
How to Bypass CAPTCHA in Web Scraping Using Python
Advanced Data Extraction Specialist
Intro
Few people know the full form of CAPTCHA. Actually, the abbreviation CAPTCHA stands for "Completely Automated Public Turing Test to Tell Computers and Humans Apart".
CAPTCHAs are designed to identify questionable users and contemporary bots by presenting difficult-to-solve problems to computers, which aids website owners in preventing scraping and crawling.Due to the large number of third-party libraries that can read text, interact with HTML forms, and scrape sophisticated HTML structures, Python is a popular choice for web scraping. So, in this article we will explain how to get over the CAPTCHA problems during web scraping using Python.
In addition to discussing practical anti-CAPTCHA solutions to incorporate into your data collection processes, we'll cover the various CAPTCHA kinds that may be found in today's online environment.
reCAPTCHA
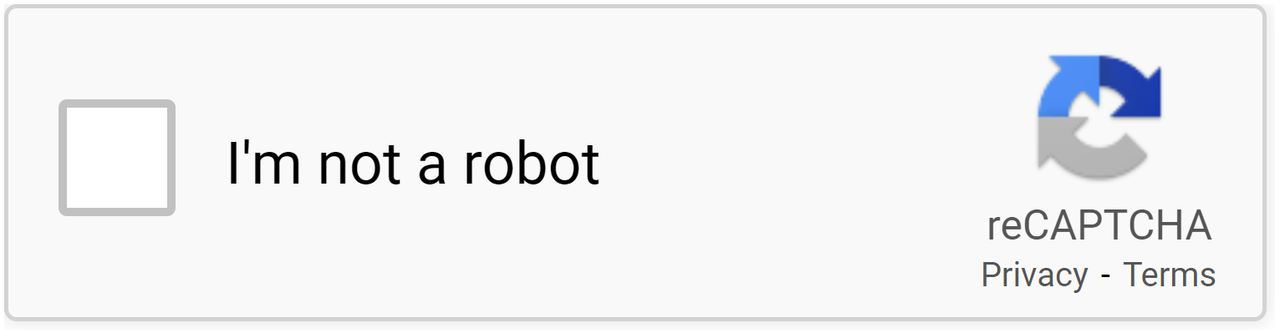
This is a Google-developed free CAPTCHA solution that provides website security, which employs cutting-edge methods to identify bot-like behavior, much like hCAPTCHA. Google reCAPTCHA can now identify human users without any input from the user. It only uses the user's past experiences with other websites as a basis for recognition. Google Search, Maps, Play, Shopping, and many more services and products employ reCAPTCHA extensively.
ImageToText CAPTCHA

Typically, ImageToText CAPTCHA is a jumble of unrelated letters and characters displayed in an illegible style, with characters that have been rotated, resized, and warped in different ways.
Audio CAPTCHA
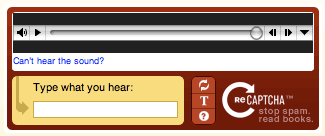
Also called a "Sound-based CAPTCHA," it requires users to input a series of letters or numbers through audio recordings. To make things more challenging, the audio is frequently complemented by background noise.
hCAPTCHA
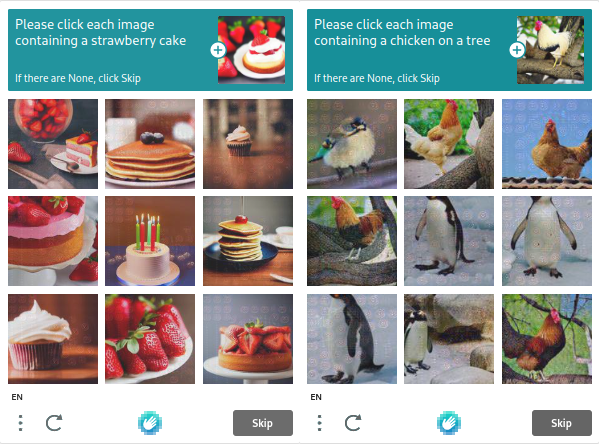
Intuition Machines is the owner of hCaptcha, which values user privacy and doesn't gather unnecessary data. As a result, its popularity is rising. The standard bot evaluation tasks, such as box-checking and picture recognition, are carried out using hCaptcha. The tests in hCaptcha are more complicated than those in reCAPTCHA, but you may change the parameters to make them harder or easier.
