
How to Build an Intelligent B2B Lead Generation Workflow with n8n and Scrapeless
Advanced Data Extraction Specialist
Transform your sales prospecting with an automated workflow that finds, qualifies, and enriches B2B leads using Google Search, Crawler, and Claude AI analysis. This tutorial shows you how to create a powerful lead generation system using n8n and Scrapeless.
What We'll Build
In this tutorial, we'll create an intelligent B2B lead generation workflow that:
- Triggers automatically on schedule or manually
- Searches Google for companies in your target market using Scrapeless
- Processes each company URL individually with Item Lists
- Crawls company websites to extract detailed information
- Uses Claude AI to qualify and structure lead data
- Stores qualified leads in Google Sheets
- Sends notifications to Discord (adaptable to Slack, email, etc.)
Prerequisites
- An n8n instance (cloud or self-hosted)
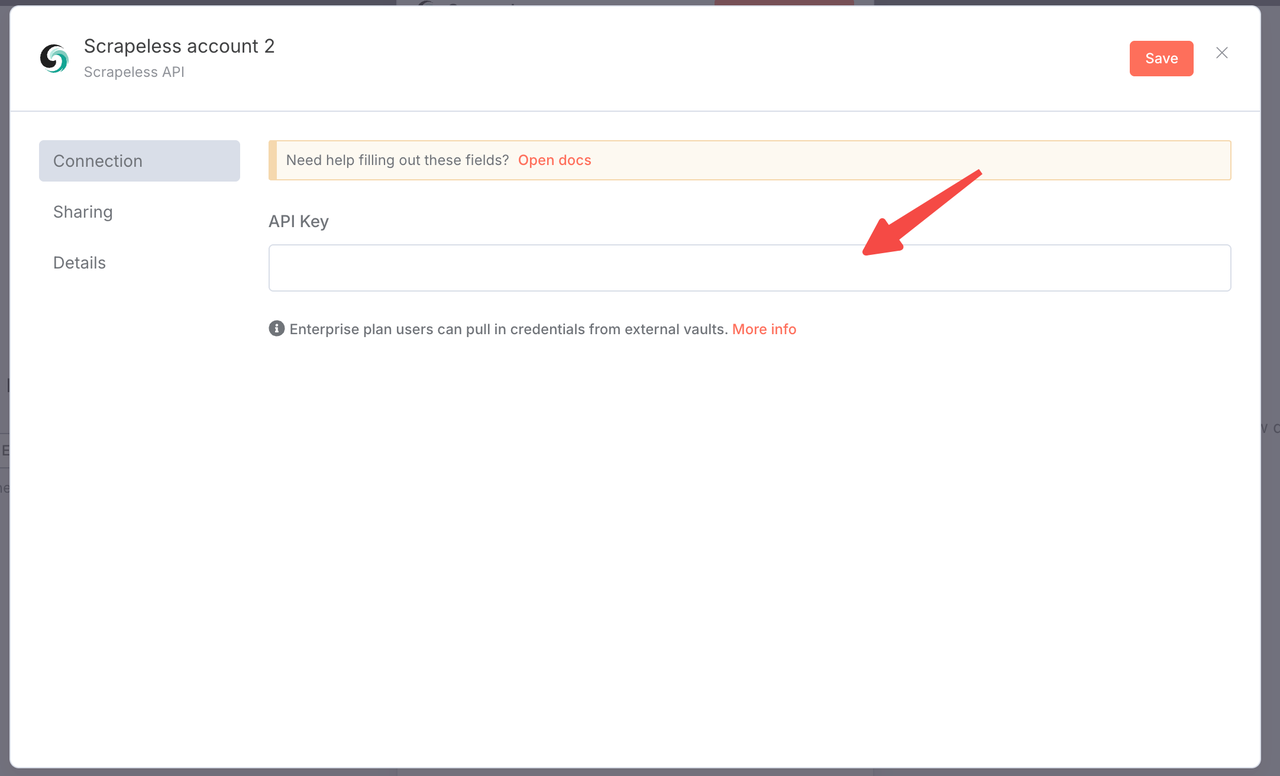
- A Scrapeless API key (get one at scrapeless.com)
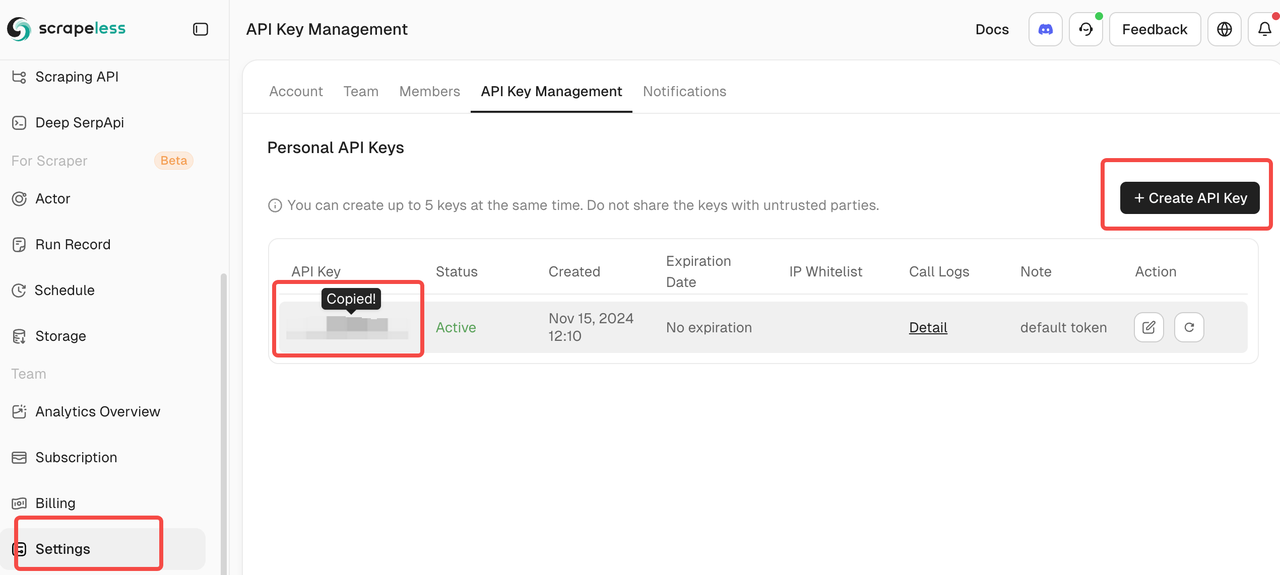
You only need to log in to the Scrapeless Dashboard and follow the picture below to get your API KEY. Scrapeless will give you a free trial quota.
- Claude API key from Anthropic
- Google Sheets access
- Discord webhook URL (or your preferred notification service)
- Basic understanding of n8n workflows
Complete Workflow Overview
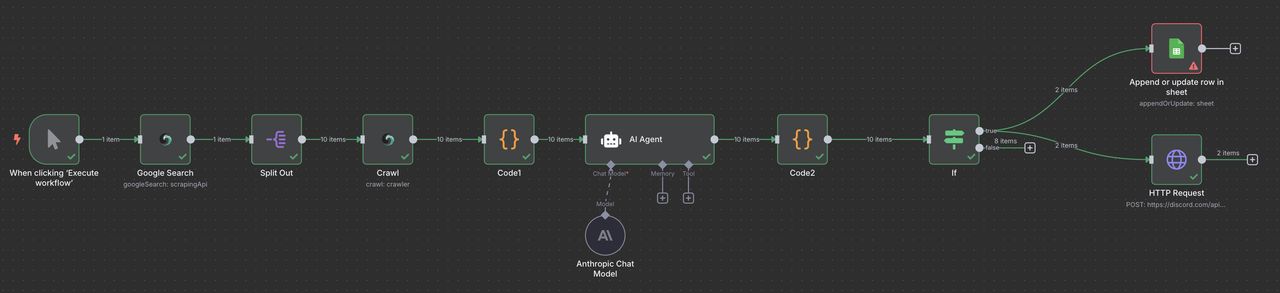
Your final n8n workflow will look like this:
Manual Trigger → Scrapeless Google Search → Item Lists → Scrapeless Crawler → Code (Data Processing) → Claude AI → Code (Response Parser) → Filter → Google Sheets or/and Discord Webhook
Step 1: Setting Up the Manual Trigger
We'll start with a manual trigger for testing, then add scheduling later.
- Create a new workflow in n8n
- Add a Manual Trigger node as your starting point
- This allows you to test the workflow before automating it
Why start manual?
- Test and debug each step
- Verify data quality before automation
- Adjust parameters based on initial results
Step 2: Adding Scrapeless Google Search
Now we'll add the Scrapeless Google Search node to find target companies.
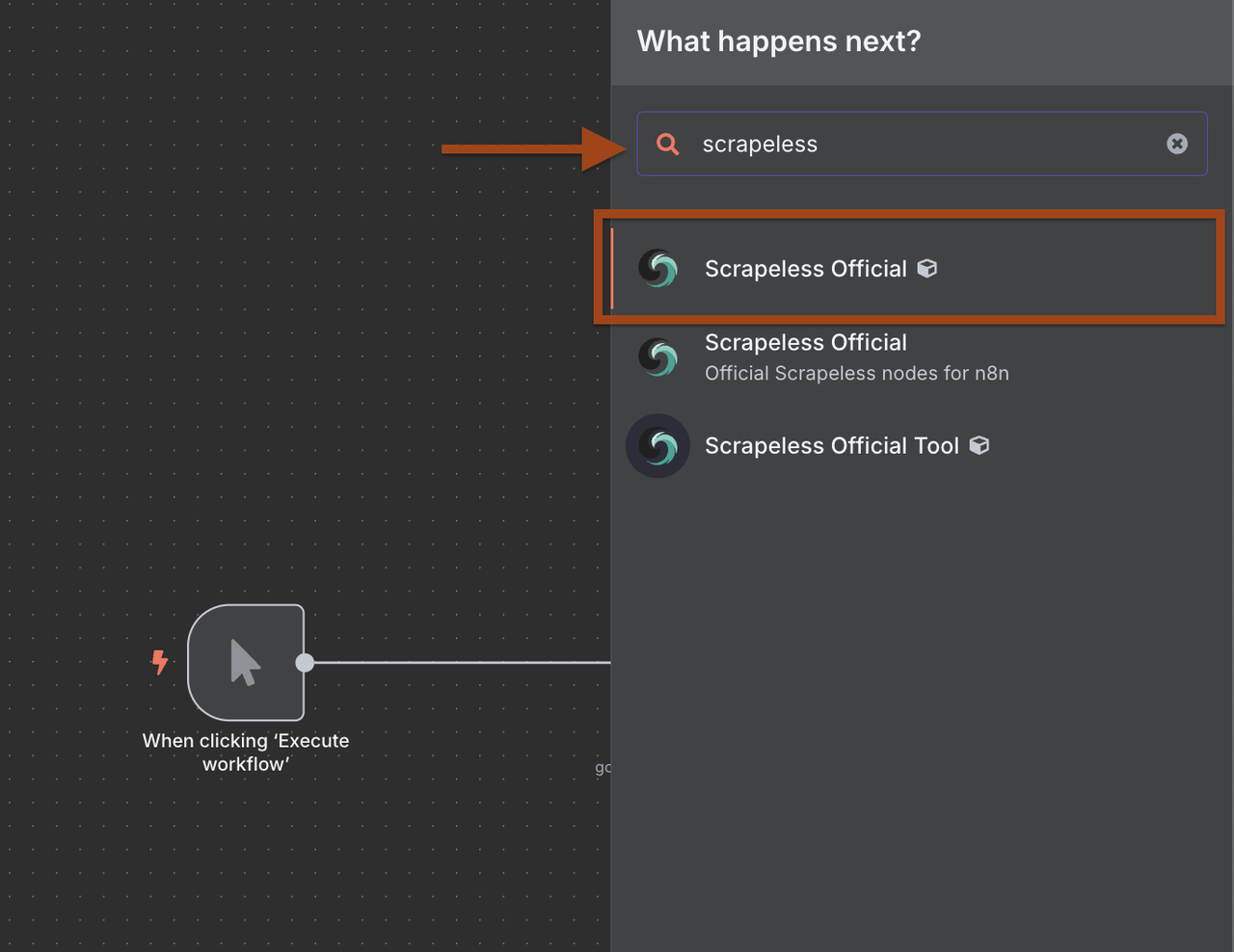
- Click + to add a new node after the trigger
- Search for Scrapeless in the node library
- Select Scrapeless and choose Search Google operation
1. Why Use Scrapeless with n8n?
Integrating Scrapeless with n8n lets you create advanced, resilient web scrapers without writing code.
