
How to Scrape Data on Make Automatically?
Senior Web Scraping Engineer
We've recently launched an official integration on Make, now available as a public app. This tutorial will show you how to create a powerful automated workflow that combines our Google Search API with Web Unlocker to extract data from search results, process it with Claude AI, and send it to a webhook.
What We'll Build
In this tutorial, we'll create a workflow that:
- Triggers automatically every day using integrated scheduling
- Searches Google for specific queries using Scrapeless Google Search API
- Processes each URL individually with Iterator
- Scrapes each URL with Scrapeless WebUnlocker to extract content
- Analyzes content with Anthropic Claude AI
- Sends processed data to a webhook (Discord, Slack, database, etc.)
Prerequisites
- A Make.com account
- A Scrapeless API key (get one at scrapeless.com)
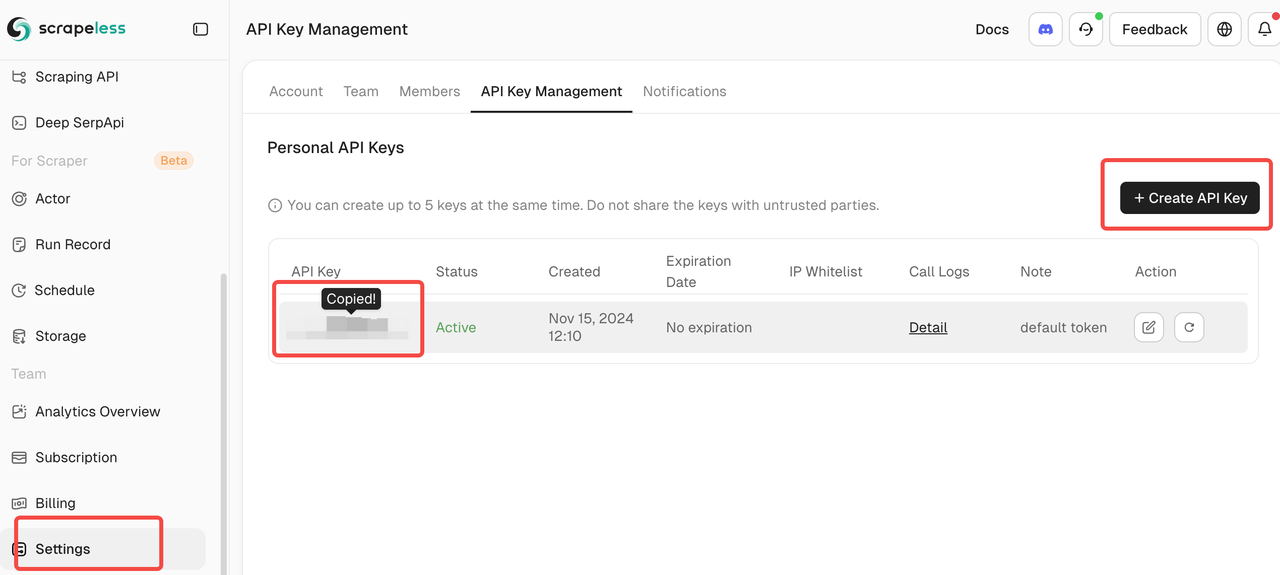
- An Anthropic Claude API key
- A webhook endpoint (Discord webhook, Zapier, database endpoint, etc.)
- Basic understanding of Make.com workflows
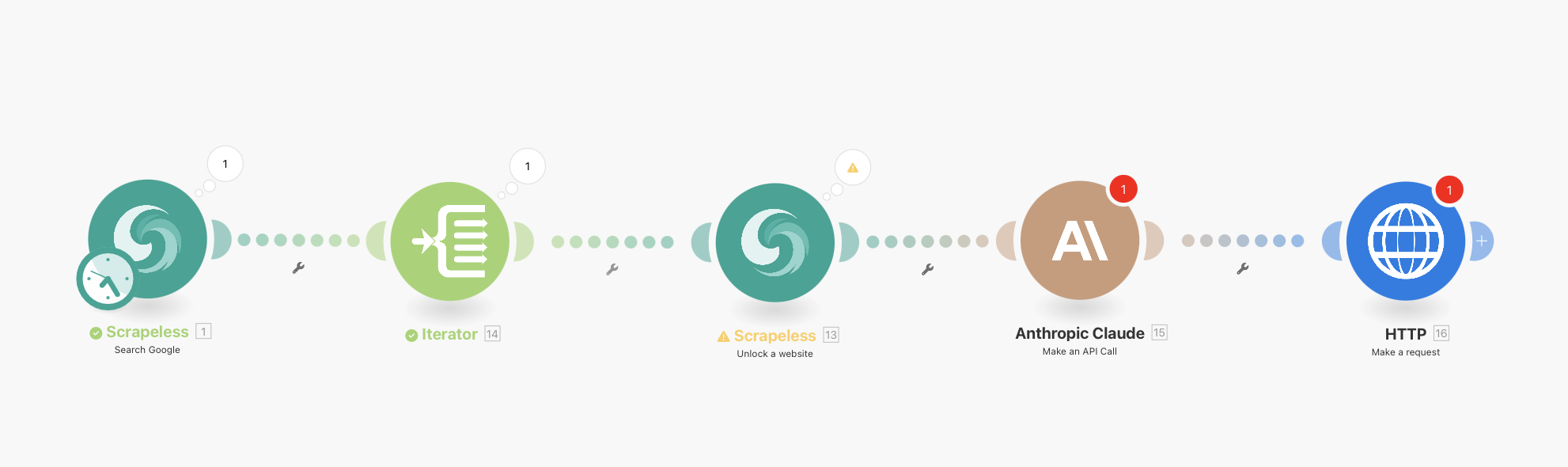
Complete Workflow Overview
Your final workflow will look like this:
Scrapeless Google Search (with integrated scheduling) → Iterator → Scrapeless WebUnlocker → Anthropic Claude → HTTP Webhook
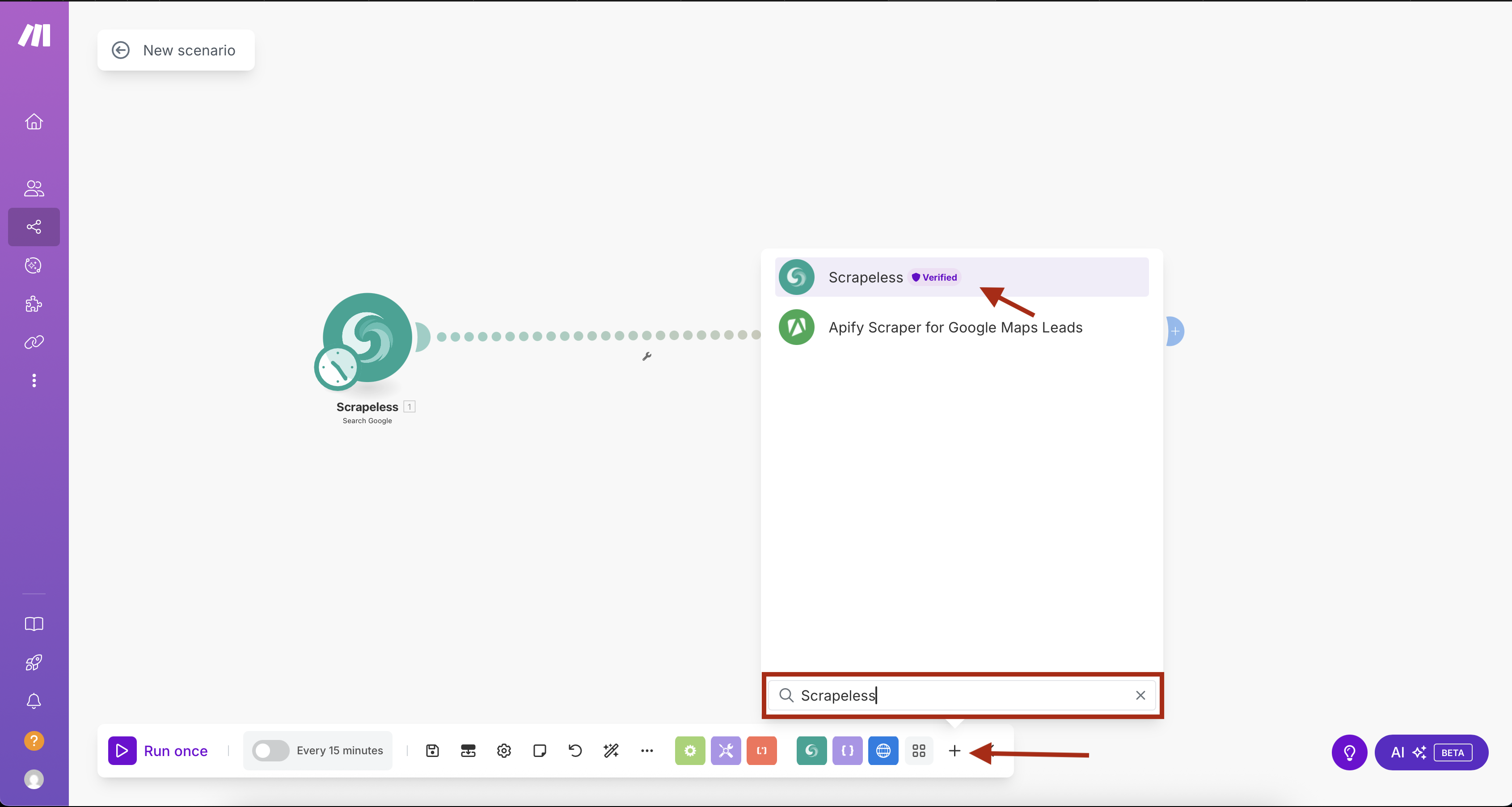
Step 1: Adding Scrapeless Google Search with Integrated Scheduling
We'll start by adding the Scrapeless Google Search module with built-in scheduling.