Web scraping: What is it?
The technique of obtaining data from websites is known as web scraping. It entails the use of automated devices to extract data from websites, sometimes referred to as web scrapers or crawlers. These programs move through a website's hierarchy, get the HTML code, and then use predefined patterns or guidelines to extract the needed data.
There are several uses for web scraping, including:
- Competitor analysis: keeping an eye on rivals' internet presence and tactics
- Data collection: Compiling text, picture, and other media content from websites
- Price monitoring: keeping tabs on and contrasting product costs from various internet merchants
- Material Aggregation: Creating a consolidated database or website by gathering material from many sources
- Market research: To comprehend market dynamics, trends, consumer feedback, and other pertinent data are analyzed.
It is noteworthy that web scraping, albeit a potent instrument for data gathering, must to be executed in an ethical and lawful manner. Scraping of private or sensitive information may be against the law, and several websites have explicit prohibitions against it in their terms of service.
When participating in online scraping activities, be sure that you are always in accordance with the conditions of use of the website and any applicable laws.
Example of Web Scraping
Web scraping is the process of obtaining data from websites, usually automatically with the use of tools or programming scripts. This is a basic example that makes use of the BeautifulSoup package, which is a well-liked option for web scraping activities, and Python.
Assume for the moment that we wish to retrieve the names of the most recent articles from an imaginary news source. The structure of the HTML may resemble this:
language
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Sample News Website</title>
</head>
<body>
<div class="article">
<h2 class="title">Breaking News 1</h2>
<p class="content">This is the content of the first article.</p>
</div>
<div class="article">
<h2 class="title">Latest Update: Important Event</h2>
<p class="content">Details about the important event.</p>
</div>
</body>
</html>Let's now utilize BeautifulSoup and Python to scrape the headlines of these articles:
language
import requests
from bs4 import BeautifulSoup
# URL of the sample news website
url = 'https://www.example-news-website.com'
# Send a GET request to the website
response = requests.get(url)
# Parse the HTML content of the page
soup = BeautifulSoup(response.text, 'html.parser')
# Find all div elements with the class 'article' and extract the titles
article_divs = soup.find_all('div', class_='article')
# Extract and print the titles
for article_div in article_divs:
title = article_div.find('h2', class_='title').text
print(f"Title: {title}")To obtain the HTML content, we use the requests library to perform a GET request to the website. Next, BeautifulSoup is used to parse the HTML content ('html.parser' is used in this case). To discover every div element that has the class article, we use find_all. We locate the h2 element with the class title for every article and retrieve its text content.
How to Use Scrapeless to Bypass CAPTCHA While Web Scraping
Fed up with constant web scraping blocks and CAPTCHAs?
Introducing Scrapeless - the ultimate all-in-one web scraping solution!
Unlock the full potential of your data extraction with our powerful suite of tools:
Best CAPTCHA Solver
Automatically solve advanced CAPTCHAs, keeping your scraping seamless and uninterrupted.
Experience the difference - try it for free!
Concluding remarks
One of the most frequent obstacles to public data collection is CAPTCHAs, thus it's critical to discover a dependable and superior method for getting over them. This article covered the various CAPTCHA types that are currently available and provided a few anti-CAPTCHA solutions you can try using in your Web Scraping activities.
Please use our Official Website to get in touch with us if you have any queries regarding this subject or would want more information about Scrapeless' best ways to get around CAPTCHAs, such as Web Unlocker or CAPTCHA Solver.
FAQ
How can CAPTCHAs be avoided While Web Scraping?
When acquiring web data, there are multiple techniques to get around CAPTCHA. A helpful trick is to fine-tune your scraper's fingerprint by modifying User-Agent headers. Furthermore, you may want to think about employing automatic programs like Web Unlocker, which may help you tackle CAPTCHA problems.
Why do website owners use CAPTCHAs to Prevent Scraping?
CAPTCHAs are used on websites to distinguish between dangerous bots and genuine visitors. They serve as a safety measure to prevent hostile or potentially destructive bot behavior, such as spamming or fraudulent transactions.
Is there a method to bypass CAPTCHA While Web Scraping?
Yes, there are a variety of services available on the market that are made especially to bypass a CAPTCHA. Examples include Web Unlocker and CAPTCHA solver. For example, Scrapeless's tool selects the appropriate set of headers, cookies, browser properties, etc. to appear as a legitimate user and eventually get past all of the target website barriers.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


