
使用 Node.JS 的亚马逊网页抓取器 - 2025 年 JavaScript 教程
Expert Network Defense Engineer
亚马逊是全球领先的电子商务平台,拥有宝贵的产品数据,可用于市场研究和价格监控。使用 JavaScript 和 Node.js 以及 Playwright,我们可以构建一个 JavaScript 网页抓取工具来提取这些数据,但是 JavaScript 渲染、反机器人检测和 CAPTCHA 等挑战使得手动抓取变得困难。
Scrapeless 的亚马逊抓取 API 提供了一种更快、更可靠的解决方案,它可以处理 CAPTCHA、代理和网站解锁,确保实时、准确的数据而不会被检测到。本教程将涵盖这两种方法,并说明为什么 Scrapeless 是高效抓取亚马逊数据的最佳选择。🚀
抓取亚马逊的挑战
由于亚马逊强大的反机器人保护,抓取亚马逊面临着若干挑战:
- JavaScript 渲染: 亚马逊严重依赖 JavaScript,这使得使用简单的 HTTP 请求提取数据变得困难。需要使用 Playwright 或类似工具的 JavaScript 抓取工具来渲染动态内容。
- CAPTCHA 保护: 频繁的 CAPTCHA 挑战会中断抓取,需要解决机制才能继续数据提取。
- IP 封锁和速率限制: 亚马逊会检测并阻止来自同一 IP 的重复请求,因此需要轮换代理或其他规避技术。
- 网站频繁更改: 亚马逊定期更新其网站结构,这可能会破坏抓取脚本并需要持续维护。
如何使用 Node.js 构建 JavaScript 抓取工具?
在下面的示例中,我们将使用 JavaScript 抓取亚马逊并将提取的数据存储在本地 JSON 文件中。
抓取准备
我们需要从一开始就设置必要的 Node.js 网页抓取工具:
在本文中,我将使用 Playwright,这是一个高度活跃的开源项目,拥有众多贡献者。它由微软开发,支持多种浏览器(Chromium、Firefox 和 WebKit)和多种编程语言(Node.js、Python、.NET 和 Java),使其成为当今最流行的 JavaScript 抓取框架之一。
在这里,确保您的 Node.js 版本为 18 或更高版本,然后运行以下脚本安装 Playwright:
Bash
# pnpm
pnpm create playwright
# yarn
yarn create playwright
# npm
npm init playwright@latest对网页封锁和头疼的项目构建感到沮丧?
加入 我们的社区 并获得有效的解决方案以及免费试用!
步骤 1. 检查目标页面
在抓取之前,尝试访问 **https://www.amazon.com/**。如果这是您第一次访问该网站,您可能会遇到 CAPTCHA。
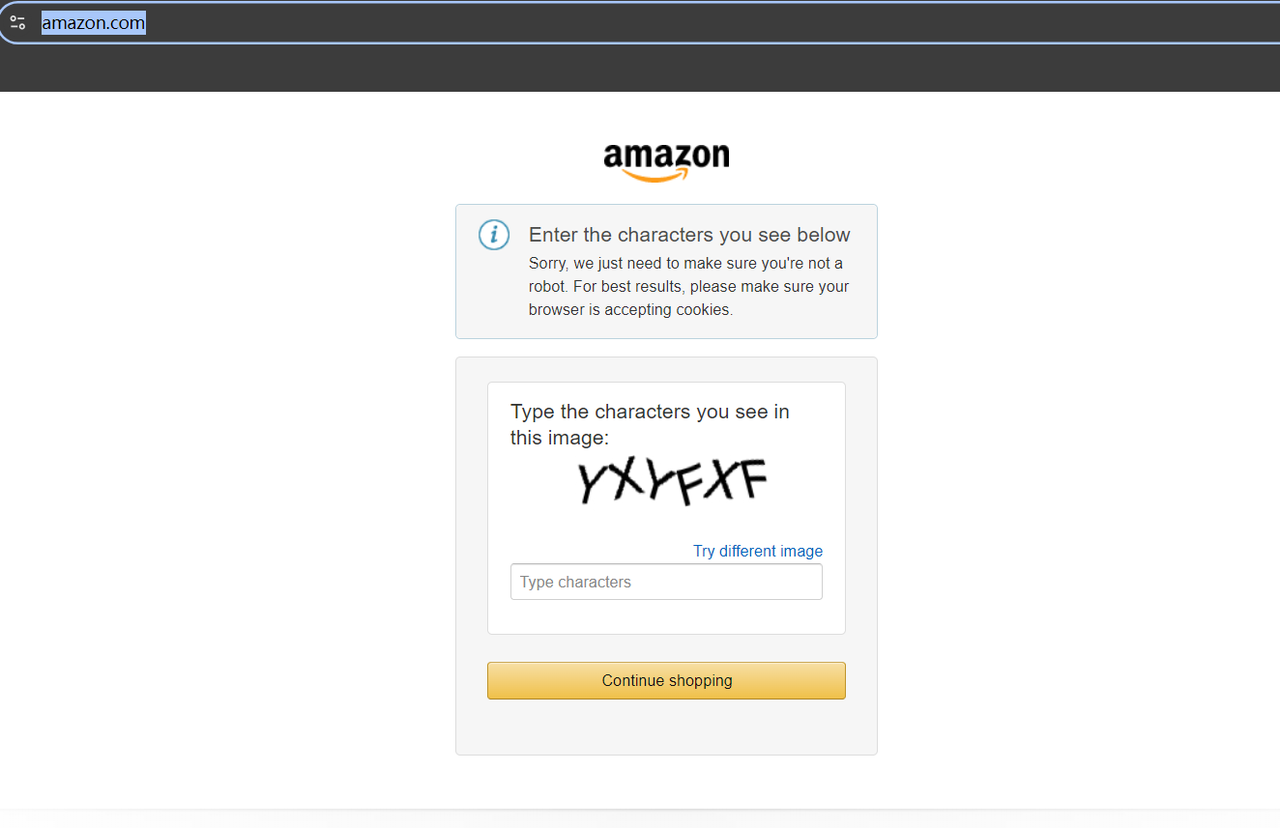
但不用担心——我们不需要费力寻找 CAPTCHA 解决工具。只需访问您所在地区或代理位置的特定亚马逊域名,就不会触发 CAPTCHA。