- Create a new scenario in Make.com
- Click the "+" button to add the first module
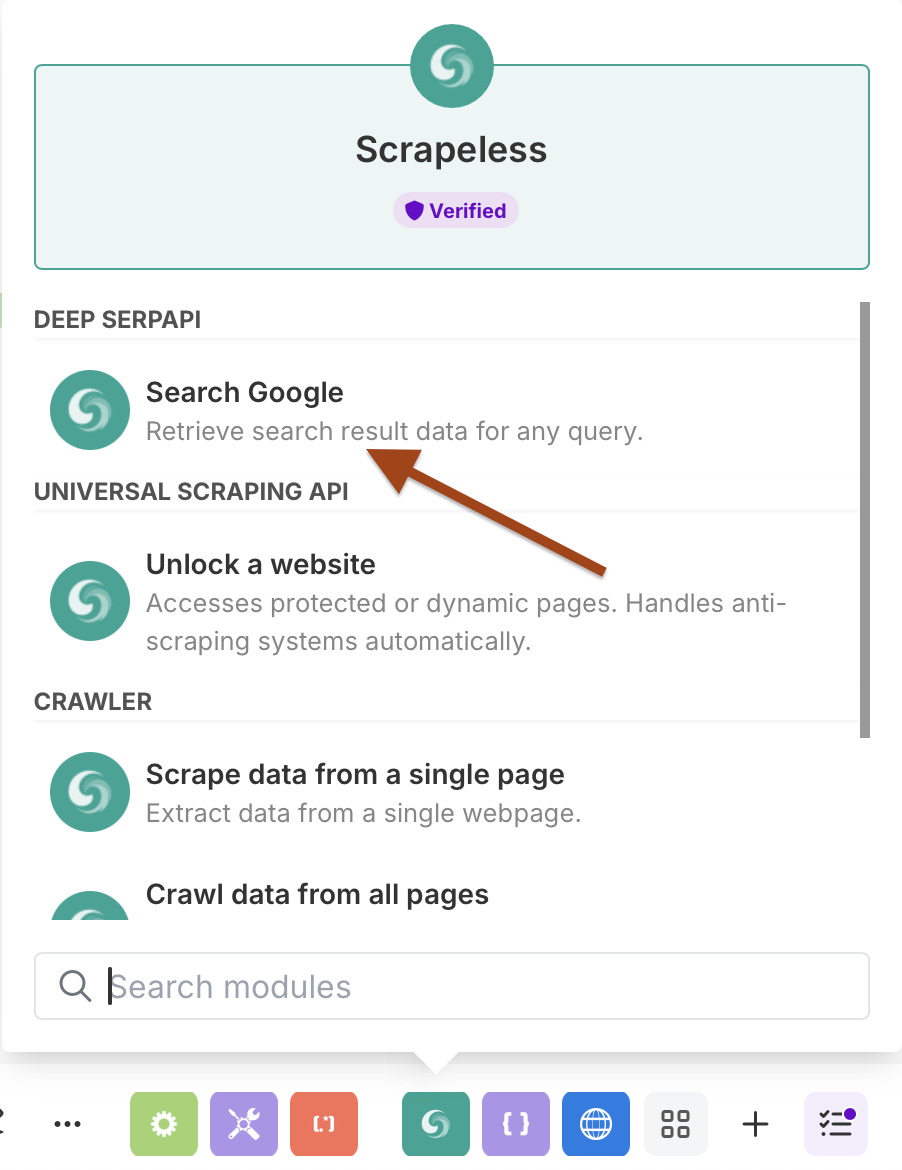
- Search for "Scrapeless" in the module library
- Select Scrapeless and choose Search Google action
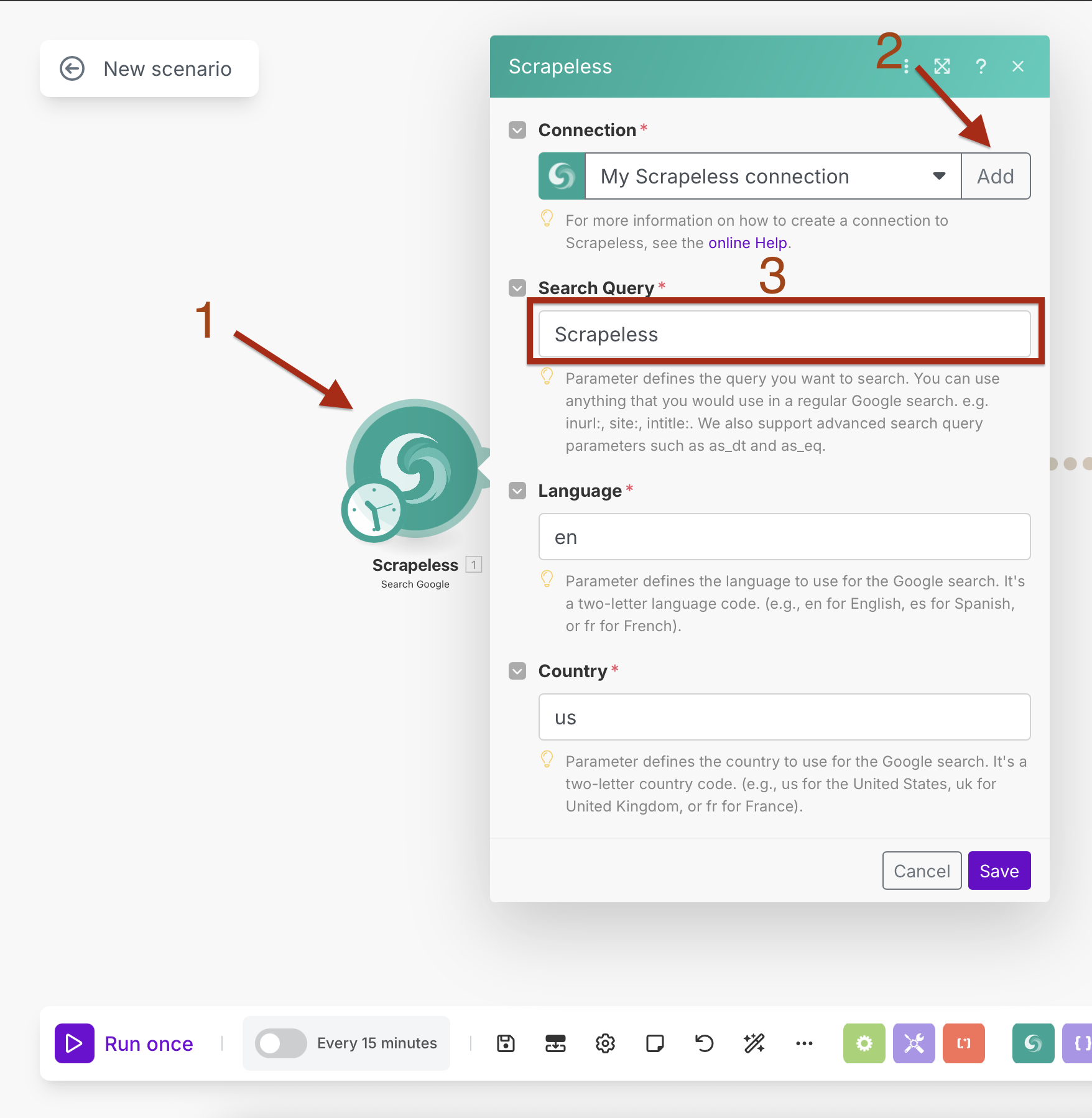
Configuring Google Search with Scheduling
Connection Setup:
- Create a connection by entering your Scrapeless API key
- Click "Add" and follow the connection setup
Search Parameters:
- Search Query: Enter your target query (e.g., "artificial intelligence news")
