
如何抓取谷歌学术公开搜索结果
Advanced Data Extraction Specialist
Google Scholar是全球学术研究人员查找和获取文献的重要工具,涵盖各个领域的论文、专著和会议论文。但是,由于其严格的反爬虫机制,直接爬取Google Scholar数据并不容易,尤其对于需要大规模数据采集的用户来说。
本文将介绍两种爬取Google Scholar数据的方法:手动爬取(Scrapy/Selenium)和Scrapeless API。手动爬取适用于小规模数据采集,但可能会遇到IP限制和验证码问题。Scrapeless API提供了一种更稳定、更高效的解决方案,尤其适用于大规模数据爬取,无需维护额外的反检测策略。
通过比较两种方法的优缺点,本文将帮助您选择最合适的方案,实现高效的数据采集。
为什么爬取Google Scholar?
Google Scholar提供了宝贵的学术资源,包括研究论文、引用、作者简介等。通过爬取Google Scholar,您可以:
- 收集特定主题的研究论文。
- 提取引用次数,进行学术影响力分析。
- 获取作者简介及其已发表作品。
- 自动化文献综述以用于研究目的。
爬取Google Scholar的挑战
爬取Google Scholar会面临以下挑战:
- CAPTCHA:频繁请求可能会触发Google的反机器人保护。
- IP封锁:Google可能会封锁重复发出自动化请求的IP。
- 动态内容:某些结果可能通过JavaScript动态加载。
为了克服这些挑战,我们建议使用专用的API,例如Scrapeless API。
方法一:如何爬取Google Scholar - 传统网页抓取(不推荐)
使用Python(例如,BeautifulSoup、Selenium)手动爬取Google Scholar网页由于Google的限制而非常困难。使用requests的示例:
import requests
from bs4 import BeautifulSoup
url = "https://scholar.google.com/scholar?q=machine+learning"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
results = soup.find_all("div", class_="gs_r")
for result in results:
title = result.find("h3").text if result.find("h3") else "No Title"
print(title)📌 缺点:
- 很容易触发Google的反爬虫机制,导致IP被封或遇到CAPTCHA。
- 数据结构复杂,需要解析HTML并处理动态加载的内容。
- 不适合大规模数据采集,稳定性低。
这种方法由于Google的反机器人措施而不可靠。相反,使用Scrapeless API之类的API是最佳替代方案。
方法二:使用Scrapeless抓取API爬取Google Scholar(推荐)
Scrapeless的Google Scholar API是为学术研究和数据分析而设计的工具。它可以自动爬取Google Scholar搜索结果以获取关键信息,例如论文标题、作者、发表日期和引用次数。它解析Google Scholar的SERP(搜索引擎结果页面)以提供结构化的JSON数据,避免IP封锁和验证码验证,并使⽤户无需处理复杂的爬虫开发。
此外,Scrapeless还支持实时搜索、批量查询和自定义参数过滤,适合研究人员、开发者和数据分析师。
Scrapeless的Google Scholar API的关键特性
- **自动解析:**无需手动编写爬虫,直接获取结构化的JSON数据。
- **实时数据:**支持实时查询,确保获取的Google Scholar结果是最新的。
- **反爬虫机制:**自动绕过Google Scholar的CAPTCHA和IP封锁,无需代理或额外配置。
- **丰富的字段数据:**提供详细的数据,例如论文标题、作者、发表日期、引用次数、期刊信息、相关论文等。
- **支持批量查询:**可以一次获取多个关键词的搜索结果,提高爬取效率。
- **自定义搜索参数:**支持按时间、语言、文档类型等过滤数据,精确定位目标信息。
- 稳定的API访问:基于云架构,确保高并发访问下的稳定性和可靠性。
免费注册并开始抓取Google搜索结果!
现在登录Scrapeless,即可获得免费试用机会,轻松从Google搜索引擎抓取数据,助力您的项目和分析。强大的API功能能够帮助您获取准确的搜索信息,提升效率。快来体验吧!
