
Automate Real Estate Listing Scraping with Scrapeless & n8n Workflows
Advanced Data Extraction Specialist
In the real estate industry, automating the process of scraping the latest property listings and storing them in a structured format for analysis is key to improving efficiency. This article will provide a step-by-step guide on how to use the low-code automation platform n8n, together with the web scraping service Scrapeless, to regularly scrape rental listings from the LoopNet real estate website and automatically write the structured property data into Google Sheets for easy analysis and sharing.
1. Workflow Goal and Architecture
Goal:Automatically fetch the latest for-sale/for-lease listings from a commercial real estate platform (e.g., Crexi / LoopNet) on a weekly schedule.
Bypass anti-scraping mechanisms and store the data in a structured format in Google Sheets, making it easy for reporting and BI visualization.
Final Workflow Architecture:
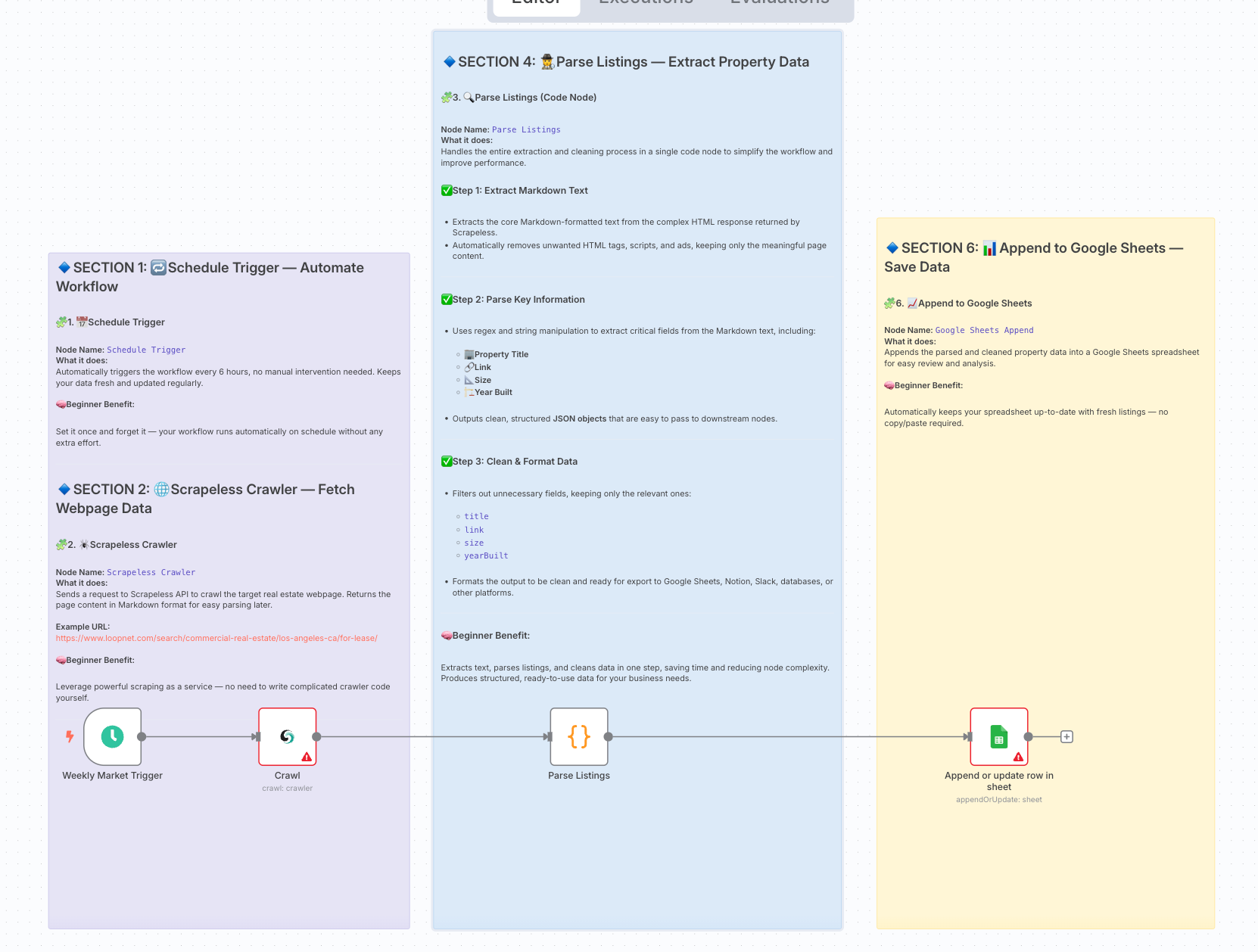
2. Preparation
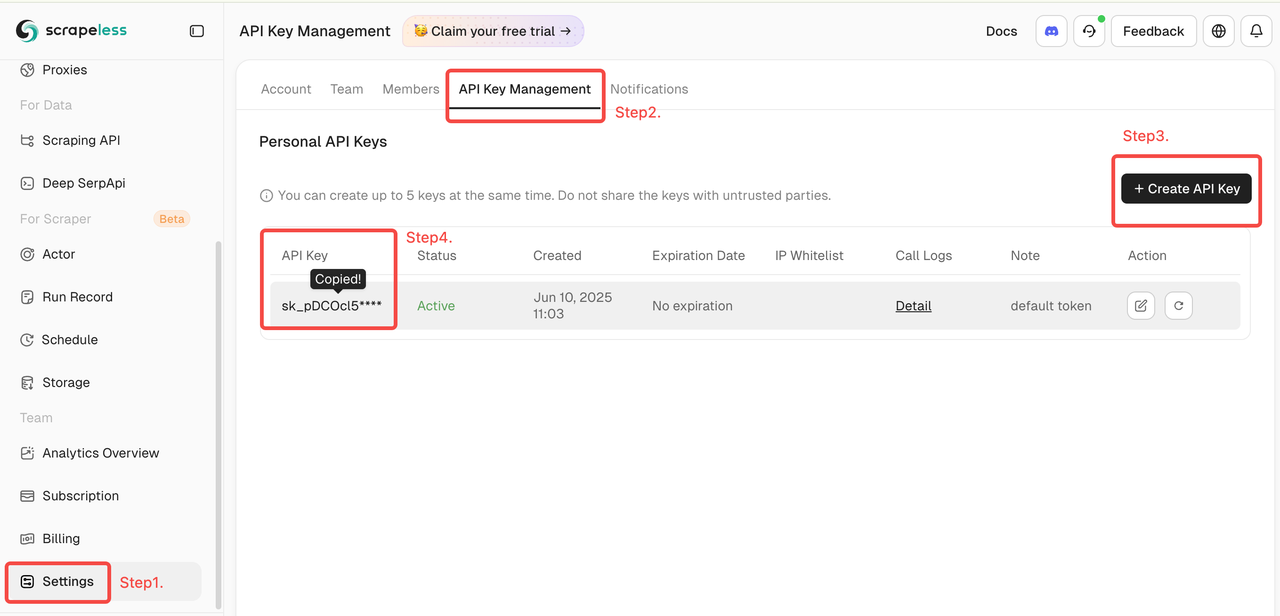
- Sign up for an account on the Scrapeless official website and obtain your API Key (2,000 free requests per month).
- Log in to the Scrapeless Dashboard
- Then click "Setting" on the left -> select "API Key Management" -> click "Create API Key". Finally, click the API Key you created to copy it.
- Make sure you have installed the community version of Scrapeless node in n8n
- A Google Sheets document with writable permissions and corresponding API credentials.
