
How to Track Google Search Results Using Scrapeless on Pipedream?
Senior Web Scraping Engineer
You already know — Scrapeless has successfully launched on Pipedream! This significantly enhances Scrapeless's convenience in helping build AI Agents and automate workflows. Simply by using node links and entering simple code, you can complete and repeatedly execute automated programs. In this outstanding tutorial, we’ll attempt to use Scrapeless's Scraping API module to track keyword update results for: Revenged Love.
I can't wait to get started on this article!
Crucial Prerequisites
How to use Scrapeless on Pipedream? With just a few basic setups, you can connect Scrapeless to Pipedream and automatically collect and process data scraped from any search engine.
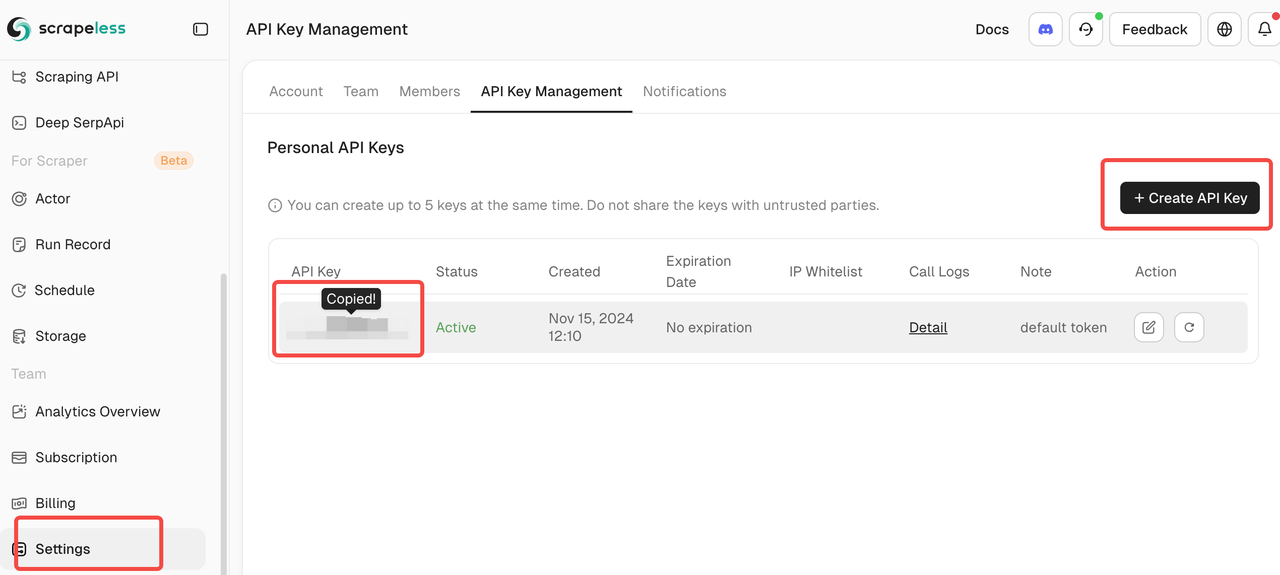
Obtain Scrapeless API Key
If you don't already have a Scrapeless account:
- Register for a Scrapeless account.
- Create your Scrapeless API Key on the dashboard.
Configure Pipedream
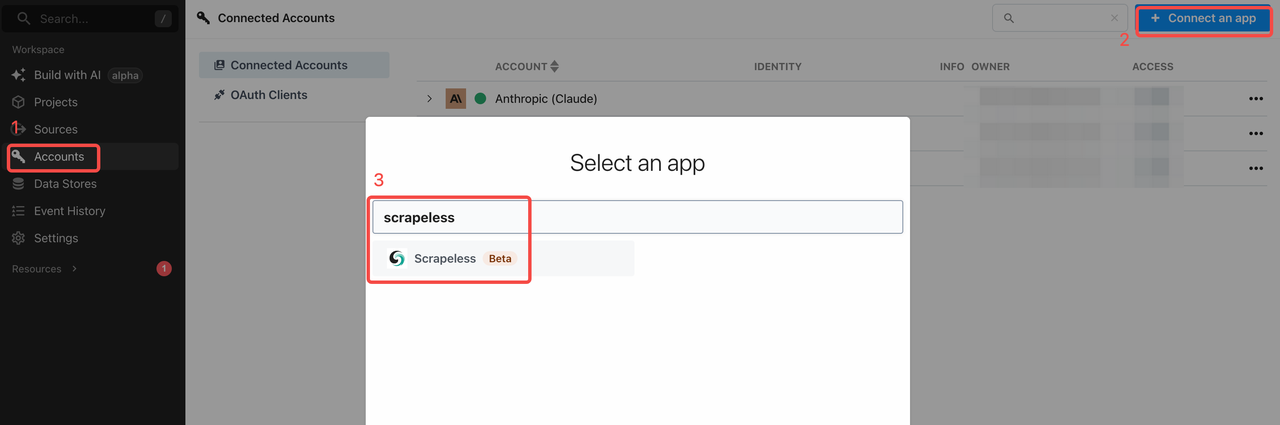
Create a Pipedream account and set up your Scrapeless API Key in Pipedream. Now, go to the "Account" tab in Pipedream and add the key there, as shown below:
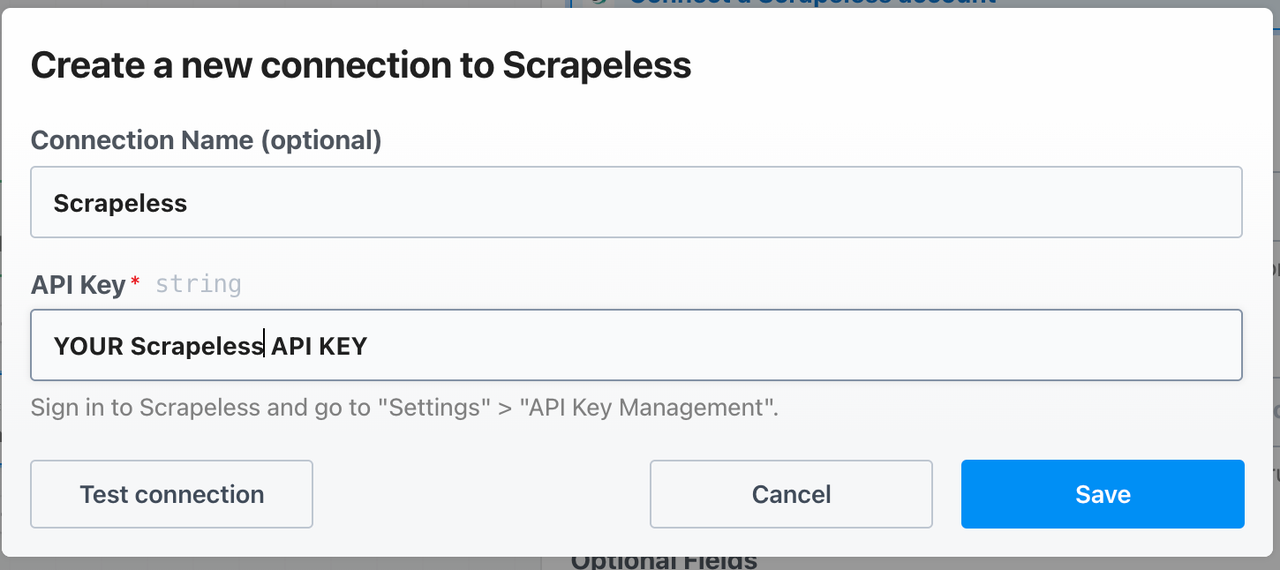
Then, set up your API key like this:
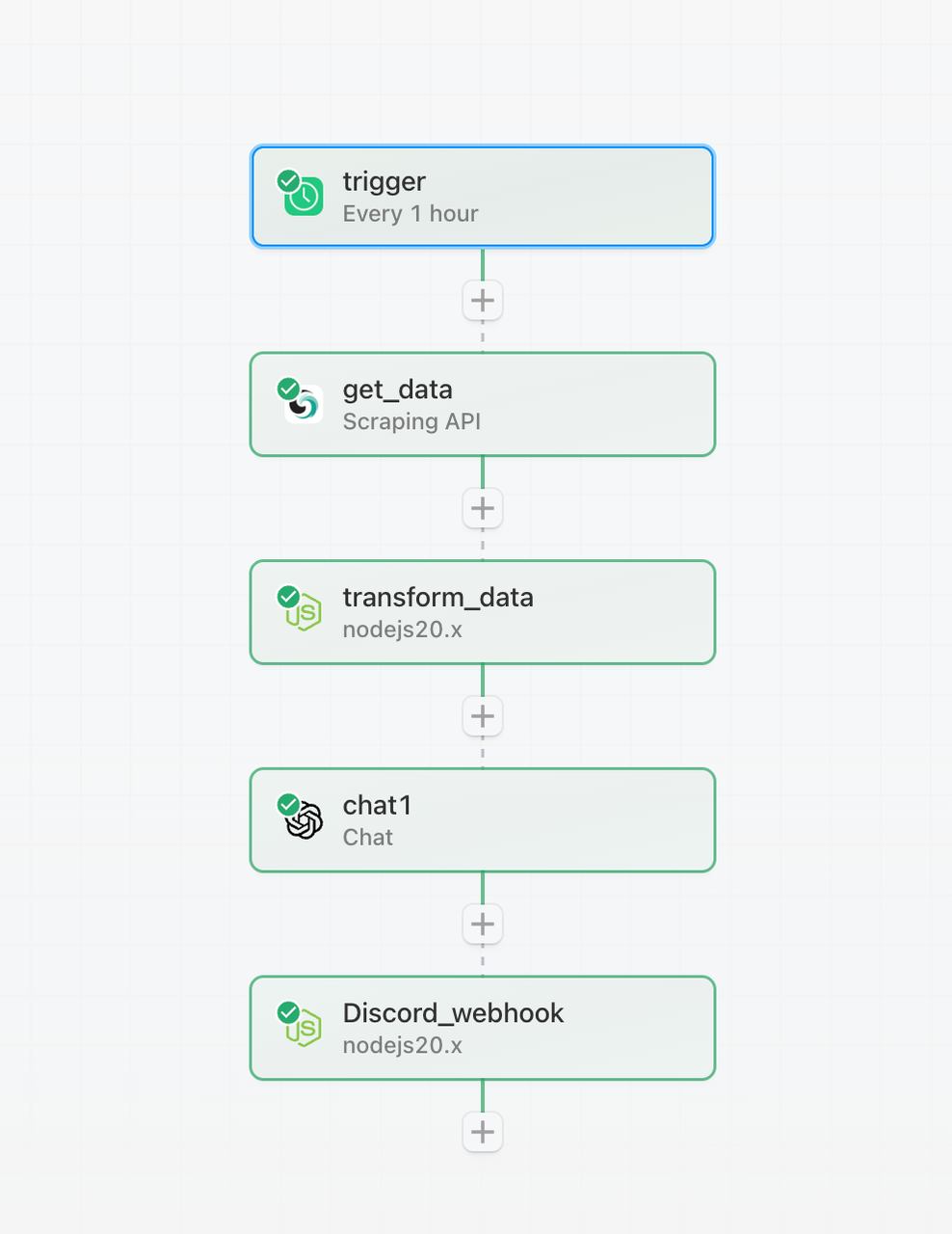
Workflow Overview
Everything is ready for you! Here are the nodes we'll use:
Trigger → Scraping API → Nodejs (transform the output structure) → OpenAI Chat → Nodejs (track keywords on Discord)
Step 1. Set Up the Trigger
The key to tracking data is repeated execution. We can use a trigger at the start of the workflow to set the execution interval. Click "Add Trigger" and configure a "Custom Interval." Now, you can set the schedule as needed.
