
Scrapeless Is Now Available on Pipedream!
Senior Web Scraping Engineer
We’re thrilled to announce that Scrapeless is now officially live on Pipedream! 🎉
This means you can now seamlessly leverage Scrapeless’s powerful scraping capabilities within this robust serverless integration platform to build automated data extraction workflows — no more messy scraper configurations or anti-bot headaches.
Why Choose Pipedream?
Pipedream is a highly flexible and efficient automation platform that supports event-driven architecture and allows you to integrate hundreds of services like Slack, Notion, GitHub, Google Sheets, and more. You can write custom logic in JavaScript, Python, and other languages — without ever managing servers or infrastructure.
It's the perfect environment for building webhooks, syncing data, creating real-time notifications, and automating anything you need — streamlining development and saving time.
Build Your First Scrapeless Workflow in Pipedream!
Prerequisites
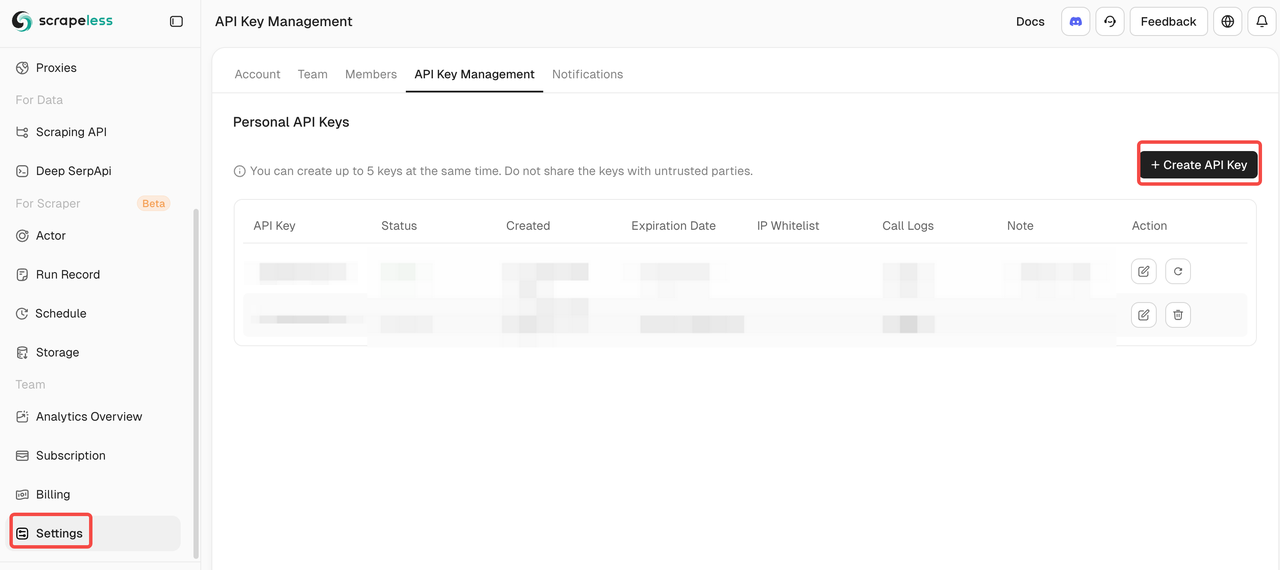
Step 1. Get Your Scrapeless API Key. Before using Scrapeless on Pipedream, make sure you already have your API key:
- Log in to Scrapeless
- Go to API Management and generate your key
Step2. Create a Pipedream Account. Sign up on Pipedream if you haven't already.
