
如何抓取TikTok获取视频信息?
Expert Network Defense Engineer
TikTok 是领先的社交媒体平台之一,拥有海量流量。试想一下,TikTok 能提供多少宝贵的数据!
本文将讲解如何抓取 TikTok 视频信息。此外,我们将演示如何通过 TikTok 的隐藏 API 或嵌入式 JSON 数据集来抓取这些数据。让我们开始吧!
为什么抓取 TikTok 数据?
TikTok 拥有巨大的社交参与度,使其能够为不同的用例收集各种见解:
趋势分析
TikTok 上的趋势变化迅速,难以跟上用户最新的偏好。抓取 TikTok 数据可以有效地捕捉这些趋势变化及其影响,从而改进与用户兴趣相符的营销策略。
潜在客户开发
抓取 TikTok 数据使企业能够识别营销机会和新客户。这可以通过查明其粉丝人口统计数据与相关商业领域匹配的影响者来实现。
情感分析
TikTok 网页抓取是收集评论文本数据的绝佳来源,可以通过情感模型分析这些数据来收集对特定主题的意见。
抓取 TikTok 数据的挑战
TikTok 抓取是指从 TikTok 中提取公开可用数据的过程。虽然它可能涉及手动和自动活动,但它通常是由网络爬虫或与 TikTok 的 API(应用程序编程接口)交互的自定义脚本执行的自动化过程。
数据可能包括各种类型的信息,例如:
- 用户资料: 关于 TikTok 用户的信息,包括个人资料名称、个人简介和粉丝数量。
- 人口统计数据: 与用户特征相关的数据,例如年龄、性别、位置和兴趣。
- 视频: 用户发布的短视频,包括字幕、点赞、评论、分享和观看次数。
- 主题标签: 用于对 TikTok 内容进行分类的关键词或短语。
- 评论: 用户提交的文本回复,包括文本内容、时间戳和点赞数。
- 互动指标: 关于用户如何与内容互动的信息(点赞、评论、分享、观看次数)。
- 趋势: 关于 TikTok 上热门话题、主题或风格的数据。
如何构建你的 TikTok 抓取工具?
让我们简化一下!我们现在正式开始逐步抓取 TikTok 视频数据的过程。是时候体验 TikTok 提供的巨大价值了!
在开始实际抓取过程之前,让我们首先一起检查一下 TikTok 视频内容的结构。这将使我们能够更有效地找到所需信息,并以更直接的方式完成数据提取。
我们能从视频中抓取哪些数据?
- 视频 URL
- 视频描述
- 音乐名称
- 发布日期
- 标签
- 观看次数
- 点赞数
- 评论数
- 分享数
- 书签数
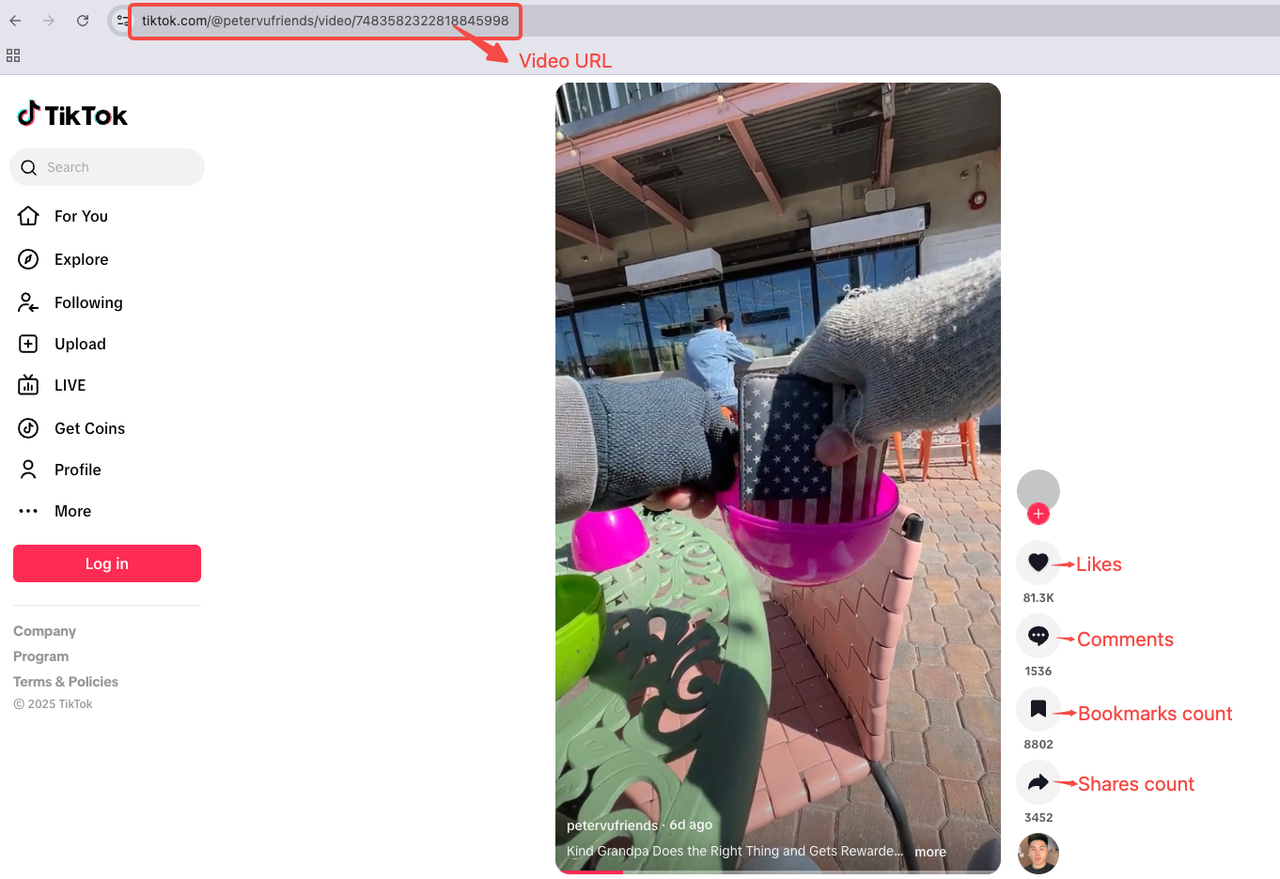
视频页面分析
为了使数据抓取更直观,我们将分析以下视频作为参考:https://www.tiktok.com/@petervufriends/video/7476546872253893934。
我们坚决保护网站的隐私。本博客中的所有数据都是公开的,仅用于演示抓取过程。我们不保存任何信息和数据。
如何找到我们需要的数据?
