Loading...
🎯 一款可定制、具备反检测功能的云浏览器,由自主研发的 Chromium驱动,专为网页爬虫和AI 代理设计。👉立即试用
最全面的指南,专为所有网络抓取开发者打造。
提供您的联系方式,我们将迅速联系您,提供产品演示和介绍。我们确保您的信息保密,符合GDPR标准。
了解什么是扭曲代理,以及它们如何帮助在线隐私、安全和访问地理限制内容。发现为什么像Scrapeless这样的现代解决方案提供更优越的匿名性。

探索顶级住宅代理提供商、它们的优势以及在选择满足您最苛刻的网络爬虫和匿名需求时需要考虑的关键因素。了解为什么Scrapeless是首选。

发现顶尖的数据中心代理提供商、他们的功能,以及如何选择最适合您高速度、大规模数据收集需求的服务。了解为什么Scrapeless是最佳选择。

了解什么是旋转代理,它们的使用案例,并比较2026年顶级旋转代理提供商,以找到满足您数据收集需求的最佳解决方案。了解为什么Scrapeless是首选。

探索2025年顶级ISP代理提供商,了解他们的特点和优势,并找到选择最适合您网页抓取需求的服务的建议。发现为什么Scrapeless被推荐为首选。

学习5种免费的代理测试方法:在线检查器、手动方法(ping/curl)、自动化脚本和基准测试工具。通过实用的测试方法确保速度、安全性和可靠性。

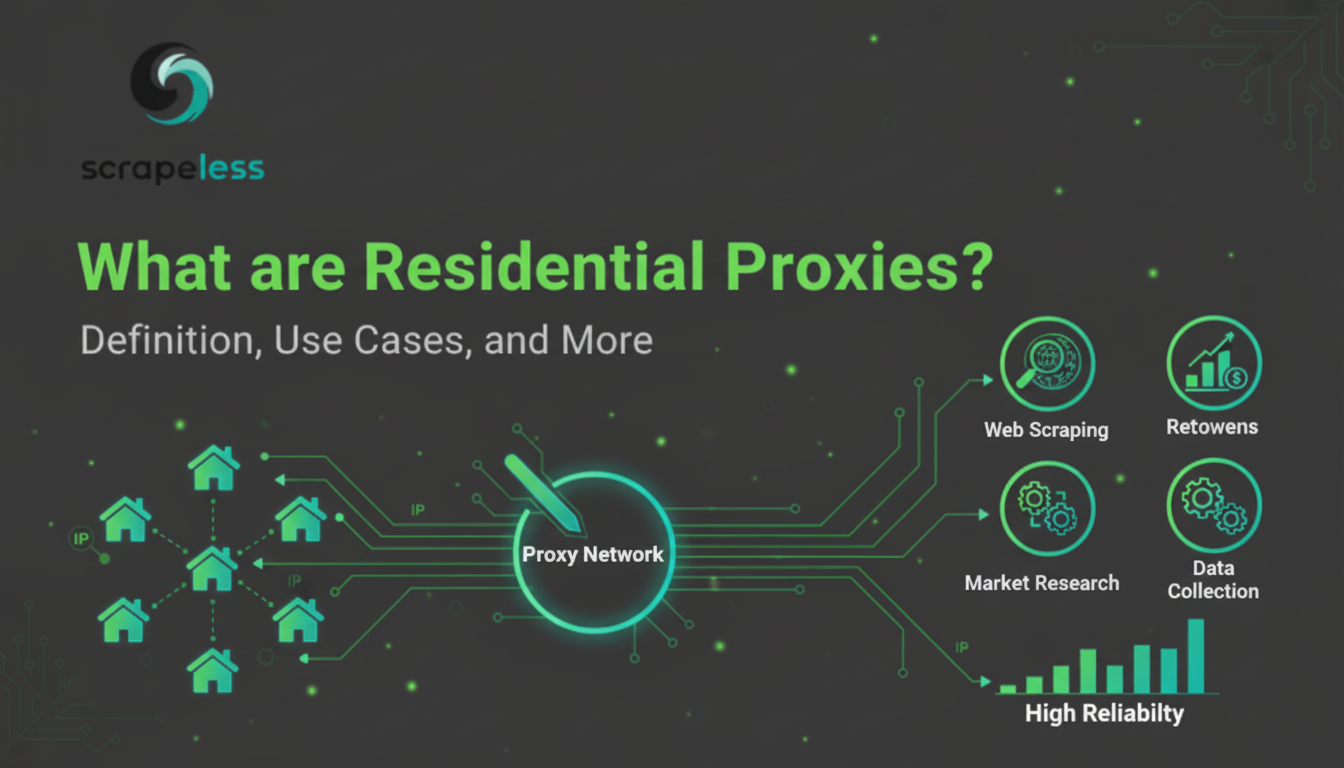
住宅代理的完整指南。了解它们是如何工作的,它们在网络抓取、价格监控和广告验证中的好处。发现为什么Scrapeless的9000万个IP和99.98%的成功率使其成为行业领导者。
学习如何使用HTTPX与Scrapeless代理进行可靠的网络抓取。完整指南包含未经身份验证、经过身份验证、轮换和备用代理连接的代码示例。99.98%的成功率,拥有超过9000万个住宅IP。



