
How to Use Playwright to Bypass Cloudflare in 2024
Advanced Data Extraction Specialist
When utilizing a headless browser, is your web scraper still being blocked? You will discover how to bypass Cloudflare by improving Playwright's mask in this guide.
Cloudflare: What Is It?
Bot Management, a service provided by security and performance optimization provider Cloudflare, is a nightmare for many scrapers. About one-fifth of websites utilize web application firewalls (WAFs), which routinely identify and stop scrapers. Headless browsers like as Playwright and Selenium fall under this category.
How Does Cloudflare Work
Cloudflare compares and separates traffic that was generated by bots and by actual users using a number of techniques, such as:
Behavioral Analysis: It monitors several aspects of the user's interactions with the website, including clicks, mouse movements, and page load times.
IP Reputation Analysis: Every request's IP address is compared to a database to determine whether it has been used for scraping.
User-Agent Analysis: string serves as a means of identifying the browser or device making the website request. Cloudflare can identify generic or instantly identifiable User-Agent strings used by scrapers.
CAPTCHA Tests: system may choose to determine if a user submitting a request to a website is a robot or a human. The request will be approved if the user passes. It will be banned otherwise.
Request Rate Analysis: Using this technique, one may track the volume of queries sent to a website and spot trends that are characteristic of automated bots. Bots, for instance, frequently send out a lot of requests in a short amount of time.
Why Using Base Playwright Is Insufficient to Bypass Cloudflare
Base It might not be possible to get past Cloudflare's anti-bot defenses using Playwright. The cause? While some of the difficulties may be overcome by simulating human-like browsing behavior using this or other browser automation tools, more sophisticated methods, such utilizing proxies and custom user agents, could need extra effort to get over.
To demonstrate this, let's start up a NodeJS Playwright project and see how it fails to work across Cloudflare.
Step 1: Verify that npm and Node.js are installed on your computer.
Step 2: Use this command to launch a new project after navigating to the desired directory:
language
npm initStep 3: Now use the following command to install Playwright as a dependency.
language
npm install playwrightStep 4: Fantastic Work! You may now start using Playwright. Make a new file with a .js extension, such as scraper.js in your project directory. In it, build a script to visit https://crozdesk.com and grab a screenshot.
language
const playwright = require("playwright");
async function scraper() {
const browser = await playwright.chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto("https://crozdesk.com");
await page.waitForTimeout(1000);
await page.screenshot({ path: "screenshot.png", fullPage: true });
await browser.close();
}
scraper();Our scraper utilizes Chromium as a browser, as you can see on line four, but you are free to use another one.
Step 5: Use this command to run the entire code:
language
node scraper.jsThis is the outcome:
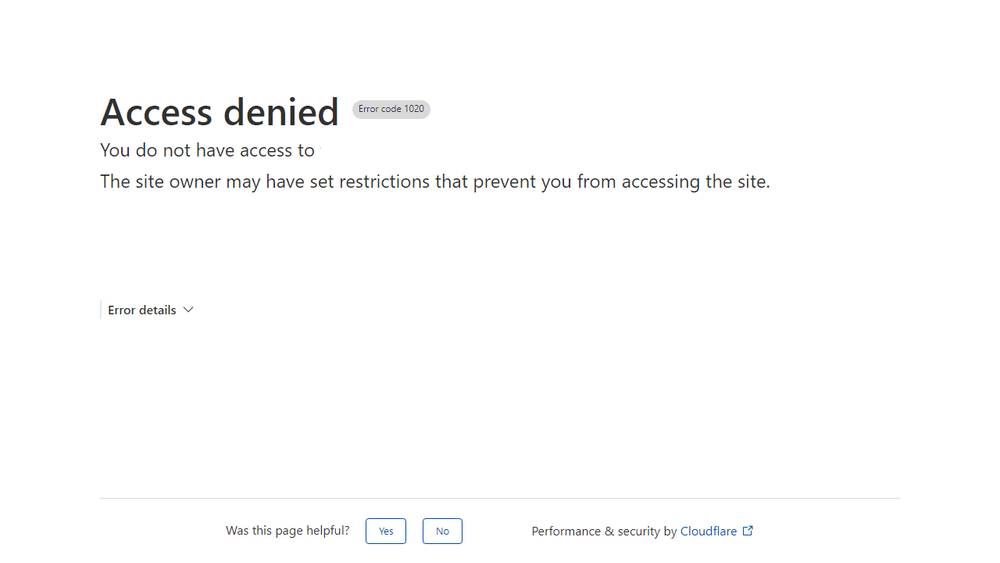
Unfortunately, Playwright's simple version gets flagged as a bot and is then blocked from accessing the website.
In the next part, we'll go over a few strategies that will assist you bypass Cloudflare. Continue reading!
How to Bypass Cloudflare by Masking Playwright
Let's look at a few strategies for handling Cloudflare's detection techniques. Usually, for your script to function, a mix of these will be required.
Method 1: Replicate Human Conduct
To make the automated browser look more human, you may add random pauses, scrolling, and other interactions with the website to our earlier Playwright scraper code.
Method 2: Employ proxies
It's simple to get banned from website scraping if you send out too many queries in a short amount of time. By employing rotating proxies to make yourself appear to be various users, you may prevent it.
Method 3: Choose a Unique User-Agent
User-Agents hold facts about the client making the requests, including the operating system and browser. It is preferable to use a custom User-Agent that mimics a popular online browser rather than Playwright's default one in order to prevent getting detected.
Method 4: Use a CAPTCHA Solver
With Playwright, you may use a variety of tools, like Scrapeless, to solve CAPTCHAs.
Fed up with constant web scraping blocks and CAPTCHAs?
Introducing Scrapeless - the ultimate all-in-one web scraping solution!
Unlock the full potential of your data extraction with our powerful suite of tools:
Best Web Unlocker
Automatically solve advanced CAPTCHAs, keeping your scraping seamless and uninterrupted.
Experience the difference - try it for free!
Method 5: Add Playwright-extra
Playwright-extra is a framework for Playwright plugins that is lightweight and allows for additional helpful add-ons. The one we'll use to get around Cloudflare is called Puppeteer-extra-plugin-stealth, and it employs a number of strategies, including mouse event generation and User-Agent modification, to conceal the usage of a headless browser.
In conclusion
As you can see, you can use Playwright to get around Cloudflare, but you might need to use some sophisticated tricks that might not work every time. In the meanwhile, Scrapeless will help you succeed right away and provide you with a free API key right now.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