📌 Scrapeless API关键特性:
| API | 功能 | 使用案例 |
|---|---|---|
| 作者API | 获取学者信息(H指数、论文数量等) | 学者影响力分析 |
| 引用API | 获取论文引用格式(BibTeX、APA等) | 论文管理 |
| 自然搜索结果API | 获取Google Scholar搜索结果 | 学术研究 |
| 简介API | 获取学者个人资料数据 | 合作研究分析 |
如何使用Scrapeless Google Scholar API
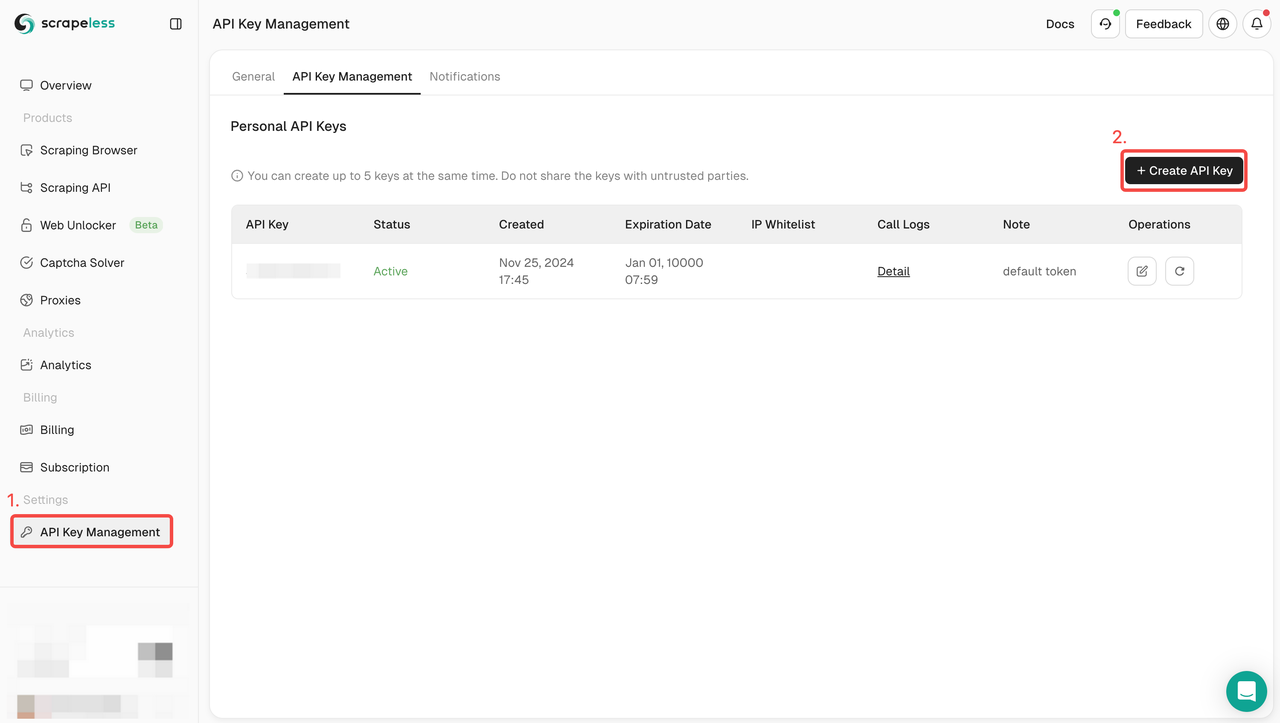
步骤1. 获取您的API密钥
要开始使用,您需要从Scrapeless仪表盘获取您的API密钥:
- 登录Scrapeless仪表盘。
- 导航到API密钥管理。
- 点击创建以生成您的唯一API密钥。
- 创建后,只需点击API密钥即可复制它。
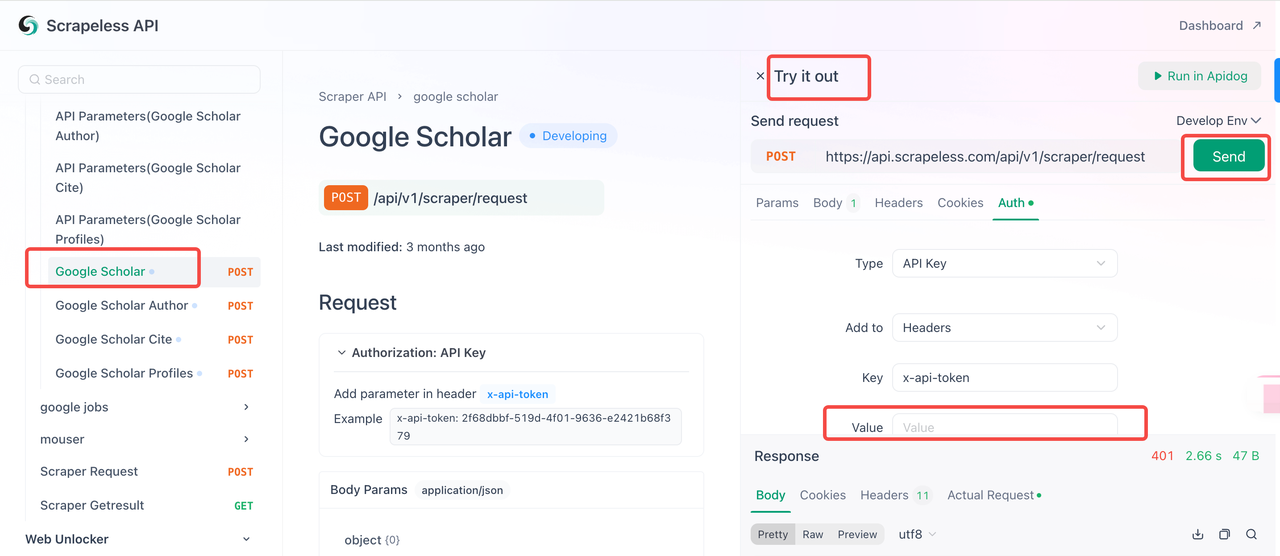
步骤2:在代码中使用您的API密钥
您现在可以使用您的API密钥将Scrapeless集成到您的项目中。请按照以下步骤测试和实现API:
- 访问API文档。
- 点击“试用”以获取所需的端点。
- 在“Auth”字段中输入您的API密钥。
- 点击“发送”以获取抓取响应。
以下是一个您可以直接集成到您的Google Scholar爬虫中的示例代码片段:
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.scholar",
"input": {
"engine": "google_scholar",
"q": "biology"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))此外,Scrapeless还支持许多抓取API解决方案,例如:亚马逊抓取API、Shopee抓取API、谷歌航班抓取API、谷歌地图抓取API等。
Scrapeless Google Scholar API
Scrapeless的Google Scholar API是一个强大的工具,可以通过API请求抓取Google Scholar上的学术论文、期刊、书籍和其他资源。它允许用户通过指定的关键词进行搜索,并获取相关文档的详细信息,例如标题、出版信息、引用次数等。
Google Scholar API参数
| 参数 | 是否必填 | 描述 |
|---|---|---|
| engine | 是 | 设置为google_scholar以使用此API。 |
| q | 是 | 搜索查询(例如,机器学习)。 |
| cites | 否 | 唯一ID,用于查找引用文章。 |
| as_ylo | 否 | 过滤特定年份的结果。 |
| as_yhi | 否 | 过滤截止到特定年份的结果。 |
| hl | 否 | 语言设置(默认为en)。 |
| num | 否 | 结果数量(1-20,默认为10)。 |
示例:抓取Google Scholar搜索结果
请求代码:
import requests
import json
# 设置API请求URL
url = "https://api.scrapeless.com/api/v1/scraper/request"
# 定义请求的有效负载
payload = json.dumps({
"actor": "scraper.google.scholar",
"input": {
"engine": "google_scholar",
"q": "machine learning", # 搜索查询
"cites": "KNJ0p4CbwgoJ", # 可选:查找引用此论文的文章
"as_ylo": 2015, # 可选:过滤自此年份的结果(起始年份)
"as_yhi": 2023, # 可选:过滤截止到此年份的结果(结束年份)
"hl": "en", # 可选:语言设置(默认为英语)
"num": 10 # 可选:结果数量(默认为10)
}
})
# 设置请求头
headers = {
'Content-Type': 'application/json'
}
# 发送请求
response = requests.request("POST", url, headers=headers, data=payload)
