
Build an AI-Powered Research Assistant with Linear + Scrapeless + Claude
Advanced Data Extraction Specialist
Modern teams need instant access to reliable data for informed decision-making. Whether you're researching competitors, analyzing trends, or gathering market intelligence, manual data collection slows down your workflow and breaks your development momentum.
By combining Linear's project management platform with Scrapeless's powerful data extraction APIs and Claude AI's analytical capabilities, you can create an intelligent research assistant that responds to simple commands directly in your Linear issues.
This integration transforms your Linear workspace into a smart command center where typing /search competitor analysis or /trends AI market automatically triggers comprehensive data gathering and AI-powered analysis—all delivered back as structured comments in your Linear issues.
Why Choose Linear + Scrapeless + Claude?
Linear: The Modern Development Workspace
Linear provides the perfect interface for team collaboration and task management:
- Issue-Driven Workflow: Natural integration with development processes
- Real-Time Updates: Instant notifications and synchronized team communication
- Webhooks & API: Powerful automation capabilities with external tools
- Project Tracking: Built-in analytics and progress monitoring
- Team Collaboration: Seamless commenting and discussion features
Scrapeless: Enterprise-Grade Data Extraction
Scrapeless delivers reliable, scalable data extraction across multiple sources:
- Google Search: Enables comprehensive extraction of Google SERP data across all result types.
- Google Trends: Retrieves keyword trend data from Google, including popularity over time, regional interest, and related searches.
- Universal Scraping API: Access and extract data from JS-Render websites that typically block bots.
- Crawl: Crawl a website and its linked pages to extract comprehensive data.
- Scrape: Extract information from a single webpage.
Claude AI: Intelligent Data Analysis
Claude AI transforms raw data into actionable insights:
- Advanced Reasoning: Sophisticated analysis and pattern recognition
- Structured Output: Clean, formatted responses perfect for Linear comments
- Context Awareness: Understands business context and user intent
- Actionable Insights: Delivers recommendations and next steps
- Data Synthesis: Combines multiple data sources into coherent analysis
Use Cases
Competitive Intelligence Command Center
Instant Competitor Research
- Market Position Analysis: Automated competitor website crawling and analysis
- Trend Monitoring: Track competitor mentions and brand sentiment shifts
- Product Launch Detection: Identify when competitors introduce new features
- Strategic Insights: AI-powered analysis of competitive positioning
Command Examples:
/search "competitor product launch" 2024
/trends competitor-brand-name
/crawl https://competitor.com/productsMarket Research Automation
Real-Time Market Intelligence
- Industry Trend Analysis: Automated Google Trends monitoring for market segments
- Consumer Sentiment: Search trend analysis for product categories
