
在Scrapeless上您可以获得哪些响应参数?
Senior Web Scraping Engineer
在现代网络数据爬虫场景中,仅仅获取HTML页面通常无法满足面对复杂反爬机制的商业需求。在Scrapeless,我们始终致力于从开发者的角度提升我们的产品能力。
今天,我们很高兴地宣布对Scrapeless核心服务之一——通用爬虫API进行重大更新。Web Unlocker现在支持多种响应格式!这一增强显著提升了API的灵活性,为企业用户和开发者提供了更适应和高效的数据爬虫体验。
为什么我们进行更新?
此前,通用爬虫API默认返回HTML页面内容,这对快速访问未加密页面或具有较弱反爬机制的网站效果良好。然而,随着用户对自动化的需求增长,我们观察到许多用户在获取HTML后仍需手动处理数据结构、清理内容和提取元素——增加了不必要的开发开销。我们能否简化这一过程,以一步交付预处理的内容?
现在你可以做到!
我们重新设计了响应逻辑。通过配置response_type参数,开发者可以灵活指定所需的数据格式。无论是原始HTML、纯文本,还是结构化元数据,只需简单的参数配置即可。
现在,你可以获取的响应格式:
目前支持的格式包括但不限于:
- JSON输出过滤:使用**
outputs参数过滤JSON格式数据。允许的过滤类型包括email、phone_numbers、headings及其他9种**,结果以结构化JSON格式返回。 - 多种返回格式:除了JSON过滤外,您还可以通过在请求中添加
response_type参数直接指定响应格式(例如,response_type=plaintext)。
目前支持的格式包括:
HTML:以HTML格式提取页面内容(适合静态页面)。Plaintext:将获取的内容返回为纯文本,去除HTML标签或Markdown格式——非常适合文本处理或分析。Markdown:以Markdown格式提取页面内容(最佳适用于基于静态Markdown的页面),使其更易阅读和处理。PNG/JPEG:通过设置response_type=png,捕获目标页面的屏幕截图,并以PNG或JPEG格式返回(可选全页面截图)。
注意:默认的
response_type为html。
示例
1. JSON返回值过滤:
您可以使用outputs参数过滤JSON格式的数据。设置此参数后,响应类型将固定为JSON。
该参数接受用逗号分隔的过滤名称列表,并以结构化的JSON格式返回数据。支持的过滤类型包括:phone_numbers、headings、images、audios、videos、links、menus、hashtags、emails、metadata、tables和favicon。
以下示例代码演示如何获取scrapeless网站首页的所有图像信息:
Javascript
JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://www.scrapeless.com",
js_render: true,
outputs: "images"
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('outputs.json', response.data.data, 'utf8');
}
})();Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.scrapeless.com",
"js_render": True,
"outputs": "images",
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('outputs.json', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])- 结果:
JSON
{
"images": [
"data:image/svg+xml;base64,PHN2ZyBzdHJva2U9IiNGRkZGRkYiIGZpbGw9IiNGRkZGRkYiIHN0cm9rZS13aWR0aD0iMCIgdmlld0JveD0iMCAwIDI0IDI0IiBoZWlnaHQ9IjIwMHB4IiB3aWR0aD0iMjAwcHgiIHhtbG5zPSJodHRwOi8vd3d3LnczLm9yZy8yMDAwL3N2ZyI+PHJlY3Qgd2lkdGg9IjIwIiBoZWlnaHQ9IjIwIiB4PSIyIiB5PSIyIiBmaWxsPSJub25lIiBzdHJva2Utd2lkdGg9IjIiIHJ4PSIyIj48L3JlY3Q+PC9zdmc+Cg==",
