
n8n and Scrapeless: Supercharge Your Website Traffic with an SEO Engine
Senior Web Scraping Engineer
If you're running an international business—whether it's cross-border e-commerce, an independent website, or a SaaS product—there’s one core challenge you simply can’t avoid: how to acquire highly targeted search engine traffic at a low cost.
With the ever-rising cost of paid advertising, content marketing has become a non-negotiable strategy for almost every product and business. So, you rally your team, crank out dozens of blog posts and “how-to” guides, all in the hopes of capturing potential customers through Google search.
But what happens next?
When your boss asks about the ROI, you’re suddenly sweating—because most of your content either targets keywords no one’s searching for or ends up buried on page 10 of Google’s results, never to be seen again.
I know that frustrating feeling all too well—pouring time and effort into content creation, only to see it flop because the topic missed the mark, the competition was too fierce, or the content simply didn’t go deep enough. The result? A painfully low return on investment and a vicious cycle of “ineffective content hustle.”
So, is there a way to break free from this cycle—something that gives you a “god mode” perspective to pinpoint high-traffic, low-competition, high-conversion topic ideas, automatically analyze competitors, and even generate quality content with minimal manual effort?
Surprisingly, yes—there is.
In this blog post, we’ll walk you through how to build a fully automated SEO content engine using n8n + Scrapeless, from the ground up. This workflow can turn a vague business niche into a well-structured SEO content pipeline, packed with actionable tasks and a clear ROI forecast. And the best part? Your database will continuously be updated with ready-to-publish articles.
Curious about what else you can automate with n8n + Scrapeless?
- Automate content ideas with Google Search + AI
- How to build an intelligent B2B lead tracker?
- How to build an AI web data pipeline on n8n?
The picture below is the automated workflow we will eventually build. It is divided into three stages: hot topic selection -> competitive product research -> SEO article writing.
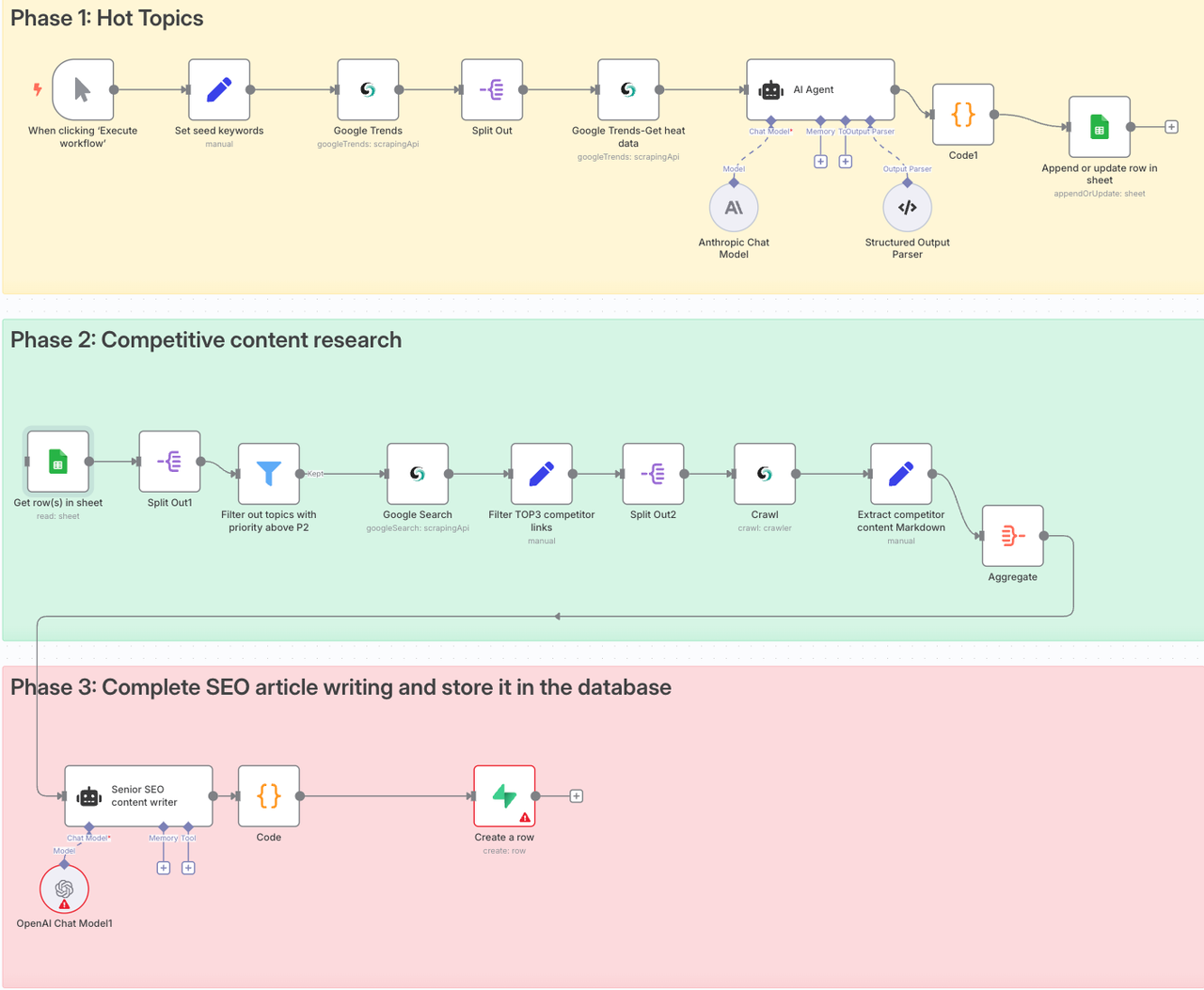
Feeling a little excited already? You should be—and we're just getting started. This system doesn't just look cool; it's built on a solid, actionable business logic that actually works in the real world.
So let’s not waste any time—let’s dive in and start building!
What Does a Good SEO Framework Look Like?
Before diving into the nitty-gritty of n8n workflows, we need to understand the core logic behind this strategy. Why is this process effective? And what pain points in traditional SEO content production does it actually solve?
Traditional SEO Content Production (a.k.a. the Manual Workshop Method)
Here’s what a typical SEO content workflow usually looks like:
- Topic Selection: The marketing team opens Google Trends, types in a core keyword (like “dropshipping” for e-commerce sellers or “project management” for SaaS companies), checks out the trendlines, and then picks a few related “Rising” keywords—mostly based on gut feeling.
- Research: They plug those keywords into Google, manually open the top 10 ranking articles one by one, read through them, and copy-paste the key points into a document.
- Writing: They then piece those insights together and rewrite everything into a blog article.
- Publishing: The article is published on the blog or company website—and then they cross their fingers, hoping Google will take notice.
What's the Biggest Problem with This Process?
Two words: inefficiency and uncertainty.
And at the heart of this inefficiency is a massive bottleneck: data collection. Sure, looking up a few terms on Google Trends is doable. But trying to analyze hundreds of long-tail keywords at scale? Practically impossible. Want to scrape the full content of top-ranking competitor pages for analysis? In 99% of cases, you’ll run into anti-bot mechanisms—CAPTCHAs or 403 Forbidden errors that shut you down instantly and waste your effort.
AI Workflow Solution
Our "SEO Content Engine" workflow was designed specifically to address this core pain point. The key idea is to delegate all the repetitive, tedious, and easily blocked tasks—like data collection and analysis—to AI and automation tools.
I've distilled it into a simple three-step framework:

Looking at this framework, it’s clear that the core capability of this system lies in reliable, large-scale data acquisition. And to make that possible, you need a tool that enables seamless data collection—without getting blocked.
That's where Scrapeless comes in.
Scrapeless is an API service purpose-built to tackle data scraping challenges. Think of it as a “super proxy” that handles all the heavy lifting—whether it’s accessing Google Trends, Google Search, or any other website. It’s designed to bypass anti-scraping mechanisms effectively and deliver clean, structured data.
In addition to working perfectly with n8n, Scrapeless also supports direct API integration, and offers ready-to-use modules on popular automation platforms like:
You can also use it directly in the official website: https://www.scrapeless.com/
Alright, theory time is over—let's move into the practical section and see exactly how this workflow is built in n8n, step by step.
Step-by-Step Tutorial: Build Your “SEO Content Engine” from Scratch
To make things easier to follow, we’ll use the example of a SaaS company offering a project management tool. But the same logic can be easily adapted to any industry or niche.
Phase 1: Topic Discovery (From Chaos to Clarity)
The goal of this phase is to take a broad seed keyword and automatically uncover a batch of long-tail keywords with high growth potential, assess their trends, and assign them a clear priority.
