![Amazon Scraper API [2025 Full Guide]](/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Famazon-scraper-api%2F85e6b675b8226b26ee9e75f176a4c951.png&w=1920&q=100)
Amazon Scraper API [2025]: The Only Guide You’ll Ever Need
Advanced Data Extraction Specialist
As the demand for e-commerce data increases, it becomes increasingly important to crawl and analyze data on the Amazon platform. Using the Amazon Scraper API, businesses and developers can easily extract product information, prices, reviews, inventory and other data from Amazon.
However, despite the continuous advancement of technology, many users still face the challenge of how to efficiently and accurately crawl data.
In this guide, we will take you to a deep understanding of the Amazon Scraper API:
#1. Understand the core functions of the Amazon Scraper API
#2. Quickly configure the API and start crawling
#3. Best practices for data crawling
In 2025, the Amazon Scraper API has become more powerful and flexible, and it can provide you with accurate structured data to help you stay ahead in the competitive market. Next, we will detail how to use this tool to its full potential.
Part 1: Why use the Amazon Scraper API?
The Amazon Scraper API is a powerful tool for businesses to simplify data collection from Amazon.

Here’s why you should use it:
- Automated Data Extraction: Saves time by automating product data collection.
- Real-time Updates: Keeps your data current with up-to-date prices, stock, reviews, etc.
- Accurate, Structured Data: Delivers data in a structured format (like JSON) for easy analysis and integration.
- Competitor Price Tracking: Monitors competitor pricing and product availability.
- Scalable and Efficient: Handles large data volumes without the risk of IP blocking.
- Seamless Integration: Easily integrates into your systems for quick setup and use.
Best Amazon Scraping API Recommendations
One of the easiest ways to scrape Amazon data is by using a dedicated scraping API like Scrapeless. This tool streamlines the entire process, enabling users to effortlessly extract key details such as product descriptions, reviews, offers, search results, and pricing, all in a convenient JSON format.
With just a simple API call, Scrapeless makes it possible to access a wealth of Amazon data without the need for extensive coding knowledge, making it an ideal solution for users looking to save time and effort.
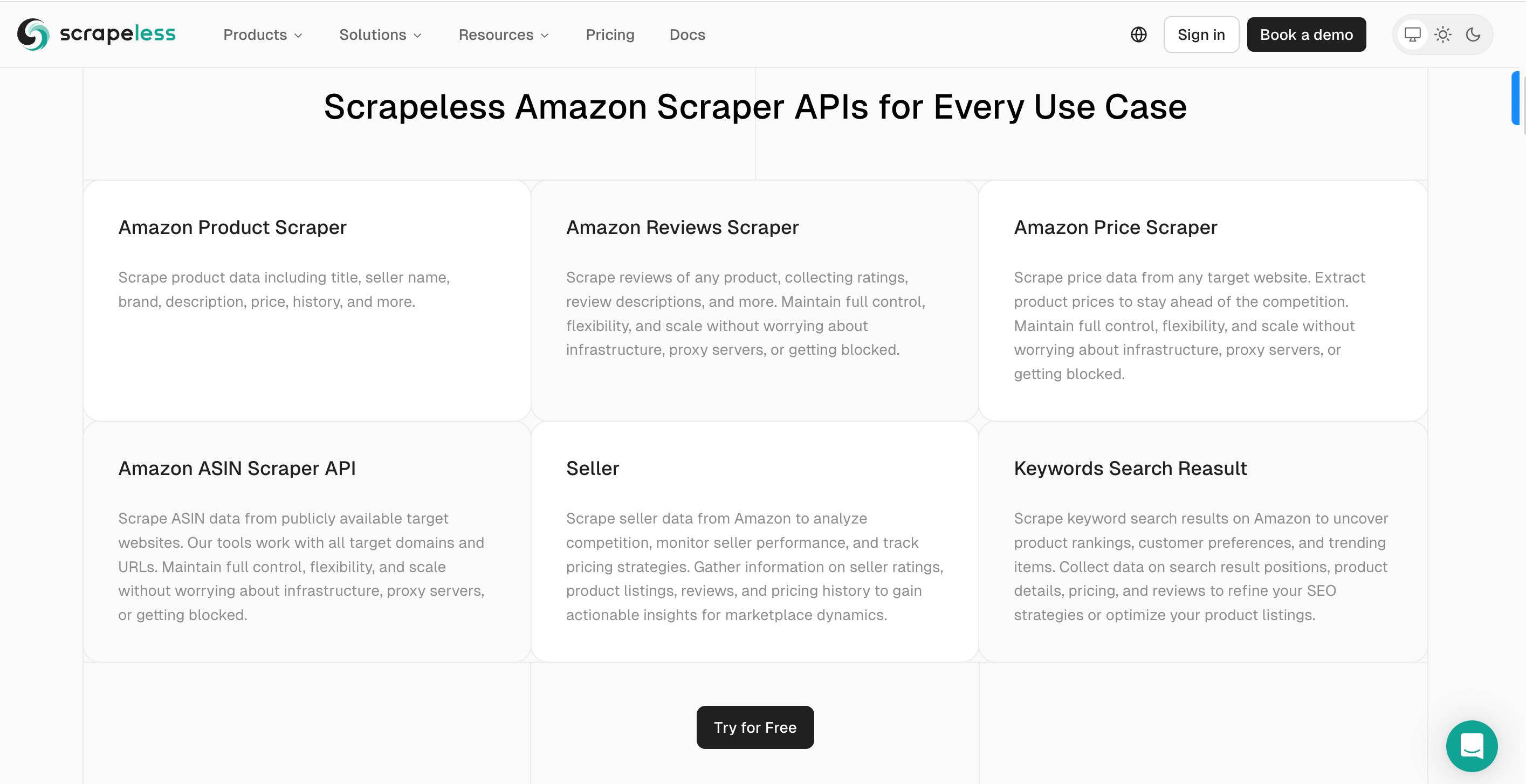
Using the Scrapeless Amazon Scraping API, you can:
- User-Friendly Interface: Most tools offer a point-and-click interface that makes it easy to select the data you want to scrape.
