
5 Best Amazon Scrapers in 2026: The Ultimate Tool for Scaling E-commerce Intelligence
Expert in Web Scraping Technologies
Key Takeaways
- Amazon's anti-bot defenses have evolved to include TLS fingerprinting and behavioral analysis, making specialized APIs essential.
- Choosing the right scraper depends on your technical stack: Scrapeless and ScraperAPI are best for developers, while Octoparse serves non-technical users.
- Data extraction from Amazon is crucial for dynamic pricing, competitor monitoring, and sentiment analysis in the 2026 retail landscape.
- Scrapeless leads the market in 2026 with a >95% success rate, offering unique support for Amazon Sponsor Ads and Rufus AI data extraction.
Introduction
In the dynamic world of e-commerce, Amazon stands as an undisputed titan, a vast ocean of products, prices, and invaluable consumer insights. For businesses, researchers, and developers alike, the ability to effectively navigate and extract data from this colossal marketplace is not just an advantage—it's a necessity. From monitoring competitor pricing strategies to analyzing product trends and understanding customer sentiment, Amazon data fuels informed decision-making and strategic growth. However, the sheer scale and sophisticated anti-scraping mechanisms employed by Amazon make manual data collection an arduous, if not impossible, task. This is where Amazon scrapers become indispensable tools, automating the extraction process and transforming raw web data into actionable intelligence.
This comprehensive guide delves into the 5 best Amazon scrapers in 2026, offering an in-depth comparison to help you choose the perfect tool for your specific needs. We'll explore their core features, evaluate their strengths and weaknesses, and provide insights into their pricing models. Whether you're a seasoned data professional or just beginning your journey into web scraping, this article will equip you with the knowledge to harness the power of Amazon data effectively. We'll also highlight how Scrapeless, with its advanced capabilities like the Web Unlocker and specialized data extraction for Sponsor Ads and Rufus data, stands out in this competitive landscape.
Why Scrape Amazon Data?
The motivations behind scraping Amazon data are as diverse as the products listed on its platform. For businesses, the insights gained can be transformative. Here are some primary reasons why scraping Amazon data is crucial in 2026:
- Market Research and Trend Analysis: By collecting data on product popularity, categories, and emerging niches, businesses can identify market gaps and capitalize on new opportunities. Understanding what's trending allows for proactive inventory management and product development.
- Competitor Monitoring: Keeping a close eye on competitors' product listings, pricing, promotions, and customer reviews is vital. Amazon scrapers enable businesses to track these metrics in real-time, allowing for agile adjustments to their own strategies. This includes monitoring how competitors utilize Sponsor Ads to gain visibility.
- Price Intelligence and Optimization: Price fluctuations on Amazon are constant. Scraping allows for continuous price tracking, enabling dynamic pricing strategies that maximize competitiveness and profitability. This is particularly important for retailers looking to maintain a competitive edge.
- Product Development and Improvement: Analyzing customer reviews and ratings provides invaluable feedback on product performance, desired features, and common pain points. This direct consumer insight can guide product improvements and inform the creation of new offerings.
- Supply Chain and Inventory Management: By monitoring stock levels of popular products, businesses can anticipate demand, optimize their supply chain, and prevent stockouts or overstocking. This proactive approach ensures operational efficiency.
- Brand Reputation Management: Tracking mentions and reviews of your brand and products across Amazon helps in quickly identifying and addressing negative feedback, protecting your brand's image. This also extends to understanding the impact of Rufus data on product visibility and sales.
Key Features to Look for in an Amazon Scraper
Choosing the right Amazon scraper involves more than just finding a tool that can extract data. The effectiveness and efficiency of your scraping operations depend heavily on several key features. When evaluating potential solutions, consider the following:
- High Success Rate: Amazon employs sophisticated anti-bot measures. A reliable scraper must have a high success rate in bypassing these defenses, ensuring consistent data delivery without frequent blocks or CAPTCHAs. This often involves advanced proxy management and IP rotation.
- Proxy Management and Rotation: To avoid IP bans and ensure continuous scraping, the scraper should offer robust proxy management, including a large pool of diverse IP addresses and automatic rotation. This is crucial for maintaining anonymity and bypassing geo-restrictions.
- CAPTCHA Handling: CAPTCHAs are a common hurdle in web scraping. An effective Amazon scraper should have built-in capabilities to automatically solve or bypass various CAPTCHA types, minimizing interruptions to your data flow. Scrapeless's Web Unlocker is designed precisely for this purpose.