Set Your Scrapeless API Key in Pipedream
Once you're ready, head to the “Accounts” tab in Pipedream and add your Scrapeless API key:
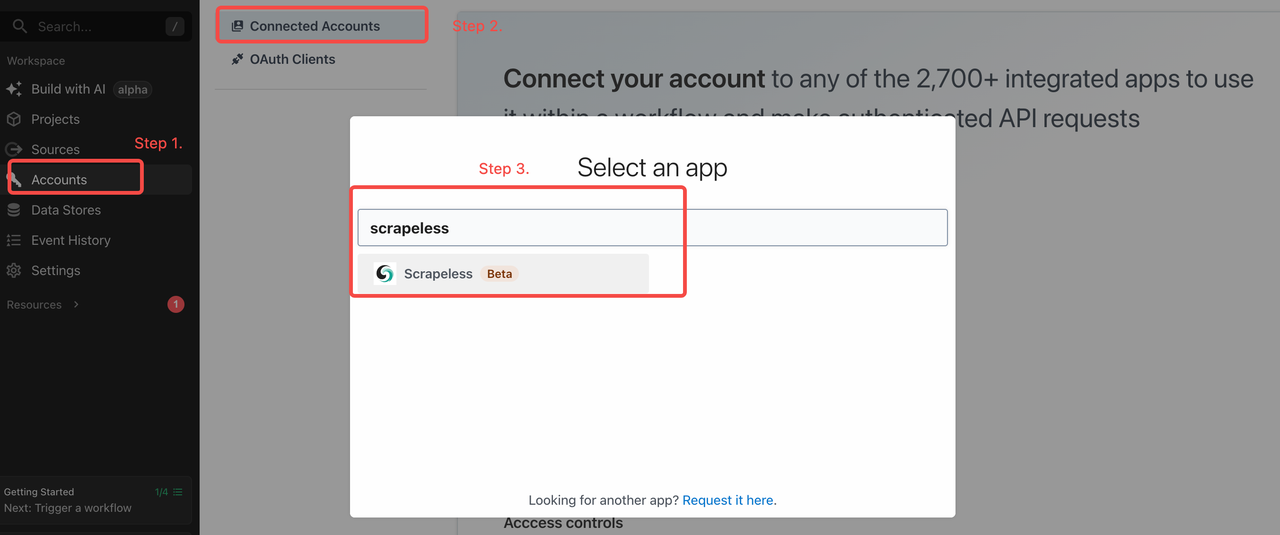
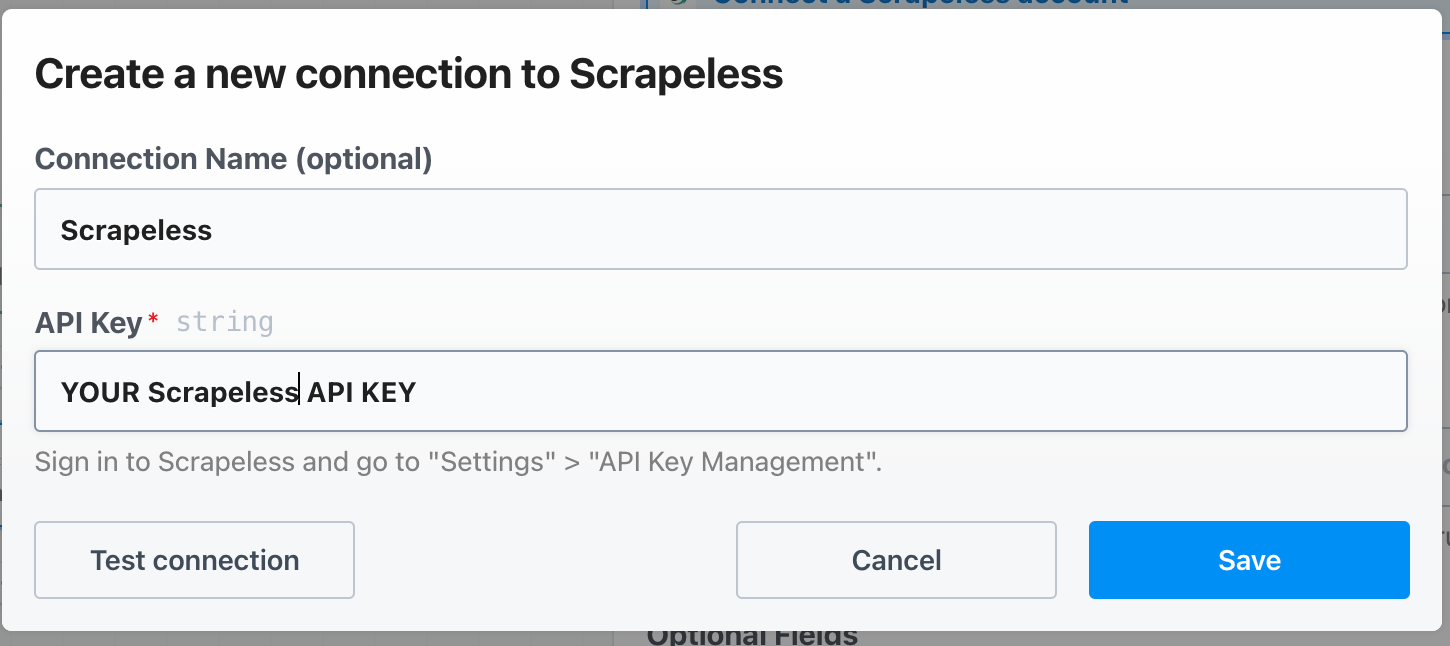
Set up the Scrapeless API key on Pipedream like this:
Scrapeless provides three powerful modules to help you build your data extraction workflows in minutes:
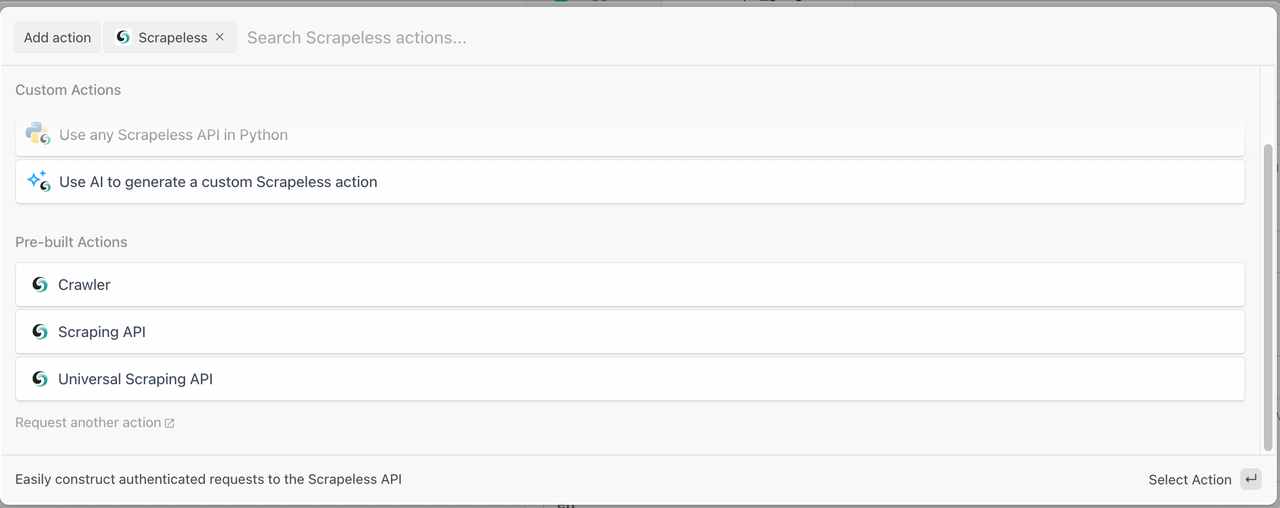
1. Crawler Module
- Crawler Crawl:Crawl the entire site, recursively access links within the page, and obtain the complete data set.
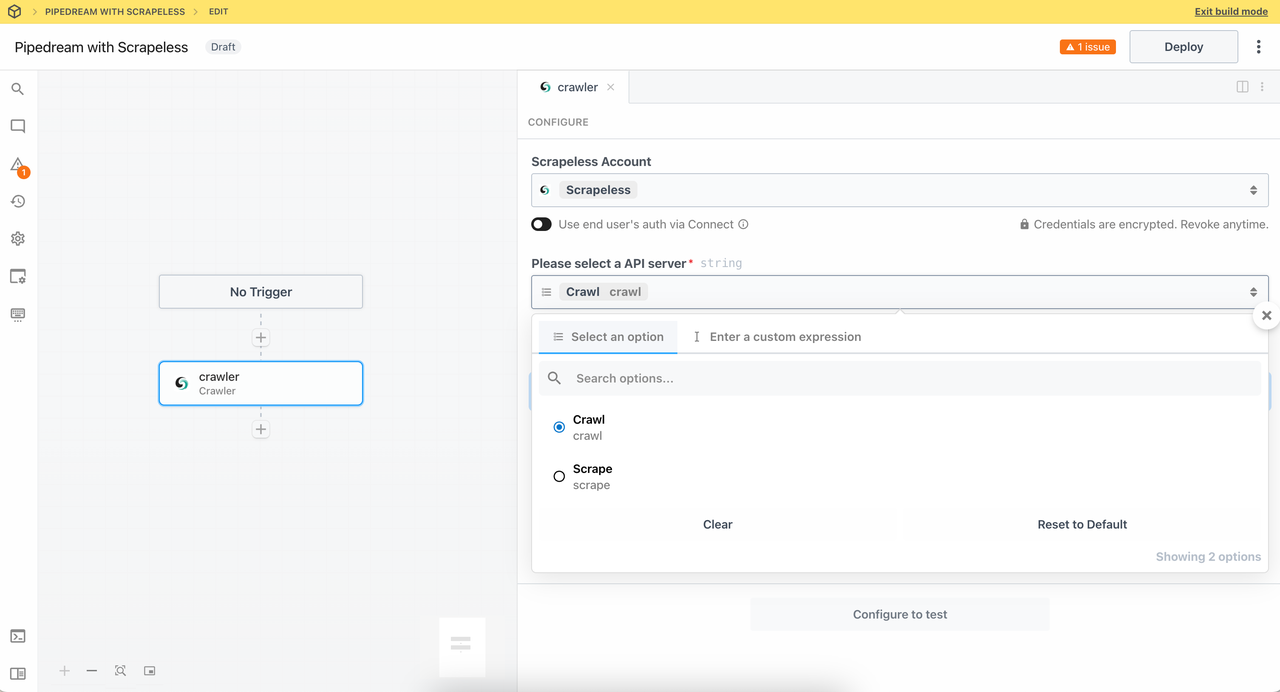
This node uses the Crawler function from Crawl. Scrapeless provides smart recursive crawling to fully capture all linked pages.
