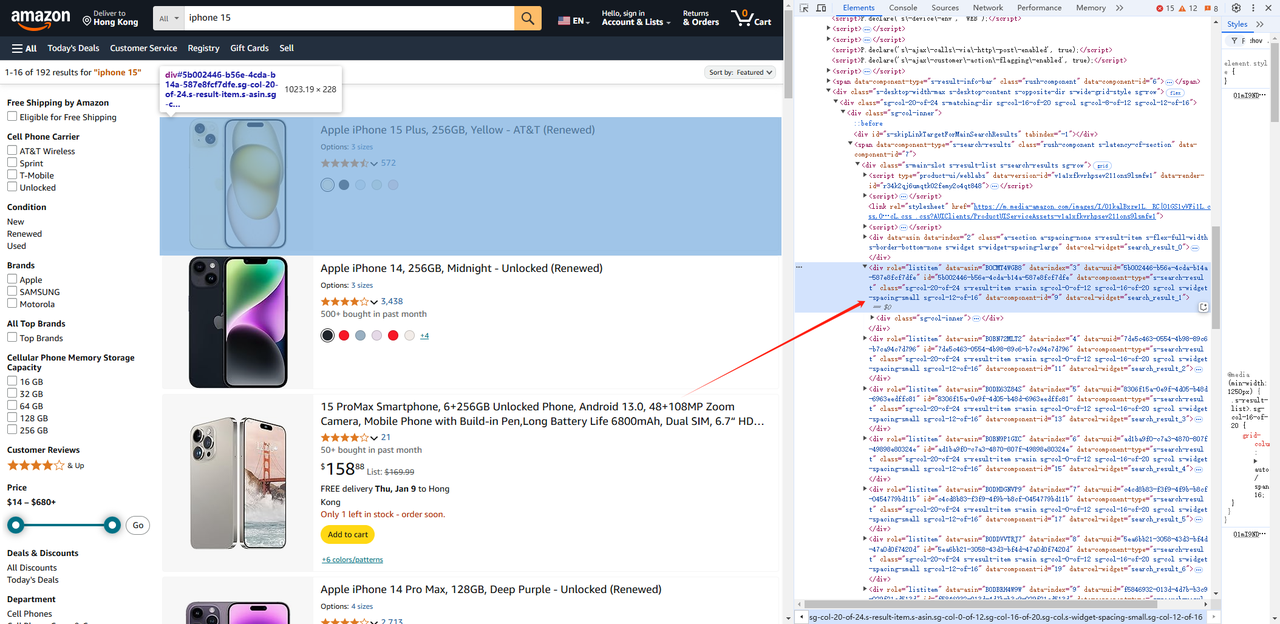
await page.waitForSelector('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]') // You need to wait for the element to be rendered before fetching it
const list = await page.$$('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')- In the same way, we can get product information such as pictures, titles, links, etc. for each Element.
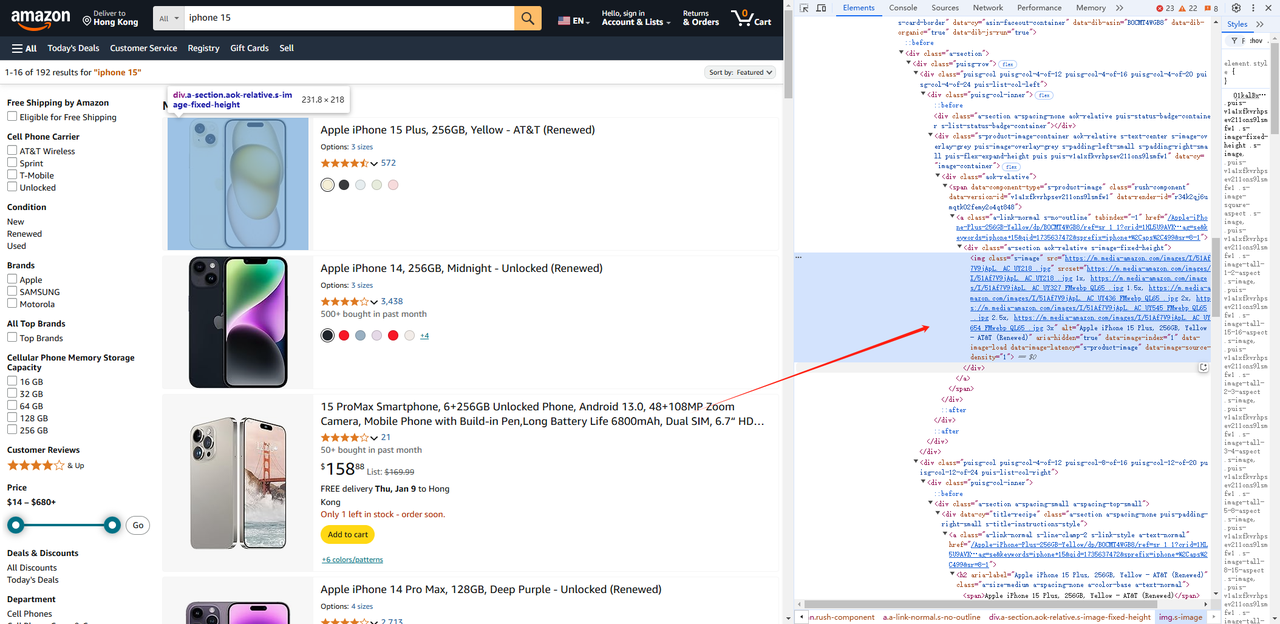
const renderList = []
for (const item of list) {
const img = await item.$('img').then((ele) => {
return ele.evaluate((ele) => {
const img = ele.getAttribute("src")
const title = ele.getAttribute("alt")
return { img, title }
})
})
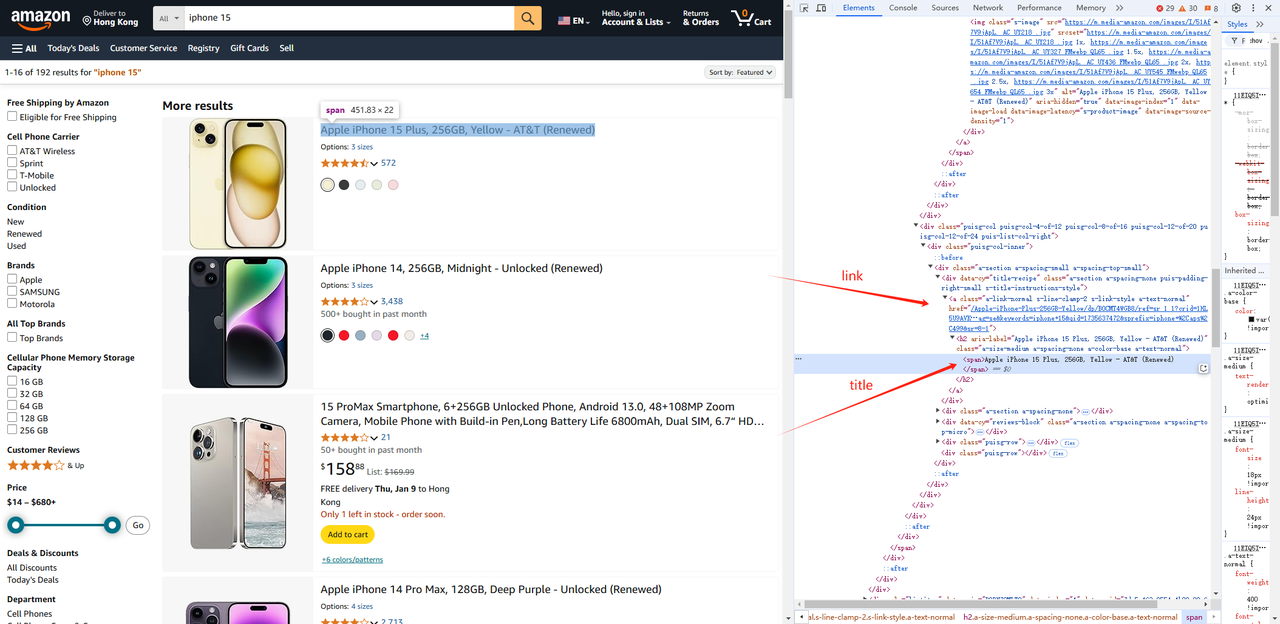
const link = await item.$('.a-link-normal.s-line-clamp-2.s-link-style.a-text-normal').then((ele) => {
return ele.evaluate((ele) => {
return `https://www.amazon.com${ele.getAttribute("href")}`
})
})
img.link = link
renderList.push(img)
}Run the following complete code to get the crawled content:
import puppeteer from 'puppeteer-core';
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOU_TOKEN&session_ttl=180&proxy_country=ANY';
(async () => {
try {
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL
});
const page = await browser.newPage();
await page.goto('https://www.amazon.com/');
await page.waitForSelector('#twotabsearchtextbox')
await page.type('#twotabsearchtextbox', 'iphone 15', { delay: 100 })
await page.click('#nav-search-submit-button')
await page.waitForSelector('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')
const list = await page.$$('.s-main-slot.s-result-list.s-search-results.sg-row > div[role=listitem]')