- JavaScript Rendering: Many modern websites, including Amazon, rely heavily on JavaScript to load content dynamically. A capable scraper must be able to render JavaScript to access all relevant data, not just the initial HTML. Tools like Scraping Browser are essential for this.
- Data Parsing and Structuring: Raw HTML is rarely useful. The best scrapers can parse the extracted data into structured formats like JSON, CSV, or Excel, making it easy to analyze and integrate into your systems. Look for tools that offer pre-built parsers for common Amazon data points.
- Ease of Use and Integration: Whether you prefer a no-code solution or a highly customizable API, the scraper should be user-friendly and offer straightforward integration with your existing workflows. Documentation and support are also important considerations.
- Scalability: Your data needs may grow. The chosen scraper should be able to scale with your requirements, handling increasing volumes of requests and data without compromising performance or reliability.
- Pricing Model: Understand the pricing structure—whether it's based on requests, data volume, or a subscription. Compare costs across different providers to find a solution that aligns with your budget and usage patterns.
Comparison Table: 5 Best Amazon Scrapers in 2026
| Scraper Name | Key Features | Pros | Cons | Pricing Model | Best For |
|---|---|---|---|---|---|
| Scrapeless | High speed and higher success rate,wide data fields-Sponsor Ads Data and Rufus Data available, AI-powered anti-bot bypass, global proxy network | High success rate, handles complex anti-bot measures, specialized Amazon data extraction, flexible API | Requires some technical setup for advanced features | Pay-as-you-go/Subscription(optional; only charge for succeessful requests) | Businesses needing highly reliable, scalable, and specialized Amazon data extraction |
| ScraperAPI | Structured Data Endpoint, DataPipeline, 40M+ IPs, Geotargeting, CAPTCHA handling | Easy to use, high success rate, good for structured data | Limited CSV export, some parameters still in development | Subscription-based (API credits) | Developers and businesses looking for a robust, easy-to-use API for structured Amazon data |
| Bright Data | Extensive proxy network (residential, datacenter, ISP), Web Scraper IDE, pre-built data collectors, unblocker | Largest proxy network, highly customizable, powerful IDE, good for large-scale projects | Can be complex for beginners, higher cost for extensive usage | Usage-based (traffic, requests, data) | Enterprises and advanced users with complex, large-scale scraping needs |
| ScrapingBee | JavaScript rendering, proxy rotation, geo-targeting, integrates with various languages | Simple API, good for general web scraping, reasonable pricing | May require more custom parsing for complex Amazon data | Request-based | Developers and small to medium businesses needing a straightforward API for general web scraping, including Amazon |
| Octoparse | Visual web scraper builder, ready-to-use templates, IP rotation, cloud service | No-code solution, easy for beginners, visual interface | Can be resource-intensive for local runs, extra charges for advanced features | Subscription-based (tasks, cloud data) | Beginners and non-technical users who prefer a visual, no-code approach to Amazon scraping |
Detailed Review of Each Scraper
1. Scrapeless: The Intelligent Choice for Amazon Data
Scrapeless emerges as a leading solution for Amazon data extraction in 2026, particularly for those who demand high reliability, advanced anti-bot bypass capabilities, and specialized data points. Our platform is engineered to tackle Amazon's most formidable defenses, ensuring that you receive consistent and accurate data.
Key Features & Advantages of Scrapeless:
- Global Proxy Network: Backed by a robust and diverse residential proxy network, Scrapeless ensures that your scraping requests appear legitimate, minimizing the risk of IP bans and geo-restrictions. Our proxies are optimized for performance and reliability, crucial for sustained Amazon scraping operations.
- Flexible API: Scrapeless offers a powerful and flexible API that integrates seamlessly into your existing infrastructure, allowing for custom data extraction workflows and real-time data delivery.
- Advanced Anti-Detection: Automatically bypasses Cloudflare, reCAPTCHA, and DataDome while mimicking human behavior to prevent blocking.
- Sponsor Ads Data Extraction: A unique advantage of Scrapeless is its ability to specifically target and extract data from Amazon's Sponsor Ads. This provides unparalleled insights into competitor advertising strategies, keyword bidding, and product visibility, offering a significant edge in market analysis.
- Rufus Data Integration: With the rise of AI-powered shopping assistants like Amazon's Rufus, understanding the data influencing these systems is crucial. Scrapeless is at the forefront of extracting and analyzing Rufus data, offering insights into how products are being presented and recommended by AI, which can be a game-changer for product optimization and marketing.
- Free trial available: New users can join Scrapeless official community to claim trial credits(up to 3,000 requests):
Discord
Telegram
Pros:
- Exceptional success rate against Amazon's anti-bot measures.