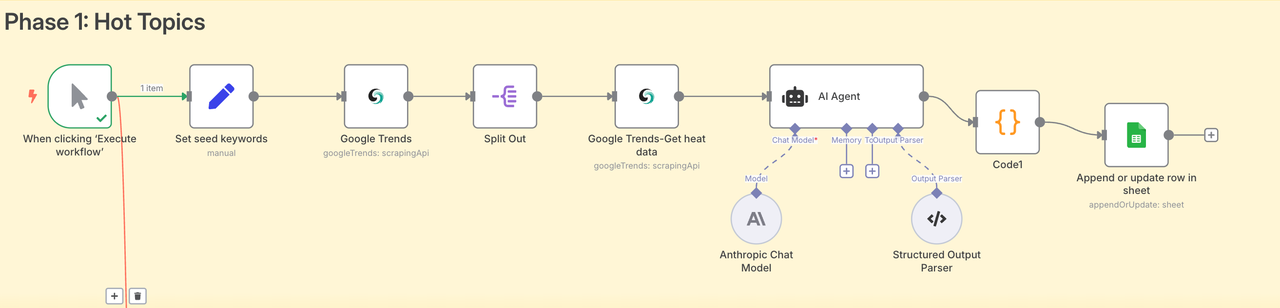
1. Node: Set Seed Keyword (Set)
- Purpose: This is the starting point of our entire workflow. Here, we define a core business keyword. For our SaaS example, that keyword is “Project Management.”
- Config: Super simple—create a variable called
seedKeywordand set its value to "Project Management".
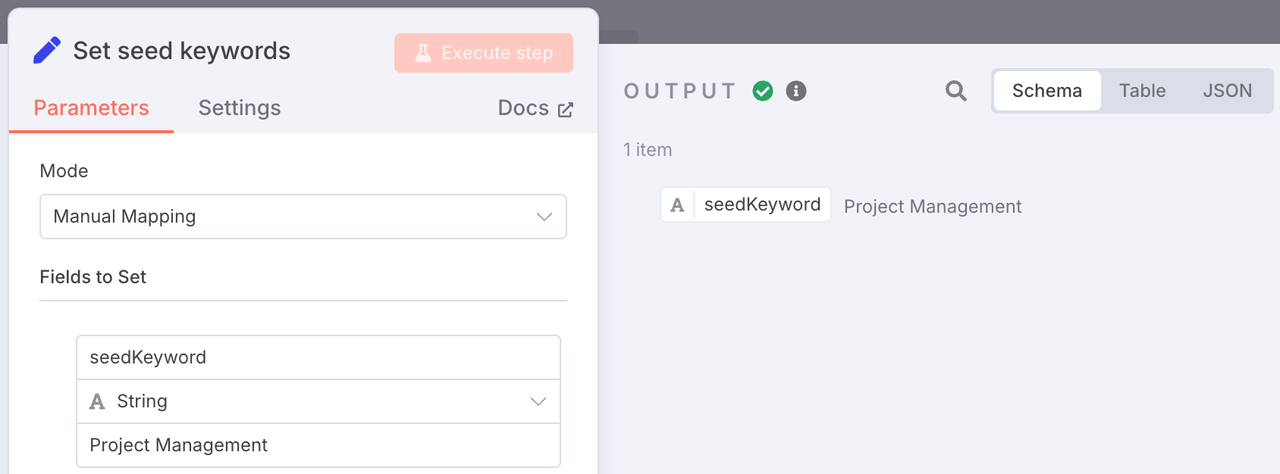
In real-world scenarios, this can also be connected to a Google Sheet or a chatbox, where users can submit keywords they want to write SEO content about.
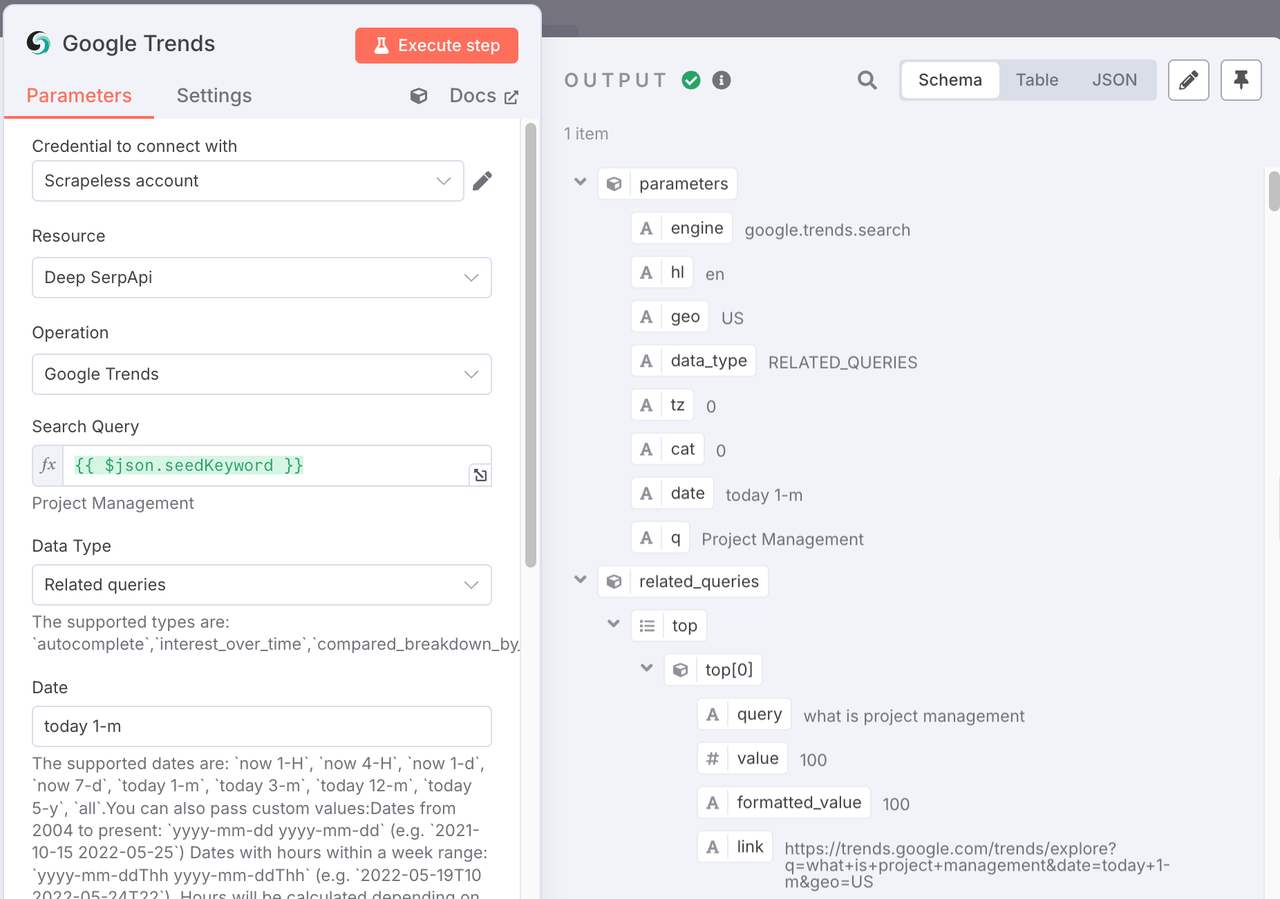
2. Node: Google Trends (Scrapeless)
This is our first major operation. We feed the seed keyword into this node to dig up all the “related queries” from Google Trends—something that’s nearly impossible to scale manually. Scrapeless has a built-in module for Google Trends.
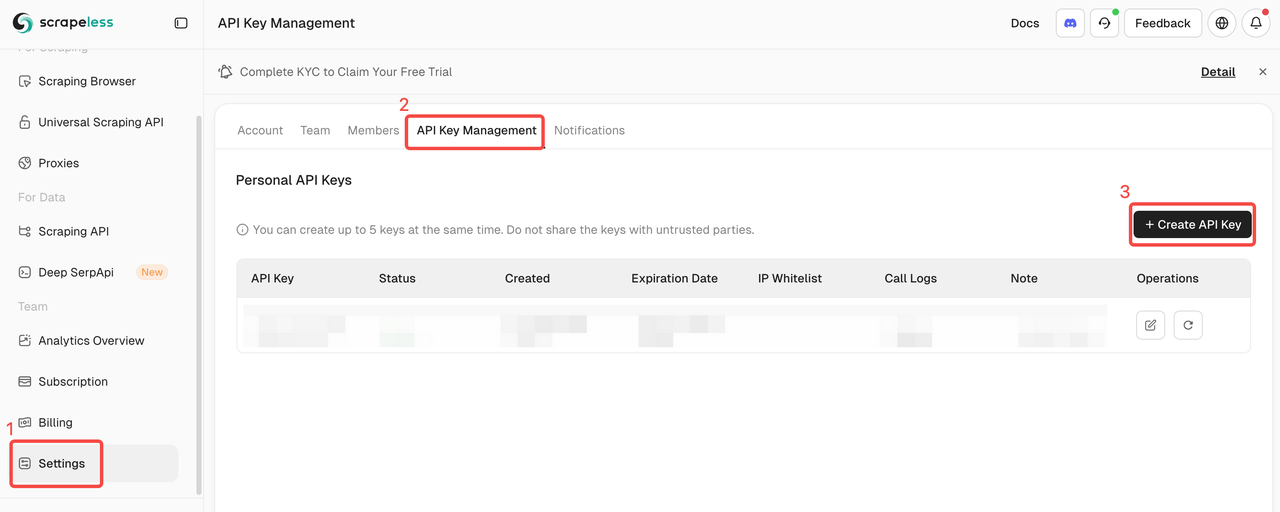
- Credentials: Sign up on the Scrapeless website to get your API key, then create a Scrapeless credential in n8n.