例如,让我们访问 https://www.amazon.co.uk/,即英国亚马逊域名。您将看到页面顺利加载。现在,尝试在顶部的搜索栏中输入您想要的产品关键词,或者直接通过 URL 访问搜索结果,例如:
Bash
https://www.amazon.co.uk/s?k=jacket在 URL 中,/s?k= 后面的值代表产品关键词。通过访问上述 URL,您将在亚马逊上看到与衬衫相关的产品。
现在,打开开发者工具 (F12) 以检查页面的 HTML 结构。使用光标突出显示元素并识别稍后需要抓取的数据。
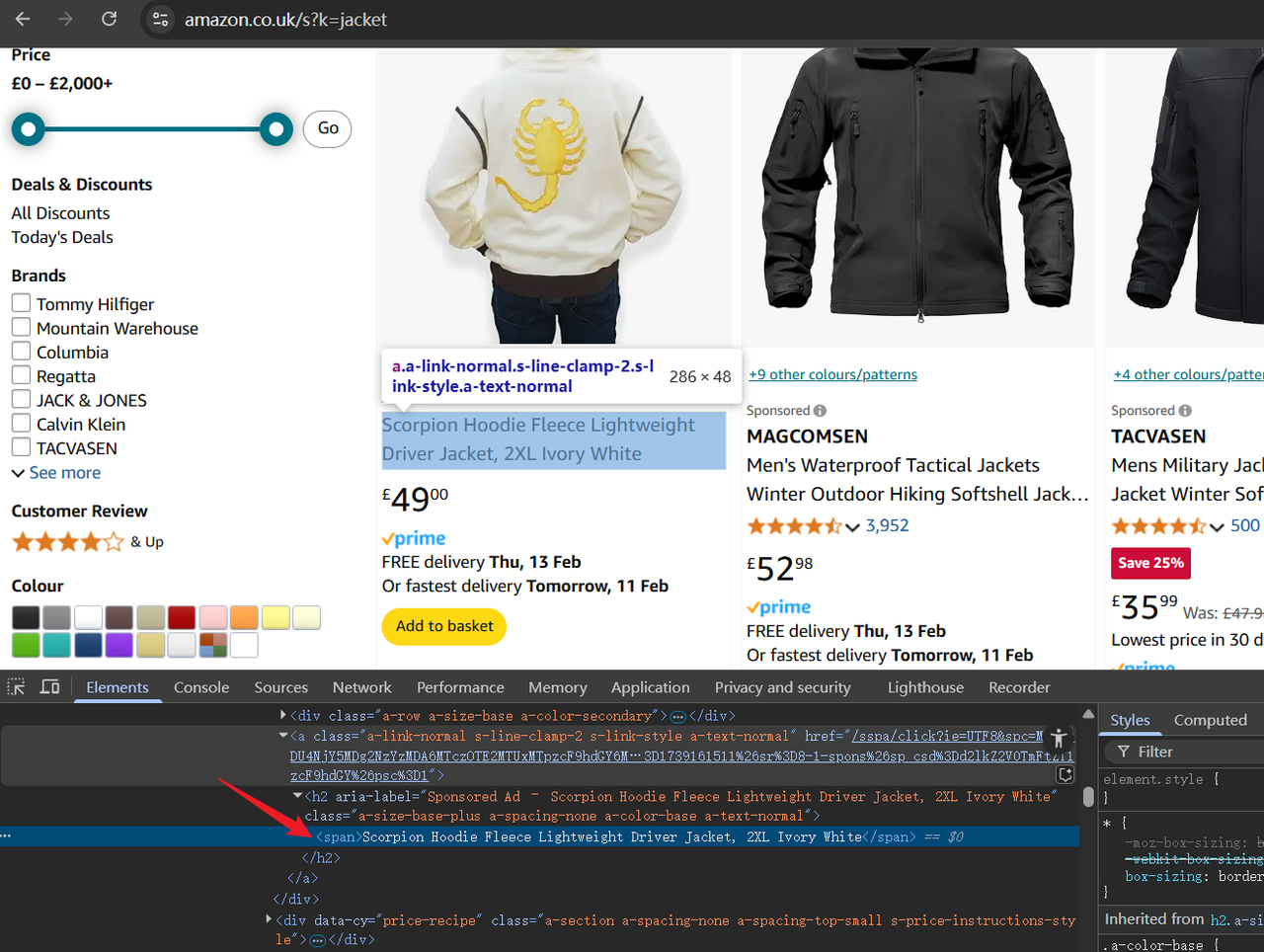
步骤 2. 编写脚本
首先,让我们在脚本顶部添加一段初始代码。以下代码将第一个脚本参数作为亚马逊产品关键词,稍后将用于抓取:
JavaScript
const productName = process.argv.slice(2);
if (productName.length !== 1) {console.error('product name CLI arguments missing!');
process.exit(2);
}接下来,我们需要:
- 导入 Playwright 以与浏览器交互。
- 导航到亚马逊搜索结果页面。
- 添加屏幕截图以验证访问成功。
JavaScript
import playwright from "playwright";
const browser = await playwright.chromium.launch()
const page = await browser.newPage();
await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);
// 添加屏幕截图进行调试
await page.screenshot({ path: 'amazon_page.png' })现在,我们将使用 page.$$ 获取所有产品容器,循环遍历它们并提取相关数据。这些数据随后存储在 productDataList 数组中并打印:
JavaScript
// 获取所有搜索结果容器
const productContainers = await page.$$('div[data-component-type="s-search-result"]')
const productDataList = []
// 提取产品详细信息:标题、评分、图片 URL 和价格
for (const product of productContainers) {
async function safeEval(selector, evalFn) {
try {
return await product.$eval(selector, evalFn);
} catch (e) {
return null;
}
}
const title = await safeEval('.s-title-instructions-style > h2 > a > span', node => node.textContent)
const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)
