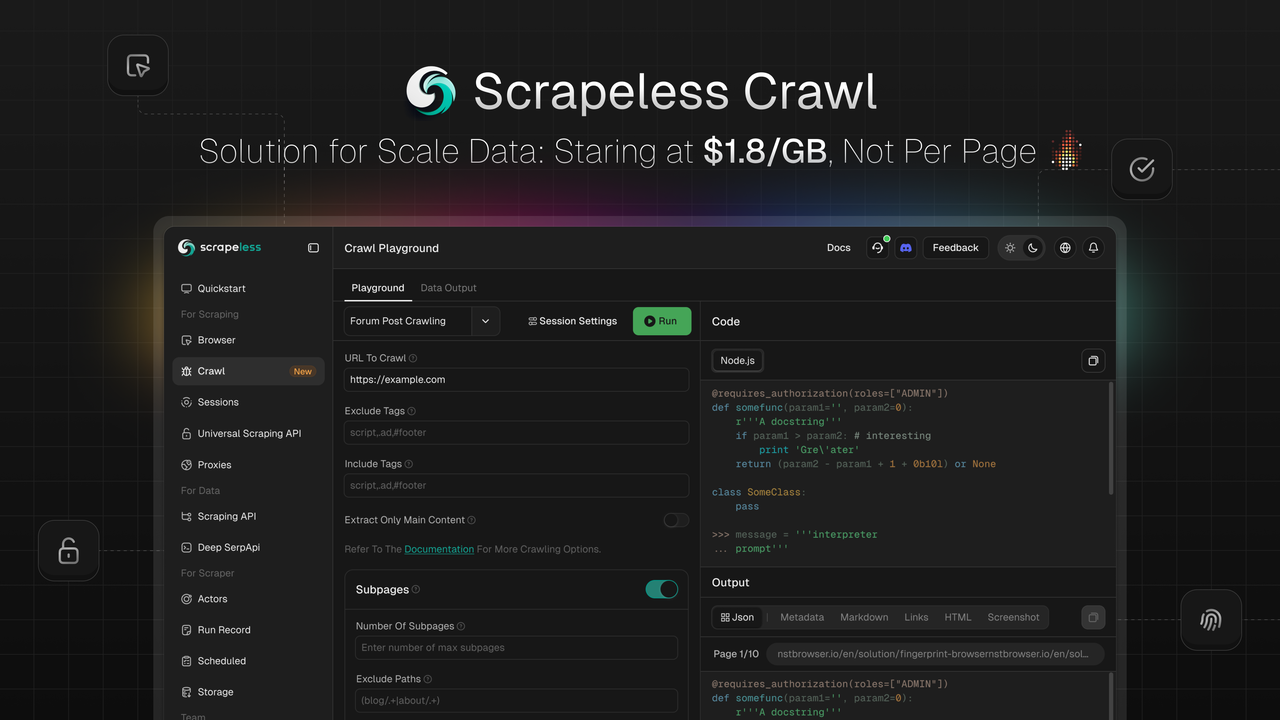
什么是Scrapeless Crawl?它是如何工作的?
Senior Web Scraping Engineer
Scrapeless 很高兴推出 Crawl,这是一个专为大规模数据抓取和处理而设计的功能。Crawl 以其核心优势脱颖而出,包括 智能递归抓取、批量数据处理能力 和 灵活的多格式输出,使企业和开发者能够迅速获取和处理海量网络数据,为人工智能训练、市场分析、商业决策等应用提供动力。
💡即将推出:通过 AI LLM 网关进行数据提取和摘要,与开源框架和可视化工作流集成无缝对接——为 AI 开发者解决网络内容难题。
什么是 Crawl
Crawl 不仅仅是一个简单的数据抓取工具,而是一个综合平台,集成了抓取和爬虫功能。
-
批量爬虫:支持大规模单页抓取和递归抓取。
-
多格式交付:兼容 JSON、Markdown、元数据、HTML、链接 和 屏幕截图 等格式。
-
反检测抓取:我们自主开发的 Chromium 内核,支持高定制、高会话管理和反检测能力,如 指纹配置、验证码解决、隐身模式 和 代理轮换,以绕过网站屏蔽。
-
自主开发的 Chromium 驱动:由我们的 Chromium 内核提供支持,实现高定制、会话管理和自动验证码解决。
1. 自动验证码解决:自动处理常见的验证码类型,包括 reCAPTCHA v2 和 Cloudflare Turnstile/Challenge。
2. 会话录制和回放:会话回放帮助您轻松检查操作和请求,通过录制的播放逐步审核,以便快速理解操作以解决问题和改进流程。
3. 并发优势:与其他限制严格的爬虫不同,Crawl 的 基础计划 支持 50 并发,在高级计划中支持 无限并发。
4. 节省成本:在具有反爬措施的网站上优于竞争对手,提供显著的免费验证码解决优势——预计 节省 70% 成本。
利用先进的数据抓取和处理能力,Crawl 确保提供结构化的 实时搜索数据。这一点使企业和开发者能够始终走在市场趋势前沿,优化数据驱动的自动化工作流,并迅速调整市场策略。
用 Crawl 解决复杂数据挑战:更快、更智能、更高效
对于需要规模可靠网络数据的开发者和企业,Crawl 还提供:
✔ 高速数据抓取 – 在几秒钟内从多个网页检索数据
✔ 无缝集成– 即将与开源框架和可视化工作流集成,如 Langchain、N8n、Clay、Pipedream、Make 等。
✔ 地理定向代理 – 内置代理支持 195 个国家
✔ 会话管理 – 智能管理会话,并实时查看 LiveURL 会话
如何使用 Crawl
Crawl API 通过一次调用从网页获取特定内容或递归抓取整个网站及其链接以收集所有可用数据,从而简化了数据抓取,支持多种格式。
Scrapeless 提供端点以启动抓取请求并检查其状态/结果。默认情况下,抓取是异步的:首先启动作业,然后监控其状态直到完成。然而,我们的 SDK 包含一个简单的功能,可以处理整个过程,并在作业完成后返回数据。
安装
使用 NPM 安装 Scrapeless SDK:
Bash
npm install @scrapeless-ai/sdk使用 PNPM 安装 Scrapeless SDK:
Bash
pnpm add @scrapeless-ai/sdk抓取单页
从网页中一次性抓取特定数据(例如,产品细节、评论)。
使用示例
JavaScript
import { Scrapeless } from "@scrapeless-ai/sdk";
// 初始化客户端
const client = new Scrapeless({
apiKey: "your-api-key", // 从 https://scrapeless.com 获取 API 密钥
});
(async () => {
const result = await client.scrapingCrawl.scrape.scrapeUrl(
"https://example.com"
);
console.log(result);
})();浏览器配置
您可以自定义抓取的会话设置,例如使用代理,就像创建新的浏览器会话一样。
Scrapeless 自动处理常见的 CAPTCHA,包括 reCAPTCHA v2 和 Cloudflare Turnstile/Challenge——无须额外设置,详情请见 捕获解决。
