
Qwen 2.5-Max“思考(QwQ)”发布:加剧大模型竞争
Senior Web Scraping Engineer
AI模型的“持续战争”
2025年2月25日凌晨5点01分,阿里巴巴在X平台上宣布推出深度推理模型QwQ-Max-Preview(在Qwen Chat中命名为“思考(QwQ)”),该模型基于Qwen2.5-Max。它还完全开源了QwQ-Max和Qwen2.5-Max。此外,轻量级版本QwQ-32B即将推出,以支持本地部署,iOS/Android移动应用程序也正在计划中。
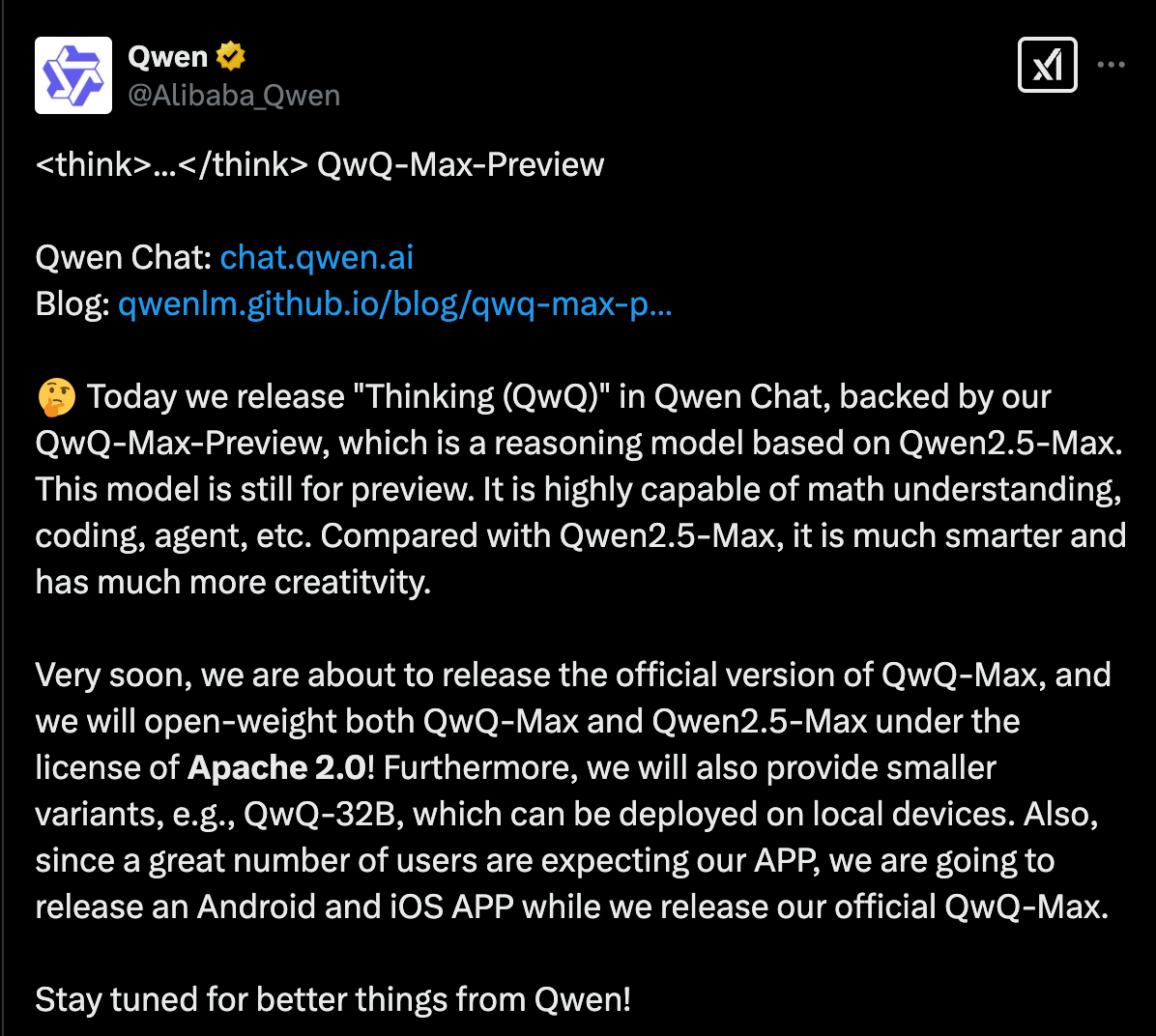
Qwen 2.5-Max的性能如何?
