
How to Bypass Anti-Bot Detection with Stable Proxies?
Expert Network Defense Engineer
Many websites have started implementing anti bot safeguards as web scraping has become more and more common. These entail complex technology that block automated software from obtaining their information. A website may restrict the quantity of requests your web scraper is allowed to make or stop it completely if it discovers it.
You can find the most popular ways how anti-bot detect you and learn how to bypass it.
Start scrolling now!
What Is an Anti Bot Verification?
Anti-bot verification technology refers to systems and techniques that identify and block automated activities performed by bots. A bot is a software created to carry out online tasks autonomously. Though the name "bot" connotes negativity, not all of them are. As an illustration, Google crawlers are also bots!
Meanwhile, malicious bots account for at least 27.7% of all online traffic worldwide. They carry out criminal activities such as DDoS attacks, spamming, and identity theft. In an effort to safeguard user privacy and enhance user experience, websites aim to steer clear of them, and they could even ban your web scraper.
A variety of techniques, including as HTTP header validation, fingerprinting, and CAPTCHAs, are used by anti-bot filters to discern between real users and automated programs.
Why do websites deploy anti-bot measures?
For website owners, anti-bot technology can help them get rid of most disturbances and challenges:
- Data Protection: Anti-bot measures prevent unauthorized scraping of sensitive or proprietary information.
- Service Reliability: Bots can consume excessive server resources and reduce user experience, and anti-bot systems can mitigate such risks.
- Fraud Prevention: Anti-bot check systems counter activities like fake account creation, ticket scalping, and ad fraud.
- User Privacy: By blocking unauthorized bots, these systems help safeguard user data from being exploited.
How Does Anti-Bot Technology Work?
Anti-bot systems employ a combination of techniques to detect and deter automated activities:
Header Validation
Header validation is a common anti-bot protection technique. It analyzes the headers of incoming HTTP requests to look for anomalies and suspicious patterns. If the system detects anything irregular, it marks the requests as coming from a bot and blocks them.
All browser requests are sent with a lot of data in the headers. If some of these fields are missing, don't have the right values or have an incorrect order, the anti bot check system will block the request.
Behavioral Analysis
Anti-bot verification mechanisms analyze user interactions, such as mouse movements, keystrokes, and browsing patterns. Unnatural or highly repetitive behaviors may signal a bot activity.
IP Address Monitoring
Many websites employ location-based blocking, which includes blocking requests from certain geographic regions, to limit access to their content to select nations. Governments employ this strategy in a similar manner to prohibit some websites within their nation.
The DNS or ISP level is where the geographical ban is applied.
In order to determine the user's location and determine whether to block them, these systems examine the user's IP address. Thus, in order to scrape location-blocked targets, you need an IP address from one of the permitted nations.
You need a proxy server in order to get around location-based blocking policies, and premium proxies usually let you choose the nation in which the server is situated. In this manner, the web scraper's queries will come from the correct place.
Are you tired of continuous web scraping blocks?
Scrapeless Rotate Proxy helps avoid IP bans
Get the Free trial now!
Browser Fingerprinting
Browser fingerprinting is the process of identifying web clients by gathering user device data. It can discern if the request originates from a legitimate user or a scraper by looking at many factors such as installed fonts, browser plugins, screen resolution, and others.
The majority of browser fingerprinting implementation strategies involve client-side technology to gather user data.
The script above gathers user data in order to fingerprint it.
This anti-bot software often anticipates that requests originate from browsers. You need a headless browser to get around it while web scraping; otherwise, you'll be recognized as a bot.
CAPTCHA Challenges
Websites employ challenge-response tests, or CAPTCHAs, to determine if a user is human. Anti-bot solutions employ these techniques to stop scrapers from accessing a website or carrying out certain tasks since humans can easily solve this problem, but bots find it difficult.
A user must complete a certain activity on a page, such as inputting the number displayed in a distorted picture or choosing the group of images, in order to answer a CAPTCHA.
TLS Fingerprinting
Analyzing the parameters that are transferred during a TLS handshake is known as TLS fingerprinting. The anti bot verification system identifies the request as coming from a bot and stops it if these don't match the ones that should be there.
Request Validation
Anti-bot verification systems validate HTTP requests for authenticity. Suspicious headers, invalid user-agent strings, or missing cookies can indicate the bot traffic.
5 Methods to Avoid Anti-Bots Detection
It might not be simple to get around an anti bot check system, but there are certain tricks you can try. The list of strategies to think about is as follows:
1. Scrapeless rotate proxies
Scrapeless provides premium global clean IP proxy services, specializing in dynamic residential IPv4 proxies.
With over 70 million IPs in 195 countries, the Scrapeless residential proxy network offers comprehensive global proxy support to drive your business growth.
We support a wide range of use cases including web scraping, market research, SEO monitoring, price comparison, social media marketing, ad verification, and brand protection, enabling you to seamlessly run your business in global markets.
