
Node Unblocker 能完全绕过网页抓取的挑战吗?
Expert Network Defense Engineer
Node Unblocker可以自定义,包含IP轮换、头部定制和加密等功能。因此我们习惯于构建Node Unblocker来绕过网站封锁。
Node Unblocker确实擅长绕过网站挑战,但在实践中我们发现仍然需要处理其一些固有的问题。
如何让你的Node Unblocker更强大?是否存在一种方法或工具可以直接完全克服网站挑战?
是时候从这篇文章中找到最佳答案了!
什么是Node Unblocker?
Node Unblocker是一个使用Node.js构建的网页代理工具,用于绕过网络限制或网站访问限制。它充当用户和目标网站之间的中介,允许用户与可能因地理限制、网络过滤器或防火墙而被阻止的内容进行交互。
Unblocker通过将用户的请求路由到Node.js服务器来实现此功能,该服务器获取所需内容并将其返回给用户。它通常支持动态内容处理,使其适用于现代Web应用程序。
如何使用Node Unblocker?
首先,我们将创建一个基本的Node.js服务。然后,我们将讨论如何使用Node Unblocker创建中间件,使其能够集成到我们的Node服务中。更多详细信息,您可以直接访问Node Unblocker文档。
先决条件
在开始之前,您需要安装Node.js。您可以在这里下载Node.js。
现在让我们开始创建一个基本的Node.js服务。
- 初始化一个新的Node.js项目。如果您还没有项目,请使用以下命令创建一个:
Bash
mkdir node-unblocker-tutorial- 导航到项目目录,初始化项目并安装所需的依赖项:
Bash
cd node-unblocker-tutorial
npm init -y
pnpm add express unblocker- 现在,创建一个新文件index.js来组织您的代码:
Bash
touch index.js设置基本的Node.js服务
- 导入必要的模块,
express和unblocker:
JavaScript
import express from 'express';
import unblocker from 'unblocker';- 接下来,创建一个Express应用程序:
JavaScript
const app = express();- 初始化Unblocker实例并设置其代理前缀:
JavaScript
const unblocker = new Unblocker({
prefix: '/proxy/'
});确保使用app.use()方法将Unblocker实例与Express应用程序集成:
JavaScript
app.use(unblocker());- 定义端口并使用
app.listen()方法启动Node.js服务:
JavaScript
const PORT = process.env.PORT || 9090;
app.listen(PORT, () => {
console.log(`Server started on port ${PORT}`);
});- 这是设置的完整代码:
JavaScript
import express from 'express';
import Unblocker from 'unblocker';
const app = express();
const unblocker = new Unblocker({ prefix: '/proxy/' });
app.use(unblocker);
const PORT = process.env.PORT || 9090;
app
.listen(PORT, () => {
console.log(`Server started on port ${PORT}`);
})
.on('upgrade', unblocker.onUpgrade);运行服务
使用Node运行index.js文件以在端口9090上启动服务器。通过将目标URL附加到代理前缀来测试代理。在此示例中,我们将使用https://ident.me/作为目标页面。运行服务后,在浏览器中打开以下链接:
node index.js
您将看到一个显示当前服务IP地址的页面,表明设置已正确运行:

Node Unblocker的5个限制
- 性能瓶颈
由于Node Unblocker实时处理Web请求和响应,因此在处理大量并发请求或大量流量时,它可能会成为性能瓶颈。
- 资源消耗
Node Unblocker需要服务器资源来处理请求,尤其是在处理大型文件、多媒体内容或高度动态网页时。这可能导致CPU和内存使用量增加。
- 绕过能力有限
虽然Node Unblocker可以绕过一些基本限制,但它难以应对高级反机器人系统,例如CAPTCHA、JavaScript指纹识别或基于IP的速率限制机制。
- 可扩展性挑战
Node Unblocker本身并非为分布式设置或高可扩展性而构建,这使得它不适合企业级或大型应用程序,除非进行大量自定义。
- 缺乏HTTPS检查
Node Unblocker不解密或检查HTTPS流量,这限制了它在代理过程中修改或分析加密数据的能力。
使用Node Unblocker的一些最佳实践?
