
How to Build an Automated Job Finder Agent with Scrapeless and Google Sheets
Advanced Data Extraction Specialist
Staying up to date with new job listings is critical for job seekers, recruiters, and tech enthusiasts. Instead of manually checking websites, you can automate the entire process—scraping job boards at regular intervals and saving results to Google Sheets for easy tracking and sharing.
This guide will show you how to build an automated job finder agent using Scrapeless, n8n, and Google Sheets. You’ll create a workflow that scrapes job listings from the Y Combinator Jobs page every 6 hours, extracts structured data, and stores it in a spreadsheet.
Prerequisites
Before you begin, make sure you have:
- n8n: A no-code automation platform (self-hosted or cloud).
- Scrapeless API: Get your API key from Scrapeless.
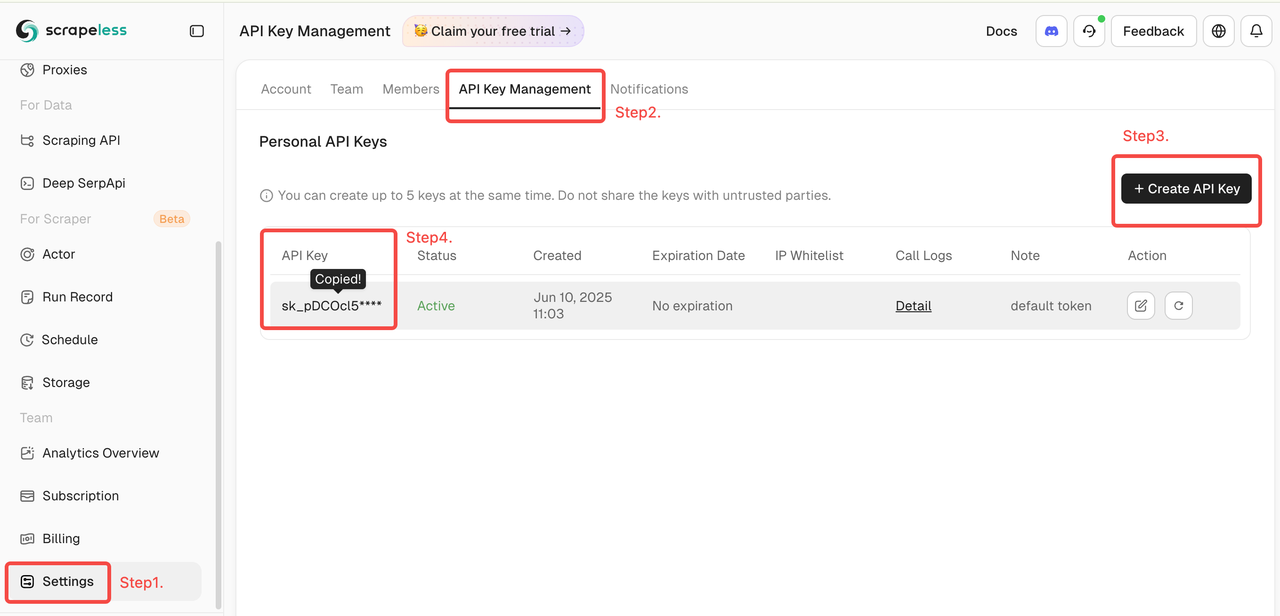
- Log in to the Scrapeless Dashboard.
- Then click "Setting" on the left -> select "API Key Management" -> click "Create API Key". Finally, click the API Key you created to copy it.
- Google Sheets account: To save and view the job data.
- Target Website: This example uses the Y Combinator Jobs page.