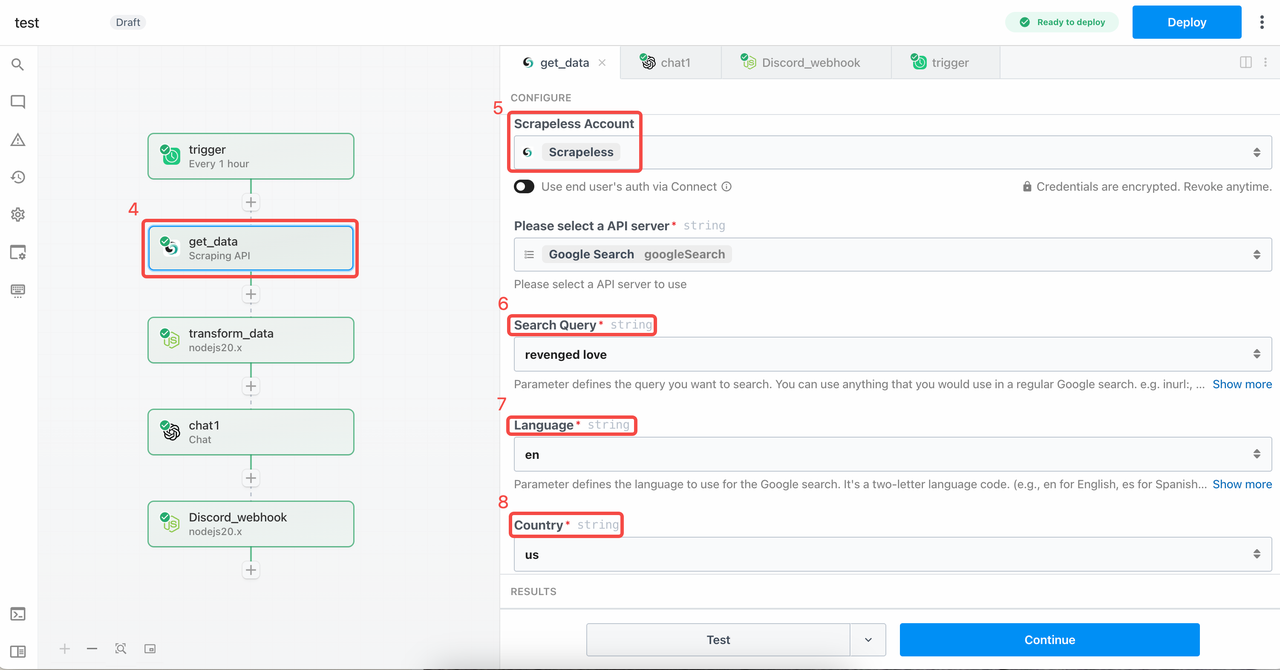
Step 2. Configure the Scraping API Module
We’ll use the Google Search feature in the Scraping API module to call Deep SerpApi for keyword searches: revenged love. Here are the parameters I used:
- Query:
revenged love - Language:
en - Country:
us
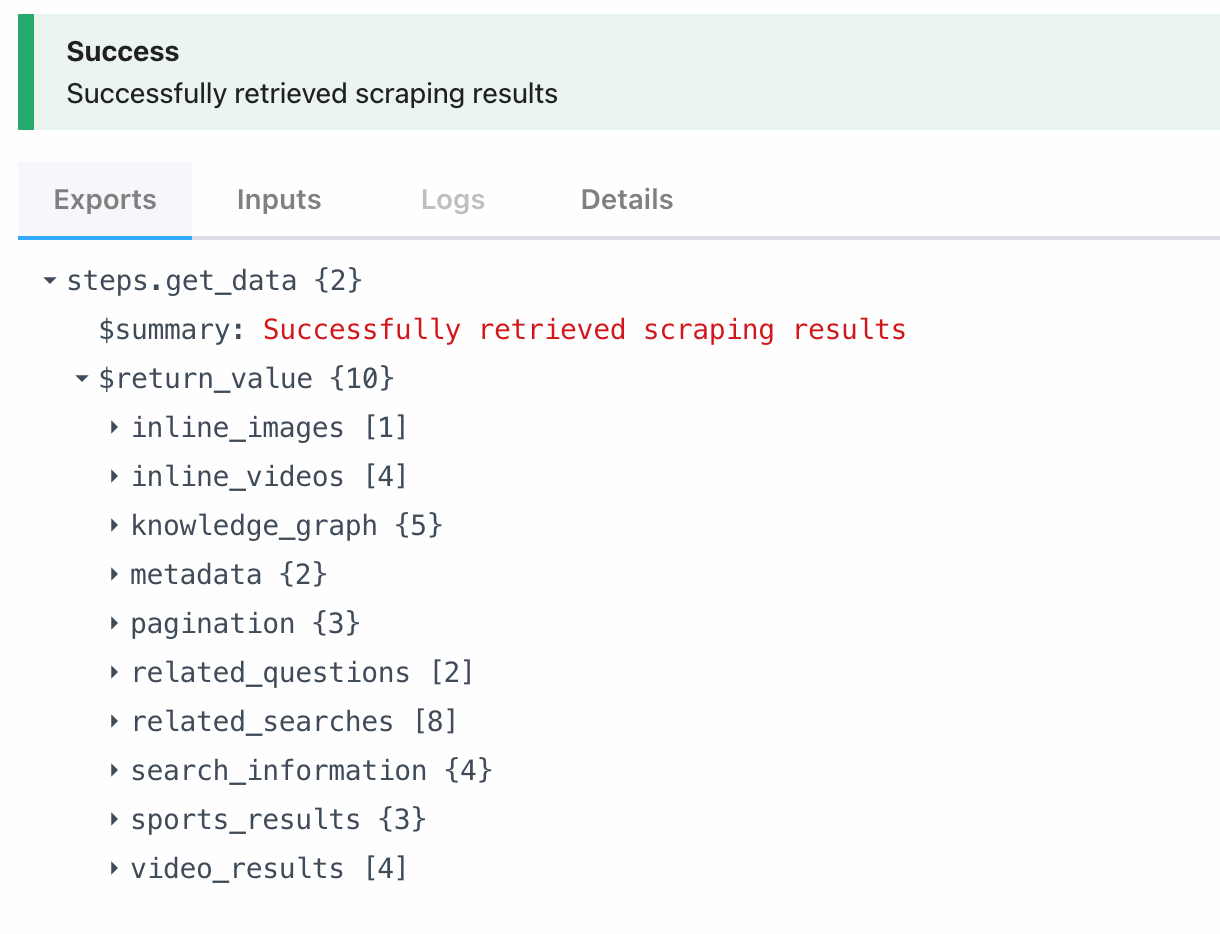
Click "Test" to successfully return real-time search results. In order to wait for the results of the asynchronous task, you may need to manually click Resume after submitting the query.