- Market Opportunity Identification: AI-powered market gap analysis
- Investment Research: Startup and industry funding trend analysis
Command Examples:
/trends "artificial intelligence market"
/search "SaaS startup funding 2024"
/crawl https://techcrunch.com/category/startupsProduct Development Research
Feature Research & Validation
- User Need Analysis: Search trend analysis for product features
- Technology Research: Automated documentation and API research
- Best Practice Discovery: Crawl industry leaders for implementation patterns
- Market Validation: Trend analysis for product-market fit assessment
Command Examples:
/search "user authentication best practices"
/trends "mobile app features"
/crawl https://docs.stripe.com/apiImplementation Guide
Step 1: Linear Workspace Setup
Prepare Your Linear Environment
-
Access Your Linear Workspace
- Navigate to linear.app and log into your workspace
- Ensure you have admin permissions for webhook configuration
- Create or select a project for research automation
-
Generate Linear API Token
- Go to Linear Settings > API > Personal API tokens
- Click "Create token" with appropriate permissions
- Copy the token for use in n8n configuration
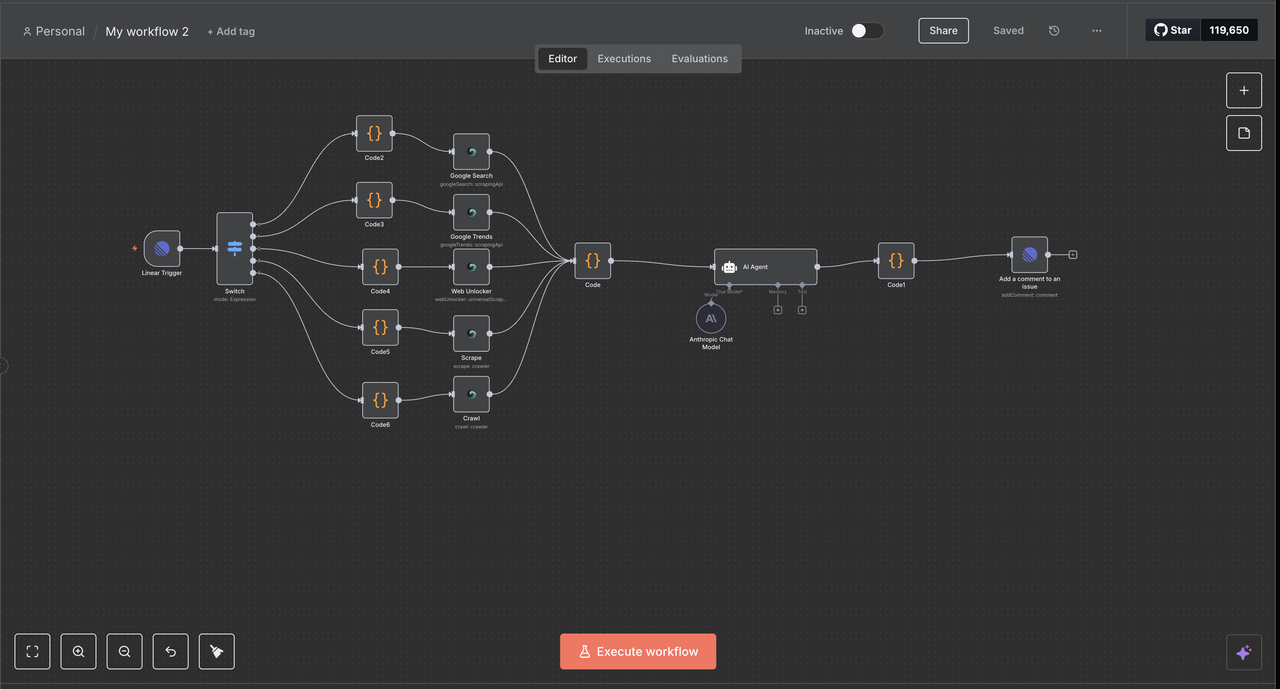
Step 2: n8n Workflow Setup
Create Your n8n Automation Environment
- Set Up n8n Instance
- Use n8n cloud or self-host (note: self-hosting requires ngrok setup; for this guide, we’ll use n8n cloud)
- Create a new workflow for the Linear integration
- Import the provided workflow JSON
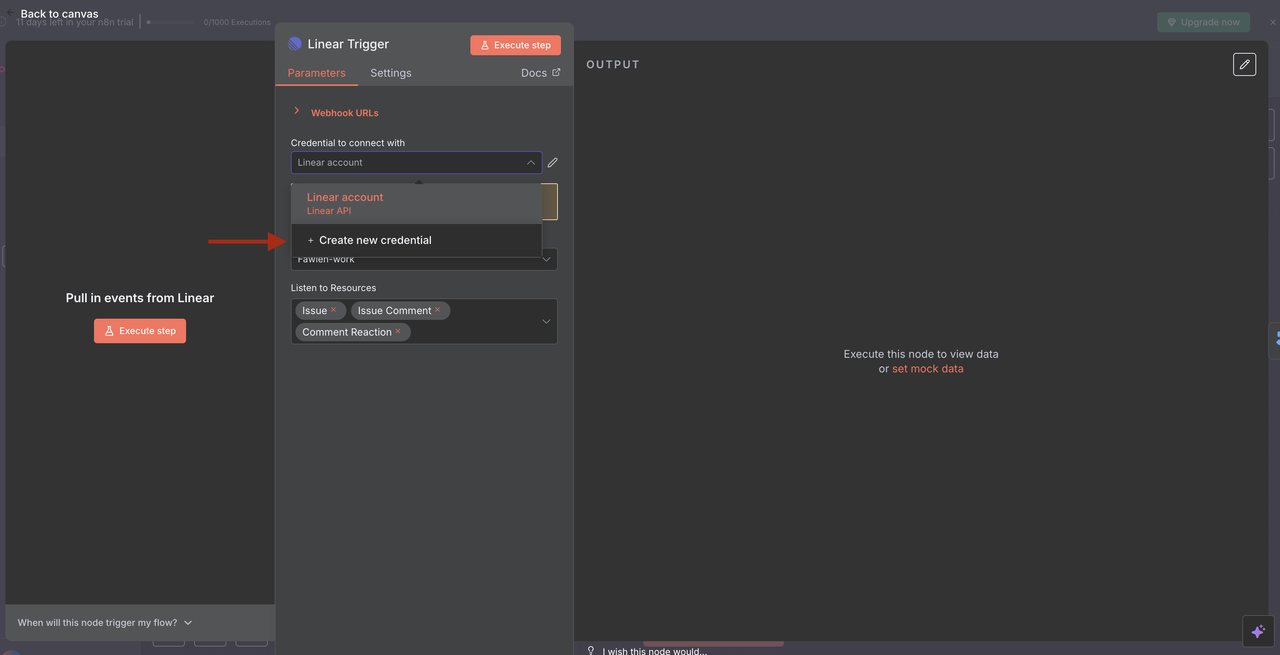
- Configure Linear Trigger
- Add Linear credentials using your API token
- Set up a webhook to listen for issue events
- Configure the team ID and apply resource filters as needed
Step 3: Scrapeless Integration Setup
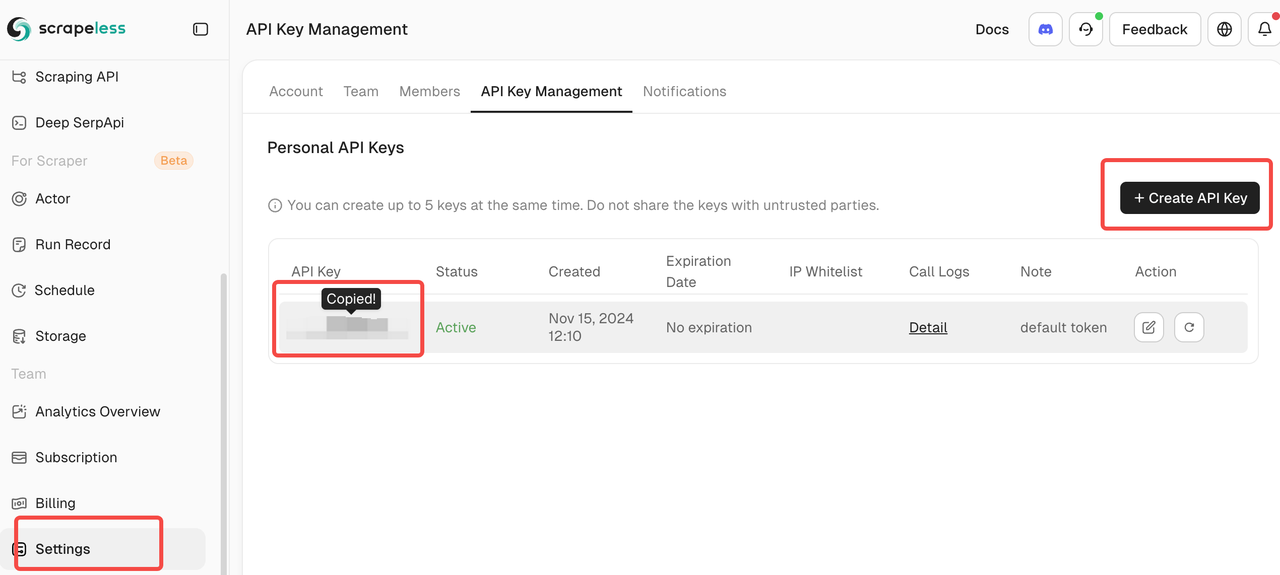
Connect Your Scrapeless Account
- Get Scrapeless Credentials
- Sign up at scrapeless.com
- Navigate to Dashboard > API Keys
- Copy your API token for n8n configuration
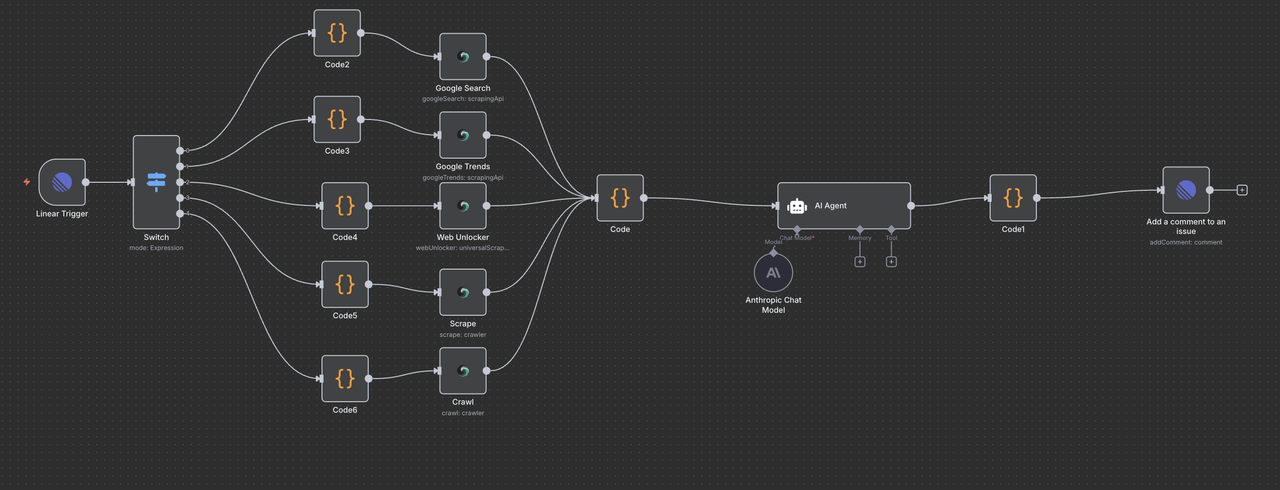
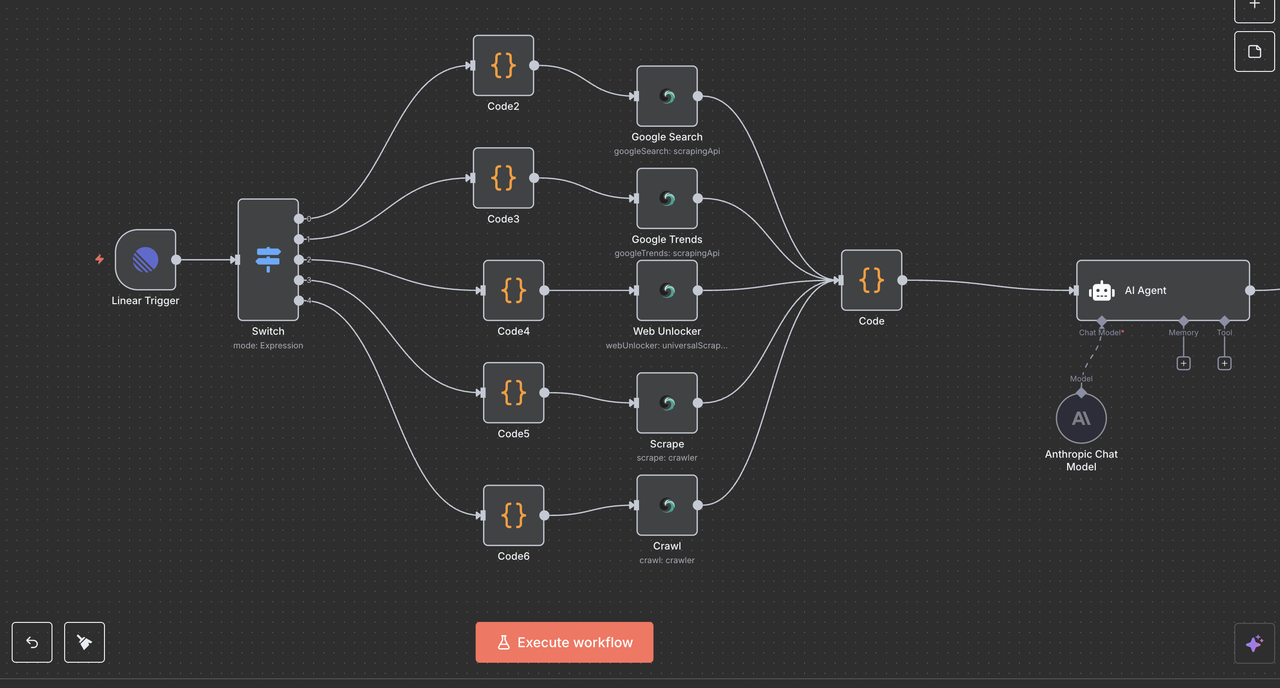
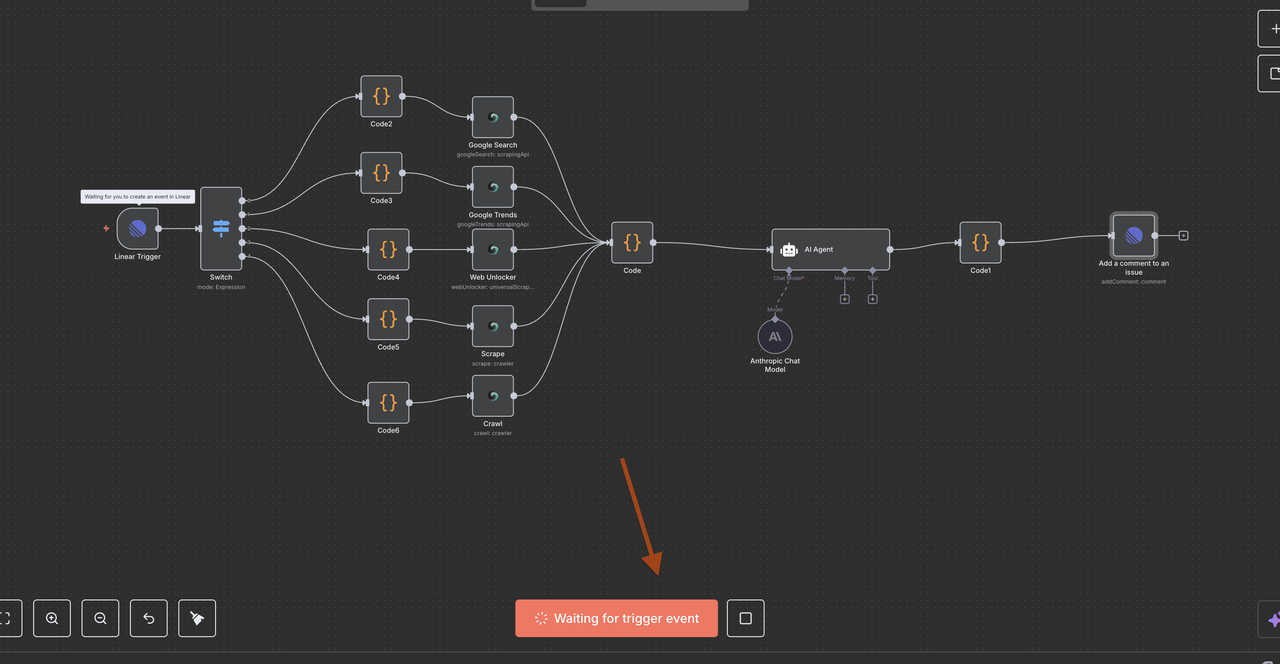
Understanding the Workflow Architecture
Let’s walk through each component of the workflow step by step, explaining what each node does and how they work together.
Step 4: Linear Trigger Node (Entry Point)
The Starting Point: Linear Trigger
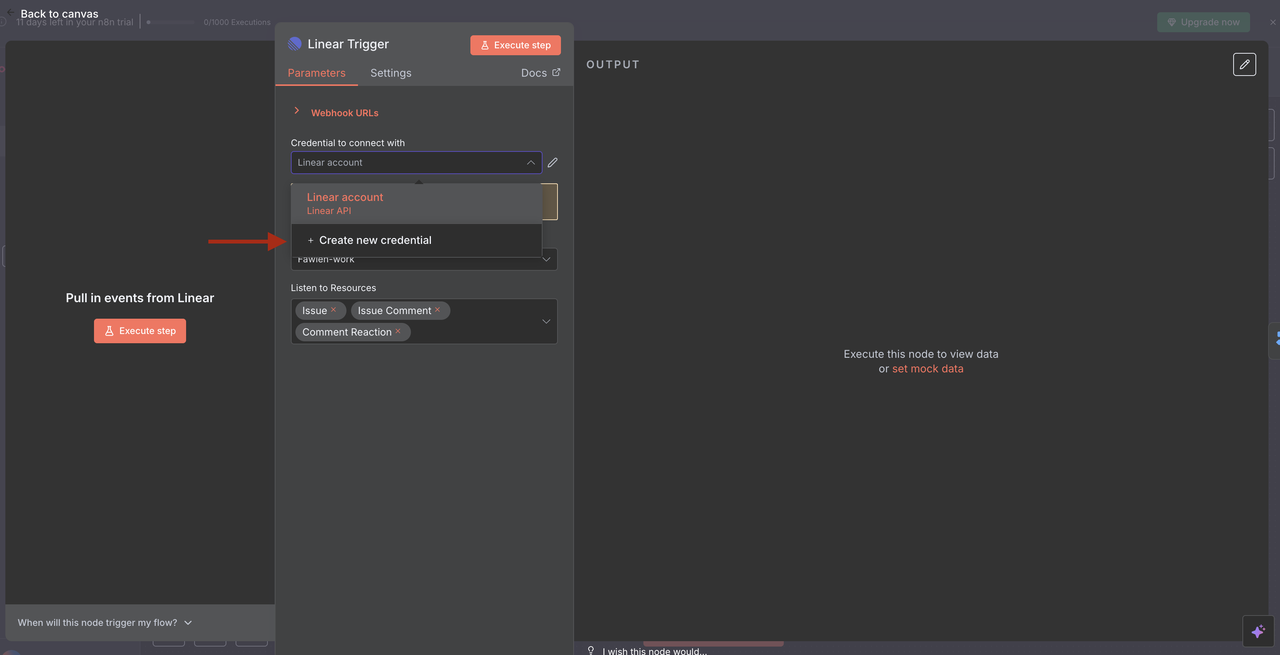
The Linear Trigger is the entry point of our workflow. This node:
What it does:
- Listens for webhook events from Linear whenever issues are created or updated
- Captures the complete issue data including title, description, team ID, and other metadata
- Only triggers when specific events occur (e.g., Issue created, Issue updated, Comment created)
Configuration Details:
- Team ID: Links to your specific Linear workspace team
- Resources: Set to monitor
issue,comment, andreactionevents - Webhook URL: Automatically generated by n8n and must be added to Linear's webhook settings
Why it's essential:
This node transforms your Linear issues into automation triggers.
For example, when someone types /search competitor analysis in an issue title, the webhook sends that data to n8n in real time.