const renderList = []
for (const item of list) {
const img = await item.$('img').then((ele) => {
return ele.evaluate((ele) => {
const img = ele.getAttribute("src")
const title = ele.getAttribute("alt")
return { img, title }
})
})
const link = await item.$('.a-link-normal.s-line-clamp-2.s-link-style.a-text-normal').then((ele) => {
return ele.evaluate((ele) => {
return `https://www.amazon.com${ele.getAttribute("href")}`
})
})
img.link = link
renderList.push(img)
}
console.log(JSON.stringify(renderList))
} catch (e) {
console.error(e)
}
})();[
{
"img": "https://m.media-amazon.com/images/I/61WUSYIQdKL._AC_UY218_.jpg",
"title": "Apple iPhone 14, 256GB, Midnight - Unlocked (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-14-256GB-Midnight/dp/B0BN72MLT2/ref=sr_1_1?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-1"
},
{
"img": "https://m.media-amazon.com/images/I/51Af7V9jApL._AC_UY218_.jpg",
"title": "Apple iPhone 15 Plus, 256GB, Yellow - AT&T (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-Plus-256GB-Yellow/dp/B0CMT4WGB8/ref=sr_1_2?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-2"
},
{
"img": "https://m.media-amazon.com/images/I/71wtsuGLA4L._AC_UY218_.jpg",
"title": "15 ProMax Smartphone, 6+256GB Unlocked Phone, Android 13.0, 48+108MP Zoom Camera, Mobile Phone with Build-in Pen,Long Batt...",
"link": "https://www.amazon.com/15-ProMax-Smartphone-Unlocked-Titanium/dp/B0DK63Z84S/ref=sr_1_3?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-3"
},
{
"img": "https://m.media-amazon.com/images/I/71Xu6GSGm1L._AC_UY218_.jpg",