Step 3. Add Node.js 20.x Node
Since Google Search returns results in HTML, which isn’t practical for most scenarios, we can add a data transformation node to clean and filter out the content we need, such as:
video_resultsinline_images
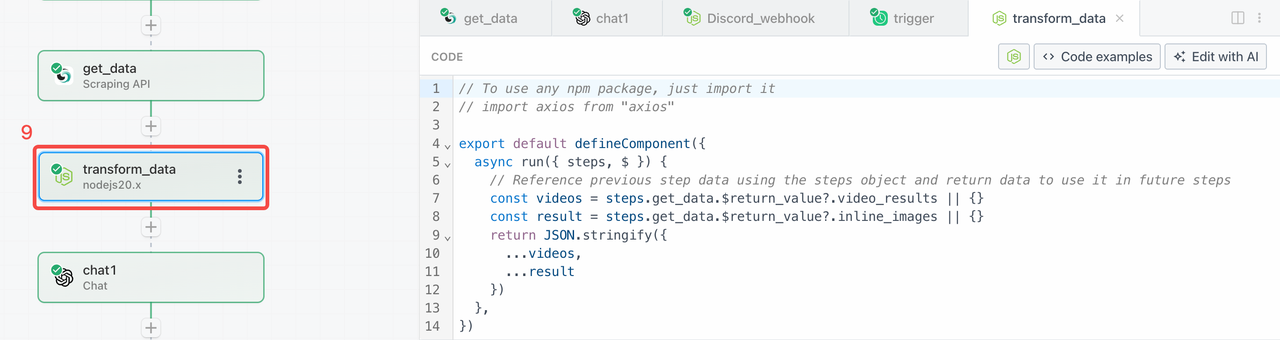
Here's the filtering code to use:
// import axios from "axios"
export default defineComponent({
async run({ steps, $ }) {
// Reference previous step data using the steps object and return data to use it in future steps
const videos = steps.get_data.$return_value?.video_results || {}
const result = steps.get_data.$return_value?.inline_images || {}
return JSON.stringify({
...videos,
...result
})
},
})Here's the returned result we obtained:
{"0":{"position":1,"thumbnail":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSd0eIXSUrXjBwCh3aU30jL3aVig5lxDtQL9w&s","related_content_id":"CnMxDy61BewRJM,8yBwVXcZCBr9dM","related_content_link":"https://www.google.com/search/about-this-image?img=H4sIAAAAAAAA_-MS5fh88MDqr-vaWqQEup4d_flg6dumN4wAqmApcRcAAAA%3D&q=https://www.viki.com/tv/38371c-first-love-again&ctx=iv&hl=en-US","source":"www.viki.com","source_logo":"","title":"First love, Again | Watch with English Subtitles & More | Viki","link":"https://www.viki.com/tv/38371c-first-love-again","original":"https://1.vikiplatform.com/c/38371c/25a36c57fc.jpg?x=b&a=0x0","original_width":3120,"original_height":1744,"in_stock":false,"is_product":false},"1":{"position":2,"title":"ENG SUB Revenged Love|EP01:Falling for the rival","link":"https://www.youtube.com/watch?v=tlCSMHgOKbE","snippet":"ENG SUB Revenged Love|EP01:Falling for the rival. 1.9M views · 2 weeks ago #RevengedLove #BL ...more. RevengedLove. 307K.","duration":"47:42","rich_snippet":{"top":{"detected_extensions":{},"extensions":[]}},"video_link":"https://encrypted-vtbn0.gstatic.com/video?q=tbn:ANd9GcR2yueHQqTvdFyBeda4_-uoEOQInAJfRm9F9A"},"2":{"position":3,"title":"EP.5 Revenged Love (2025) Engsub - video Dailymotion","link":"https://www.dailymotion.com/video/x9lrrn8","snippet":"Watch EP.5 Revenged Love (2025) Engsub - RJSN on Dailymotion. ... Revenged Love (2025) Ep 6 Eng Sub #RevengedLove · Daily Drama HD™. yesterday.","duration":"44:22","rich_snippet":{"top":{"detected_extensions":{},"extensions":[]}},"video_link":"https://encrypted-vtbn0.gstatic.com/video?q=tbn:ANd9GcS6XBgsSk3vqCefja0bVhQSxavTw43aP5dqJg"},"3":{"position":4,"title":"(2025) REVENGED LOVE EP 8 ENG SUB - video Dailymotion","link":"https://www.dailymotion.com/video/x9m5r3a","snippet":"EP.8 Revenged Love (2025) Engsub · RJSN. yesterday. 1:01:39. Revenged Love (2025) EP 8 ENG SUB · Spirit Studios HD. yesterday. 1:06:11. (2025) ...","duration":"41:17","rich_snippet":{"top":{"detected_extensions":{},"extensions":[]}}}}Step 4. Add an OpenAI Chat Node
To directly and simply obtain the most important data, you can add an OpenAI Chat node for efficient data consolidation. We need to bind the OpenAI API key and select the target model.
