
AI Powered Blog Writer using Scrapeless and Pinecone Database
Senior Web Scraping Engineer
You must be an experienced content creator. As a startup team, the daily updated content of the product is too rich. Not only do you need to lay out a large number of drainage blogs to increase website traffic quickly, but you also need to prepare 2-3 blogs per week that are subject to product update promotion.
Compared with spending a lot of money to increase the bidding budget of paid ads in exchange for higher display positions and more exposure, content marketing still has irreplaceable advantages: wide range of content, low cost of customer acquisition testing, high output efficiency, relatively low investment of energy, rich field experience knowledge base, etc.
However, what are the results of a large amount of content marketing?
Unfortunately, many articles are deeply buried on the 10th page of Google search.
Is there any good way to avoid the strong impact of "low-traffic" articles as much as possible?
Have you ever wanted to create a self-updating SEO writer that clones the knowledge of top-performing blogs and generates fresh content at scale?
In this guide, we'll walk you through building a fully automated SEO content generation workflow using n8n, Scrapeless, Gemini (You can choose some other ones like Claude/OpenRouter as wanted), and Pinecone.
This workflow uses a Retrieval-Augmented Generation (RAG) system to collect, store, and generate content based on existing high-traffic blogs.
YouTube tutorial: https://www.youtube.com/watch?v=MmitAOjyrT4
What This Workflow Does?
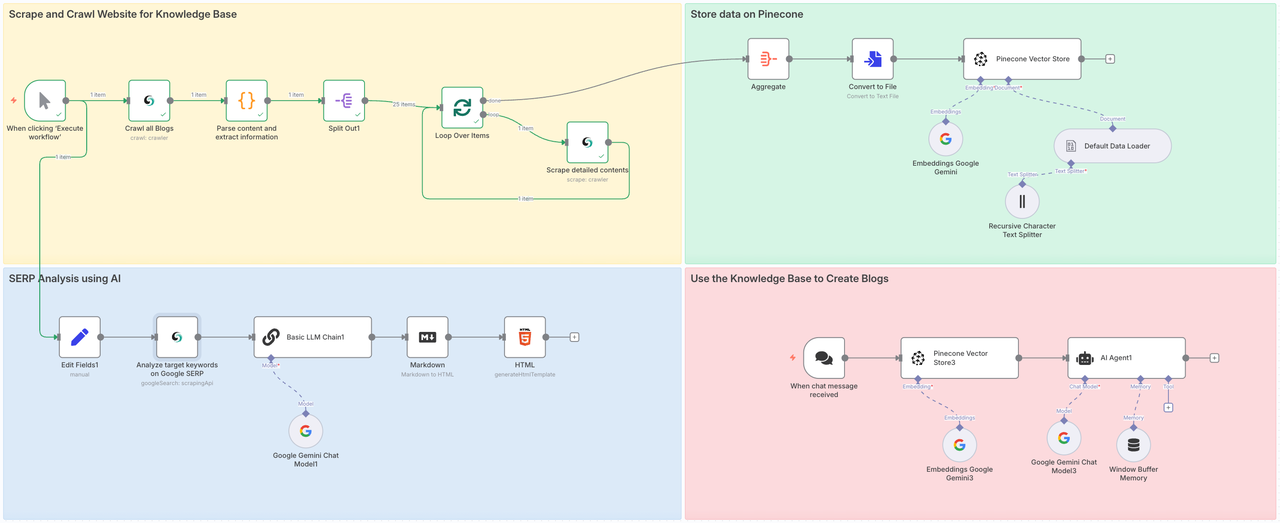
This workflow will involve four steps:
- Part 1: Call the Scrapeless Crawl to crawl all sub-pages of the target website, and use Scrape to deeply analyze the entire content of each page.
- Part 2: Store the crawled data in Pinecone Vector Store.
- Part 3: Use Scrapeless's Google Search node to fully analyze the value of the target topic or keywords.
- Part 4: Convey instructions to Gemini, integrate contextual content from the prepared database through RAG, and produce target blogs or answer questions.
If you haven't heard of Scrapeless, it’s a leading infrastructure company focused on powering AI agents, automation workflows, and web crawling. Scrapeless provides the essential building blocks that enable developers and businesses to create intelligent, autonomous systems efficiently.
At its core, Scrapeless delivers browser-level tooling and protocol-based APIs—such as headless cloud browser, Deep SERP API, and Universal Crawling APIs—that serve as a unified, modular foundation for AI agents and automation platforms.
It is really built for AI applications because AI models are not always up to date with many things, whether it be current events or new technologies
In addition to n8n, it can also be called through API, and there are nodes on mainstream platforms such as Make:
You can also use it directly on the official website.
To use Scrapeless in n8n:
- Go to Settings > Community Nodes
- Search for n8n-nodes-scrapeless and install it
We need to install the Scrapeless community node on n8n first:
Credential Connection
Scrapeless API Key
In this tutorial, we will use the Scrapeless service. Please make sure you have registered and obtained the API Key.
- Sign up on the Scrapeless website to get your API key and claim the free trial.
- Then, you can open the Scrapeless node, paste your API key in the credentials section, and connect it.
Pinecone Index and API Key
After crawling the data, we will integrate and process it and collect all the data into the Pinecone database. We need to prepare the Pinecone API Key and Index in advance.