"title": "Apple iPhone 15 Pro, 128GB, Natural Titanium - Boost Mobile (Renewed)",
"link": "https://www.amazon.com/Apple-iPhone-128GB-Natural-Titanium/dp/B0DK7BCPH5/ref=sr_1_4?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-4"
},
{
"img": "https://m.media-amazon.com/images/I/61j3-75mrLL._AC_UY218_.jpg",
"title": "SZV 15 ProMAX 12+512GB Unlocked Cell Phone,Smartphone 6.85\" HD Screen Unlocked Phones,Battery 7000mAh Android 13,5G/Face I...",
"link": "https://www.amazon.com/SZV-Unlocked-Smartphone-Battery-Fingerprint/dp/B0DHDGNVP9/ref=sr_1_5?dib=eyJ2IjoiMSJ9.y5hgU9CApRyUEgA7ZqW8yu5W1la5NtBQIQw2LoI8H-oi25OtUzmmkGfI72ra-OzBH8ix2c2Sdap-SkliBNr2FinxXk8oMIF7nRzL2EGFN7OpMgrBxAppYmhHHML8mmhwPvCvF0tYHIZG8XXnHx0ka36Uk-Hl4h2P1Kn6BYwBwCWESgu6uTcaW2-TVjYAOOvR_FgOf9R_vO6ZRFbVJIupFN3Gdo-VRxFytgP3qPt7NoM.INS-GGw10RU3RMfRuxNdFR_9rPFaQq2hsqtZZiC9PY8&dib_tag=se&keywords=iphone+15&qid=1735619455&sr=8-5"
}
]Advanced Features for Power Users
When conducting large-scale or complex web scraping operations, advanced features are essential to maintain efficiency, overcome obstacles, and scale your scraping tasks. Scrapeless Scraping Browser offers a range of powerful features to meet the needs of professional users who need more than just basic scraping capabilities, and also provides some advanced features:
- Customize scraping parameters for specific use cases
One of the main challenges of web scraping is tailoring your tools to extract exactly what you need without generating redundant data or missing opportunities. Scrapeless offers advanced customization options that allow users to set specific scraping parameters to fit their exact use case.