- Pre-Built Templates: Tools like Scrapeless provide pre-built templates specifically designed for Amazon, allowing users to scrape product details with minimal setup.
- Automated Data Extraction: These tools handle IP rotation and CAPTCHA challenges automatically, reducing the risk of being blocked by Amazon.
How to Scrape Amazon product data with Amazon Scraper API:
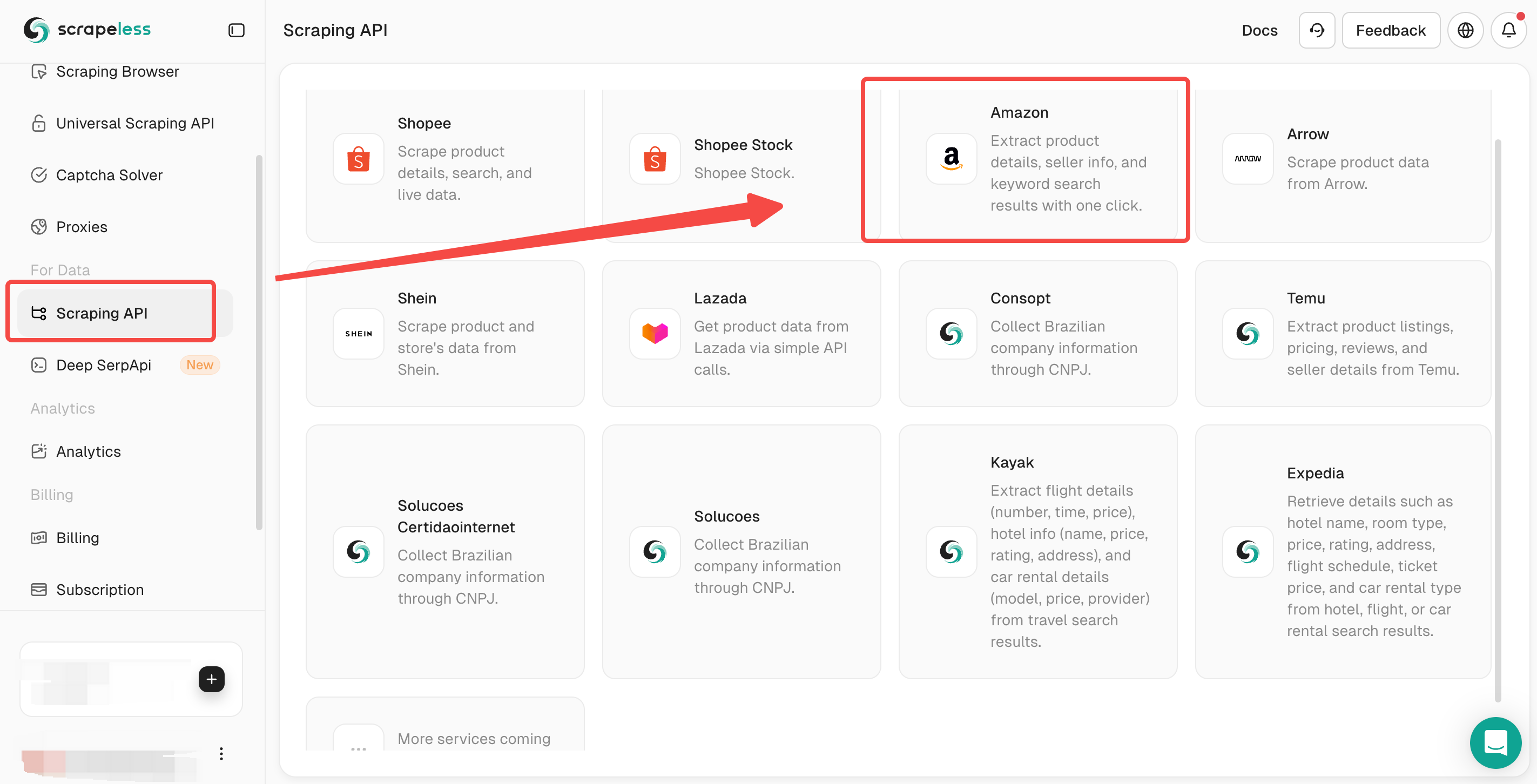
Step 1. Log in to Scrapeless
Step 2. Click Scraping API > select Amazon to enter the Shopee scraping page.
Step 3. Paste the link of the Amazon product page you want to crawl into the input box. And select the type of data to crawl.