const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))
const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)
productDataList.push({ title, rate, img, price })
}
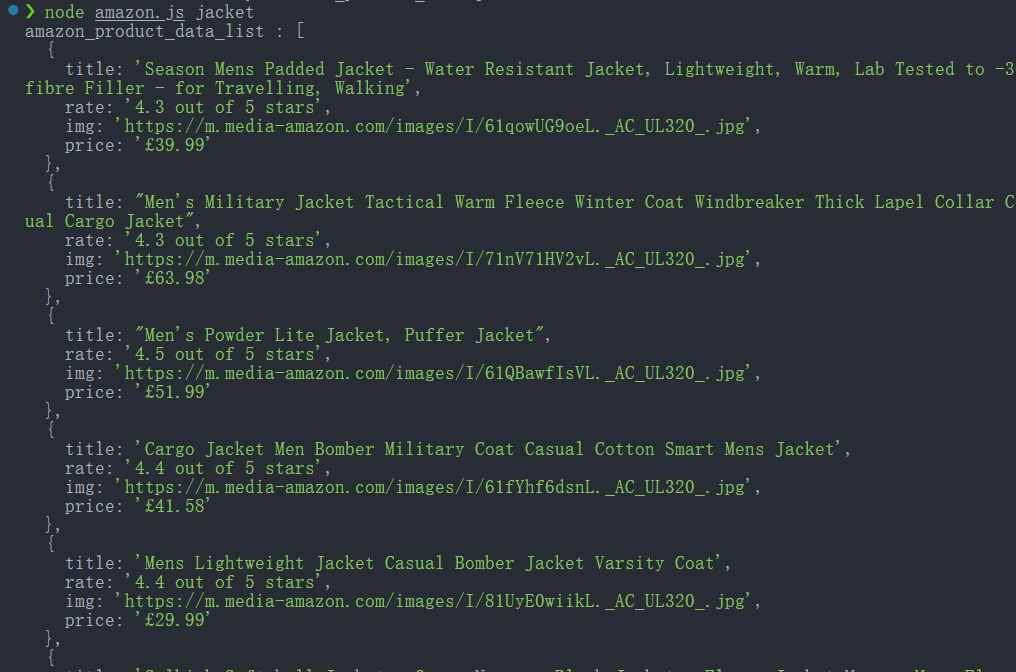
console.log('amazon_product_data_list :', productDataList);
await browser.close();使用以下命令运行脚本:
Bash
node amazon.js jacket如果成功,控制台将打印提取的产品数据。
步骤 3. 将抓取的数据保存为 JSON 文件
仅将数据打印到控制台不足以进行正确的分析。让我们使用 Node.js 的 fs 模块将提取的数据保存到 JSON 文件中:
JavaScript
import fs from 'fs'
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}
saveObjectToJson(productDataList, 'amazon_product_data.json')好了,让我们来看一下完整的脚本:
JavaScript
import playwright from "playwright";
import fs from 'fs'
const productName = process.argv.slice(2);
if (productName.length !== 1) {
console.error('product name CLI arguments missing!');
process.exit(2);
}
const browser = await playwright.chromium.launch()
const page = await browser.newPage();
await page.goto(`https://www.amazon.co.uk/s?k=${productName}`);
// 添加屏幕截图进行调试
await page.screenshot({ path: 'amazon_page.png' })
// 获取所有搜索结果容器
const productContainers = await page.$$('div[data-component-type="s-search-result"]')
const productDataList = []
// 提取产品详细信息:标题、评分、图片 URL 和价格
for (const product of productContainers) {
async function safeEval(selector, evalFn) {
try {
return await product.$eval(selector, evalFn);
} catch (e) {
return null;