1. 轮换用户代理头
为了使您的网络抓取活动看起来像是来自不同的用户,旋转User-Agent头至关重要。此做法显著降低了网站将您的请求检测为自动化的可能性。
2. 实现IP轮换
依赖单个代理IP几乎与直接访问网站一样危险,因为它增加了您的IP被标记或阻止的可能性。实施IP轮换有助于避免检测并确保无缝访问以收集所需的Web数据。
3. 限制请求频率
速率限制是防止您的IP被标记的重要措施。在短时间内从同一IP快速发送多个请求可能会触发网站的反机器人保护,可能导致被禁止。通过在您的抓取代码中加入延迟,您可以最大限度地降低这些风险并保持平稳运行。
4. 错误处理
有效的错误处理对于成功的网络抓取至关重要。在您的代码中加入机制以处理目标网站未返回预期响应的情况,确保您的抓取过程保持强大和高效。
集成Scrapeless Web Unlocker以获得高级功能
为什么Scrapeless有效避免封锁?
Scrapeless Web Unlocker利用遍布195个国家的全球网络,并支持访问超过7000万个住宅IP。凭借99.9%的正常运行时间和卓越的成功率,Scrapeless轻松克服了IP封锁和CAPTCHA等挑战,使其成为复杂Web自动化和AI驱动数据收集的强大解决方案。
Scrapeless是否昂贵?
Scrapeless提供可靠且可扩展的网络抓取平台,价格具有竞争力,为用户带来极高的价值:
- 抓取浏览器: 每小时0.09美元起
- 抓取API: 每1k个URL 1.00美元起
- Web Unlocker: 每1k个URL 0.20美元起
- 验证码求解器: 每1k个URL 0.80美元起
- 代理: 每GB 2.80美元起