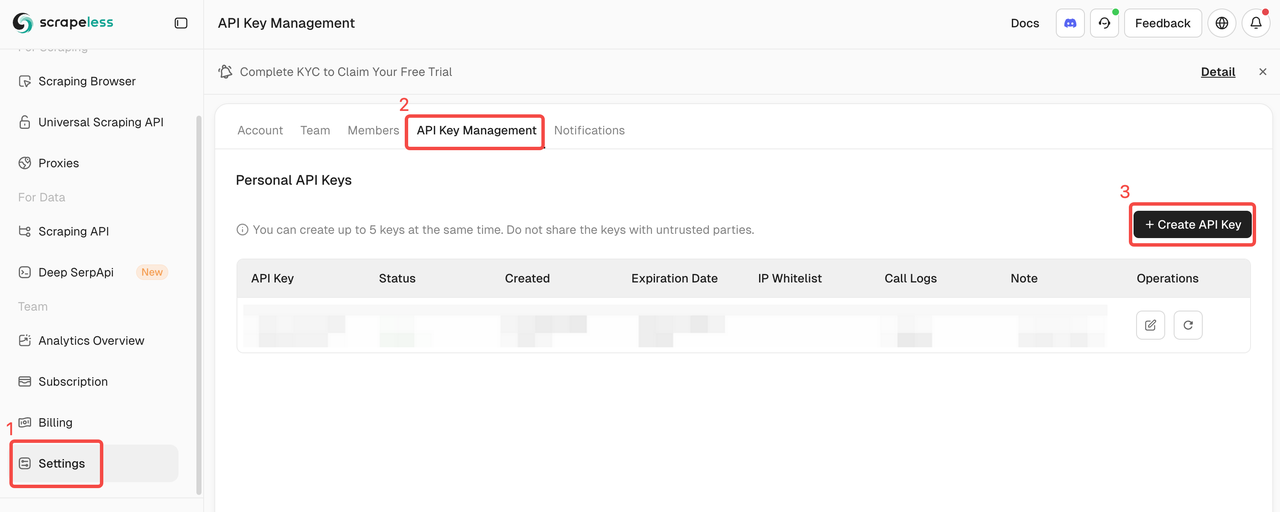
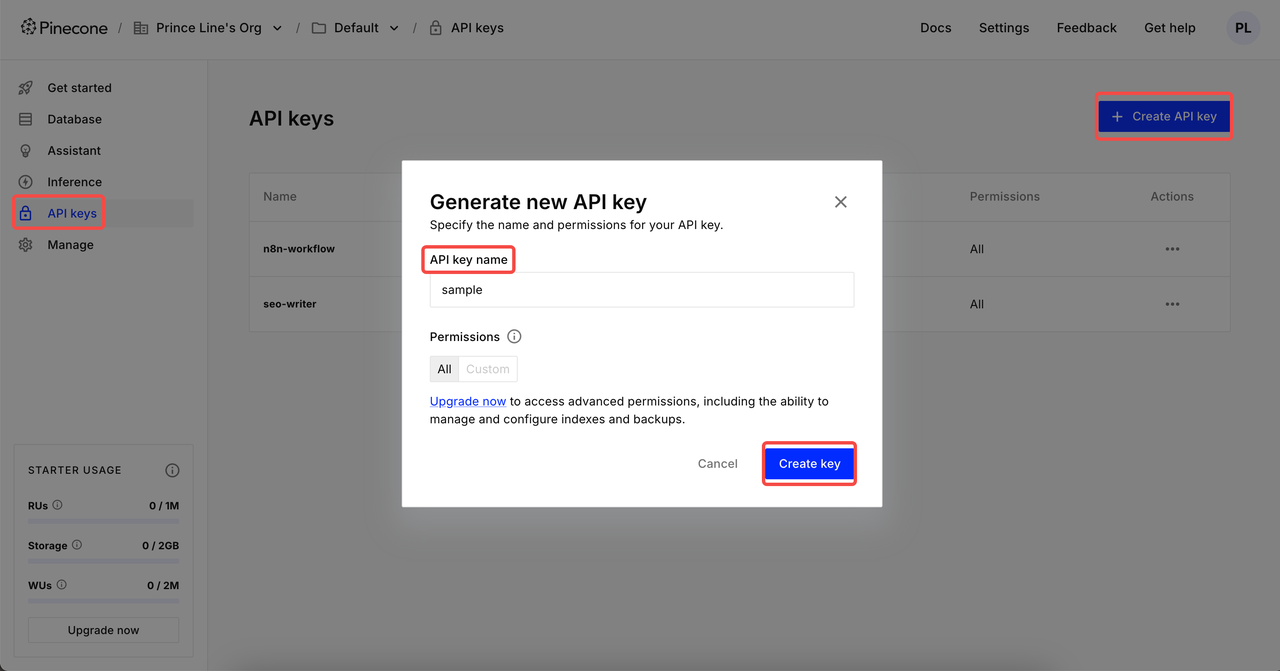
Create API Key
After logging in, click API Keys → Click Create API key → Supplement your API key name → Create key. Now, you can set it up in the n8n credentials
⚠️ After the creation is complete, please copy and save your API Key. For data security, Pinecone will no longer display the created API key.
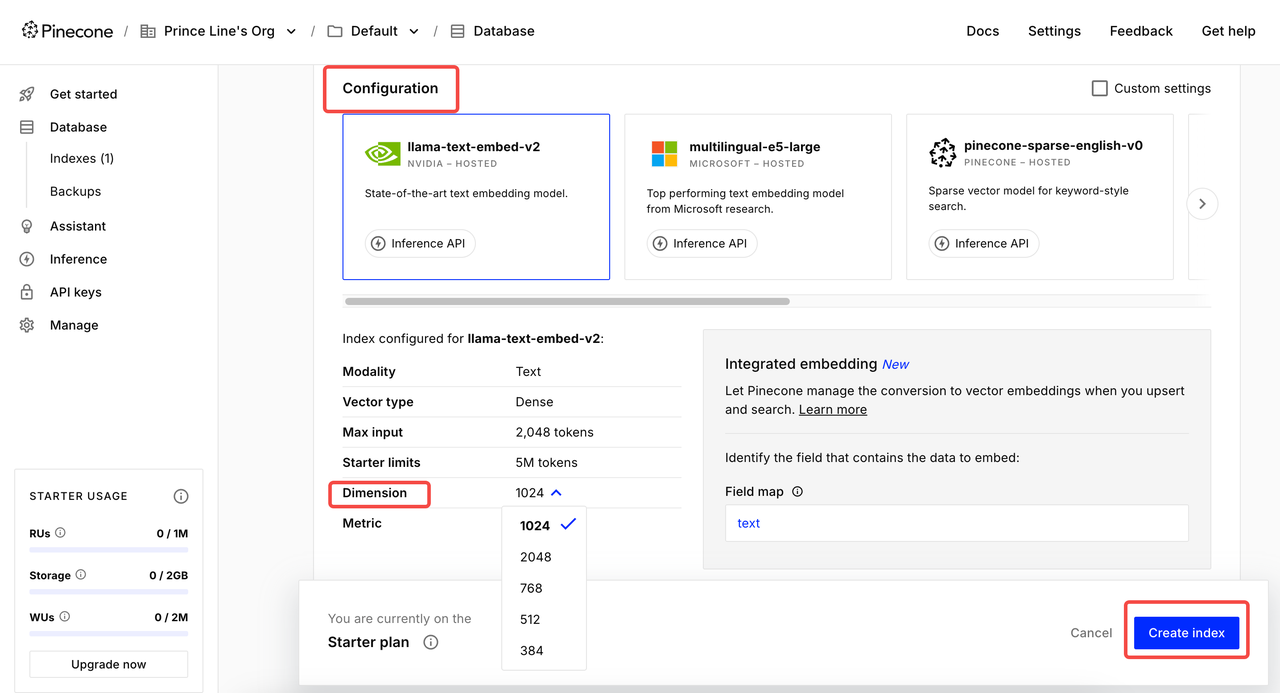
Create Index
Click Index and enter the creation page. Set the Index name → Select model for Configuration → Set the appropriate Dimension → Create index.