要探索所有浏览器参数,请查看 API 参考 或 浏览器参数。
JavaScript
import { Scrapeless } from "@scrapeless-ai/sdk";
// 初始化客户端
const client = new Scrapeless({
apiKey: "your-api-key", // 从 https://scrapeless.com 获取你的 API 密钥
});
(async () => {
const result = await client.scrapingCrawl.scrapeUrl(
"https://example.com",
{
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();抓取配置
抓取任务的可选参数包括输出格式、只返回主页内容的过滤,以及设置页面导航的最大超时时间。
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// 初始化客户端
const client = new ScrapingCrawl({
apiKey: "your-api-key", // 从 https://scrapeless.com 获取你的 API 密钥
});
(async () => {
const result = await client.scrapeUrl(
"https://example.com",
{
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
}
);
console.log(result);
})();有关抓取端点的完整参考,请查看 API 参考。
批量抓取
批量抓取的工作方式与常规抓取相同,不同之处在于您可以提供一组 URL 进行一次抓取。
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// 初始化客户端
const client = new ScrapingCrawl({
apiKey: "your-api-key", // 从 https://scrapeless.com 获取你的 API 密钥
});
(async () => {
const result = await client.batchScrapeUrls(
["https://example.com", "https://scrapeless.com"],
{
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();爬取子页面
爬取 API 支持递归地爬取网站及其链接,以提取所有可用数据。
有关详细用法,请查看爬取 API 参考。
用法
使用递归爬取来探查整个域及其链接,提取每一个可访问的数据。
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// 初始化客户端
const client = new ScrapingCrawl({
apiKey: "your-api-key", // 从 https://scrapeless.com 获取你的 API 密钥
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
scrapeOptions: {
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
},
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();响应
JavaScript
{
"success": true,
"status": "completed",
"completed": 2,
"total": 2,
"data": [
{
"url": "https://example.com",
"metadata": {
"title": "示例页面",
"description": "一个示例网页"
},
"markdown": "# 示例页面\n这是内容...",
...
},
...