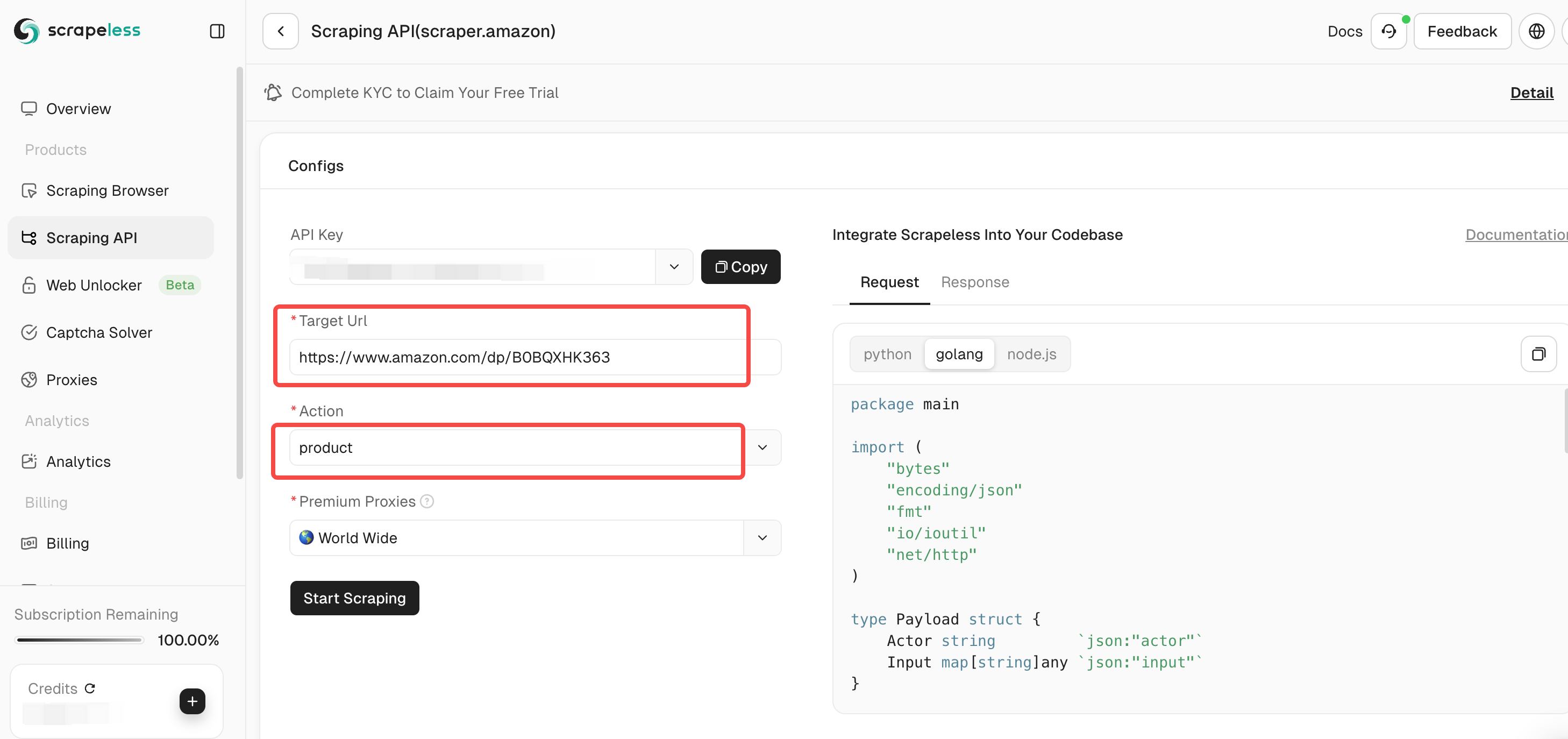
On the tool page, you can select the type of data to crawl:
- Seller: Crawl seller information, including seller name, rating, contact information, etc.
- Product: Crawl product details such as title, price, rating, comments, etc.
- Keywords: Crawl keywords related to the product to help you analyze the product's SEO and market trends.
Step 4. After confirming that the input link and selected data type are correct, click the "Start