- Operation: Select
Google Trends. - Query (q): Enter the variable
{{ $json.seedKeyword }}. - Data Type: Choose
Related Queries. - Date: Set the timeframe, e.g.,
today 1-mfor data from the past month.
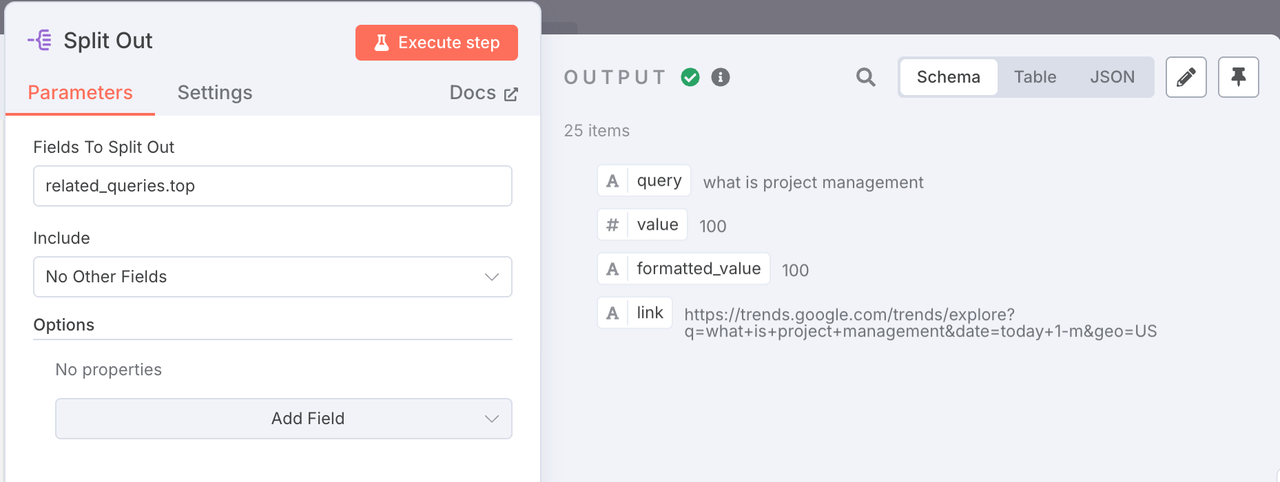
3. Node: Split Out
The previous node returns a list of related queries. This node breaks that list into individual entries so we can process them one by one.
4. Node: Google Trends(Scrapeless)
Purpose: For each related query, we again call Google Trends—this time to get Interest Over Time data (trendline).
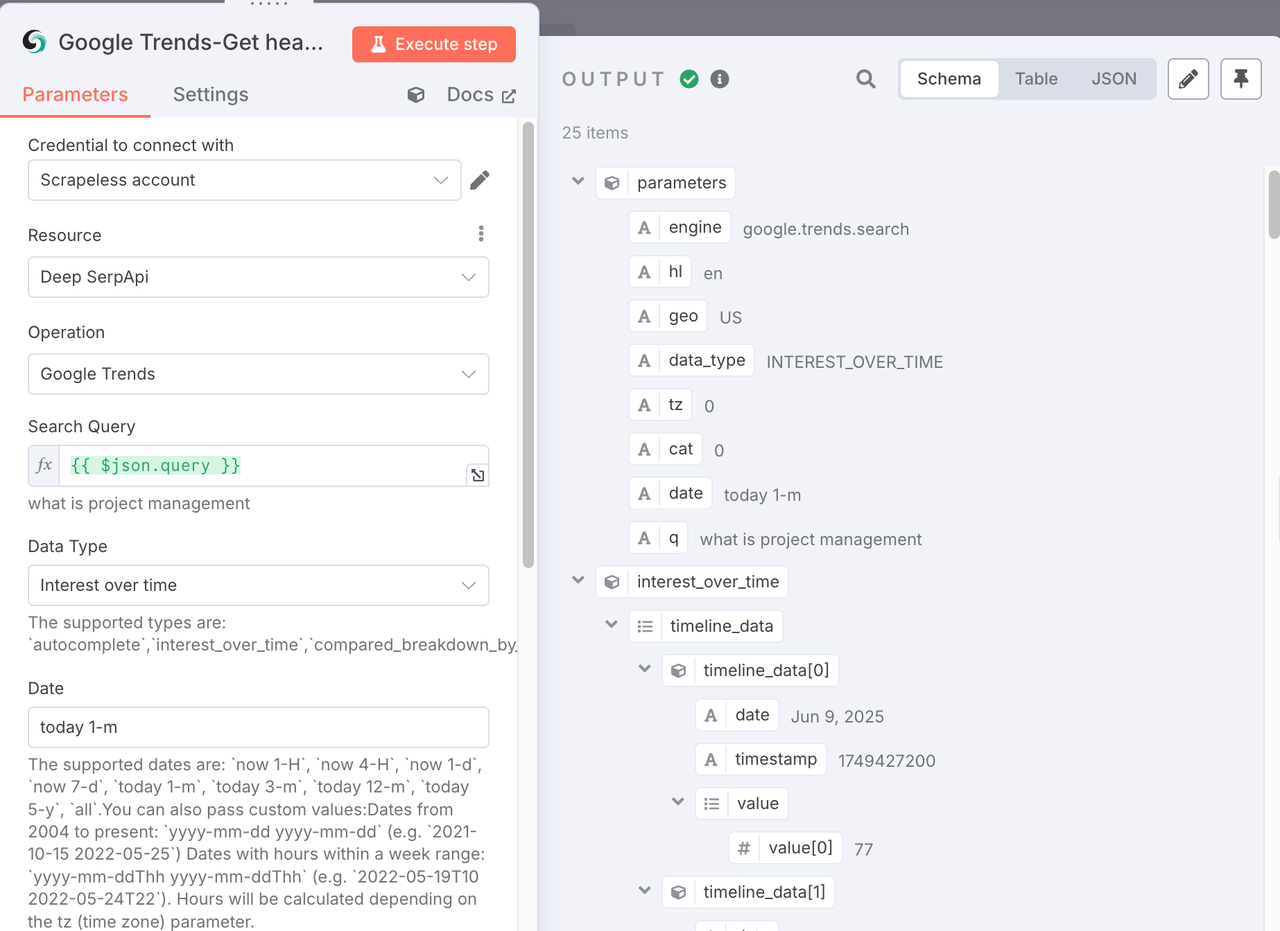
Config:
- Operation: Still
Google Trends. - Query (
q): Use{{ $json.query }}from the Split Out node. - Data Type: Leave empty to get
Interest Over Timeby default.