3. Workflow Steps Overview
| Step | Node Type | Purpose |
|---|---|---|
| 1 | Schedule Trigger | Automatically trigger the workflow every 6 hours. |
| 2 | Scrapeless Crawler | Scrape LoopNet pages and return the crawled content in markdown format. |
| 4 | Code Node (Parse Listings) | Extract the markdown field from the Scrapeless output; use regex to parse the markdown and extract structured property listing data. |
| 6 | Google Sheets Append | Write the structured property data into a Google Sheets document. |
4. Detailed Configuration and Code Explanation
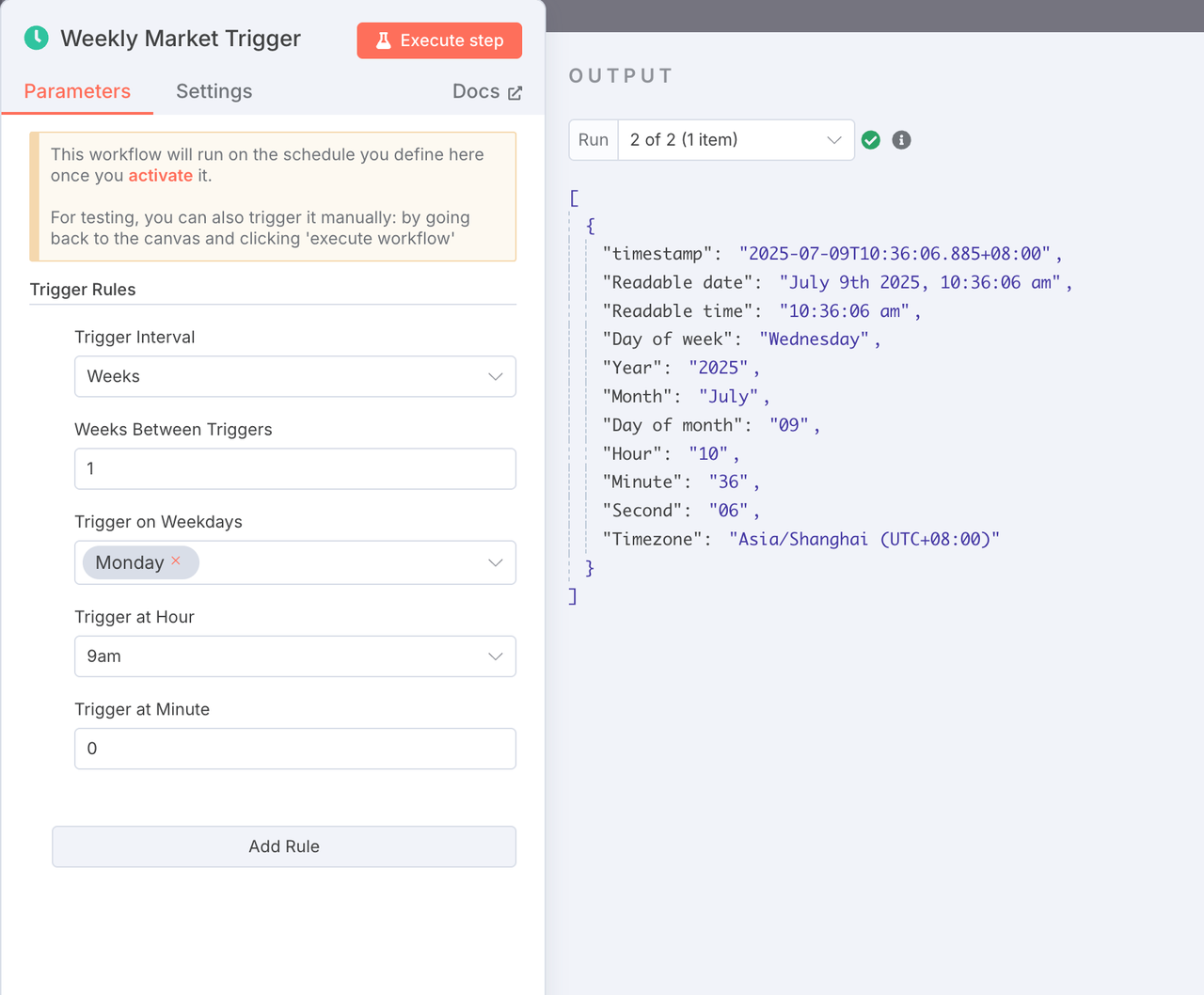
1. Schedule Trigger
- Node Type: Schedule Trigger
- Configuration: Set the interval to weekly (or adjust as needed).
- Purpose: Automatically triggers the scraping workflow on schedule, no manual action required.