- Specialized extraction of Sponsor Ads and Rufus data, offering unique market insights.
- Automated CAPTCHA and retry handling with Web Unlocker.
- Full JavaScript rendering capabilities with Scraping Browser.
- Scalable and reliable for large-volume data extraction.
- Comprehensive documentation and support.
Cons:
- May require some initial technical setup for optimal configuration.
- Not a no-code solution, requiring basic programming knowledge for API integration.
Pricing: Scrapeless operates on a usage-based model, where you only pay for successful requests and the volume of data extracted. This ensures cost-efficiency and aligns with the value you receive.
2. ScraperAPI: Simplified Amazon Data Extraction
ScraperAPI is a popular choice for developers seeking a straightforward yet powerful solution for Amazon data extraction. It simplifies the complexities of web scraping by handling proxies, CAPTCHAs, and retries behind a single API endpoint.
Key Features:
- Structured Data Endpoint: ScraperAPI offers specialized endpoints for Amazon, allowing users to retrieve structured JSON data for products, search results, reviews, and offers with minimal effort.
- Extensive Proxy Pool: With over 40 million IP addresses and geotargeting capabilities across 50+ countries, it provides robust proxy management to ensure high success rates.
- CAPTCHA Handling and JavaScript Rendering: It automatically manages CAPTCHAs and can render JavaScript, making it suitable for dynamic Amazon pages.
- DataPipeline: A low-code solution for collecting large amounts of data from Amazon using pre-built templates, ideal for users who prefer a more visual approach without extensive coding.
Pros:
- Very easy to use, especially with structured data endpoints.
- High success rate and reliable performance.
- Good for extracting specific, structured data points from Amazon.
- Offers both API and low-code solutions.
Cons:
- Limited CSV export options currently.
- Some advanced parameters are still under development.
Pricing: ScraperAPI uses a subscription-based model with different tiers based on the number of API credits. Plans start from $49/month for 100,000 API credits.
3. Bright Data: The Enterprise-Grade Solution
Bright Data is renowned for its comprehensive suite of web scraping tools and the world's largest proxy network. It's an enterprise-grade solution favored by large organizations and users with highly complex and demanding data extraction needs from Amazon.
Key Features:
- Vast Proxy Network: Offers residential, datacenter, ISP, and mobile proxies, providing unparalleled flexibility and anonymity for scraping Amazon at scale.
- Web Scraper IDE: A powerful integrated development environment for building, running, and managing web scrapers, offering extensive customization options.
- Pre-built Data Collectors: Provides ready-to-use data collectors for popular websites, including Amazon, simplifying the setup process for common scraping tasks.
- Unblocker: An advanced solution designed to bypass sophisticated anti-bot systems, ensuring access to even the most protected Amazon pages.
Pros:
- Unmatched proxy network size and diversity.
- Highly customizable and powerful for complex scraping scenarios.
- Excellent for large-scale, high-volume data extraction.
- Robust unblocker technology.
Cons:
- Can be expensive, especially for high usage.
- Steep learning curve for beginners due to its extensive features and customization options.
Pricing: Bright Data's pricing is usage-based, typically calculated on traffic, requests, and data volume. It offers various plans, including pay-as-you-go and custom enterprise solutions.
4. ScrapingBee: Developer-Friendly Web Scraping API
ScrapingBee offers a simple yet effective API for general web scraping, including Amazon. It focuses on providing a developer-friendly experience by handling headless browsers, proxies, and retries, allowing users to focus on data extraction logic.
Key Features:
- JavaScript Rendering: Automatically renders JavaScript, making it suitable for scraping dynamic content on Amazon product pages.
- Proxy Rotation and Geo-targeting: Manages proxy rotation and allows for geo-targeting, helping to bypass geo-restrictions and maintain anonymity.
- Simple API: Provides a clean and easy-to-use API that integrates well with various programming languages.
- Screenshot and Ad Blocking: Offers additional features like taking screenshots and blocking ads, which can be useful for specific scraping tasks.
Pros:
- Developer-friendly and easy to integrate.
- Handles common scraping challenges like headless browsers and proxies.
- Good for general web scraping tasks.
- Transparent and predictable pricing.
Cons:
- May require more custom parsing logic for highly specific Amazon data points compared to specialized Amazon scrapers.
- Proxy pool might not be as extensive as dedicated proxy providers.
Pricing: ScrapingBee uses a request-based pricing model, with different tiers offering varying numbers of API calls per month. Plans typically start from a free tier for a limited number of requests, scaling up to paid subscriptions.