How to get your special proxies? Please follow my steps:
- Step 1. Sign in Scrapeless.
- Step 2. Click the "Proxies", and create a channel.
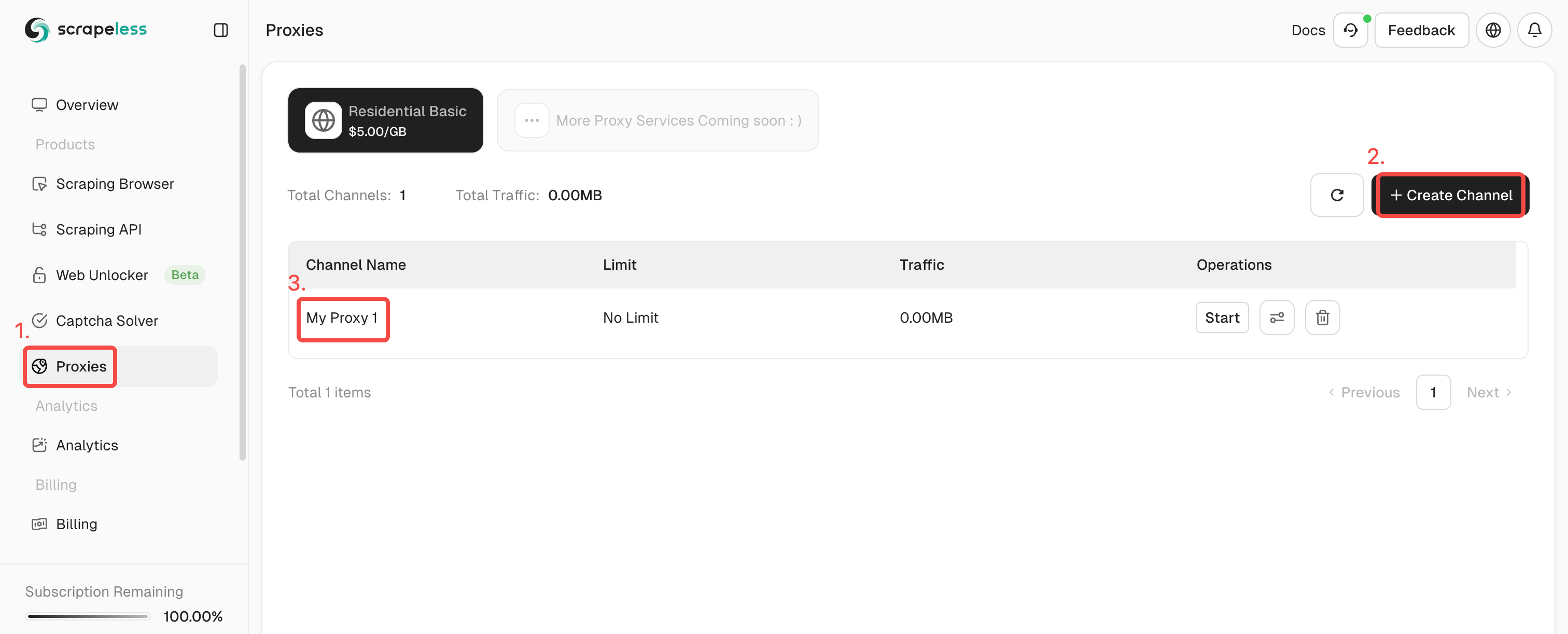
- Step 3. Fill in the information you need in the left operation box. Then click "Generate". After a while, you can see the rotate proxy we generated for you on the right. Now just click "Copy" to use it.