}
}
const title = await safeEval('.s-title-instructions-style > a > h2 > span', node => node.textContent)
const rate = await safeEval('a > i.a-icon.a-icon-star-small > span', node => node.textContent)
const img = await safeEval('span[data-component-type="s-product-image"] img', node => node.getAttribute('src'))
const price = await safeEval('div[data-cy="price-recipe"] .a-offscreen', node => node.textContent)
productDataList.push({ title, rate, img, price })
}
console.log('amazon_product_data_list :', productDataList);
function saveObjectToJson(obj, filename) {
const jsonString = JSON.stringify(obj, null, 2)
fs.writeFile(filename, jsonString, 'utf8', (err) => {
err ? console.error(err) : console.log(`File saved successfully: ${filename}`);
});
}
saveObjectToJson(productDataList, 'amazon_product_data.json')
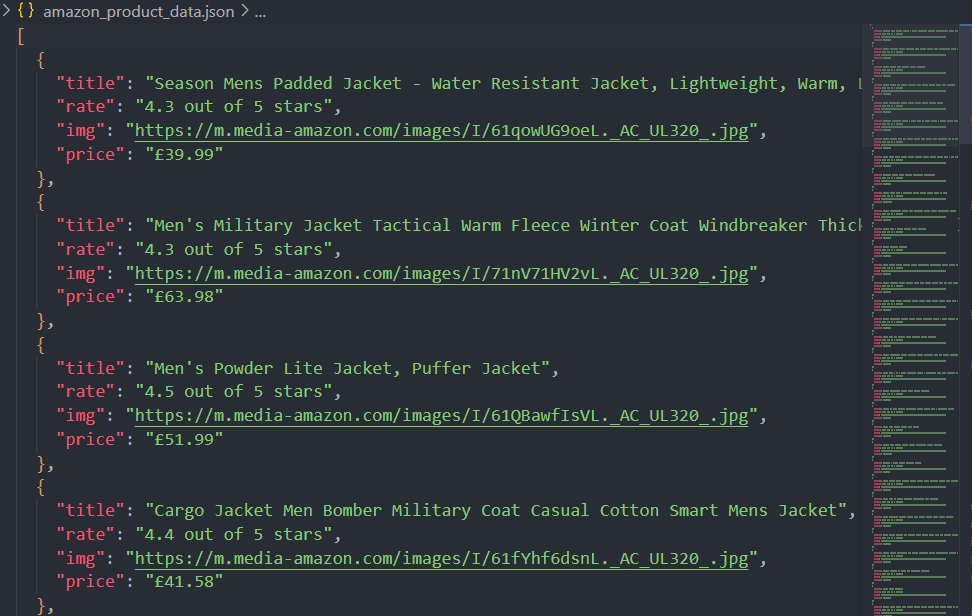
await browser.close();现在,运行脚本后,数据不仅会打印在控制台上,还会保存为 JSON 文件(amazon_product_data.json)。
避免在抓取亚马逊时被封锁
由于亚马逊严格的反机器人措施,从亚马逊抓取数据可能具有挑战性,但使用 Scrapeless 的网页解锁器 有助于有效绕过这些限制。
亚马逊采用诸如 IP 速率限制、浏览器指纹识别和 CAPTCHA 验证等机器人检测技术来防止自动访问。Scrapeless 的网页解锁器通过轮换住宅代理、模拟真实用户行为和处理动态内容渲染来克服这些障碍。
通过将 Scrapeless 与无头浏览器(如 playwright 或 Playwright)集成,用户可以抓取亚马逊的产品数据而不会被封锁,从而确保无缝高效的数据提取过程。
JavaScript 抓取最佳实践和注意事项
在 JavaScript 中构建网页抓取工具时,至关重要的是要优化效率、处理动态内容并避免常见的陷阱。以下是一些关键的最佳实践和注意事项:
- 处理 JavaScript 渲染的页面
