
如何在 Make 上自动抓取数据?
Senior Web Scraping Engineer
我们最近推出了一个官方的Make集成,现在作为公共应用程序可用。本教程将向您展示如何创建一个强大的自动化工作流程,将我们的Google搜索API与Web解锁器结合起来,从搜索结果中提取数据,使用Claude AI处理这些数据,并将其发送到webhook。
我们将构建的内容
在本教程中,我们将创建一个工作流程:
- 使用集成调度每天自动触发
- 使用Scrapeless Google搜索API在Google上搜索特定查询
- 使用迭代器逐个处理每个URL
- 使用Scrapeless WebUnlocker抓取每个URL以提取内容
- 使用Anthropic Claude AI分析内容
- 将处理后的数据发送到webhook(Discord、Slack、数据库等)
先决条件
- 一个Make.com帐户
- 一个Scrapeless API密钥(请访问scrapeless.com获取一个)
- 一个Anthropic Claude API密钥
- 一个webhook端点(Discord webhook、Zapier、数据库端点等)
- 对Make.com工作流程的基本理解
完整工作流程概述
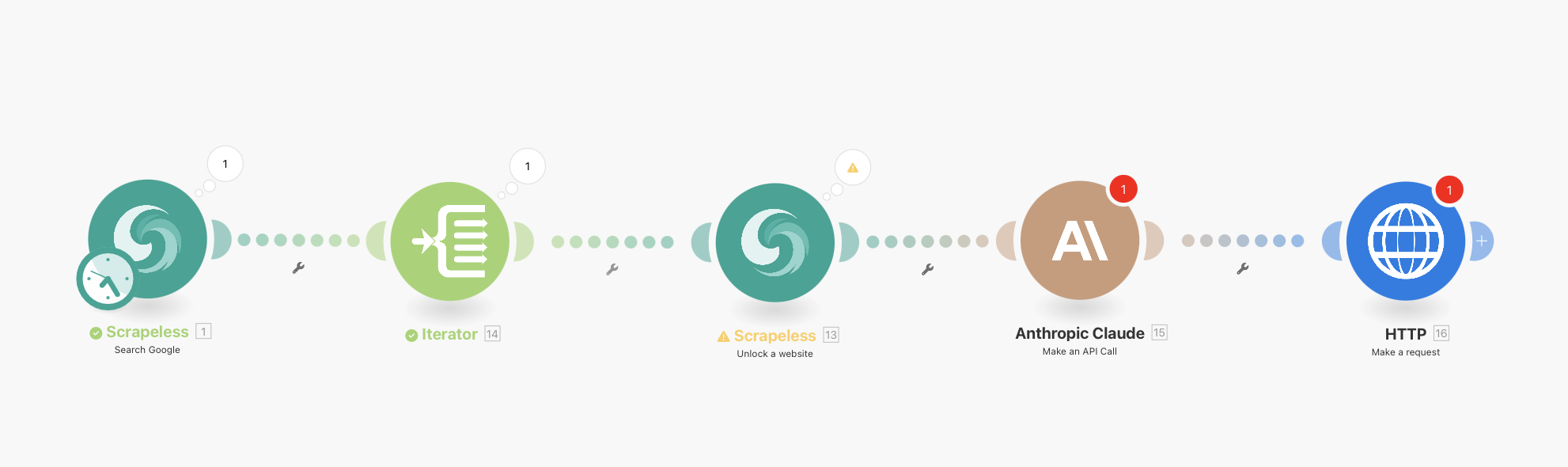