让我们深入研究 HTML 结构!以下是我们需要从此视频中提取的内容:
观看次数
观看次数通常在视频页面上醒目显示。只需打开开发者工具并找到相关的标签:
Python
<strong data-e2e="video-views" class="video-count css-dirst9-StrongVideoCount e148ts222">281.4K</strong>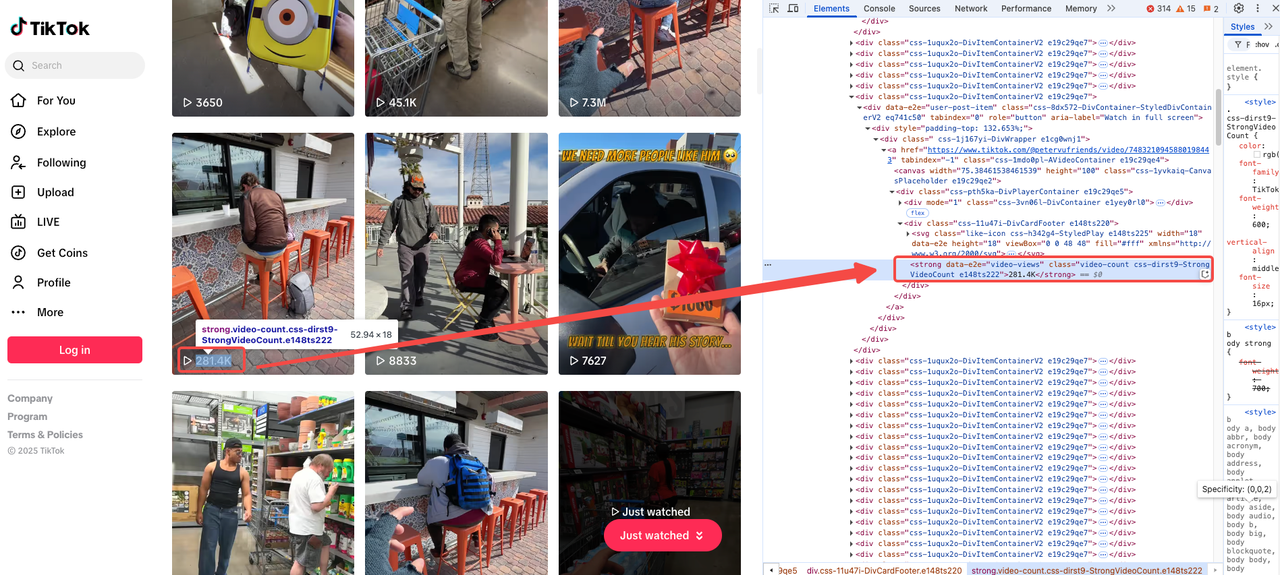
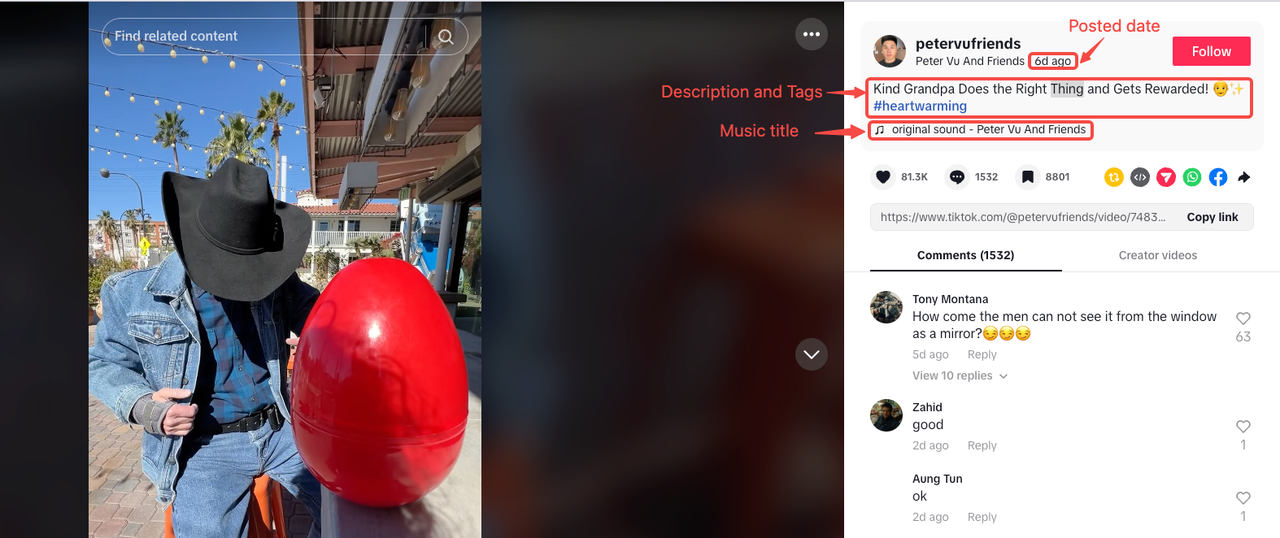
视频描述和标签
正如我们最初观察到的那样,视频描述和标签通常出现在同一部分。但是,有些视频可能没有描述或标签。
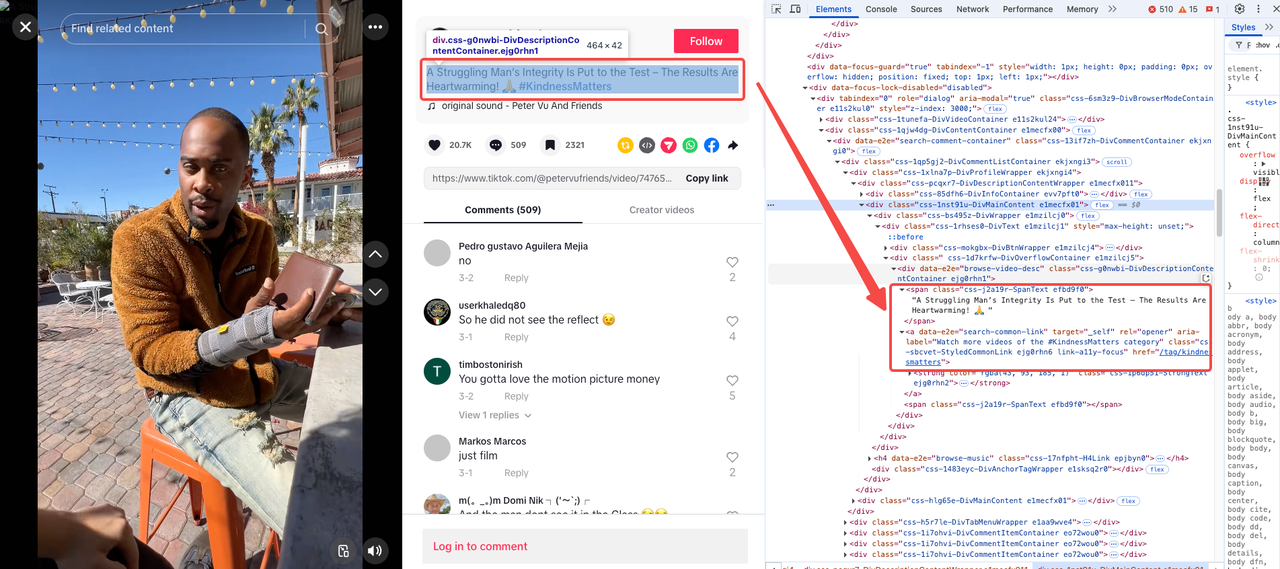
- 视频描述位于具有唯一类的
<span>内:css-j2a19r-SpanText。 - 视频标签是分开的,但共享相同的属性:
data-e2e="search-common-link"。
音乐标题
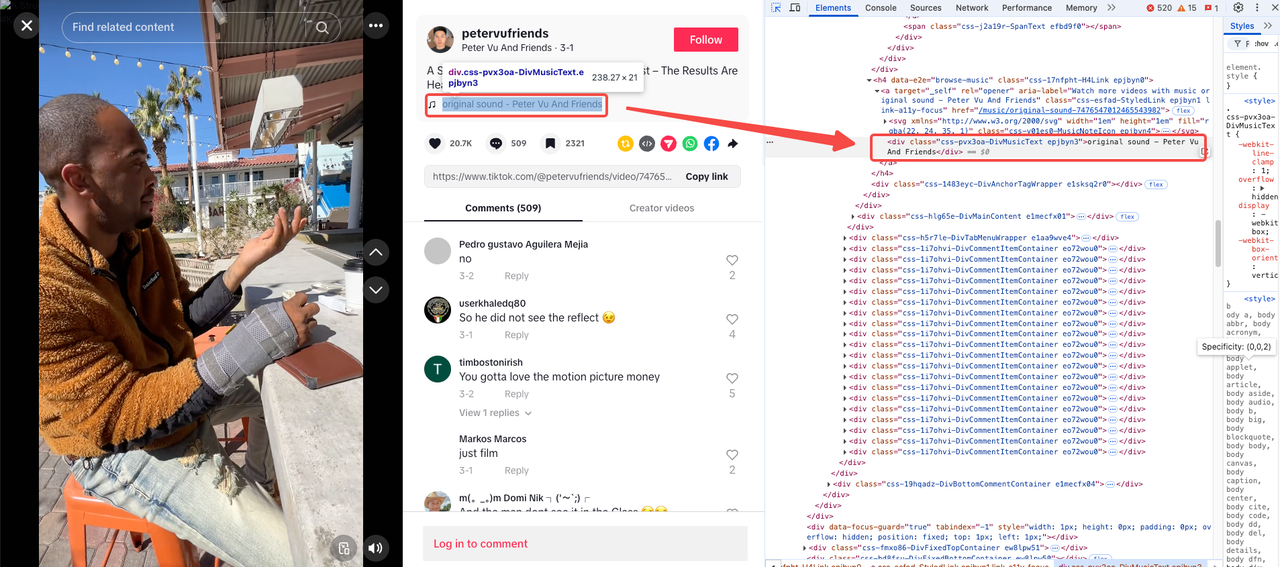
上传日期
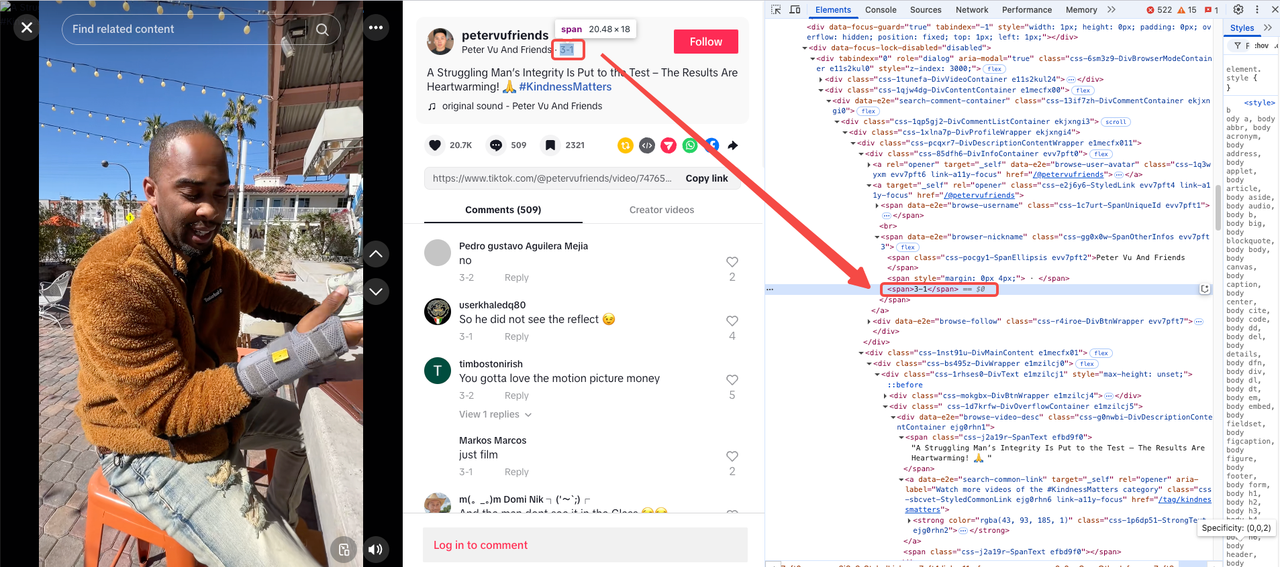
日期作为最后一个 <span> 分离在包含属性的父元素内:data-e2e="browser-nickname"。
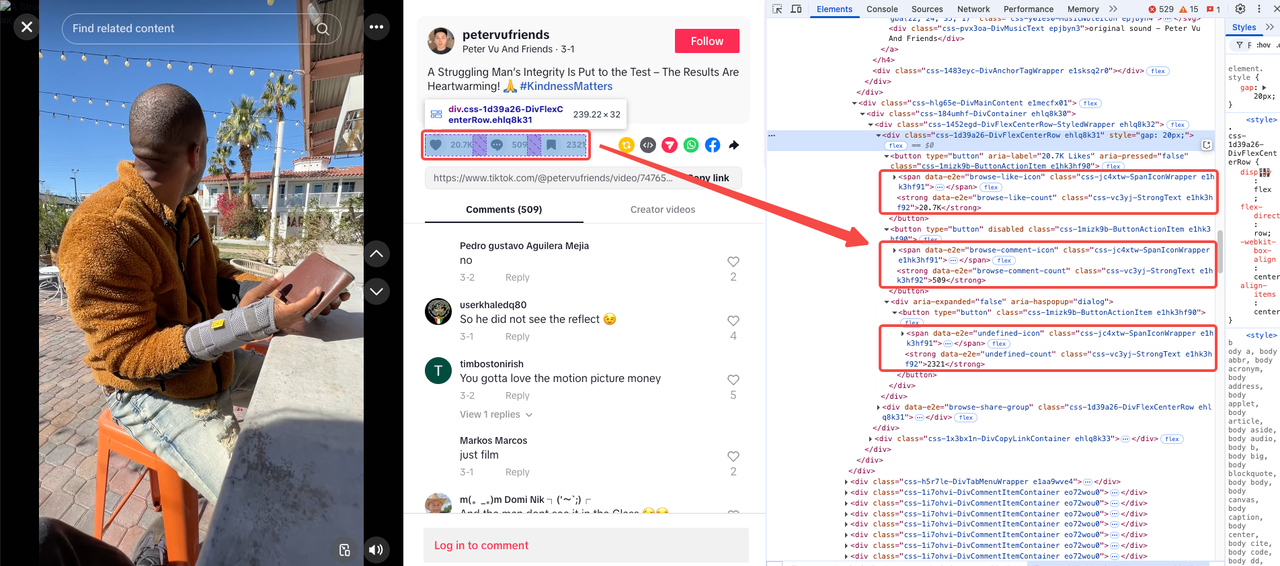
点赞、评论和书签计数
这些指标通常一起出现,你可以在同一个集合下找到它们:
为了简化你的抓取过程,以下是基本选择器的摘要:
- 视频 URL:
<meta property="og:url"> - 视频描述:
['span.css-j2a19r-SpanText'] - 音乐标题:
['.css-pvx3oa-DivMusicText'] - 上传日期:
['span[data-e2e="browser-nickname"] span:last-child'] - 标签:
[data-e2e="search-common-link"] - 观看次数:
[data-e2e="video-views"] - 点赞数:
[data-e2e="like-count"] - 评论数:
[data-e2e="comment-count"] - 分享数:
[data-e2e="share-count"] - 书签数:
[data-e2e="undefined-count"]
恭喜!你现在完全了解了如何找到必要的数据。接下来,让我们正式构建抓取工具!
完整的抓取代码
跳过不必要的解释——以下是可立即实施的现成抓取代码:
Python
from playwright.async_api import async_playwright
import asyncio, random, json, logging, time, os, yt_dlp
from urllib.parse import urlparse
# Configure logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('tiktok_scraper.log'),
logging.StreamHandler()
]
)
class TikTokScraper:
def __init__(self):
self.DOWNLOAD_VIDEO = True
self.SAVE_DIR = "downloaded_videos"
self.USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
self.VIEWPORT = {'width': 1280, 'height': 720}
self.TIMEOUT = 300 # 5 minute timeout
async def random_sleep(self, min_seconds=1, max_seconds=3):
"""Random Delay"""
delay = random.uniform(min_seconds, max_seconds)
logging.info(f"Sleeping for {delay:.2f} seconds...")
await asyncio.sleep(delay)
async def handle_captcha(self, page):
"""Handling verification codes"""
try:
captcha_dialog = page.locator('div[role="dialog"]')
if await captcha_dialog.count() > 0 and await captcha_dialog.is_visible():
logging.warning("CAPTCHA detected. Please solve it manually.")
await page.wait_for_selector('div[role="dialog"]', state='detached', timeout=self.TIMEOUT*1000)
logging.info("CAPTCHA solved. Resuming...")