Scraping" button. The system will start crawling data and display the crawled results on the panel on the right side of the page.
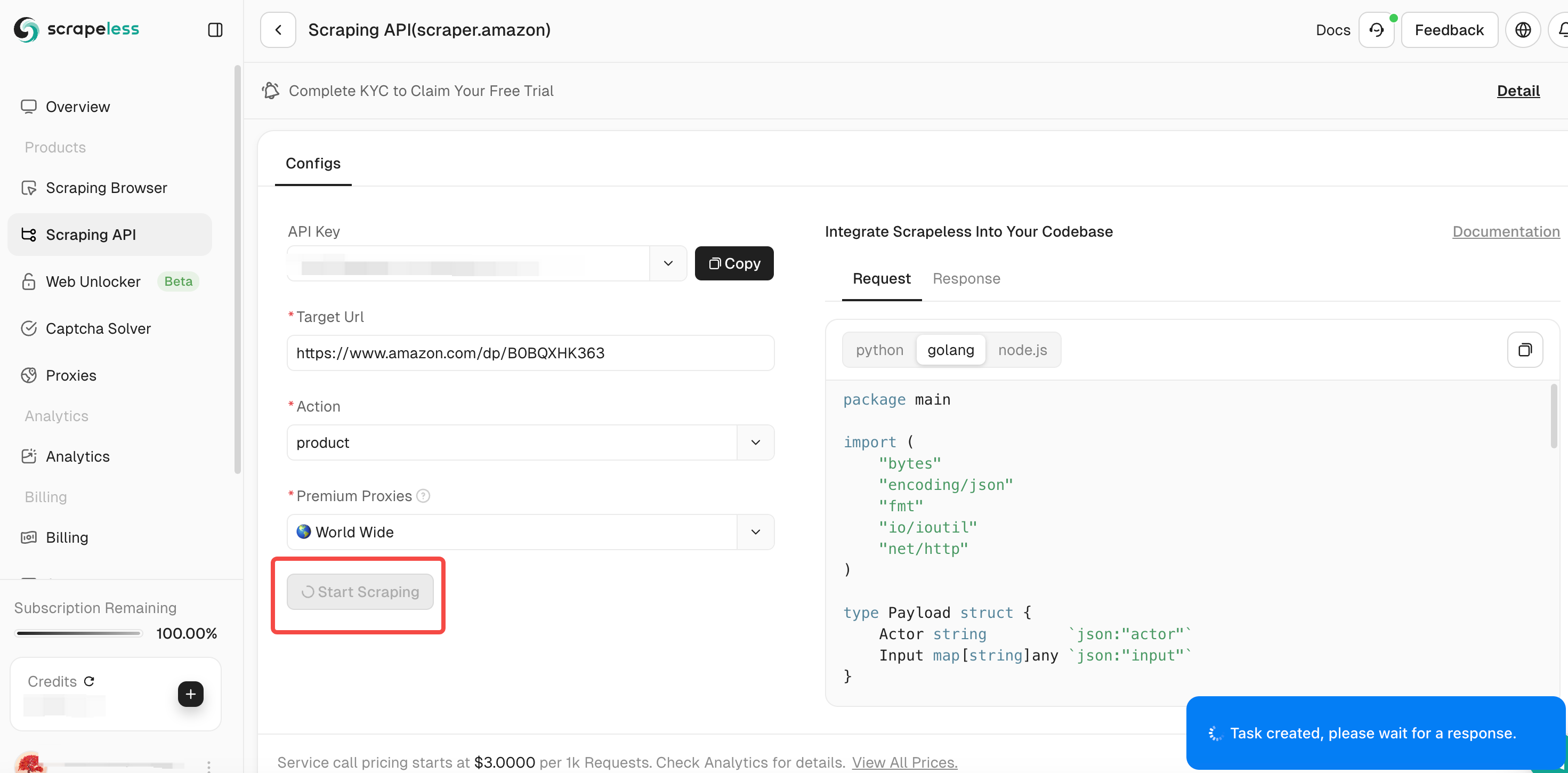
Step 5. After the crawling is completed, you can view the crawled data in the panel on the right. The results will be displayed in a clear format for easy analysis.
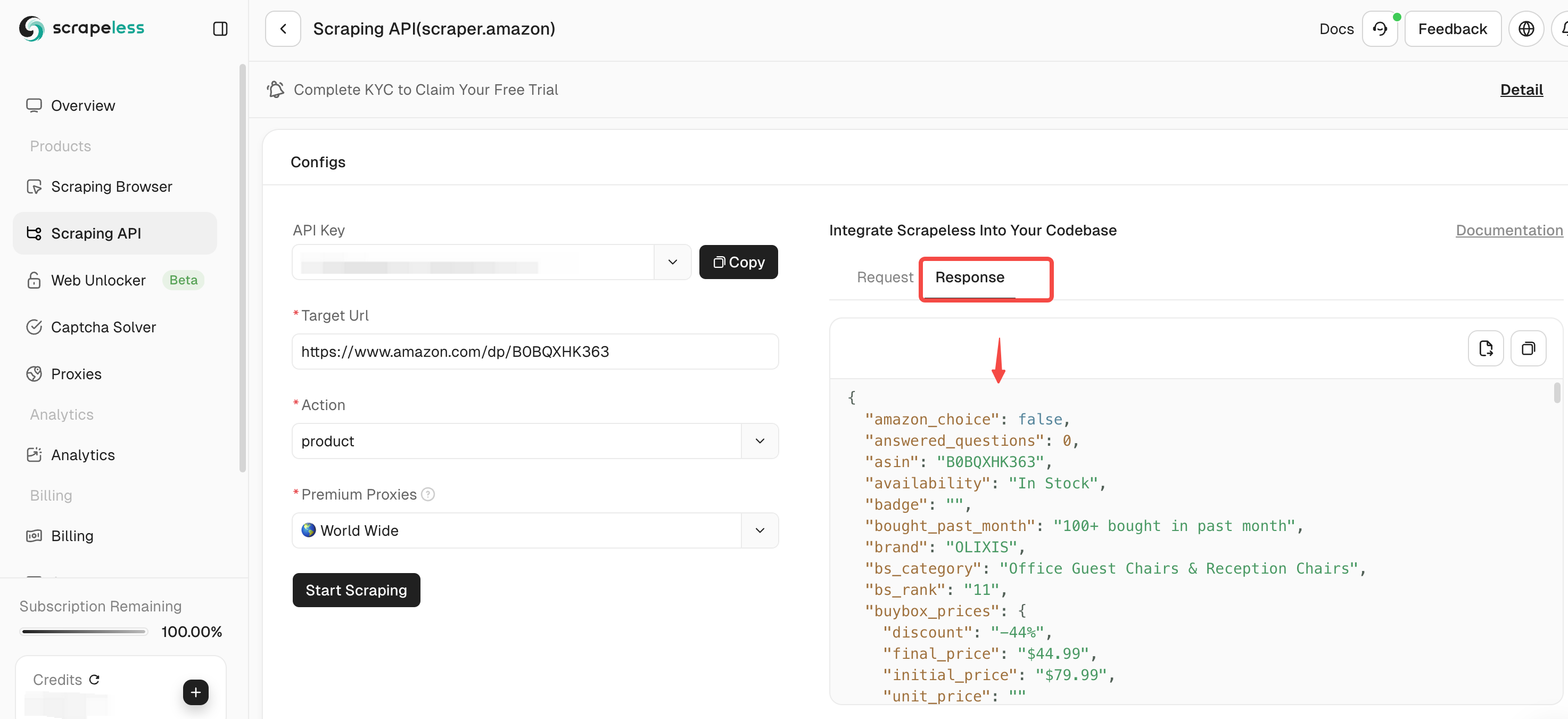
If you need to crawl other products, click Continue to enter a new Amazon link and repeat the above steps.