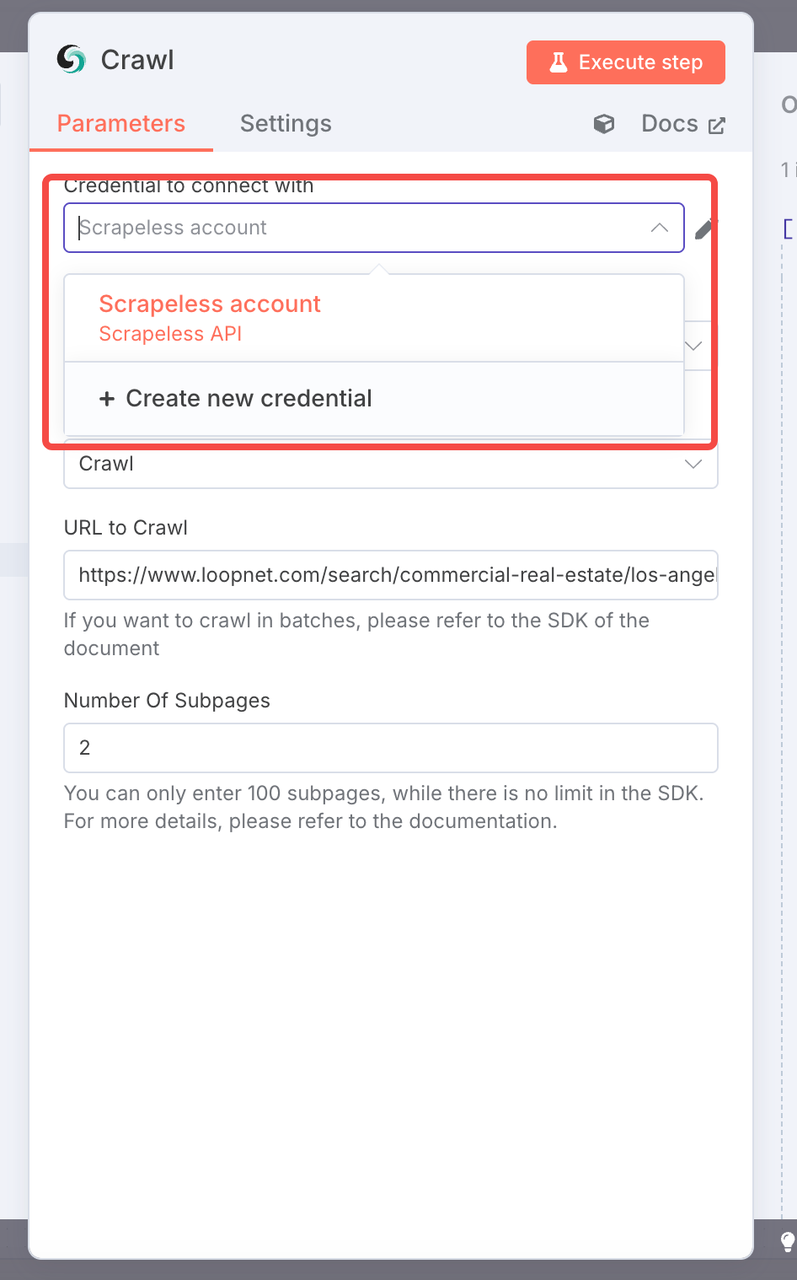
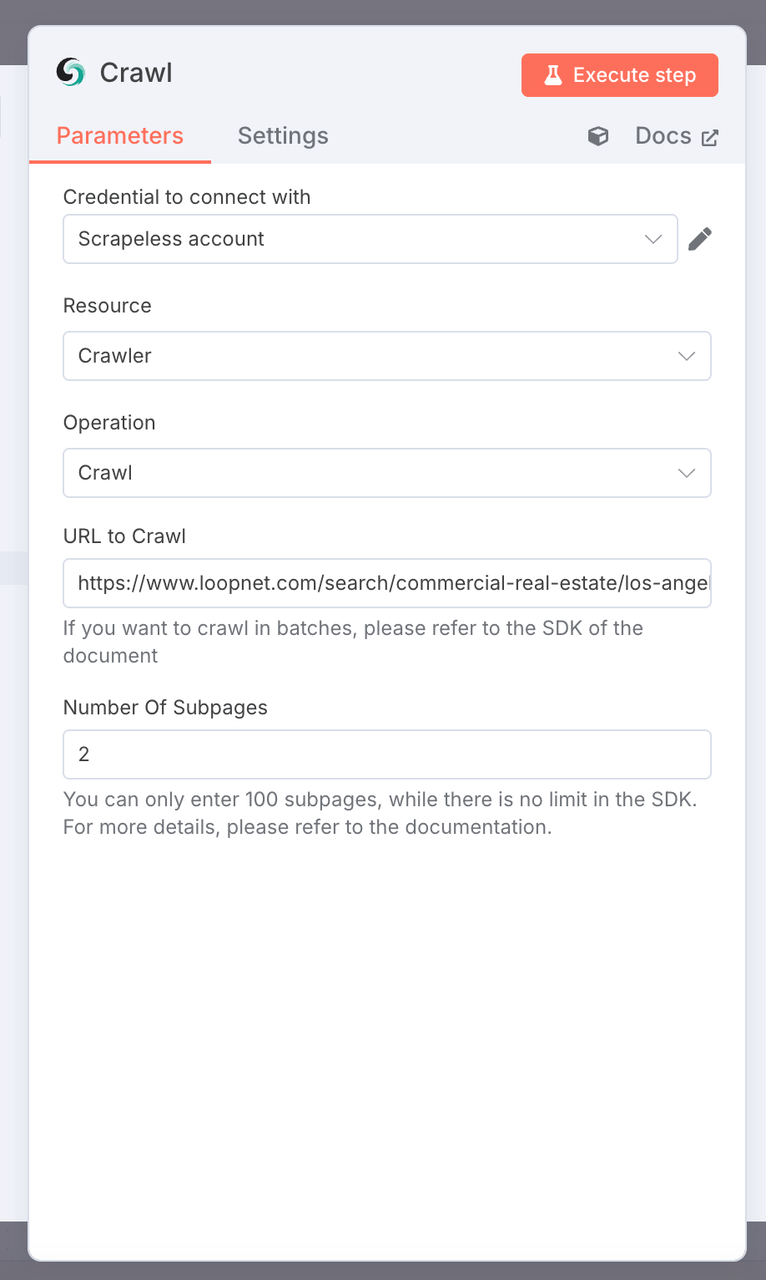
2. Scrapeless Crawler Node
- Node Type: Scrapeless API Node (
crawler - crawl) - Configuration:
- URL: Target LoopNet page, e.g.
https://www.loopnet.com/search/commercial-real-estate/los-angeles-ca/for-lease/ - API Key: Enter your Scrapeless API Key.
- Limit Pages: 2 (adjust as needed).
- URL: Target LoopNet page, e.g.
- Purpose: Automatically scrape the page content and output the web page in markdown format.
3. Parse Listings
- Purpose: Extract key commercial real estate data from the markdown-formatted web page content scraped by Scrapeless, and generate a structured data list.