Set the subpage count to collect the amount of page data you need. Now, let's try to crawling https://www.scrapeless.com/en:
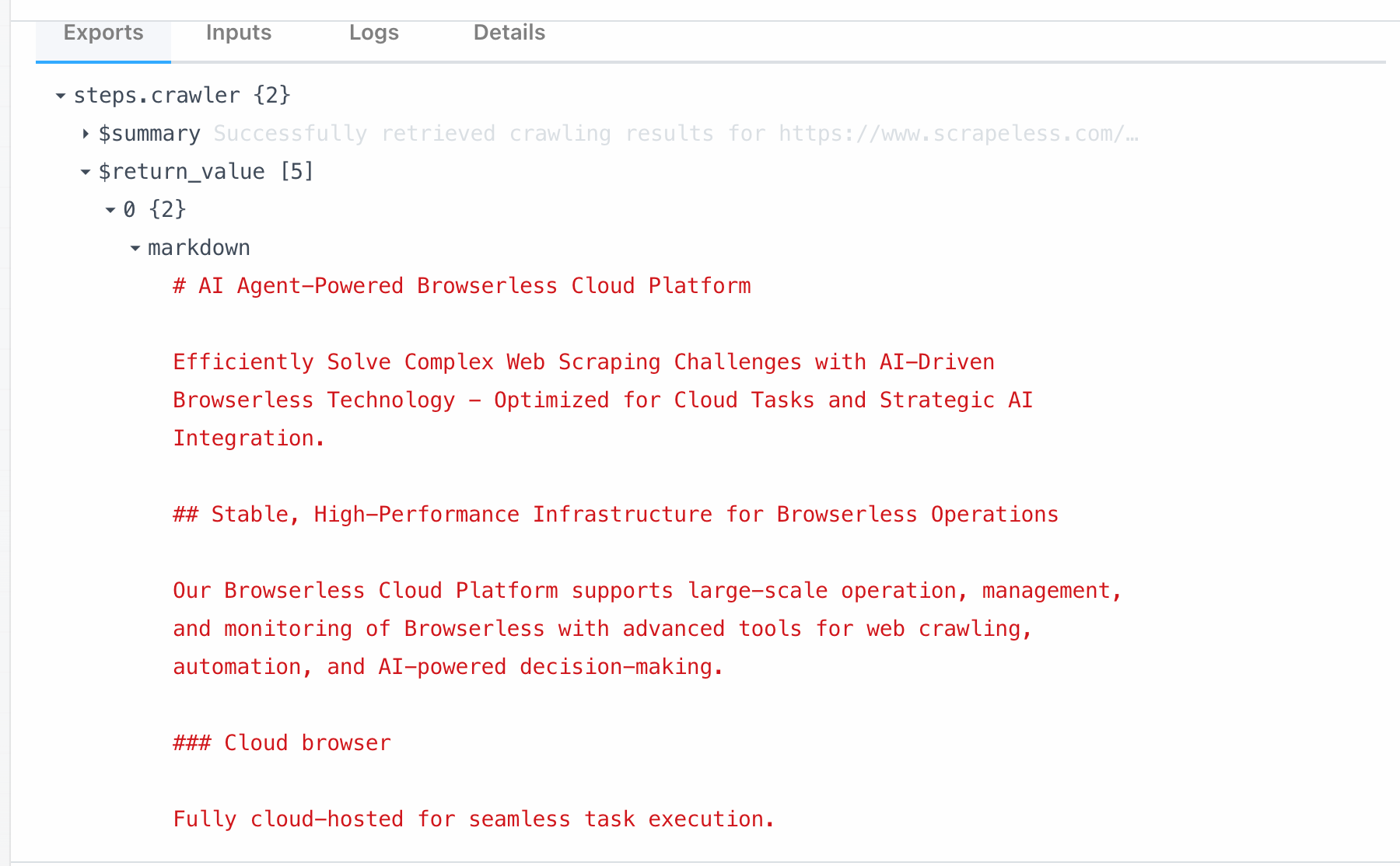
- Crawler Scrape: Used to crawl the content of a single web page and extract structured data.
