
Exciting Upgrades to Scraping Browser and SERP API You Need to Know
Advanced Data Extraction Specialist
In the digital age, data scraping and analysis have become indispensable tools for enterprises and researchers. Whether it is in market surveys, SEO optimization, or building large language models (LLMs), efficient data acquisition and management are crucial. Scrapeless Scraping Browser and SERP API have undergone significant upgrades, which will help you more easily obtain and manage data, whether you need to scrape comments from Google Maps or extract information from search engine results pages (SERPs).
Scraping Browser new features: smarter and more efficient data capture
With the increasing demand for data scraping, Scrapeless has delved into the pain points of developers and launched a new version of the Scraping Browser , aiming to provide a smarter and more efficient data scraping experience. These new features of the Scraping Browser can help you save time, reduce errors, and improve overall scraping efficiency. Let's take a closer look at how these updates make data scraping easier and more intuitive.
Real-time data statistics and session management
Real-time monitoring and management of sessions are key to ensuring efficient work during the data capture process. The new version of Scraping Browser introduces real-time data statistics, which can track new session data in real-time and display the status (running, successful, and failed) of the captured browser session. The addition of this feature allows users to more intuitively monitor session status and ensure smooth data capture.
In addition, Scrapeless has added conversation features, including:
- Session list and records: Users can better manage and monitor sessions by viewing the session list and records. Whether viewing historical sessions or tracking current sessions, it is clear at a glance.
- Session stop function: Users can terminate sessions directly through the dashboard without manual intervention, greatly improving the convenience of operation.
Session status display and API key configuration optimization
In order to help users track active sessions more easily, we have added a session status display function, which clearly displays the status of success and failure through logs. At the same time, we have optimized the UI of API key configuration. When the API key is empty, the system will provide clear guidance to help users solve problems quickly.
How to Use the Scraping Browser: A Detailed Guide
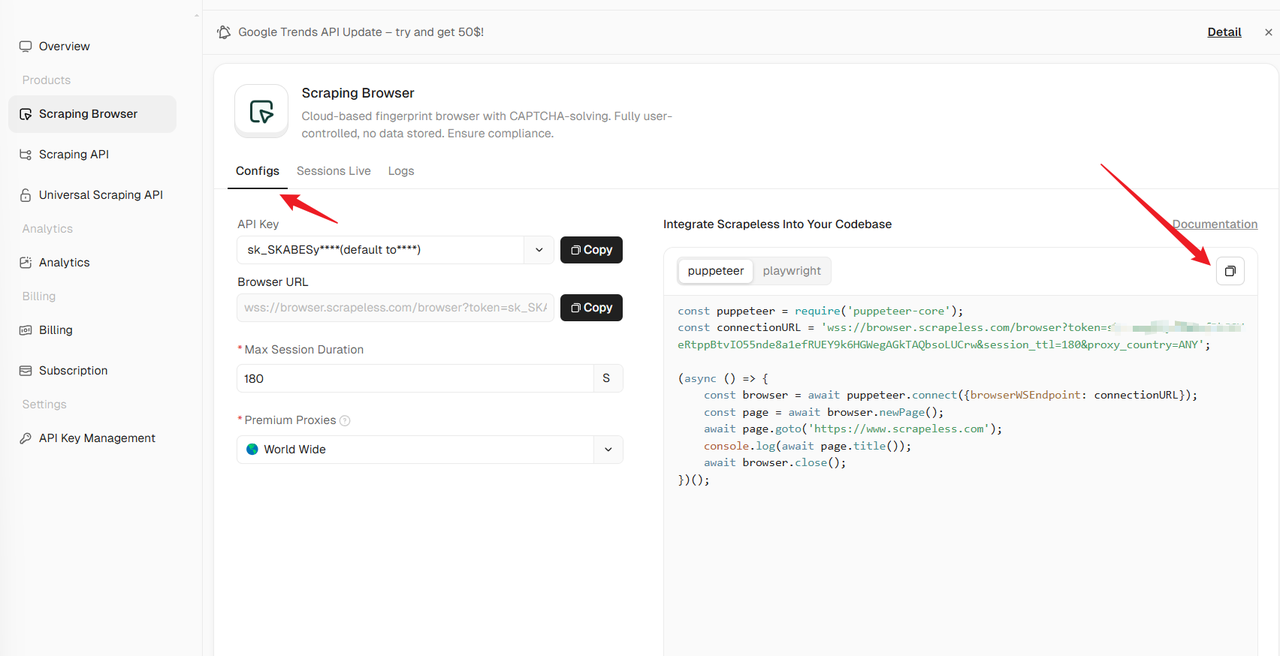
Step 1: Run your Scraping Browser
Go to the Scraping Browser menu and click Configs . You can select your apiKey and other configurations on the left, and then select your preferred crawler framework sample code on the right. Copy the sample code to your IDE, modify the code execution logic according to the actual situation, and run the code.