If you expect large amounts of returned data, don’t forget to adjust Max Tokens to avoid failures or timeouts.
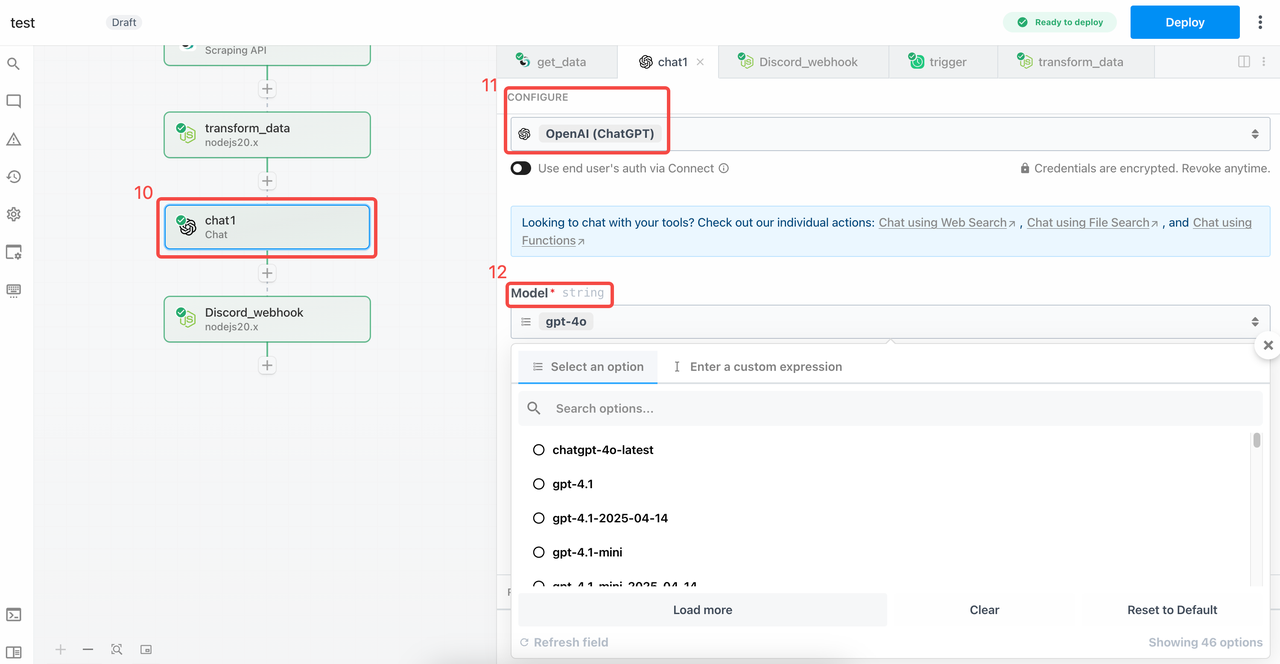
Discord has strict formatting requirements for data, and for aesthetic tracking, we now need to give Chat clear instructions: return only the target parameters in JSON format without Markdown. This makes it easier for later configuration.
Here’s a reference prompt you can refine:
Format the following JSON search results into an array of objects for Discord embeds. Each object must include:
- title (string)
- link (string)
- description (string)
- image_url (string)
- source (string)
- duration (string, optional)
❗️Output only raw JSON without any markdown code block, backticks, or explanation. If it is a arrary javascript type, you need output the Array type not a string type
Data:
{{steps.transform_data.$return_value}} // The address where the result is returnedsteps.transform_data.$return_value is the array returned from the previous step in your workflow.)