订阅后,您可以享受每项服务高达20%的折扣。您有特殊要求吗?立即联系我们,我们将根据您的需求提供更大的优惠!
将Scrapeless集成到您的项目的详细步骤
先决条件
在开始之前,您需要注册Scrapeless帐户。您还可以访问官方网站了解更多关于Scrapeless的信息。
注册后,导航到Scrapeless仪表板,然后单击左侧面板上的Web Unlocker菜单。在这里,您会找到各种配置选项,包括代理、JS渲染、请求方法和JS指令。这些功能解决了Node Unblocker的一些限制,您可以根据需要对其进行自定义。
如果您不熟悉这些配置选项,您可以参考详细文档,方法是单击页面上的“文档”链接。
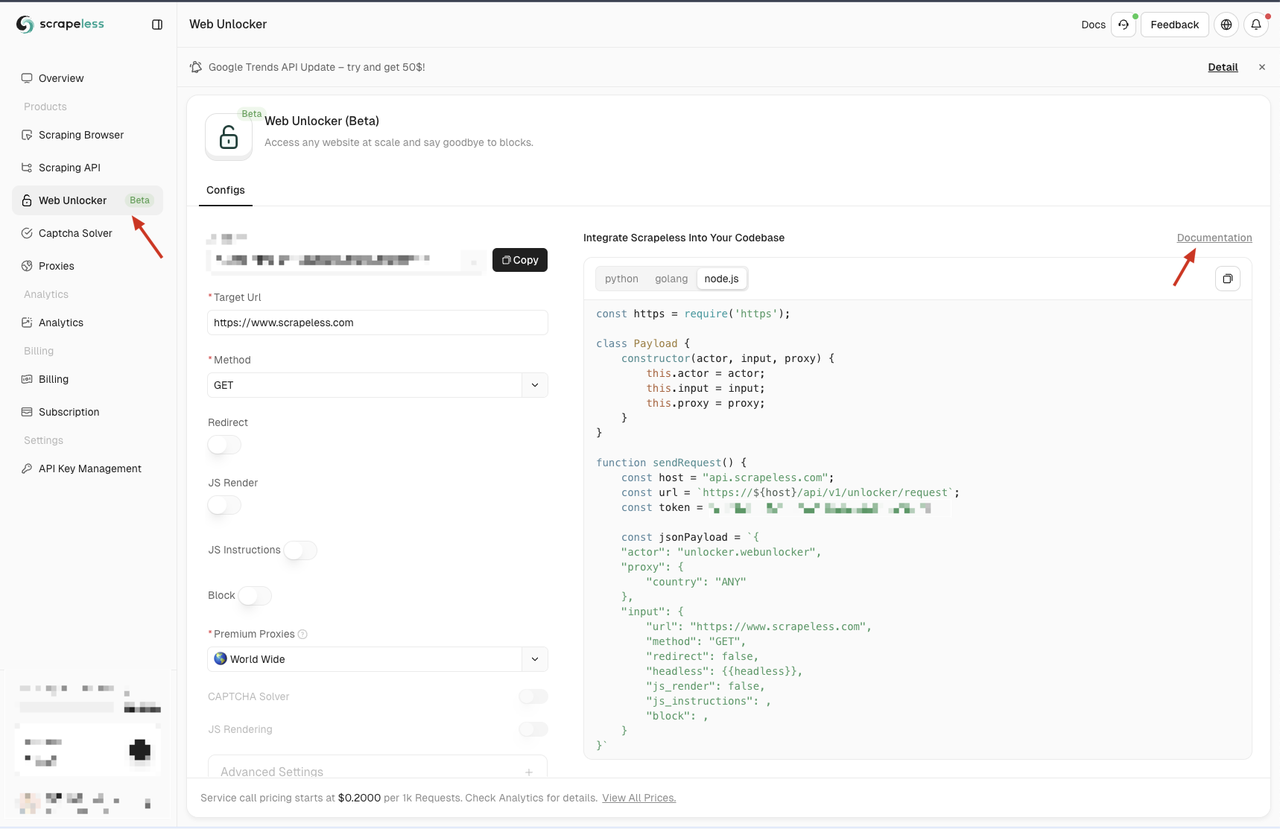
Scrapeless还提供三种编程语言的代码示例——Python、Node.js和Golang。您可以选择适合您集成需求的语言。在此示例中,我们将使用Node.js。
绕过验证码
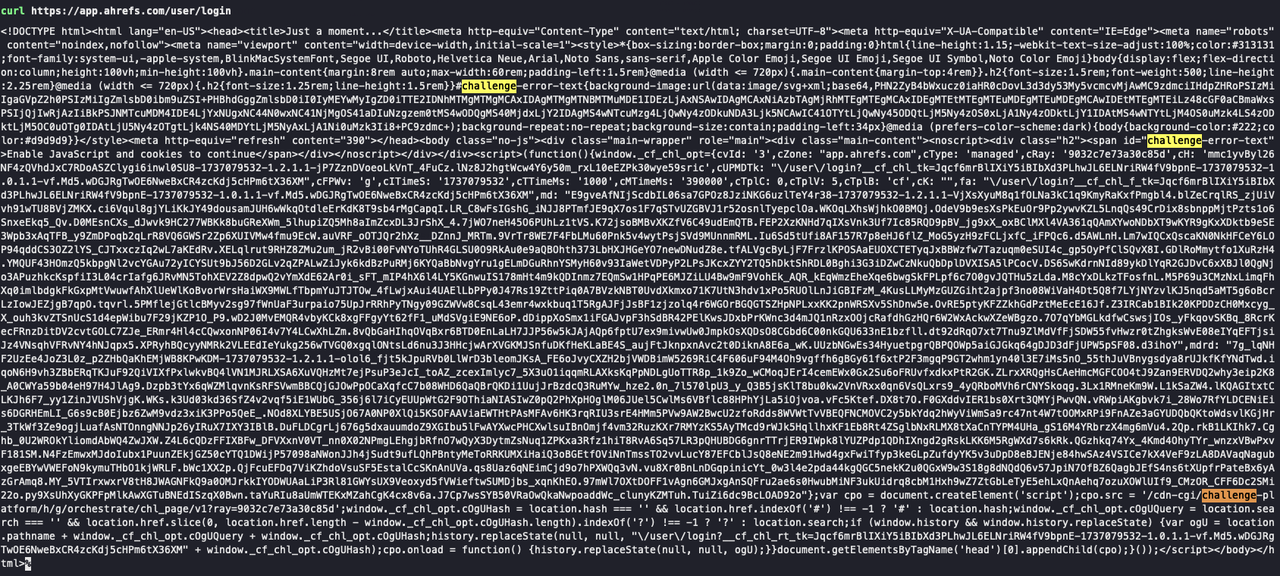
Scrapeless Web Unlocker自动启用CAPTCHA绕过功能,消除了对CAPTCHA挑战的担忧。要验证这一点,首先,使用Curl向需要验证的站点发出请求,例如:
Bash
curl https://app.ahrefs.com/user/login在下面的屏幕截图中,Curl请求返回一个CAPTCHA验证页面。您可以在响应中看到Cloudflare验证详细信息:
现在,使用Scrapeless Web Unlocker请求同一站点,请按照以下步骤操作:
- 创建一个scrapeless-web-unlocker.js文件,其中包含以下代码:
JavaScript
import fetch from 'node-fetch';
class Payload {
constructor(actor, input, proxy) {
this.actor = actor;
this.input = input;
this.proxy = proxy;
}
}
async function sendRequest() {
const host = 'api.scrapeless.com';
const url = `https://${host}/api/v1/unlocker/request`;
const token = ''; // your token
const inputData = {
url: 'https://app.ahrefs.com/user/login',
method: 'GET',
redirect: false,
};
const proxy = {
country: 'ANY',
};
const payload = new Payload('unlocker.webunlocker', inputData, proxy);
try {
const response = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-token': token,
},
body: JSON.stringify(payload),
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const body = await response.text();
console.log('body', body);
} catch (error) {
console.error('Error:', error);
}
}
sendRequest();- 使用
node scrapeless-web-unlocker.js运行代码。
我们可以看到,返回的结果中已成功绕过验证码验证,并且已获得页面的DOM内容。此外,页面代码中的标题“User login - Ahrefs”也可以在我们的结果中成功检索。
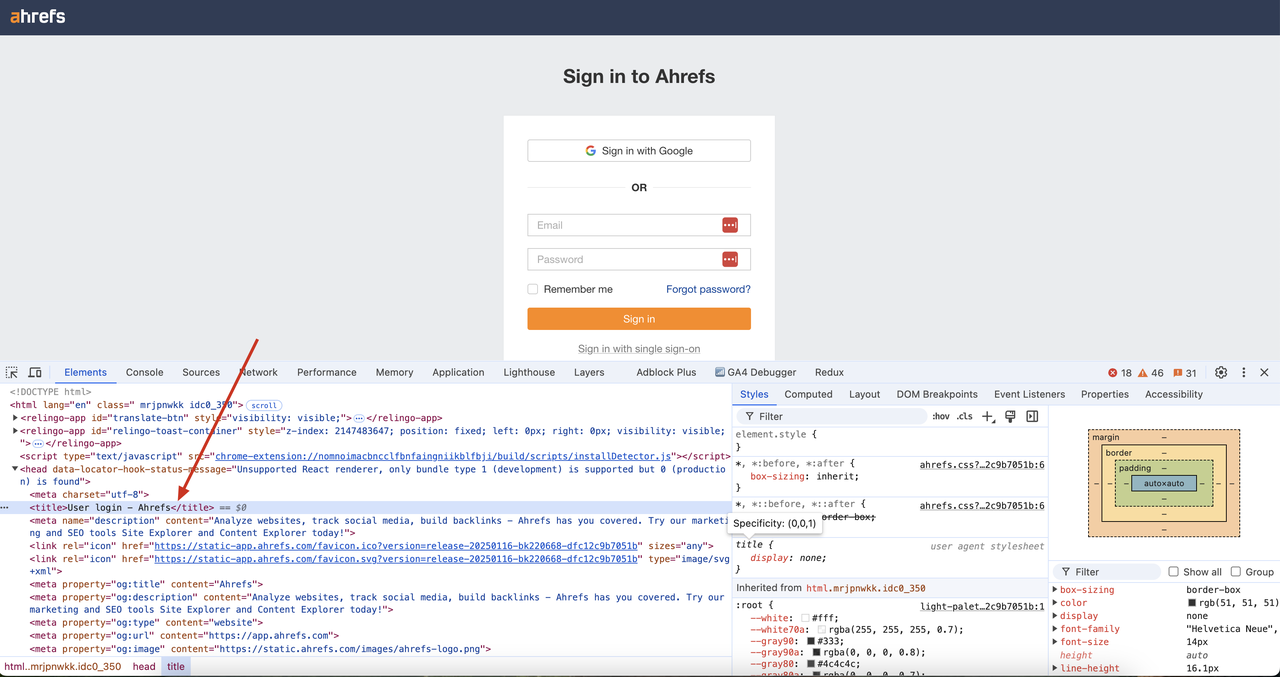

Javascript渲染
JavaScript渲染可以处理动态加载的内容和单页应用程序(SPA)。它支持完整的浏览器环境,并支持更复杂的页面交互和渲染需求。Scrapeless的Web Unlocker服务可以解决Node Unblocker无法执行JavaScript的问题。我们可以启用Scrapeless的Web Unlocker中的JavaScript渲染功能,以便我们可以获取由JavaScript渲染的页面内容。
我们可以找到一个使用JavaScript渲染的网站,例如Cloudflare的仪表板登录页面。我们可以看到它使用的框架技术是React.js,而React.js是一个单页应用程序框架,其内容由JavaScript渲染。
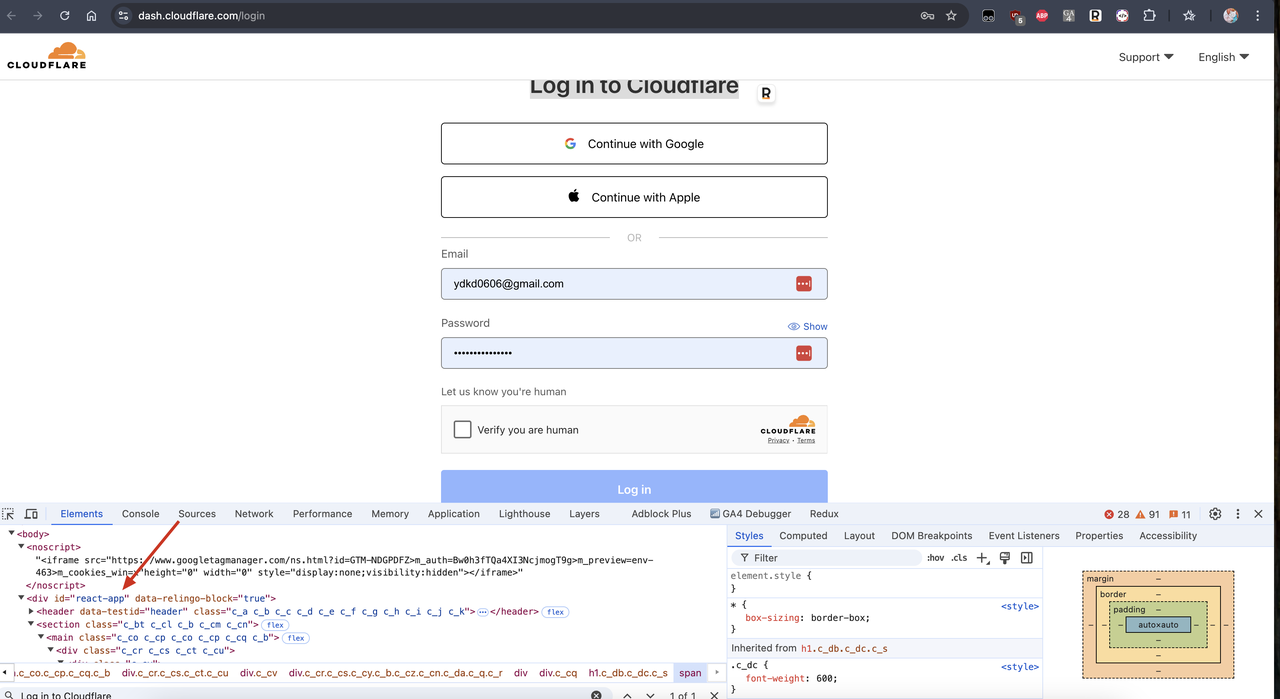
现在,让我们稍微修改之前的代码,看看我们是否可以在不启用JavaScript渲染的情况下获得Cloudflare仪表板登录页面的内容。修改代码如下:
JavaScript
...