5. Octoparse: The No-Code Visual Scraper
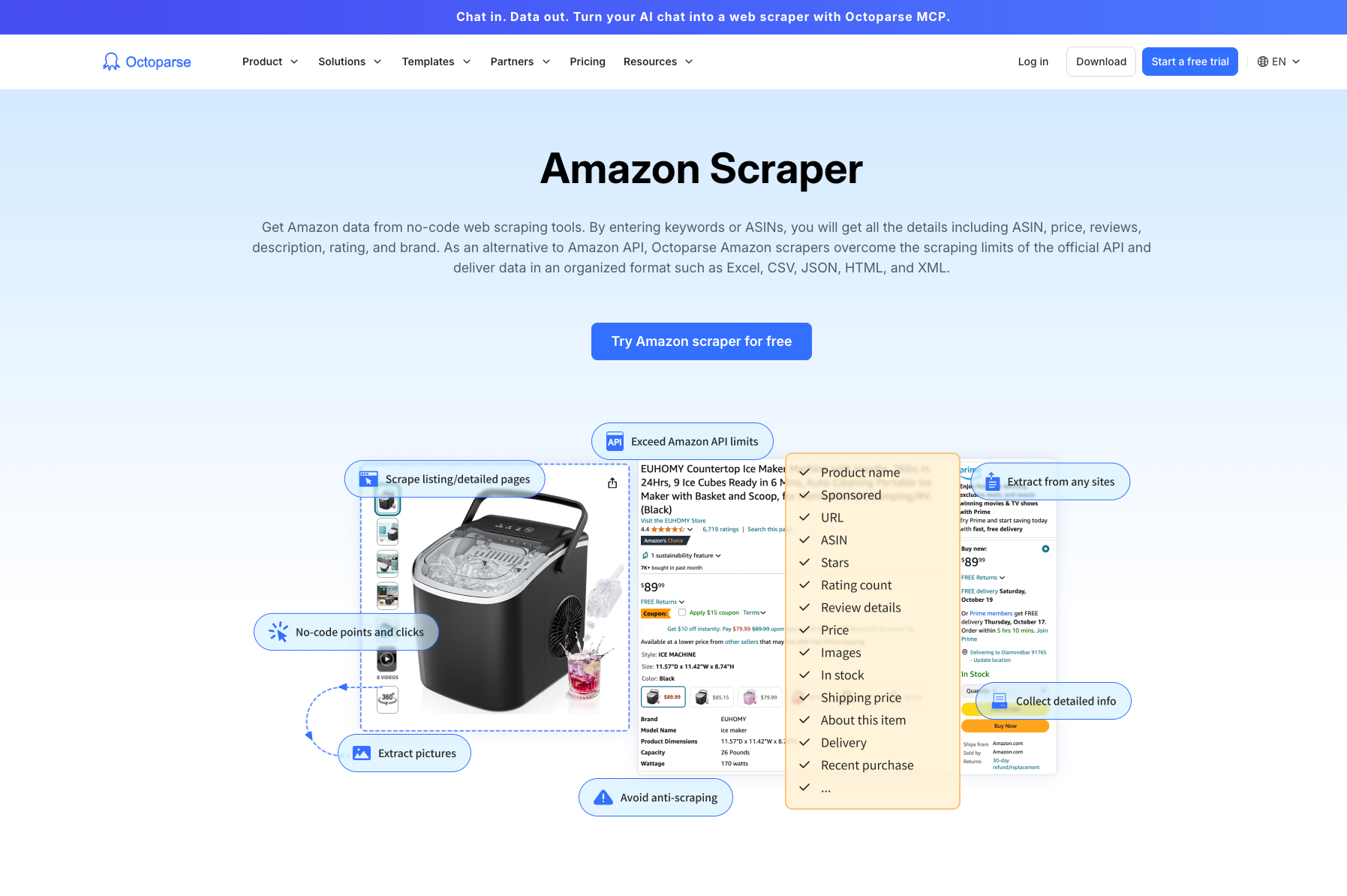
Octoparse is a popular no-code web scraping tool that empowers users without programming knowledge to extract data from websites, including Amazon. Its visual interface allows users to build scrapers by simply clicking on elements they wish to extract.
Key Features:
- Visual Workflow Builder: Users can create scraping workflows by pointing and clicking on web elements, making it highly accessible for beginners.
- Ready-to-Use Templates: Offers pre-built templates for popular websites like Amazon, simplifying the process of extracting common data points such as product details and reviews.
