Loading...
🎯 一款可定制、具备反检测功能的云浏览器,由自主研发的 Chromium驱动,专为网页爬虫和AI 代理设计。👉立即试用
最全面的指南,专为所有网络抓取开发者打造。
提供您的联系方式,我们将迅速联系您,提供产品演示和介绍。我们确保您的信息保密,符合GDPR标准。
学习如何使用 Python 的 socket 和 threading 模块构建一个基本的多线程 HTTP 代理服务器。本指南涵盖了网络编程的核心概念,并将自定义解决方案与像 Scrapeless Proxies 这样的商业服务的强大功能进行了比较,以便于生产级网页抓取。

探索UDP代理的世界:了解它们是什么,如何作为实时应用程序(如游戏和VoIP)的网关运行,以及它们与HTTP和SOCKS代理的比较。发现使用像Scrapeless这样的专业代理解决方案以满足您的数据需求的好处。

一份关于在 Node.js 中使用 `node-fetch` 库和代理代理包配置 HTTP/HTTPS 和 SOCKS 代理的逐步指南,这是匿名网络爬虫和数据收集所必需的。特色无痕代理。

一份全面的IPv6指南,详细介绍了其128位结构、相较于IPv4的关键优势(地址空间、安全性、效率),以及在为网页抓取提供可扩展且具成本效益的代理解决方案方面的关键作用。

了解开放代理是什么,它们的好处,以及它们带来的重大安全风险。了解为什么像Scrapeless这样的高级服务提供了一个更安全、更可靠的替代方案,以实现匿名和网络爬取。

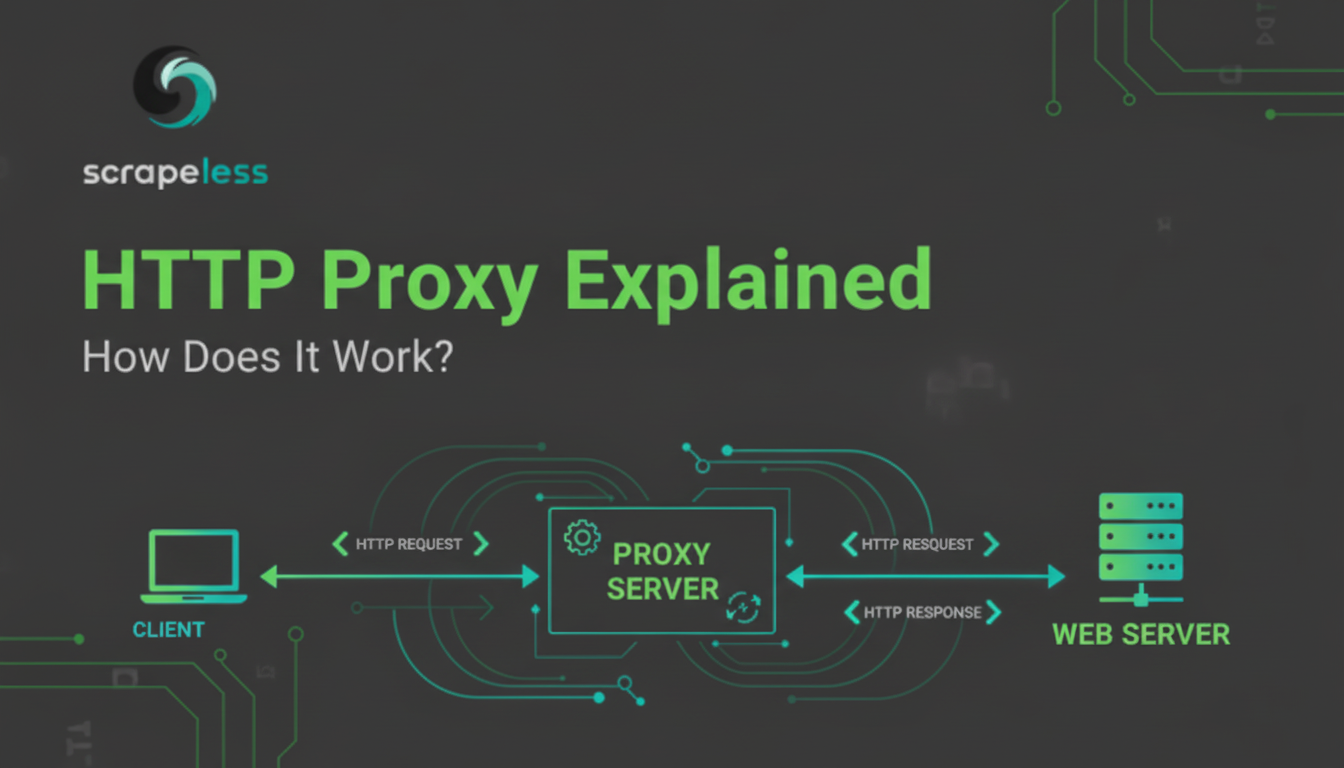
对HTTP代理的详细解释,涵盖其功能、类型(正向代理、反向代理、透明代理)、优点(安全性、缓存、匿名性)和在网络爬虫中的重要角色。功能包括无痕代理。
《星际代理的全面指南》,涵盖其特点、部署步骤,以及为何像Scrapeless Proxies这样的专业解决方案对于可靠的大规模数据操作至关重要。

比较IPv4和IPv6在现实世界中的速度和性能,分析设计差异、基础设施影响,以及像Scrapeless这样的双协议代理如何优化您的数据抓取和网络操作。