url: 'https://dash.cloudflare.com/login',
...我们可以看到,返回结果中id="react-app"的div为空,这意味着我们没有在JavaScript渲染后获得页面内容:
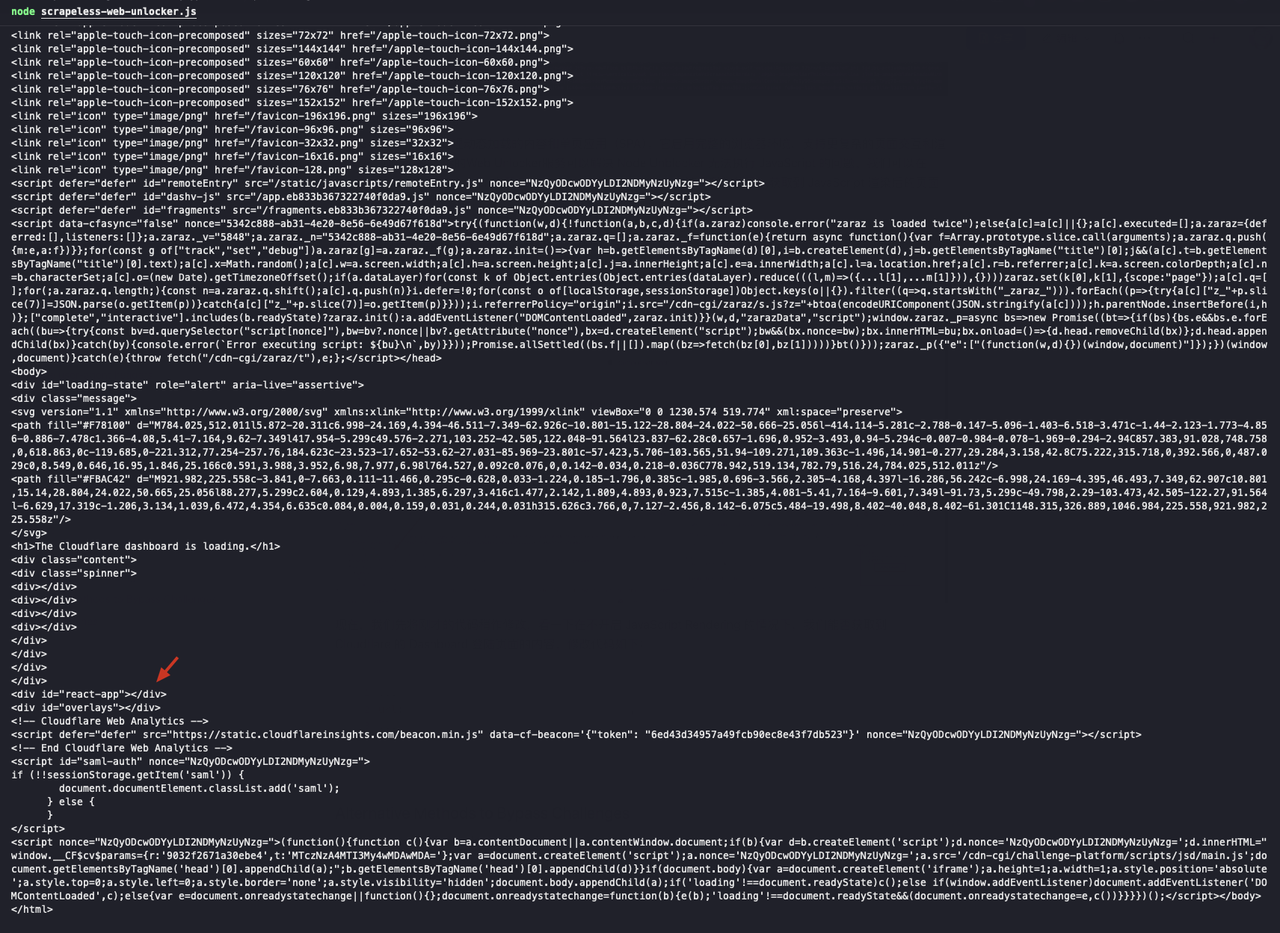
接下来,我们打开JavaScript渲染功能并修改代码如下:
JavaScript
const inputData = {
url: 'https://dash.cloudflare.com/login',
method: 'GET',
redirect: false,
js_render: true, // new option
js_instructions: [ // new option
{
wait: 20000,
},
],
};在上面的代码中,我们添加了两个新的配置选项,js_render和js_instructions。有关更多指令参考,请参考Scrapeless Docs:
js_render用于打开JavaScript渲染功能js_instructions用于设置JavaScript渲染的指令。在这里,我们设置了一个20秒的等待指令,以便在页面加载后返回结果。