How to Build an Automated Job Finder Agent with Scrapeless and Google Sheets
1. Schedule Trigger: Run Every 6 Hours
Node Type: Schedule Trigger
Settings:
- Interval Field:
hours - Interval Value:
6
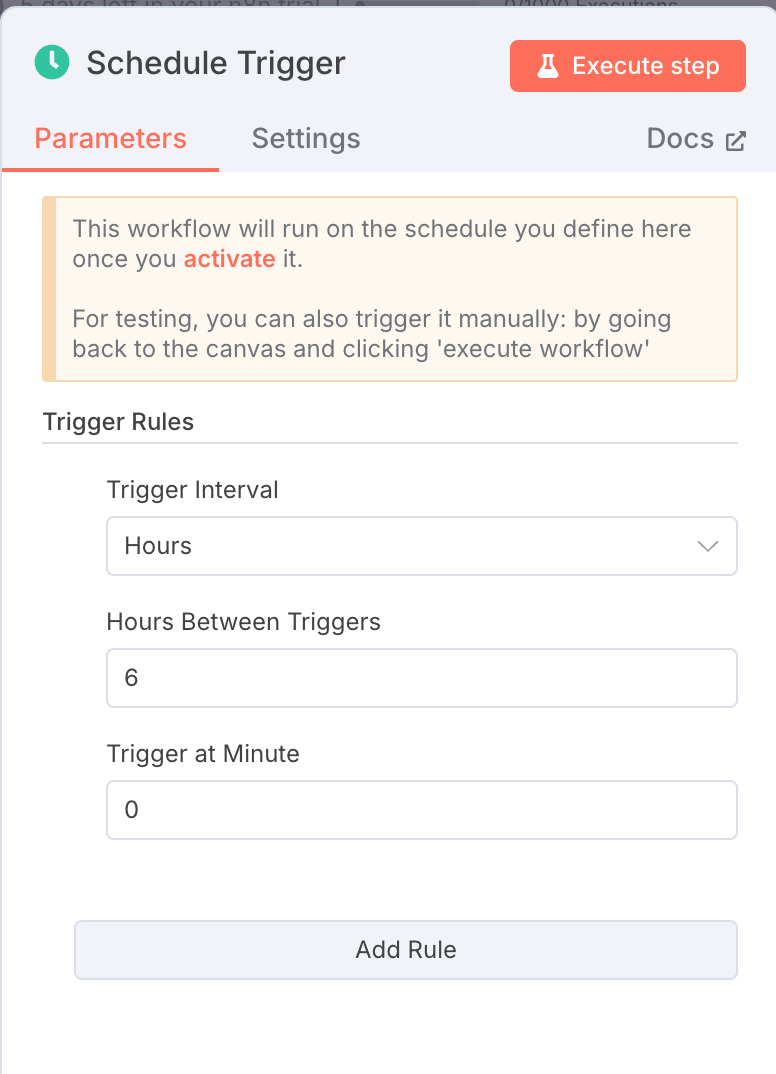
This node ensures that your workflow runs automatically every 6 hours without manual input.
2. Scrapeless Crawler: Scrape Job Listings