2 common dimension settings:
- Google Gemini Embedding-001 → 768 dimensions
- OpenAI's text-embedding-3-small → 1536 dimensions
Phase1: Scrape and Crawl Websites for Knowledge Base
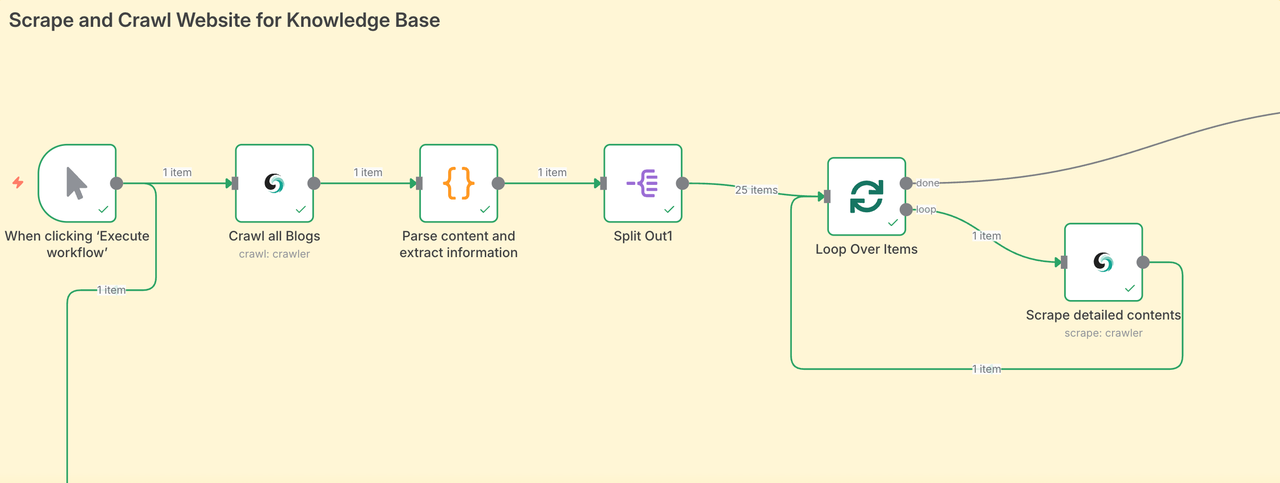
The first stage is to directly aggregate all blog content. Crawling content from a large area allows our AI Agent to obtain data sources from all fields, thereby ensuring the quality of the final output articles.
- The Scrapeless node crawls the article page and collects all blog post URLs.
- Then it loops through every URL, scrapes the blog content, and organizes the data.
- Each blog post is embedded using your AI model and stored in Pinecone.
- In our case, we scraped 25 blog posts in just a few minutes — without lifting a finger.
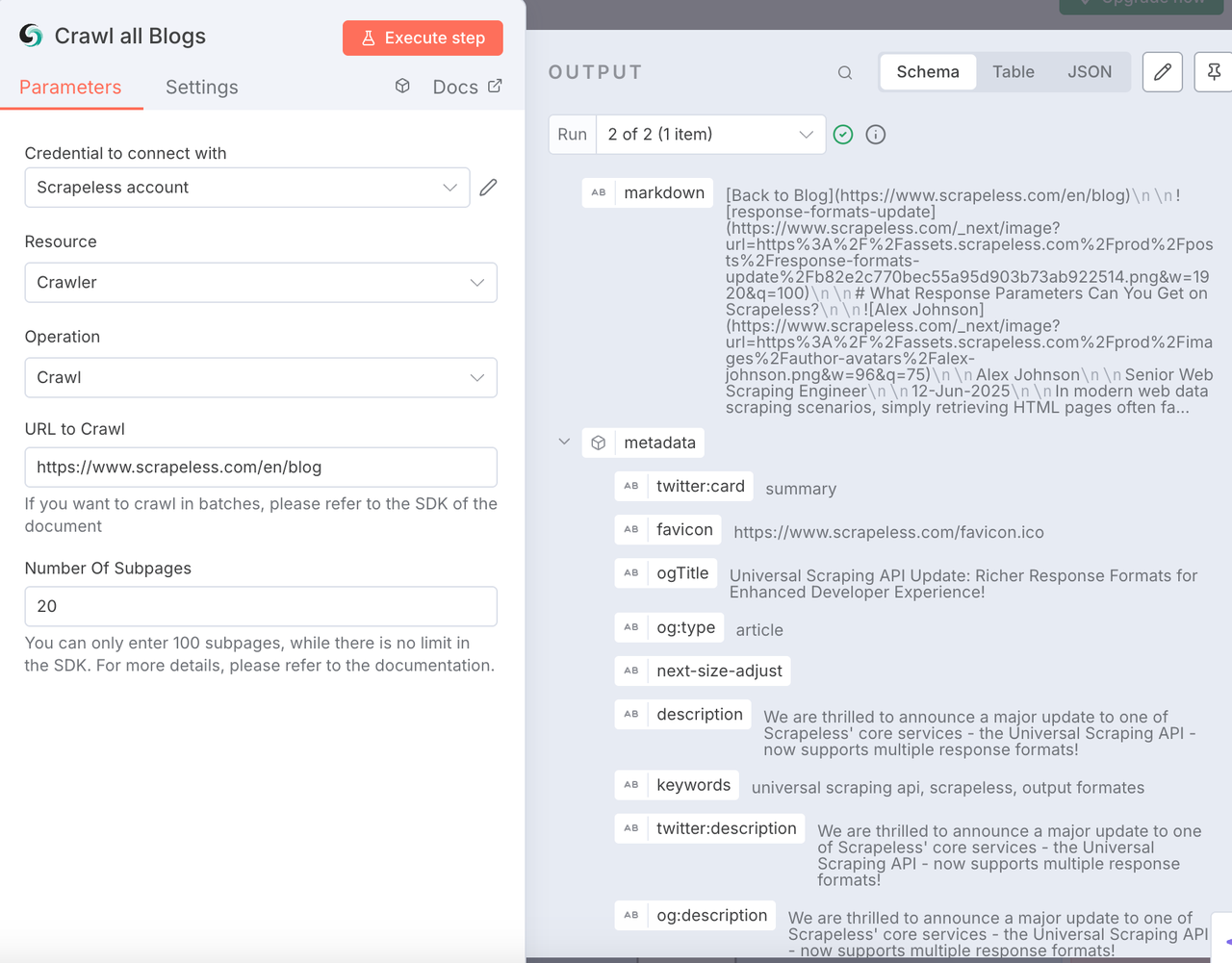
Scrapeless Crawl node
This node is used to crawl all the content of the target blog website including Meta data, sub-page content and export it in Markdown format. This is a large-scale content crawling that we cannot quickly achieve through manual coding.
Configuration:
- Connect your Scrapeless API key
- Resource:
Crawler - Operation:
Crawl - Input your target scraping website. Here we use https://www.scrapeless.com/en/blog as a reference.
Code node
After getting the blog data, we need to parse the data and extract the structured information we need from it.