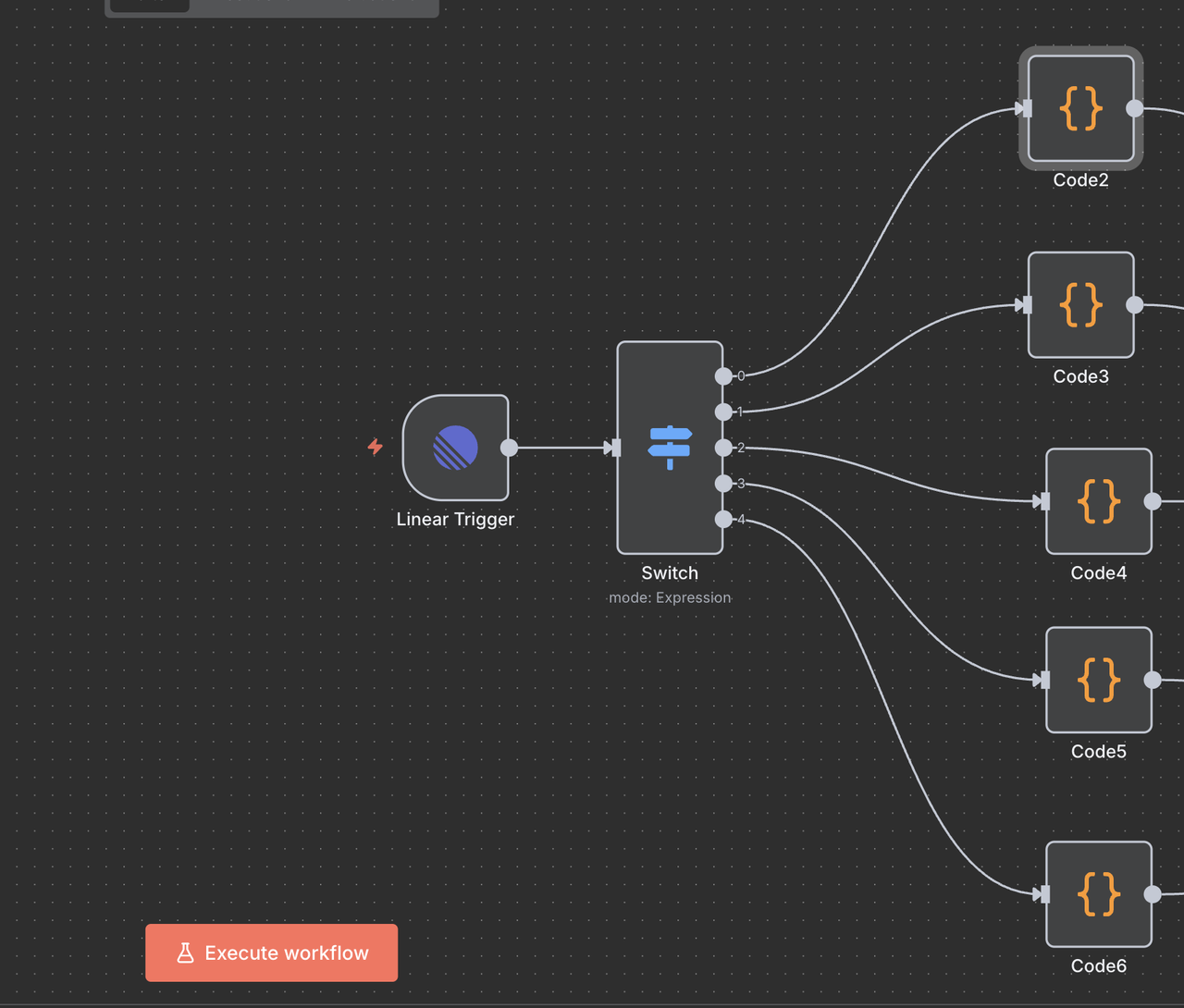
Step 5: Switch Node (Command Router)
Intelligent Command Detection and Routing
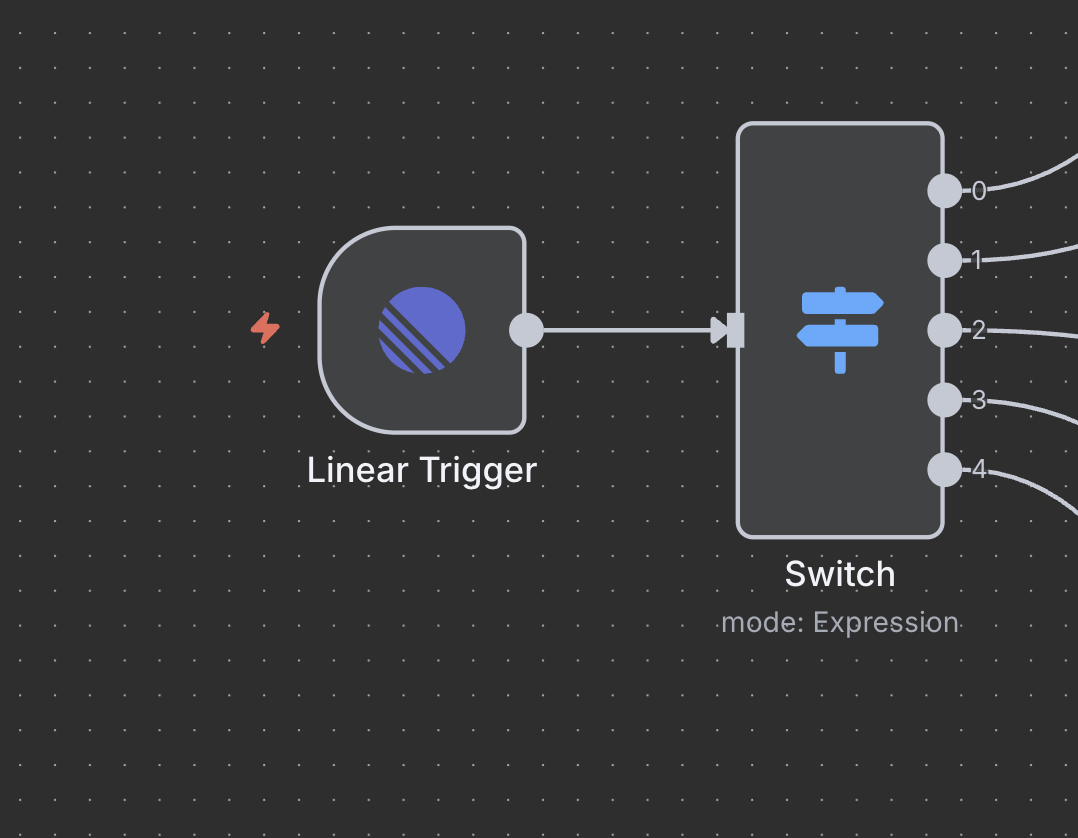
The Switch node acts as the “brain” that determines what type of research to perform based on the command in the issue title.
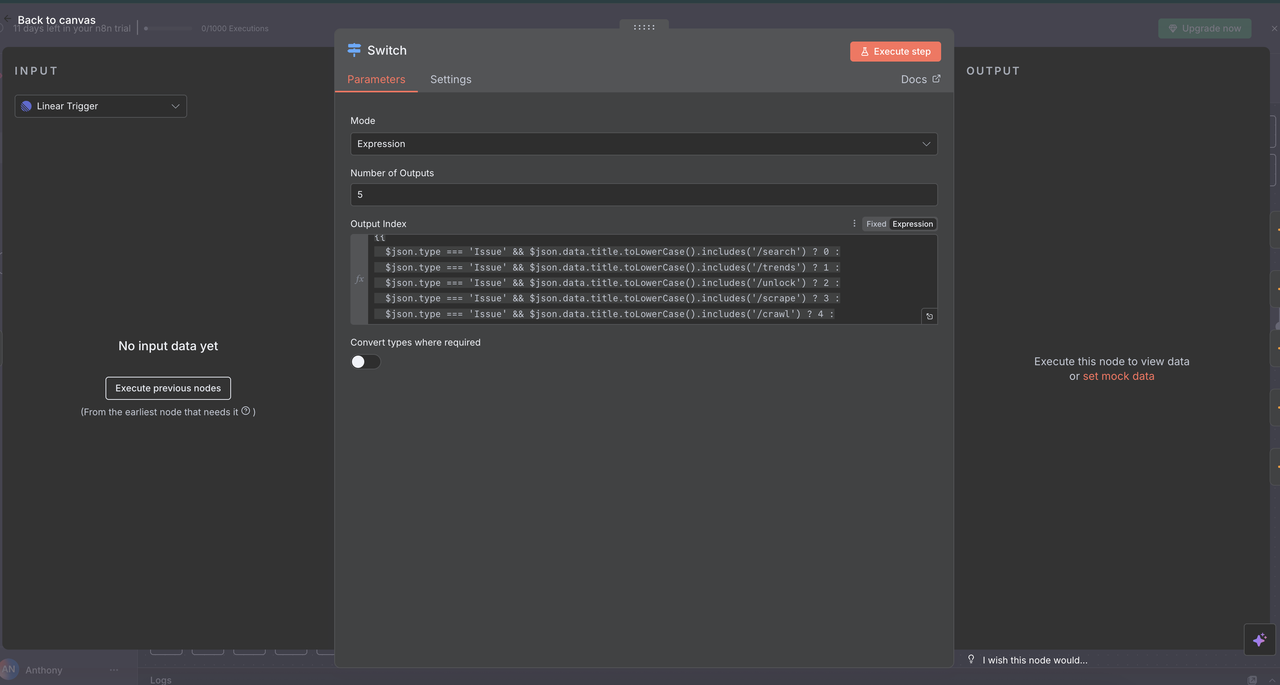
How it works:
// Command detection and routing logic
{
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/search') ? 0 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/trends') ? 1 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/unlock') ? 2 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/scrape') ? 3 :
$json.type === 'Issue' && $json.data.title.toLowerCase().includes('/crawl') ? 4 :
-1
}Route Explanations
- Output 0 (
/search): Routes to Google Search API for web search results - Output 1 (
/trends): Routes to Google Trends API for trend analysis - Output 2 (
/unlock): Routes to Web Unlocker for protected content access - Output 3 (
/scrape): Routes to Scraper for single-page content extraction - Output 4 (
/crawl): Routes to Crawler for multi-page website crawling - Output -1: No command detected, workflow ends automatically
Switch Node Configuration
- Mode: Set to
"Expression"for dynamic routing - Number of Outputs:
5(one for each command type) - Expression: JavaScript code determines routing logic
Step 6: Title Cleaning Code Nodes
Preparing Commands for API Processing
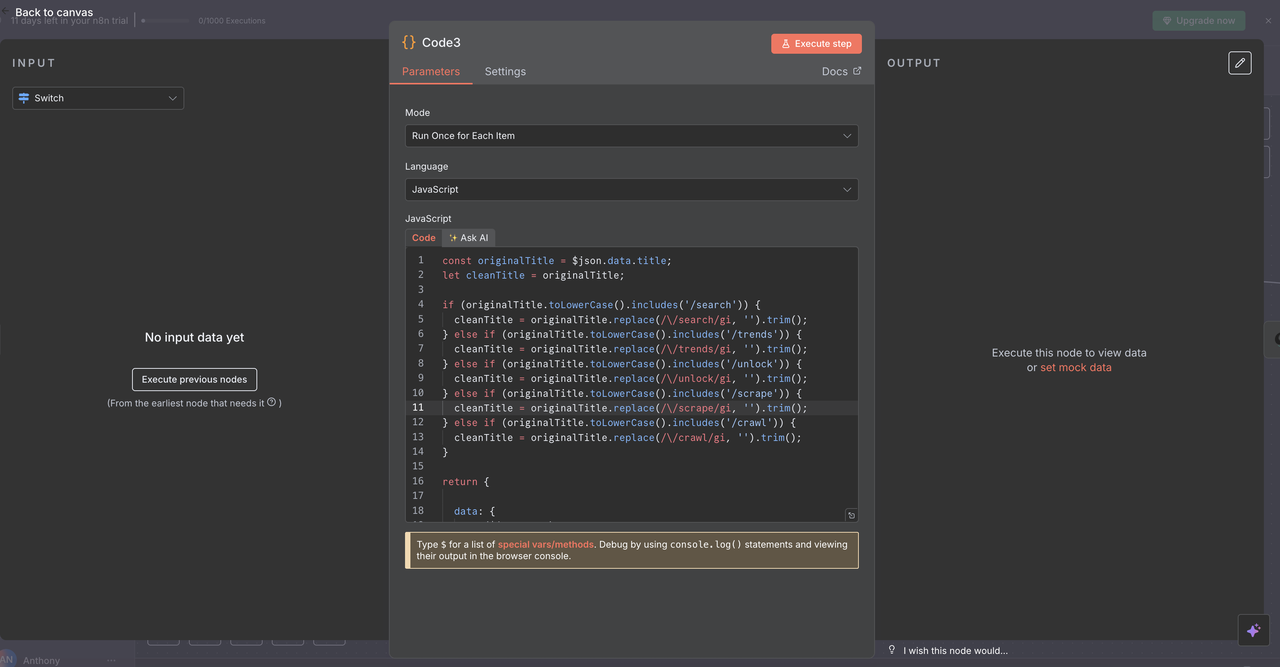
Each route includes a Code Node that cleans the command from the issue title before calling Scrapeless APIs.