After testing, check the returned result, but ignore unimportant details—focus on the content under generated_message:
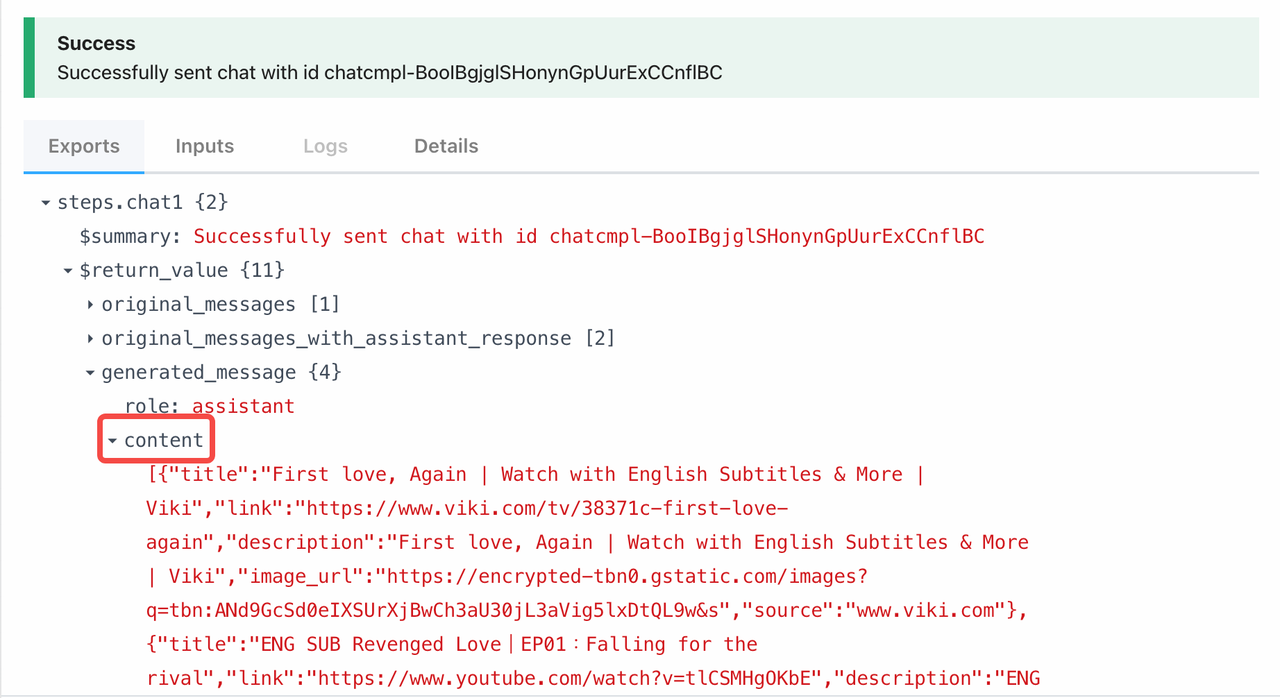
[{"title":"First love, Again | Watch with English Subtitles & More | Viki","link":"https://www.viki.com/tv/38371c-first-love-again","description":"First love, Again | Watch with English Subtitles & More | Viki","image_url":"https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSd0eIXSUrXjBwCh3aU30jL3aVig5lxDtQL9w&s","source":"www.viki.com"},{"title":"ENG SUB Revenged Love|EP01:Falling for the rival","link":"https://www.youtube.com/watch?v=tlCSMHgOKbE","description":"ENG SUB Revenged Love|EP01:Falling for the rival. 1.9M views · 2 weeks ago #RevengedLove #BL ...more. RevengedLove. 307K.","image_url":"https://encrypted-vtbn0.gstatic.com/video?q=tbn:ANd9GcR2yueHQqTvdFyBeda4_-uoEOQInAJfRm9F9A","source":"www.youtube.com","duration":"47:42"},{"title":"EP.5 Revenged Love (2025) Engsub - video Dailymotion","link":"https://www.dailymotion.com/video/x9lrrn8","description":"Watch EP.5 Revenged Love (2025) Engsub - RJSN on Dailymotion. ... Revenged Love (2025) Ep 6 Eng Sub #RevengedLove · Daily Drama HD™. yesterday.","image_url":"https://encrypted-vtbn0.gstatic.com/video?q=tbn:ANd9GcS6XBgsSk3vqCefja0bVhQSxavTw43aP5dqJg","source":"www.dailymotion.com","duration":"44:22"},{"title":"(2025) REVENGED LOVE EP 8 ENG SUB - video Dailymotion","link":"https://www.dailymotion.com/video/x9m5r3a","description":"EP.8 Revenged Love (2025) Engsub · RJSN. yesterday. 1:01:39. Revenged Love (2025) EP 8 ENG SUB · Spirit Studios HD. yesterday. 1:06:11. (2025) ...","image_url":"https://encrypted-vtbn0.gstatic.com/video?q=tbn:ANd9GcS6XBgsSk3vqCefja0bVhQSxavTw43aP5dqJg","source":"www.dailymotion.com","duration":"41:17"}]Step 5. Track the Keywords Updates on Discord
Congratulations! All the data is ready. Now, we just need to complete the final step: bind Discord and configure the auto-forwarding script. Since Chat returns results in JSON format, we can add a parameter for format conversion: 'string' ? JSON.parse(_res) : _res.
