
如何使用Scrapeless Scraping API抓取Naver产品?
Senior Web Scraping Engineer
随着在线购物的兴起,24%的零售销售额现在来自电子商务市场。到2025年,全球电子商务零售销售预计将达到$7.4万亿美元。
Naver,韩国最大的搜索引擎和科技巨头,是该国数字生活的核心。从电子商务和数字支付到网络漫画、博客和移动消息,它在多个领域捕获用户数据,超过任何其他平台。
Naver的架构旨在打破可预测的模式,检测不一致,并比大多数系统更快地适应。如果你的抓取策略依赖于静态脚本或蛮力代理,它已经过时。成功的Naver商店数据抓取不仅仅是绕过防御——它还需要协调会话行为、时间逻辑,并与平台期望对齐。
如何快速、大规模地以最小成本抓取Naver商店的产品数据?
本指南适用于面临现代Naver抓取挑战的商业团队、数据所有者和领导者!
💼 为什么要抓取Naver数据?
- 竞争定价策略:使用Naver购物数据抓取收集竞争对手的定价,使你能在市场中保持领先。
- 库存优化:实时监控库存水平,减少短缺,提高效率。
- 市场趋势分析:识别新兴趋势和消费者偏好,以调整你的产品。
- 增强产品列表:提取详细描述、图片和规格,以创建引人注目的列表。
- 价格监控与调整:跟踪价格变化和折扣,以优化促销。
- 竞争分析:分析竞争对手的产品供应、定价和促销,以超越他们。
- 数据驱动的营销:收集消费者行为洞察,以便进行有针对性的营销活动。
- 提高客户满意度:监控评论和评级,以完善产品并提升满意度。
💡 我们可以从Naver提取什么产品数据?
抓取价格、库存状态、描述、评论和折扣可以确保全面、最新的数据。一个强大的Naver抓取工具可以提取:
| 字段 | 字段 | 字段 |
|---|---|---|
| ✅ 产品名称 | ✅ 客户评级 | ✅ 促销 |
| ✅ 产品特性 | ✅ 描述 | ✅ 图片 |
| ✅ 评论 | ✅ 交货选项 | ✅ 类别 |
| ✅ 子类别 | ✅ 产品ID | ✅ 品牌 |
| ✅ 交货时间 | ✅ 退货政策 | ✅ 可用性 |
| ✅ 价格 | ✅ 卖家信息 | ✅ 到期日期 |
| ✅ 店铺位置 | ✅ 成分 | ✅ 折扣价 |
| ✅ 原价 | ✅ 套餐优惠 | ✅ 最后更新 |
| ✅ 库存单位(SKU) | ✅ 重量/体积 | ✅ 折扣百分比 |
| ✅ 单价 | ✅ 营养信息 |
⚠️ 抓取Naver产品信息的困难是什么?
在考虑如何从Naver抓取数据之前,每个公司都应首先考虑以下六个主要挑战:
1. 缺乏稳定的入境点或会话控制
匿名抓取是一个红旗。Naver要求用户行为的一致性。没有反映用户活动的会话模拟,你的行为会显得可疑、脆弱,并很快被丢弃。
2. JavaScript渲染挑战
JavaScript控制着Naver上的关键内容和响应时间。如果你的提取工具无法准确渲染JS或检测加载后的变化,你的数据将不完整、过时或不可见。忽视这一复杂性可能导致隐藏的失败,对决策者造成扭曲的洞察。
3. 会话验证、地理锁定和CAPTCHA升级
每一层自动化都带来风险!