- Language:
en(English) - Country:
US(United States)
Scheduling Setup:
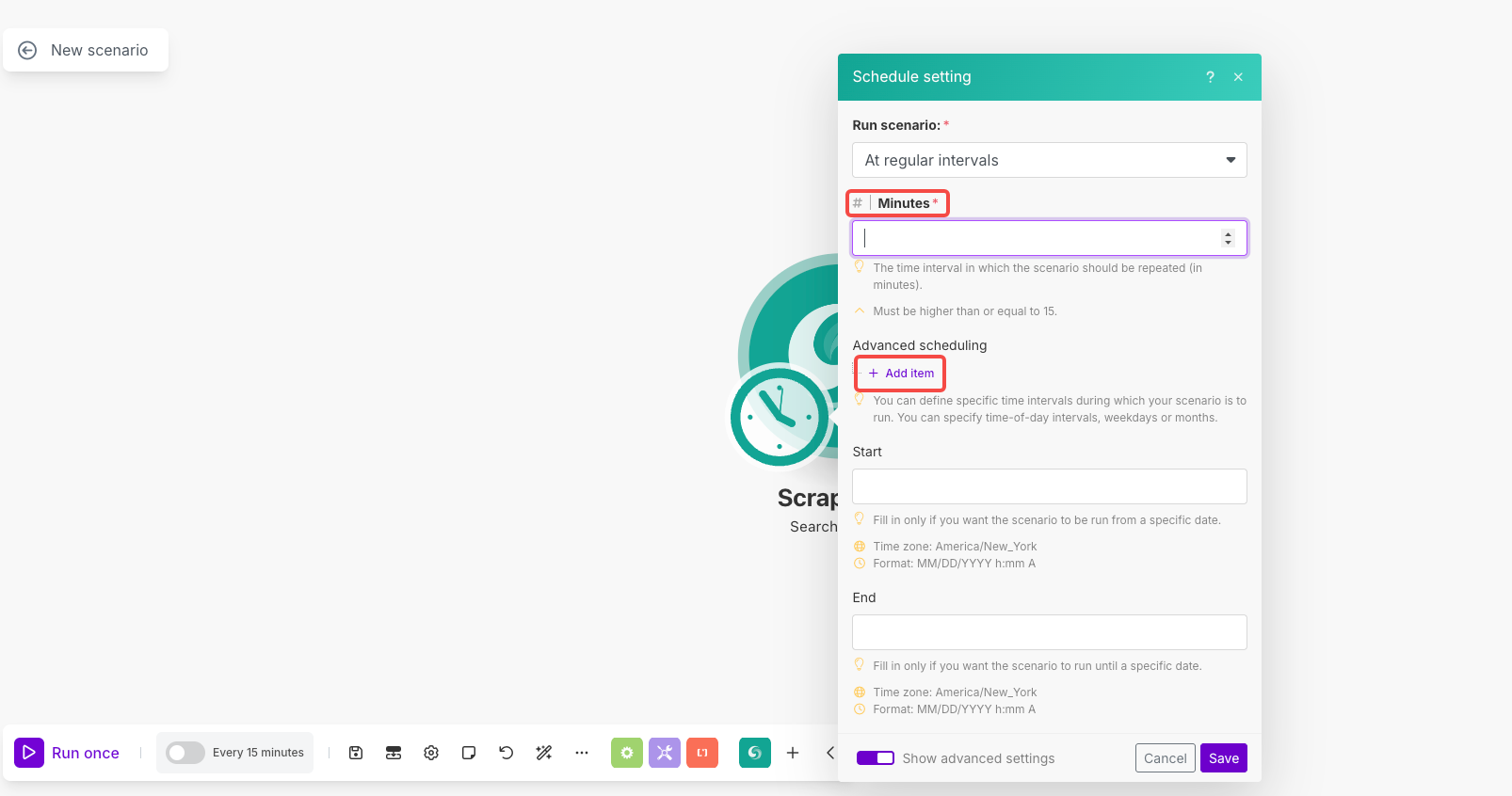
- Click the clock icon on the module to open scheduling
- Run scenario: Select "At regular intervals"
- Minutes: Set to
1440(for daily execution) or your preferred interval - Advanced scheduling: Use "Add item" to set specific times/days if needed
Step 2: Processing Results with Iterator
The Google Search returns multiple URLs in an array. We'll use Iterator to process each result individually.