- Handle CAPTCHA and anti-scraping protections
Websites often deploy CAPTCHA challenges and complex anti-scraping mechanisms to block automated robots. Scrapeless Scraping Browser is a cloud-based fingerprinting browser with CAPTCHA unblocking capabilities. These advanced solutions not only increase the speed of data collection, but also reduce the likelihood of being detected or blocked by websites with strong anti-bot measures.
- Use proxies and rotations for scalability and avoid IP bans
Scaling up scraping operations often leads to websites banning IPs and limiting rates, which interrupts data collection. To alleviate this problem, Scrapeless provides a powerful proxy network that includes IP rotation and proxy pools to help you maintain continuous, large-scale crawling without interruption. Scrapeless provides access to a vast proxy network of more than 80 million IPs from more than 200 countries, ensuring that users can distribute requests and avoid IP bans.
Best Practices for Effective Web Scraping
Web scraping is a powerful tool for businesses looking to collect valuable data from the web. However, in order to extract data efficiently and avoid common pitfalls, it’s important to follow best practices. By leveraging AI-driven solutions like Scrapeless, businesses can enhance their scraping strategies to ensure accuracy, compliance, and scalability. Here’s a breakdown of web scraping best practices, including how Scrapeless can optimize these processes for you.
Ensure Data Accuracy and Completeness
One of the main challenges of web scraping is ensuring the data collected is accurate. When extracting large datasets from a variety of sources, it’s easy to run into issues like missing or inconsistencies in data. To combat this, AI algorithms in Scrapeless can automatically analyze web page structure and adjust the scraping approach to fit the content.
Comply with Legal and Ethical Standards
With increasing scrutiny on web scraping, it’s critical to operate within legal and ethical boundaries. Scrapers must be aware of privacy laws, website terms of service, and regulations like GDPR. Scrapeless helps maintain compliance by integrating intelligent robot.txt detection to ensure that scraping adheres to the rules set by website owners.
Additionally, AI can be used to analyze web page content and filter sensitive or protected data, ensuring businesses avoid unethical practices. Scrapeless’s AI algorithms are designed to help users comply with legal requirements, helping them avoid risks such as intellectual property infringement or privacy violations.
Avoid being blocked by websites
Websites often deploy anti-scraping measures to detect and block automated scrapers. The AI technology in Scrapeless helps avoid detection by simulating human browsing behavior, making scraping requests look more natural. The AI algorithm adjusts request frequency, timing, and headers to mimic real user activity, greatly reducing the likelihood of being blocked.
In addition, Scrapeless uses proxy rotation, an AI-driven system that automatically switches between multiple IP addresses to distribute requests. This helps bypass rate limits and prevents websites from blocking a single IP address for sending too many requests. By intelligently using AI-based proxy rotation, Scrapeless ensures uninterrupted data extraction.
Optimizing Scrapeless Technology for Large-Scale Data Collection
For businesses engaged in large-scale data collection, scraping efficiency and scalability are critical. Scrapeless’ AI capabilities automatically adjust scraping strategies to ensure optimal performance, even when extracting data from complex or large websites. For example, Scrapeless’ AI-driven crawler can handle dynamic content such as JavaScript-intensive websites, enabling businesses to crawl a wider range of content that traditional tools may struggle to handle.
In addition, AI algorithms help prioritize the most important data, ensuring efficient allocation of resources when processing large amounts of information. This enables seamless high-volume crawling that meets business needs while maintaining speed and performance.
Following web scraping best practices is key to maximizing the value of the data collected. By leveraging Scrapeless’ AI-driven crawling technology, businesses can improve data accuracy, ensure legal compliance, avoid being blocked by websites, and optimize crawling operations for large-scale data collection. With Scrapeless, companies can quickly, efficiently, and ethically access the data they need, helping them stay ahead in a competitive, data-driven space.
Troubleshooting Common Web Scraping Issues
- Website Structure Changes
- Problem: Websites frequently update their layout or HTML structure, causing scrapers that rely on specific tags to break.