许多现代网站使用 JavaScript 动态加载内容。传统的 HTTP 请求(如 Axios 或 Fetch)无法捕获此类内容。相反,请使用无头浏览器(如 playwright、Playwright 或 Selenium)来渲染并从 JavaScript 密集型页面提取数据。 - 管理并发以加快抓取速度
顺序运行抓取工具可能会很慢。通过启动多个并行抓取任务来实现并发以提高性能。使用 async/await 与 Promises 并管理队列系统以有效地平衡抓取负载。 - 尊重 robots.txt 和网站策略
在抓取之前,请检查网站的robots.txt文件以确定其抓取规则。忽略这些规则可能会导致 IP 被封禁或法律问题。此外,请考虑使用 用户代理轮换和请求节流 以最大限度地减少对目标服务器的影响。 - 避免 Web 应用防火墙 (WAF)
网站部署诸如 Akamai、Cloudflare 和 PerimeterX 等 WAF 来阻止自动流量。诸如 会话持久性、浏览器指纹规避和 CAPTCHA 解决工具 等技术可以帮助减轻检测和封锁。 - 高效的 URL 管理和去重
通过维护已访问 URL 集,确保您的抓取工具不会多次访问相同的 URL。实现规范化技术以规范化 URL 并防止重复数据收集。 - 处理分页和无限滚动
网站通常使用分页或无限滚动来动态加载内容。确定分页结构(例如,?page=2)或使用无头浏览器来模拟滚动并提取所有内容。 - 数据提取和存储优化
提取数据后,请正确格式化并高效地存储数据。将结构化数据保存在 JSON、CSV 或 MongoDB 或 PostgreSQL 等数据库中,以便更好地处理和分析。 - 大规模抓取的分布式抓取
对于大规模抓取任务,请使用 基于队列的抓取框架或云浏览器解决方案 将工作负载分配到多台机器或云实例上。这可以防止单个系统过载并提高容错能力。
使用 Scrapeless 抓取 API 获得更快、更可靠的解决方案
通过将 Scrapeless 与无头浏览器(如 Playwright)集成,用户可以使用 JavaScript 构建抓取工具来提取亚马逊产品数据而不会被封锁,从而确保无缝高效的数据提取过程。
特性:
✅ 只需一个 API 调用即可立即访问最新数据。
✅ 每秒超过 200 个并发请求,每月超过 1 亿个请求。
✅ 每个请求平均需要 5 秒,确保实时数据检索而无需缓存。
✅ 支持自定义抓取规则以满足不同的需求
✅ 支持多平台抓取,除了亚马逊外,还可以支持其他电子商务平台:Shopee,Shein 等。
✅ 只需为成功的搜索付费
为什么选择 Scrapeless?
- 实时数据: 确保产品列表是最新的和准确的。
- 集成的网站解锁: 自动绕过限制和 CAPTCHA。
- 合法性: Scrapeless 提供了一种合法且符合规定的访问搜索结果的方式。
- 可靠性: 该 API 使用复杂的技巧来避免检测,确保不间断的数据收集。
- 易于使用: Scrapeless 提供了一个简单的 API,可以轻松地与 Python 集成,非常适合需要快速访问搜索结果数据的开发人员。
- 可定制: 您可以根据自己的需要定制结果,例如指定内容类型(例如,自然列表、广告等)。
Scrapeless 抓取 API 成本高吗?