What each Code Node does:
js
// Clean command from title for API processing
const originalTitle = $json.data.title;
let cleanTitle = originalTitle;
// Remove command prefixes based on detected command
if (originalTitle.toLowerCase().includes('/search')) {
cleanTitle = originalTitle.replace(/\/search/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/trends')) {
cleanTitle = originalTitle.replace(/\/trends/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/unlock')) {
cleanTitle = originalTitle.replace(/\/unlock/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/scrape')) {
cleanTitle = originalTitle.replace(/\/scrape/gi, '').trim();
} else if (originalTitle.toLowerCase().includes('/crawl')) {
cleanTitle = originalTitle.replace(/\/crawl/gi, '').trim();
}
return {
data: {
...($json.data),
title: cleanTitle
}
};
Example Transformations
/search competitor analysis→competitor analysis/trends AI market growth→AI market growth/unlock https://example.com→https://example.com
Why This Step Matters
The Scrapeless APIs need clean queries without command prefixes to function properly.
This ensures that the data sent to the APIs is precise and interpretable, improving automation reliability.
Step 7: Scrapeless Operation Nodes
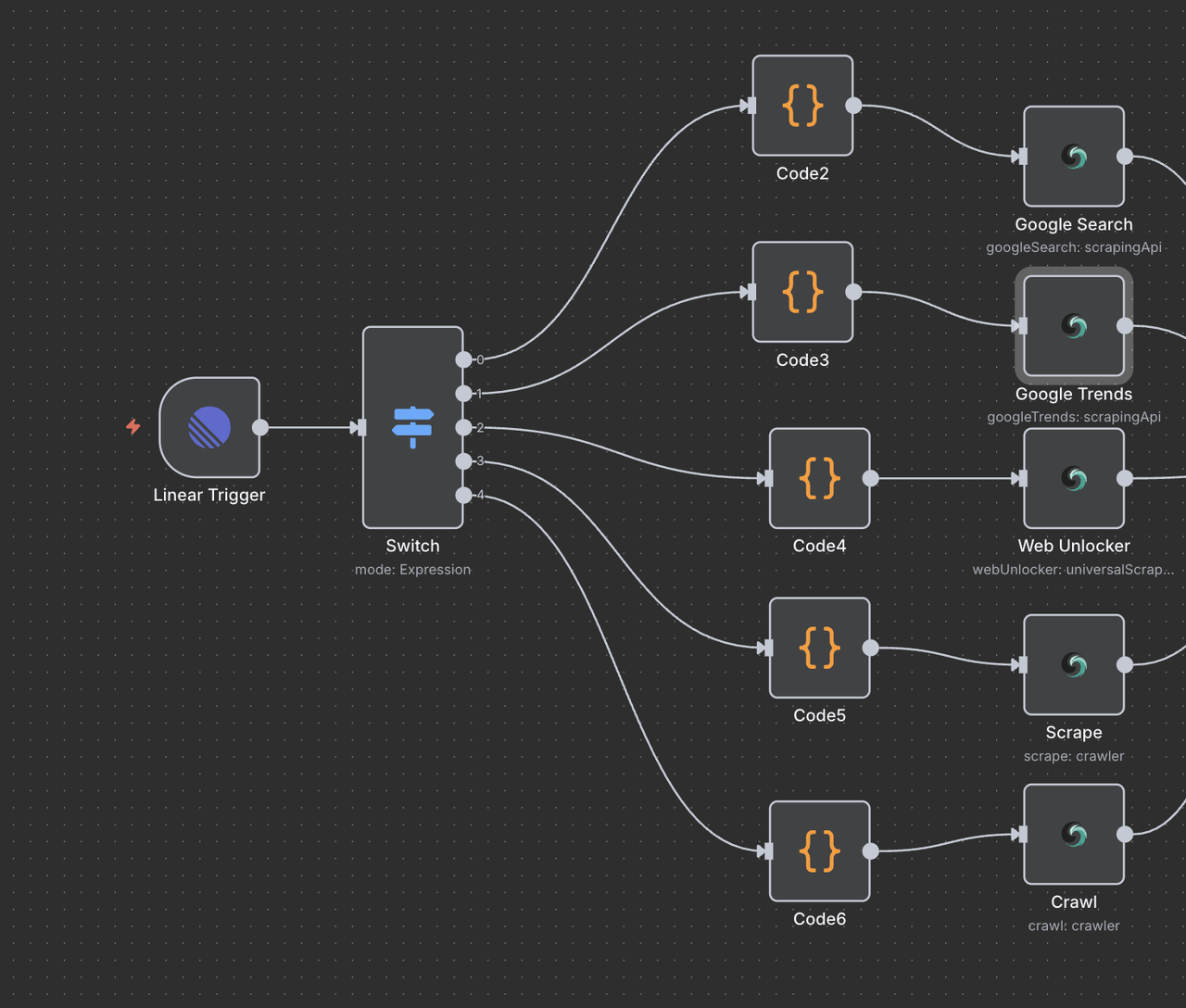
This section walks through each Scrapeless operation node and explains its function.
7.1 Google Search Node (/search command)
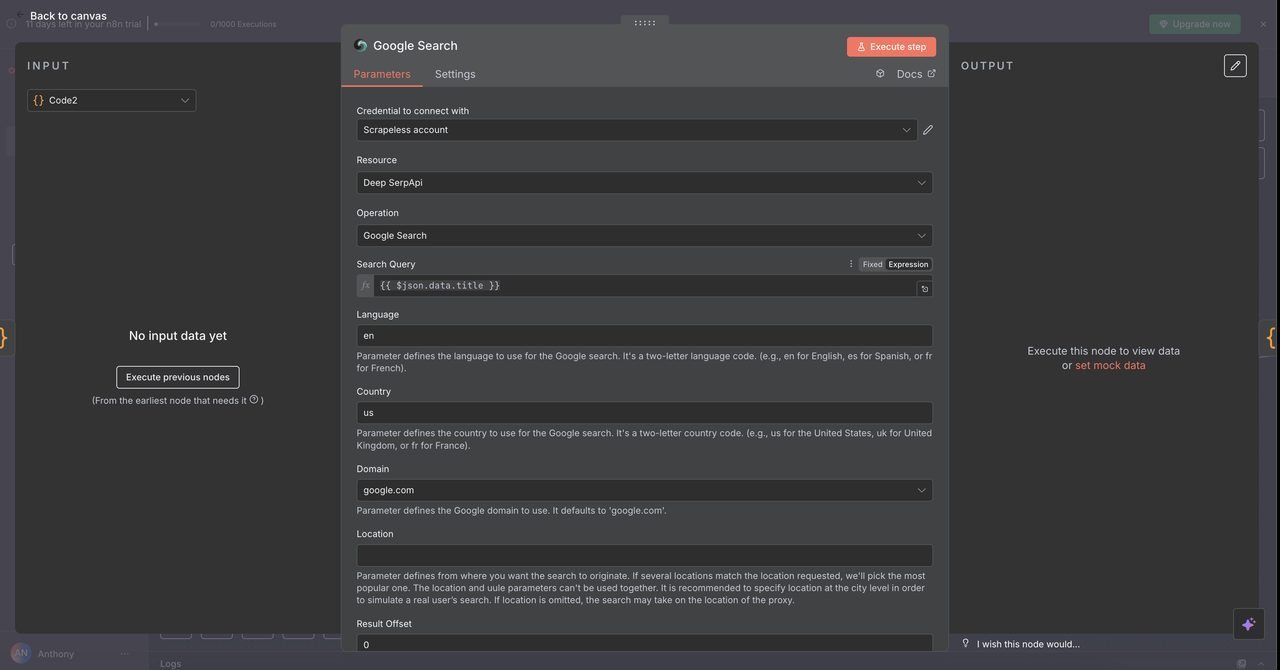
Purpose:
Performs Google web searches and returns organic search results.
Configuration:
- Operation:
Search Google(default) - Query:
{{ $json.data.title }}(cleaned title from the previous step) - Country:
"US"(can be customized per locale) - Language:
"en"(English)
What It Returns:
- Organic search results: Titles, URLs, and snippets
- "People also ask" related questions
- Metadata: Estimated results count, search duration
Use Cases:
- Research competitor products
/search competitor pricing strategy
- Find industry reports
/search SaaS market report 2024
- Discover best practices
/search API security best practices
7.2 Google Trends Node (/trends command)
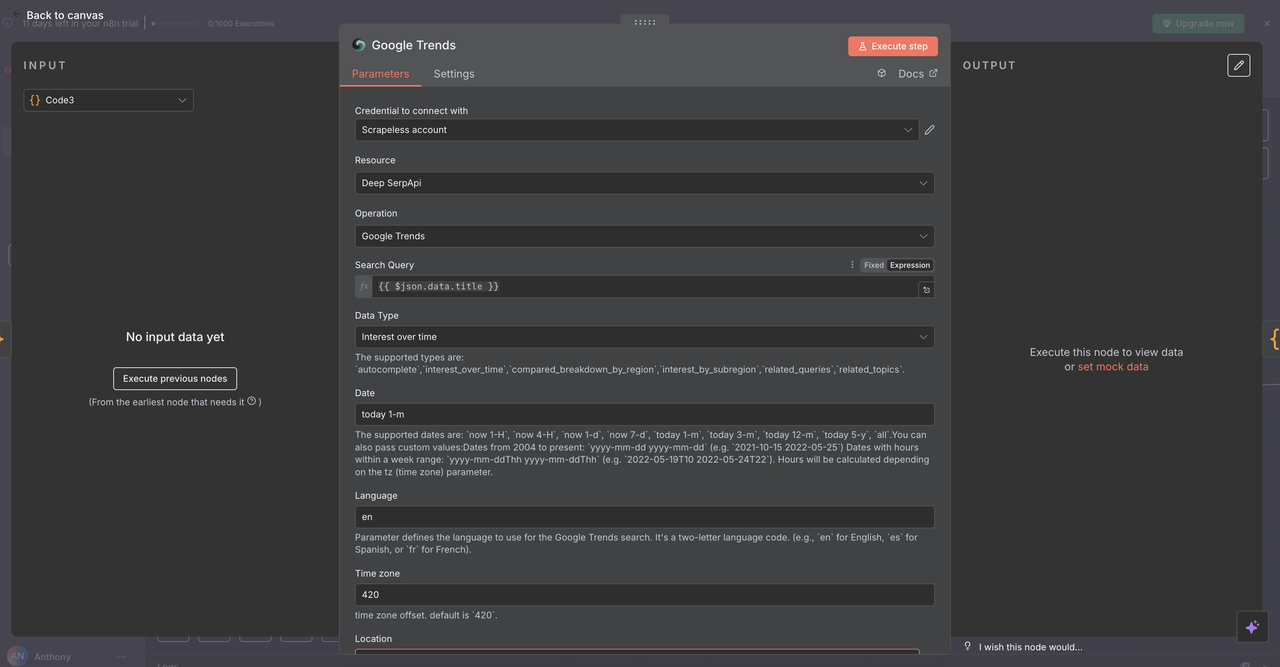
Purpose:
Analyzes search trend data and interest over time for specific keywords.