How to Scrape Amazon product Asin data with Amazon Scraper API:
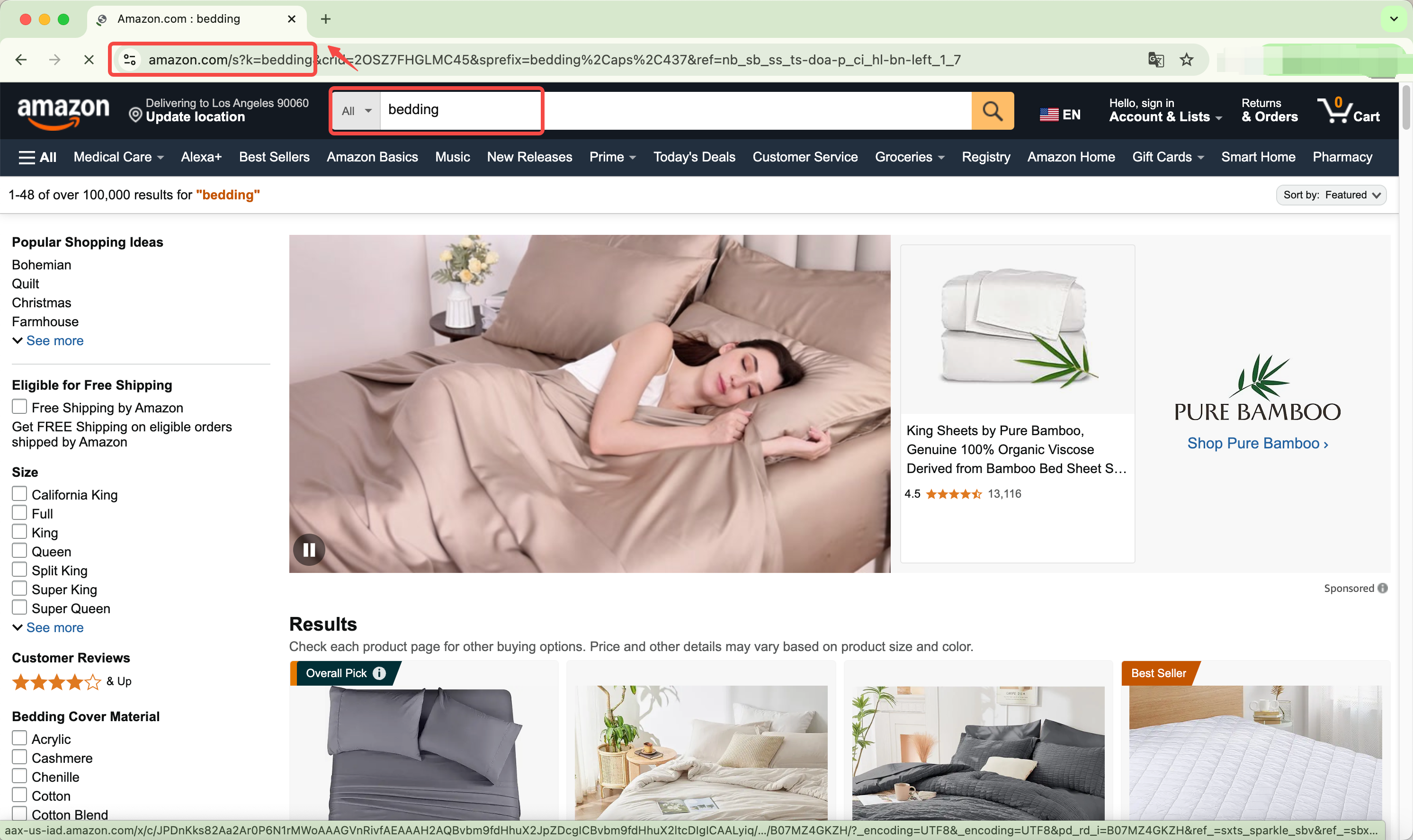
Step 1: Build the URL
Enter the keyword in the Amazon search box and copy the corresponding URL.Here, "bedding" is listed as the URL: https://www.amazon.com/s?k=bedding
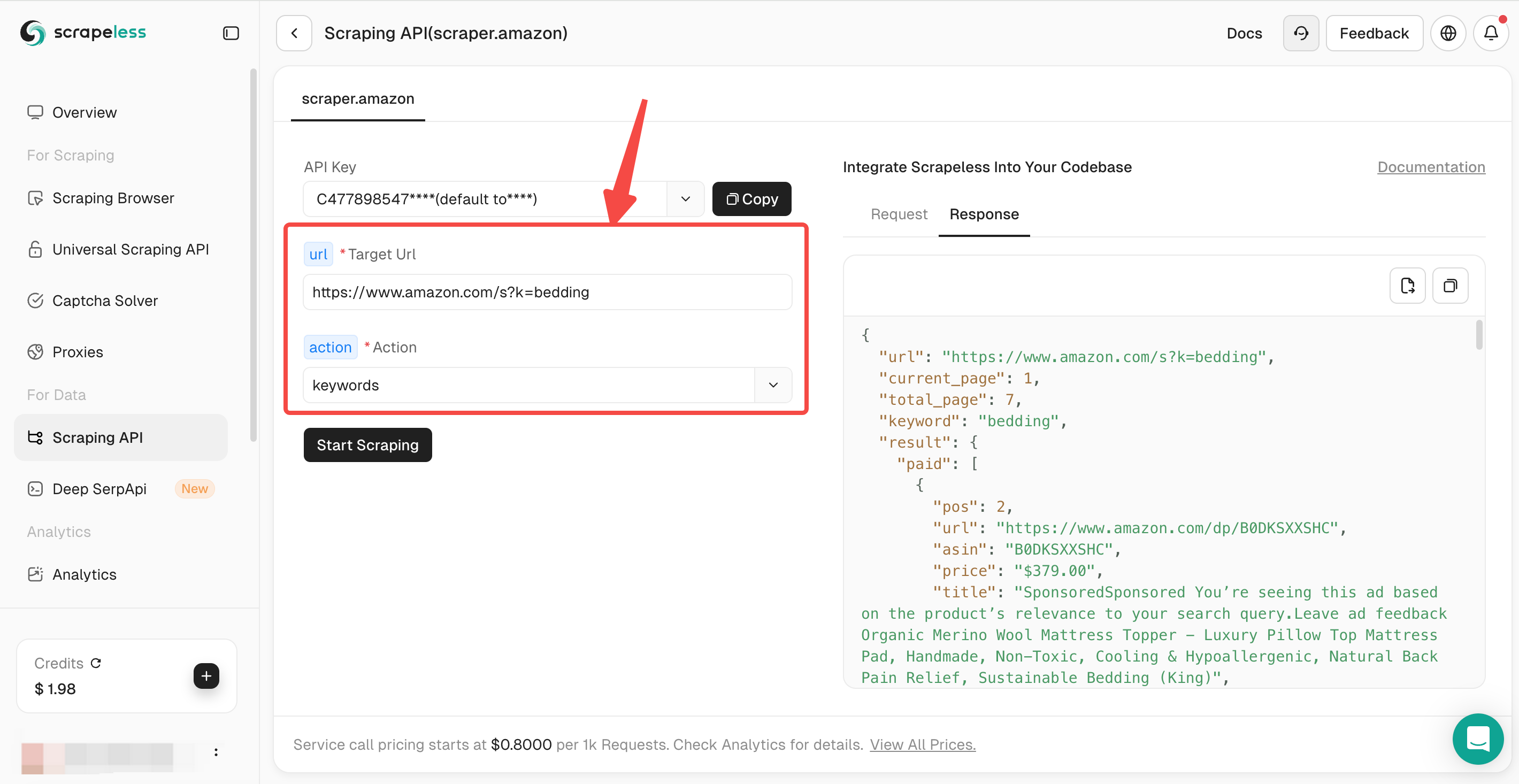
Step 2:Set crawling parameters
Copy the URL you built into the Scrapeless Amazon Scraping API, and select Keywords.
Step 3: Start Scraping
Click “Start Scraping”. The crawl results will be in the dashboard on the right.
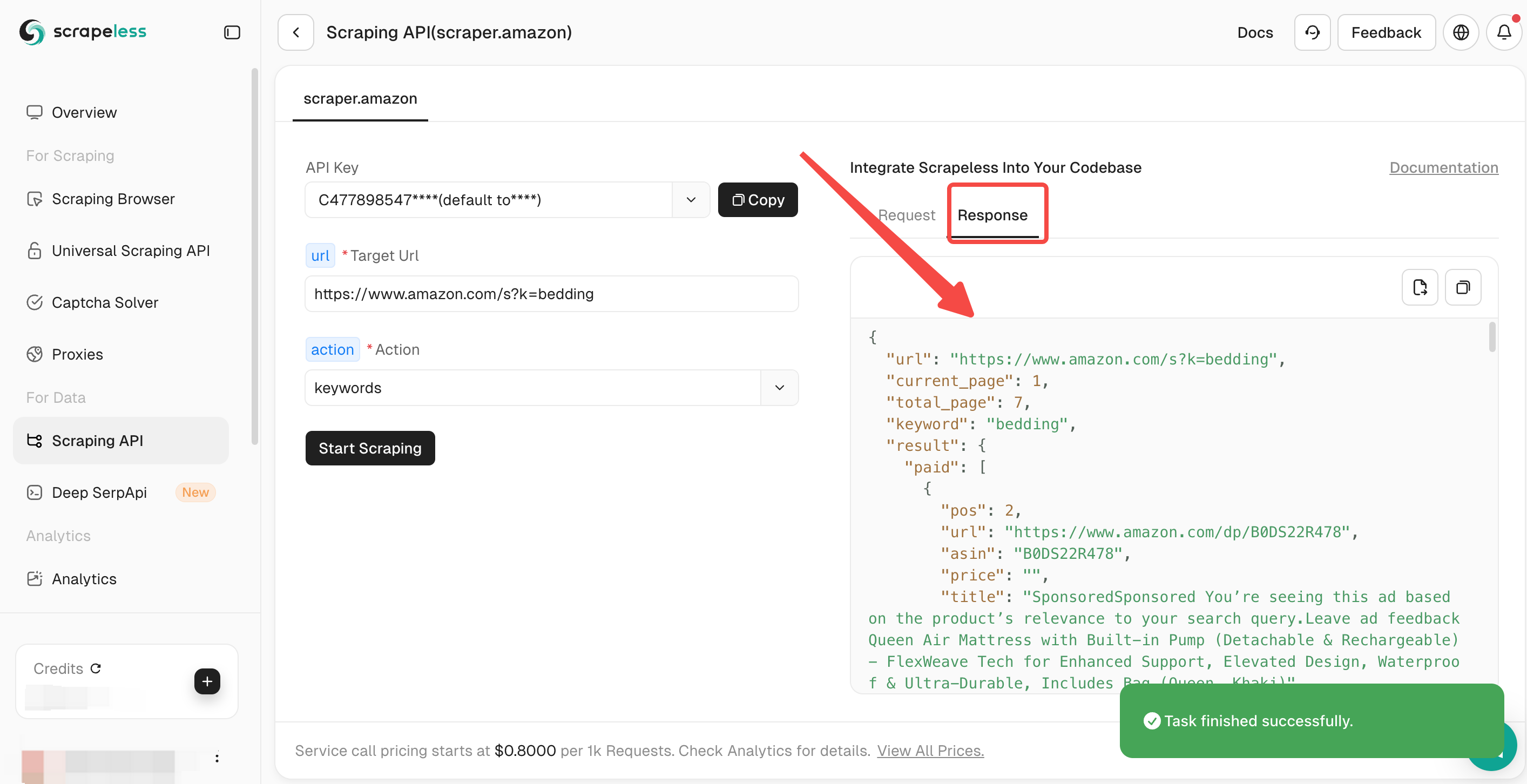
Some search result codes are listed below:
"url": "https://www.amazon.com/s?k=bedding",
"current_page": 1,
"total_page": 7,
"keyword": "bedding",
"result": {
"paid": [
{
"pos": 2,
"url": "https://www.amazon.com/dp/B0DS22R478",
"asin": "B0DS22R478",
"price": "",
"title": "SponsoredSponsored You’re seeing this ad based on the product’s relevance to your search query.Leave ad feedback Queen Air Mattress with Built-in Pump (Detachable & Rechargeable) - FlexWeave Tech for Enhanced Support, Elevated Design, Waterproof & Ultra-Durable, Includes Bag (Queen, Khaki)",
"rating": "",
"is_prime": false,
"url_image": "/sspa/click?ie=UTF8&spc=MTo5MzMyMzAwNTI2MjQzOTg6MTc0MjA5NzkwMzpzcF9hdGY6MzAwNjcxMjQ0OTI2ODAyOjowOjo&url=%2FLunaDream-Mattress-Built-Detachable-Rechargeable%2Fdp%2FB0DS22R478%2Fref%3Dsr_1_1_sspa%3Fdib%