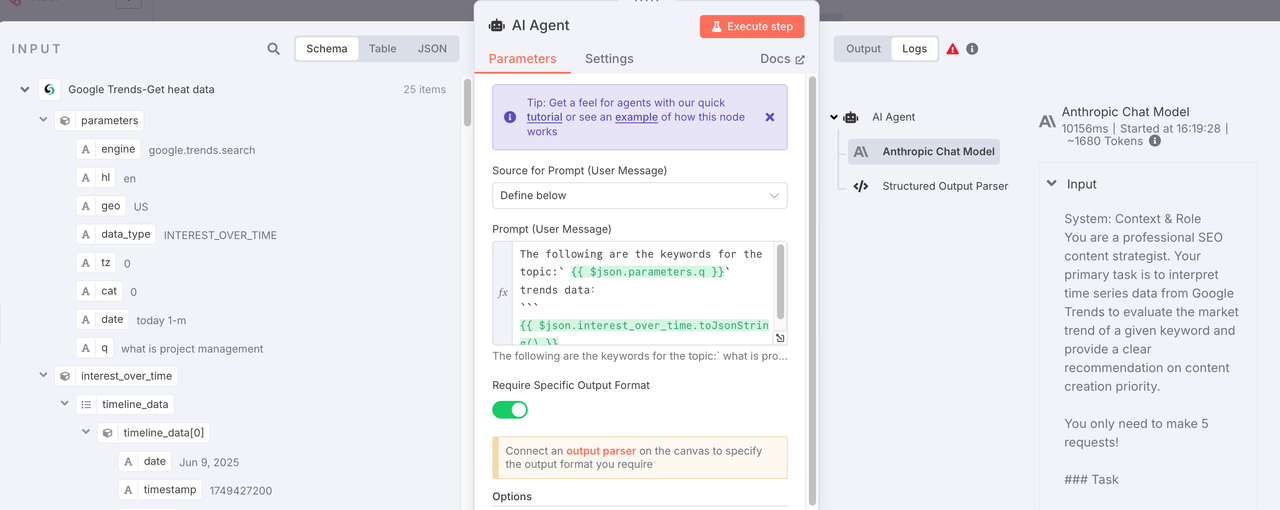
5. Node: AI Agent (LangChain)
- Purpose: The AI acts as an SEO content strategist, analyzing the trend data and assigning a priority (P0–P3) based on predefined rules.
- Config: The heart of this step is the Prompt. In the System Message of this node, we embed a detailed rule set. The AI compares the average heat of the first half vs. second half of the trendline to determine whether the trend is “Breakout,” “Rising,” “Stable,” or “Falling,” and maps that to a corresponding priority.
- Prompt:
Context & Role
You are a professional SEO content strategist. Your primary task is to interpret time series data from Google Trends to evaluate the market trend of a given keyword and provide a clear recommendation on content creation priority.
### Task
Based on the user-provided input data (a JSON object containing Google Trends timeline_data), analyze the popularity trend and return a JSON object with three fields—data_interpretation, trend_status, and recommended_priority—strictly following the specified output format.
### Rules
You must follow the rules below to determine trend_status and recommended_priority:
1. Analyze the timeline_data array:
• Split the time-series data roughly into two halves.
•Compare the average popularity value of the second half with that of the first half.
2. Determine trend_status — You must choose one of the following:
• Breakout: If the data shows a dramatic spike at the latest time point that is significantly higher than the average level.
• Rising: If the average popularity in the second half is significantly higher than in the first half (e.g., more than 20% higher).
• Stable: If the averages of both halves are close, or if the data exhibits a regular cyclical pattern without a clear long-term upward or downward trend.
• Falling: If the average popularity in the second half is significantly lower than in the first half.
3. Determine recommended_priority — You must map this directly from the trend_status:
• If trend_status is Breakout, then recommended_priority is P0 - Immediate Action.
• If trend_status is Rising, then recommended_priority is P1 - High Priority.
• If trend_status is Stable, then recommended_priority is P2 - Moderate Priority.
• If trend_status is Falling, then recommended_priority is P3 - Low Priority.
4. Write data_interpretation:
• Use 1–2 short sentences in English to summarize your observation of the trend. For example: “This keyword shows a clear weekly cycle with dips on weekends and rises on weekdays, but overall the trend remains stable.” or “The keyword’s popularity has been rising steadily over the past month, indicating strong growth potential.”
### Output Format
You must strictly follow the JSON structure below. Do not add any extra explanation or text.
{
"data_interpretation": "Your brief summary of the trend",
"trend_status": "One of ['Breakout', 'Rising', 'Stable', 'Falling']",
"recommended_priority": "One of ['P0 - Immediate Action', 'P1 - High Priority', 'P2 - Moderate Priority', 'P3 - Low Priority']"
}Make sure to use Structured Output Parser to ensure the result can be passed on to the next step.
6. Node: Code
We need to add a new code to classify and limit the results exported by AI Agent. You can refer to our code to ensure that the long-tail keywords crawled are arranged in the order of P0, P1, P2, P3 on Google Sheets.
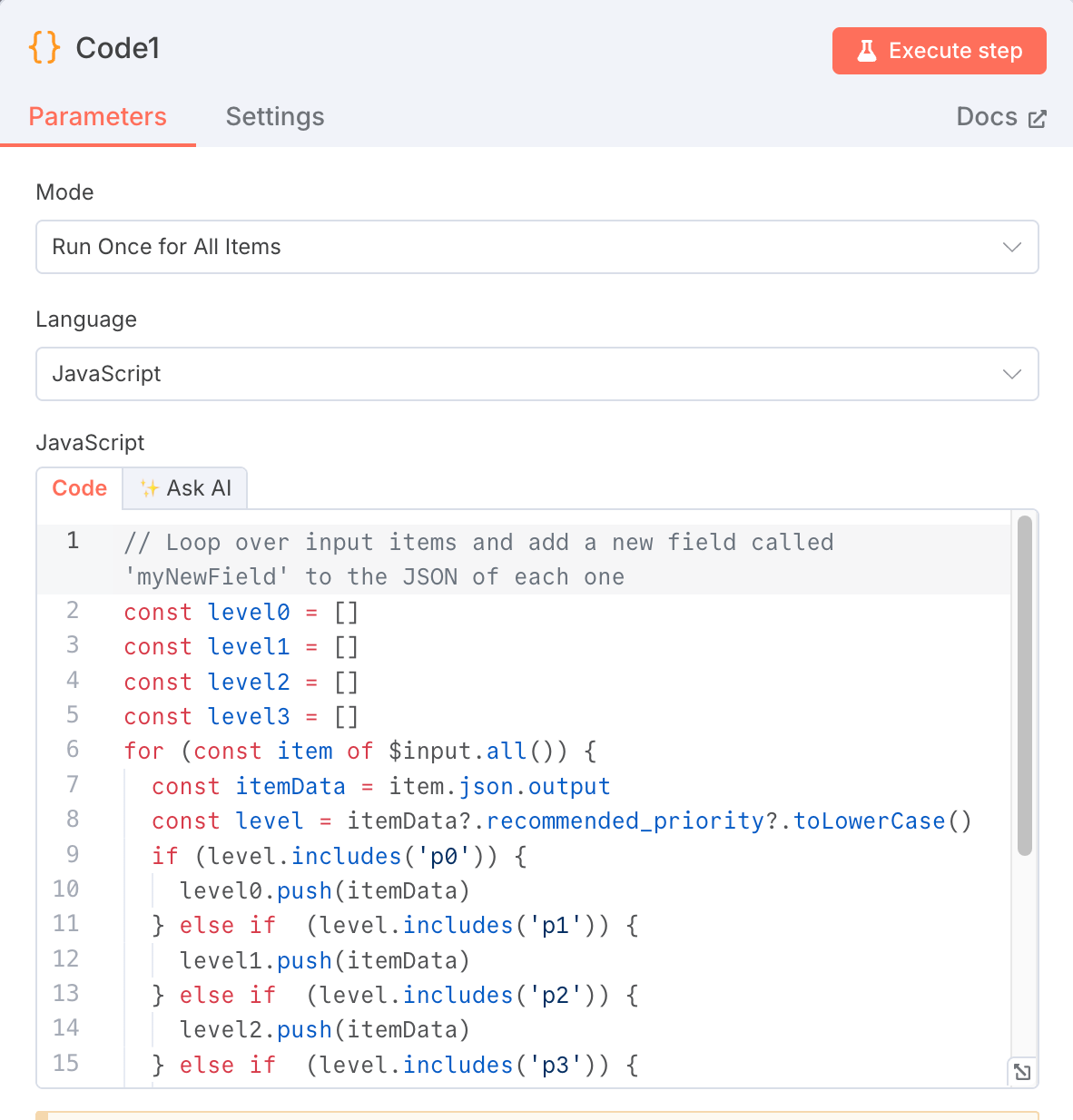
// Loop over input items and add a new field called 'myNewField' to the JSON of each one
const level0 = []
const level1 = []
const level2 = []
const level3 = []
for (const item of $input.all()) {
const itemData = item.json.output
const level = itemData?.recommended_priority?.toLowerCase()
if (level.includes('p0')) {
level0.push(itemData)
} else if (level.includes('p1')) {
level1.push(itemData)
} else if (level.includes('p2')) {
level2.push(itemData)
} else if (level.includes('p3')) {
level3.push(itemData)
}
}
return [
...level0,
...level1,
...level2,
...level3
]7. Google Sheets
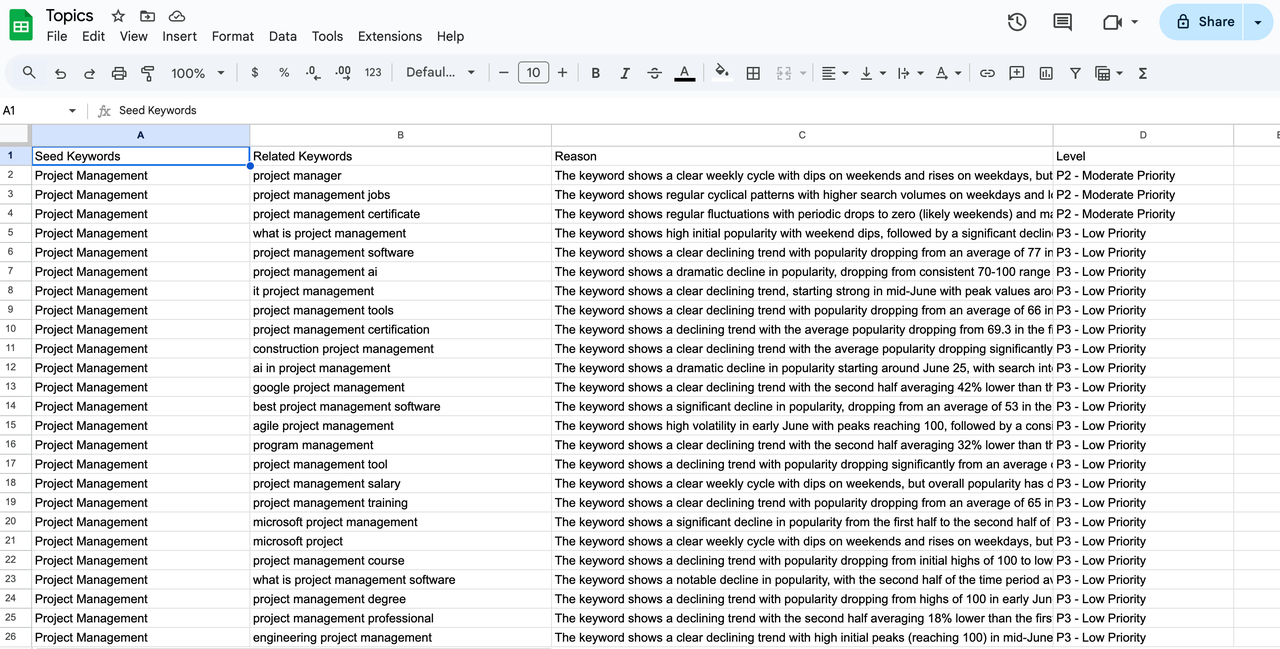
- Purpose: Store the results of AI analysis, including data interpretation, trend status and recommended priority, together with the topic itself, into Google Sheets. In this way, we get a dynamically updated, prioritized "topic library".