- Code:
const markdownData = [];
$input.all().forEach((item) => {
item.json.forEach((c) => {
markdownData.push(c.markdown);
});
});
const results = [];
function dataExtact(md) {
const re = /\[More details for ([^\]]+)\]\((https:\/\/www\.loopnet\.com\/Listing\/[^\)]+)\)/g;
let match;
while ((match = re.exec(md))) {
const title = match[1].trim();
const link = match[2].trim()?.split(' ')[0];
// Extract a snippet of context around the match
const context = md.slice(match.index, match.index + 500);
// Extract size range, e.g. "10,000 - 20,000 SF"
const sizeMatch = context.match(/([\d,]+)\s*-\s*([\d,]+)\s*SF/);
const sizeRange = sizeMatch ? `${sizeMatch[1]} - ${sizeMatch[2]} SF` : null;
// Extract year built, e.g. "Built in 1988"
const yearMatch = context.match(/Built in\s*(\d{4})/i);
const yearBuilt = yearMatch ? yearMatch[1] : null;
// Extract image URL
const imageMatch = context.match(/!\[[^\]]*\]\((https:\/\/images1\.loopnet\.com[^\)]+)\)/);
const image = imageMatch ? imageMatch[1] : null;
results.push({
json: {
title,
link,
size: sizeRange,
yearBuilt,
image,
},
});
}
// Return original markdown if no matches found (for debugging)