3DeyJ2IjoiMSJ9.kQJ5rAORw8oqha9VD8o8yW0gjsD58K6tZK0xcTj0AWrml0pG3A8RQySnBFxZh4rD4WjAWF5iALvRwV7hdxXVeCUIjDOOUeeEj_JI5T4YZR2XjrlG0i-l63cHd3JrsDC_xzvwvHRNM9CybOL9WXa_MiqHie_2jNpf2y4CrgFBeI6k8ZLiLcSwP4UKXQnT_zf9zJdCWdUMVJG5Dq65K-zq80Rxrz_bX0WYA_hNzTi3w1eAkXClZ5rmho1yX2qTkiOV7HhZXKWWioD6O4eEI6X-KUDUKRXthez3xwu88aOWUng.-ZkU0sCs2lJJKIyHERUSqfIoWc4eO9qjfh9yF1UfGx8%26dib_tag%3Dse%26keywords%3Dbedding%26qid%3D1742097903%26sr%3D8-1-spons%26sp_csd%3Dd2lkZ2V0TmFtZT1zcF9hdGY%26psc%3D1",
"best_seller": false,
"price_upper": "",
"is_sponsored": true,
"manufacturer": "",
"pricing_count": 1,
"reviews_count": 0,
"price_strikethrough": "",
"shipping_information": ""
},
{
"pos": 3,
"url": "https://www.amazon.com/dp/B0CPPLH6RL",
"asin": "B0CPPLH6RL",
"price": "$279.99",
"title": "SponsoredSponsored You’re seeing this ad This scraped result is a partial analysis of the Amazon search SERP (Search Engine Results Page) for the keyword "bedding". It contains the following information:
Basic Search Information
- url: The URL of the search results page (https://www.amazon.com/s?k=bedding).
- current_page: The current page number in the search results (1).
- total_page: The total number of pages in the search results (7).
- keyword: The search keyword used (bedding).
Sponsored (Paid) Product Information
-
The data includes details about some Sponsored products (advertised listings) stored in "result": { "paid": [...] }. The key details include:
-
pos (Position): 2 (Rank of this sponsored product in the search results).
-
url: The Amazon product page URL (https://www.amazon.com/dp/B0DS22R478).
-
asin (Amazon Standard Identification Number): B0DS22R478 (a unique identifier for the product).
.....
Scrapeless Amazon Scraping API Parameters
| Parameters | Required | Desc |
|---|---|---|
| action | true | This parameter defines the type of search to be performed. Possible types include: product, seller, and keywords. |
| url | false | This parameter is the URL information of the product or seller. If type is product, this parameter is required. |
| page | false | This parameter defines the page number of the searched product. It can be used when type is keywords. |
| domain | false | This parameter defines the domain name of the URL, for example. |
| zip_code | false | This parameter is the postal code. When you fill it in, you can get relevant delivery information. |
| return_HTML | false | This parameter defines whether to return the original HTML page. True means return, false means not return. |
Looking to quickly scrape structured data from Amazon? The Scrapeless Amazon API handles all the complexities, from rotating proxies to headless browsers, ensuring fast and seamless data extraction. Log in now to your dashboard and claim your FREE Trial immediately!