Node Type: Scrapeless Node
Settings:
- Resource:
crawler - Operation:
crawl - URL:
https://www.ycombinator.com/jobs - Limit Crawl Pages: 2
- Credentials:
Your Scrapeless API Key
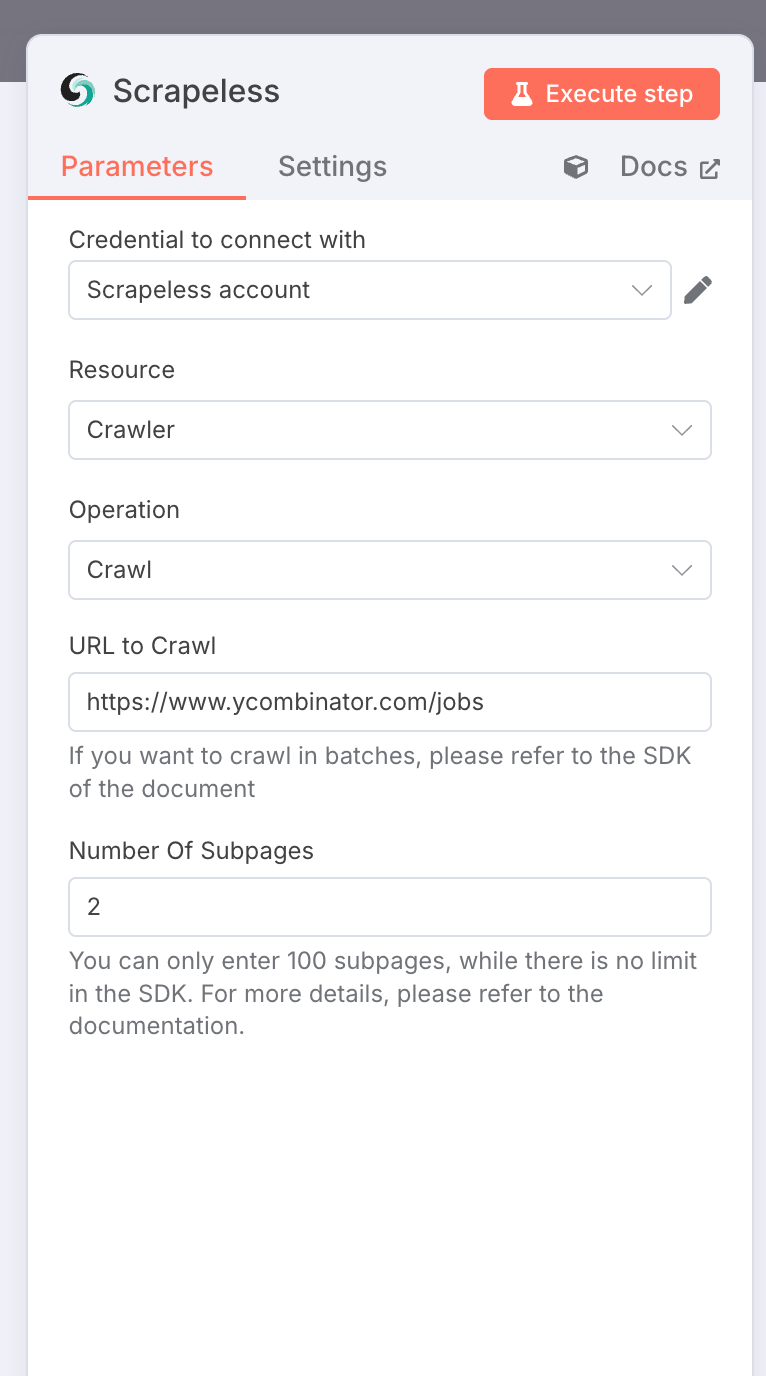
Output: An array of objects containing rich job data in Markdown format.
3. Extract Markdown Content
Node Type: JavaScript Code Node
Purpose: Extract only the markdown field from the raw crawl results.