# 打印响应
print(response.text)参数说明:
- engine: 设置为google_scholar,表示使用Google Scholar进行搜索。
- q: 搜索查询(例如,机器学习)。
- cites: 可选。提供论文的ID(如KNJ0p4CbwgoJ)以查找引用它的文章。
- as_ylo: 可选。过滤结果的起始年份(例如,2015)。
- as_yhi: 可选。过滤结果的结束年份(例如,2023)。
- hl: 可选。语言设置,默认为en表示英语。可以设置为其他语言(例如,zh表示中文)。
- num: 可选。要返回的结果数量,介于1和20之间。默认为10。
示例响应:
{
"search_information": {
"total_results": 5000000,
"time_taken_displayed": 0.05,
"query_displayed": "machine learning"
},
"organic_result": [
{
"position": 1,
"title": "A survey on machine learning methods",
"result_id": "KNJ0p4CbwgoJ",
"link": "https://example.com/article1",
"snippet": "This article provides a comprehensive survey of machine learning methods, including supervised and unsupervised learning.",
"publication_info": {
"summary": "Author1, Author2 - Journal of Machine Learning, 2020"
}
},
{
"position": 2,
"title": "Deep learning in artificial intelligence",
"result_id": "KNJ0p4CbwgoK",
"link": "https://example.com/article2",
"snippet": "This paper discusses the applications of deep learning in various fields, including computer vision and natural language processing.",
"publication_info": {
"summary": "Author3, Author4 - AI Journal, 2021"
}
}
]
}响应结构:
- search_information: 包含有关搜索查询的详细信息:
- total_results: 结果总数。
- time_taken_displayed: 显示结果所花费的时间。
- query_displayed: 输入的搜索查询。
- organic_result: 搜索结果列表,每个结果包含:
- position: 结果的排名(例如,第1名,第2名)。
- title: 论文的标题。
- result_id: 论文的唯一ID。
- link: 论文的URL。
- snippet: 论文的简短摘要或摘录。
- publication_info: 出版物详细信息。
通过调整这些参数,您可以微调搜索以从Google Scholar获得最相关的结果,例如按年份、语言或结果数量限制结果。
想开始抓取Google Scholar结果?点击此处查看我们的产品详细信息,立即登录开始使用Scrapeless Google Scholar API!
Scrapeless Google Scholar 作者API
Scrapeless Google Scholar 作者API是一个强大的工具,用于获取Google Scholar上的学术作者信息。它可以提供作者的基本信息、研究领域、论文列表和引用数据。此API特别适合学术研究人员和开发人员提取学术资料、进行数据分析或集成到其他应用程序中。
Google Scholar 作者API参数
| 参数 | 是否必填 | 描述 |