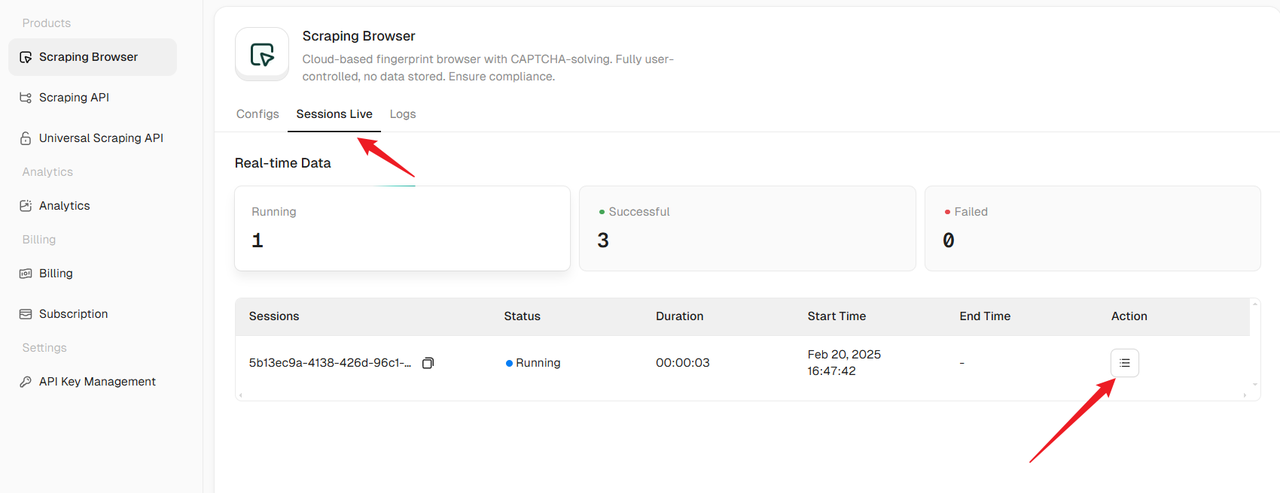
Step 2: View browser running status in real time
After the code script starts, you can see the current browser running status and the list of running browsers in the Sessions Live tab. Click the button in the Action column of the list to enter the details page.
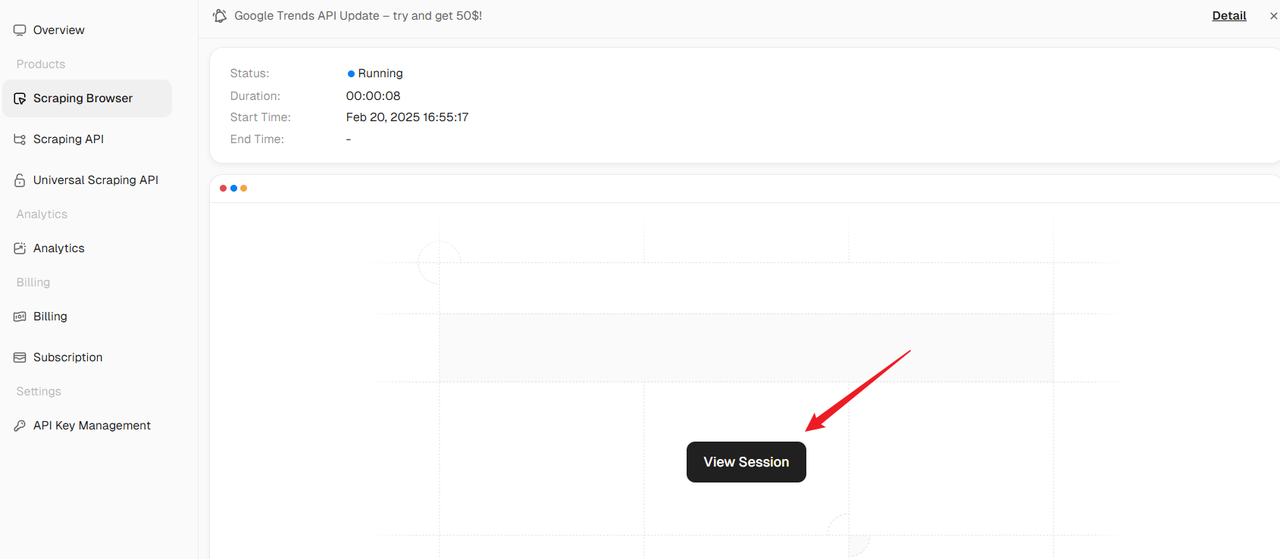
In the details page, you can see the basic information of the current browser running. Click "View Session" to view the real-time session preview of the browser.