Scrapeless 提供了一个可靠且可扩展的网页抓取平台,价格具有 竞争力(与 Zenrows 和 Apify 相比),确保为用户提供极高的价值:
- 抓取浏览器: 每小时 0.09 美元起
- 抓取 API: 每 1k 个 URL 0.8 美元起
- 网页解锁器: 每 1k 个 URL 0.20 美元起
- 验证码求解器: 每 1k 个 URL 0.80 美元起
- 代理: 每 GB 2.80 美元起
通过 订阅,您可以享受每项服务高达 20% 的折扣。
如何实现 Scrapeless 的亚马逊抓取 API
如果您希望从亚马逊产品页面提取 ASIN 编号,Scrapeless 提供了一种简单有效的方法。通过使用 Scrapeless 的亚马逊抓取 API,您可以轻松获得 ASIN 编号以及其他关键产品详细信息。
步骤 1. 登录到 Scrapeless。
步骤 2. 点击抓取 API > 选择亚马逊 以进入 Shopee 抓取页面。
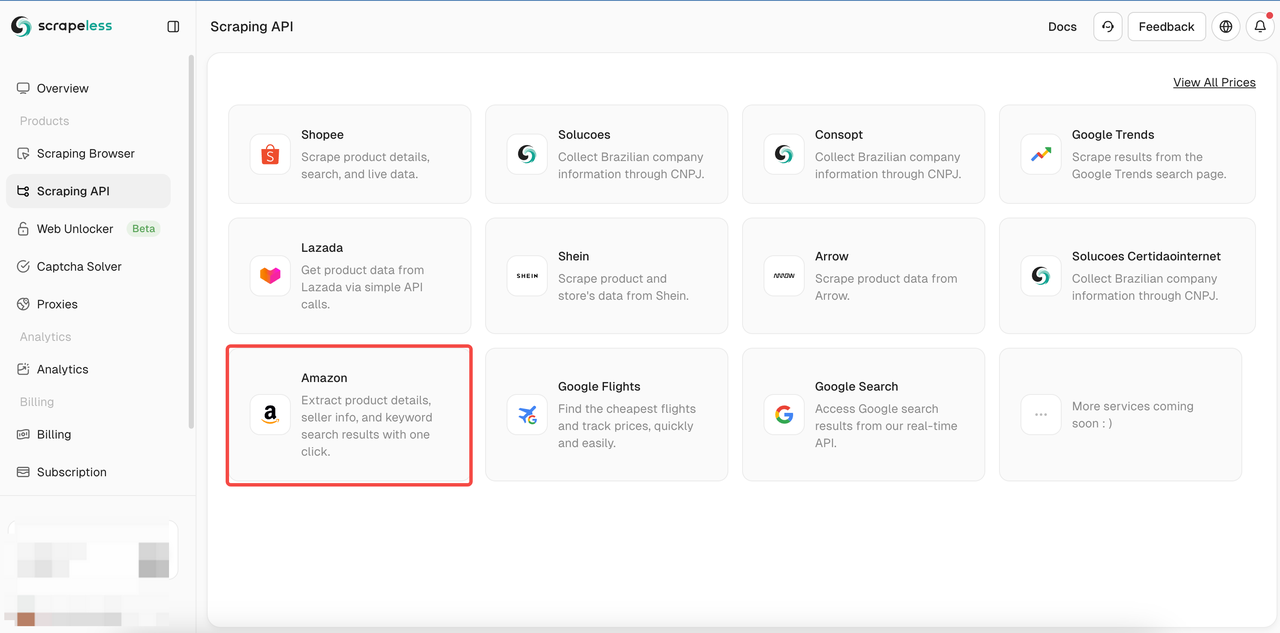
步骤 3. 将要抓取的 亚马逊产品页面 的链接粘贴到输入框中。并选择要抓取的 数据类型。
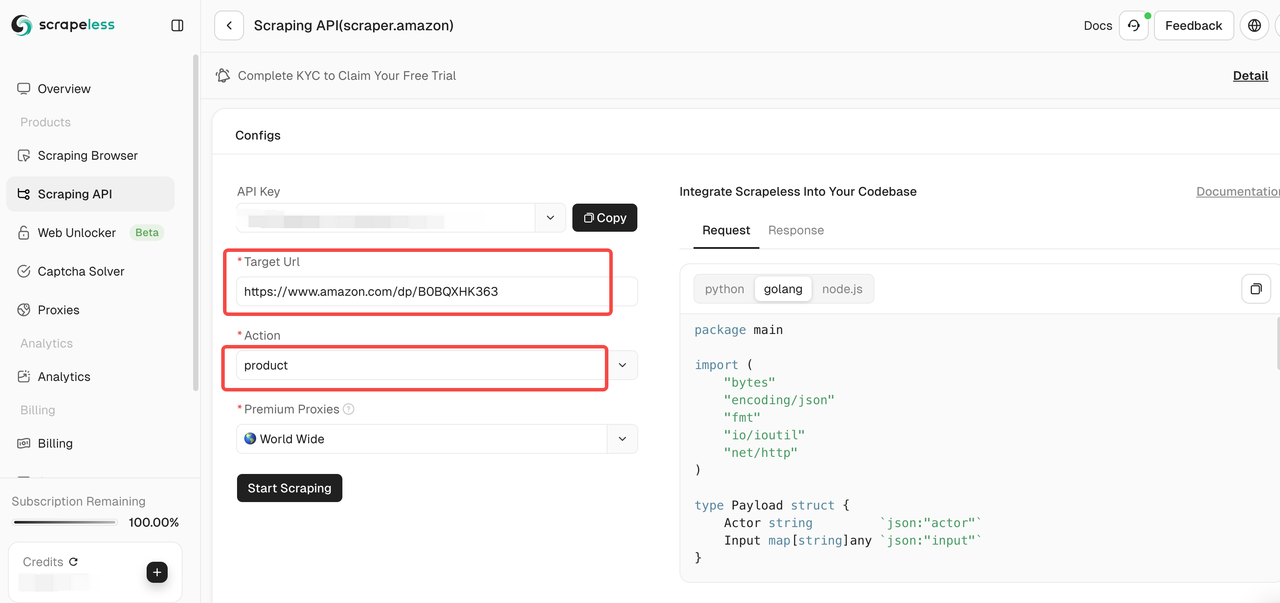
在工具页面上,您可以选择要抓取的数据类型:
- 卖家: 抓取卖家信息,包括卖家名称、评分、联系信息等。
- 产品: 抓取产品详细信息,例如标题、价格、评分、评论等。
- 关键词: 抓取与产品相关的关键词,以帮助您分析产品的 SEO 和市场趋势。
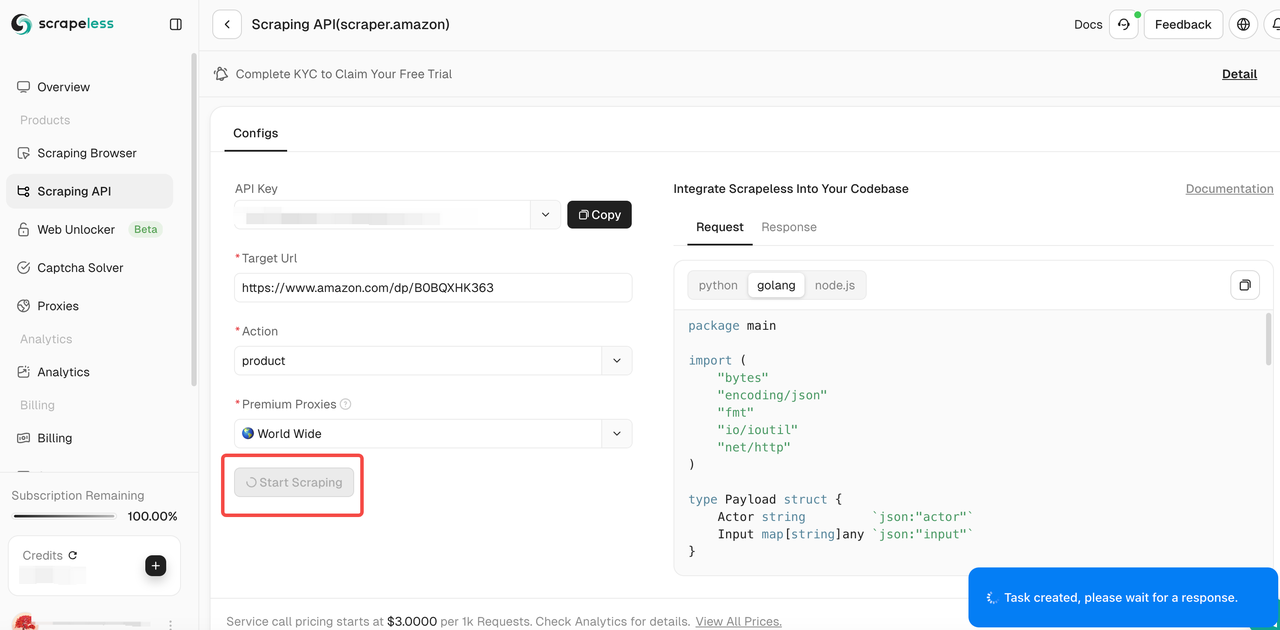
步骤 4. 确认输入链接和所选数据类型正确后,单击“开始抓取”按钮。系统将开始抓取数据,并在页面右侧的面板中显示抓取的结果。
步骤 5. 抓取完成后,您可以在右侧的面板中查看抓取的数据。结果将以清晰的格式显示,便于分析。
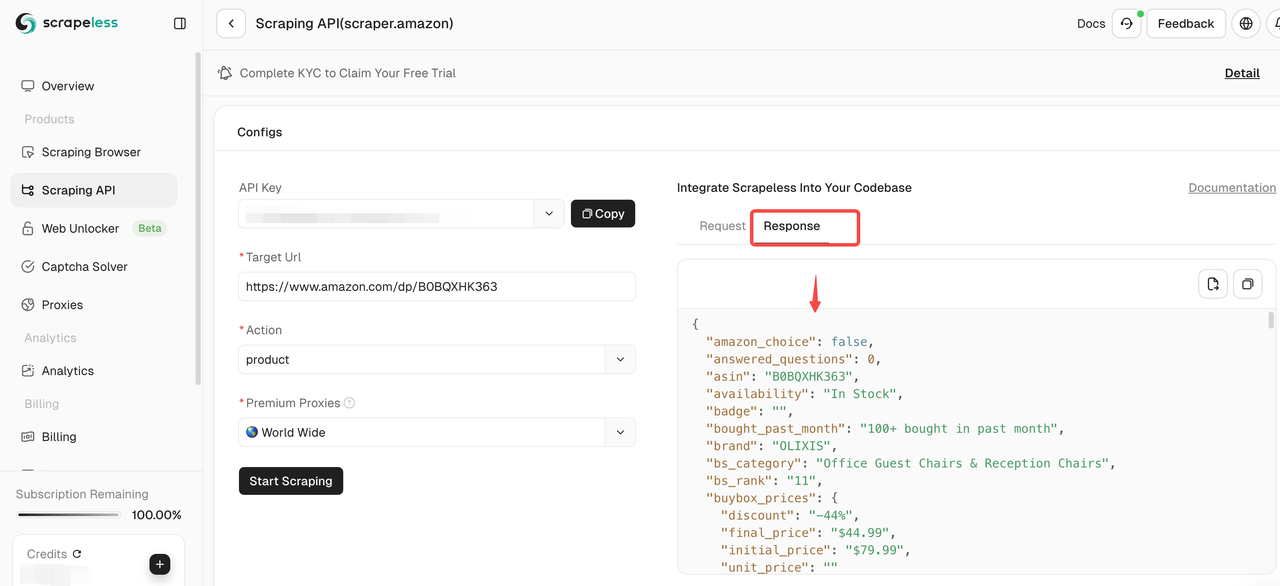
如果您需要抓取其他产品,请单击继续以输入新的亚马逊链接并重复上述步骤!
您还可以直接 集成我们的代码 到您的项目中:
Node.js
JavaScript
const https = require('https');
class Payload {
constructor(actor, input) {
this.actor = actor;
this.input = input;
}
}
function sendRequest() {