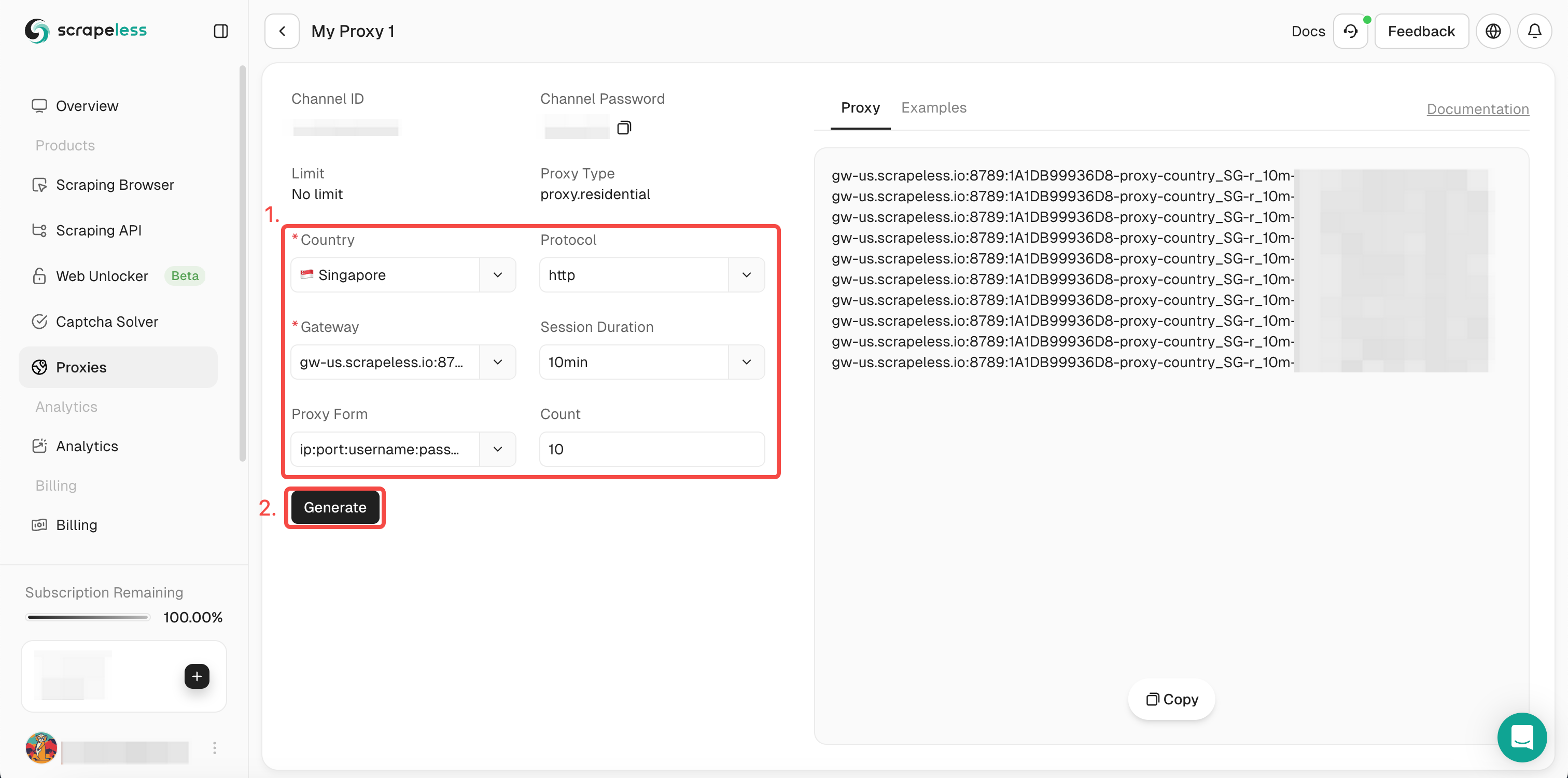
Or you can just integrate our proxy codes into your project:
- Code:
C
curl --proxy host:port --proxy-user username:password API_URL- Browser:
- Selenium
Python
from seleniumbase import Driver
proxy = 'username:password@gw-us.scrapeless.com:8789'
driver = Driver(browser="chrome", headless=False, proxy=proxy)
driver.get("API_URL")
driver.quit()- Puppeteer
JavaScript
const puppeteer =require('puppeteer');
(async() => {
const proxyUrl = 'http://gw-us.scrapeless.com:8789';
const username = 'username';
const password = 'password';
const browser = await puppeteer.launch({
args: [`--proxy-server=${proxyUrl}`],
headless: false
});
const page = await browser.newPage();
await page.authenticate({ username, password });
await page.goto('API_URL');
await browser.close();
})();2. Please abide by robots.txt
This file serves as a standard for websites to indicate whether files or pages are accessible to or inaccessible to bots. Web scrapers can prevent anti-bot measures from being activated by adhering to the specified criteria. Find out more about reading robot.txt files for web scraping purposes.
Restrict the number of queries made from the same IP address: Web scrapers sometimes make many requests to a website quickly. You could consider minimizing the amount of queries that come from the same IP address because this behavior might set off anti-bot systems. Examine the methods for getting around the rate restriction while using web scraping.
3. Adapt your User-Agent
The HTTP header for User-Agent contains a string that indicates the browser and operating system from which the request originated. The requests appear to be from a regular user since this header has been modified. View the list of most popular User Agents for web scraping.
4. Use a browser without a head
Without a graphical user interface, a headless browser is still controllable. By using a tool like this, you may prevent your scraper from being identified as a bot by making it behave like a human user—that is, by scrolling. Learn more about headless browsers and which ones are suitable for web scraping.
5. Streamline the procedure with an online scraping API
By using straightforward API calls, web scraping APIs enable users to scrape websites without getting detected by anti-bot systems. Because of this, web scraping is quick, simple, and effective.
Try Scrapeless scraping API for free right now to see what the most potent web scraping API available has to offer.
In Summary
In this tutorial, you have discovered a lot about anti bot detection. How to bypass anti-bot detection for you is just a piece of cake.
Which one is the best method to avoid blocking?
With Scrapeless, an online scraping tool with a sophisticated CAPTCHA solver, built-in IP rotation, headless browser capability, and web unlocker, you can avoid them all!
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