Benefits include:
- Access Deep SerpApi to fetch and extract Google SERP data with a single request.
- Use Universal Scraping API to bypass restrictions and access any website.
- Use Crawler Scrape to perform detailed scraping of individual pages.
- Use Crawler Crawl for recursive crawling and retrieving data from all linked pages.
These features allow you to build end-to-end data flows that link Scrapeless with 350+ services supported by n8n, including Google Sheets, Airtable, Notion, Slack, and more.
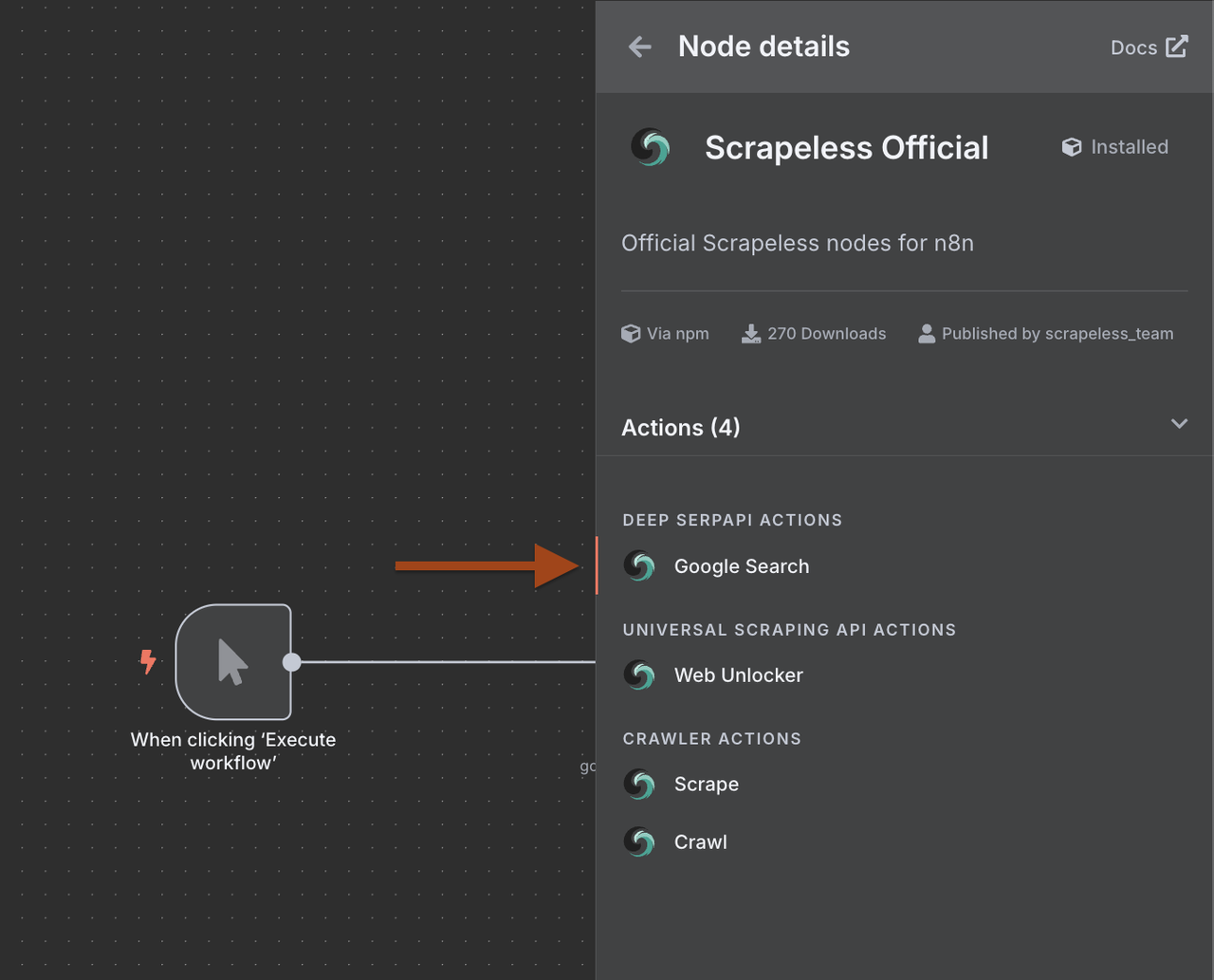
2. Configuring the Google Search Node
Next, we need to configure the Scrapeless Google Search Node
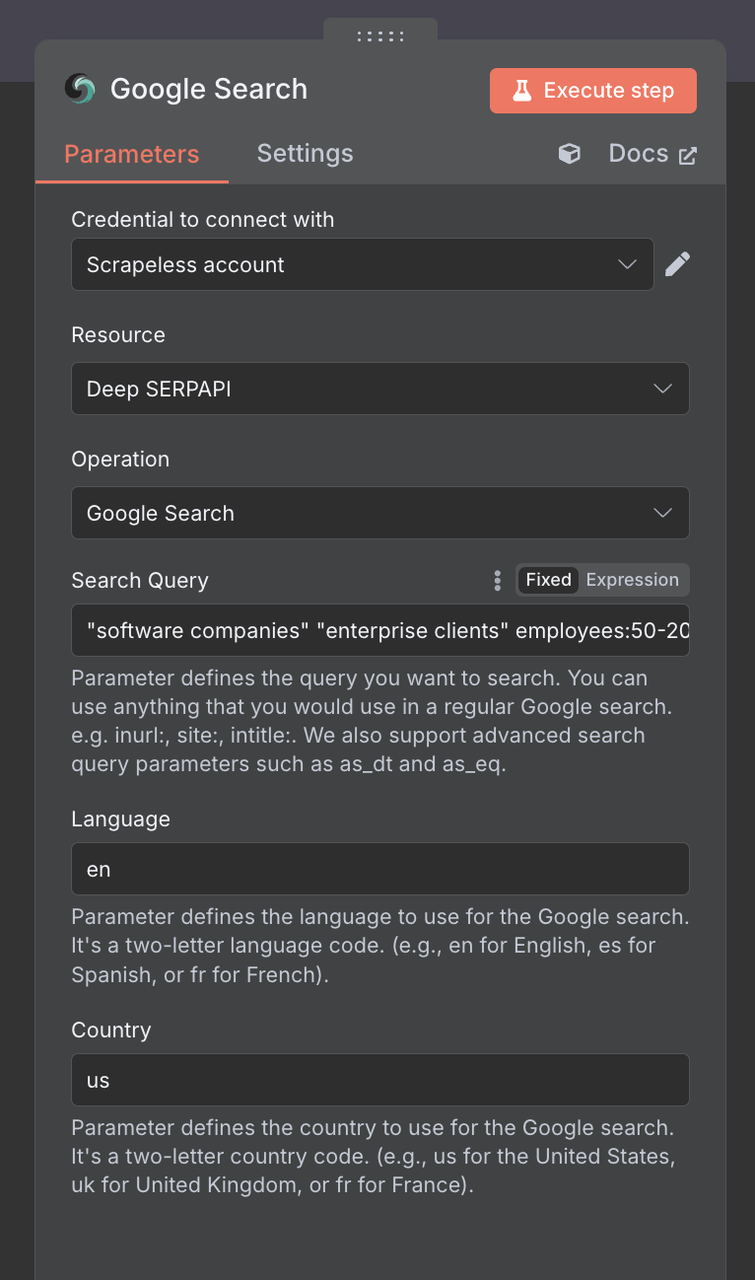
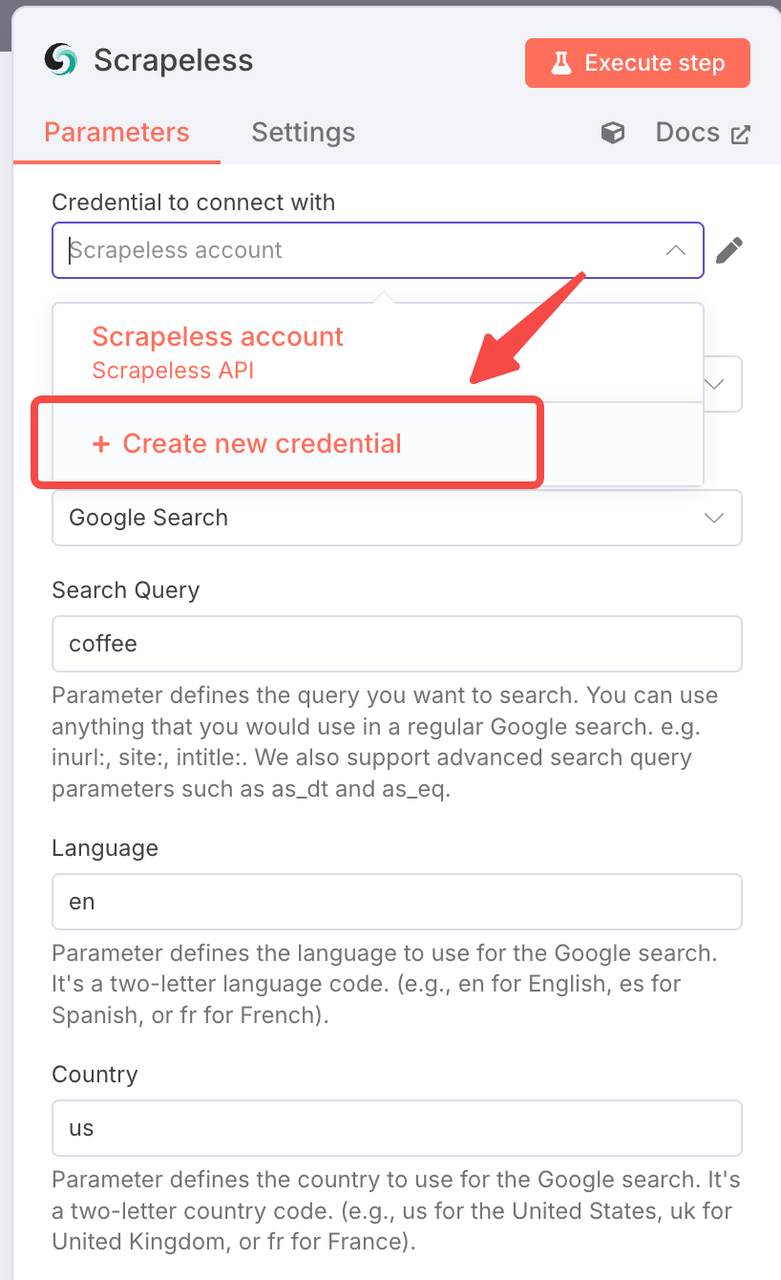
Connection Setup:
- Create a connection with your Scrapeless API key
- Click "Add" and enter your credentials
Search Parameters:
Search Query: Use B2B-focused search terms:
"software companies" "enterprise clients" employees:50-200
"marketing agencies" "B2B services" "digital transformation"
"SaaS startups" "Series A" "venture backed"
"manufacturing companies" "digital solutions" ISOCountry: US (or your target market)
Language: en
Pro B2B Search Strategies:
- Company size targeting: employees:50-200, "mid-market"
- Funding stage: "Series A", "venture backed", "bootstrapped"
- Industry specific: "fintech", "healthtech", "edtech"
- Geographic: "New York", "San Francisco", "London"
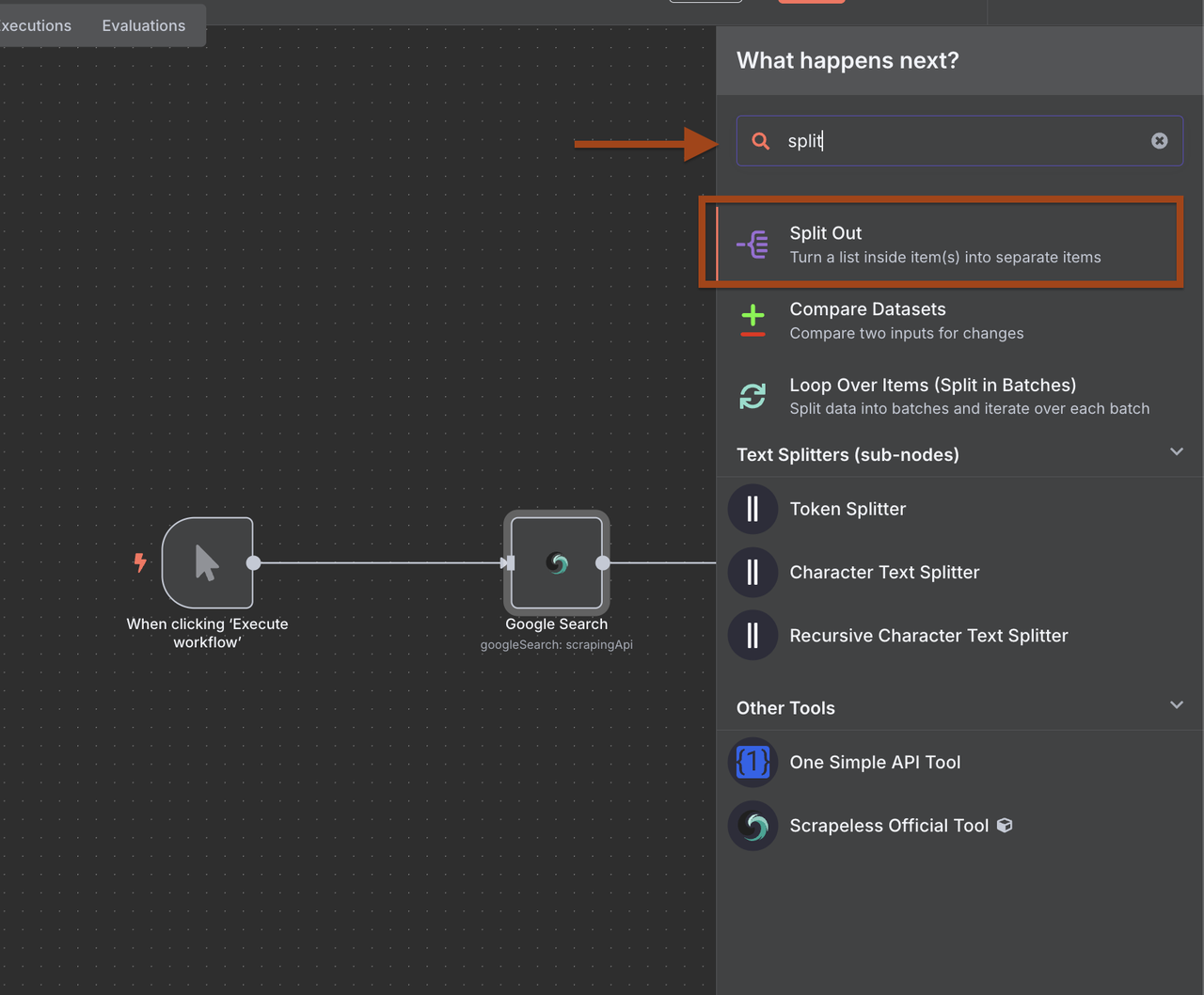
Step 3: Processing Results with Item Lists
The Google Search returns an array of results. We need to process each company individually.