- Add an Iterator module after Google Search
- Configure the Array field to process search results
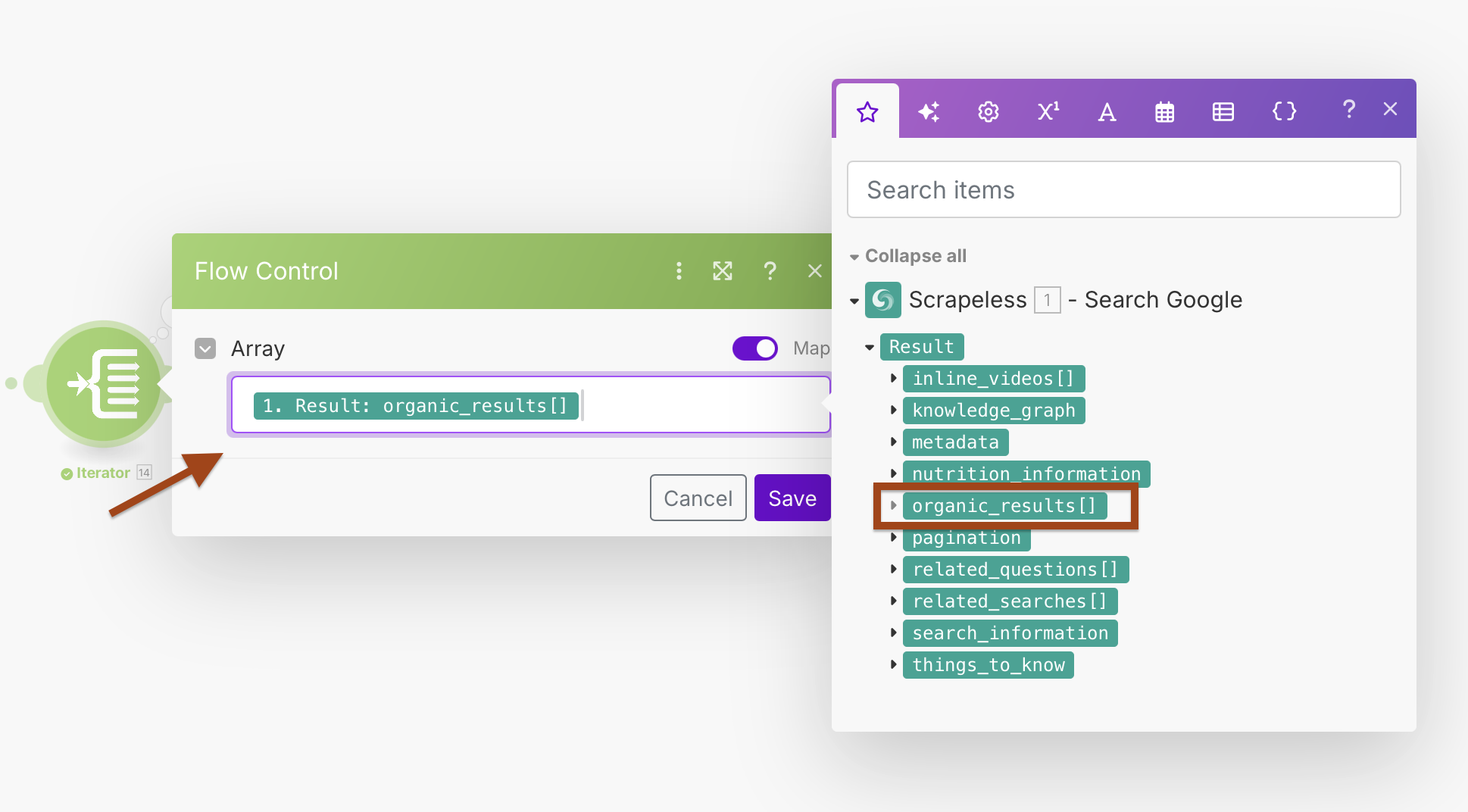
Iterator Configuration:
- Array:
{{1.result.organic_results}}
This will create a loop that processes each search result separately, allowing better error handling and individual processing.