"https://www.scrapeless.com/_next/image?url=%2Fassets%2Fimages%2Fcode%2Fcode-l.jpg&w=3840&q=75",
plaintext
"https://www.scrapeless.com/_next/image?url=%2Fassets%2Fimages%2Fregulate-compliance.png&w=640&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fimages%2Fauthor-avatars%2Falex-johnson.png&w=48&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fdeep-serp-api-online%2Fd723e1e516e3dd956ba31c9671cde8ea.jpeg&w=3840&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fscrapeless-web-scraping-toolkit%2Fac20e5f6aaec5c78c5076cb254c2eb78.png&w=3840&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fimages%2Fauthor-avatars%2Femily-chen.png&w=48&q=75",
"https://www.scrapeless.com/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fgoogle-shopping-scrape%2F251f14aedd946d0918d29ef710a1b385.png&w=3840&q=75"
Plain Text
# Scrapeless API
## 文档
- 抓取浏览器 [CDP API](https://apidocs.scrapeless.com/doc-801748.md):
- 抓取 API > shopee [演员列表](https://apidocs.scrapeless.com/doc-754333.md):
- 抓取 API > amazon [API 参数](https://apidocs.scrapeless.com/doc-857373.md):
- 抓取 API > google 搜索 [API 参数](https://apidocs.scrapeless.com/doc-800321.md):
- 抓取 API > google 趋势 [API 参数](https://apidocs.scrapeless.com/doc-796980.md):
- 抓取 API > google 航班 [API 参数](https://apidocs.scrapeless.com/doc-796979.md):
- 抓取 API > google 航班图表 [API 参数](https://apidocs.scrapeless.com/doc-908741.md):
- 抓取 API > google 地图 [API 参数(谷歌地图)](https://apidocs.scrapeless.com/doc-834792.md):
- 抓取 API > google 地图 [API 参数(谷歌地图自动补全)](https://apidocs.scrapeless.com/doc-834799.md):
- 抓取 API > google 地图 [API 参数(谷歌地图贡献者评论)](https://apidocs.scrapeless.com/doc-834806.md):
- 抓取 API > google 地图 [API 参数(谷歌地图导航)](https://apidocs.scrapeless.com/doc-834821.md):
- 抓取 API > google 地图 [API 参数(谷歌地图评论)](https://apidocs.scrapeless.com/doc-834831.md):
- 抓取 API > google 学术 [API 参数(谷歌学术)](https://apidocs.scrapeless.com/doc-842638.md):
- 抓取 API > google 学术 [API 参数(谷歌学术作者)](https://apidocs.scrapeless.com/doc-842645.md):
- 抓取 API > google 学术 [API 参数(谷歌学术引用)](https://apidocs.scrapeless.com/doc-842647.md):