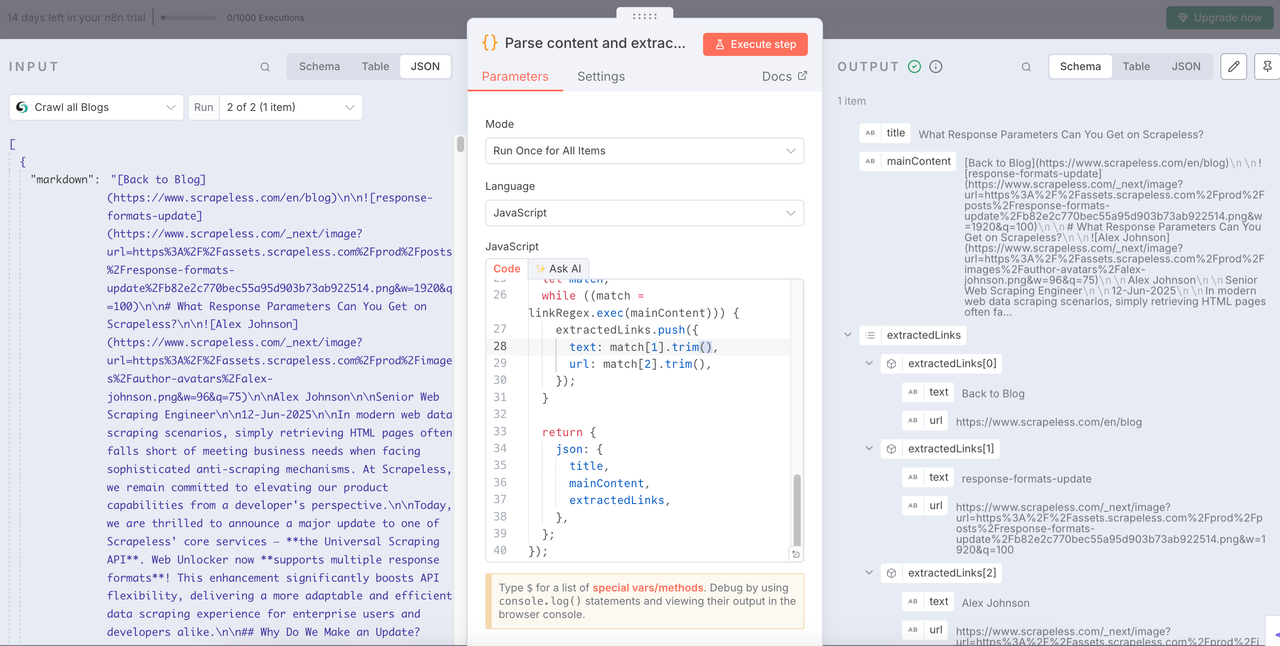
The following is the code I used. You can refer to it directly:
JavaScript
return items.map(item => {
const md = $input.first().json['0'].markdown;
if (typeof md !== 'string') {
console.warn('Markdown content is not a string:', md);
return {
json: {
title: '',
mainContent: '',
extractedLinks: [],
error: 'Markdown content is not a string'
}
};
}
const articleTitleMatch = md.match(/^#\s*(.*)/m);
const title = articleTitleMatch ? articleTitleMatch[1].trim() : 'No Title Found';
let mainContent = md.replace(/^#\s*.*(\r?\n)+/, '').trim();
const extractedLinks = [];
// The negative lookahead `(?!#)` ensures '#' is not matched after the base URL,
// or a more robust way is to specifically stop before the '#'
const linkRegex = /\[([^\]]+)\]\((https?:\/\/[^\s#)]+)\)/g;
let match;
while ((match = linkRegex.exec(mainContent))) {
extractedLinks.push({
text: match[1].trim(),
url: match[2].trim(),
});
}
return {
json: {
title,
mainContent,
extractedLinks,
},
};
});Node: Split out
The Split out node can help us integrate the cleaned data and extract the URLs and text content we need.
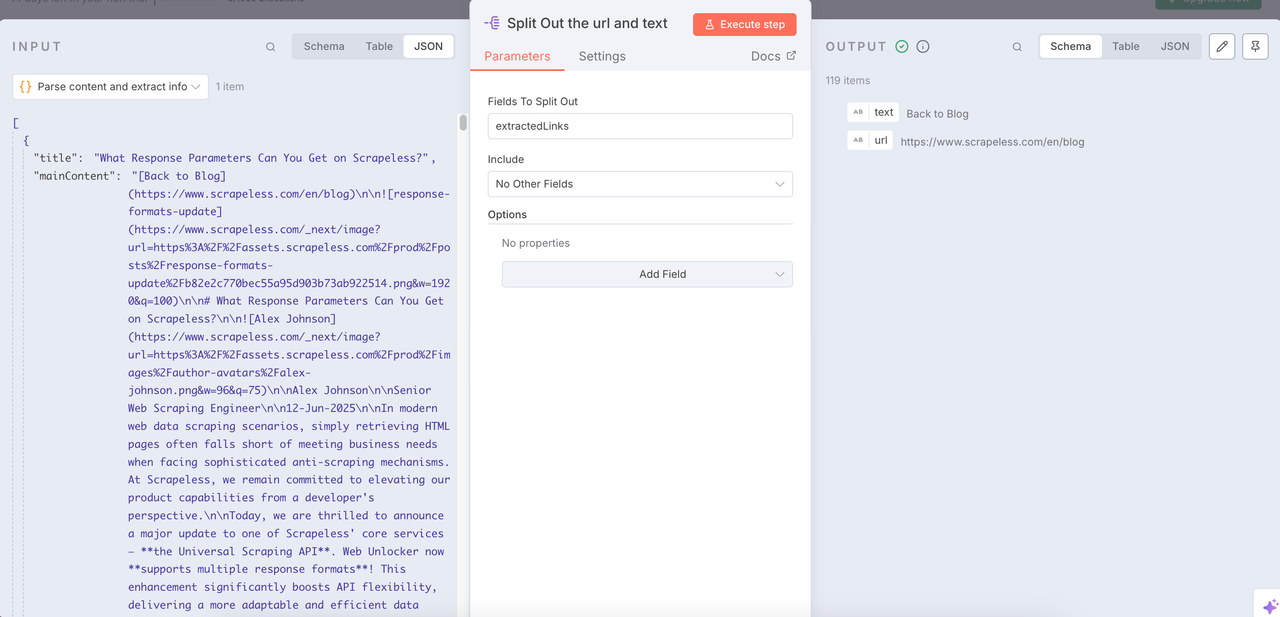
Loop Over Items + Scrapeless Scrape
Loop Over Items
Use the Loop Over Time node with Scrapeless's Scrape to repeatedly perform crawling tasks, and deeply analyze all the items obtained previously.
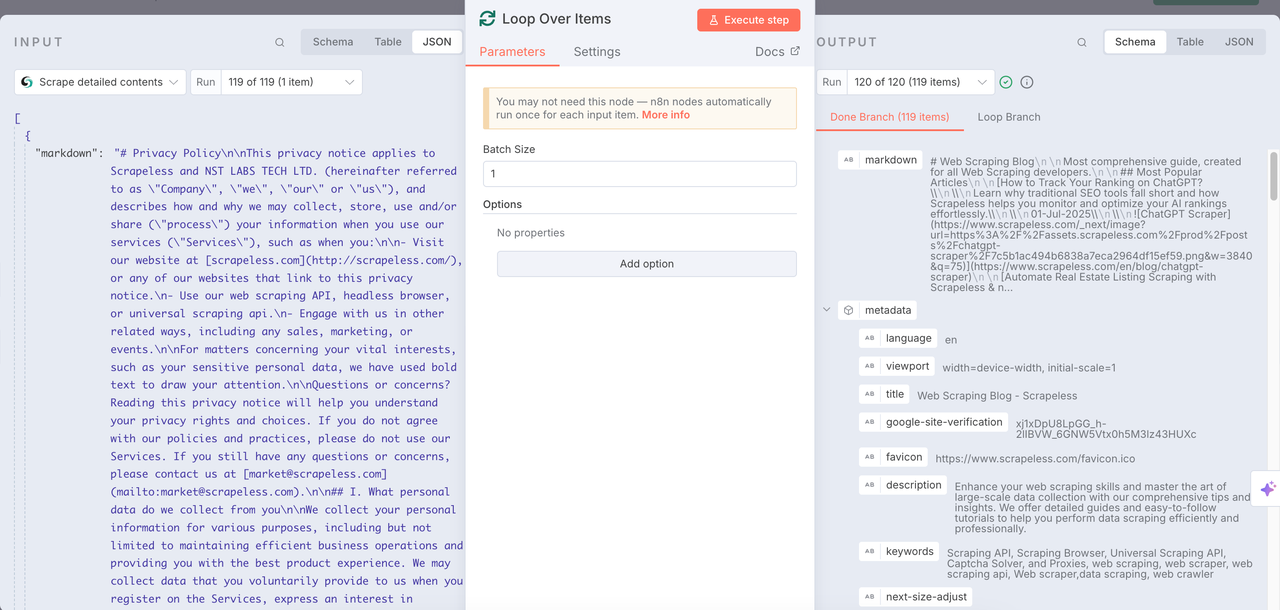
Scrapeless Scrape
Scrape node is used to crawl all the content contained in the previously obtained URL. In this way, each URL can be deeply analyzed. The markdown format is returned and metadata and other information are integrated.