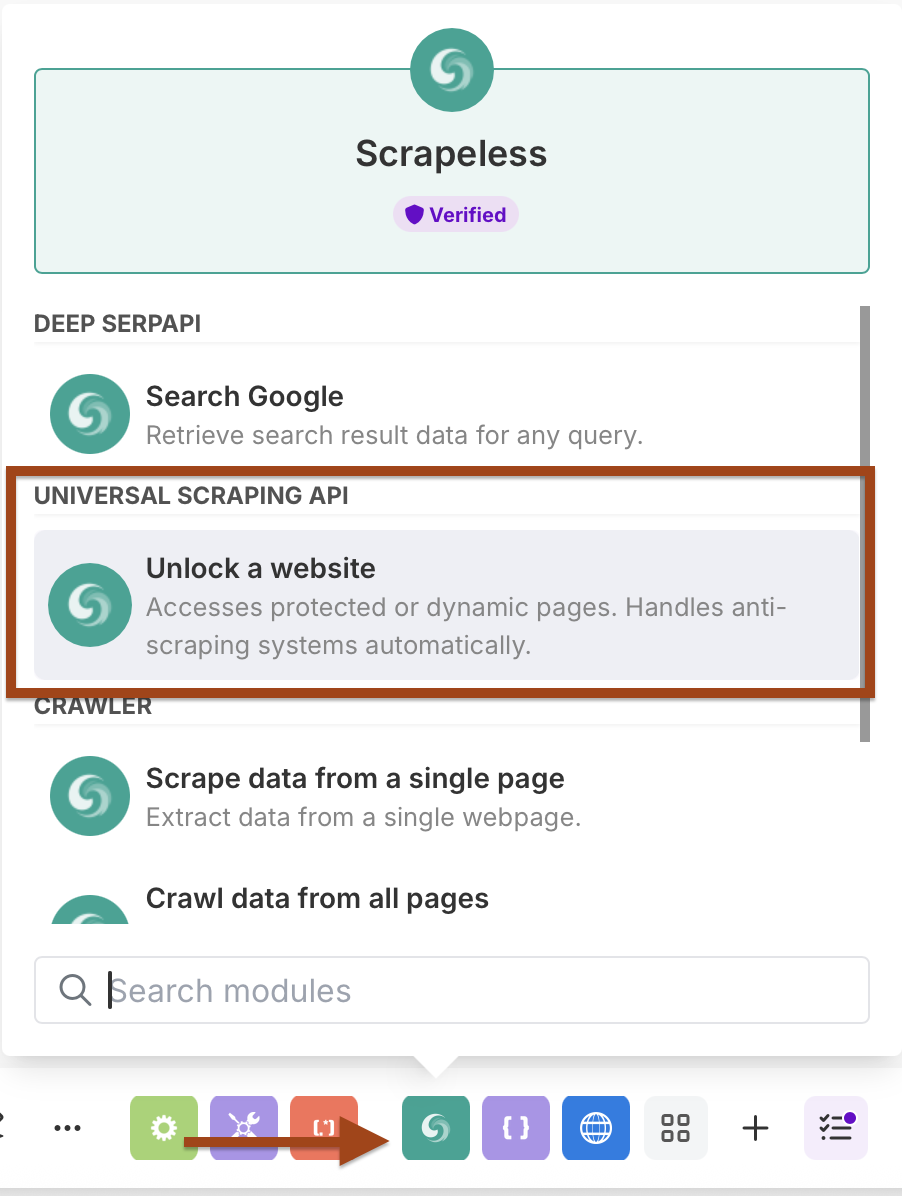
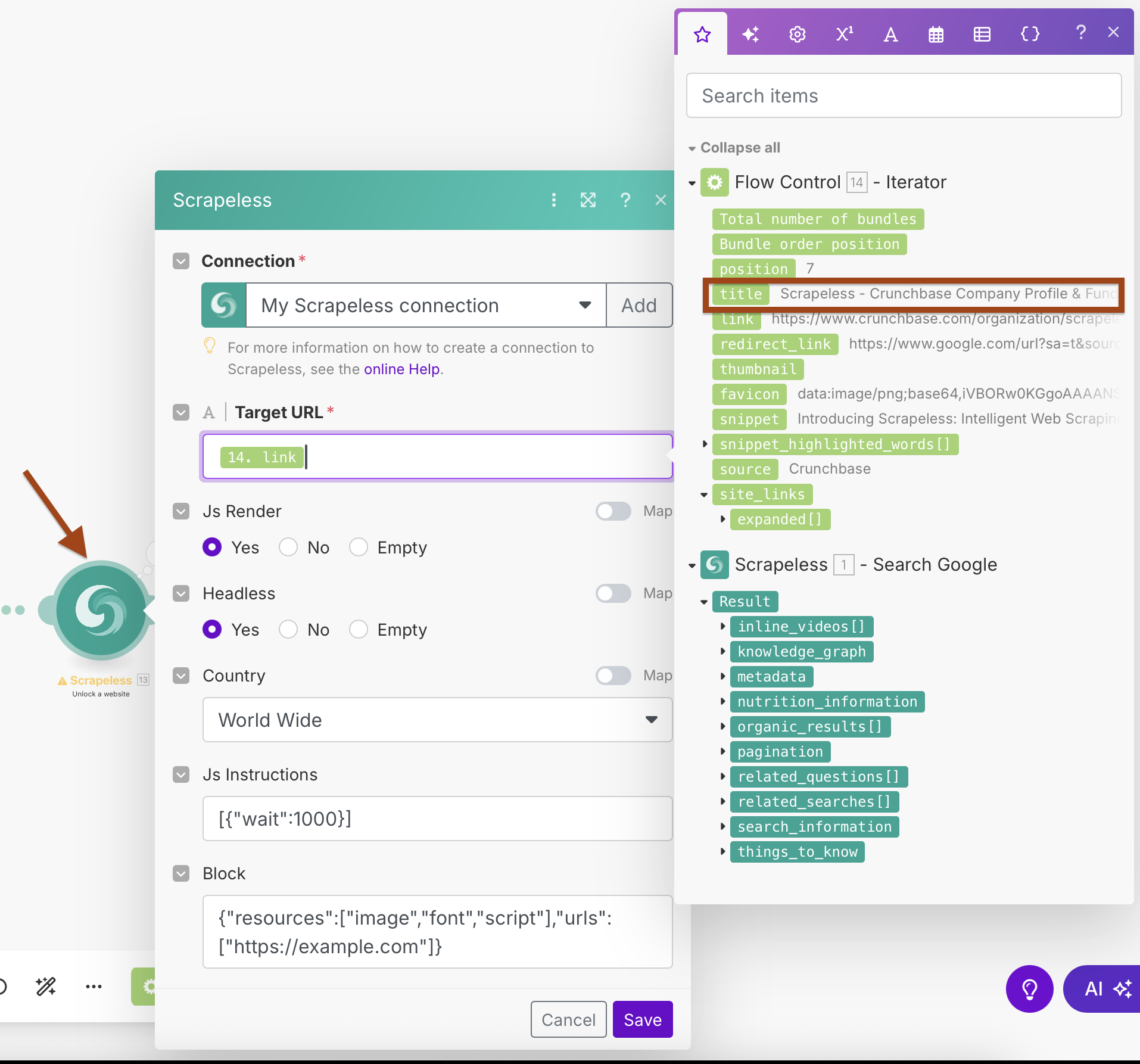
Step 3: Adding Scrapeless WebUnlocker
Now we'll add the WebUnlocker module to scrape content from each URL.