await self.random_sleep(0.5, 1)
except Exception as e:
logging.error(f"Error handling CAPTCHA: {str(e)}")
async def extract_video_info(self, page, video_url):
"""Extract video details"""
logging.info(f"Extracting info from: {video_url}")
try:
await page.goto(video_url, wait_until="networkidle")
await self.random_sleep(2, 4)
await self.handle_captcha(page)
# Waiting for key elements to load
await page.wait_for_selector('[data-e2e="like-count"]', timeout=10000)
video_info = await page.evaluate("""() => {
const getTextContent = (selectors) => {
for (let selector of selectors) {
const element = document.querySelector(selector);
if (element && element.textContent.trim()) {
return element.textContent.trim();
}
}
return 'N/A';
};
const getTags = () => {
const tagElements = document.querySelectorAll('a[data-e2e="search-common-link"]');
return Array.from(tagElements).map(el => el.textContent.trim());
};
return {
likes: getTextContent(['[data-e2e="like-count"]', '[data-e2e="browse-like-count"]']),
comments: getTextContent(['[data-e2e="comment-count"]', '[data-e2e="browse-comment-count"]']),
shares: getTextContent(['[data-e2e="share-count"]']),
bookmarks: getTextContent(['[data-e2e="undefined-count"]']),
views: getTextContent(['[data-e2e="video-views"]']),
description: getTextContent(['span.css-j2a19r-SpanText']),
musicTitle: getTextContent(['.css-pvx3oa-DivMusicText']),
date: getTextContent(['span[data-e2e="browser-nickname"] span:last-child']),
author: getTextContent(['a[data-e2e="browser-username"]']),
tags: getTags(),
videoUrl: window.location.href
};
}""")
logging.info(f"Successfully extracted info for: {video_url}")
return video_info
except Exception as e:
logging.error(f"Failed to extract info from {video_url}: {str(e)}")
return None
def download_video(self, video_url):
"""Download Video"""
if not os.path.exists(self.SAVE_DIR):
os.makedirs(self.SAVE_DIR)
ydl_opts = {
'outtmpl': os.path.join(self.SAVE_DIR, '%(id)s.%(ext)s'),
'format': 'best',
'quiet': False,
'no_warnings': False,
'ignoreerrors': True
}
try:
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(video_url, download=True)
filename = ydl.prepare_filename(info)
logging.info(f"Video successfully downloaded: {filename}")
return filename
except Exception as e:
logging.error(f"Error downloading video: {str(e)}")
return None
async def scrape_single_video(self, video_url):
"""Scrape the single short"""
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context(
viewport=self.VIEWPORT,
user_agent=self.USER_AGENT,
)
page = await context.new_page()
result = {}
try:
# Extract shorts information
video_info = await self.extract_video_info(page, video_url)
if not video_info:
raise Exception("Failed to extract video info")
result.update(video_info)
# Download TikTok shorts
if self.DOWNLOAD_VIDEO:
filename = self.download_video(video_url)
if filename:
result['local_path'] = filename
except Exception as e:
logging.error(f"Error scraping video: {str(e)}")
finally:
await browser.close()
return result
def save_results(self, data, filename="tiktok_video_data.json"):
"""Save the results to a JSON file"""
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, indent=2, ensure_ascii=False)
logging.info(f"Results saved to {filename}")
async def main():
# Initialize the crawler
scraper = TikTokScraper()
# Target TikTok short's URL
video_url = "https://www.tiktok.com/@petervufriends/video/7476546872253893934" # Just as an reference
# scrape the short
video_data = await scraper.scrape_single_video(video_url)
# save the scraping result
if video_data:
scraper.save_results(video_data)
logging.info("\nScraping completed. Results:")
for key, value in video_data.items():
logging.info(f"{key}: {value}")
else:
logging.error("Failed to scrape video data")
if __name__ == "__main__":
asyncio.run(main())抓取结果
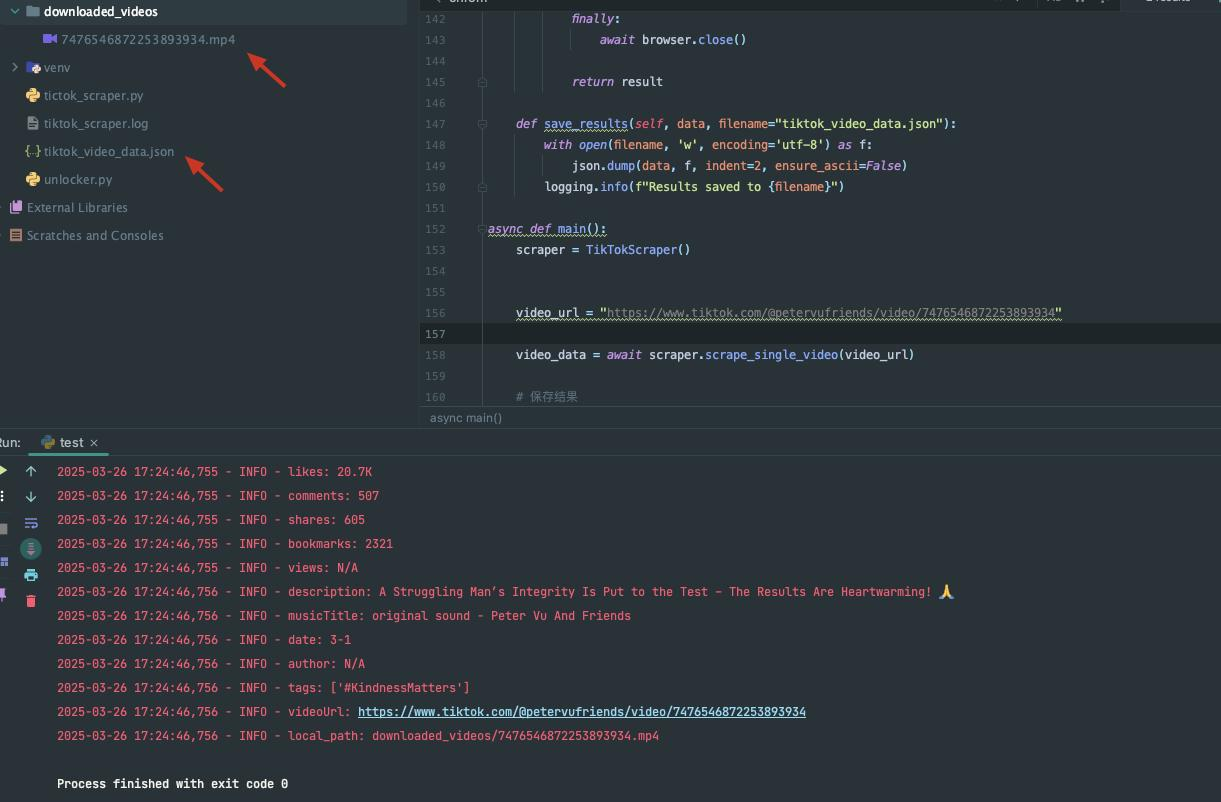
显然,我们需要复杂的编程和措施: 设置延迟、绕过 CAPTCHA 等来实现数据抓取。那么如何快速获取 TikTok 数据呢?强大的第三方抓取 API 是你的最佳选择!
抓取 API:轻松收集 TikTok 数据
为什么使用 API 来检索 TikTok 产品详细信息?