- Add an Item Lists node after Google Search
- This will split the search results into individual items
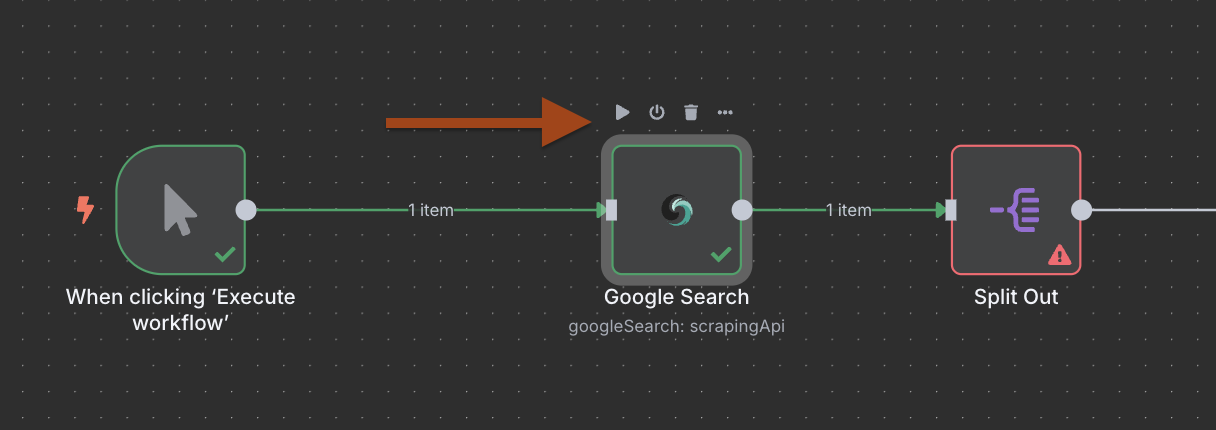
Tips : Run the Google Search Node
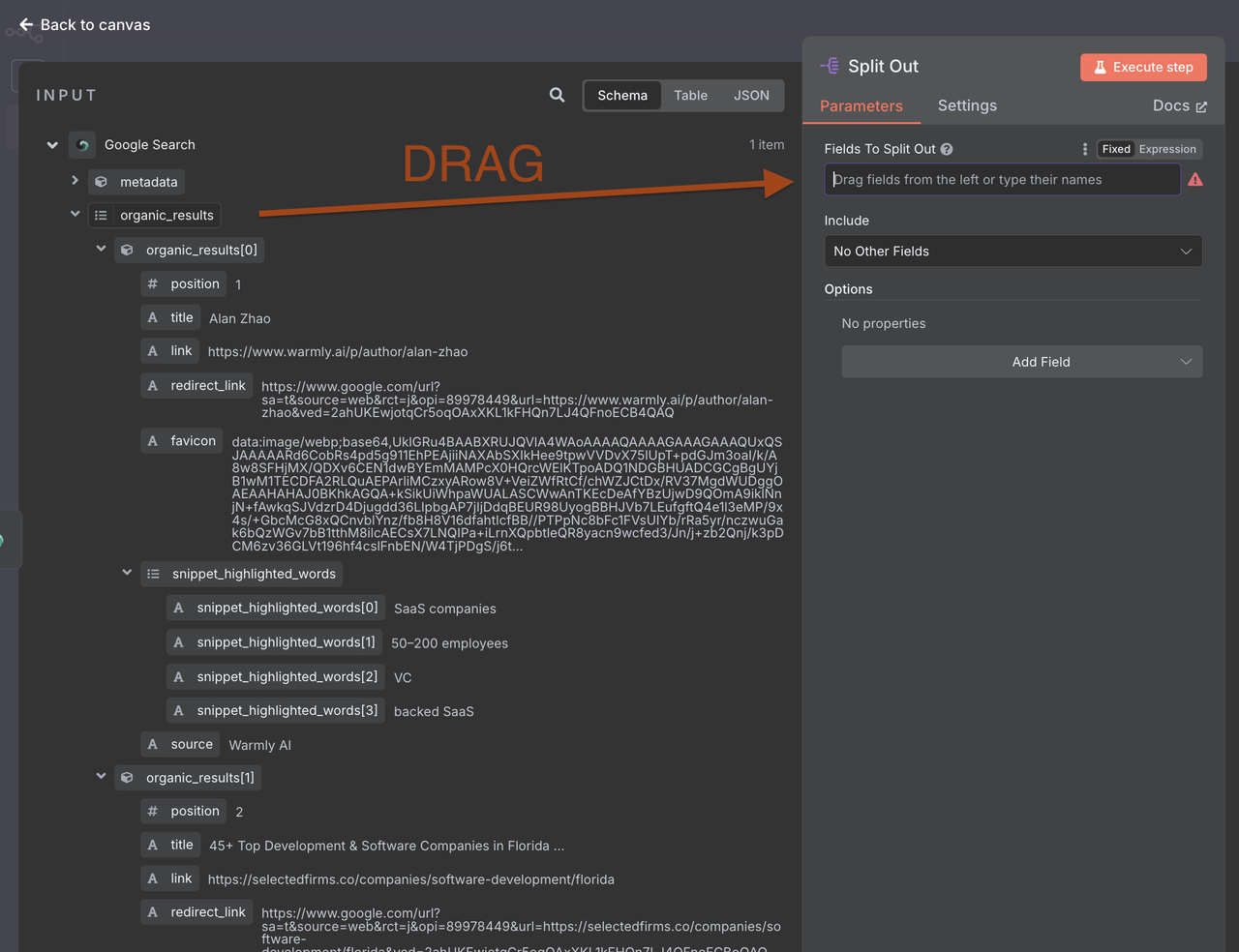
1. Item Lists Configuration:
- Operation: "Split Out Items"
- Field to Split Out: organic_results - Link
- Include Binary Data: false
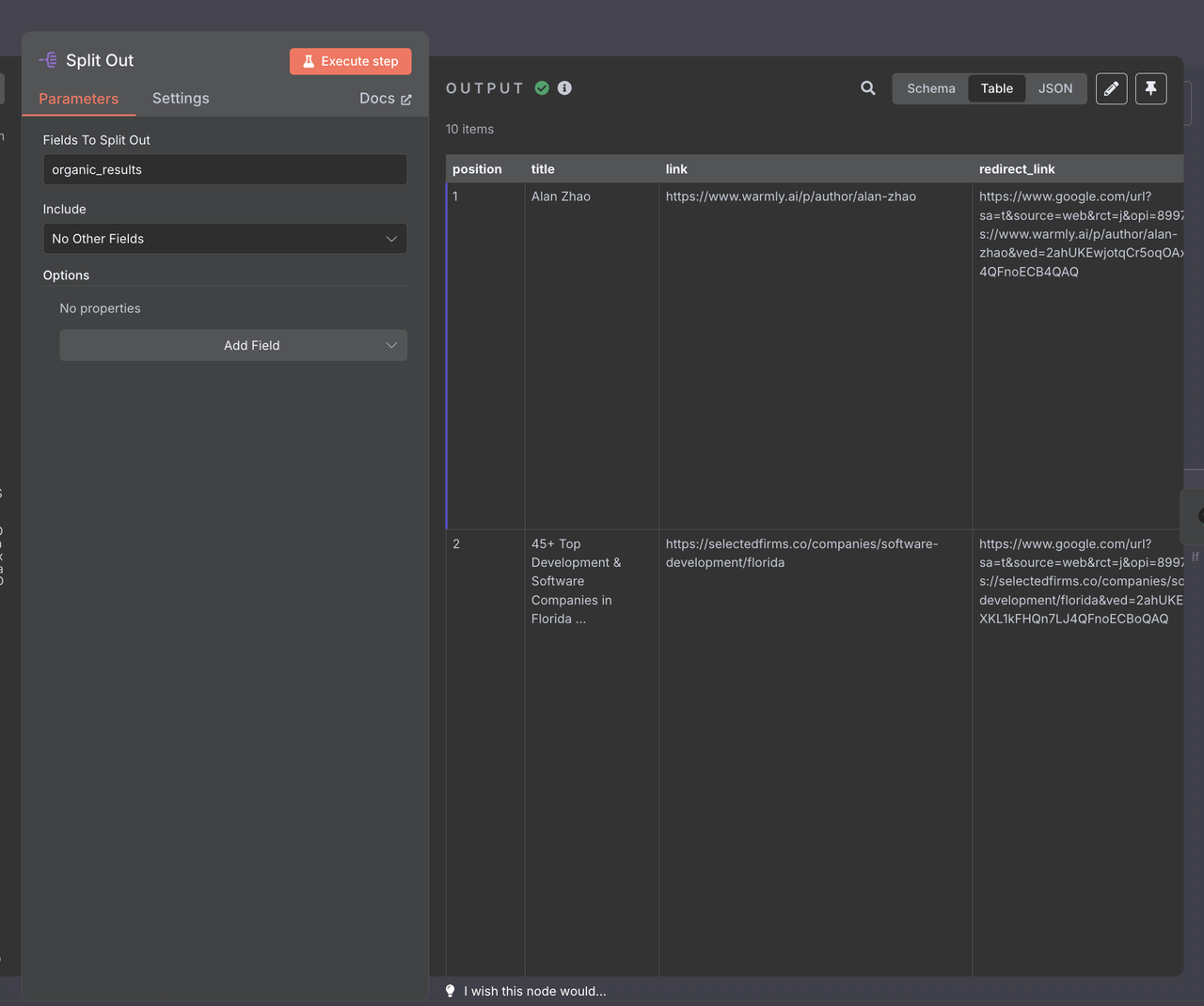
This creates a separate execution branch for each search result, allowing parallel processing.