Configuration:
- Operation:
Google Trends - Query:
{{ $json.data.title }}(cleaned keyword or phrase) - Time Range: Choose from options like 1 month, 3 months, 1 year
- Geographic: Set to
Globalor specify a region
What It Returns:
- Interest-over-time chart (0–100 scale)
- Related queries and trending topics
- Geo-distribution of interest
- Category breakdowns for trend context
Use Cases:
- Market validation
/trends electric vehicle adoption - Seasonal analysis
/trends holiday shopping trends - Brand monitoring
/trends company-name mentions
7.3 Web Unlocker Node (/unlock command)
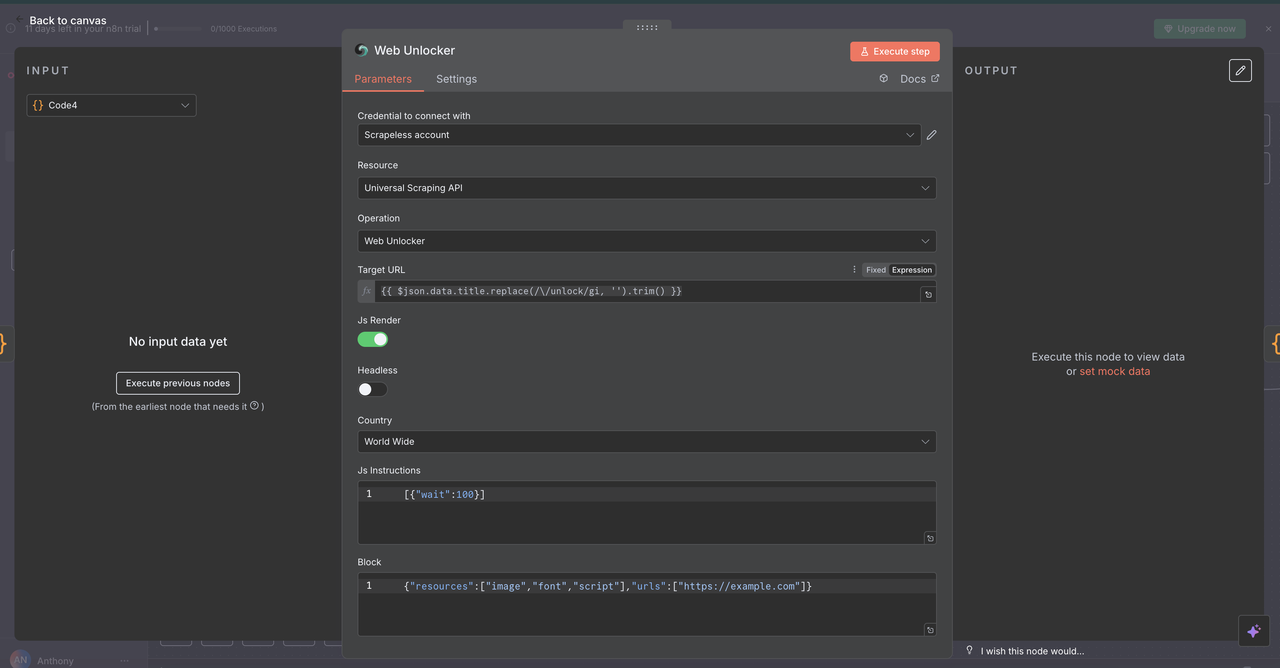
Purpose:
Access content from websites protected by anti-bot mechanisms or paywalls.
Configuration:
- Resource:
Universal Scraping API - URL:
{{ $json.data.title }}(must contain a valid URL) - Headless:
false(for better anti-bot compatibility) - JavaScript Rendering:
enabled(for full dynamic content loading)
What It Returns:
- Complete HTML content of the page
- JavaScript-rendered final content
- Ability to bypass common anti-bot protections
Use Cases:
- Competitor pricing analysis
/unlock https://competitor.com/pricing - Access gated research
/unlock https://research-site.com/report - Scrape dynamic apps
/unlock https://spa-application.com/data
7.4 Scraper Node (/scrape command)
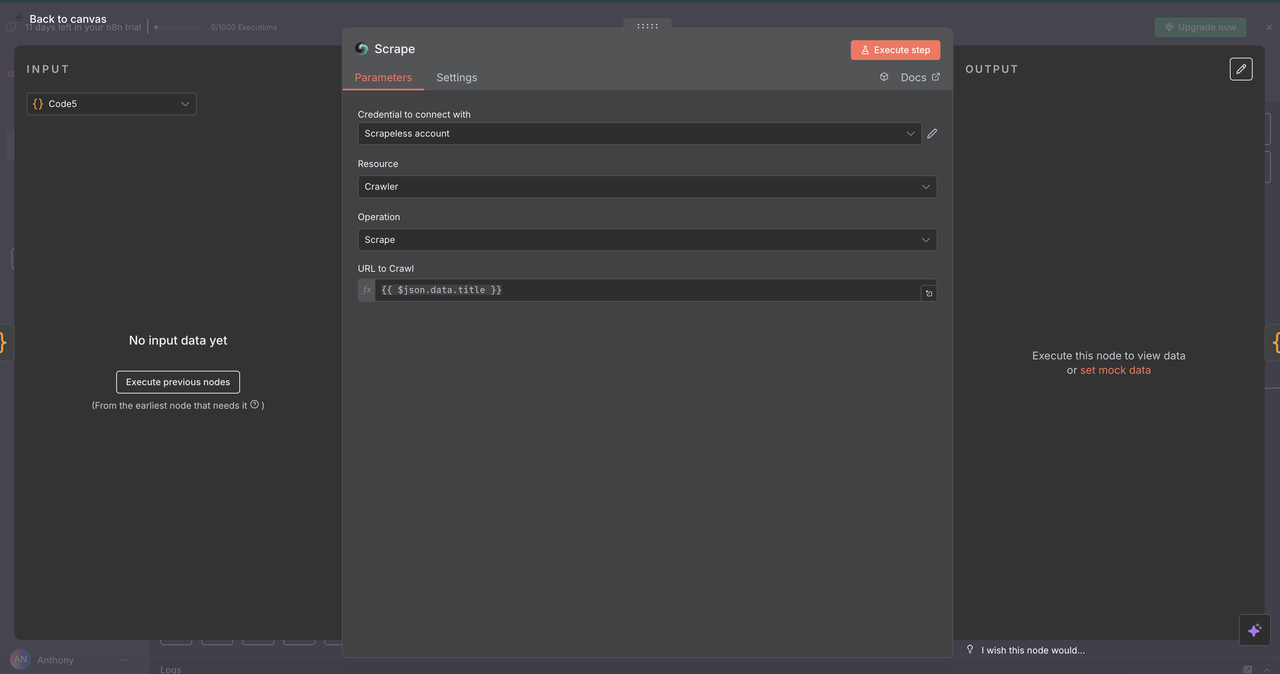
Purpose:
Extract structured content from a single webpage using selectors or default parsing.
Configuration:
- Resource:
Crawler(used here for single-page scraping) - URL:
{{ $json.data.title }}(target webpage) - Format: Choose output as
HTML,Text, orMarkdown - Selectors: Optional CSS selectors to target specific content
What It Returns:
- Structured, clean text from the page
- Page metadata (title, description, etc.)
- Excludes navigation/ads by default
Use Cases:
- News article extraction
/scrape https://news-site.com/article - API docs parsing
/scrape https://api-docs.com/endpoint - Product info capture
/scrape https://product-page.com/item
7.5 Crawler Node (/crawl command)
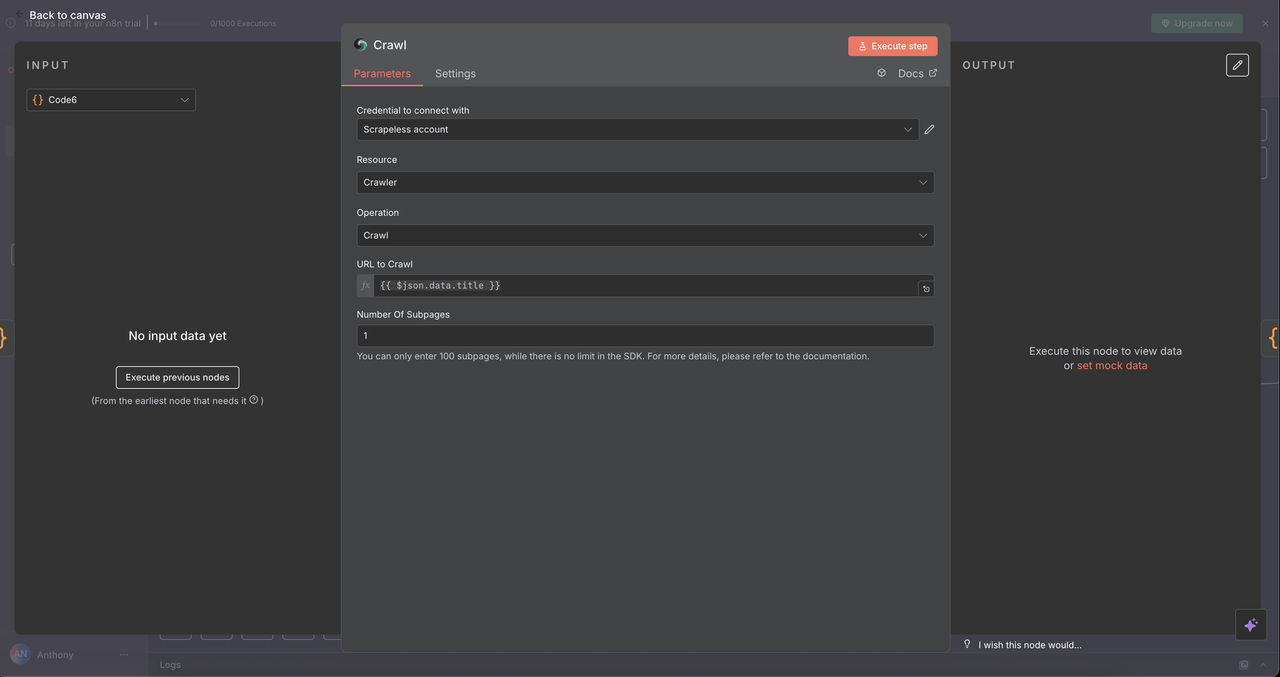
Purpose:
Systematically crawls multiple pages of a website for comprehensive data extraction.