if (results.length === 0) {
return [
{
json: {
error: 'No listings matched',
raw: md,
},
},
];
}
}
markdownData.forEach((item) => {
dataExtact(item);
});
return results;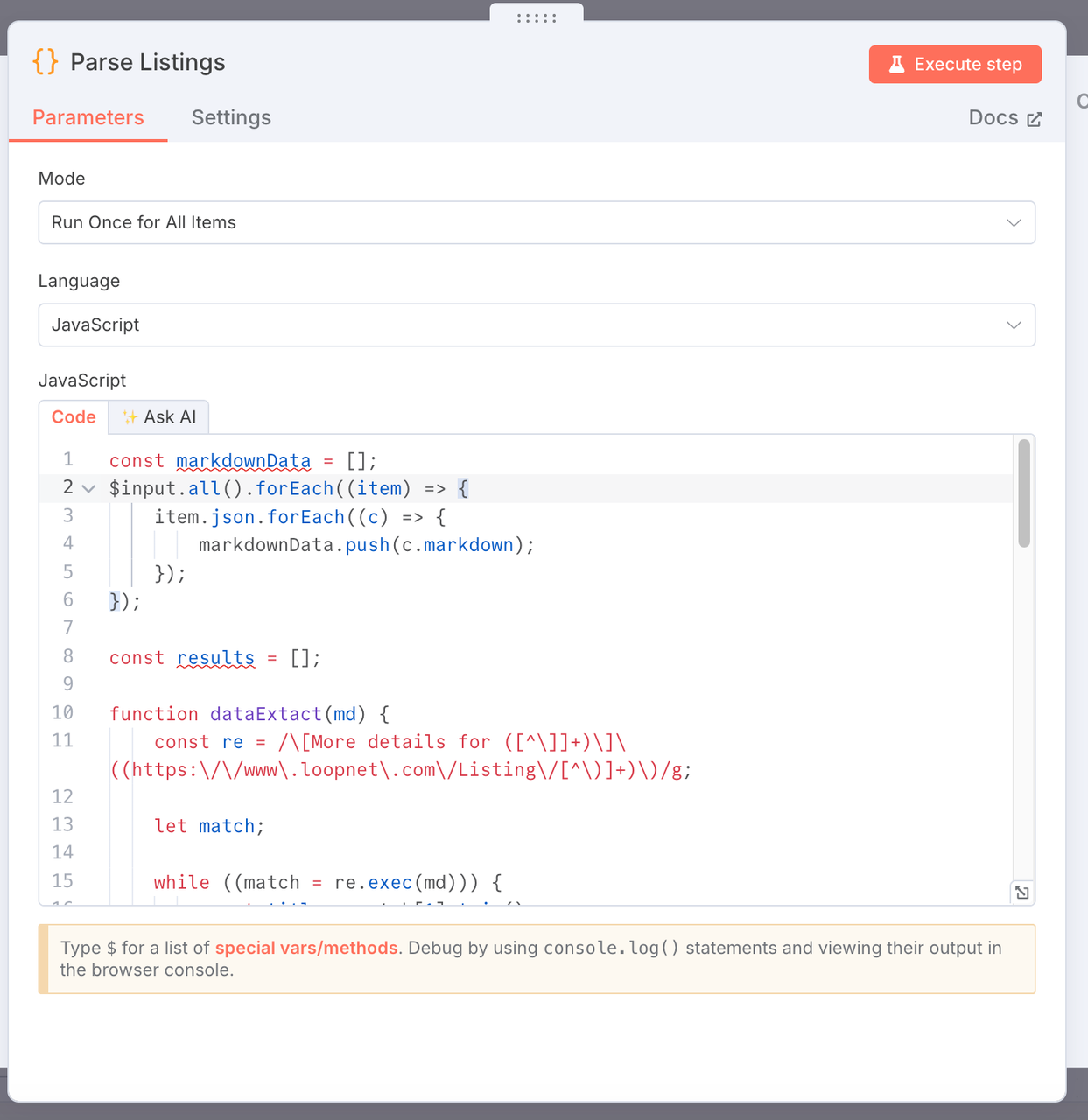
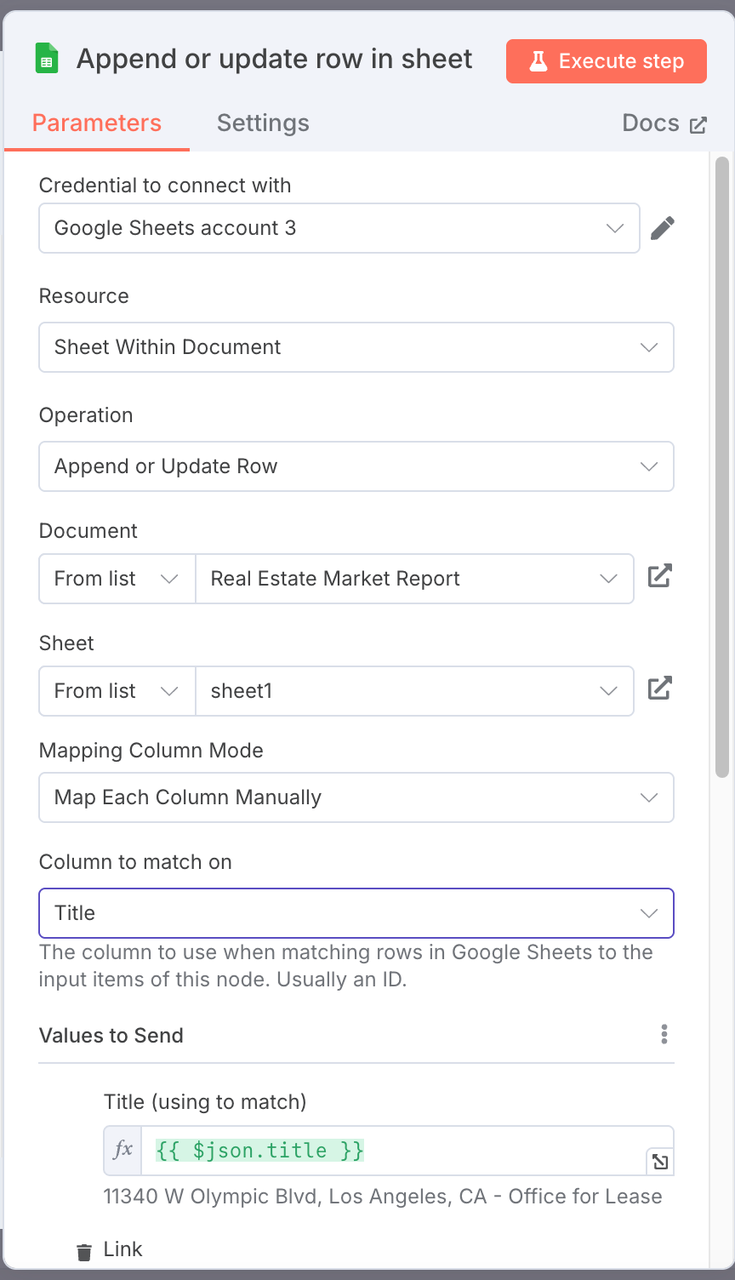
4. Google Sheets Append (Google Sheets Node)
- Operation: Append
- Configuration:
- Select the target Google Sheets file.
- Sheet Name: For example,
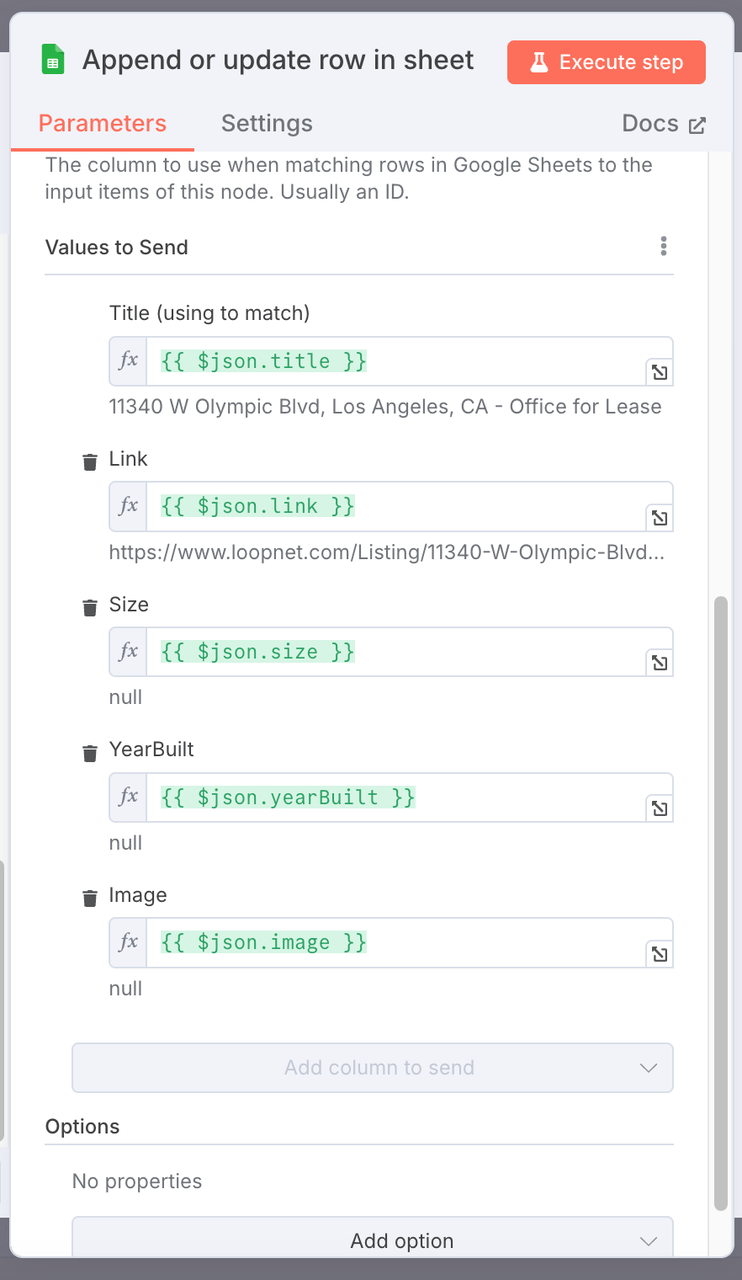
Real Estate Market Report. - Column Mapping Configuration: Map the structured property data fields to the corresponding columns in the sheet.