]
}每个爬取的页面都有自己的状态 completed 或 failed,并可能具有自己的错误字段,因此请小心处理。若要查看完整的架构,请查看 API 参考。
浏览器配置
自定义抓取任务的会话配置与创建新浏览器会话的流程相同。可用的选项包括代理配置。若要查看所有支持的会话参数,请查阅 API 参考 或 浏览器参数。
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// 初始化客户端
const client = new ScrapingCrawl({
apiKey: "your-api-key", // 从 https://scrapeless.com 获取你的 API 密钥
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
browserOptions: {
proxy_country: "ANY",
session_name: "Crawl",
session_recording: true,
session_ttl: 900,
},
}
);
console.log(result);
})();抓取配置
参数可以包括输出格式、仅返回主页内容的过滤器以及页面导航的最大超时设置。
JavaScript
import { ScrapingCrawl } from "@scrapeless-ai/sdk";
// 初始化客户端
const client = new ScrapingCrawl({
apiKey: "your-api-key", // 从 https://scrapeless.com 获取您的 API 密钥
});
(async () => {
const result = await client.crawlUrl(
"https://example.com",
{
limit: 2,
scrapeOptions: {
formats: ["markdown", "html", "links"],
onlyMainContent: false,
timeout: 15000,
}
}
);
console.log(result);
})();有关抓取端点的完整参考,请查看 API 参考。
探索抓取的多样化用例
开发人员可以访问内置的游乐场来测试和调试他们的代码,您可以利用抓取满足任何抓取需求,例如:
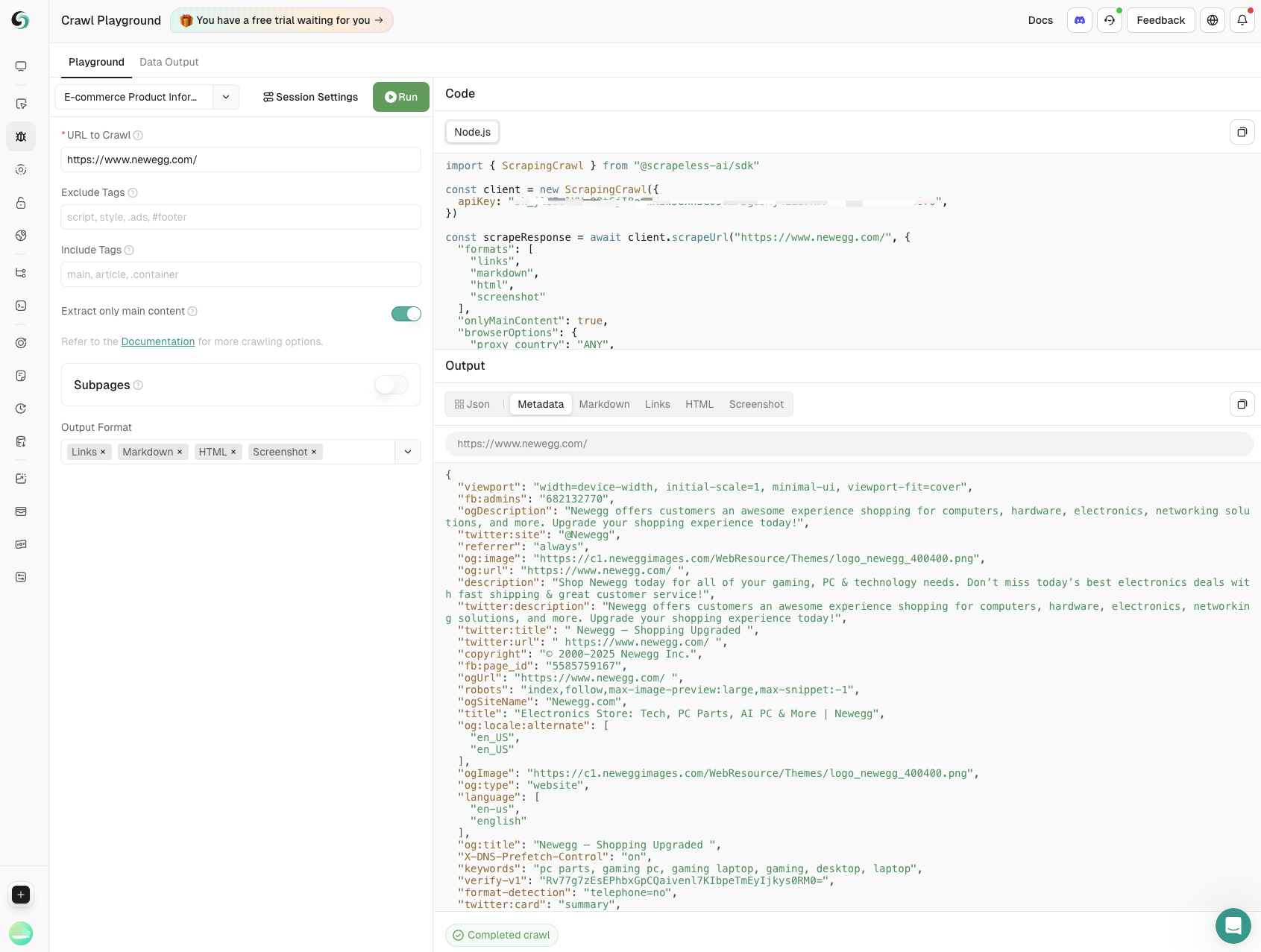
- 产品信息抓取
通过在电子商务网站上的抓取,提取关键数据,包括产品名称、价格、用户评分和评论数量。全面支持产品监控,帮助企业做出明智的决策。
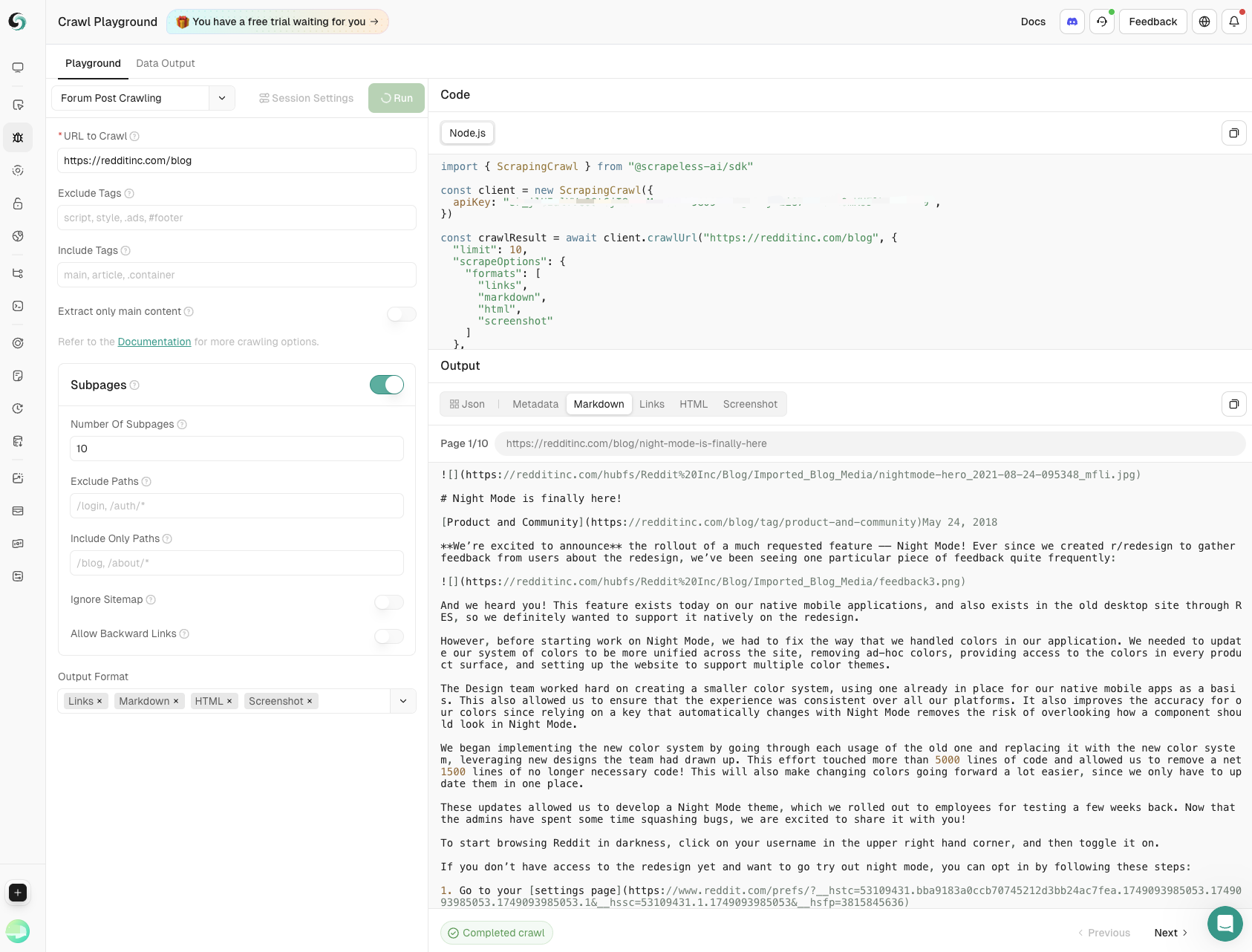
- 论坛帖子抓取
捕捉主帖内容和子页面评论,精确控制深度和广度,确保从社区讨论中获得全面洞察。
立即享受抓取和抓取!
适合任何需求的经济实惠:起价为 $1.8/GB,非按页计费
我们的基于 Chromium 的抓取器以结合代理流量和小时费率的定价模型超越竞争对手,在大规模数据项目中与按页计费模型相比节省 70% 的成本。
立即注册试用并获取强大的网络工具包。
💡对于大宗用户,请联系我们以获取定制定价 – 竞争性价格根据您的需求量身定制。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