Phase 2: Competitor Content Research (Know Your Enemy to Win Every Battle)
The goal of this phase is to automatically filter out high-priority topics identified in Phase 1, and perform a deep “tear-down” analysis of the top 3 Google-ranked competitors for each topic.
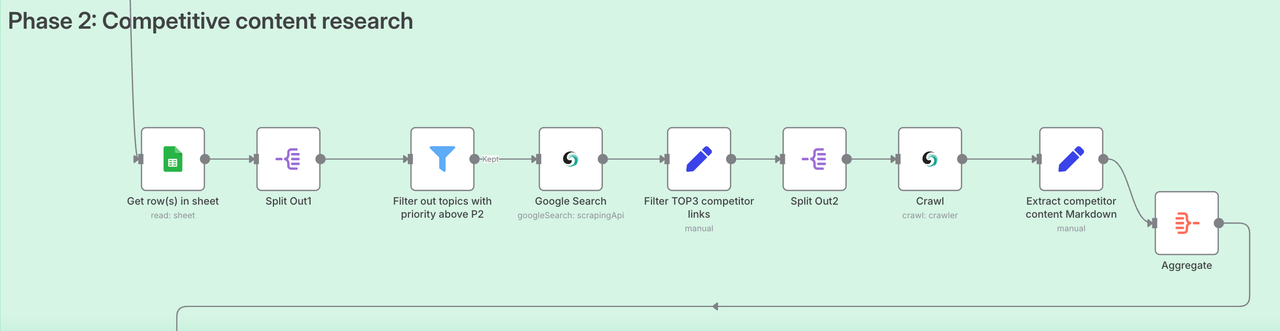
1. Filter out topics worth writing
There are two forms here.
- According to the following three nodes, use the
Filterto split out all topics whose recommended priority is not "P3 - not considered yet" from the "Topic Library" of Google Sheets. - Directly write the filter conditions into the node where Google Sheets extracts records.
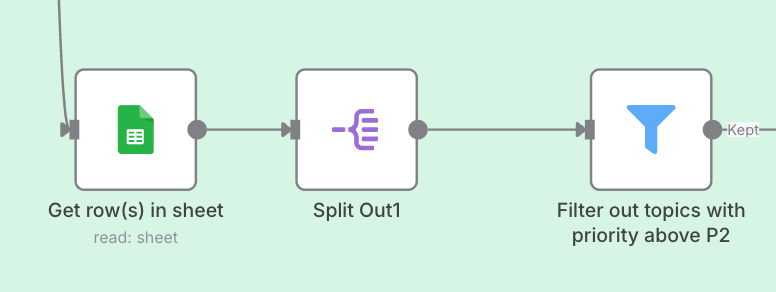
In fact, I am doing this for the convenience of testing. You can just add a Filter from the previous stage.
2. Node: Google search (Deep SerpApi)
- Purpose: With the high-value topics filtered out, this node sends them to Google Search to fetch the top-ranking competitor URLs
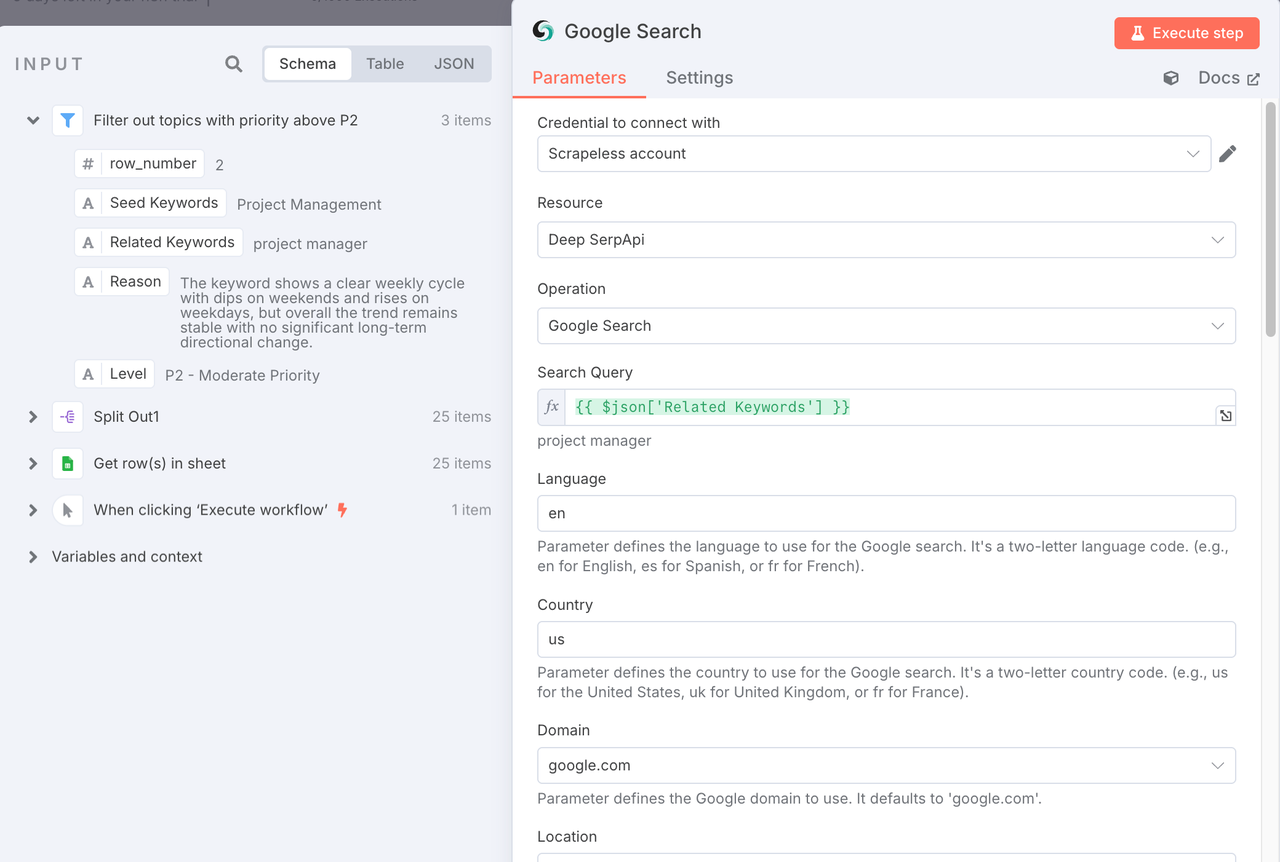
To explain, normally we want to call Google's search interface, which will be troublesome and there will be network problems. Therefore, there are many packaged interfaces on the market to make it easier for users to obtain Google search results. Deep SerpApi is one of them.
