
How to Use Playwright to Bypass CAPTCHA
Advanced Bot Mitigation Engineer
Have any CAPTCHAs prevented you from web scraping? These difficulties might cause headaches when automating the gathering of data. Fortunately, there are 2 ways to get around CAPTCHA using Playwright, which we'll go into in this post.
Is Playwright Able to Solve CAPTCHA?
CAPTCHAs are meant to be difficult for bots but simple for people, but we'll also look about how you may utilize Playwright in conjunction with other useful tools to eliminate them.
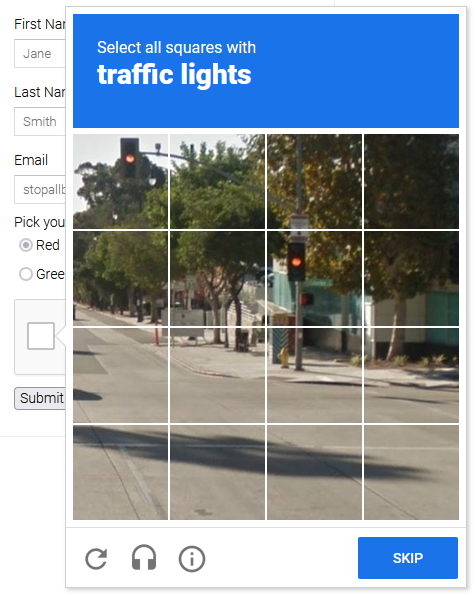
One crucial lesson is that you may either: A) complete the exam as soon as it occurs; or B) avoid it altogether and attempt again if it does appear.
In the first scenario, using a Playwright CAPTCHA solver will be necessary, and it may get pricey in large quantities. To avoid detection in the second case, your scraper has to better mimic human behavior. Both strategies will be shown, but as a starting point, the second one is the greatest.
Let's now examine how you can put these into practice!
Method 1: Use Base Playwright and Captcha Solver to Bypass CAPTCHA.
The first method we'll discuss is using Playwright with Scrapeless, a service that solves CAPTCHAs by employing humans on your behalf.
Are you tired with CAPTCHAs and continuous web scraping blocks?
Scrapeless: the best all-in-one online scraping solution available!
Utilize our formidable toolkit to unleash the full potential of your data extraction:
Best CAPTCHA Solver
Automated resolution of complex CAPTCHAs to ensure ongoing and smooth scraping.
Try it for free!
Method 2: Employ the Stealth Plugin in Playwright
If you need to scrape data from a website that employs more difficult CAPTCHA obstacles, the previous Playwright setup won't work, but the Stealth plugin is a useful workaround. This open-source project adds elements to Playwright to make it more like real web traffic:
- Your User-Agent is hidden.
- In order to avoid IP address identification, WebRTC is disabled. It preserves privacy by hiding browsing history even if it doesn't specifically prohibit tracking scripts.
- To make your requests seem more natural, it enhances your headless browser with additional components.
- To add additional vigor to our example, let's try Astra, a website that has minimal Cloudflare security.
Install the necessary dependencies before you begin by executing the following command within your project folder:
language
npm install playwright playwright-extraIt should be noted that the playwright-extra framework has the Stealth plugin.
To enhance Playwright, use playwright-extra to launch a headless Chrome browser and chromium.use(pluginStealth) to enable puppeteer-extra-plugin-stealth. This set of technologies offers further safeguards to make it harder for websites to identify your web scraper.
language
const { chromium } = require('playwright-extra')
// Load the stealth plugin and use defaults (all tricks to hide playwright usage)
const pluginStealth = require("puppeteer-extra-plugin-stealth");
// Use stealth
chromium.use(pluginStealth)
// That's it, the rest is playwright usage as normal 😊
chromium.launch({ headless: true }).then(async browser => {
// Create a new page
const page = await browser.newPage()
// Go to the website
await page.goto('https://www.scrapeless.com/')
// Wait for page to download
await page.waitForTimeout(1000);
// Take screenshot
await page.screenshot({ path: 'screen.png'})
// Close the browser
console.log('All done, check the screenshot. ✨')
await browser.close()
})Our website is prepared for scraping when a new page has been loaded using browser.newPage() and a page.goto() method has been called.
Conclusion
It can be difficult to get around CAPTCHA using Playwright because this well-known obstacle is meant to stop automatic access to websites. Nonetheless, you will be able to scrape the desired data if you have the appropriate tools and libraries.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