|---|---|---|
| engine | 是 | 设置为google_scholar_author。 |
| view_op | 否 | 查看引用或合著者。 |
| sort | 否 | 按标题或发表日期排序。 |
| start | 否 | 分页的偏移量。 |
| num | 否 | 结果数量(最大:100)。 |
| "view_op false" | 否 | 它有两个选项:view_citation - 选择查看引用。需要citation_id。list_colleagues - 选择查看所有合著者。 |
| citation_id | 否 | 当选择view_op=view_citation时,这是一个必需的参数。您可以在我们的结构化JSON响应中访问ID。 |
示例:获取作者的出版物
这是一个用Python编写的代码示例,展示了如何使用Scrapeless Google Scholar作者API查询有关学术作者的信息:
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
# 定义请求有效负载,指定爬虫引擎和作者ID
payload = json.dumps({
"actor": "scraper.google.scholar",
"input": {
"engine": "google_scholar_author",
"author_id": "LSsXyncAAAAJ" # 示例作者ID
}
})
# 设置请求头
headers = {
'Content-Type': 'application/json'
}
# 发出POST请求
conn.request("POST", "/api/v1/scraper/request", payload, headers)
# 获取响应结果
res = conn.getresponse()
# 读取并输出数据
data = res.read()
print(data.decode("utf-8"))API请求返回的结果是一个JSON格式的响应,包含有关学术作者的详细信息,例如姓名、学术领域、机构等。返回的数据还包括作者的论文和引文列表。以下是一个简化的示例,显示API返回的一些结果:
{
"name": "John Doe",
"institution": "Harvard University",
"research_areas": [
{
"title": "Epigenetics",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:epigenetics"
},
{
"title": "Gene Regulation",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:gene_regulation"
},
{
"title": "Genomics",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:genomics"
},
{
"title": "Transcription Factors",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:transcription_factors"
}
...响应数据包含详细的作者信息和研究成果。具体的字段结果包括:
- research_areas:列出作者的研究领域,每个领域都有一个相应的链接指向Google Scholar上的搜索结果。
- thumbnail:作者头像图片的URL。
- articles:包含作者的主要学术文章。每篇文章的信息包括标题、链接、作者、发表期刊、引用次数等。
例如,一篇文章的详细信息如下:
- title:文章标题
- link:文章链接,指向Google Scholar上的详细引用页面
- citation_id:文章在Google Scholar中的唯一引用ID
- authors:所有参与作者的列表
- publication:发表文章的期刊及其卷号和期号
- cited_by:文章被引用的次数,并提供指向引用页面的链接
这些信息对于学术研究人员和开发者分析作者的学术贡献非常有帮助。