| Google Sheets Column | Mapped JSON Field |
|---|---|
| Title | {{ $json.title }} |
| Link | {{ $json.link }} |
| Size | {{ $json.size }} |
| YearBuilt | {{ $json.yearBuilt }} |
| Image | {{ $json.image }} |
Note:
It is recommended that your worksheet name should be consistent with ours. If you need to modify a specific name, you need to pay attention to the mapping relationship.
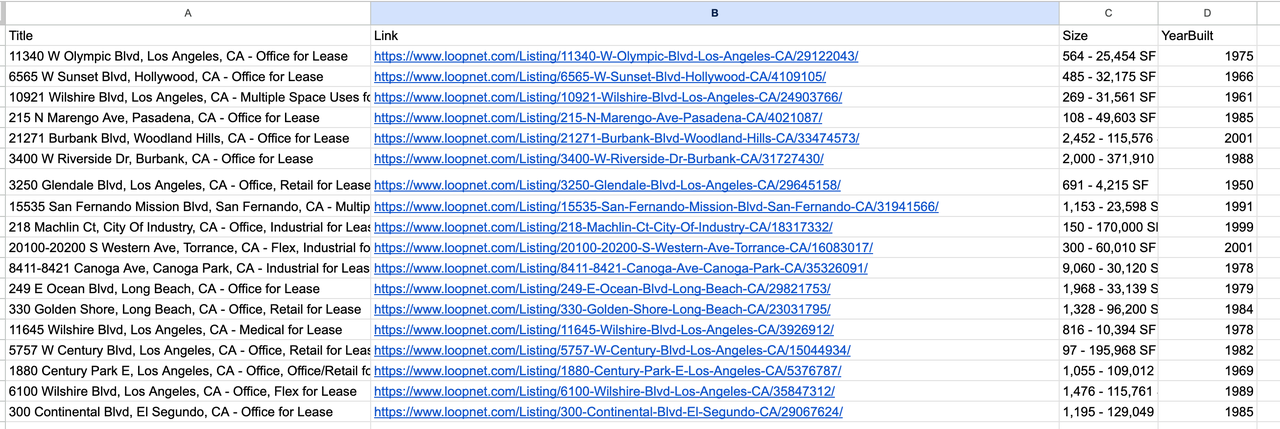
5. Result Output
5. Workflow Flowchart

6. Debugging Tips
- When running each Code node, open the node output to check the extracted data format.
- If the Parse Listings node returns no data, check whether the Scrapeless output contains valid markdown content.
- The Format Output node is mainly used to clean and normalize the output to ensure correct field mapping.
- When connecting the Google Sheets Append node, make sure your OAuth authorization is properly configured.
7. Future Optimization
- Deduplication: Avoid writing duplicate property listings.
- Filtering by Price or Size: Add filters to target specific listings.
- New Listing Notifications: Send alerts via email, Slack, etc.
- Multi-City & Multi-Page Automation: Automate scraping across different cities and pages.
- Data Visualization & Reporting: Build dashboards and generate reports from the structured data.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