您的最终工作流程将如下所示:
Scrapeless Google搜索(带有集成调度)→ 迭代器 → Scrapeless WebUnlocker → Anthropic Claude → HTTP Webhook
第1步:添加带有集成调度的Scrapeless Google搜索
我们将首先添加带有内置调度的Scrapeless Google搜索模块。
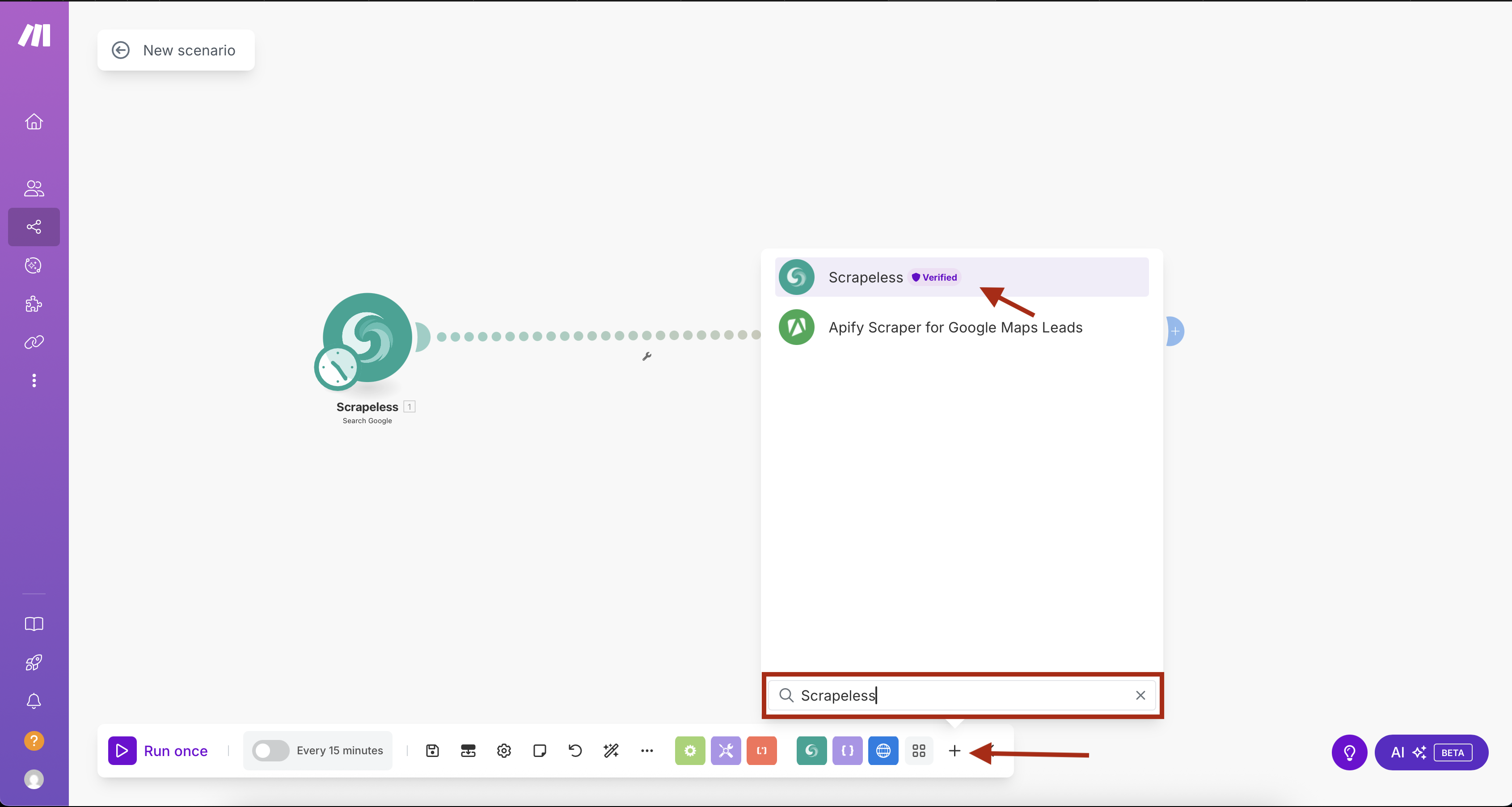
- 在Make.com中创建一个新场景
- 点击“+”按钮以添加第一个模块
- 在模块库中搜索“Scrapeless”