Scrapeless Google Scholar 引用API
Scrapeless的Google Scholar引用API是一个强大的工具,允许用户直接从Google Scholar提取学术文章的引用信息。它可以检索多种格式的格式化引用,包括MLA、APA、Chicago、Harvard和Vancouver,为研究人员、学生和开发人员提供便利。
此外,Scrapeless的Google Scholar引用API还提供不同引用管理工具(例如BibTeX、EndNote、RefMan和RefWorks)的导出链接,实现与参考文献工作流程的无缝集成。凭借实时数据检索和结构化JSON输出,Scrapeless的Google Scholar引用API简化了引用过程,提高了学术研究效率。
Google Scholar 引用API参数
| 参数 | 是否必填 | 描述 |
|---|---|---|
| engine | 是 | 设置为google_scholar_cite。 |
| q | 是 | 要检索引用的文章的ID。 |
| hl | 否 | 语言设置(默认为en)。 |
示例:提取引用详细信息
这是一个Python代码示例,演示了如何向Scrapeless Google Scholar引用API发出请求。
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.scholar",
"input": {
"engine": "google_scholar_cite",
"q": "s1QWFy06YAYJ"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))示例结果代码
API返回一个JSON对象,其中包含多种格式的引用详细信息:
{
"citations": [
{
"title": "MLA",
"snippet": "Masters, Paul S. \"The molecular biology of coronaviruses.\" Advances in virus research 66 (2006): 193-292."
},
{
"title": "APA",
"snippet": "Masters, P. S. (2006). The molecular biology of coronaviruses. Advances in virus research, 66, 193-292."
},
{
"title": "Chicago",
"snippet": "Masters, Paul S. \"The molecular biology of coronaviruses.\" Advances in virus research 66 (2006): 193-292."
},
{
"title": "Harvard",
"snippet": "Masters, P.S., 2006. The molecular biology of coronaviruses. Advances in virus research, 66, pp.193-292."
},
{
"title": "Vancouver",
...
]
}Scrapeless Google Scholar 引用API返回一个JSON结构,包含两个主要部分:citations(引用信息)和links(引用格式导出链接)。以下是每个字段的详细分析:
1. Citations
此字段是一个数组,其中每个元素表示不同的引用格式,包括MLA、APA、Chicago、Harvard和Vancouver。每种格式都包含以下字段:
| 字段名称 | 数据类型 | 描述 |
|---|---|---|
| title | 字符串 | 引用格式的名称,例如“MLA”或“APA” |
| snippet | 字符串 | 各自格式中的引用文本,包括文章标题、作者、期刊信息等。 |
示例数据:
"citations": [
{
"title": "MLA",
"snippet": "Masters, Paul S. \"The molecular biology of coronaviruses.\" Advances in virus research 66 (2006): 193-292."