1. 提高效率
手动搜索产品数据速度慢且容易出错。API 允许自动检索 TikTok 产品信息,确保快速一致的数据收集。
2. 准确的实时数据
Scrapeless API 直接从 TikTok 产品页面提取数据,确保检索到的信息是最新的和准确的。这可以防止因延迟手动输入或过时来源造成的错误。
3. 适用于各种业务场景
- 价格监控:比较竞争对手的价格并调整定价策略。
- 库存跟踪:检查产品可用性以优化供应链管理。
- 评论分析:分析客户反馈以改进产品和服务。
- 市场调查:识别畅销产品并做出明智的业务决策。
TikTok 抓取工具有什么作用?
这个 TikTok 数据抓取工具是一个强大的非官方 TikTok API,它为你提供大规模的 TikTok 数据,用于你自己的数据项目、业务报告以及作为新应用程序的基础。使用这个最好的 TikTok 抓取工具,你可以获得:
- 来自所选主题标签的所有结果,包括详细信息:热门视频、时间戳、观看次数、分享次数、评论和视频数量等。
- 来自所选用户资料的所有帖子,包括详细信息:姓名、昵称、ID、个人简介、关注者/关注对象、播放次数、分享次数和评论等。
- 带有特定视频 URL 的单个视频帖子。
- 视频和音乐相关数据。
使用 API 抓取 TikTok 数据
步骤 1. 创建你的 API 令牌
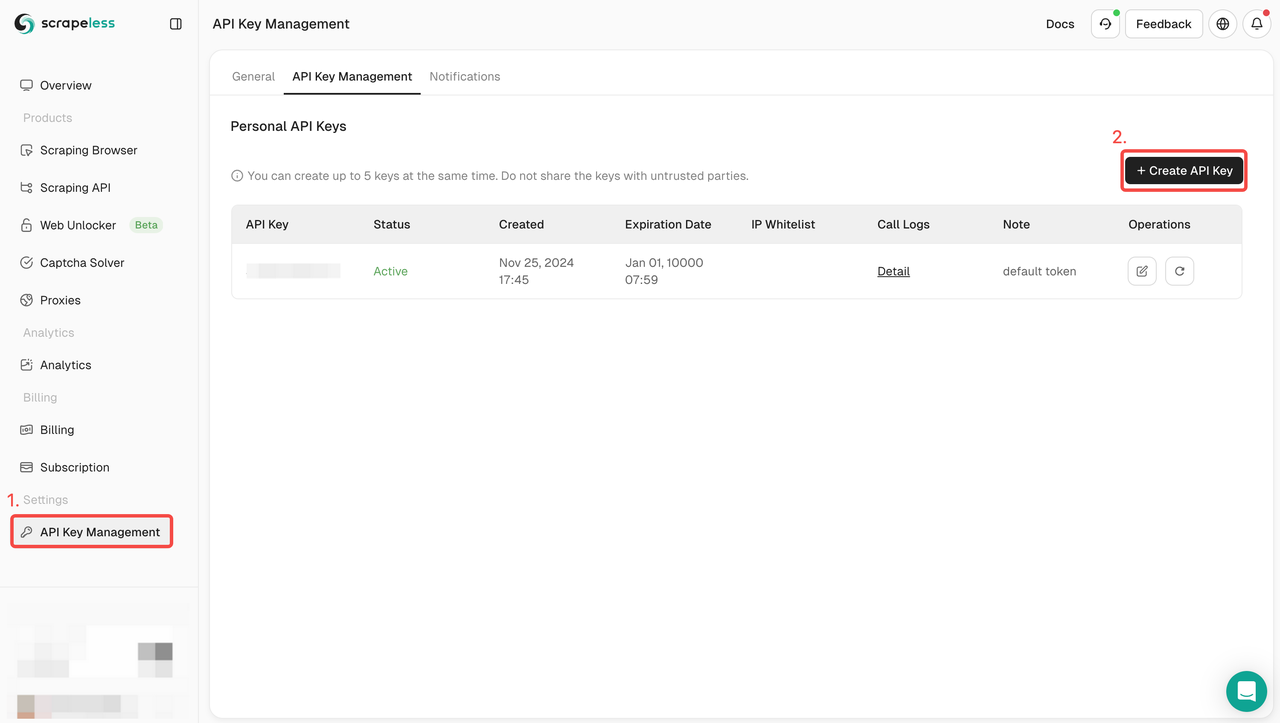
要开始,你需要从 Scrapeless 仪表板获取你的 API 密钥:
- 登录到Scrapeless 仪表板。
- 导航到API 密钥管理。
- 点击创建以生成你唯一的 API 密钥。
- 创建后,只需点击 API 密钥即可复制它。
步骤 2. 输入 TikTok API
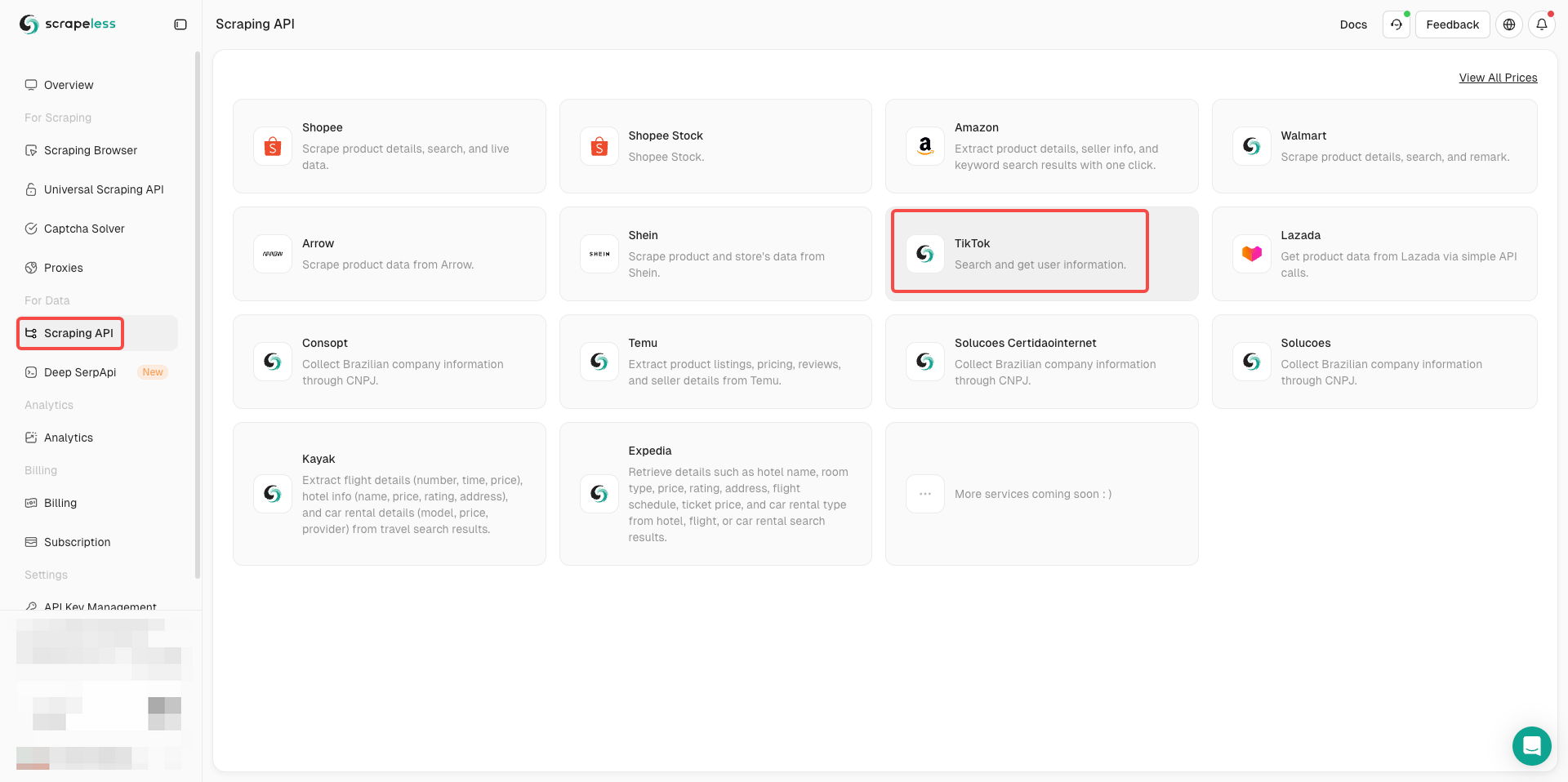
- 点击“用于数据”下的“抓取 API”
- 找到 TikTok 并输入
步骤 3. 请求参数配置
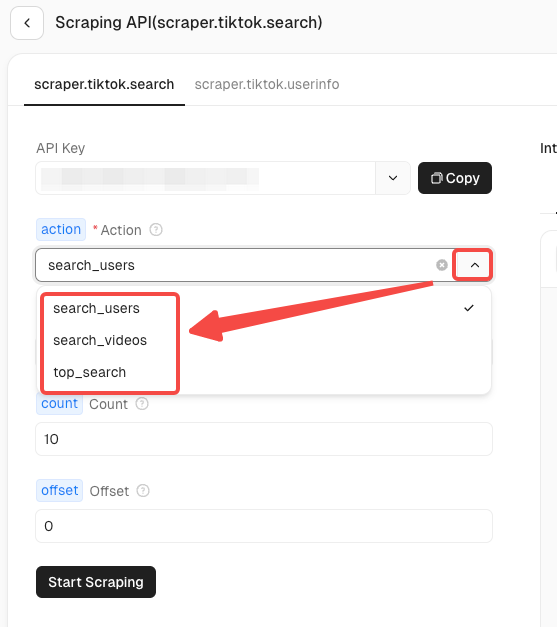
TikTok 执行器目前有两种抓取场景:
- TikTok 搜索信息: 抓取特定关键词的视频搜索结果。
- TikTok 用户信息: 抓取指定用户的个人资料信息。