Phase 2. Store data on Pinecone
We have successfully extracted the entire content of the Scrapeless blog page. Now we need to access the Pinecone Vector Store to store this information so that we can use it later.
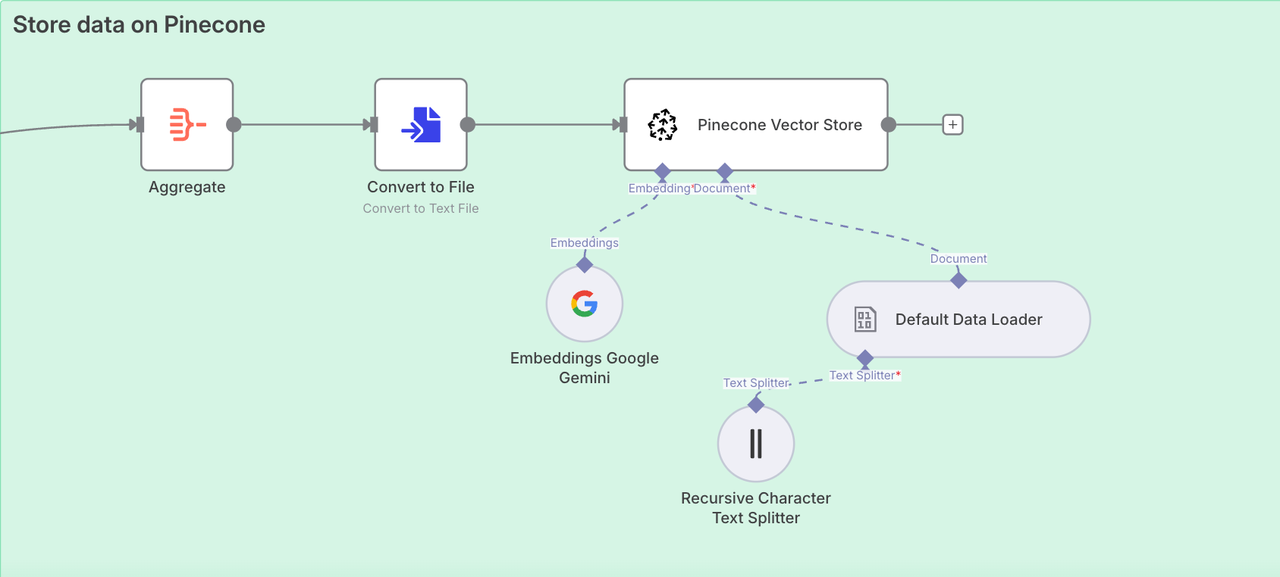
Node: Aggregate
In order to store data in the knowledge base conveniently, we need to use the Aggregate node to integrate all the content.
- Aggregate:
All Item Data (Into a Single List) - Put Output in Field:
data - Include:
All Fields
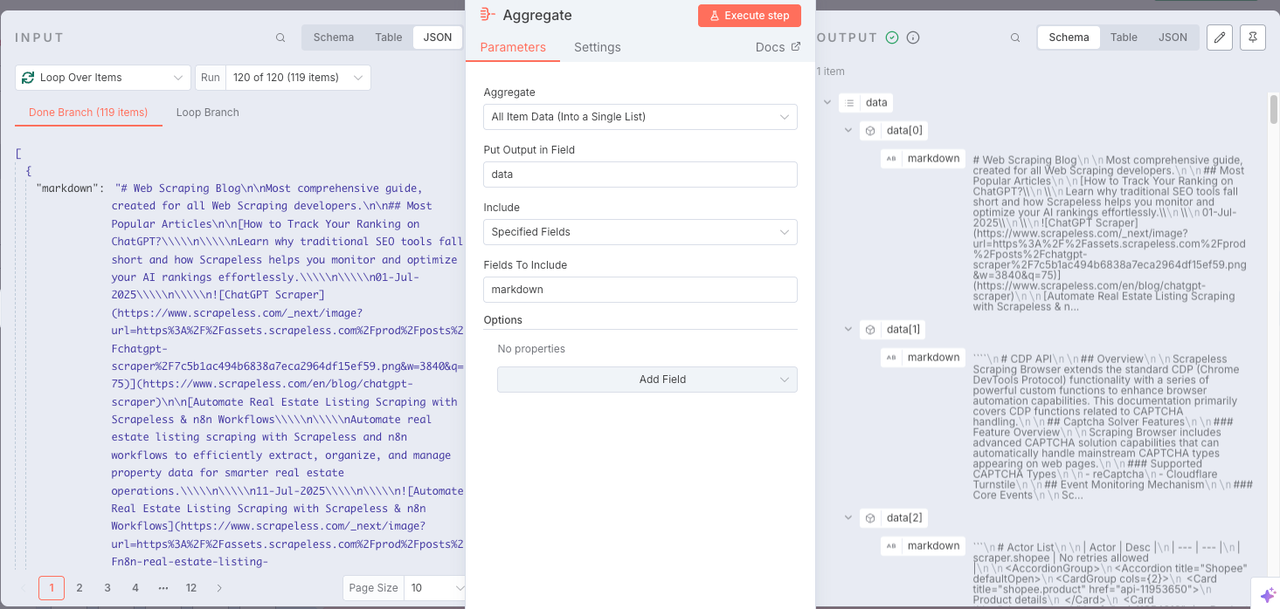
Node: Convert to File
Great! All the data has been successfully integrated. Now we need to convert the acquired data into a text format that can be directly read by Pinecone. To do this, just add a Convert to File.