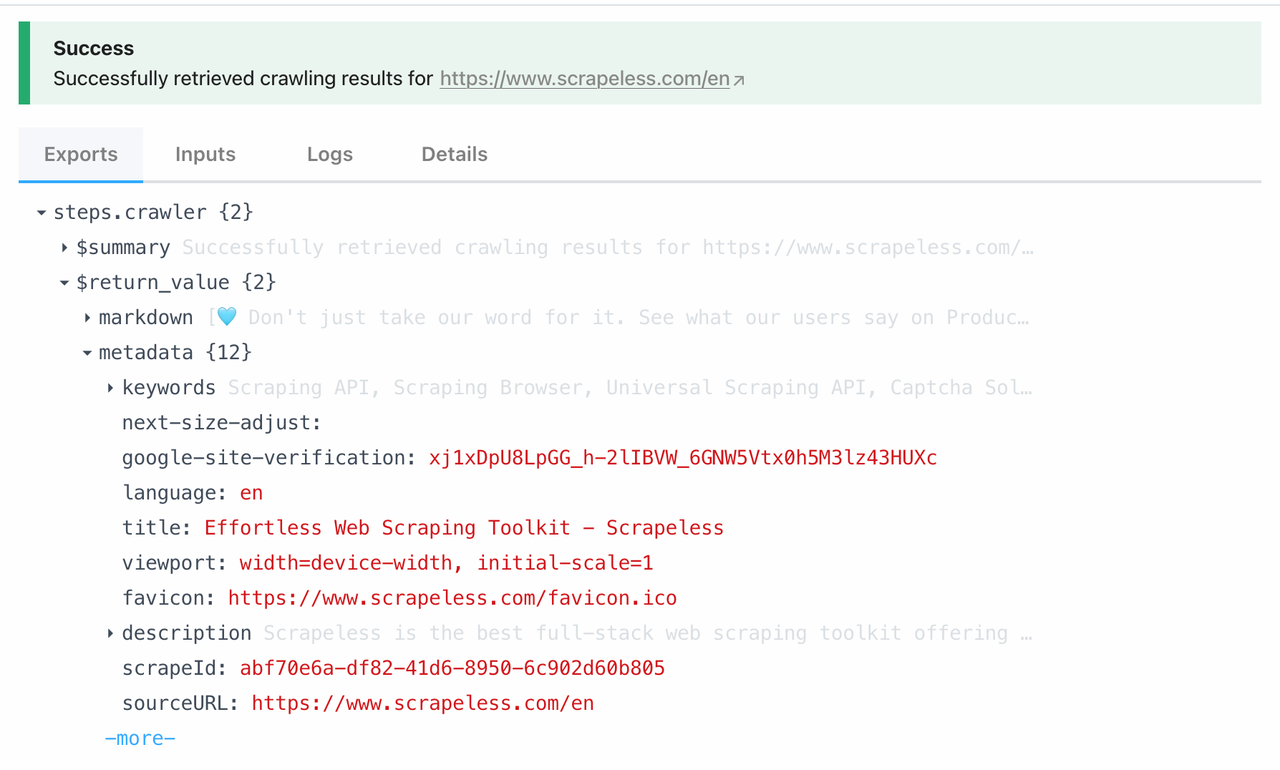
Scrape node is directly linked to the Scrape function under Scrapeless Crawl. By calling this module, you can scrape all data from a single page in one click. Here are what can we get crawling from https://www.scrapeless.com/en:
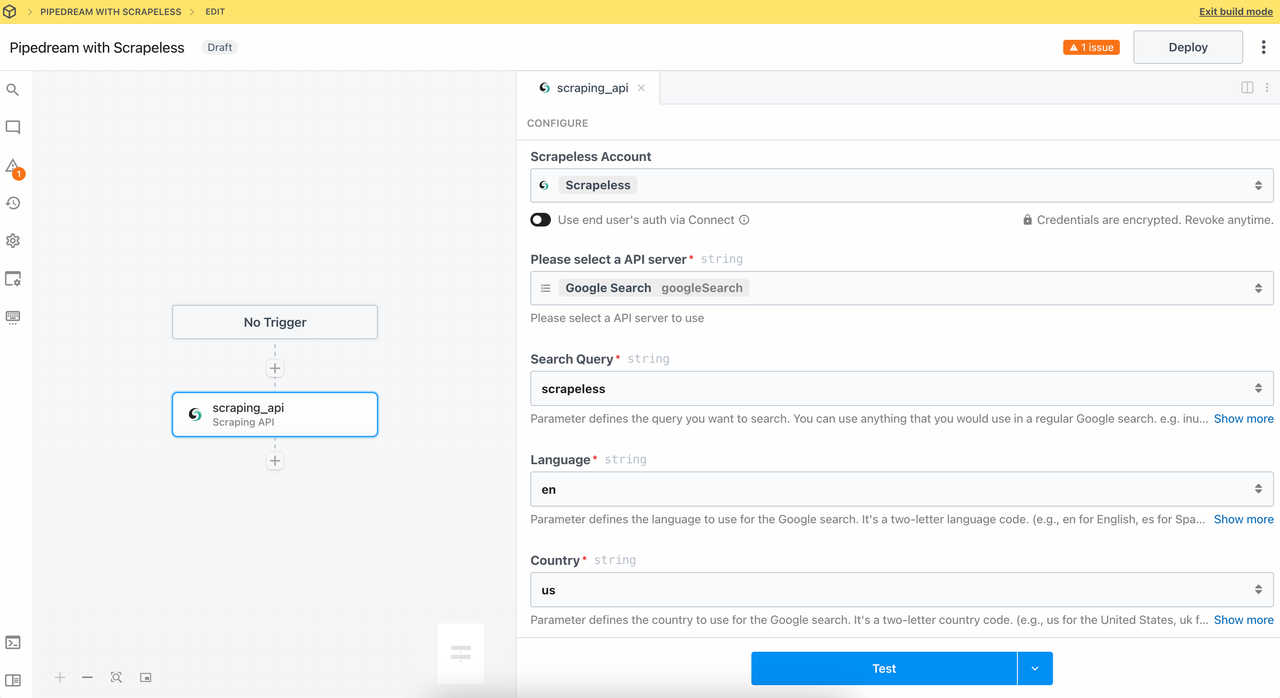
2. Scraping API Module
Calling the Scraping API module can access data sources such as Google Search and Google Trends with one click, and easily obtain search results and trend data without having to write complex requests or process responses yourself.