每个场景都会有不同的操作请求。你可以点击折叠箭头来查找你需要准确抓取的数据信息。以 TikTok 搜索信息为例:
准备好了吗?了解基本信息后,我们就可以正式开始抓取数据了!
- 现在你只需要根据你的需要完成执行器左侧的参数配置
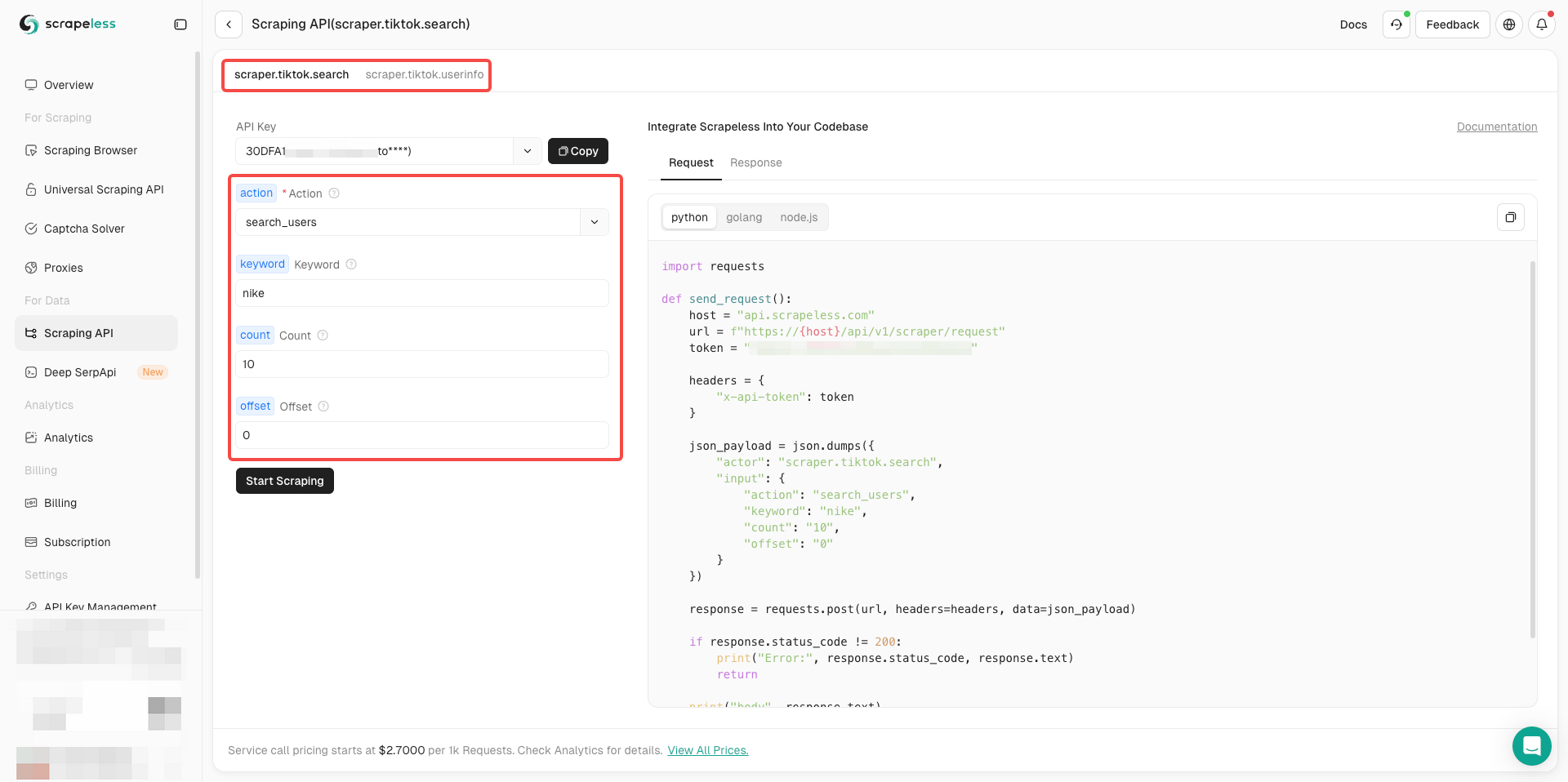
- 确认一切正确后,只需点击“开始抓取”即可轻松获得抓取结果。
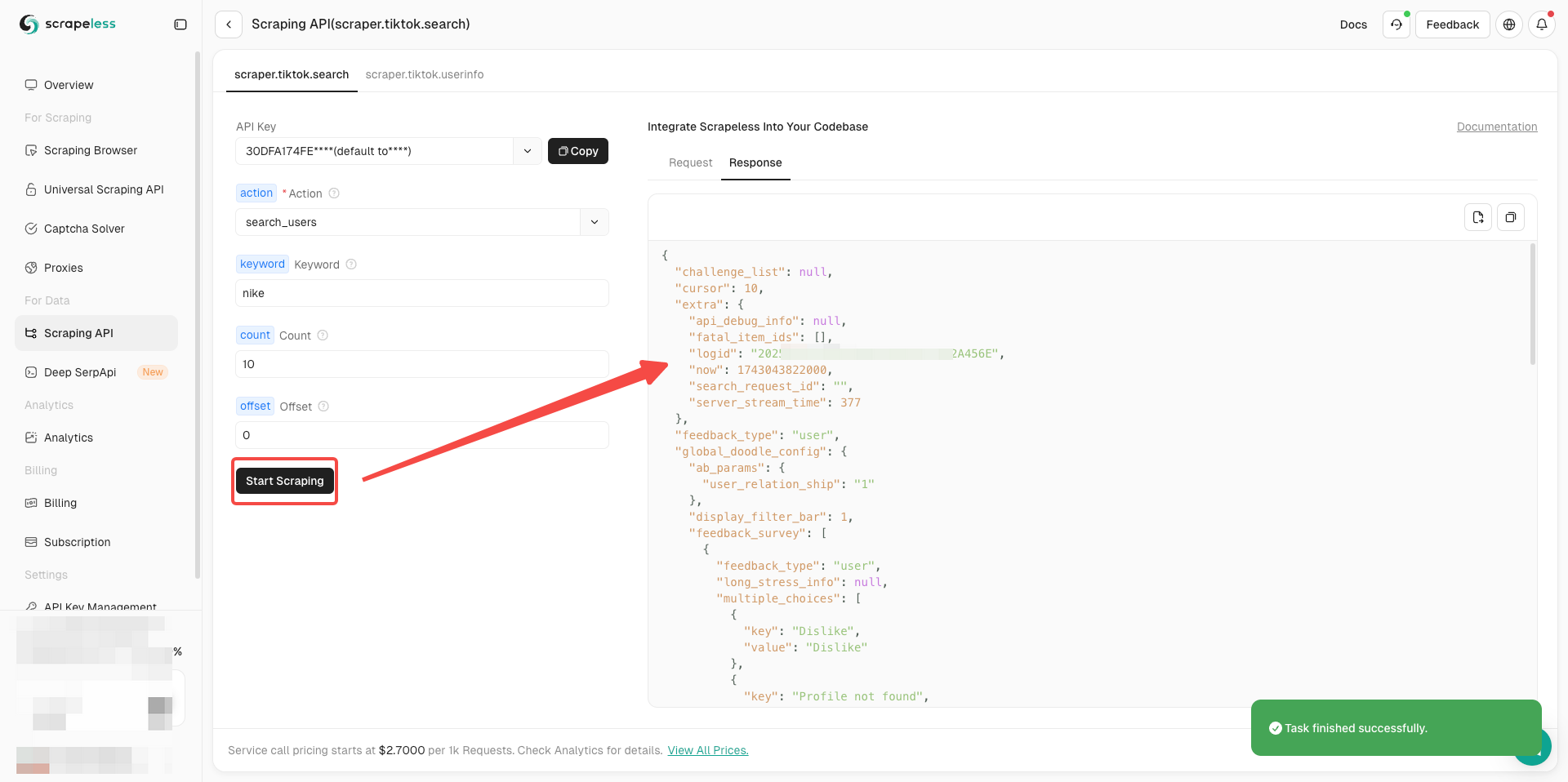
立即获取 TikTok 视频数据!
从现在开始,你应该拥有一个可以从 TikTok 提取数据的有效抓取工具。这是一个很好的开始,但你绝对可以走得更远。
无论你是分析 TikTok 趋势、进行研究还是满足你的数据好奇心,你现在都有强大的工具来探索 TikTok 数据仓库,而不会遇到很多麻烦。
Scrapeless 抓取 API 可让你免于处理复杂的代码。只需配置几个参数即可立即获取最新数据。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