3. Node: Edit Fields & Split Out2
- Purpose: Process the search results. We typically only care about the top 3 organic search results, so here we filter out everything else and split the 3 competitor results into individual entries for further handling.
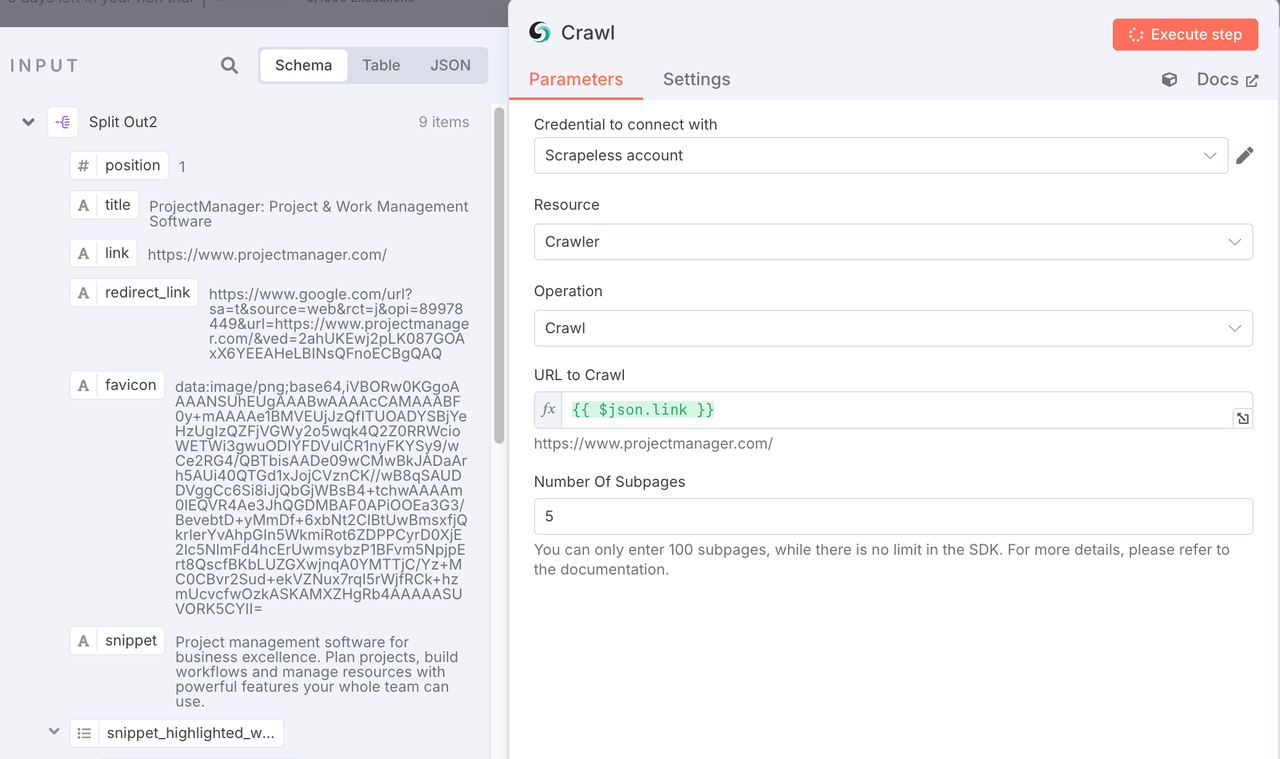
4. Node: Crawl (Scrapeless)
Purpose: This is one of the most valuable parts of the entire workflow!
We feed the competitor URLs into this node, and it automatically fetches the entire article content from the page, returning it to us in clean Markdown format.
Now, of course, you could write your own crawler for this step—but you’d need patience. Every website has a different structure, and you’ll most likely hit anti-bot mechanisms.
Scrapeless' Crawl solves this: you give it a URL, and it delivers back clean, structured core content.
Behind the scenes, it uses a custom infrastructure powered by dynamic IP rotation, full JS rendering, and automatic CAPTCHA solving (including reCAPTCHA, Cloudflare, hCaptcha, etc.), achieving "invisible scraping" for 99.5% of websites. You can also configure page depth and content filters.
In the future, this feature will integrate large language models (LLMs) to provide contextual understanding, in-page actions, and structured output of crawled content.