Step 4: Adding Scrapeless Crawler
Now we'll crawl each company website to extract detailed information.
- Add another Scrapeless node
- Select Crawl operation (not WebUnlocker)
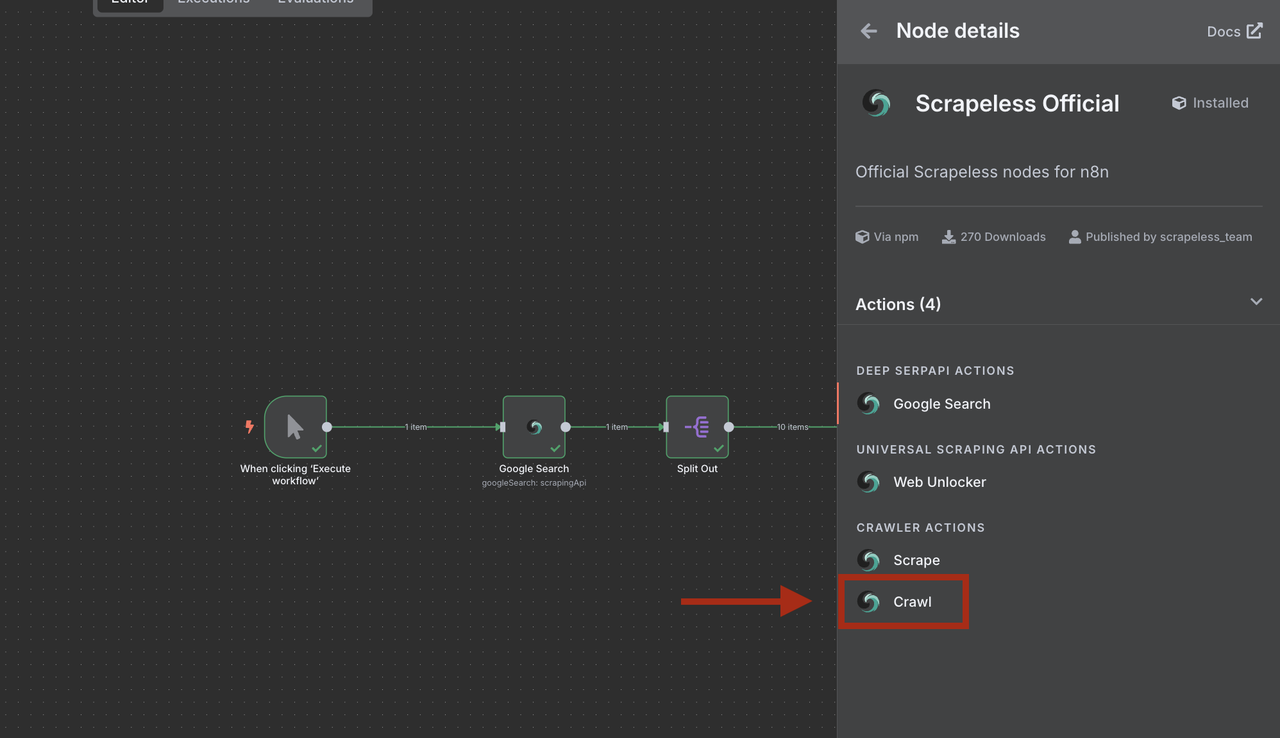
Use Crawler Crawl for recursive crawling and retrieving data from all linked pages.
- Configure for company data extraction
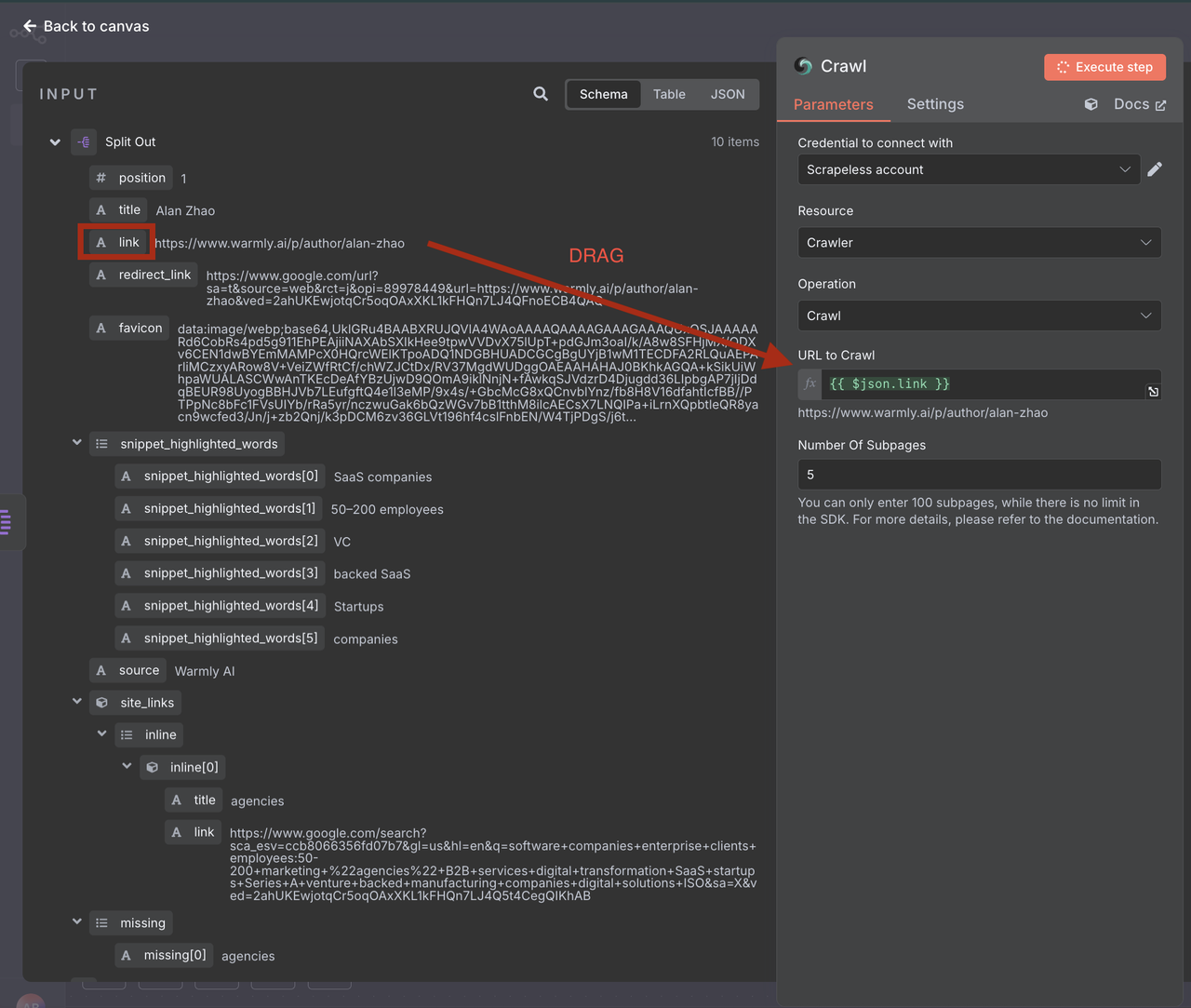
1. Crawler Configuration
- Connection: Use the same Scrapeless connection
- URL: {{ $json.link }}
- Crawl Depth: 2 (homepage + one level deep)
- Max Pages: 5 (limit for faster processing)
- Include Patterns: about|contact|team|company|services
- Exclude Patterns: blog|news|careers|privacy|terms
- Format: markdown (easier for AI processing)
2. Why use Crawler vs Web Unlocker?
- Crawler gets multiple pages and structured data
- Better for B2B where contact info might be on /about or /contact pages
- More comprehensive company information
- Follows site structure intelligently
Step 5: Data Processing with Code Node
Before sending the crawled data to Claude AI, we need to clean and structure it properly. The Scrapeless Crawler returns data in a specific format that requires careful parsing.