Configuration:
- Resource:
Crawler - Operation:
Crawl - URL:
{{ $json.data.title }}(starting point URL) - Limit Crawl Pages: Optional cap, e.g. 5–10 pages to avoid overload
- Include/Exclude Patterns: Regex or string filters to refine crawl scope
What It Returns:
- Content from multiple related pages
- Navigation structure of the site
- Rich dataset across target domain/subsections
Use Cases:
-
Competitor Research
/crawl https://competitor.com
(e.g. pricing, features, about pages) -
Documentation Mapping
/crawl https://docs.api.com
(crawl entire API or developer documentation) -
Content Audits
/crawl https://blog.company.com
(map articles, categories, tags for SEO review)
Step 8: Data Convergence and Processing
Bringing All Scrapeless Results Together
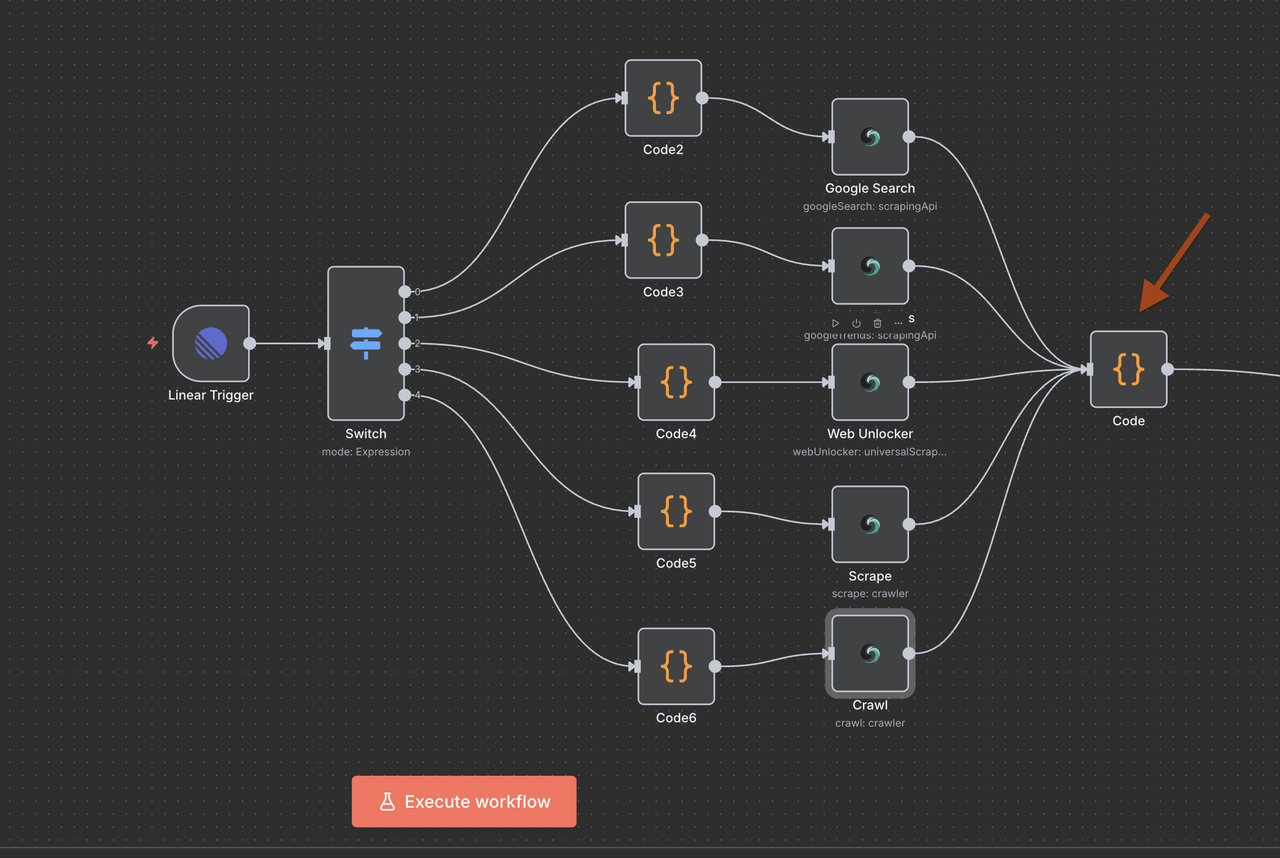
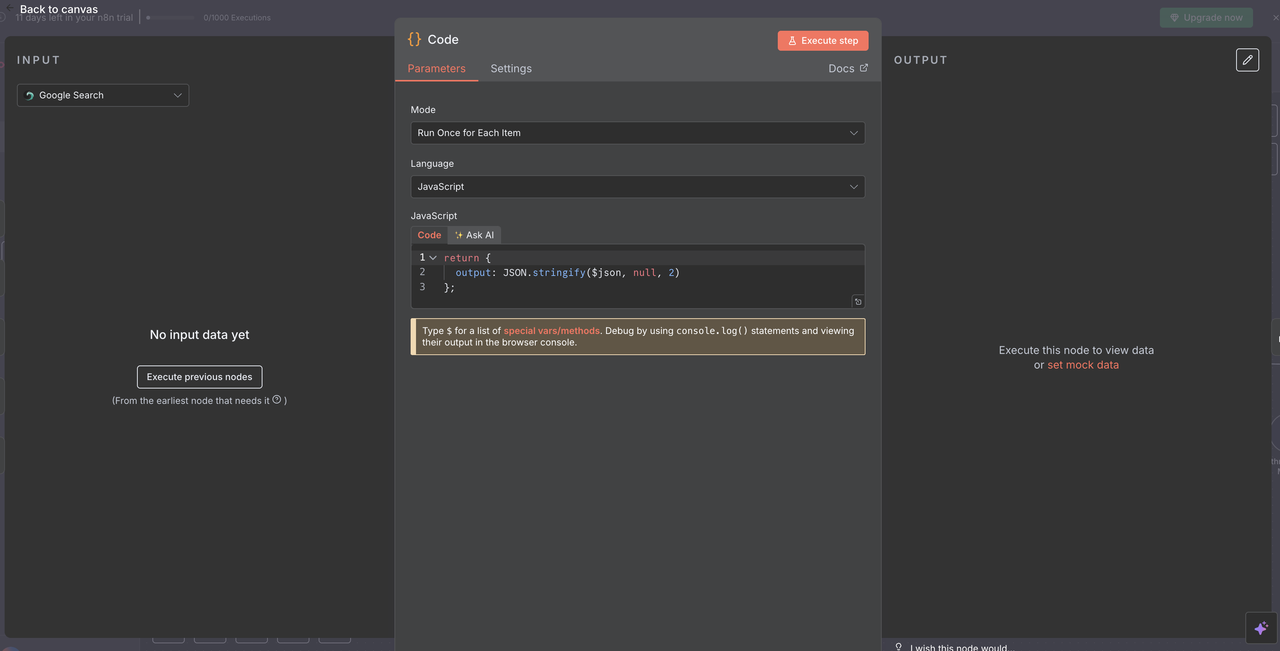
After executing one of the 5 Scrapeless operation branches, a single Code Node is used to normalize the response for AI processing.
Purpose of the Convergence Code Node:
- Aggregates output from any of the Scrapeless nodes
- Normalizes the data format across all commands
- Prepares final payload for Claude or other AI model input
Code Configuration:
javascript
// Convert Scrapeless response to AI-readable format
return {
output: JSON.stringify($json, null, 2)
};
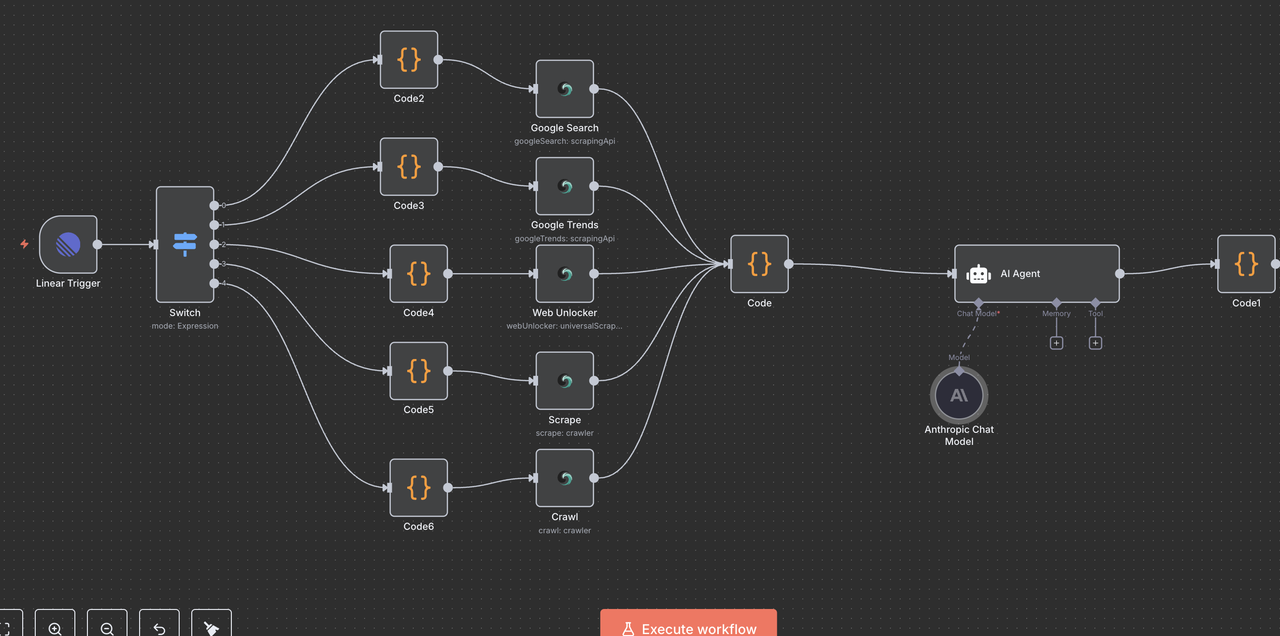
Step 9: Claude AI Analysis Engine
Intelligent Data Analysis and Insight Generation
9.1 AI Agent Node Setup
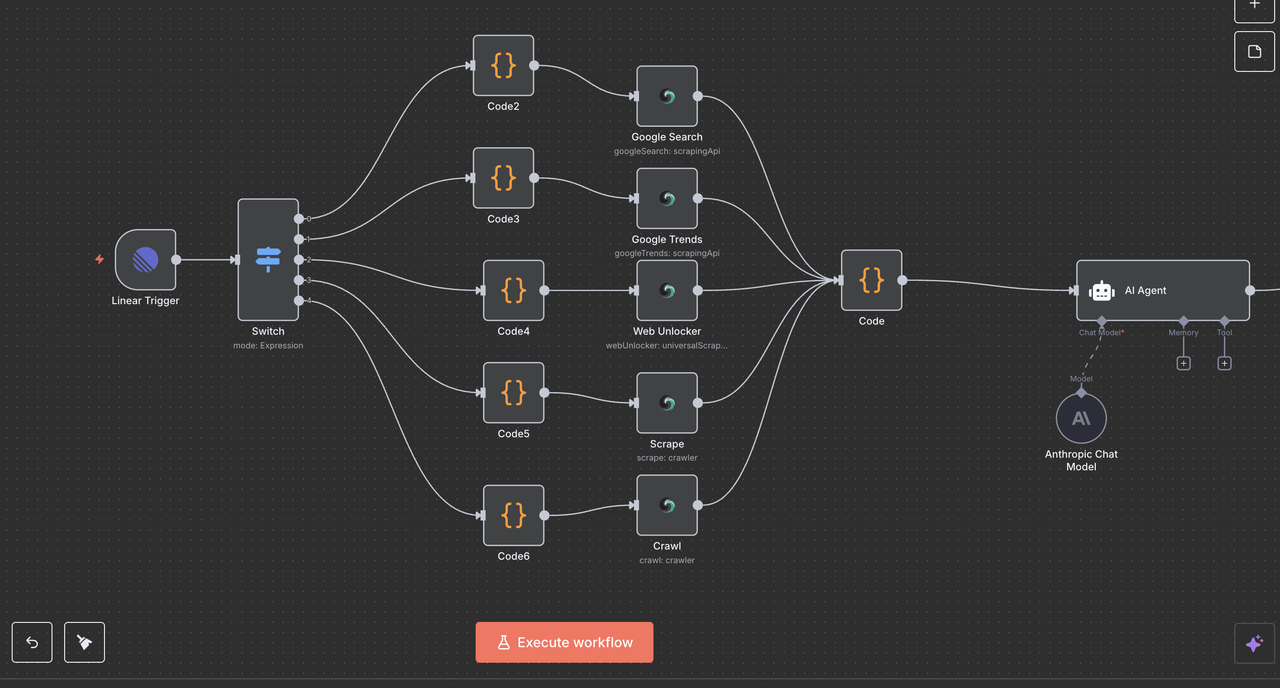
⚠️ Don't forget to set up your API key for Claude.