- Solution: Build flexible scrapers using dynamic techniques or implement error handling that can adapt to minor changes. Scrapeless offers a smart, AI-powered scraper that detects changes and adjusts accordingly.
- IP Blocking
- Problem: Websites limit the number of requests from a single IP address, blocking scrapers after too many attempts.
- Solution: Use Scrapeless Proxies with IP rotation to distribute requests across multiple IPs, making it harder for websites to detect scraping patterns and block access.
- CAPTCHAs and Anti-Scraping Mechanisms
- Problem: CAPTCHAs and other anti-bot measures (like JavaScript challenges) can stop your scraper in its tracks.
- Solution: Leverage Scrapeless Captcha Solver to automate CAPTCHA solving. For JavaScript-heavy pages, use Scrapeless Scraping Browser, which efficiently handles dynamic content.
- Rate Limiting
- Problem: Websites limit the number of requests in a specific time frame to prevent server overload, causing scrapers to fail.
- Solution: Set up your scraper with proxies and rotation, and rate-limiting controls to mimic human behavior and avoid hitting rate limits.
- Data Inaccuracy or Missing Information
- Problem: Scraping results in incomplete or inaccurate data due to errors in scraping logic or poor data parsing.
- Solution: Implement checks to validate the scraped data and ensure the scraper is properly configured. Scrapeless uses AI-driven algorithms to ensure data integrity and consistency.
- Legal and Ethical Issues
- Problem: Scraping certain websites may violate terms of service or local laws, leading to legal consequences.
- Solution: Always ensure you are in compliance with legal and ethical standards. Scrapeless provides a built-in framework to help ensure your scraping activities stay within legal boundaries.
For more common challenges in web scraping and how to solve them, read: How to Solve Web Scraping Challenges - Full Guide 2025
FAQs About Scraping Web Pages
1. How do I scrape a web page?
The simplest method is to manually copy the required data directly from the web page and paste it into the document.
You can also use the browser's developer tools (such as Chrome's "Inspect" function) to view the HTML structure of the web page and extract data from it. The simplest is to use no-code tools such as Scrapeless, which allow users to easily set up scraping tasks through a graphical interface without writing code.
With these methods, you can effectively scrape the web page and extract the required data.
2. Is it OK to scrape data from websites?
Web scraping is legal as long as you follow the site's terms of service, data use policy, and local laws. Always check the site's robots.txt file and terms of service before scraping. It's best to follow rate limits and avoid scraping personal or copyrighted data.
3. How do I extract all pages from a website?
You can use a web crawler to scrape all pages of a website. This involves recursively visiting all the links from the homepage or other key pages. Tools like Scrapeless Scraping Browser or Scrapeless API can automate this process, extracting data from every page based on the website’s structure.
4. Which tool is used for web scraping?
Common web scraping tools include Scrapeless, BeautifulSoup, Selenium, Octoparse, and Scrapy. These tools allow users to automate the process of extracting data from websites by sending requests, parsing HTML content, and providing the data in structured formats like CSV, JSON, or Excel.
5. Can you make money web scraping?
Yes, you can make money with web scraping by providing data extraction services to businesses, conducting market research, or scraping publicly available data for clients. Web scraping can also be used to gather data for competitive analysis, lead generation, or building specialized databases that are valuable to industries like e-commerce, real estate, and finance.
Conclusion: Why Scrapeless is the Future of Web Scraping
Scrapeless provides a powerful, AI-driven solution to simplify web scraping tasks, bringing huge benefits to developers and businesses. With its cutting-edge features, Scrapeless ensures that your data collection is efficient, accurate, and scalable:
- AI Scraping: Leverages AI to improve scraping efficiency and handle complex, dynamic content.
- 10x Faster: Optimized browser operation makes it 10x faster than traditional scraping methods.
- CAPTCHA and Anti-Scraping Bypass: Automatically bypass CAPTCHA and other anti-bot protections.
- Customizable Scraping: Customize scraping parameters to meet specific needs and use cases.
- Automated Workflows: AI-driven automation reduces manual intervention and simplifies data collection.
Whether you are a developer looking to improve scraping efficiency or an enterprise looking to collect structured data at scale, Scrapeless offers a comprehensive solution to meet your needs. Don’t let the complexity of web scraping slow you down - start using Scrapeless today and unlock the potential of seamless, AI-driven web data extraction.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