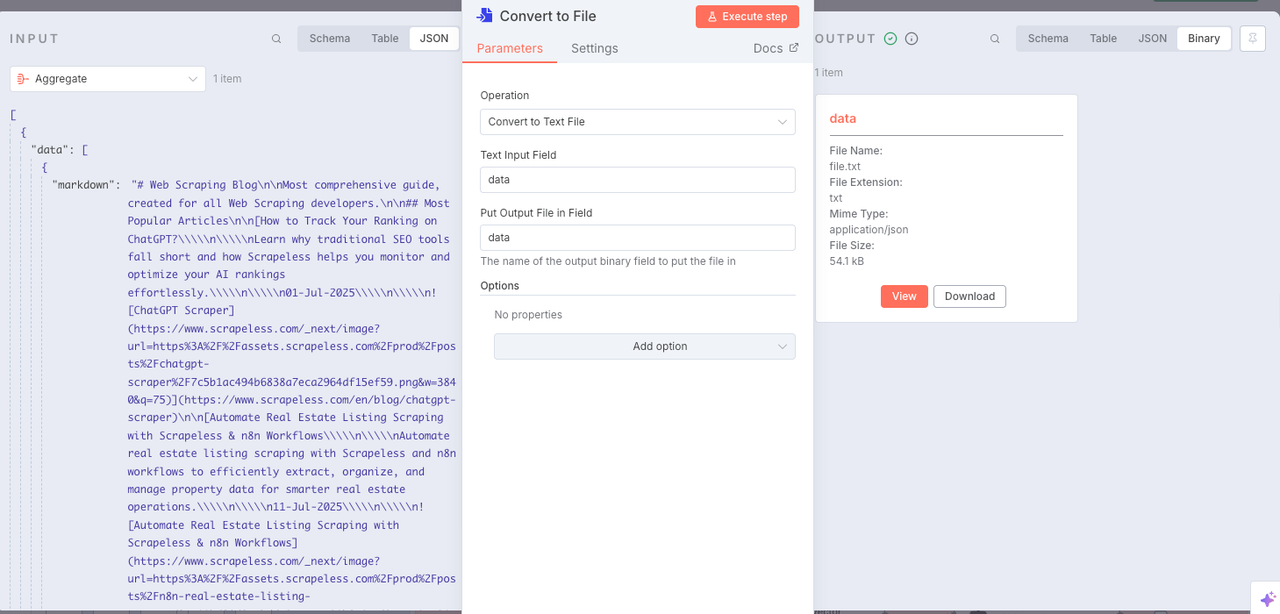
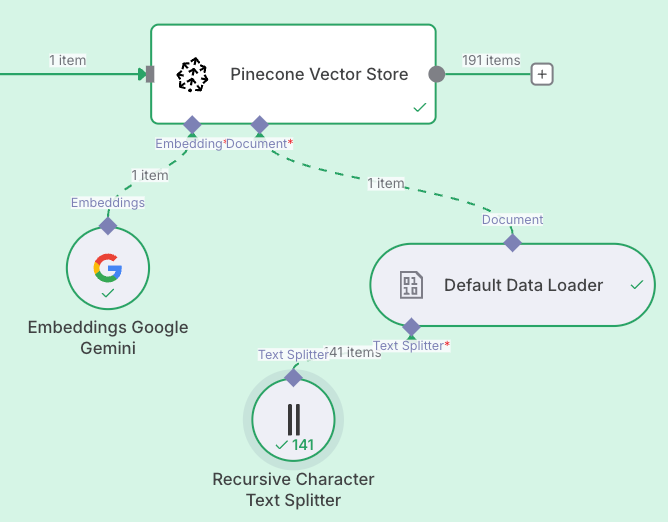
Node: Pinecone Vector store
Now we need to configure the knowledge base. The nodes used are:
Pinecone Vector StoreGoogle GeminiDefault Data LoaderRecursive Character Text Splitter
The above four nodes will recursively integrate and crawl the data we have obtained. Then all are integrated into the Pinecone knowledge base.
Phase 3. SERP Analysis using AI
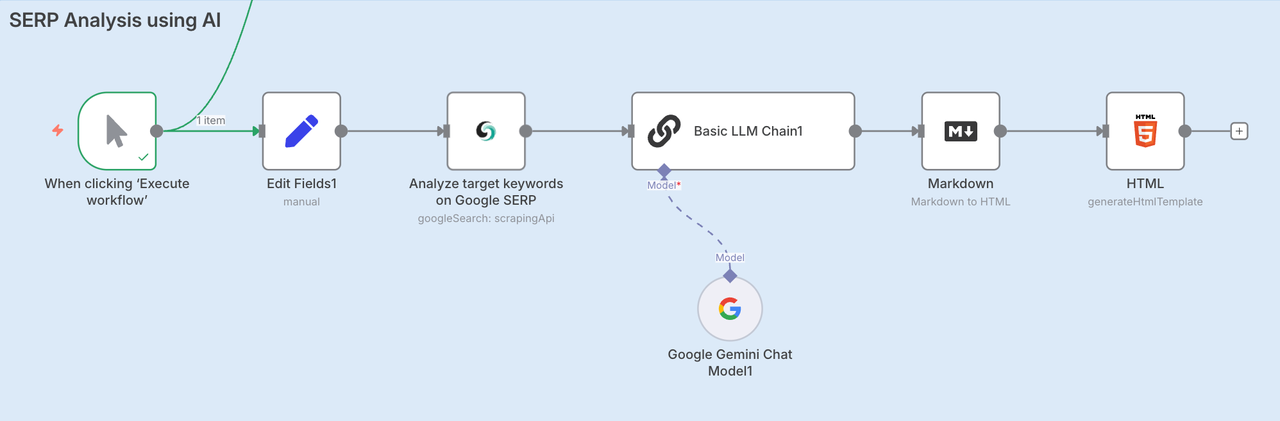
To ensure you're writing content that ranks, we perform a live SERP analysis:
- Use the Scrapeless Deep SerpApi to fetch search results for your chosen keyword
- Input both the keyword and search intent (e.g., Scraping, Google trends, API)
- The results are analyzed by an LLM and summarized into an HTML report
Node: Edit Fields
The knowledge base is ready! Now it’s time to determine our target keywords. Fill in the target keywords in the content box and add the intent.
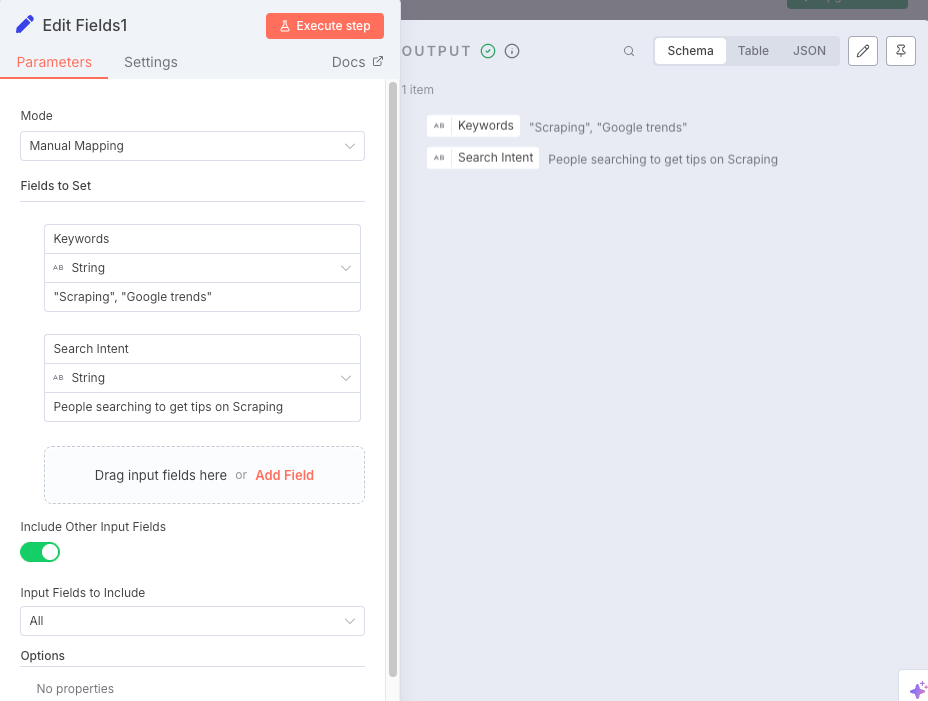
Node: Google Search
The Google Search node calls Scrapeless's Deep SerpApi to retrieve target keywords.