- Add a Code node after the Scrapeless Crawler
- Use JavaScript to parse and clean the raw crawl data
- This ensures consistent data quality for AI analysis
1. Understanding Scrapeless Crawler Data Structure
The Scrapeless Crawler returns data as an array of objects, not a single object:
[
{
"markdown": "# Company Homepage\n\nWelcome to our company...",
"metadata": {
"title": "Company Name - Homepage",
"description": "Company description",
"sourceURL": "https://company.com"
}
}
]2. Code Node Configuration
console.log("=== PROCESSING SCRAPELESS CRAWLER DATA ===");
try {
// Data arrives as an array
const crawlerDataArray = $json;
console.log("Data type:", typeof crawlerDataArray);
console.log("Is array:", Array.isArray(crawlerDataArray));
console.log("Array length:", crawlerDataArray?.length || 0);
// Check if array is empty
if (!Array.isArray(crawlerDataArray) || crawlerDataArray.length === 0) {
console.log("❌ Empty or invalid crawler data");
return {
url: "unknown",
company_name: "No Data",
content: "",
error: "Empty crawler response",
processing_failed: true,
skip_reason: "No data returned from crawler"
};
}
// Take the first element from the array
const crawlerResponse = crawlerDataArray[0];
// Markdown content extraction
const markdownContent = crawlerResponse?.markdown || "";
// Metadata extraction (if available)
const metadata = crawlerResponse?.metadata || {};
// Basic information
const sourceURL = metadata.sourceURL || metadata.url || extractURLFromContent(markdownContent);
const companyName = metadata.title || metadata.ogTitle || extractCompanyFromContent(markdownContent);
const description = metadata.description || metadata.ogDescription || "";
console.log(`Processing: ${companyName}`);
console.log(`URL: ${sourceURL}`);
console.log(`Content length: ${markdownContent.length} characters`);
// Content quality verification
if (!markdownContent || markdownContent.length < 100) {
return {
url: sourceURL,
company_name: companyName,
content: "",
error: "Insufficient content from crawler",
processing_failed: true,
raw_content_length: markdownContent.length,
skip_reason: "Content too short or empty"
};
}
// Cleaning and structuring markdown content
let cleanedContent = cleanMarkdownContent(markdownContent);
// Contact information extraction
const contactInfo = extractContactInformation(cleanedContent);
// Important business sections extraction
const businessSections = extractBusinessSections(cleanedContent);
// Building content for Claude AI
const contentForAI = buildContentForAI({
companyName,
sourceURL,
description,
businessSections,
contactInfo,
cleanedContent
});
// Content quality metrics
const contentQuality = assessContentQuality(cleanedContent, contactInfo);
const result = {
url: sourceURL,
company_name: companyName,
content: contentForAI,
raw_content_length: markdownContent.length,
processed_content_length: contentForAI.length,
extracted_emails: contactInfo.emails,
extracted_phones: contactInfo.phones,
content_quality: contentQuality,
metadata_info: {
has_title: !!metadata.title,
has_description: !!metadata.description,
site_name: metadata.ogSiteName || "",
page_title: metadata.title || ""
},
processing_timestamp: new Date().toISOString(),
processing_status: "SUCCESS"
};
console.log(`✅ Successfully processed ${companyName}`);
return result;
} catch (error) {
console.error("❌ Error processing crawler data:", error);
return {
url: "unknown",
company_name: "Processing Error",
content: "",
error: error.message,
processing_failed: true,
processing_timestamp: new Date().toISOString()
};
}
// ========== UTILITY FUNCTIONS ==========
function extractURLFromContent(content) {
// Try to extract URL from markdown content
const urlMatch = content.match(/https?:\/\/[^\s\)]+/);
return urlMatch ? urlMatch[0] : "unknown";
}
function extractCompanyFromContent(content) {
// Try to extract company name from content
const titleMatch = content.match(/^#\s+(.+)$/m);
if (titleMatch) return titleMatch[1];
// Search for emails to extract domain
const emailMatch = content.match(/@([a-zA-Z0-9.-]+\.[a-zA-Z]{2,})/);
if (emailMatch) {
const domain = emailMatch[1].replace('www.', '');
return domain.split('.')[0].charAt(0).toUpperCase() + domain.split('.')[0].slice(1);
}
return "Unknown Company";
}
function cleanMarkdownContent(markdown) {
return markdown
// Remove navigation elements
.replace(/^\[Skip to content\].*$/gmi, '')
.replace(/^\[.*\]\(#.*\)$/gmi, '')
// Remove markdown links but keep text
.replace(/\[([^\]]+)\]\([^)]+\)/g, '$1')
// Remove images and base64
.replace(/!\[([^\]]*)\]\([^)]*\)/g, '')
.replace(/<Base64-Image-Removed>/g, '')
// Remove cookie/privacy mentions
.replace(/.*?(cookie|privacy policy|terms of service).*?\n/gi, '')
// Clean multiple spaces
.replace(/\s+/g, ' ')
// Remove multiple empty lines
.replace(/\n\s*\n\s*\n/g, '\n\n')
.trim();
}
function extractContactInformation(content) {
// Regex for emails
const emailRegex = /[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}/g;
// Regex for phones (with international support)
const phoneRegex = /(?:\+\d{1,3}\s?)?\d{3}\s?\d{3}\s?\d{3,4}|\(\d{3}\)\s?\d{3}-?\d{4}/g;
const emails = [...new Set((content.match(emailRegex) || [])
.filter(email => !email.includes('example.com'))
.slice(0, 3))];
const phones = [...new Set((content.match(phoneRegex) || [])
.filter(phone => phone.replace(/\D/g, '').length >= 9)
.slice(0, 2))];
return { emails, phones };
}
function extractBusinessSections(content) {
const sections = {};
// Search for important sections
const lines = content.split('\n');
let currentSection = '';
let currentContent = '';
for (let i = 0; i < lines.length; i++) {
const line = lines[i].trim();
// Header detection
if (line.startsWith('#')) {
// Save previous section
if (currentSection && currentContent) {
sections[currentSection] = currentContent.trim().substring(0, 500);
}
// New section
const title = line.replace(/^#+\s*/, '').toLowerCase();
if (title.includes('about') || title.includes('service') ||
title.includes('contact') || title.includes('company')) {
currentSection = title.includes('about') ? 'about' :
title.includes('service') ? 'services' :
title.includes('contact') ? 'contact' : 'company';
currentContent = '';
} else {
currentSection = '';
}
} else if (currentSection && line) {
currentContent += line + '\n';
}
}
// Save last section
if (currentSection && currentContent) {
sections[currentSection] = currentContent.trim().substring(0, 500);
}
return sections;
}
function buildContentForAI({ companyName, sourceURL, description, businessSections, contactInfo, cleanedContent }) {
let aiContent = `COMPANY ANALYSIS REQUEST\n\n`;
aiContent += `Company: ${companyName}\n`;
aiContent += `Website: ${sourceURL}\n`;
if (description) {
aiContent += `Description: ${description}\n`;
}
aiContent += `\nCONTACT INFORMATION:\n`;
if (contactInfo.emails.length > 0) {
aiContent += `Emails: ${contactInfo.emails.join(', ')}\n`;
}
if (contactInfo.phones.length > 0) {
aiContent += `Phones: ${contactInfo.phones.join(', ')}\n`;
}
aiContent += `\nBUSINESS SECTIONS:\n`;
for (const [section, content] of Object.entries(businessSections)) {
if (content) {
aiContent += `\n${section.toUpperCase()}:\n${content}\n`;
}
}
// Add main content (limited)
aiContent += `\nFULL CONTENT PREVIEW:\n`;
aiContent += cleanedContent.substring(0, 2000);
// Final limitation for Claude API
return aiContent.substring(0, 6000);
}
function assessContentQuality(content, contactInfo) {
const wordCount = content.split(/\s+/).length;
return {
word_count: wordCount,
has_contact_info: contactInfo.emails.length > 0 || contactInfo.phones.length > 0,
has_about_section: /about|company|who we are/gi.test(content),
has_services_section: /services|products|solutions/gi.test(content),
has_team_section: /team|leadership|staff/gi.test(content),
content_richness_score: Math.min(10, Math.floor(wordCount / 50)),
email_count: contactInfo.emails.length,
phone_count: contactInfo.phones.length,
estimated_quality: wordCount > 200 && contactInfo.emails.length > 0 ? "HIGH" :
wordCount > 100 ? "MEDIUM" : "LOW"
};
}3. Why Add a Code Processing Step?
- Data Structure Adaptation: Converts Scrapeless array format to Claude-friendly structure
- Content Optimization: Extracts and prioritizes business-relevant sections
- Contact Discovery: Automatically identifies emails and phone numbers
- Quality Assessment: Evaluates content richness and completeness
- Token Efficiency: Reduces content size while preserving important information
- Error Handling: Manages failed crawls and insufficient content gracefully
- Debugging Support: Comprehensive logging for troubleshooting
4. Expected Output Structure
After processing, each lead will have this structured format:
{
"url": "https://company.com",
"company_name": "Company Name",
"content": "COMPANY ANALYSIS REQUEST\n\nCompany: ...",
"raw_content_length": 50000,
"processed_content_length": 2500,
"extracted_emails": ["contact@company.com"],
"extracted_phones": ["+1-555-123-4567"],
"content_quality": {
"word_count": 5000,
"has_contact_info": true,
"estimated_quality": "HIGH",
"content_richness_score": 10
},
"processing_status": "SUCCESS"
}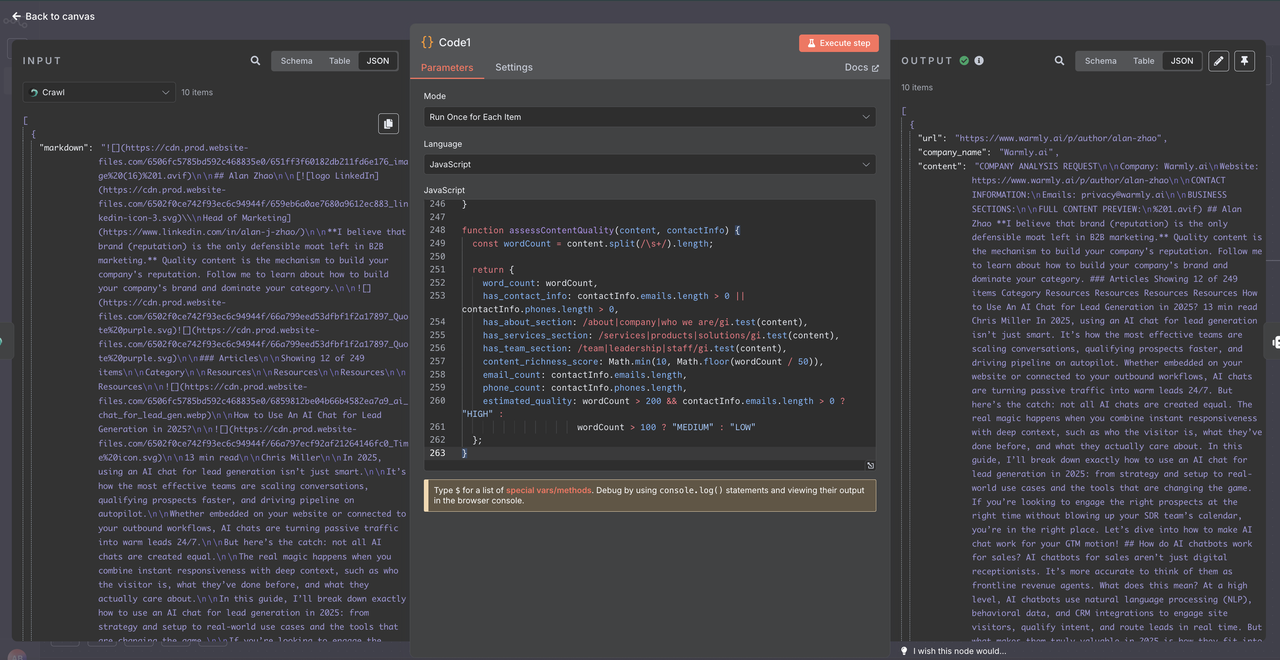
This helps verify the data format and troubleshoot any processing issues.
5. Code Node Benefits
- Cost Savings: Smaller, cleaner content = fewer Claude API tokens
- Better Results: Focused content improves AI analysis accuracy
- Error Recovery: Handles empty responses and failed crawls
- Flexibility: Easy to adjust parsing logic based on results
- Quality Metrics: Built-in assessment of lead data completeness
Step 6: AI-Powered Lead Qualification with Claude
Use Claude AI to extract and qualify lead information from crawled content that has been processed and structured by our Code Node.