Let's set:
- Query:
Scrapeless - Language:
en - Country:
us
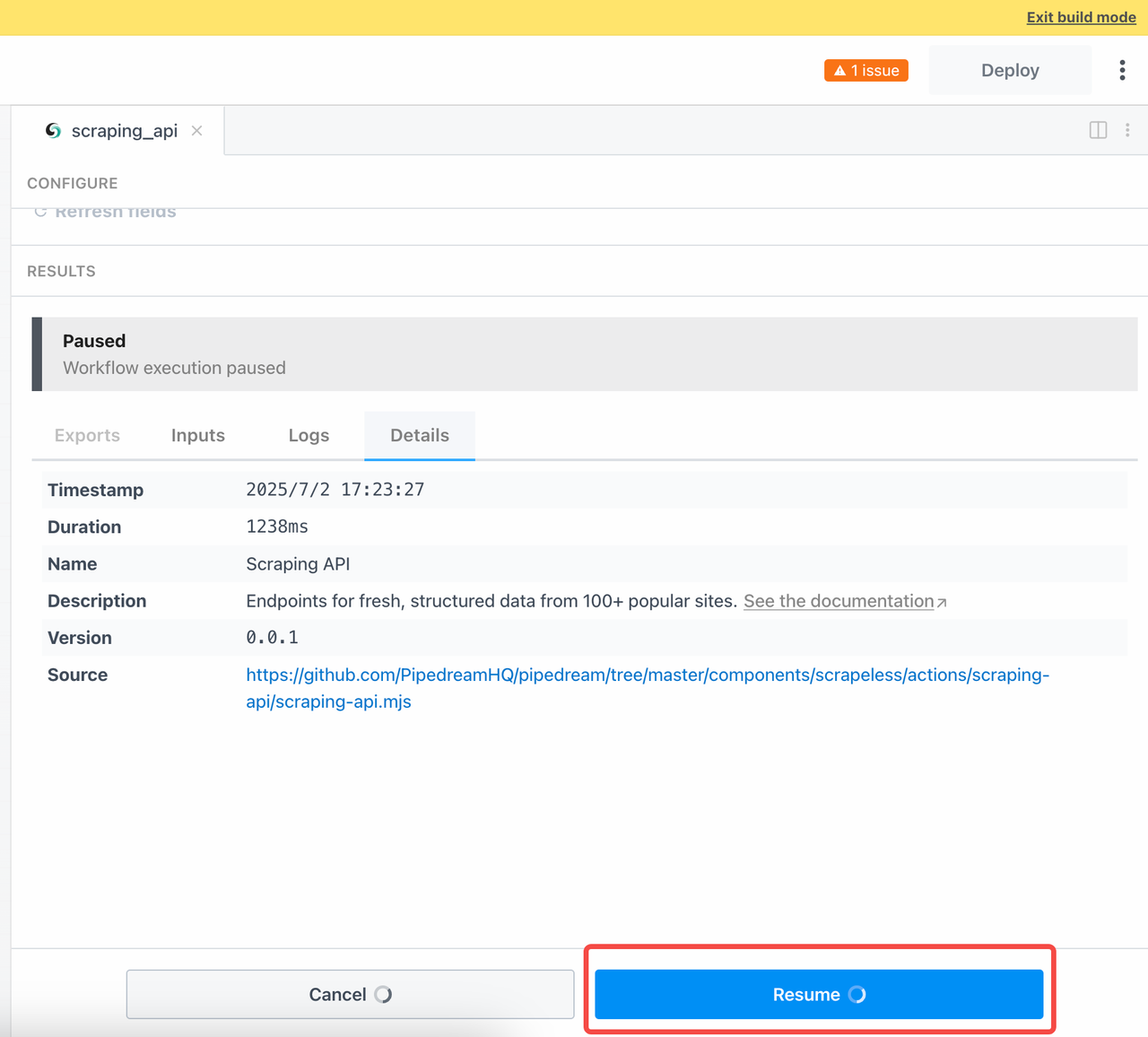
In order to wait for the results of the asynchronous task, we need to manually click Resume after submitting the query:
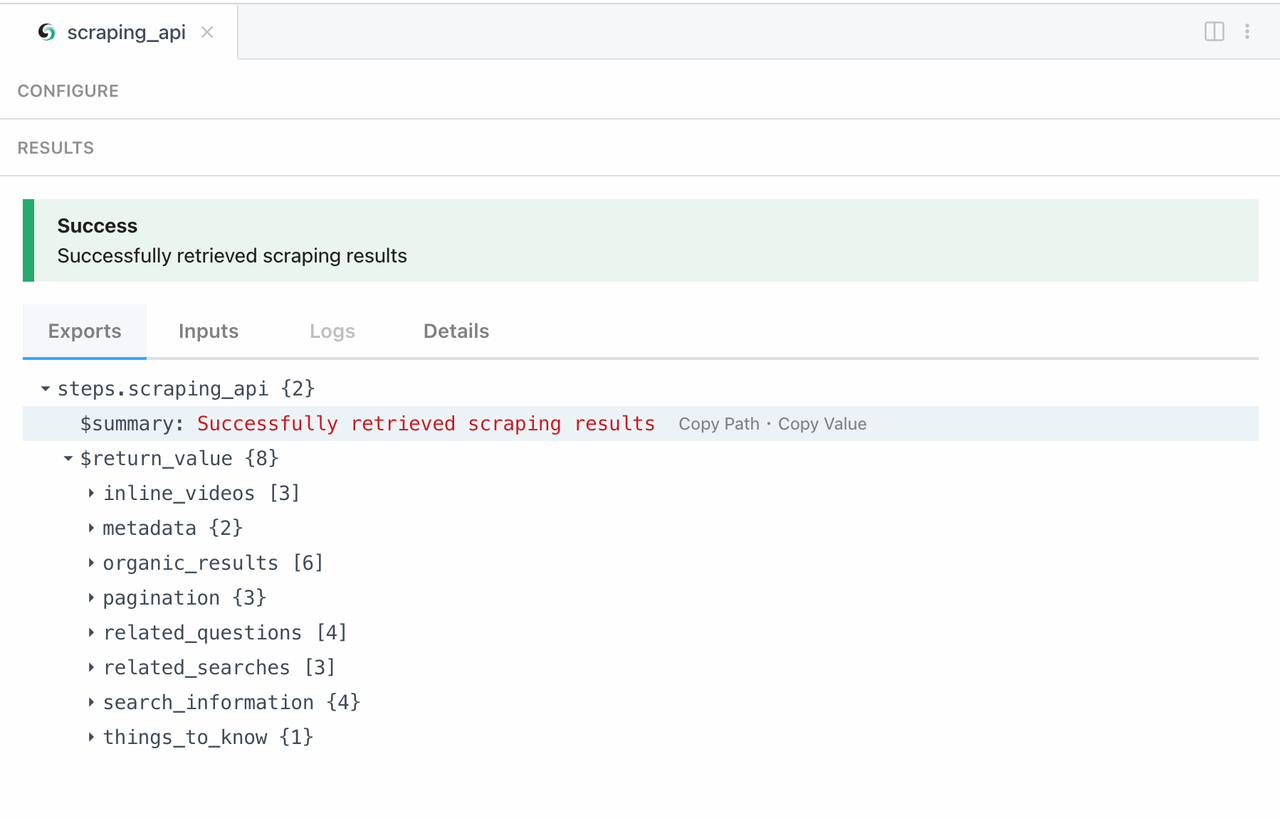
Now, let's check our scraping results:
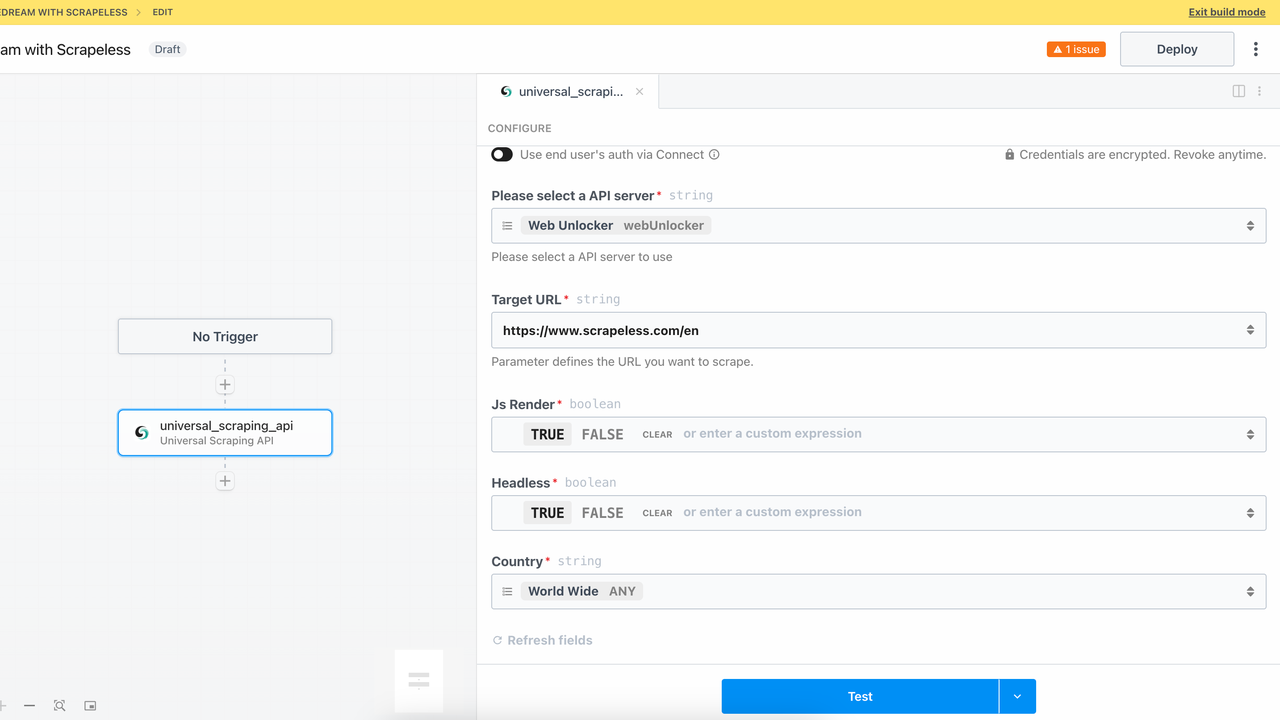
3. Universal Scraping API Module
By adding the Unlock a website module, you can successfully call Scrapeless's Universal Scraping API service. Faced with complex pages such as JavaScript rendering pages, login verification, anti-crawling mechanisms, etc., this module can automatically handle various obstacles and access pages and extract data like a browser.