- Add another Scrapeless module
- Select Scrape URL (WebUnlocker) action
- Use the same Scrapeless connection
WebUnlocker Configuration:
- Connection: Use your existing Scrapeless connection
- Target URL:
{{2.link}}(mapped from Iterator output) - Js Render: Yes
- Headless: Yes
- Country: World Wide
- Js Instructions:
[{"wait":1000}](wait for page load) - Block: Configure to block unnecessary resources for faster scraping
Step 4: AI Processing with Anthropic Claude
Add Claude AI to analyze and summarize the scraped content.
- Add an Anthropic Claude module
- Select Make an API Call action
- Create a new connection with your Claude API key
Claude Configuration:
- Connection: Create connection with your Anthropic API key
- Prompt: Configure to analyze the scraped content
- Model: claude-3-sonnet-20240229 / claude-3-opus-20240229 or your preferred model
- Max Tokens: 1000-4000 depending on your needs
URL
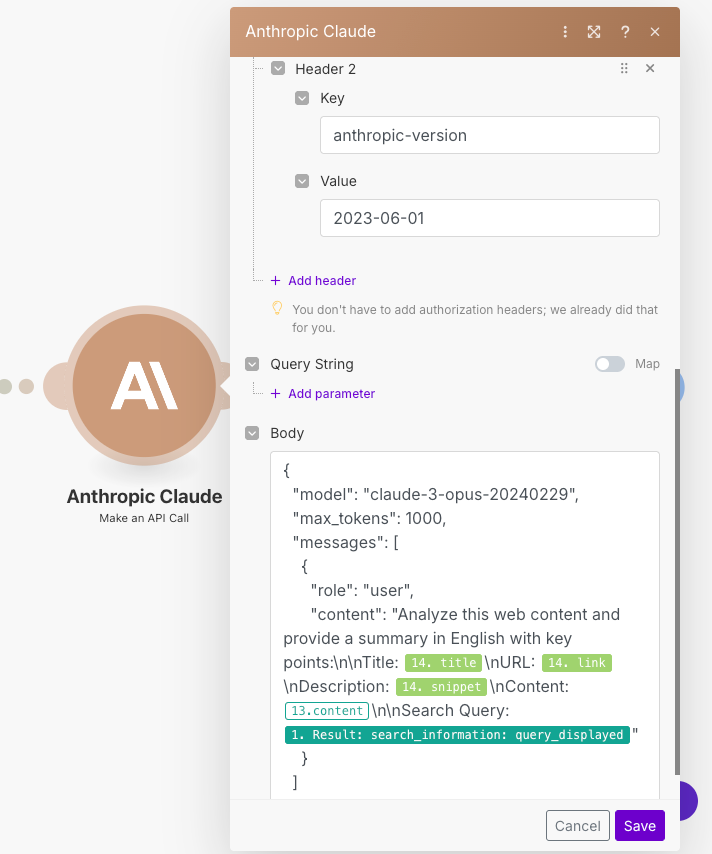
/v1/messagesHeader 1
Key : Content-TypeValue : application/json
Header 2
Key : anthropic-versionValue : 2023-06-01
Example Prompt copy paste in body:
{
"model": "claude-3-sonnet-20240229",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": "Analyze this web content and provide a summary in English with key points:\n\nTitle: {{14.title}}\nURL: {{14.link}}\nDescription: {{14.snippet}}\nContent: {{13.content}}\n\nSearch Query: {{1.result.search_information.query_displayed}}"
}
]
}- Don't forget to change number ```14`` by your module number.
Step 5: Webhook Integration
Finally, send the processed data to your webhook endpoint.