- Add an AI Agent node after the Code node
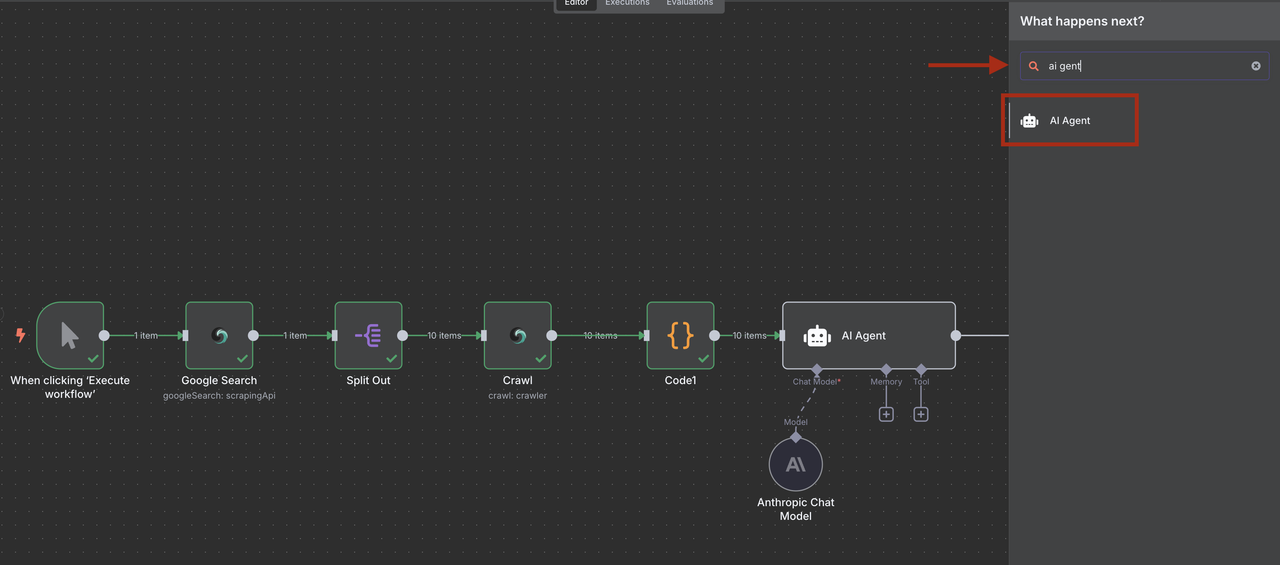
- Add an Anthropic Claude node and configure for lead analysis
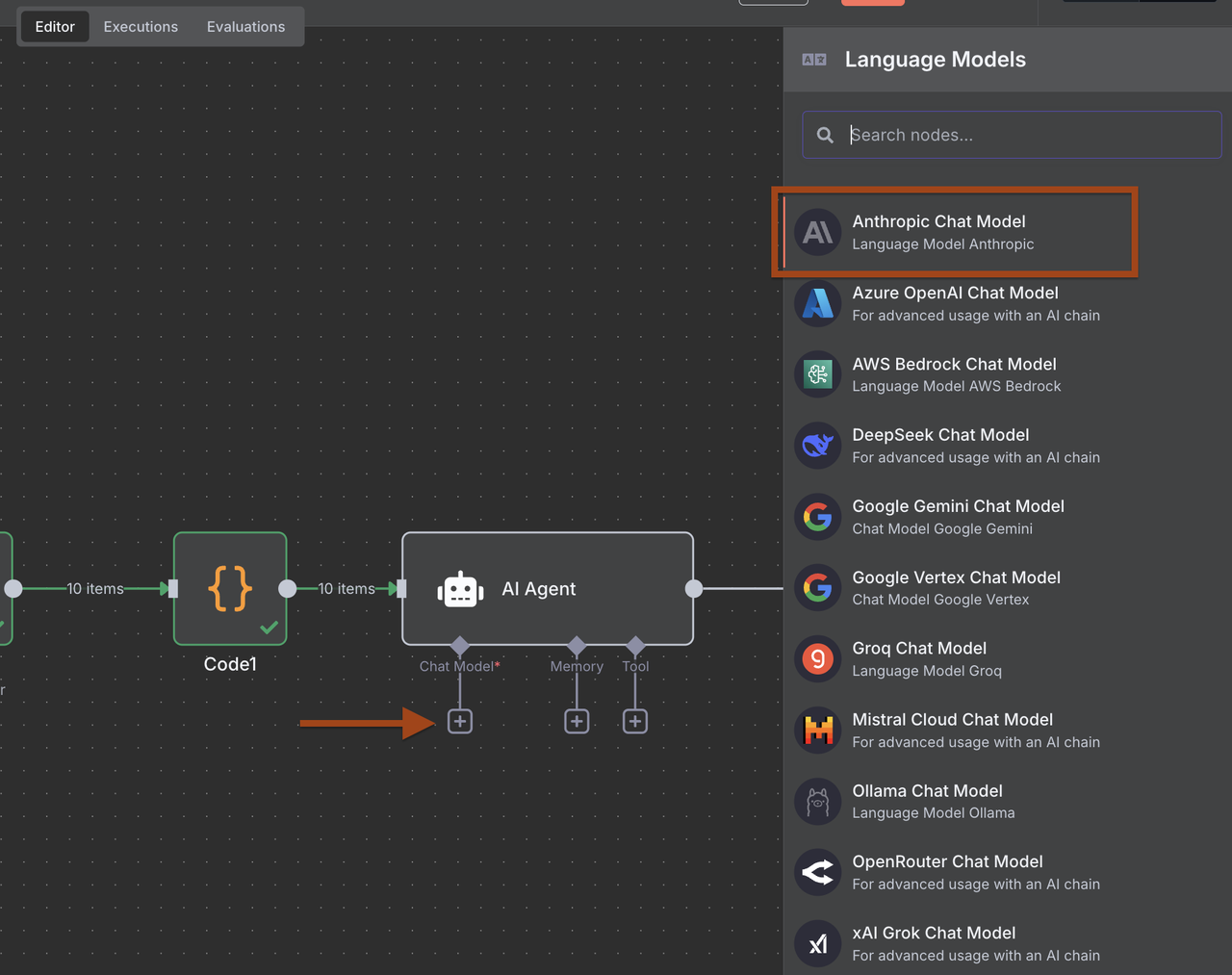
- Configure prompts to extract structured B2B lead data
Click on AI agent -> add option -> System Message and copy paste message below
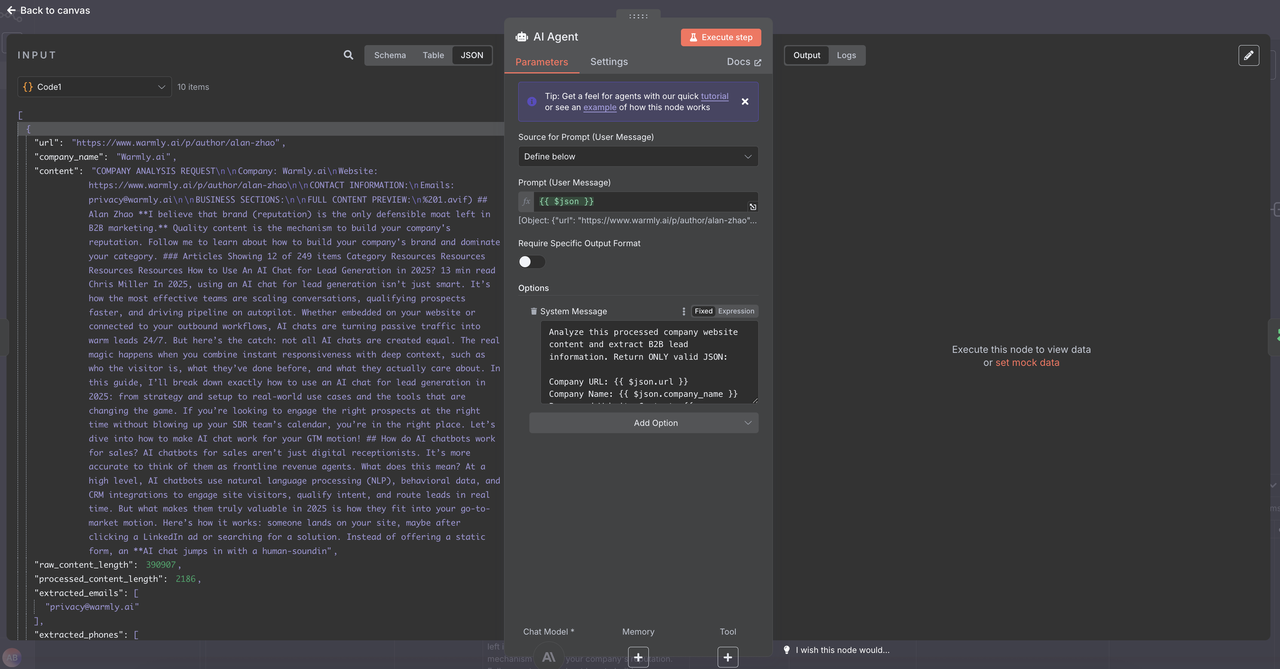
System Lead Extraction Prompt:
Analyze this processed company website content and extract B2B lead information. Return ONLY valid JSON:
Company URL: {{ $json.url }}
Company Name: {{ $json.company_name }}
Processed Website Content: {{ $json.content }}
Content Quality Assessment: {{ $json.content_quality }}
Pre-extracted Contact Information:
Emails: {{ $json.extracted_emails }}
Phones: {{ $json.extracted_phones }}
Metadata Information: {{ $json.metadata_info }}
Processing Details:
Raw content length: {{ $json.raw_content_length }} characters
Processed content length: {{ $json.processed_content_length }} characters
Processing status: {{ $json.processing_status }}
Based on this structured data, extract and qualify this B2B lead. Return ONLY valid JSON:
{
"company_name": "Official company name from content",
"industry": "Primary industry/sector identified",
"company_size": "Employee count or size category (startup/SMB/mid-market/enterprise)",
"location": "Headquarters location or primary market",
"contact_email": "Best general or sales email from extracted emails",
"phone": "Primary phone number from extracted phones",
"key_services": ["Main services/products offered based on content"],
"target_market": "Who they serve (B2B/B2C, SMB/Enterprise, specific industries)",
"technologies": ["Tech stack, platforms, or tools mentioned"],
"funding_stage": "Funding stage if mentioned (seed/series A/B/C/public/private)",
"business_model": "Revenue model (SaaS/consulting/product/marketplace)",
"social_presence": {
"linkedin": "LinkedIn company URL if found in content",
"twitter": "Twitter handle if found"
},
"lead_score": 8.5,
"qualification_reasons": ["Specific reasons why this lead is qualified or not"],
"decision_makers": ["Names and titles of key contacts found"],
"next_actions": ["Recommended follow-up strategies based on company profile"],
"content_insights": {
"website_quality": "Professional/Basic/Poor based on content richness",
"recent_activity": "Any recent news, funding, or updates mentioned",
"competitive_positioning": "How they position vs competitors"
}
}
Enhanced Scoring Criteria (1-10):
9-10: Perfect ICP fit + complete contact info + high growth signals + professional content
7-8: Good ICP fit + some contact info + stable company + quality content
5-6: Moderate fit + limited contact info + basic content + needs research
3-4: Poor fit + minimal info + low-quality content + wrong target market
1-2: Not qualified + no contact info + processing failed + irrelevant
Scoring Factors to Consider:
Content Quality Score: {{ $json.content_quality.content_richness_score }}/10
Contact Information: {{ $json.content_quality.email_count }} emails, {{ $json.content_quality.phone_count }} phones
Content Completeness: {{ $json.content_quality.has_about_section }}, {{ $json.content_quality.has_services_section }}
Processing Success: {{ $json.processing_status }}
Content Volume: {{ $json.content_quality.word_count }} words
Instructions:
Use ONLY the pre-extracted contact information from extracted_emails and extracted_phones
Base company_name on the processed company_name field, not the raw content
Factor in the content_quality metrics when determining lead_score
If processing_status is not "SUCCESS", lower the score significantly
Use null for any missing information - do not hallucinate data
Be conservative with scoring - better to underscore than overscore
Focus on B2B relevance and ICP fit based on the structured content providedThe prompt structure makes filtering more reliable since Claude now receives consistent, structured input. This leads to more accurate lead scores and better qualification decisions in the next step of your workflow.
Step 7: Parsing Claude AI Response
Before filtering leads, we need to properly parse Claude's JSON response which may come wrapped in markdown formatting.