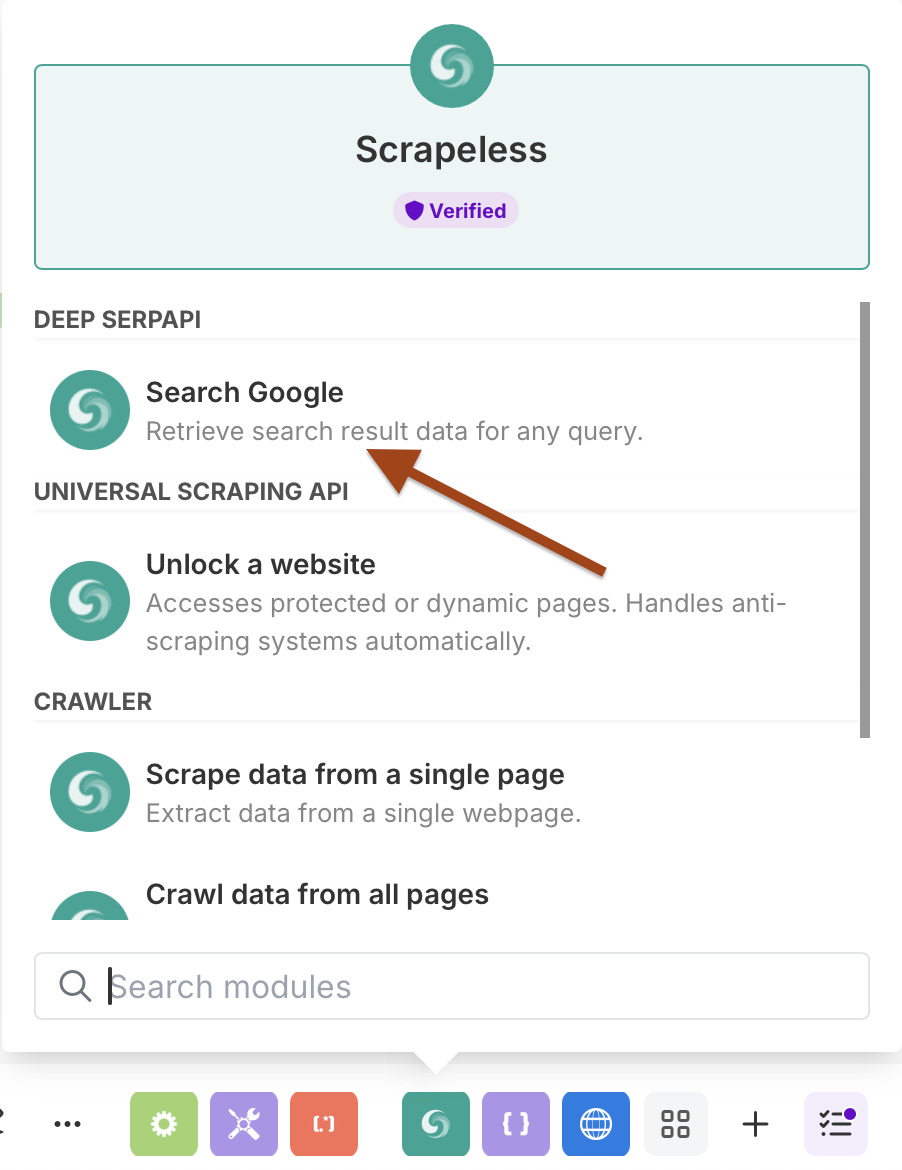
- 选择Scrapeless并选择Search Google操作
配置带有调度的Google搜索
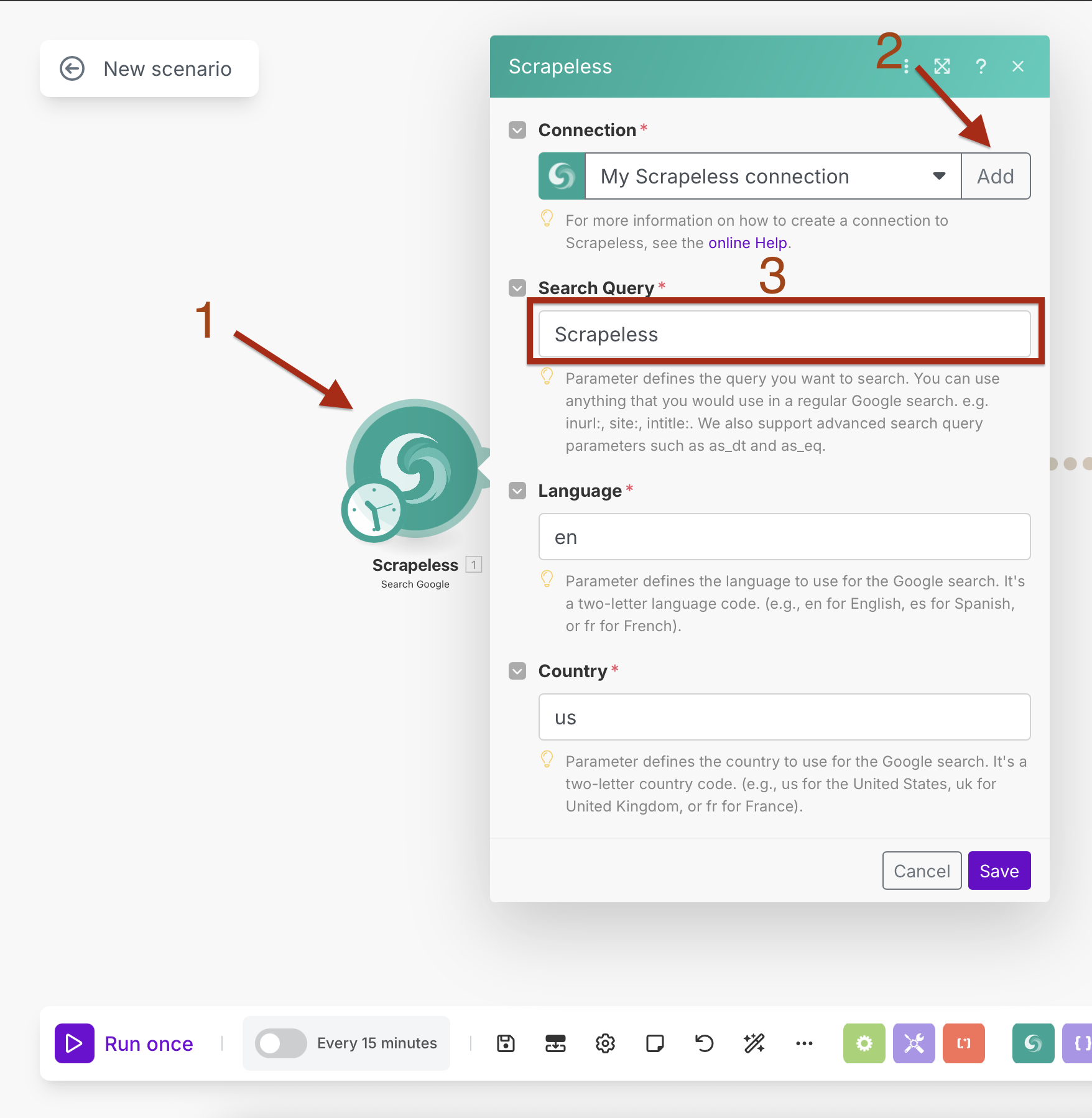
连接设置:
- 通过输入您的Scrapeless API密钥创建连接
- 点击“添加”并按照连接设置流程
搜索参数:
- 搜索查询:输入您的目标查询(例如,“人工智能新闻”)
- 语言:
en(英语) - 国家:
US(美国)
调度设置:
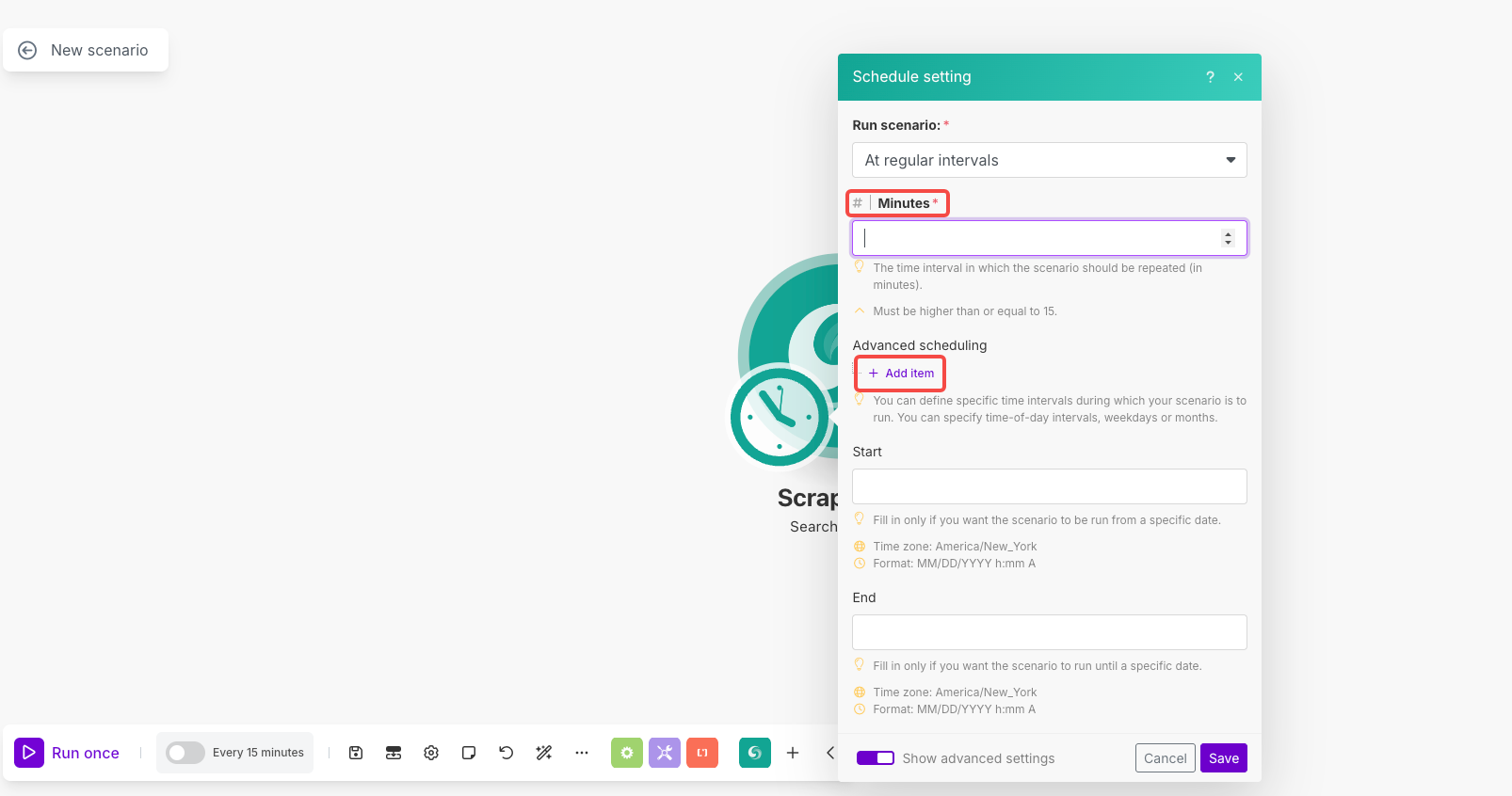