- IP Rotation and Cloud Service: Provides IP rotation to prevent blocks and offers a cloud platform for running scrapers, reducing reliance on local machine resources.
- Data Export Options: Supports exporting extracted data in various formats, including CSV, Excel, and JSON.
Pros:
- Excellent for beginners and non-technical users.
- No coding required to build and run scrapers.
- Visual interface makes workflow creation intuitive.
- Cloud-based execution reduces local resource consumption.
Cons:
- Can be less flexible for highly complex or custom scraping scenarios compared to API-based solutions.
- Advanced features like CAPTCHA handling or premium proxies may incur additional costs.
- Performance can sometimes be limited for very large-scale projects.
Pricing: Octoparse offers a free plan with limited features, and paid subscription plans that vary based on the number of tasks, cloud data, and advanced features. Plans typically start from around $89/month.
How to Choose the Right Amazon Scraper for Your Needs
Selecting the ideal Amazon scraper depends on a confluence of factors unique to your project and organizational capabilities. Consider the following to make an informed decision:
- Project Scale and Frequency: For small, infrequent data extraction tasks, a simpler, more affordable solution like Octoparse or a basic ScrapingBee plan might suffice. However, for large-scale, continuous monitoring or high-volume data needs, enterprise-grade solutions like Scrapeless or Bright Data, with their robust infrastructure and advanced anti-detection capabilities, are essential.
- Technical Expertise: If your team has strong programming skills, API-driven solutions like Scrapeless, ScraperAPI, or ScrapingBee offer maximum flexibility and customization. For non-technical users or those preferring a visual approach, Octoparse provides an excellent no-code alternative.
- Specific Data Requirements: Do you need general product information, or are you targeting niche data points like Sponsor Ads performance or Rufus data insights? Scrapeless, with its specialized extraction capabilities, excels in these areas. Ensure the chosen scraper can reliably deliver the precise data you need.
- Budget Constraints: Pricing models vary significantly. Evaluate whether a subscription-based model, usage-based pricing, or a combination best fits your budget and expected data volume. Remember to factor in potential additional costs for proxies or advanced features.
- Integration with Existing Systems: Consider how easily the scraper can integrate with your current data pipelines, analytics tools, or internal systems. API-based solutions generally offer more seamless integration options.
- Support and Documentation: Reliable customer support and comprehensive documentation can be invaluable, especially when encountering unexpected scraping challenges. Look for providers that offer responsive assistance and clear guides.
Conclusion
The ability to effectively scrape Amazon data is a powerful asset in today's data-driven e-commerce landscape. The right Amazon scraper can unlock a wealth of insights, empowering businesses to make smarter decisions, optimize strategies, and gain a competitive edge. From the no-code simplicity of Octoparse to the enterprise-grade power of Bright Data, and the developer-friendly APIs of ScraperAPI and ScrapingBee, there's a solution for every need.
However, for those seeking a truly intelligent, scalable, and specialized approach to Amazon data extraction—especially when it comes to navigating complex anti-bot measures and accessing unique data points like Sponsor Ads and Rufus data—Scrapeless stands out. Our advanced Web Unlocker and Scraping Browser ensure unparalleled success rates, allowing you to focus on what matters most: leveraging data for growth.
Don't let Amazon's defenses hinder your data ambitions. Explore the power of Scrapeless today and transform your e-commerce strategy with reliable, high-quality Amazon data. Try Scrapeless now!
FAQ
1. Is scraping Amazon legal in 2026?
Scraping publicly available data is generally legal, but you must comply with data privacy laws (like GDPR) and avoid disrupting Amazon's services. Using a professional service like Scrapeless ensures your scraping is done ethically and responsibly.
2. How do I avoid being blocked by Amazon?
The most effective way is to use an API that handles TLS fingerprinting and IP rotation automatically. Scrapeless uses advanced AI to mimic human behavior, keeping your success rate above 95%.
3. Can I scrape Amazon Sponsor Ads?
Most scrapers struggle with ads because they are dynamically loaded and highly protected. However, Scrapeless offers a dedicated endpoint specifically for Sponsor Ads, providing deep insights into competitor marketing.
4. What is Rufus data, and why should I scrape it?
Rufus is Amazon's AI shopping assistant. Scraping Rufus data allows you to see how AI recommends products, which is essential for modern SEO and product positioning. Scrapeless is currently a leader in providing this data.
5. Do I need a proxy for Amazon scraping?
Yes, but managing your own proxies is difficult and expensive. It is better to use a tool like Scrapeless that includes a high-quality residential proxy network as part of the service.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