- 抓取 API > google 学术 [API 参数(谷歌学术个人资料)](https://apidocs.scrapeless.com/doc-842649.md):
- 抓取 API > google 职位 [API 参数](https://apidocs.scrapeless.com/doc-850038.md):
- 抓取 API > google 购物 [API 参数](https://apidocs.scrapeless.com/doc-853695.md):
- 抓取 API > google 酒店 [API 参数](https://apidocs.scrapeless.com/doc-865231.md):
- 抓取 API > google 酒店 [支持的谷歌度假租赁物业类型](https://apidocs.scrapeless.com/doc-890578.md):
- 抓取 API > google 酒店 [支持的谷歌酒店物业类型](https://apidocs.scrapeless.com/doc-890580.md):
- 抓取 API > google 酒店 [支持的谷歌度假租赁设施](https://apidocs.scrapeless.com/doc-890623.md):
- 抓取 API > google 酒店 [支持的谷歌酒店设施](https://apidocs.scrapeless.com/doc-890631.md):
- 抓取 API > google 新闻 [API 参数](https://apidocs.scrapeless.com/doc-866643.md):
- 抓取 API > google lens [API 参数](https://apidocs.scrapeless.com/doc-866644.md):
- 抓取 API > google finance [API 参数](https://apidocs.scrapeless.com/doc-873763.md):
- 抓取 API > google 产品 [API 参数](https://apidocs.scrapeless.com/doc-880407.md):
- 抓取 API [谷歌应用商店](https://apidocs.scrapeless.com/folder-3277506.md):
- 抓取 API > google 应用商店 [API 参数](https://apidocs.scrapeless.com/doc-882690.md):
- 抓取 API > google 应用商店 [支持的谷歌应用类别](https://apidocs.scrapeless.com/doc-882822.md):
- 抓取 API > google 广告 [API 参数](https://apidocs.scrapeless.com/doc-881439.md):
- 通用抓取 API [JS 渲染文档](https://apidocs.scrapeless.com/doc-801406.md):
## API 文档
- 用户 [获取用户信息](https://apidocs.scrapeless.com/api-11949851.md): 检索当前身份验证用户的基本信息,包括其账户余额和订阅计划详情。
- 抓取浏览器 [连接](https://apidocs.scrapeless.com/api-11949901.md):
- 抓取浏览器 [运行会话](https://apidocs.scrapeless.com/api-16890953.md): 获取所有正在运行的会话
- 抓取浏览器 [实时网址](https://apidocs.scrapeless.com/api-16891208.md): 通过会话任务 ID 获取正在运行的会话的实时网址
- 抓取 API > shopee [Shopee 产品](https://apidocs.scrapeless.com/api-11953650.md):
- 抓取 API > shopee [Shopee 搜索](https://apidocs.scrapeless.com/api-11954010.md):
- 抓取 API > shopee [Shopee 推荐](https://apidocs.scrapeless.com/api-11954111.md):
- 抓取 API > br 站点 [Solucoes cnpjreva](https://apidocs.scrapeless.com/api-11954435.md): 目标网址 `https://solucoes.receita.fazenda.gov.br/servicos/cnpjreva/valida_recaptcha.asp`