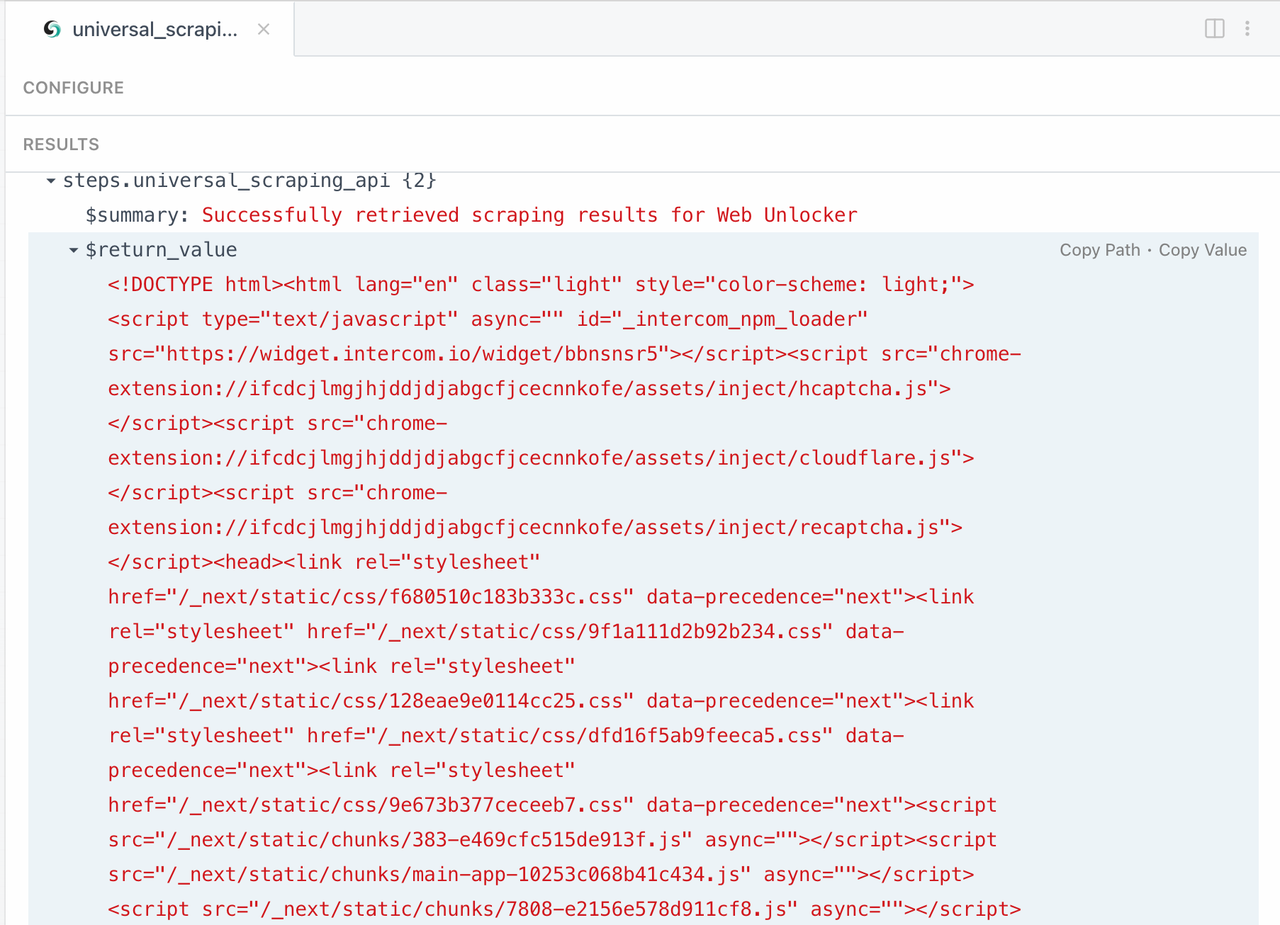
The following is the HTML result returned:
Getting Started!
Whether you want to scrape public web pages, extract search trends, or access highly protected dynamic pages, Scrapeless + Pipedream allows you to complete the most complex data automation tasks with minimal code.
🔗 Try it now -> Scrapeless on Pipedream
Further Readings
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