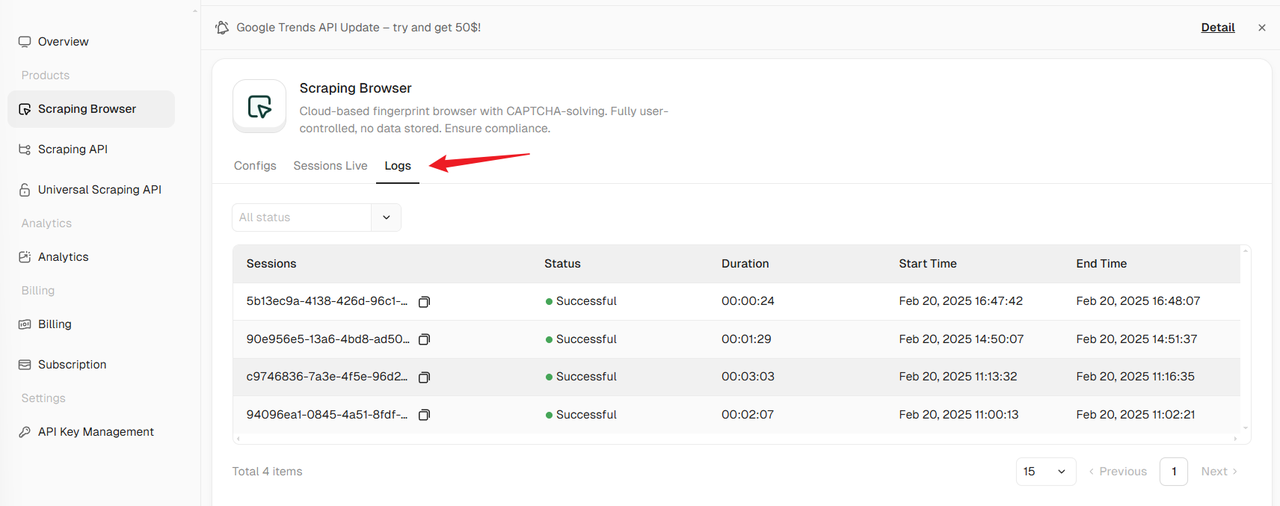
Step 3: View log information
In the Logs tab, you can view browser logs of all past executions, making it easy for you to review and analyze historical data.
Why choose Scraping Browser?
Scraping Browser 's updates and new features not only improve the flexibility of crawling, but also make the operation more intuitive and simple. Whether you are conducting Data Analysis, SEO research, or data crawling for e-commerce platforms, Scraping Browser can provide efficient and reliable crawling solutions.
- Real-time monitoring: comprehensively track the progress of each session to ensure efficient and accurate crawling process.
- Flexible configuration: The user-friendly interface allows you to quickly configure API keys and supports multiple crawler frameworks.
- Automatic Unblocking: It has a built-in website unlocking feature that can automatically handle various anti-spider mechanisms, including CAPTCHA solving, fingerprinting, and automatic retries
SERP API New Feature: Google Shopping API Launched
In addition to the update of Scraping Browser, SERP API has also welcomed new features. This week, we officially launched the Google Shopping API , which will help users obtain more comprehensive search result data. The documentation of Google Shopping API has been launched on Apifox and Apidog, and users can visit the Google Shopping API documentation for more information.
Main features:
- Easy to integrate and use
Scrapeless provides concise API interfaces and detailed documentation, supports multiple programming languages, and facilitates developers to quickly integrate into existing systems.
- High availability and stability
Scrapeless ensures high success rate and stability of data capture through a global proxy network and advanced technology backend, with an SLA of up to 99.9%.
- Flexible parameter configuration
Users can configure search parameters according to their needs, such as keywords, geographic location, language, etc., to obtain accurate shopping search results.
Usage scenarios of Google Shopping API
- E-commerce Data Analysis
By capturing data from Google Shopping pages, you can analyze competitors' product information, pricing strategies, and user reviews to optimize your own product strategy.
- Market trend research
Google Shopping API can help you obtain search trends for popular products, analyze market dynamics, and provide data support for product development and marketing strategies.
- SEO optimization
By analyzing the search results of Google Shopping pages, you can better understand user requests, optimize keyword strategies, and improve the natural search ranking of your website.
Stay tuned for more exciting updates!
The above are the main updates of Scraping Browser and SERPAPI. We are always committed to providing users with more efficient and convenient data capture tools. Thank you for your continuous support, and stay tuned for more exciting updates! You can also join Scrapeless's Discord community to learn more.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