- 如果一层失败,你的会话将过期。
- 如果两层失败,可能会引起怀疑。
- 如果三层失败,你将被标记并阻止。
如果没有稳健的会话模拟策略、旋转区域IP和自动处理用户面临的挑战(包括CAPTCHA),你的基础设施将变得如同纸牌屋。
4. Naver商店的布局变化和界面重设计
Naver的变化微妙、频繁且不可预测!昨天有效的方法今天可能无效。分页逻辑、标签移动或加载重构的变化可能会严重影响您的抓取工具。您的团队将面临不断的返工,系统必须能够检测、响应并自我修复——否则风险就是资源耗尽。
5. 速率限制和封锁
在抓取大规模数据时,请注意短时间内请求的数量和数据量。精明的数据提取专家总是关注页面操作、行为模拟和多样化的访问协议——这些都是高容量数据获取的基本配置。
6. 韩国的数据隐私和法律法规
一个盲点可能会导致数百万的损失!在不了解当地数据抓取要求和知识产权法的情况下,从海外抓取Naver数据会使您的公司面临声誉和法律风险。强烈建议在抓取之前进行彻底的研究。
🤔 为什么使用Scrapeless提取Naver产品数据?
Scrapeless采用先进的网络数据抓取技术,确保高质量、精确的数据提取,以满足各种商业需求——从市场分析和竞争定价策略到库存管理和消费者行为分析。我们的服务为零售商、电子商务平台和市场分析师提供无缝解决方案,帮助他们深入了解快速消费品(FMCG)市场。
通过我们的Naver抓取API,您可以轻松追踪市场趋势、优化定价策略,并在快速发展的杂货行业中保持竞争优势。相信我们为您提供可行的洞察,推动您的业务增长和创新。
主要特点
1️⃣ 超快且可靠:快速获取数据,而不影响稳定性。
2️⃣ 丰富的数据字段:包括产品详情、卖家信息、定价、评级等。
3️⃣ 智能代理轮换系统:自动切换代理IP,有效绕过基于IP的访问限制。
4️⃣ 先进的指纹技术:动态模拟浏览器特征和用户交互模式,以绕过复杂的反抓取机制。
5️⃣ 集成的CAPTCHA解决:自动处理reCAPTCHA和Cloudflare挑战,确保顺利的数据收集。