在我们的测试中,该模型的性能在数学、编程和多模态生成等任务中与GPT-4o、DeepSeek-V3、Llama-3.1-405B和Claude 3.5 Sonnet具有竞争力。
基准性能比较
- Arena-Hard(偏好基准): Qwen2.5-Max得分为89.4,领先于DeepSeek V3(85.5)和Claude 3.5 Sonnet(85.2)。
- MMLU-Pro(知识和推理): Qwen2.5-Max得分为76.1,略高于DeepSeek V3(75.9),但略低于Claude 3.5 Sonnet(78.0)和GPT-4o(77.0)。
- GPQA-Diamond(常识问答): Qwen2.5-Max得分为60.1,略胜于DeepSeek V3(59.1),而Claude 3.5 Sonnet以65.0领先。
- LiveCodeBench(编码能力): Qwen2.5-Max得分为38.7,大致相当于DeepSeek V3(37.6),但落后于Claude 3.5 Sonnet(38.9)。
- LiveBench(整体能力): Qwen2.5-Max得分为62.2,领先于DeepSeek V3(60.5)和Claude 3.5 Sonnet(60.3)。
总的来说,Qwen2.5-Max已被证明是一个全面的AI模型,在基于偏好的任务和通用AI能力方面表现出色,同时保持了具有竞争力的知识和编码能力。
此外,Qwen2.5-Max通过Artifacts功能支持代码片段生成、文件解析和图像理解。一次调用可以处理超过1小时的视频内容。
数据真相
- 模型迭代和数据更新之间的剪刀差:传统工具的数据更新周期为几天,而Qwen2.5-Max通过20万亿token的预训练数据实现了动态知识更新。
- 技术代差的风险:Gartner预测,到2025年,AI模型性能将每三个月提高15%,而滞后的数据基础设施将导致竞争力断裂。
流行模型的实时数据比较
1. 长文本处理速度比较
| 模型 | 处理速度(秒/千字) |
|---|---|
| Qwen 2.5-Max | 0.5 |
| GPT-4 | 0.6 |
| DeepSeek-V3 | 0.575 |
| Llama-3.1-405B | 0.600 |
2. 训练数据集大小比较
| 模型 | 训练数据集大小(万亿字) |
|---|---|
| Qwen 2.5-Max | 2 |
| GPT-4 | 1.5 |
| DeepSeek-V3 | 1.8 |
| Llama-3.1-405B | 1.7 |
3. 平均响应时间比较
| 模型 | 平均响应时间(秒) |
|---|---|
| Qwen 2.5-Max | 0.3 |
| GPT-4 | 0.5 |
| DeepSeek-V3 | 0.4 |
| Llama-3.1-405B | 0.45 |
4. 更新频率比较
| 模型 | 更新频率 |
|---|---|
| Qwen 2.5-Max | 每月一次 |
| GPT-4 | 每季度一次 |
| DeepSeek-V3 | 每两个月一次 |
| Llama-3.1-405B | 每三个月一次 |
哪些方面直接影响数据模型的发展?
在AI竞争中,数据基础设施的质量直接决定了模型的上限。实时数据提取工具通过三种核心能力影响AI工具的发展:
数据覆盖广度
虽然Qwen2.5-Max支持29种语言,但其开源版本仍然依赖于公共语料库,导致数据覆盖范围有限。因此,需要一个集成众多数据接口和数据源的信息提取工具来确保模型数据的全面性和准确性。
信息更新速度
AI模型性能每三个月迭代一次,但传统爬虫受到反爬虫机制(如验证码和动态加载)的限制,数据更新周期为几天。显然,信息提取工具的数据采集和迭代能力需要不断更新,以确保数据的时效性。
多模态支持
AI模型对多模态数据的需求激增,但传统爬虫在解析PDF表格时的错误率为40%,提取视频字幕需要10多分钟。强大的AI模型应集成结构化数据提取技术,自动解析PDF表格、视频字幕和图像元数据,并确保准确性。
Scrapeless Deep SerpApi:LLM开发的有利工具
如果Qwen 2.5-Max开启了AI的持续发展,那么Scrapeless Deep SerpApi就是推动这一变化的关键武器。
Deep SerpApi是一个专为大型语言模型(LLM)和AI代理设计的专用搜索引擎。它提供实时、准确和无偏差的信息,使AI应用程序能够有效地检索和处理数据:
✅ 它内置了20多个谷歌搜索API场景接口,并连接到主流搜索引擎的数据。
✅ 它涵盖20多种数据类型,例如搜索结果、新闻、视频和图像。
✅ 它支持过去24小时内的历史数据更新。
在未来的产品规划中,我们将充分考虑AI开发者的需求。我们将简化将动态网络信息集成到AI驱动解决方案的过程,最终实现一个一体化API,允许一键搜索和提取网络数据。此外,我们将长期保持该领域最低的价格:0.1-0.3美元/1K查询。
最重要的事件!🔔 开发者支持计划已启动:
您可以将Scrapeless集成到您的AI工具、应用程序或您正在参与的任何项目中。我们支持Dify(Langchain、Langflow、FlowiseAI等框架,以及许多其他即将推出的框架!)。您还可以通过适合您项目的其他方式集成Scrapeless。
集成完成后,请通过GitHub或社交媒体与我们分享您的作品,并提供集成证明。作为回报,我们将为您提供50万次免费查询(有效期为1个月),以帮助您最大限度地利用我们产品的优势。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