How to integrate Scrapeless into your project
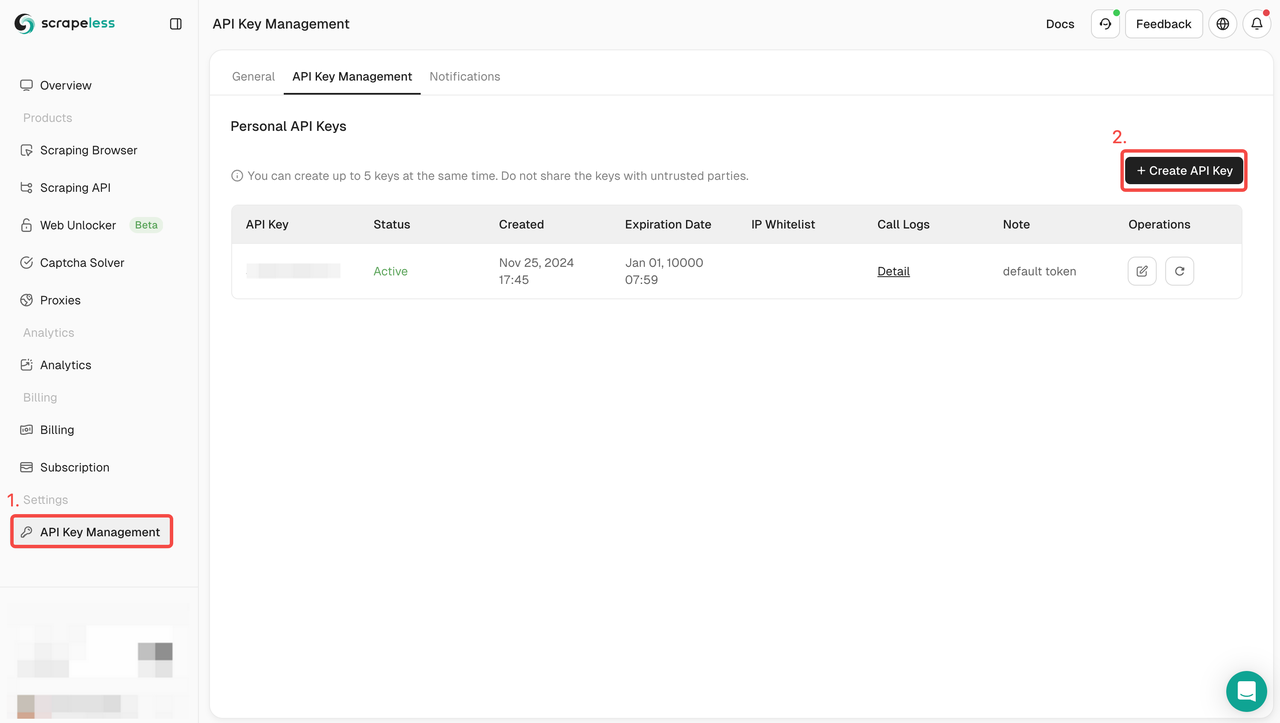
Step 1: Get the Scrapeless API KEY
- Sign up for Scrapeless
- Choose API Key Management
- Click Create API Key to create your Scrapeless API Key.
Scrapeless ensures seamless web scraping.
🎁 Join Discord and Claim your free trial now!
Step 2: Integrate the following code into your project
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "YOUTR API KEY"
headers = {
"x-api-token": token
}
input_data = {
"action": "keywords",
"url": "https://www.amazon.com/s?k=bedding"
}
payload = Payload("scraper.amazon", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()How to avoid common problems encountered in data scraping
Problem 1: Websites often block or throttle requests from the same IP address if too many requests are made in a short period of time, which prevents data scraping.
- Solution: Use a rotating proxy or proxy pool to distribute requests to different IP addresses. This helps avoid hitting rate limits or getting blocked.
Problem 2: Many websites, including Amazon, use captchas or other anti-bot mechanisms to detect automated scraping attempts, which makes it difficult to extract data.
- Solution: To bypass captchas, use a headless browser or a captcha solving service that automatically completes the captcha for you. The Scrapeless Scraper API can solve this problem by automatically solving captchas or using machine learning algorithms to avoid detection.
FAQ about Amazon Scraper API
Does Amazon allow data scraping?
Amazon's terms of service allow automated access to its website for data collection, but there are some requirements:
- Public Data: Amazon allows scraping of data that is accessible to anyone who visits the site, such as product information, prices, and reviews.
- Personal Use or Research: Amazon allows scraping for personal use or research purposes.
Can you scrape Amazon for prices?
Yes, you can get product information from Amazon, including:
- Price: current price, discounts, and historical price changes.
- Product Title: the name and description of the product.
- Product Details: specifications, features, and technical details.
- Customer Reviews and Ratings: user feedback, ratings, and review summaries.
- Availability: stock status, shipping options, and delivery times.
- Images: product images and thumbnails.
- ASIN (Amazon Standard Identification Number): a unique identifier for a product.
You may need:
How to Scrape Shein Data
Best Google Trends Scraping API - Easily Scrape Data from Google Trends
Top 6 SERP API for Search Engine Scraping
Conclusion
Here, as a professional API service provider, Scrapeless[Web Scraping Toolkit] will provide you with a detailed guide to help you quickly understand how to use the Amazon Scraper API and easily get the required data without worrying about complex technical settings or data extraction issues.
For developers and companies who want to quickly extract data from Amazon, Amazon Scraper API is an efficient and easy-to-use solution. It simplifies the crawling process, allowing you to obtain accurate data without investing a lot of time and effort.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