- 点击模块上的钟表图标以打开调度
- 运行场景:选择“定期间隔”
- 分钟:设置为
1440(每日执行)或您优选的间隔 - 高级调度:如有需要,使用“添加项目”设置特定的时间/天
第2步:使用迭代器处理结果
Google搜索返回一个包含多个URL的数组。我们将使用迭代器逐个处理每个结果。
- 在Google搜索之后添加一个迭代器模块
- 配置数组字段以处理搜索结果
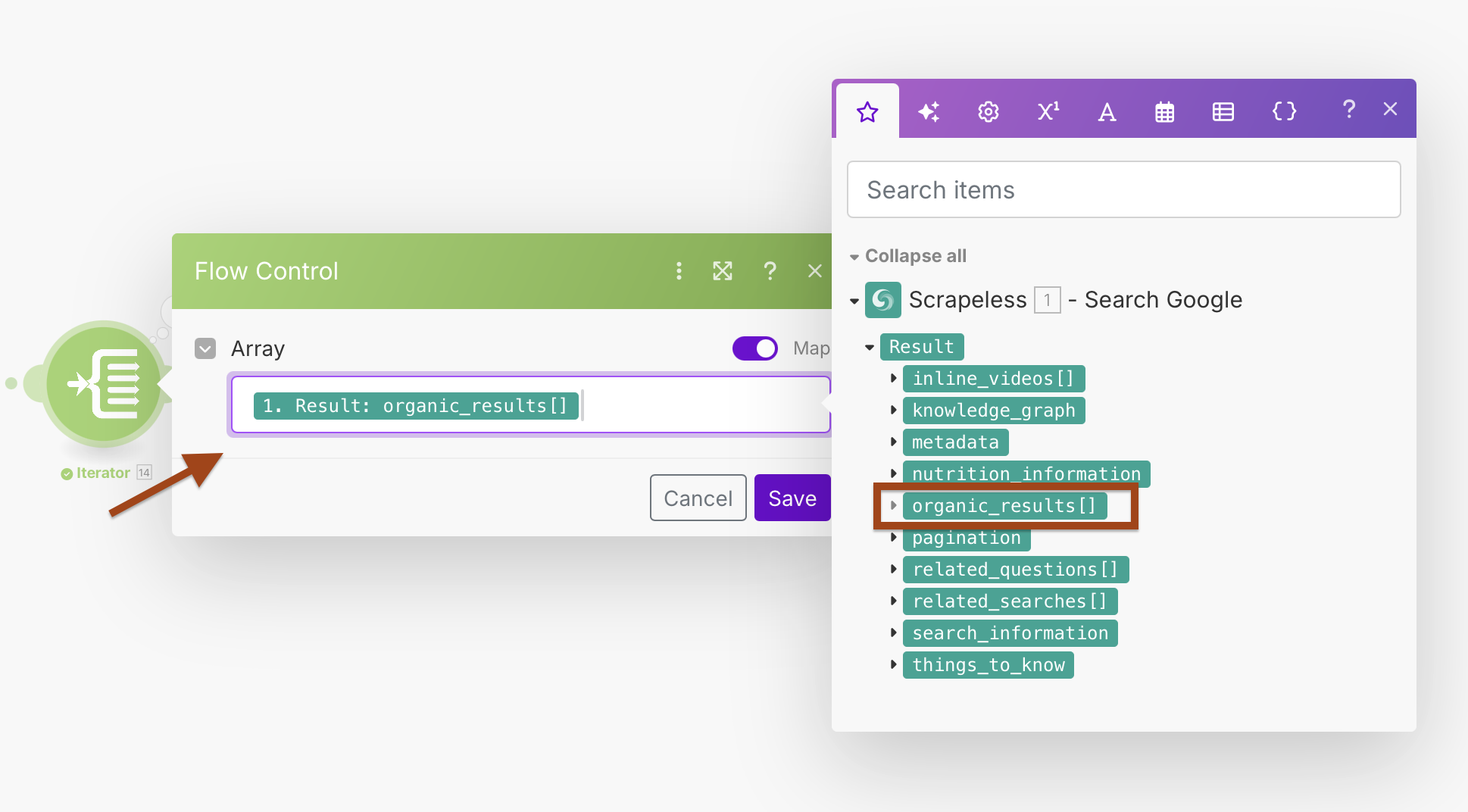
迭代器配置:
- 数组:
{{1.result.organic_results}}
这将创建一个循环,单独处理每个搜索结果,从而改善错误处理和单独处理。