Here's the code:
import { axios } from "@pipedream/platform";
export default defineComponent({
async run({ steps, $ }) {
const _res = steps.chat1.$return_value.generated_message.content;
const results = typeof _res === 'string' ? JSON.parse(_res) : _res
const discordWebhookUrl = "YOUR_DISCORD_WEBHOOK";
const embeds = results.map(item => ({
title: item.title,
url: item.link,
description: item.description || "No description.",
color: 0x7289DA, // Discord blurple
image: item.image_url ? { url: item.image_url } : undefined,
fields: [
item.source ? { name: "Source", value: item.source, inline: true } : undefined,
item.duration ? { name: "Duration", value: item.duration, inline: true } : undefined,
].filter(Boolean),
timestamp: new Date().toISOString(),
}));
const payload = {
content: "🔎 **Search Results:**",
embeds: embeds.slice(0, 10),
};
try {
const response = await axios($, {
method: "POST",
url: discordWebhookUrl,
headers: {
"Content-Type": "application/json",
},
data: payload,
});
console.log("Sent to Discord:", response.status);
return { success: true, count: embeds.length };
} catch (error) {
console.error("Error sending to Discord:", error.message);
return { success: false, error: error.message };
}
},
});steps.Code_step.$return_valueis the JSON array returned from the previous step.- Each data entry generates a Discord embed, including title, link, description, image, source, and timestamp.
- A maximum of 10 embeds can be sent at once (Discord’s limit). If you have more data, modify it for batch sending.
- You can change the text in the
contentfield to customize the displayed title or description.
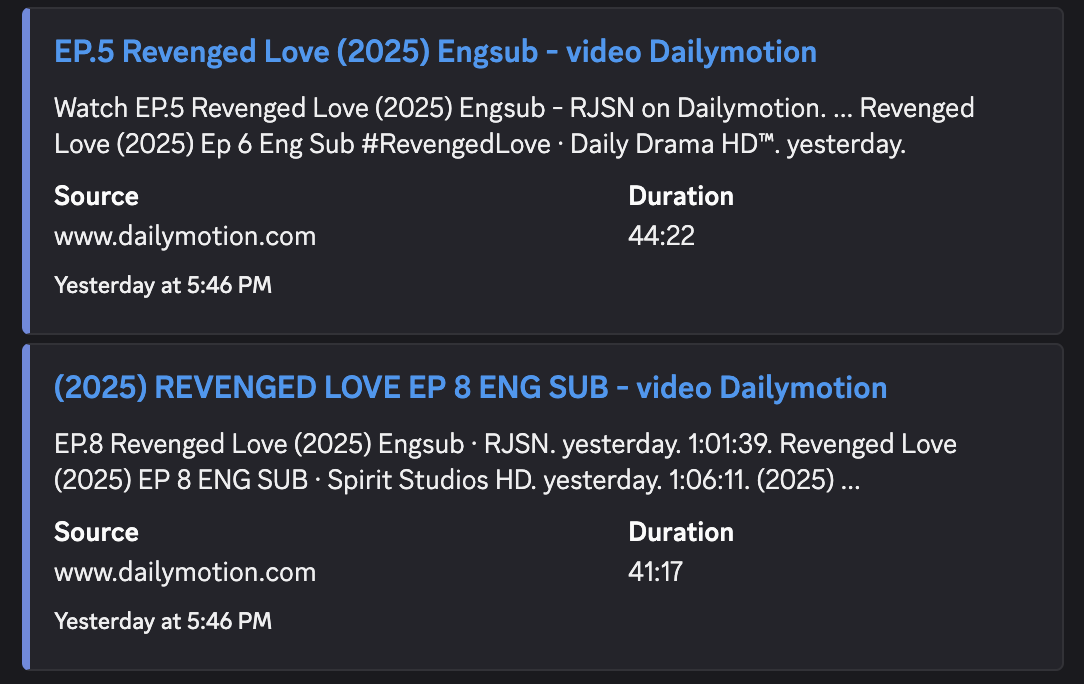
Step 6. Check Discord Results
Click Test, and after execution completes, we can switch to Discord to see the results!
The Ending Thoughts
In this tutorial, we successfully demonstrated how to integrate Scrapeless with Pipedream to build a complete workflow for automatically tracking search results for the keyword "Revenged Love." You learned how to:
- Configure APIs
- Parse HTML
- Use OpenAI Chat to organize data
- Send real-time updates to Discord
Whether you're monitoring brand trends, popular shows, market movements, or building data input channels for your AI Agent, Scrapeless + Pipedream is an indispensable tool combination.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