- Add a Code node after the AI Agent (Claude)
- Configure to parse and clean Claude's JSON response
1. Code Node Configuration
// Code to parse Claude AI JSON response
console.log("=== PARSING CLAUDE AI RESPONSE ===");
try {
// Claude's response arrives in the "output" field
const claudeOutput = $json.output || "";
console.log("Claude output length:", claudeOutput.length);
console.log("Claude output preview:", claudeOutput.substring(0, 200));
// Extract JSON from Claude's markdown response
let jsonString = claudeOutput;
// Remove markdown backticks if present
if (jsonString.includes('json')) { const jsonMatch = jsonString.match(/json\s*([\s\S]*?)\s*/); if (jsonMatch && jsonMatch[1]) { jsonString = jsonMatch[1].trim(); } } else if (jsonString.includes('')) {
// Fallback for cases with only const jsonMatch = jsonString.match(/\s*([\s\S]*?)\s*```/);
if (jsonMatch && jsonMatch[1]) {
jsonString = jsonMatch[1].trim();
}
}
// Additional cleaning
jsonString = jsonString.trim();
console.log("Extracted JSON string:", jsonString.substring(0, 300));
// Parse the JSON
const leadData = JSON.parse(jsonString);
console.log("Successfully parsed lead data for:", leadData.company_name);
console.log("Lead score:", leadData.lead_score);
console.log("Contact email:", leadData.contact_email);
// Validation and data cleaning
const cleanedLead = {
company_name: leadData.company_name || "Unknown",
industry: leadData.industry || null,
company_size: leadData.company_size || null,
location: leadData.location || null,
contact_email: leadData.contact_email || null,
phone: leadData.phone || null,
key_services: Array.isArray(leadData.key_services) ? leadData.key_services : [],
target_market: leadData.target_market || null,
technologies: Array.isArray(leadData.technologies) ? leadData.technologies : [],
funding_stage: leadData.funding_stage || null,
business_model: leadData.business_model || null,
social_presence: leadData.social_presence || { linkedin: null, twitter: null },
lead_score: typeof leadData.lead_score === 'number' ? leadData.lead_score : 0,
qualification_reasons: Array.isArray(leadData.qualification_reasons) ? leadData.qualification_reasons : [],
decision_makers: Array.isArray(leadData.decision_makers) ? leadData.decision_makers : [],
next_actions: Array.isArray(leadData.next_actions) ? leadData.next_actions : [],
content_insights: leadData.content_insights || {},
// Meta-information for filtering
is_qualified: leadData.lead_score >= 6 && leadData.contact_email !== null,
has_contact_info: !!(leadData.contact_email || leadData.phone),
processing_timestamp: new Date().toISOString(),
claude_processing_status: "SUCCESS"
};
console.log(✅ Lead processed: ${cleanedLead.company_name} (Score: ${cleanedLead.lead_score}, Qualified: ${cleanedLead.is_qualified}));
return cleanedLead;
} catch (error) {
console.error("❌ Error parsing Claude response:", error);
console.error("Raw output:", $json.output);
// Structured error response
return {
company_name: "Claude Parsing Error",
industry: null,
company_size: null,
location: null,
contact_email: null,
phone: null,
key_services: [],
target_market: null,
technologies: [],
funding_stage: null,
business_model: null,
social_presence: { linkedin: null, twitter: null },
lead_score: 0,
qualification_reasons: [Claude parsing failed: ${error.message}],
decision_makers: [],
next_actions: ["Fix Claude response parsing", "Check JSON format"],
content_insights: {},
is_qualified: false,
has_contact_info: false,
processing_timestamp: new Date().toISOString(),
claude_processing_status: "FAILED",
parsing_error: error.message,
raw_claude_output: $json.output || "No output received"
};
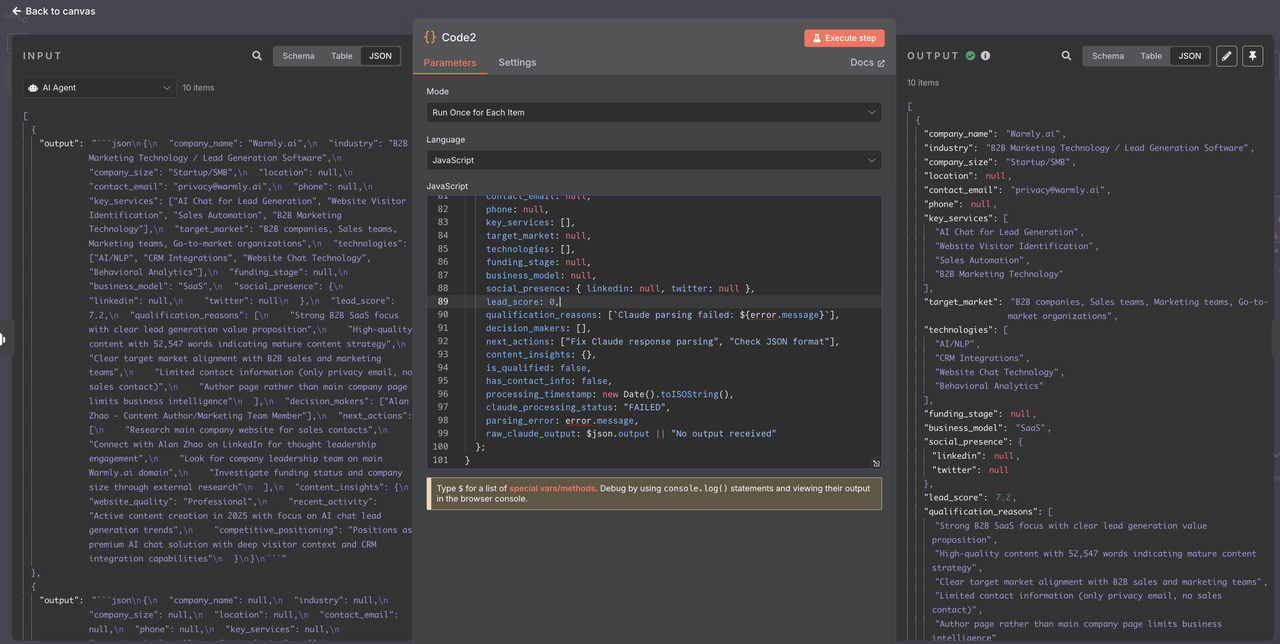
}2. Why Add Claude Response Parsing?
- Markdown Handling: Removes json formatting from Claude responses
- Data Validation: Ensures all fields have proper types and defaults
- Error Recovery: Handles JSON parsing failures gracefully
- Filtering Preparation: Adds computed fields for easier filtering
- Debug Support: Comprehensive logging for troubleshooting
Step 8: Lead Filtering and Quality Control
Filter leads based on qualification scores and data completeness using the parsed and validated data.
- Add an IF node after the Claude Response Parser
- Set up enhanced qualification criteria
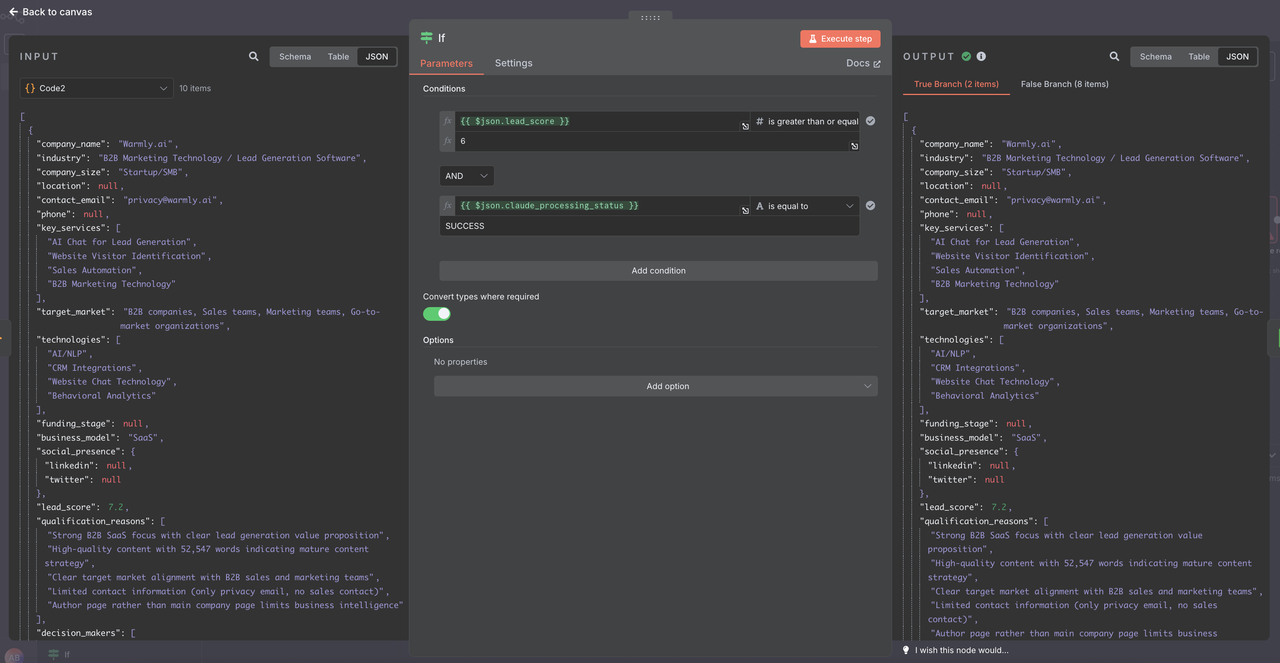
1. New IF Node Configuration
Now that the data is properly parsed, use these conditions in the IF node:
1: Add Multiple Conditions
Condition 1:
- Field: {{ $json.lead_score }}
- Operator: is equal or greater than
- Value: 6
Condition 2:
- Field: {{ $json.claude_processing_status }}
- Operator: is equal to
- Value: SUCCESS
Option : Convert types where required
- TRUE
2. Filtering Benefits
- Quality Assurance: Only qualified leads proceed to storage
- Cost Optimization: Prevents processing of low-quality leads
- Data Integrity: Ensures parsed data is valid before storage
- Debug Capability: Failed parsing is caught and logged
Step 9: Storing Leads in Google Sheets
Store qualified leads in a Google Sheets database for easy access and management.
- Add a Google Sheets node after the filter
- Configure to append new leads
However, you can choose to manage the data as you wish.
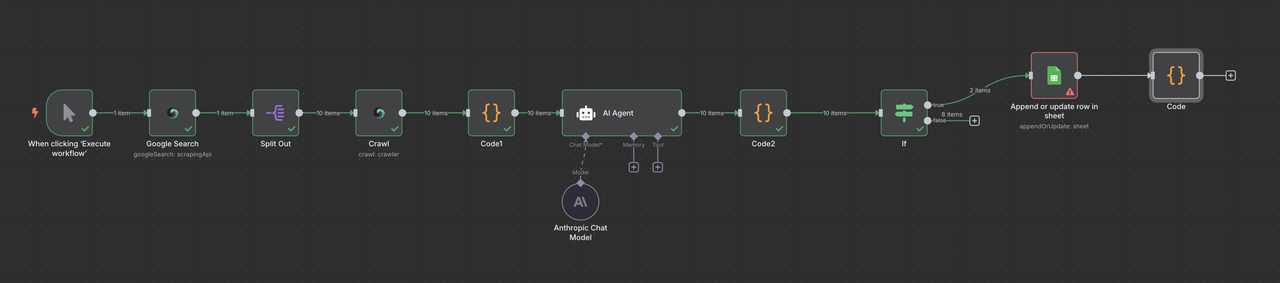
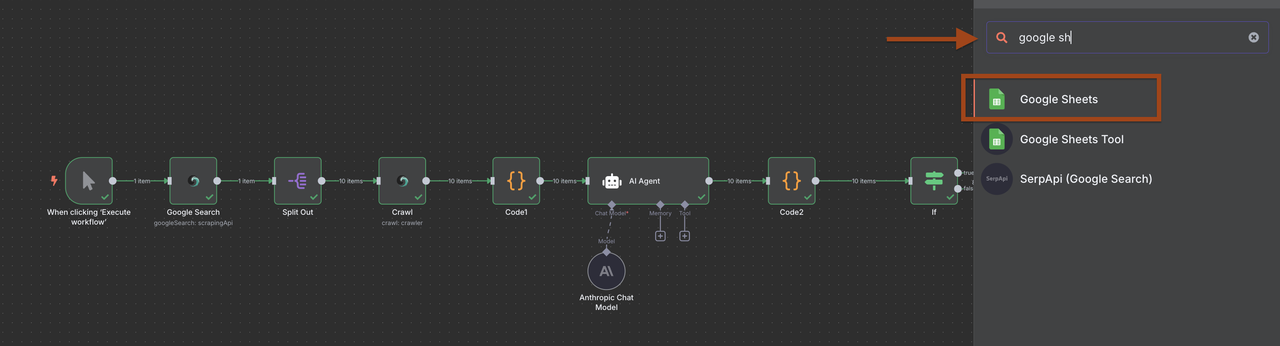
Google Sheets Setup:
- Create a spreadsheet called "B2B Leads Database"
- Set up columns:
- Company Name
- Industry
- Company Size
- Location
- Contact Email
- Phone
- Website
- Lead Score
- Date Added
- Qualification Notes
- Next Actions
For my part I choose to directly use a discord webhook
Step 9-2: Discord Notifications (Adaptable to Other Services)
Send real-time notifications for new qualified leads.