},
{
"title": "APA",
"snippet": "Masters, P. S. (2006). The molecular biology of coronaviruses. Advances in virus research, 66, 193-292."
}
]数据分析:
- title: “MLA”表示此条目遵循MLA引用格式。
- snippet: 引用文本包括作者Paul S. Masters、文章标题The molecular biology of coronaviruses、期刊Advances in Virus Research、卷号66和页码193-292。
2. Links(引用导出链接)
此字段是一个数组,其中每个元素提供一个链接,用于以不同的格式导出引用,例如BibTeX、EndNote、RefMan和RefWorks。每种格式都包含以下字段:
| 字段名称 | 数据类型 | 描述 |
|---|---|---|
| name | 字符串 | 引用格式的名称,例如“BibTeX”或“EndNote” |
| link | 字符串 | 允许用户直接下载指定格式引用的URL |
示例数据:
"links": [
{
"name": "BibTeX",
"link": "https://scholar.googleusercontent.com/scholar.bib?q=info:s1QWFy06YAYJ..."
},
{
"name": "EndNote",
"link": "https://scholar.googleusercontent.com/scholar.enw?q=info:s1QWFy06YAYJ..."
}
]数据分析:
- name: “BibTeX”表示此条目是BibTeX引用导出链接。
- link: “https://scholar.googleusercontent.com/scholar.bib?q=info:s1QWFy06YAYJ...”是一个直接访问BibTeX引用的URL,可以在LaTeX或其他参考文献管理工具中使用。
Scrapeless Google Scholar 简介API
Scrapeless Google Scholar 简介API允许用户根据作者姓名搜索Google Scholar简介并获取详细信息,包括引用、兴趣、关联机构等。以下是有关如何使用API、所涉及的参数以及如何解释结果的概述。
Google Scholar 简介API参数
| 参数 | 是否必填 | 描述 |
|---|---|---|
| engine | 是 | 设置为google_scholar_profiles。 |
| mauthors | 是 | 用于简介搜索的作者姓名。 |
| hl | 否 | 语言设置(默认为en)。 |
| after_author | 否 | 分页的令牌。 |
示例:搜索作者简介
以下Python代码演示了如何使用Scrapeless服务发出API请求:
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.scholar",
"input": {
"engine": "google_scholar_author",
"author_id": "LSsXyncAAAAJ"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))API返回一个JSON对象,其中包含有关搜索结果的信息。这是部分示例:
{
"pagination": {
"next": "https://scholar.google.com//citations?view_op=search_authors&hl=en&mauthors=Mike&after_author=pnnfAUQM__8J&astart=10",
"next_page_token": "pnnfAUQM__8J"
},
"profiles": [
{
"name": "Mike Robb",
"link": "https://scholar.google.com//citations?hl=en&user=kq0NYnMAAAAJ",
"author_id": "kq0NYnMAAAAJ",
"affiliations": "帝国理工学院化学系",
"email": "已验证的帝国理工学院邮箱",
"cited_by": 230346,
"interests": [
{
"title": "计算化学",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:computational_chemistry"
},
{
"title": "理论化学",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:theoretical_chemistry"
},
{
"title": "圆锥交叉",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:conical_intersections"
},
{
"title": "非绝热动力学",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:non_adiabatic_dynamics"
}
],
"thumbnail": "https://scholar.google.com//citations?hl=en&user=kq0NYnMAAAAJ"
},
{
"name": "Mike A. Nalls",
"link": "https://scholar.google.com//citations?hl=en&user=ZjfgPLMAAAAJ",
"author_id": "ZjfgPLMAAAAJ",
"affiliations": "Data Tecnica International创始人/顾问 + NIH中心数据科学主管……",
"email": "已验证的nih.gov邮箱",
"cited_by": 175760,
"interests": [
{
"title": "统计遗传学",
"link": "https://scholar.google.com//citations?hl=en&view_op=search_authors&mauthors=label:statistical_genetics"
},
{
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