注意: 现在许多网站都有默认的加载过程,因此我们需要等待一段时间以确保页面加载完毕后再返回结果
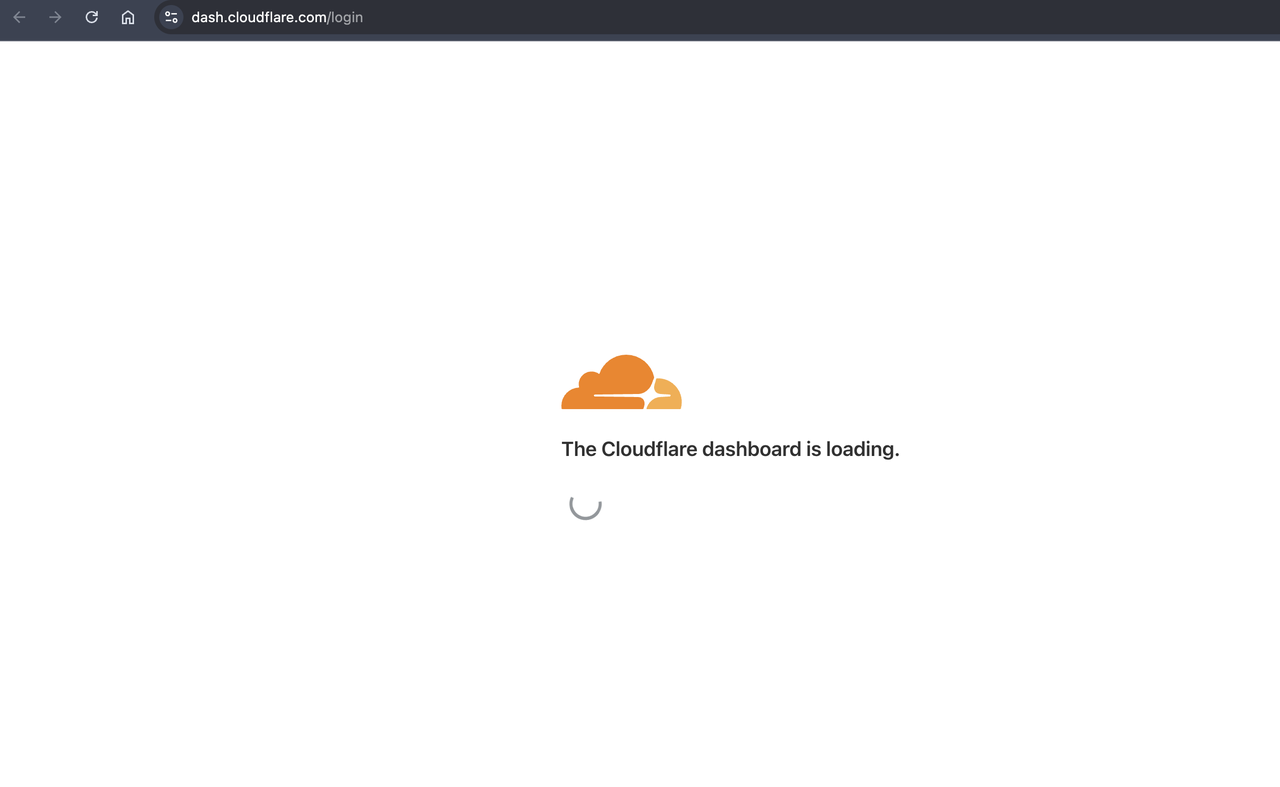
现在,我们再次运行代码,我们可以看到返回的结果中已成功获得Cloudflare仪表板登录页面的内容。通过检索“Log in to Cloudflare”的文本,我们可以看到我们已经成功获得了由JavaScript渲染的页面内容。
Bash
node scrapeless-web-unlocker.js
底线
访问Web内容的挑战日益增多,需要新的解决方案。在本文中,我们研究了Node Unblocker,这是一个NodeJS库,它提供一个处理数据并将其转发给客户端的Web代理。
但是,其局限性使其无法成为具有成本效益的网络抓取解决方案。因此,需要一个更高效且更便宜的解决方案。正如大家一致认为的那样——Scrapeless凭借其卓越的全方位服务和更低的价格,是明显的赢家。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