- Add an HTTP Request node for Discord webhook
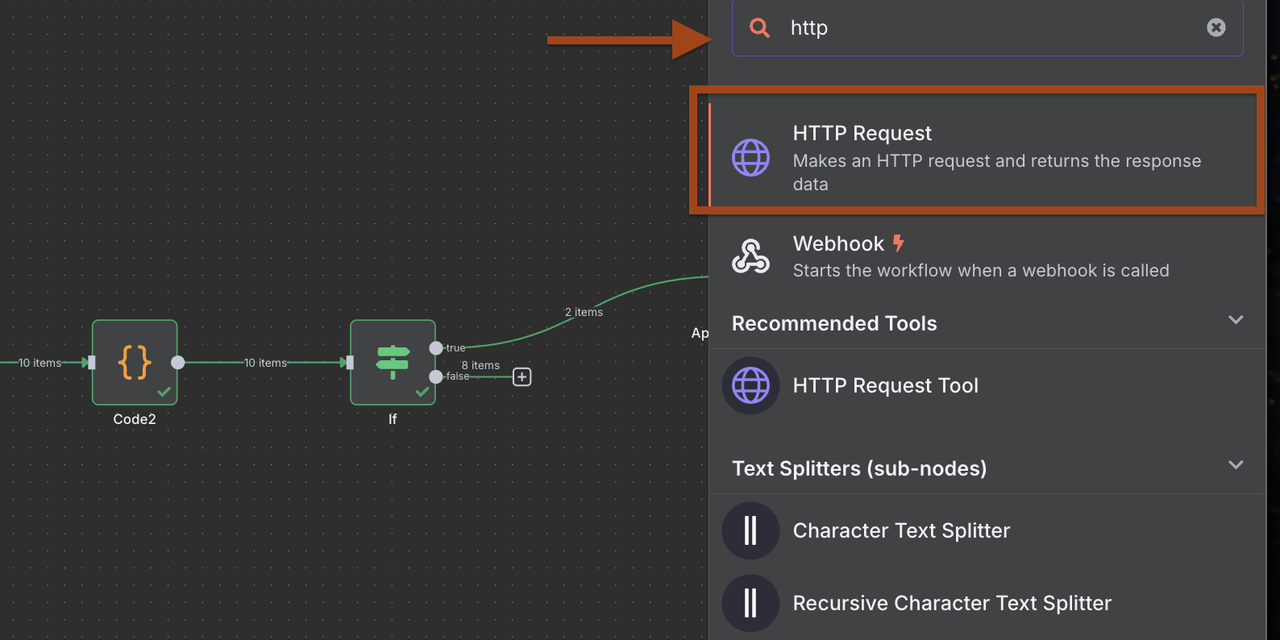
- Configure Discord-specific payload format
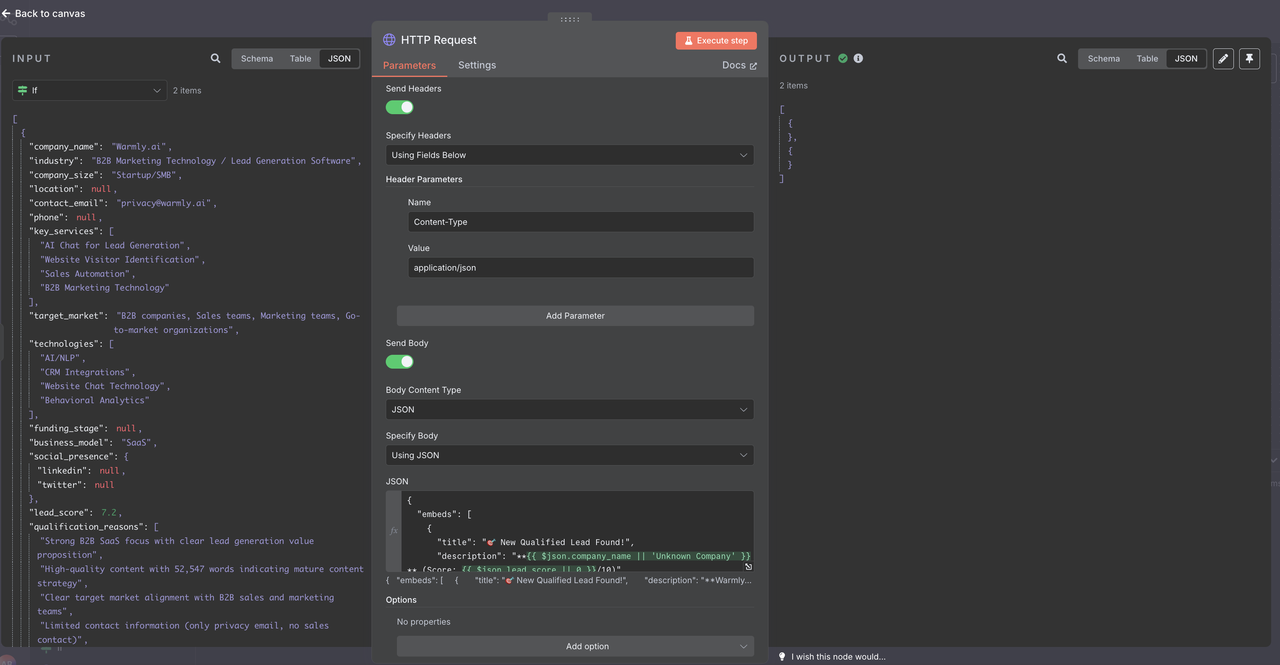
Discord Webhook Configuration:
- Method: POST
- URL: Your Discord webhook URL
- Headers: Content-Type: application/json
Discord Message Payload:
{
"embeds": [
{
"title": "🎯 New Qualified Lead Found!",
"description": "**{{ $json.company_name || 'Unknown Company' }}** (Score: {{ $json.lead_score || 0 }}/10)",
"color": 3066993,
"fields": [
{
"name": "Industry",
"value": "{{ $json.industry || 'Not specified' }}",
"inline": true
},
{
"name": "Size",
"value": "{{ $json.company_size || 'Not specified' }}",
"inline": true
},
{
"name": "Location",
"value": "{{ $json.location || 'Not specified' }}",
"inline": true
},
{
"name": "Contact",
"value": "{{ $json.contact_email || 'No email found' }}",
"inline": false
},
{
"name": "Phone",
"value": "{{ $json.phone || 'No phone found' }}",
"inline": false
},
{
"name": "Services",
"value": "{{ $json.key_services && $json.key_services.length > 0 ? $json.key_services.slice(0, 3).join(', ') : 'Not specified' }}",
"inline": false
},
{
"name": "Website",
"value": "[Visit Website]({{ $node['Code2'].json.url || '#' }})",
"inline": false
},
{
"name": "Why Qualified",
"value": "{{ $json.qualification_reasons && $json.qualification_reasons.length > 0 ? $json.qualification_reasons.slice(0, 2).join(' • ') : 'Standard qualification criteria met' }}",
"inline": false
}
],
"footer": {
"text": "Generated by n8n Lead Generation Workflow"
},
"timestamp": ""
}
]
}Results
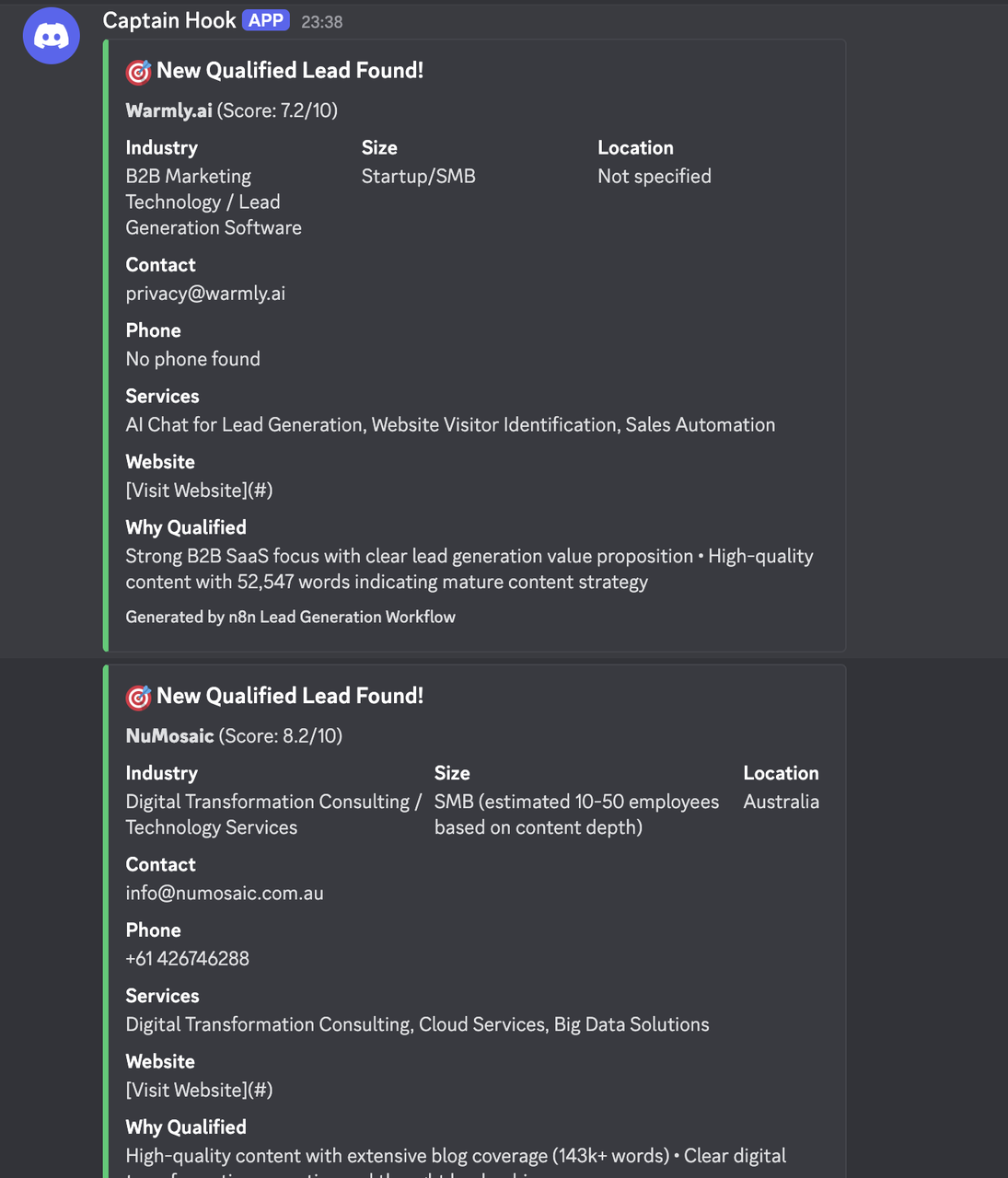
Industry-Specific Configurations
SaaS/Software Companies
Search Queries:
"SaaS companies" "B2B software" "enterprise software"
"cloud software" "API" "developers" "subscription model"
"software as a service" "platform" "integration"Qualification Criteria:
- Employee count: 20-500
- Uses modern tech stack
- Has API documentation
- Active on GitHub/technical content
Marketing Agencies
Search Queries:
"digital marketing agency" "B2B marketing" "enterprise clients"
"marketing automation" "demand generation" "lead generation"
"content marketing agency" "growth marketing" "performance marketing"Qualification Criteria:
- Client case studies available
- Team size: 10-100
- Specializes in B2B
- Active content marketing
E-commerce/Retail
Search Queries:
"ecommerce companies" "online retail" "D2C brands"
"Shopify stores" "WooCommerce" "ecommerce platform"
"online marketplace" "digital commerce" "retail technology"Qualification Criteria:
- Revenue indicators
- Multi-channel presence
- Technology platform mentioned
- Growth trajectory signals
Data Management and Analysis
Lead Database Schema
Structure your Google Sheets for maximum utility:
Core Lead Information:
- Company Name, Industry, Size, Location
- Contact Email, Phone, Website
- Lead Score, Date Added, Source Query
Qualification Data:
- Qualification Reasons, Decision Makers
- Next Actions, Follow-up Date
- Sales Rep Assigned, Lead Status
Enrichment Fields:
- LinkedIn URL, Social Media Presence
- Technologies Used, Funding Stage
- Competitors, Recent News
Analytics and Reporting
Track workflow performance with additional sheets:
Daily Summary Sheet:
- Leads Generated Per Day
- Average Lead Score
- Top Industries Found
- Conversion Rates
Search Performance:
- Best Performing Queries
- Geographic Distribution
- Company Size Breakdown
- Success Rate by Industry
ROI Tracking:
- Cost Per Lead (API costs)
- Time to Contact
- Conversion to Opportunity
- Revenue Attribution
Conclusion
This intelligent B2B lead generation workflow transforms your sales prospecting by automating the discovery, qualification, and organization of potential customers. By combining Google Search with intelligent crawling and AI analysis, you create a systematic approach to building your sales pipeline.
The workflow adapts to your specific industry, company size targets, and qualification criteria while maintaining high data quality through AI-powered analysis. With proper setup and monitoring, this system becomes a consistent source of qualified leads for your sales team.
The integration with Google Sheets provides an accessible database for sales teams, while Discord notifications ensure immediate awareness of high-value prospects. The modular design allows easy adaptation to different notification services, CRM systems, and data storage solutions.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