Configuration:
- Operation: Select
Crawl。 - URL: Input the competitor URL from the previous step using
{{ $json.link }}.
5. Node: Aggregate
- Purpose: Merge the full Markdown content of all 3 competitors into a single data object. This prepares it for the final step—feeding it to the AI for content generation.
Phase 3: Completing the SEO Article Draft
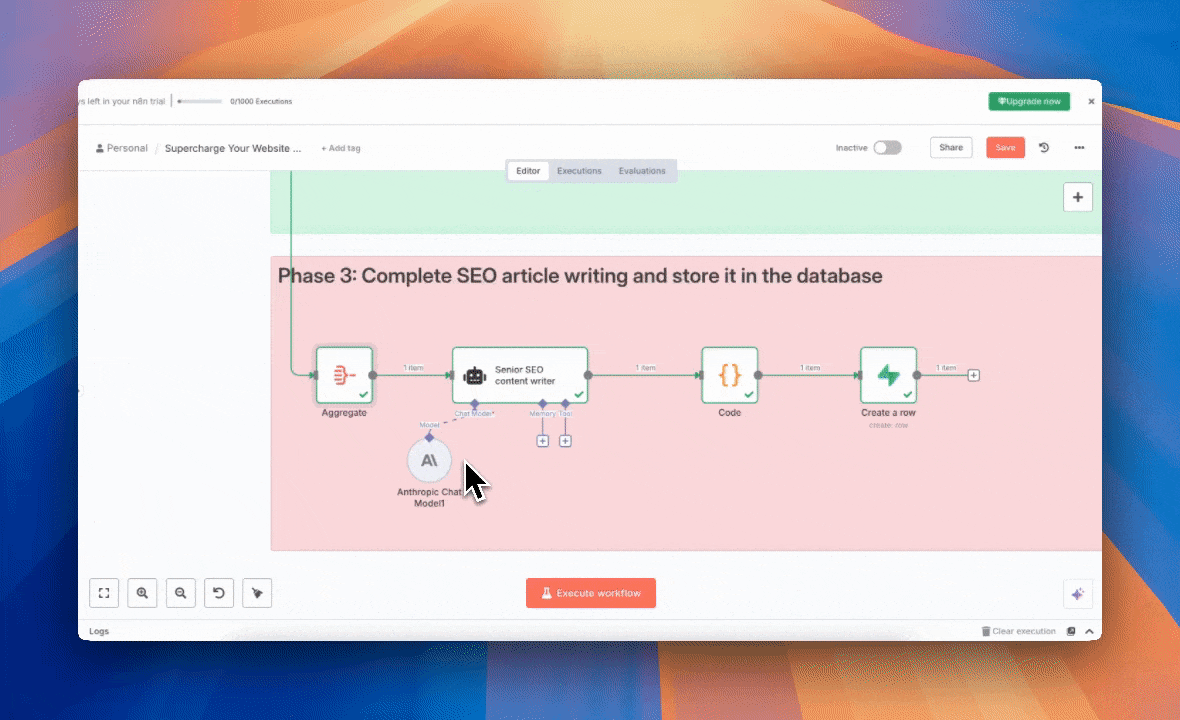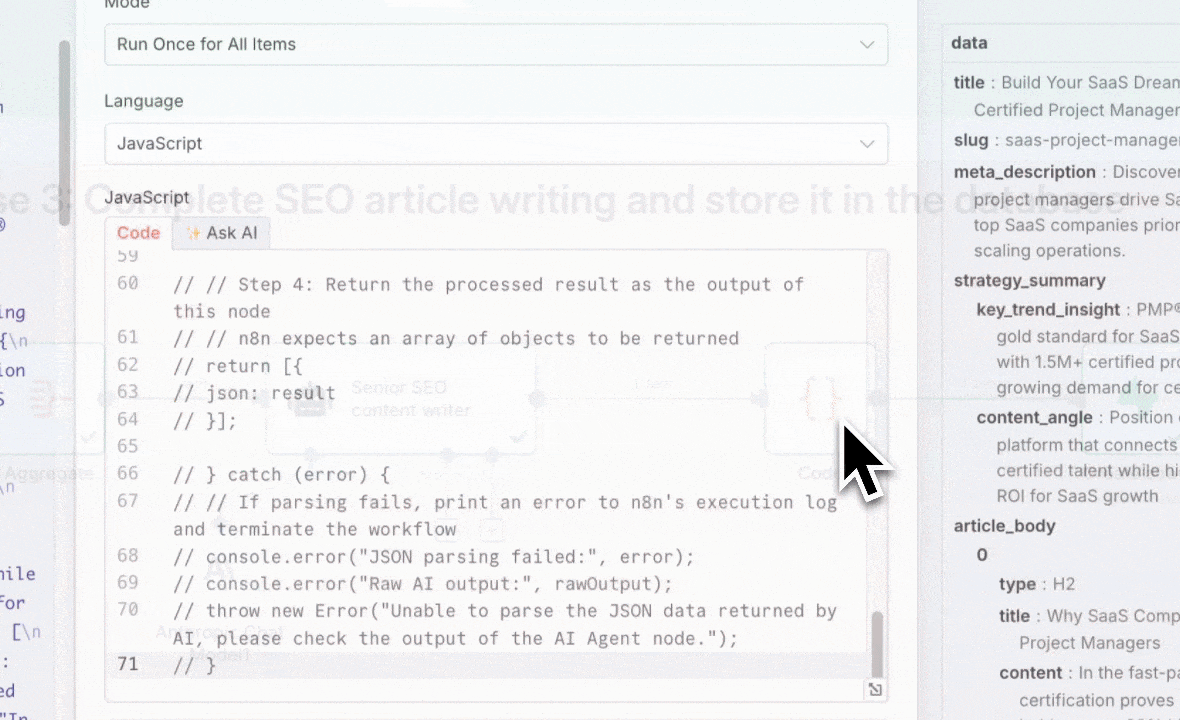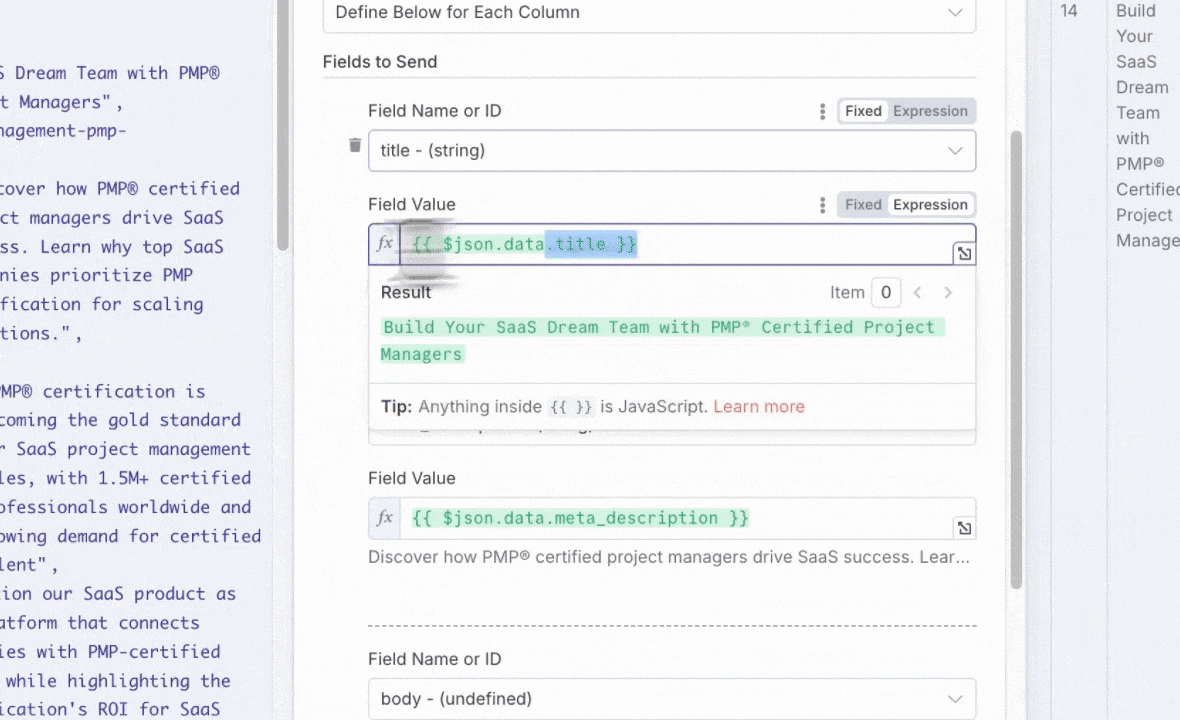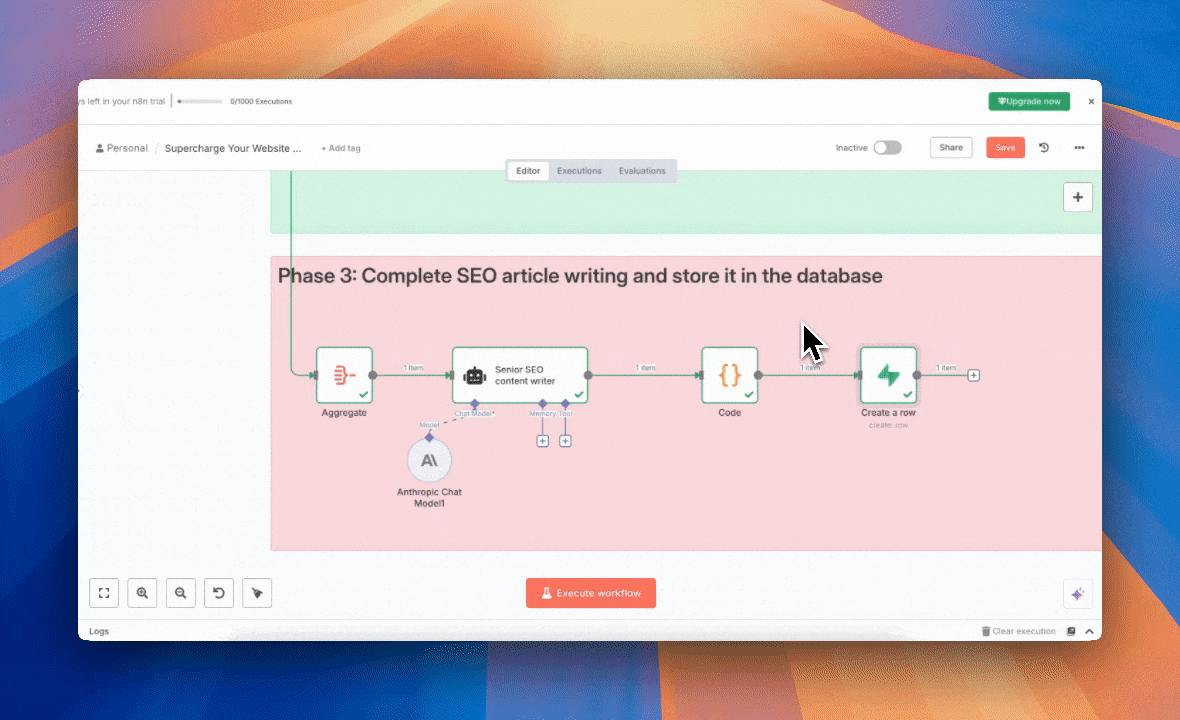
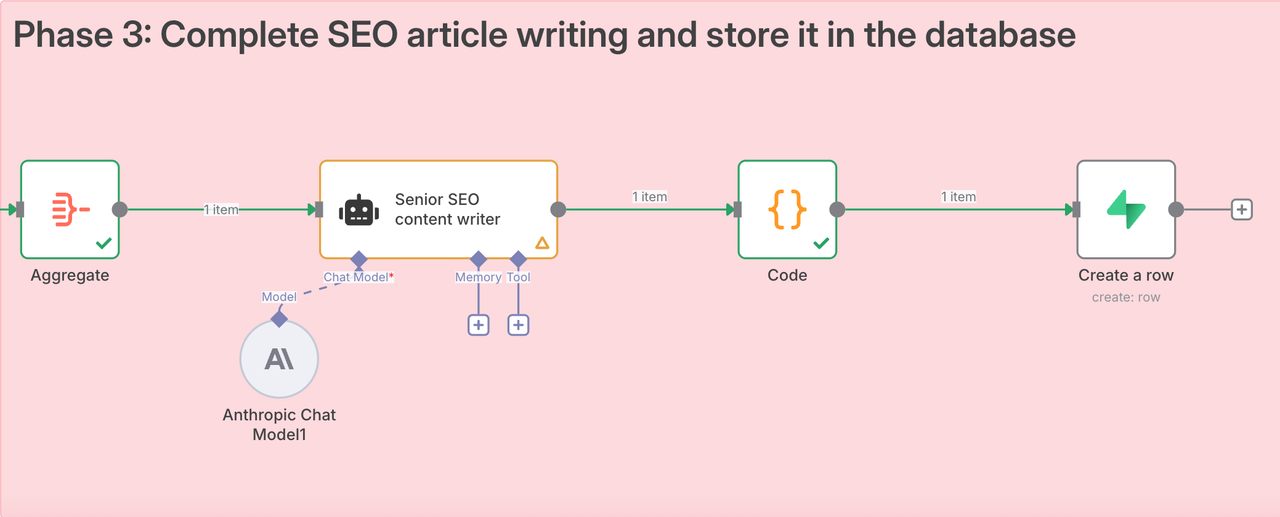
1. Node: AI Agent
This is our “AI writer.” It receives a comprehensive SEO brief that includes all the context gathered from the previous two phases:
- The target keyword for the article
- The name of our product (in this case, a SaaS tool)
- The latest trend analysis related to the keyword
- Full content from the top 3 competitor articles on Google
Prompt:
# Role & Objective
You are a senior SEO content writer at a SaaS company focused on “project management software.” Your core task is to write a complete, high-quality, and publish-ready SEO-optimized article based on the provided context.