- 抓取 API > br 站点 [Solucoes certidaointernet](https://apidocs.scrapeless.com/api-12160439.md): 目标网址 `https://solucoes.receita.fazenda.gov.br/Servicos/certidaointernet/pj/emitir`- 抓取 API > 巴西网站 Servicos receita: 目标网址
https://servicos.receita.fazenda.gov.br/servicos/cpf/consultasituacao/ConsultaPublica.asp - 抓取 API > 巴西网站 Consopt: 目标网址
https://consopt.www8.receita.fazenda.gov.br/consultaoptantes - 抓取 API > 亚马逊 产品:
- 抓取 API > 亚马逊 卖家:
- 抓取 API > 亚马逊 关键词:
- 抓取 API > 谷歌搜索 谷歌搜索:
- 抓取 API > 谷歌搜索 谷歌图片:
- 抓取 API > 谷歌搜索 谷歌本地:
- 抓取 API > 谷歌趋势 自动补全:
- 抓取 API > 谷歌趋势 随时间变化的兴趣:
- 抓取 API > 谷歌趋势 按区域比较的细分:
- 抓取 API > 谷歌趋势 按子区域的兴趣:
- 抓取 API > 谷歌趋势 相关查询:
- 抓取 API > 谷歌趋势 相关主题:
- 抓取 API > 谷歌趋势 现在流行:
- 抓取 API > 谷歌航班 往返票:
- 抓取 API > 谷歌航班 单程票:
- 抓取 API > 谷歌航班 多城市:
- 抓取 API > 谷歌航班图表 图表:
- 抓取 API > 谷歌地图 谷歌地图:
- 抓取 API > 谷歌地图 谷歌地图自动补全:
- 抓取 API > 谷歌地图 谷歌地图贡献者评论:
- 抓取 API > 谷歌地图 谷歌地图路线:
- 抓取 API > 谷歌地图 谷歌地图评论:
- 抓取 API > 谷歌学术 谷歌学术:
- 抓取 API > 谷歌学术 谷歌学术作者:
- 抓取 API > 谷歌学术 谷歌学术引用:
- 抓取 API > 谷歌学术 谷歌学术个人资料:
- 抓取 API > 谷歌职业 谷歌职业:
- 抓取 API > 谷歌购物 谷歌购物:
- 抓取 API > 谷歌酒店 谷歌酒店:
- 抓取 API > 谷歌新闻 谷歌新闻:
- 抓取 API > 谷歌镜头 谷歌镜头:
- 抓取 API > 谷歌财经 谷歌财经:
- 抓取 API > 谷歌财经 谷歌财经市场:
- 抓取 API > 谷歌产品 谷歌产品:
- 抓取 API > 谷歌应用商店 谷歌游戏:
- 抓取 API > 谷歌应用商店 谷歌图书:
- 抓取 API > 谷歌应用商店 谷歌电影:
- 抓取 API > 谷歌应用商店 谷歌产品:
- 抓取 API > 谷歌应用商店 谷歌应用:
- 抓取 API > 谷歌广告 谷歌广告:
- 抓取 API 抓取请求:
- 抓取 API 抓取获取结果:
- 通用抓取 API JS 渲染:
- 通用抓取 API 网页解锁器:
- 通用抓取 API Akamaiweb Cookie:
- 通用抓取 API Akamaiweb 传感器:
- 爬虫 > 抓取 抓取单个 URL:
- 爬虫 > 抓取 抓取多个URL:
- 爬虫 > 抓取 取消批量抓取任务:
- 爬虫 > 抓取 获取抓取状态:
- 爬虫 > 抓取 获取批量抓取任务状态:
- 爬虫 > 抓取 获取批量抓取任务的错误:
- 爬虫 > 爬取 根据选项爬取多个URL:
- 爬虫 > 爬取 取消爬取任务:
- 爬虫 > 爬取 获取爬取任务状态:
- 爬虫 > 爬取 获取爬取任务的错误:
- 公共 演员状态:
- 公共 演员状态:
### 4. Markdown
通过在请求参数中添加 `response_type=markdown`,Scrapeless Universal Scraping API 将以Markdown格式返回特定页面的内容。
以下示例展示了 [抓取浏览器快速入门页面](https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started) 的Markdown效果。我们首先使用页面检查获取表格的CSS选择器。
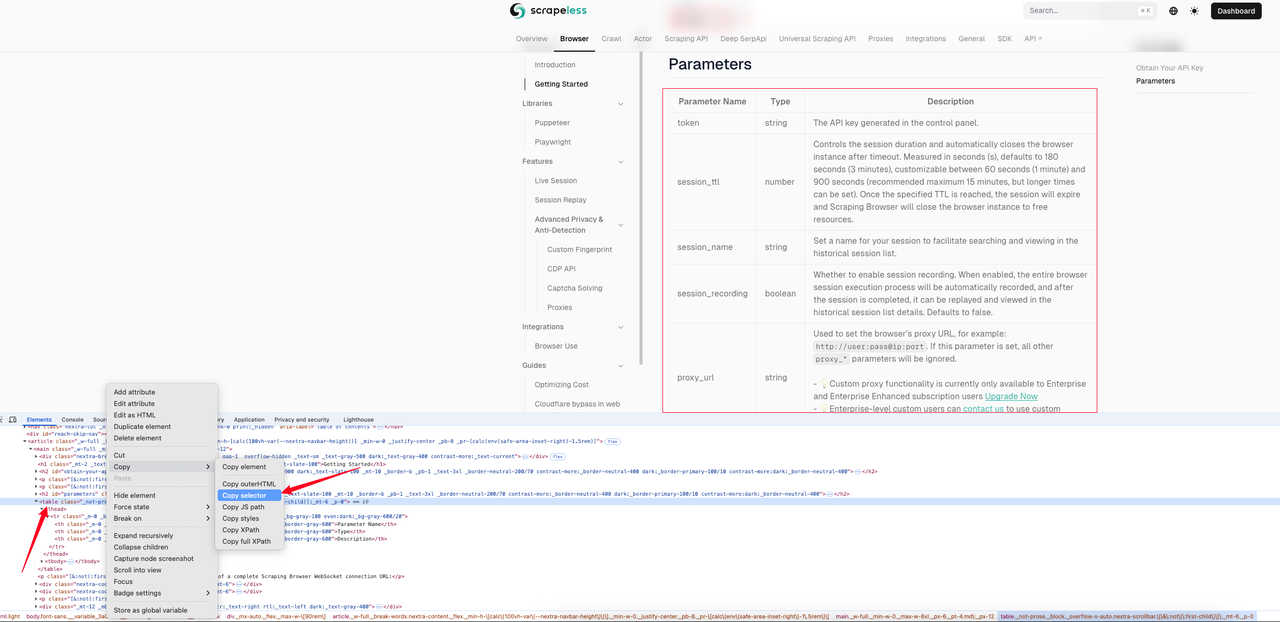