- Add an HTTP module
- Configure it to send a POST request to your webhook
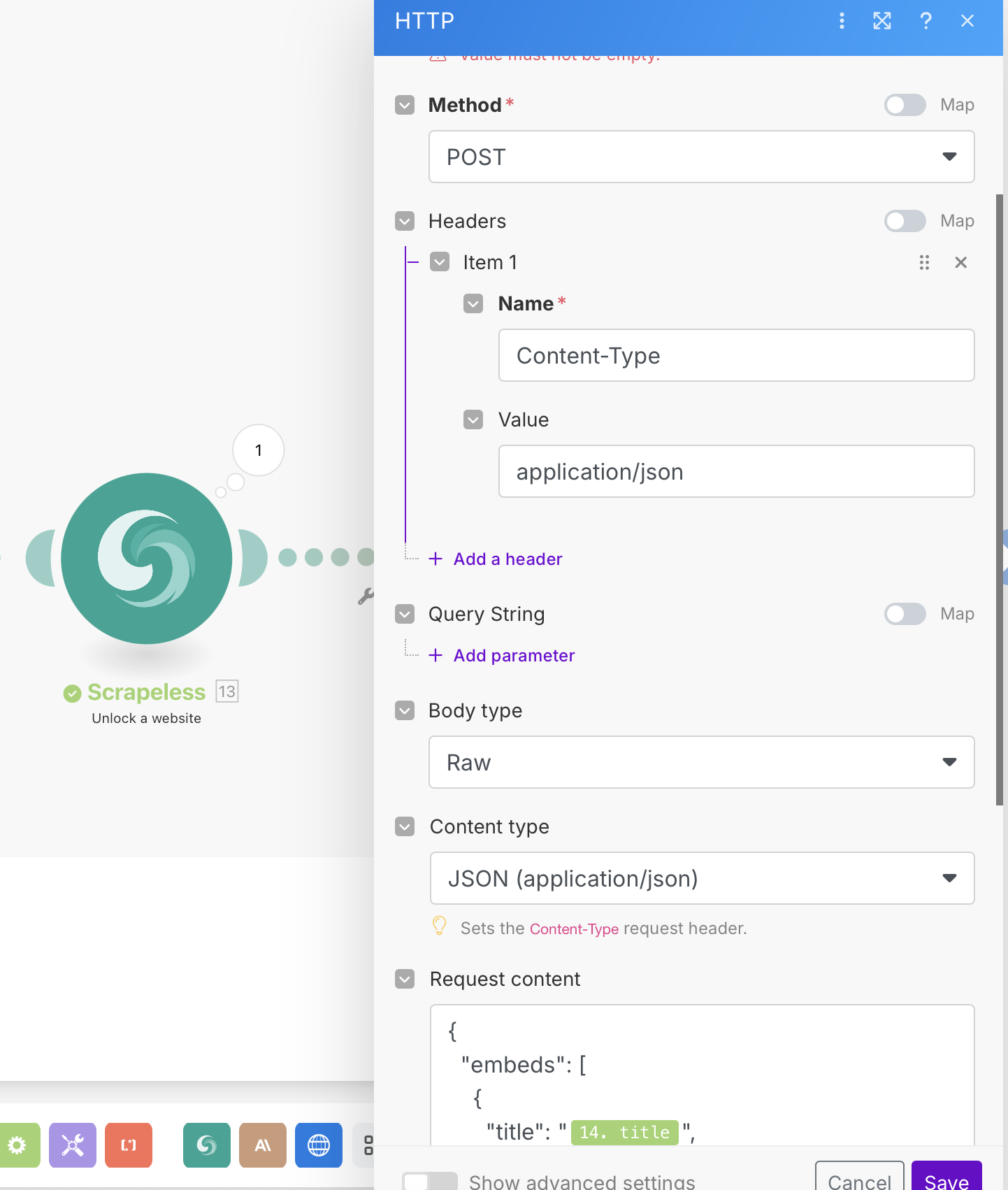
HTTP Configuration:
- URL: Your webhook endpoint (Discord, Slack, database, etc.)
- Method: POST
- Headers:
Content-Type: application/json - Body Type: Raw (JSON)
Example Webhook Payload:
{
"embeds": [
{
"title": "{{14.title}}",
"description": "*{{15.body.content[0].text}}*",
"url": "{{14.link}}",
"color": 3447003,
"footer": {
"text": "Analysis complete"
}
}
]
}Running Results
Module Reference and Data Flow
Data Flow Through Modules:
- Module 1 (Scrapeless Google Search): Returns
result.organic_results[] - Module 14 (Iterator): Processes each result, outputs individual items
- Module 13 (WebUnlocker): Scrapes
{{14.link}}, returns content - Module 15 (Claude AI): Analyzes
{{13.content}}, returns summary - Module 16 (HTTP Webhook): Sends final structured data
Key Mappings:
- Iterator Array:
{{1.result.organic_results}} - WebUnlocker URL:
{{14.link}} - Claude Content:
{{13.content}} - Webhook Data: Combination of all previous modules
Testing Your Workflow
- Run once to test the complete scenario
- Check each module:
- Google Search returns organic results
- Iterator processes each result individually
- WebUnlocker successfully scrapes content
- Claude provides meaningful analysis
- Webhook receives structured data
- Verify data quality in your webhook destination
- Check scheduling - ensure it runs at your preferred intervals
Advanced Configuration Tips
Error Handling
- Add Error Handler routes after each module
- Use Filters to skip invalid URLs or empty content
- Set Retry logic for temporary failures
Benefits of This Workflow
- Fully Automated: Runs daily without manual intervention
- AI-Enhanced: Content is analyzed and summarized automatically
- Flexible Output: Webhook can integrate with any system
- Scalable: Processes multiple URLs efficiently
- Quality Controlled: Multiple filtering and validation steps
- Real-time Notifications: Immediate delivery to your preferred platform
Use Cases
Perfect for:
- Content Monitoring: Track mentions of your brand or competitors
- News Aggregation: Automated news summaries on specific topics
- Market Research: Monitor industry trends and developments
- Lead Generation: Find and analyze potential business opportunities
- SEO Monitoring: Track search result changes for target keywords
- Research Automation: Gather and summarize academic or industry content
Conclusion
This automated workflow combines the power of Scrapeless's Google Search and WebUnlocker with Claude AI's analysis capabilities, all orchestrated through Make's visual interface. The result is an intelligent content discovery system that runs automatically and delivers enriched, analyzed data directly to your preferred platform via webhook.
The workflow will run on your schedule, automatically discovering, scraping, analyzing, and delivering relevant content insights without any manual intervention.
Time to build your first AI Agent on Make using Scrapeless!
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