6️⃣ 自动化:全面自动化的抓取过程,快速响应更新。
⏯️ PLAN-A. 通过API提取Naver产品数据
- 只需配置商店ID和产品ID。
- Scrapeless Naver API将提取来自Naver Shop的详细产品数据,包括定价、卖家信息、评论等。
- 您可以下载并分析数据。
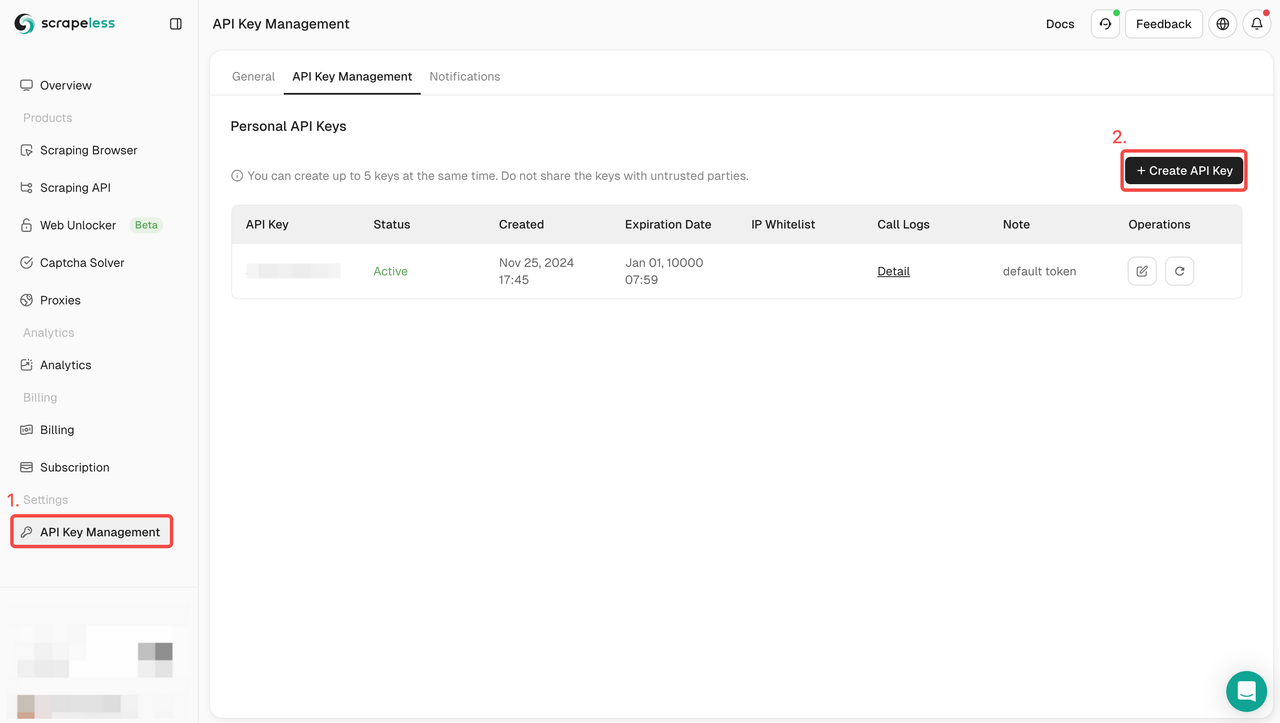
步骤1:创建您的API令牌
要开始使用,您需要从Scrapeless仪表板获取API密钥:
- 登录Scrapeless仪表板。
- 导航到API密钥管理。
- 点击创建以生成您的唯一API密钥。
- 创建后,您可以直接点击API密钥以复制它。
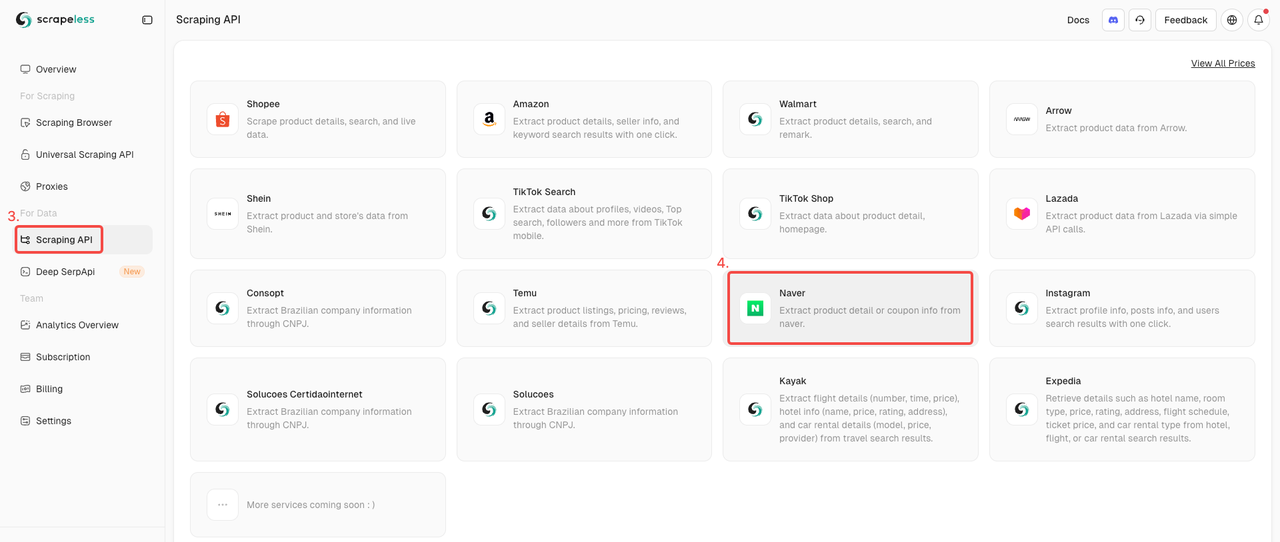
步骤2. 启动Naver商店API
- 在数据收集下找到抓取API。
- 只需点击Naver商店演员以准备抓取产品数据。
步骤3:定义您的目标
要使用Naver抓取API抓取产品数据,您必须提供两个必需参数:storeId和productId。channelUid参数是可选的。
您可以直接在产品URL中找到产品ID和商店ID。例如:
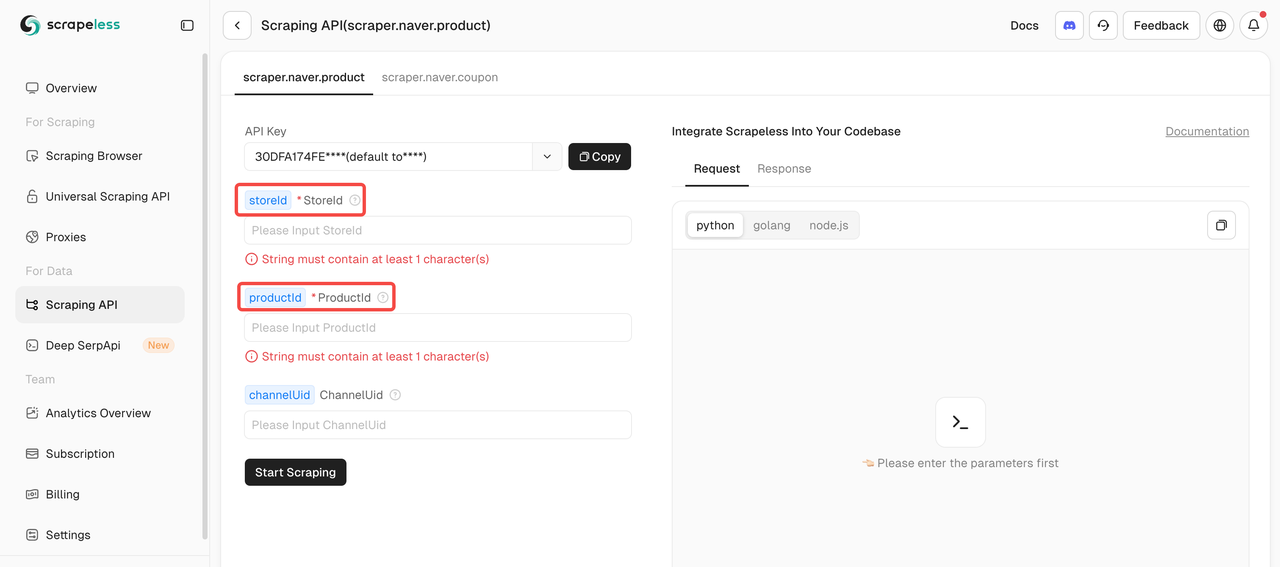
您可以直接在产品URL中找到产品ID和商店ID。以[바르닭] 닭가슴살 143종 크런치 소품닭 닭스테이크 소스큐브 골라담기 [원산지:국산(경기도 포천시) 등] 为例:
- 商店ID:barudak
- 产品ID:4469033180
我们严格保护网站的隐私。本文中的所有数据均为公开数据,仅用作抓取过程的演示。我们不保存任何信息和数据。
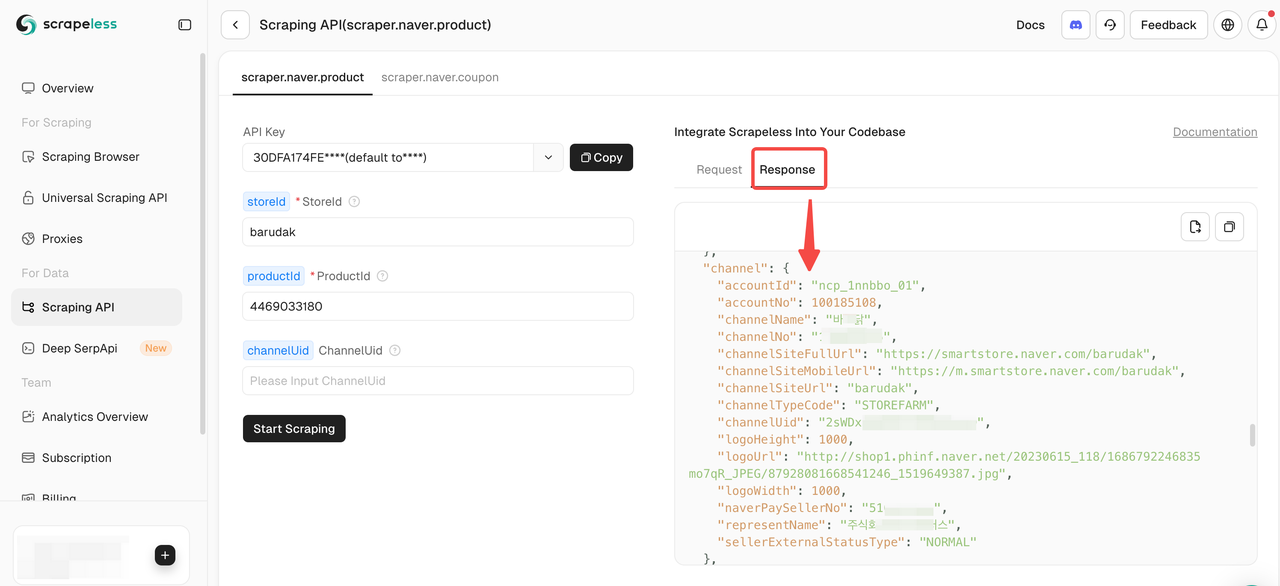
第4步:开始抓取Naver产品数据
一旦您填入了所需的参数,只需点击开始抓取即可获取全面的产品数据。
以下是提取Naver产品数据的示例代码片段。只需将YOUR_SCRAPELESS_API_TOKEN替换为您的实际API密钥:
Python
import json
import requests
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "YOUR_SCRAPELESS_API_TOKEN"
headers = {
"x-api-token": token
}
json_payload = json.dumps({
"actor": "scraper.naver.product",
"input": {
"storeId": "barudak",
"productId": "4469033180",
"channelUid": " " ## 可选
}
})
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("错误:", response.status_code, response.text)
return
print("内容", response.text)
if __name__ == "__main__":
send_request()⏯️ PLAN-B. 使用Scraping Browser提取Naver产品数据
如果您的团队更喜欢编程,Scrapeless的Scraping Browser是一个很好的选择。它封装了所有复杂操作,从动态网站简化了高效的大规模数据提取。它与Puppeteer和Playwright等流行工具无缝集成。
第一步:与Scrapeless Scraping Browser集成
进入Scraping Browser后,只需在左侧填写配置参数,即可自动生成抓取脚本。
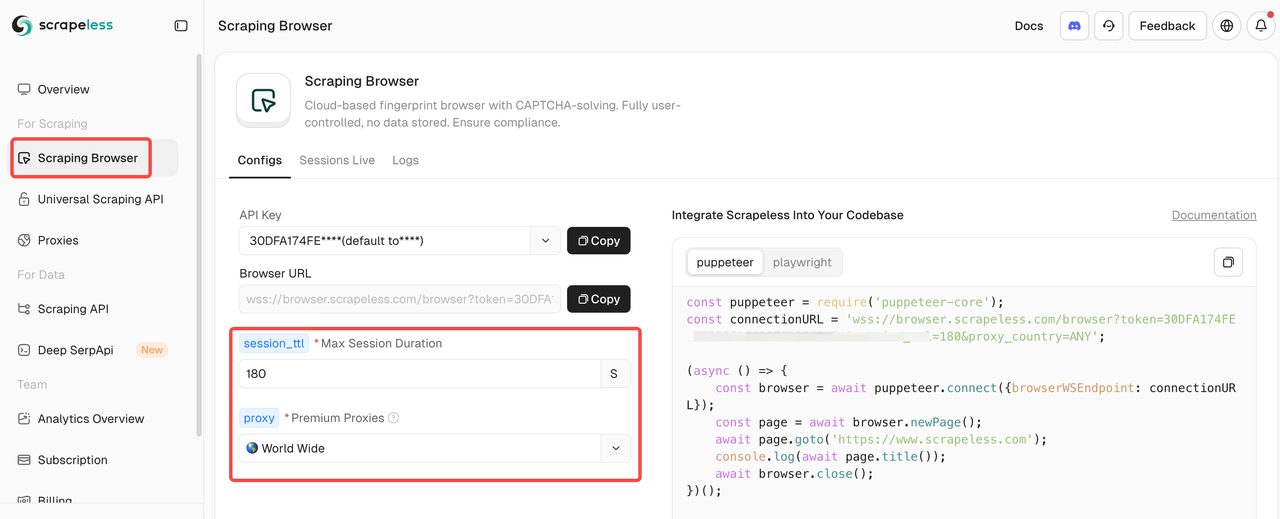
以下是示例集成代码(推荐使用JavaScript):