在这个例子中,我们获得的CSS选择器是: `#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table`。以下是完整的示例代码。
> Javascript
```JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started",
js_render: true,
response_type: "markdown",
selector: "#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table", // 页面表格元素的CSS选择器
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.md', response.data.data, 'utf8');
}
})();Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://docs.scrapeless.com/en/scraping-browser/quickstart/getting-started",
"js_render": True,
"response_type": "markdown",
"selector": "#__next > div:nth-child(3) > div._mx-auto._flex._max-w-\[90rem\] > article > main > table", # 页面表格元素的CSS选择器
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.md', 'w', encoding='utf-8') as f:
f.write(response.json()["data"])抓取表格的Markdown文本展示:
Markdown
| 参数名称 | 类型 | 描述 |
| --- | --- | --- |
| token | string | 在控制面板中生成的API密钥。 |
| session_ttl | number | 控制会话的持续时间,并在超时后自动关闭浏览器实例。以秒(s)为单位,默认为180秒(3分钟),可自定义为60秒(1分钟)到900秒(推荐最长15分钟,但可以设置更长的时间)。一旦达到指定的TTL,会话将过期,并且抓取浏览器将关闭浏览器实例以释放资源。 |
| session_name | string | 为您的会话设置一个名称,以方便在历史会话列表中搜索和查看。 |
| session_recording | boolean | 是否启用会话录制。当启用时,整个浏览器会话执行过程将自动录制,完成后可以在历史会话列表的详情中回放和查看。默认为false。 |
| proxy_url | string | 用于设置浏览器的代理URL,例如:http://user:pass@ip:port。如果设置了此参数,将忽略所有其他proxy_*参数。- 💡自定义代理功能当前仅对企业和增强企业订阅用户可用立即升级- 💡企业级自定义用户可以联系我们以使用自定义代理。 || proxy_country | 字符串 | 设置代理的目标国家/地区,通过该地区的 IP 地址发送请求。您可以指定国家代码(例如,美国为 US,英国为 GB,ANY 表示任何国家)。请参阅国家代码以获取所有支持的选项。 |
| fingerprint | 字符串 | 浏览器指纹是使用您的浏览器和设备配置生成的几乎唯一的“数字指纹”,可以在没有 cookies 的情况下用于跟踪您的在线活动。幸运的是,在 Scraping Browser 中配置指纹是可选的。我们提供浏览器指纹的深度定制,例如像浏览器用户代理、时区、语言和屏幕分辨率等核心参数,并支持通过自定义启动参数扩展功能。适用于多账户管理、数据收集和隐私保护场景,使用 scrapeless 自有的 Chromium 浏览器完全避免检测。默认情况下,我们的 Scraping Browser 服务为每个会话生成一个随机指纹。参考 |
### 5. PNG/JPEG
通过在请求中添加 response_type=png,您可以捕获目标页面的屏幕截图并返回 png 或 jpeg 图像。当响应结果设置为 png 或 jpeg 时,您可以使用 `response_image_full_page=true` 参数设置返回结果是否为全屏。该参数的默认值为 false。
以下代码示例展示了如何获取 [Scrapeless 主页](https://www.scrapeless.com/?utm_source=official&utm_medium=blog&utm_campaign=response-formats-update) 上指定区域的屏幕截图。首先,我们找到想要捕获图像的区域的 CSS 选择器。