The AI Agent Node is where the magic happens — it takes the normalized Scrapeless output and transforms it into clear, actionable insights suitable for use in Linear comments or other reporting tools.
Configuration Details:
- Prompt Type:
Define - Text Input:
{{ $json.output }}(processed JSON string from the convergence node) - System Message: Sets the tone, role, and task for Claude
AI Analysis System Prompt:
You are a data analyst. Summarize search/scrape results concisely. Be factual and brief. Format for Linear comments.
Analyze the provided data and create a structured summary that includes:
- Key findings and insights
- Data source and reliability assessment
- Actionable recommendations
- Relevant metrics and trends
- Next steps for further research
Format your response with clear headers and bullet points for easy reading in Linear.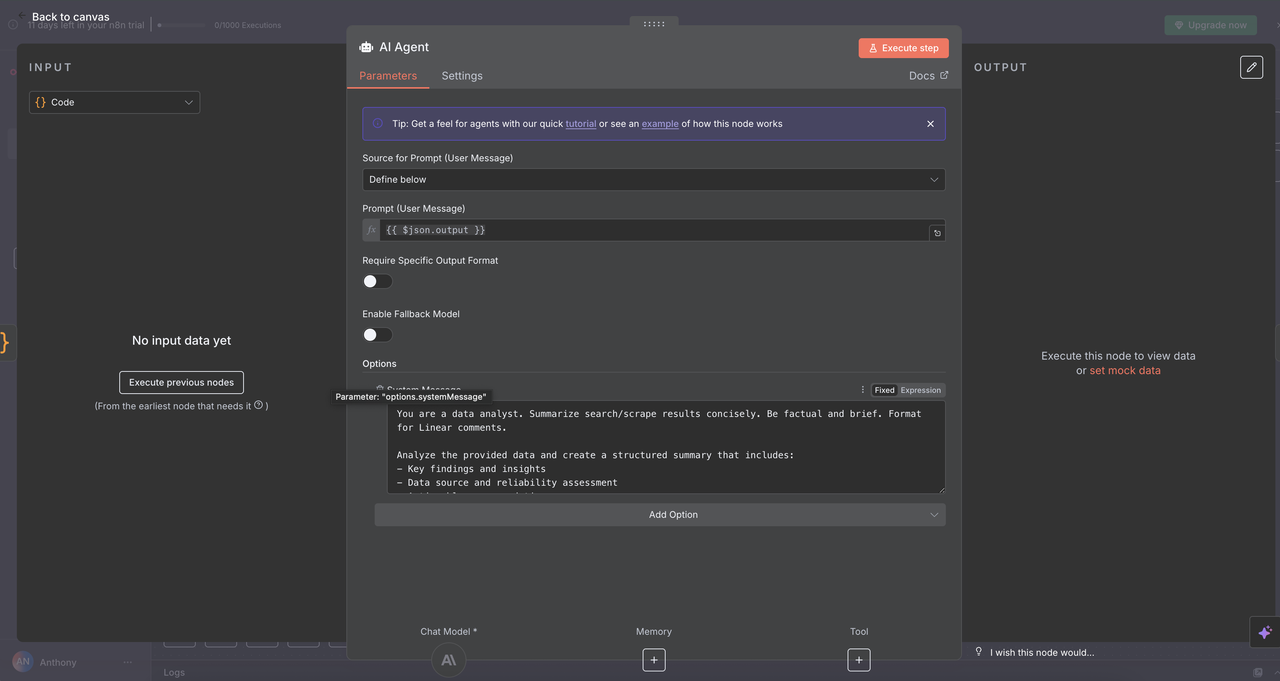
Why this Prompt Works
- Specificity: Tells Claude exactly what type of analysis to perform
- Structure: Requests organized output with clear sections
- Context: Optimized for Linear comment formatting
- Actionability: Focuses on insights that teams can act upon
9.2 Claude Model Configuration
The Anthropic Chat Model Node connects the AI Agent to Claude's powerful language processing.
Model Selection and Parameters
- Model:
claude-3-7-sonnet-20250219(Claude Sonnet 3.7) - Temperature:
0.3(balanced between creativity and consistency) - Max Tokens:
4000(enough for comprehensive responses)
Why These Settings
- Claude Sonnet 3.7: A strong balance of intelligence, performance, and cost-efficiency
- Low Temperature (0.3): Ensures factual, repeatable responses
- 4000 Tokens: Sufficient for in-depth insight generation without excessive cost
Step 10: Response Processing and Cleanup
Preparing Claude's Output for Linear Comments
10.1 Response Cleaning Code Node
The Code Node after Claude cleans up the AI response for proper display in Linear comments.
Response Cleaning Code:
// Clean Claude AI response for Linear comments
return {
output: $json.output
.replace(/\\n/g, '\n')
.replace(/\\\"/g, '"')
.replace(/\\\\/g, '\\')
.trim()
};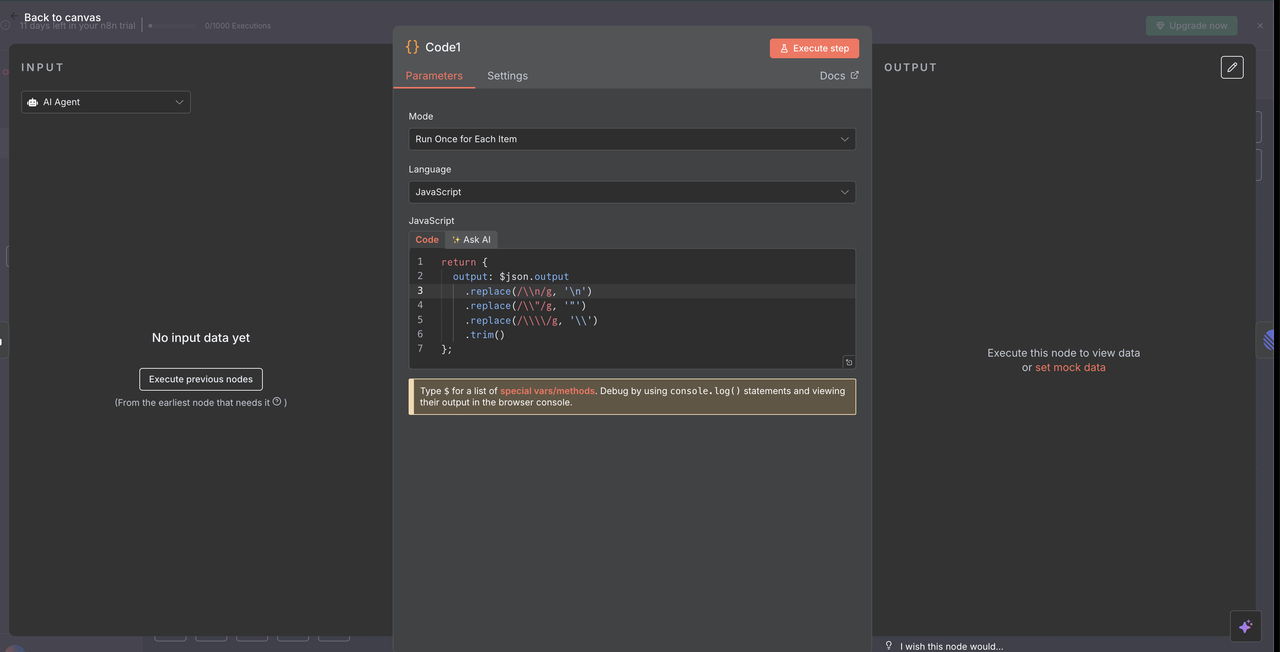
What This Cleaning Accomplishes
- Escape Character Removal: Removes JSON escape characters that would otherwise display incorrectly
- Line Break Fixing: Converts literal
\nstrings into actual line breaks - Quote Normalization: Ensures quotes render properly in Linear comments
- Whitespace Trimming: Removes unnecessary leading and trailing spaces
Why Cleaning Is Necessary
- Claude's output is delivered as JSON which escapes special characters
- Linear's markdown renderer requires properly formatted plain text
- Without this cleaning step, the response would show raw escape characters, hurting readability
10.2 Linear Comment Delivery
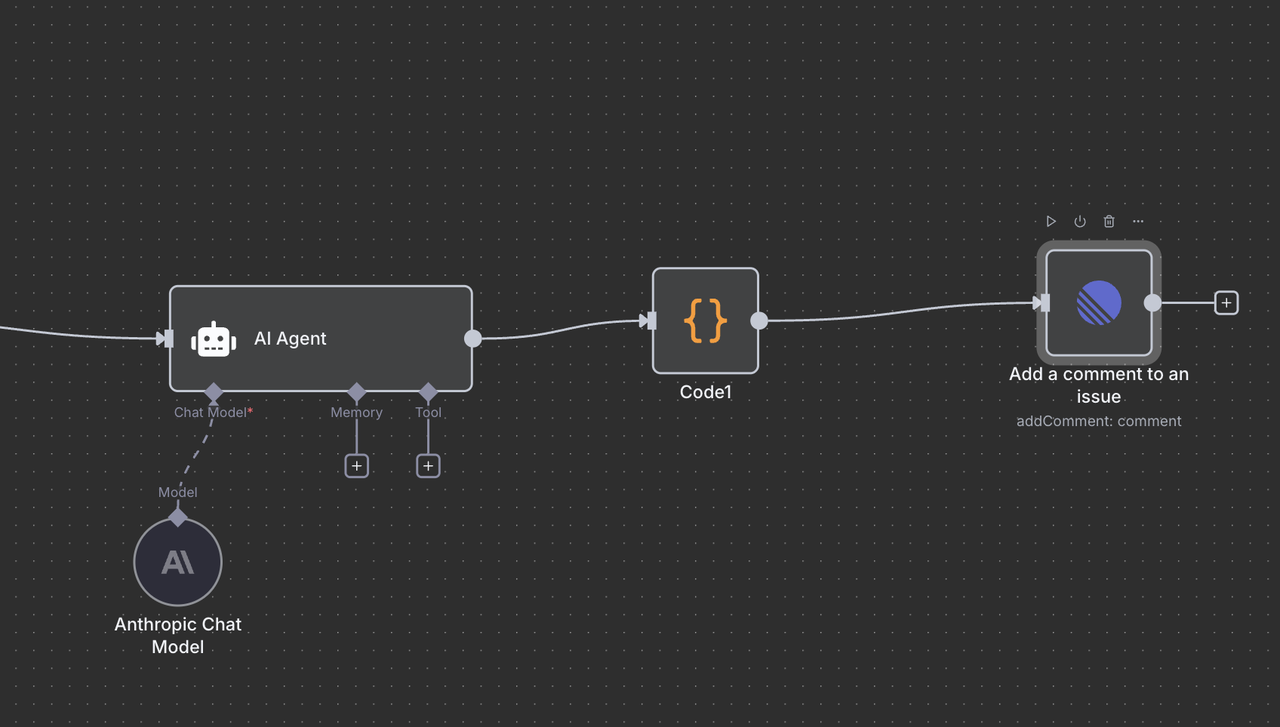
The final Linear Node posts the AI-generated analysis as a comment back to the original issue.