const host = "api.scrapeless.com";
const url = `https://${host}/api/v1/scraper/request`;
const token = " "; // API Token
const inputData = {
action: "product",
url: " " // Product URL
};
const payload = new Payload("scraper.amazon", inputData);
const jsonPayload = JSON.stringify(payload);
const options = {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token
}
};
const req = https.request(url, options, (res) => {
let body = '';
res.on('data', (chunk) => {
body += chunk;
});
res.on('end', () => {
console.log("body", body);
});
});
req.on('error', (error) => {
console.error('Error:', error);
});
req.write(jsonPayload);
req.end();
}
sendRequest();Python
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = " " ## API Token
headers = {
"x-api-token": token
}
input_data = {
"action": "product",
"url": " " ## Product URL
}
payload = Payload("scraper.amazon", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Golang
Go
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
type Payload struct {
Actor string `json:"actor"`
Input map[string]any `json:"input"`
}
func sendRequest() error {
host := "api.scrapeless.com"
url := fmt.Sprintf("https://%s/api/v1/scraper/request", host)
token := " " // API Token
headers := map[string]string{"x-api-token": token}
inputData := map[string]any{
"action": "product",
"url": " ", // Product URL
}
payload := Payload{
Actor: "scraper.amazon",
Input: inputData,
}
jsonPayload, err := json.Marshal(payload)
if err != nil {
return err
}
req, err := http.NewRequest("POST", url, bytes.NewBuffer(jsonPayload))
if err != nil {
return err
}
for key, value := range headers {
req.Header.Set(key, value)
}
client := &http.Client{}
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return err
}
fmt.Printf("body %s\n", string(body))
return nil
}
func main() {
err := sendRequest()
if err != nil {
fmt.Println("Error:", err)
return
}
}结论:2025 年抓取亚马逊的最佳方法
使用 Node.js 构建 JavaScript 抓取工具可以完全控制抓取过程,但会面临处理动态内容、解决 CAPTCHA、管理代理和避免检测等挑战。它需要大量的技术工作和持续的维护。
对于大规模、高效且不易被检测到的抓取,Scrapeless 的 API 是最佳选择。它消除了机器人检测的复杂性,使数据提取变得轻松且可扩展!
🚀 立即试用 Scrapeless 的亚马逊抓取 API,获得快速、可靠且无忧的抓取体验!
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