# Context & Data
- Target Keyword: {{ $json.markdown }}
- Your SaaS Product Name: SaaS Product
- Latest Trend Insight: "{{ $json.markdown }}"
- Competitor 1 (Top-ranked full content):
"""
{{ $json.markdown[0] }}
"""
- Competitor 2 (Top-ranked full content):
"""
{{ $json.markdown[1] }}
"""
- Competitor 3 (Top-ranked full content):
"""
{{ $json.markdown[2] }}
"""
# Your Task
Please use all the above information to write a complete article. You must:
1. Analyze the competitors’ content deeply, learn from their strengths, and identify opportunities for differentiation.
2. Integrate the trend insight naturally into the article to enhance its relevance and timeliness.
3. Write the full content directly—do not give bullet points or outlines. Output full paragraphs only.
4. Follow the exact structure below and output a well-formed JSON object with no additional explanation or extra text.
Use the following strict JSON output format:
{
"title": "An eye-catching SEO title including the target keyword",
"slug": "a-keyword-rich-and-user-friendly-url-slug",
"meta_description": "A ~150 character meta description that includes the keyword and a call to action.",
"strategy_summary": {
"key_trend_insight": "Summarize the key trend insight used in the article.",
"content_angle": "Explain the unique content angle this article takes."
},
"article_body": [
{
"type": "H2",
"title": "This is the first H2 heading of the article",
"content": "A rich, fluent, and informative paragraph related to this H2. Each paragraph should be 150–200 words and offer valuable insights beyond surface-level content."
},
{
"type": "H2",
"title": "This is the second H2 heading",
"content": "Deep dive into this sub-topic. Use data, examples, and practical analysis to ensure content depth and value."
},
{
"type": "H3",
"title": "This is an H3 heading that refines the H2 topic above",
"content": "Provide detailed elaboration under this H3, maintaining relevance to the H2."
},
{
"type": "H2",
"title": "This third H2 could focus on how your product solves the problem",
"content": "Explain how [Your SaaS Product] helps users address the issue discussed above. This section should be persuasive and naturally lead the reader to take action."
}
]
}The beauty of this prompt lies in how it requires both strategic content adaptation from competitors and trend integration, resulting in a cleanly structured JSON output ready for publishing.
2. Node: Code
This step converts the AI-generated output into JSON that is compatible with n8n.
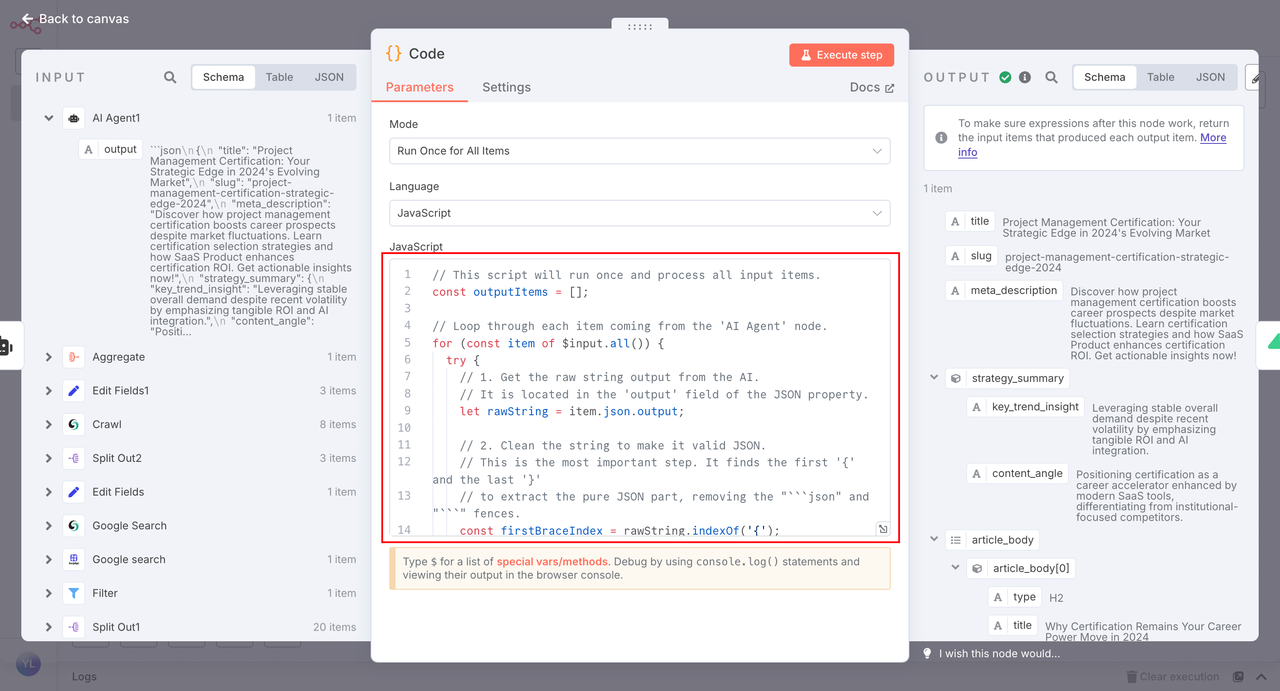
If your output structure is different, no worries—just adjust the AI prompt to match the expected format.
3. Node: Create a row (Supabase)
Finally, the structured JSON is parsed and inserted into a Supabase database (or another DB like MySQL, PostgreSQL, etc.).
Here’s the SQL you can use to create the seo_articles table:
-- Create a table called seo_articles to store AI-generated SEO articles
CREATE TABLE public.seo_articles (
id BIGINT PRIMARY KEY GENERATED ALWAYS AS IDENTITY,
title TEXT NOT NULL,
slug TEXT NOT NULL UNIQUE,
meta_description TEXT,
status TEXT NOT NULL DEFAULT 'draft',
target_keyword TEXT,
strategy_summary JSONB,
body JSONB,
source_record_id TEXT,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
-- Add comments to clarify the use of each column
COMMENT ON TABLE public.seo_articles IS 'Stores SEO articles generated by AI workflow';
COMMENT ON COLUMN public.seo_articles.title IS 'SEO title of the article';
COMMENT ON COLUMN public.seo_articles.slug IS 'URL slug for page generation';
COMMENT ON COLUMN public.seo_articles.status IS 'Publication status (e.g., draft, published)';
COMMENT ON COLUMN public.seo_articles.strategy_summary IS 'Stores trend insights and content angle in JSON format';
COMMENT ON COLUMN public.seo_articles.body IS 'Structured article content stored as JSON array of sections';
COMMENT ON COLUMN public.seo_articles.source_record_id IS 'Record ID to link back to source data from n8n';Once this is set up, your content team can retrieve these articles directly from the database, or your website can call them via API for automatic publishing.
Bonus: Advanced SEO Implementation
You might wonder: why not just let AI generate the whole article in Markdown instead of breaking it into JSON? Isn’t that more convenient?
That’s the difference between a “toy AI demo” and a truly scalable content engine.
Here’s why a structured JSON format is more powerful:
- Dynamic Content Insertion: Easily inject high-converting CTA buttons, product videos, or related links at any point in the article—something static Markdown simply can’t do.
- Rich Media SEO: Quickly extract H2 titles and their content to generate FAQ Schema for Google, boosting click-through rates in SERPs.
- Content Reusability: Each JSON block is a standalone knowledge unit. You can use it to train chatbots, run A/B tests on sections, or repackage the content for newsletters or social posts.
Use Scrapeless+n8n to achieve highly automated programs today!
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