const raw = items[0].json;
const output = raw.map(obj => ({
json: {
markdown: obj.markdown,
}
}));
return output;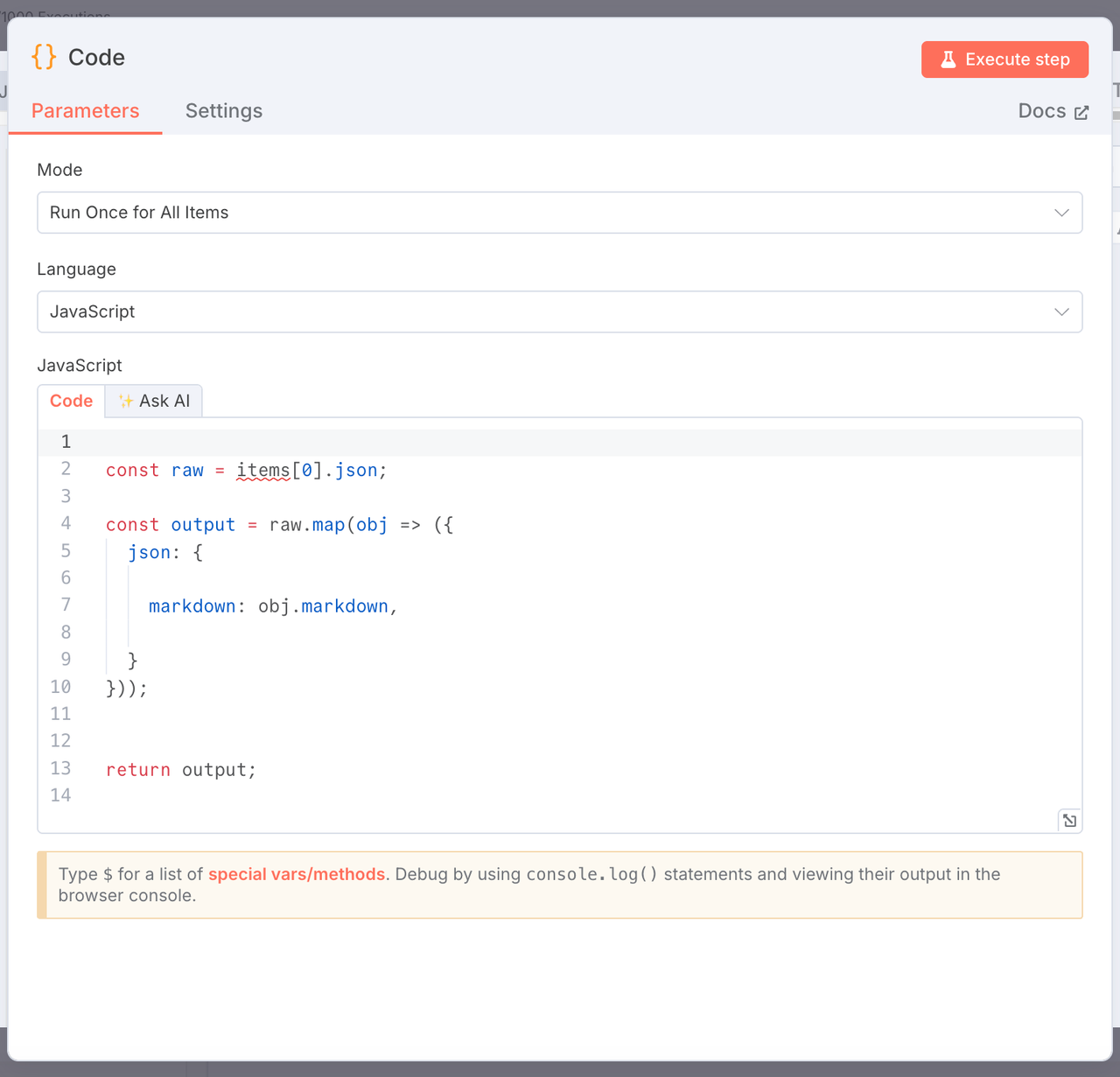
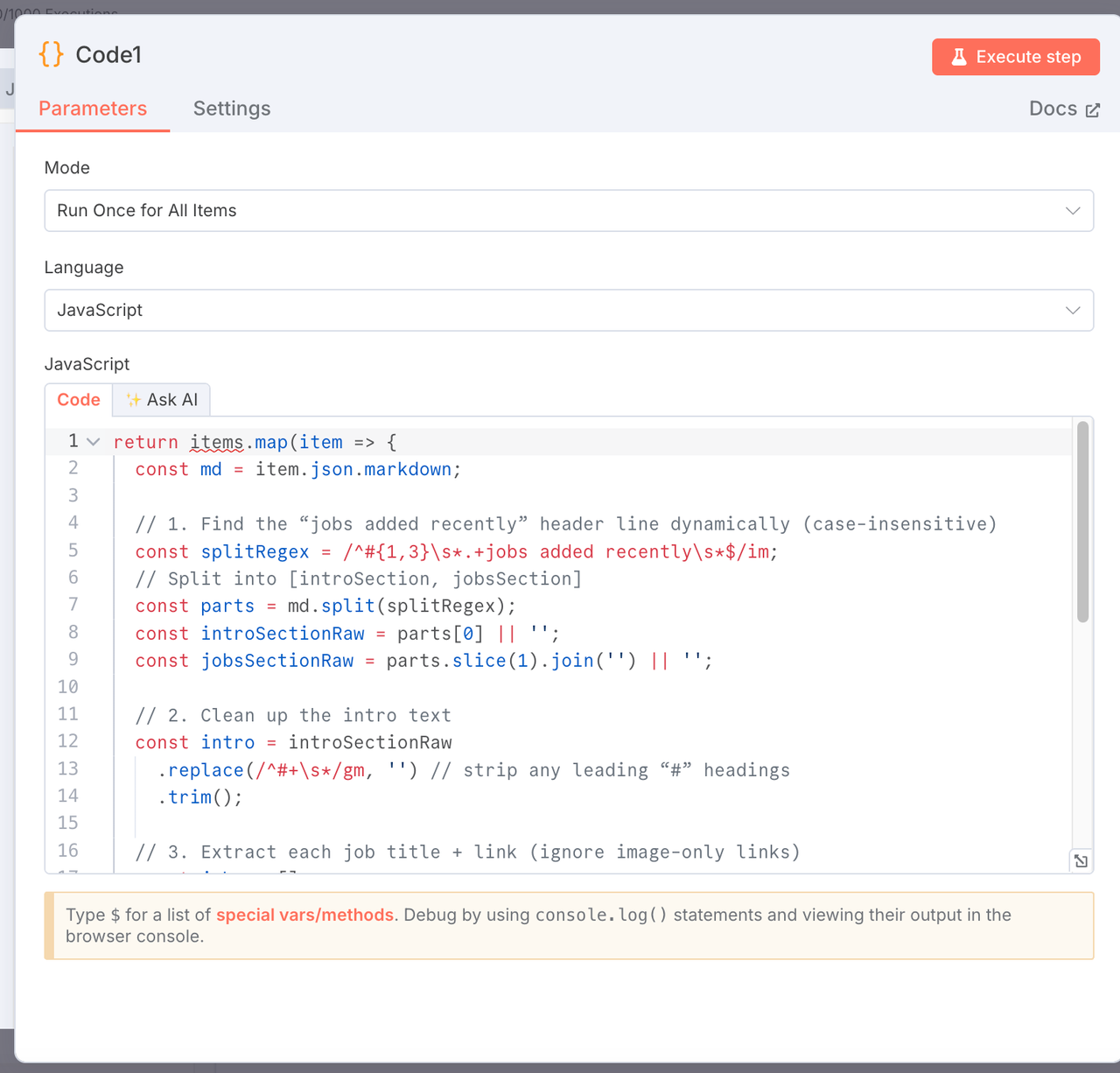
4. Parse Markdown: Extract Intro and Job List
Node Type: JavaScript Code Node
Purpose: Split the markdown into an intro and a structured list of job titles and links.