Configuration Details:
- Resource: Set to
"Comment"operation - Issue ID:
{{ $('Linear Trigger').item.json.data.id }} - Comment:
{{ $json.output }} - Additional Fields: Optionally include metadata or formatting options
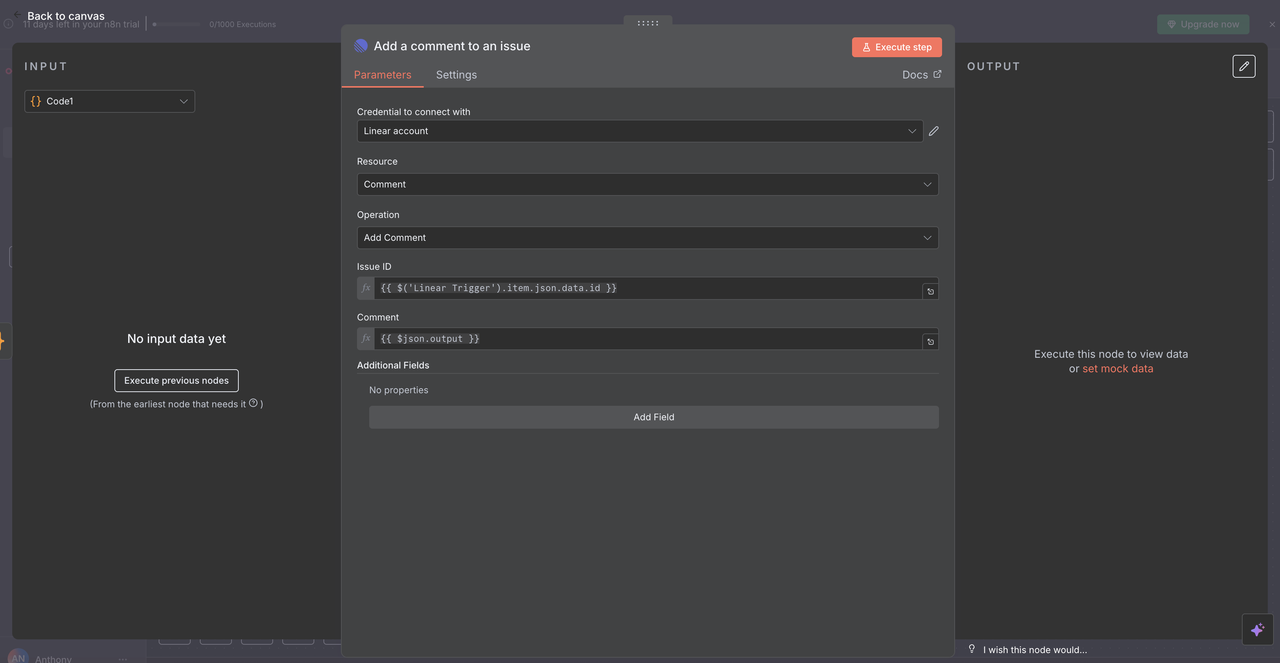
How the Issue ID Works
- References the original Linear Trigger node
- Uses the exact issue ID from the webhook that started the workflow
- Ensures the AI response appears on the correct Linear issue
The Complete Circle
- User creates an issue with
/search competitive analysis - Workflow processes the command and gathers data
- Claude analyzes the collected results
- Analysis is posted back as a comment on the same issue
- Team sees the research insights directly in context
Step 11: Testing Your Research Assistant
Validate Complete Workflow
Now that all nodes are configured, test each command type to ensure proper functionality.
11.1 Test Each Command Type
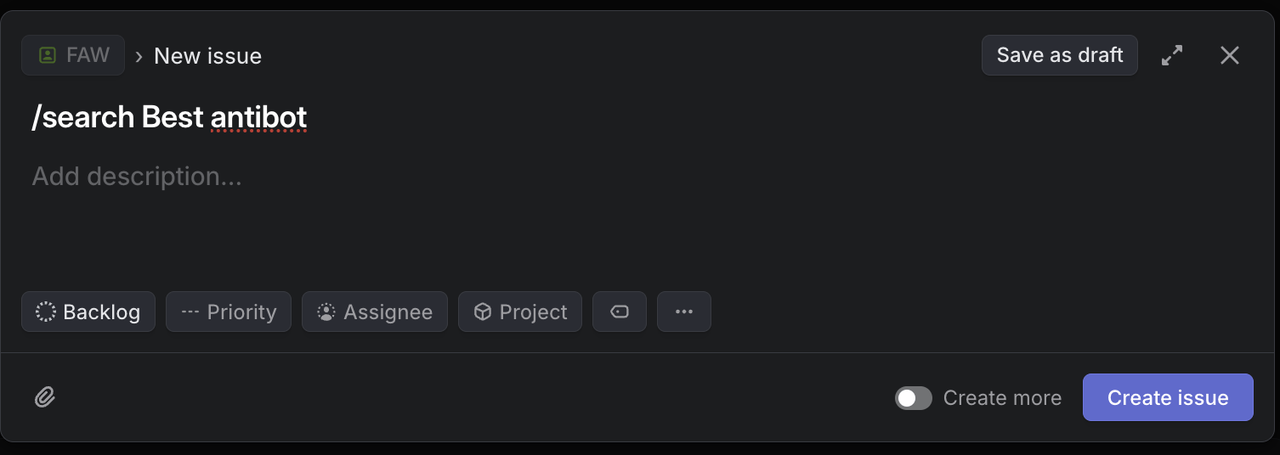
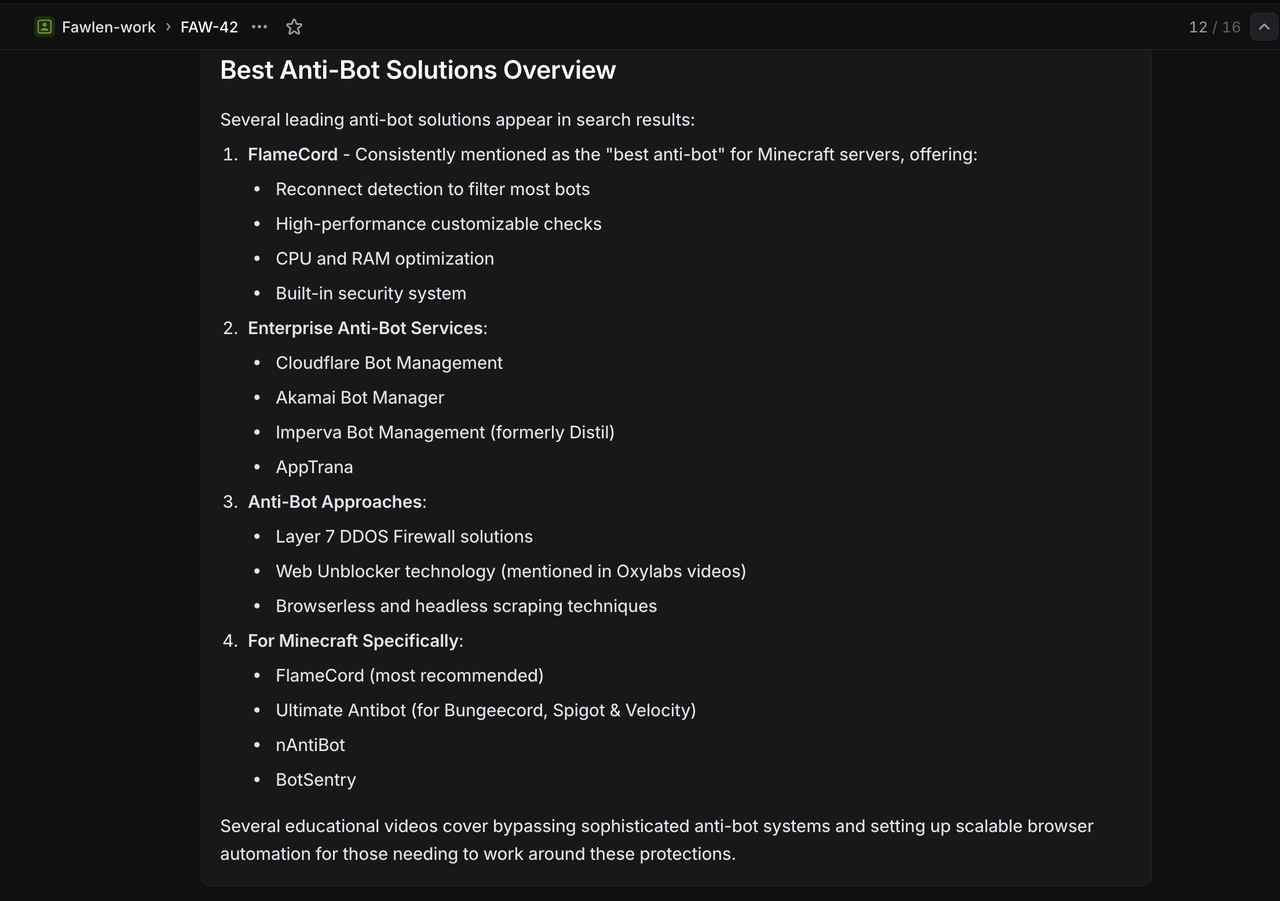
Create Test Issues in Linear with These Specific Titles:
Google Search Test:
`/search competitive analysis for SaaS platforms` Expected Result: Returns Google search results about SaaS competitive analysis
Google Trends Test:
`/trends artificial intelligence adoption` Expected Result: Returns trend data showing AI adoption interest over time
Web Unlocker Test:
`/unlock https://competitor.com/pricing` Expected Result: Returns content from a protected or JavaScript-heavy pricing page
Scraper Test:
`/scrape https://news.ycombinator.com` Expected Result: Returns structured content from the Hacker News homepage
Crawler Test:
`/crawl https://docs.anthropic.com` Expected Result: Returns content from multiple pages of Anthropic's documentation
Troubleshooting Guide
Linear Webhook Problems
- Issue: Webhook not triggering
- Solution: Verify webhook URL and Linear permissions
- Check: n8n webhook endpoint status
Scrapeless API Errors
- Issue: Authentication failures
- Solution: Verify API keys and account limits
- Check: Scrapeless dashboard for usage metrics
Claude AI Response Issues
- Issue: Poor or incomplete analysis
- Solution: Refine system prompts and context
- Check: Input data quality and formatting
Linear Comment Formatting
- Issue: Broken markdown or formatting
- Solution: Update response cleaning code
- Check: Special character handling
Conclusion
The combination of Linear's collaborative workspace, Scrapeless's reliable data extraction, and Claude AI's intelligent analysis creates a powerful research automation system that transforms how teams gather and process information.
This integration eliminates the friction between identifying research needs and obtaining actionable insights. By simply typing commands in Linear issues, your team can trigger comprehensive data gathering and analysis workflows that would traditionally require hours of manual work.
Key Benefits
- ⚡ Instant Research: From question to insight in under 60 seconds
- 🎯 Context Preservation: Research stays connected to project discussions
- 🧠 AI Enhancement: Raw data becomes actionable intelligence automatically
- 👥 Team Efficiency: Shared research accessible to entire team
- 📊 Comprehensive Coverage: Multiple data sources in unified workflow
Transform your team's research capabilities from reactive to proactive. With Linear, Scrapeless, and Claude working together, you're not just gathering data—you're building a competitive intelligence advantage that scales with your business.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