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=" YourAPIKey"&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Scrapeless会自动为您匹配代理,因此无需额外配置或处理CAPTCHA。结合代理轮换、浏览器指纹管理和强大的并发抓取能力,Scrapeless确保高效绕过IP阻塞和CAPTCHA挑战,从而进行大规模抓取Naver产品数据。
第二步:设置导出格式
现在,您需要过滤和清理抓取的数据。考虑以CSV格式导出结果以便于分析:
JavaScript
const csv = parse([productData]);
fs.writeFileSync('naver_product_data.csv', csv, 'utf-8');
console.log('CSV文件已保存:naver_product_data.csv');
await browser.close();
})();以下是我们的抓取脚本,供参考:
JavaScript
const puppeteer = require('puppeteer-core');
const fs = require('fs');
const { parse } = require('json2csv');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YourAPIKey&session_ttl=180&proxy_country=KR';
(async () => {
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL
});
const page = await browser.newPage();
// 替换为您实际想爬取的Naver产品页面的URL
const url = 'https://smartstore.naver.com/barudak/products/4469033180';
await page.goto(url, { waitUntil: 'networkidle2' });
// 简单示例:抓取产品标题、价格、描述等(根据实际页面结构进行调整)
const productData = await page.evaluate(() => {
const title = document.querySelector('h3._2Be85h')?.innerText || '';
const price = document.querySelector('span._1LY7DqCnwR')?.innerText || '';
const description = document.querySelector('div._2w4TxKo3Dx')?.innerText || '';
return {
title,
price,
description
};
});
console.log('产品数据:', productData);
// 导出为CSV
const csv = parse([productData]);
fs.writeFileSync('naver_product_data.csv', csv, 'utf-8');
console.log('CSV文件已保存:naver_product_data.csv');
await browser.close();
})();恭喜您,您已成功完成整个抓取Naver产品数据的过程!
结论
抓取Naver数据是一项战略性投资!然而,当团队使用编程进行抓取时,他们需要实施自适应系统,协调会话行为,并严格遵守平台规定和韩国数据法律。与Naver的动态架构竞争意味着需要配置代理、CAPTCHA求解器和模拟真实用户操作——这一切都是劳动密集型的任务。
实际上,我们不需要花费太多时间进行维护!为了实现这一点,只需利用强大的技术栈,包括浏览器自动化工具和API,以确保在任何规模下可扩展、合规的Naver产品数据提取,无需担心网页阻塞。
立即开始你的免费试用! 仅需3美元即可获得1000个请求,这是网络上最低的价格!
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