return items.map(item => {
const md = item.json.markdown;
const splitRegex = /^#{1,3}\s*.+jobs added recently\s*$/im;
const parts = md.split(splitRegex);
const introSectionRaw = parts[0] || '';
const jobsSectionRaw = parts.slice(1).join('') || '';
const intro = introSectionRaw.replace(/^#+\s*/gm, '').trim();
const jobs = [];
const re = /\-\s*\[(?!\!)([^\]]+)\]\((https?:\/\/[^\)]+)\)/g;
let match;
while ((match = re.exec(jobsSectionRaw))) {
jobs.push({
title: match[1].trim(),
link: match[2].trim(),
});
}
return {
json: {
intro,
jobs,
},
};
});
5. Flatten Jobs for Export
Node Type: JavaScript Code Node
Purpose: Convert each job into a separate row for easy export.
const output = [];
items.forEach(item => {
const intro = item.json.intro;
const jobs = item.json.jobs || [];
jobs.forEach(job => {
output.push({
json: {
intro,
jobTitle: job.title,
jobLink: job.link,
},
});
});
});
return output;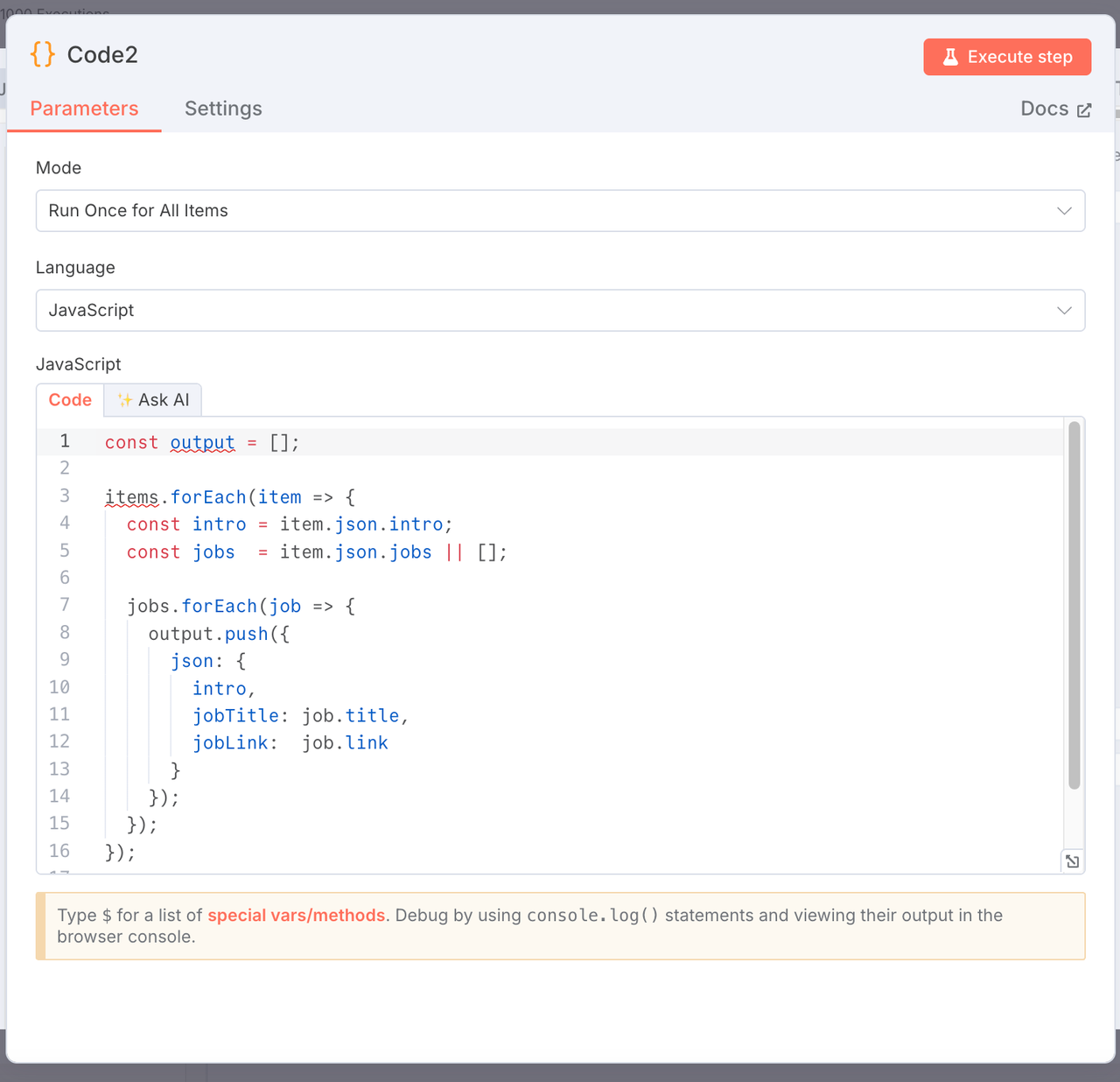
6. Append to Google Sheets
Node Type: Google Sheets Node
Settings:
- Operation:
append - Document URL: You can also directly select the name of the Google Sheet you created (recommended method)
- Sheet Name:
Links(Tab ID:gid=0) - Column Mapping:
title←{{ $json.jobTitle }}link←{{ $json.jobLink }}
- Convert Types:
false - OAuth: Connect your Google Sheets account
The final data is automatically appended to your sheet for tracking or further analysis.
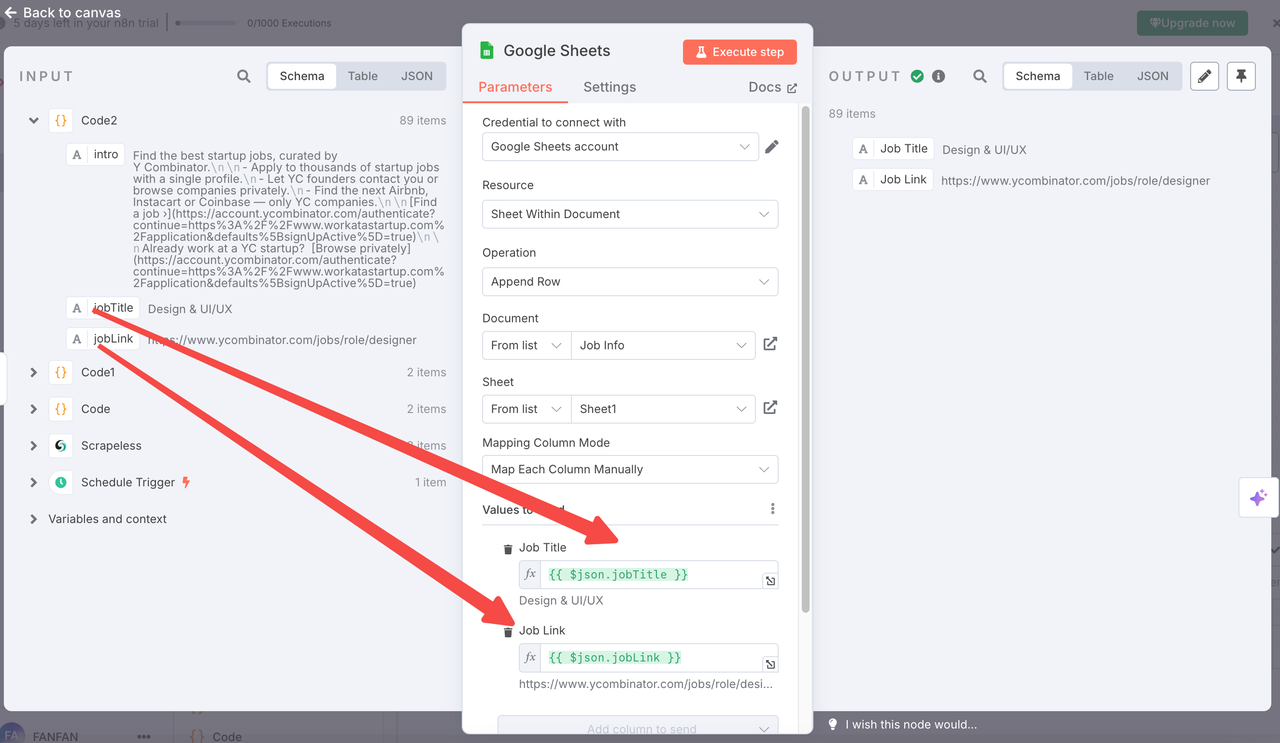
7. Output result example
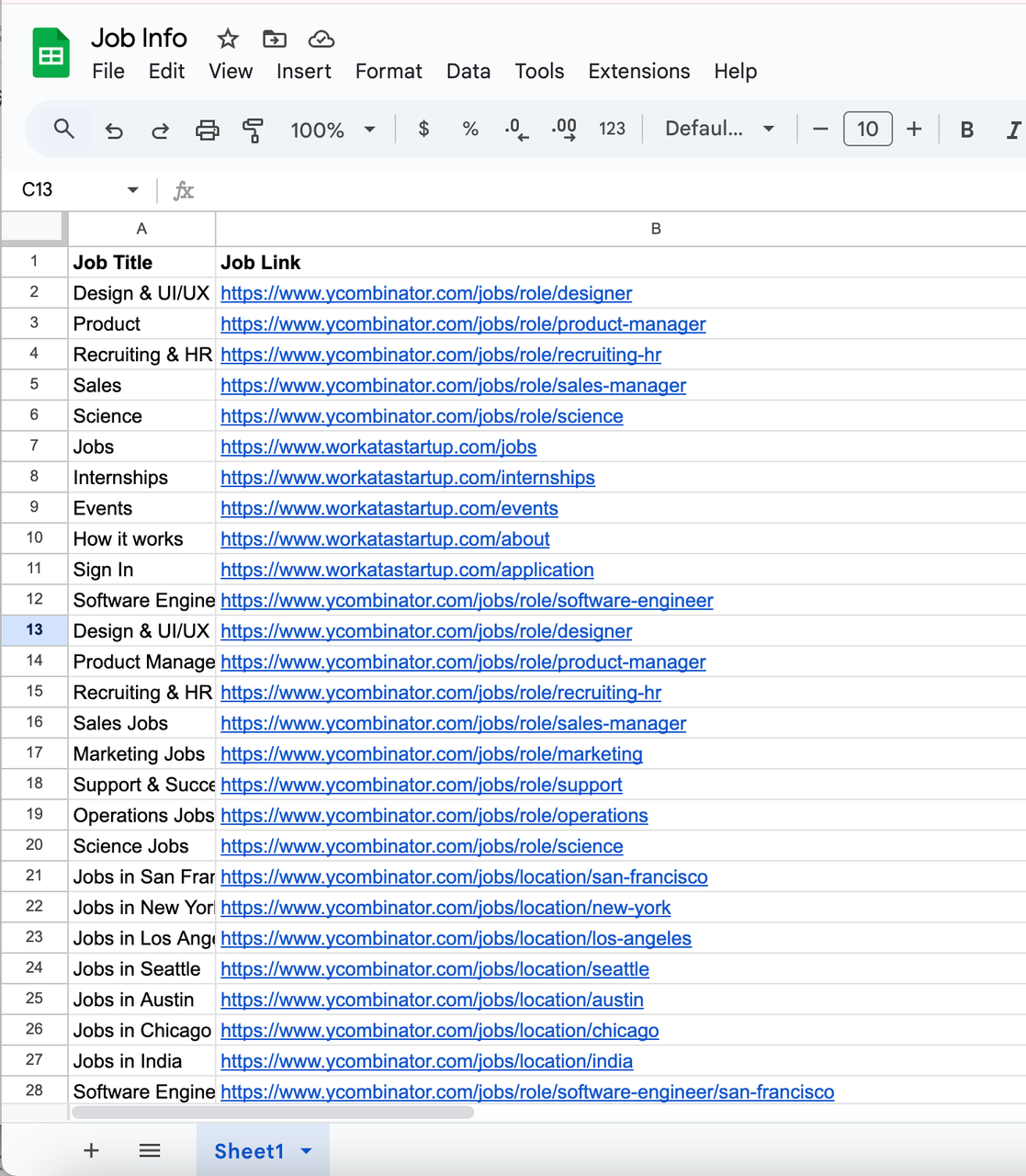
Workflow Diagram
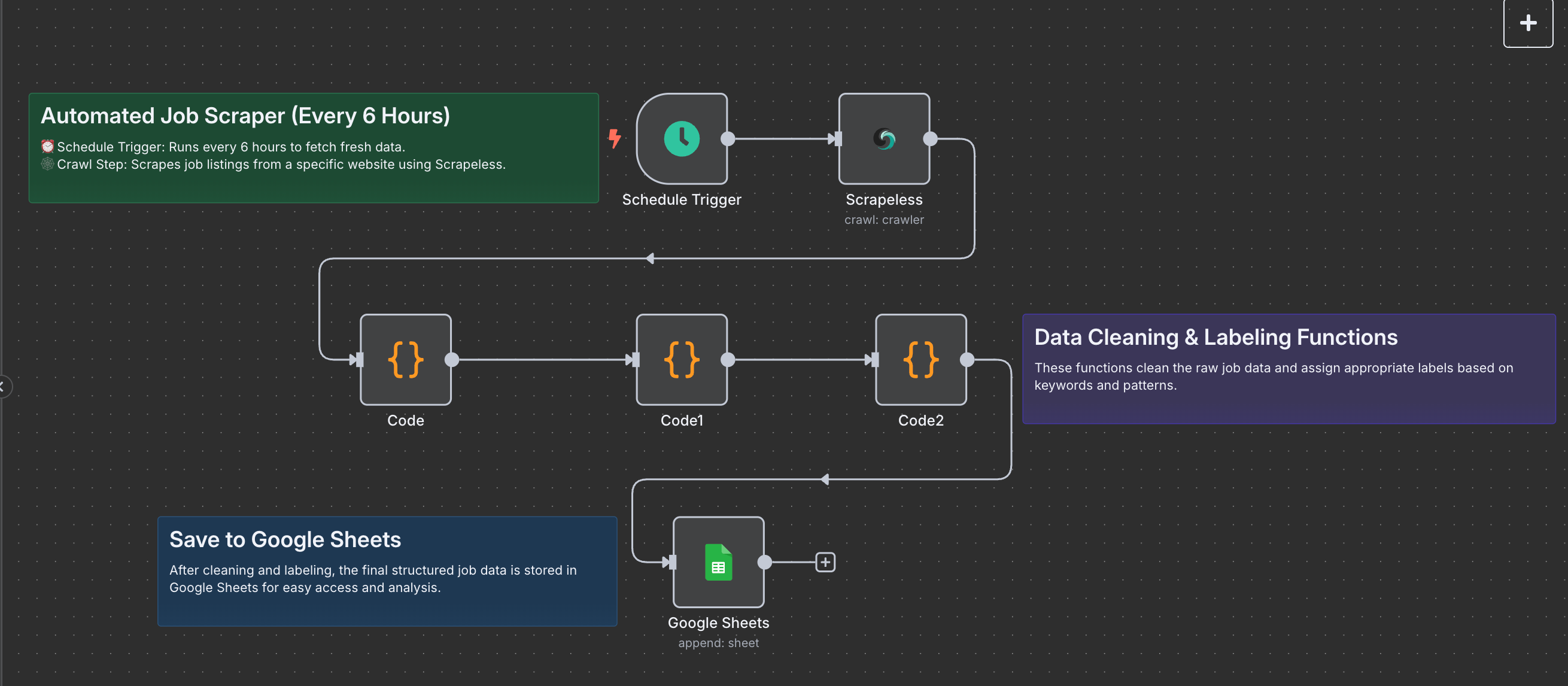
Each node is modular and customizable. You can change the website, the scraping frequency, or the data formatting logic as needed.
Customization Ideas