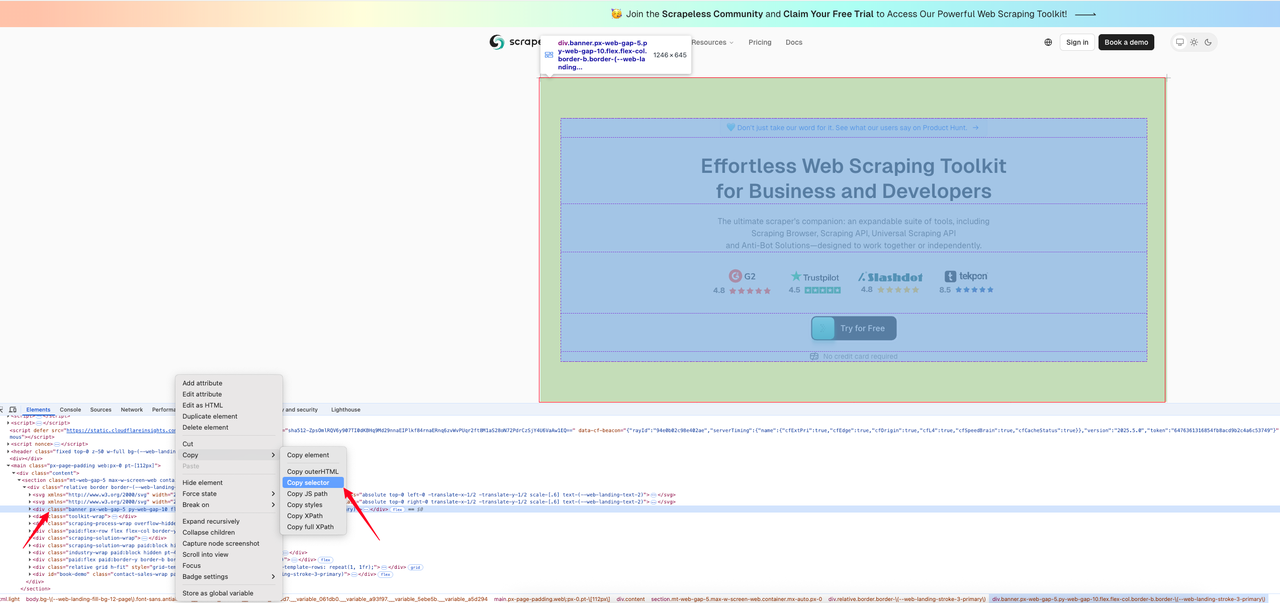
以下是拦截代码:
> Javascript
```JavaScript
const axios = require('axios');
const fs = require('fs');
(async () => {
const payload = {
actor: "unlocker.webunlocker",
input: {
url: "https://www.scrapeless.com/en",
js_render: true,
response_type: "png",
selector: "body > main > div > section > div > div.banner.px-web-gap-5.py-web-gap-10.flex.flex-col.border-b.border-\(--web-landing-stroke-3-primary\)", // 页面表元素的 CSS 选择器
},
proxy: {
country: "ANY"
}
};
const response = await axios.post("https://api.scrapeless.com/api/v1/unlocker/request", payload, {
headers: {
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout: 60000
});
if (response.data?.code === 200) {
fs.writeFileSync('response.png',Buffer.from(response.data.data, 'base64'));
}
})(); Python
Python
import requests
payload = {
"actor": "unlocker.webunlocker",
"input": {
"url": "https://www.scrapeless.com/en",
"js_render": True,
"response_type": "png",
"selector": "body > main > div > section > div > div.banner.px-web-gap-5.py-web-gap-10.flex.flex-col.border-b.border-\(--web-landing-stroke-3-primary\)", # 页面表元素的 CSS 选择器
},
"proxy": {
"country": "ANY"
}
}
response = requests.post(
"https://api.scrapeless.com/api/v1/unlocker/request",
json=payload,
headers={
"x-api-token": "API Key",
"Content-Type": "application/json"
},
timeout=60
)
if response.json()["code"] == 200:
with open('response.png', 'wb') as f:
content = base64.b64decode(response.json()["data"])
f.write(content)- PNG 返回结果:

👉 访问 Scrapeless 文档 了解更多信息
👉 立即查看 API 文档:JS 渲染
使用场景完全覆盖
此更新特别适合于:
- 内容提取应用程序(例如摘要生成、情报收集)
- SEO 数据爬取(例如元数据、结构化数据分析)
- 新闻聚合平台(快速提取文本和作者)
- 链接分析和监测工具(提取 href、nofollow 信息)
无论您是想快速爬取文本还是希望获取结构化数据,此更新都可以帮助您以更少的努力获得更多结果。
立即体验
此功能已在 Scrapeless 上全面推出。无需额外授权或升级计划。只需限制输出参数或传入 response_type 参数,即可体验新的数据返回格式!
Scrapeless 一直致力于构建一个智能、稳定且易于使用的网络数据平台。此次更新只是又一步的进展。欢迎您的体验和反馈,让我们一起使网络数据获取变得更简单。
📣 加入社区,第一时间获取更新和实用技巧!
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