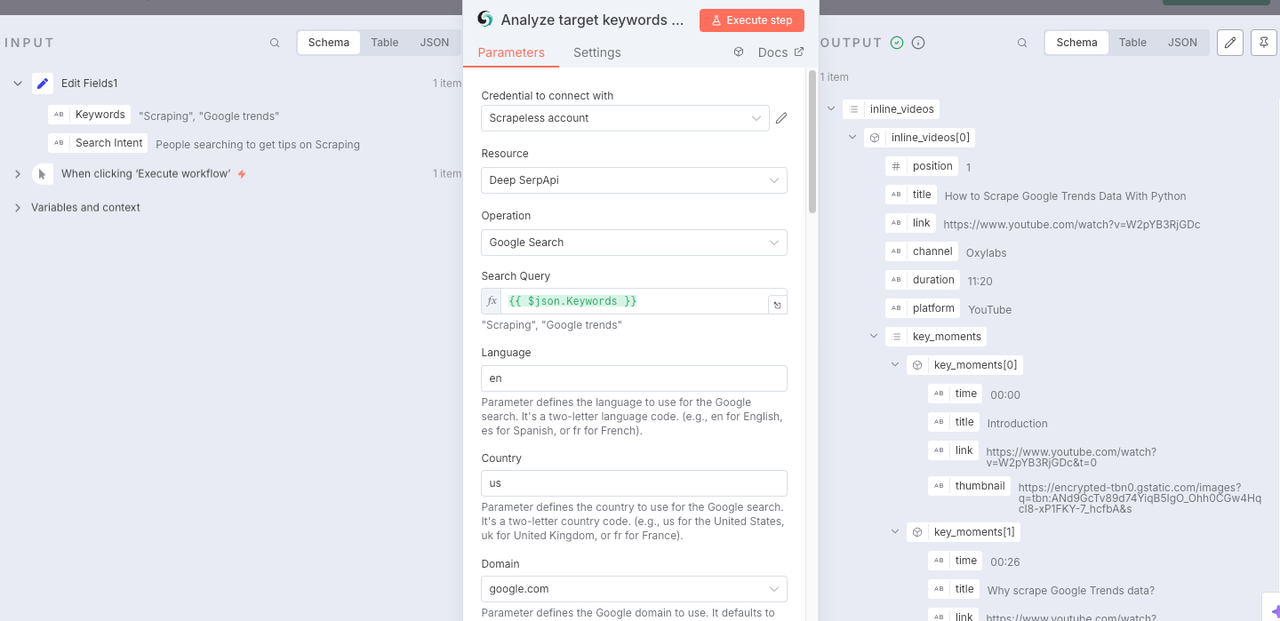
Node: LLM Chain
Building LLM Chain with Gemini can help us analyze the data obtained in the previous steps and explain to LLM the reference input and intent we need to use so that LLM can generate feedback that better meets the needs.
Node: Markdown
Since LLM usually exports in Markdown format, as users we cannot directly obtain the data we need most clearly, so please add a Markdown node to convert the results returned by LLM into HTML.
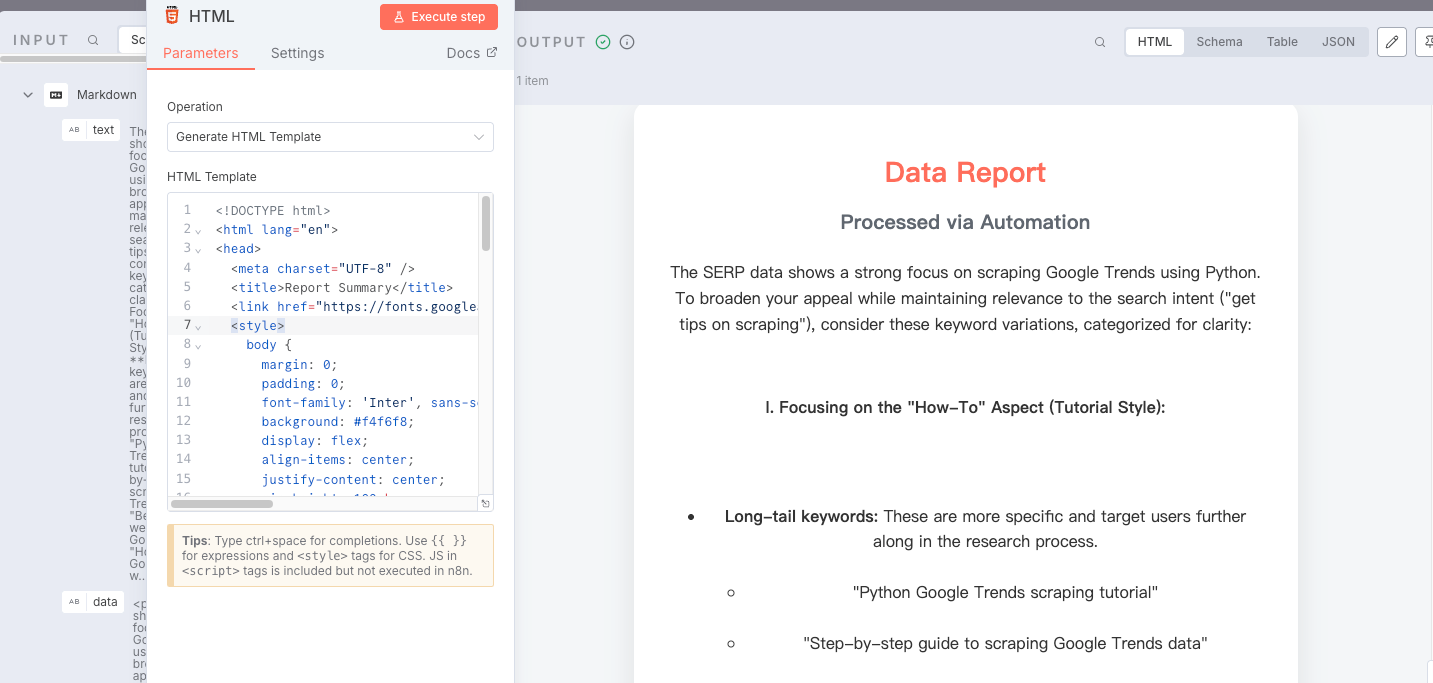
Node: HTML
Now we need to use the HTML node to standardize the results - use the Blog/Report format to intuitively display the relevant content.