- Scrape More Sites: Replace the URL with LinkedIn, AngelList, or other job boards.
- Add Notifications: Send job updates to Slack, Discord, or email.
- Enhance with AI: Use GPT nodes to generate job summaries or keyword tags.
Applicable Business Use Cases
This automated job finder agent can be applied to various business scenarios, including:
- Recruitment Agencies: Continuously monitor niche job boards and company career pages to discover new openings for their talent pool.
- Startup Incubators & Accelerators: Track hiring activities of portfolio companies (such as Y Combinator startups) and stay informed about market demand.
- HR & Talent Teams: Automate competitive intelligence by tracking job postings from rival companies or industry leaders.
- Job Aggregator Platforms: Aggregate jobs from multiple sources and streamline publishing to their own platforms without manual scraping.
- Freelance & Remote Work Communities: Curate fresh job listings for newsletters, community forums, or job boards targeting specific audiences.
- Market Research Teams: Analyze hiring trends across industries to gain insights into market growth, tech stacks in demand, or emerging roles.
This workflow is especially useful for companies needing regular, structured, and scalable job market intelligence, saving countless hours of manual effort and ensuring data accuracy.
Automated Job Finder Agent Workflow
Conclusion
With Scrapeless, n8n, and Google Sheets, you can easily build a fully automated job finder agent that scrapes job listings, cleans the data, and saves it to a spreadsheet. This setup is flexible, cost-effective, and ideal for individuals, recruiters, or teams who want real-time job monitoring without manual effort.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