- Operation:
Generate HTML Template
The following code is required:
XML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Report Summary</title>
<link href="https://fonts.googleapis.com/css2?family=Inter:wght@400;600;700&display=swap" rel="stylesheet">
<style>
body {
margin: 0;
padding: 0;
font-family: 'Inter', sans-serif;
background: #f4f6f8;
display: flex;
align-items: center;
justify-content: center;
min-height: 100vh;
}
.container {
background-color: #ffffff;
max-width: 600px;
width: 90%;
padding: 32px;
border-radius: 16px;
box-shadow: 0 10px 30px rgba(0, 0, 0, 0.1);
text-align: center;
}
h1 {
color: #ff6d5a;
font-size: 28px;
font-weight: 700;
margin-bottom: 12px;
}
h2 {
color: #606770;
font-size: 20px;
font-weight: 600;
margin-bottom: 24px;
}
.content {
color: #333;
font-size: 16px;
line-height: 1.6;
white-space: pre-wrap;
}
@media (max-width: 480px) {
.container {
padding: 20px;
}
h1 {
font-size: 24px;
}
h2 {
font-size: 18px;
}
}
</style>
</head>
<body>
<div class="container">
<h1>Data Report</h1>
<h2>Processed via Automation</h2>
<div class="content">{{ $json.data }}</div>
</div>
<script>
console.log("Hello World!");
</script>
</body>
</html>This report includes:
- Top-ranking keywords and long-tail phrases
- User search intent trends
- Suggested blog titles and angles
- Keyword clustering
Phase 4. Generating the Blog with AI + RAG
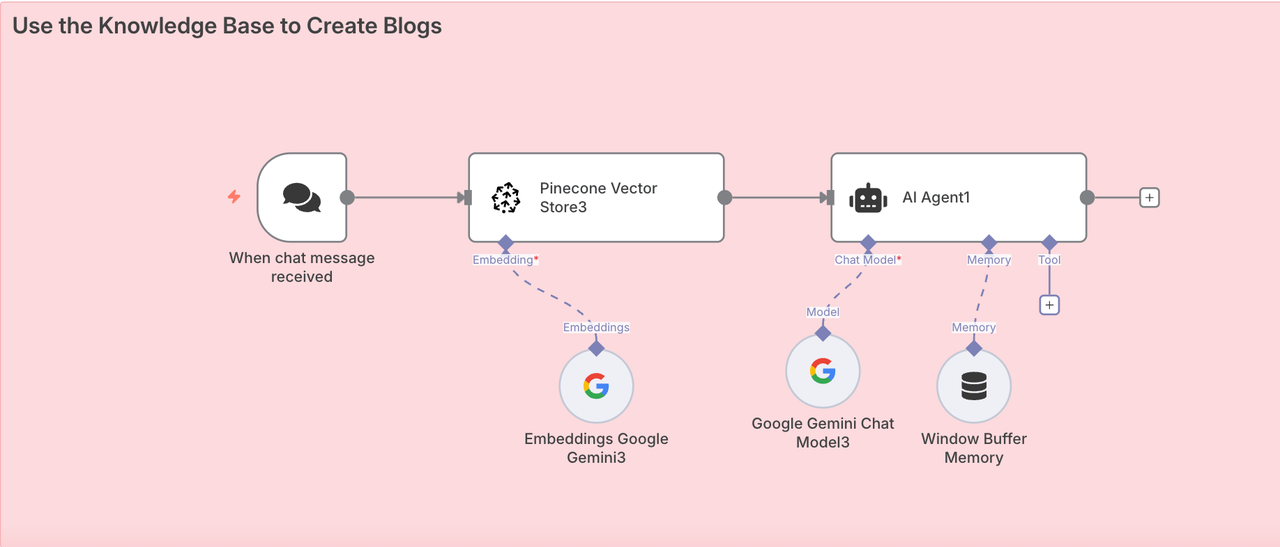
Now that you've collected and stored the knowledge and researched your keywords, it's time to generate your blog.
- Construct a prompt using insights from the SERP report
- Call an AI agent (e.g., Claude, Gemini, or OpenRouter)
- The model retrieves the relevant context from Pinecone and writes a full blog post
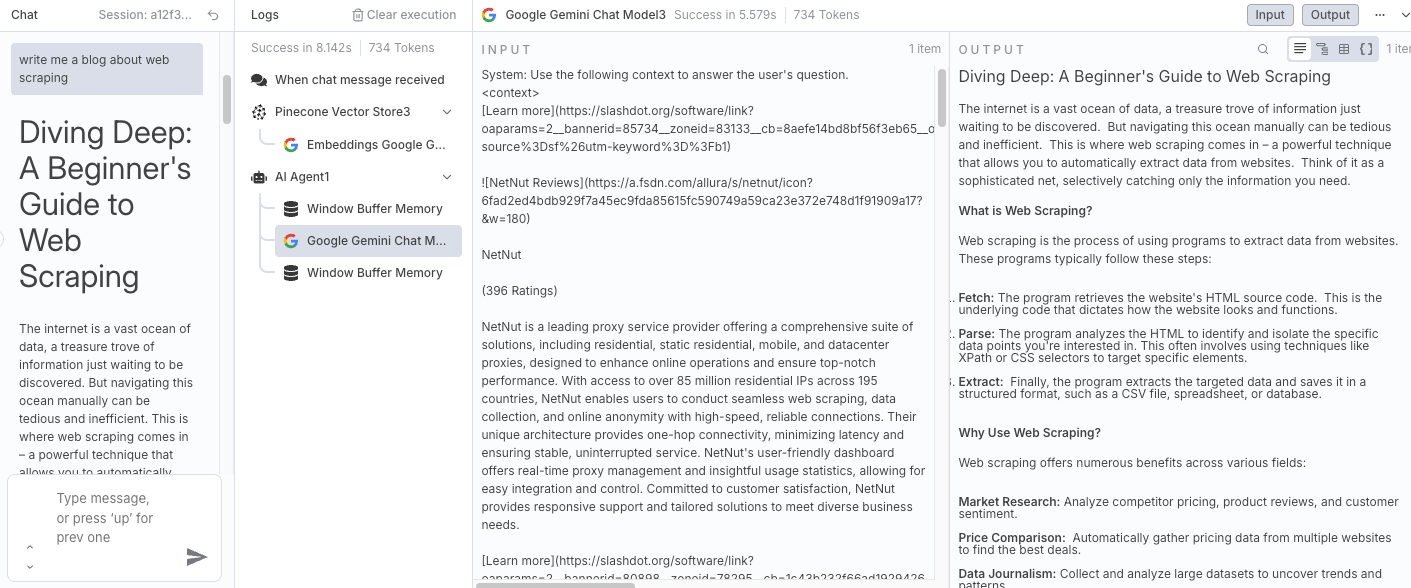
Unlike generic AI output, the result here includes specific ideas, phrases, and tone from Scrapeless' original content — made possible by RAG.
The Ending Thoughts
This end-to-end SEO content engine showcases the power of n8n + Scrapeless + Vector Database + LLMs.
You can:
- Replace Scrapeless Blog Page with any other blog
- Swap Pinecone for other vector stores
- Use OpenAI, Claude, or Gemini as your writing engine
- Build custom publishing pipelines (e.g., auto-post to CMS or Notion)
👉 Get started today by installing Scrapeless community node and start generating blogs at scale — no coding required.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