第3步:添加Scrapeless WebUnlocker
现在我们将添加WebUnlocker模块以从每个URL抓取内容。
- 添加另一个Scrapeless模块
- 选择Scrape URL(WebUnlocker)操作
- 使用相同的Scrapeless连接
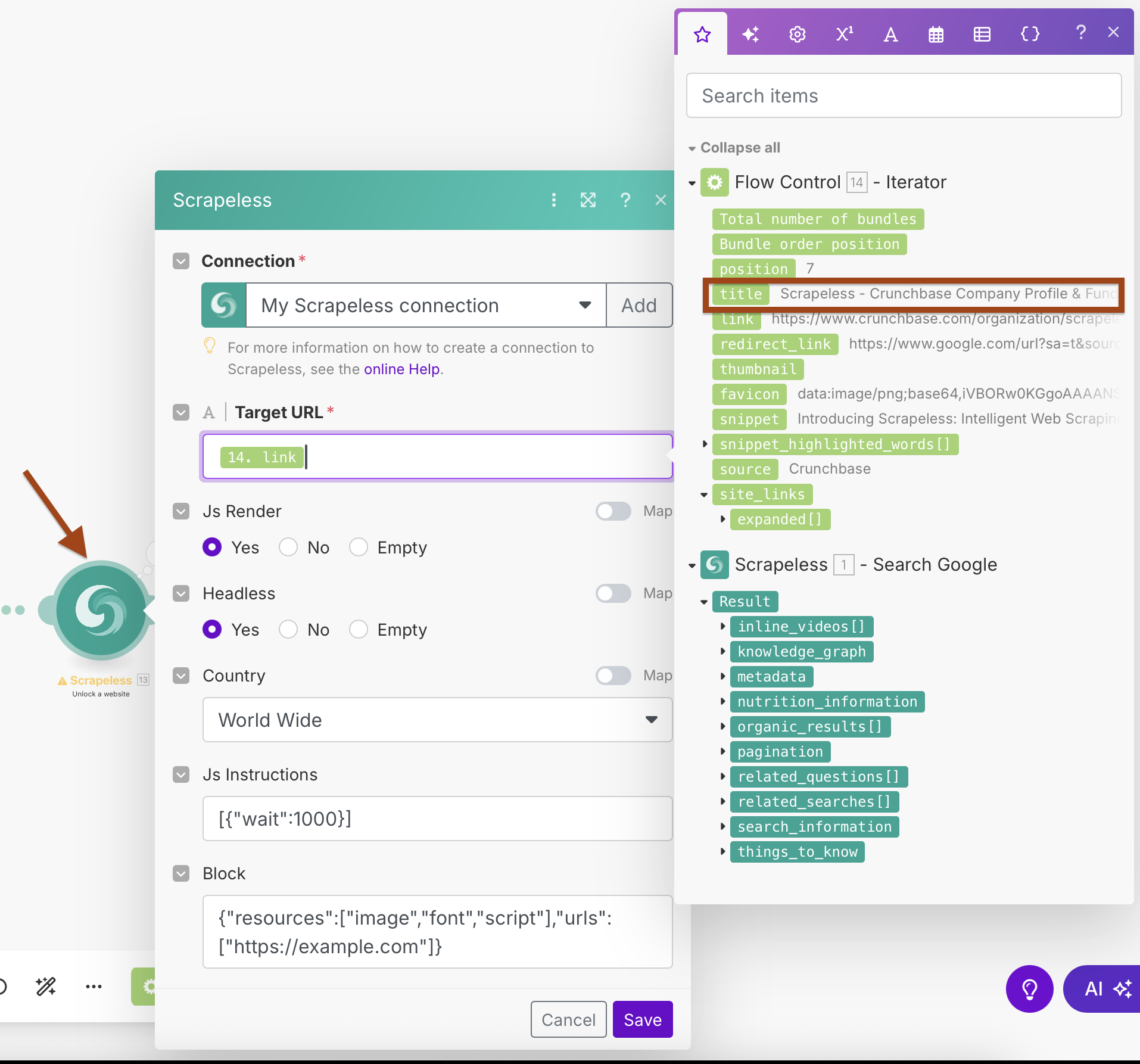
WebUnlocker配置:
- 连接:使用现有的Scrapeless连接
- 目标URL:
{{2.link}}(映射自迭代器输出) - Js渲染:是
- 无头:是
- 国家:全球
- Js指令:
[{"wait":1000}](等待页面加载) - 阻止:配置以阻止不必要的资源以加快抓取速度
第4步:使用Anthropic Claude进行AI处理
添加Claude AI以分析和总结抓取的内容。
- 添加一个Anthropic Claude模块
- 选择进行API调用操作
- 使用您的Claude API密钥创建一个新连接
Claude配置:
- 连接:使用您的Anthropic API密钥创建连接
- 提示:配置以分析抓取的内容
- 模型:claude-3-sonnet-20240229 / claude-3-opus-20240229 或您选择的模型
- 最大令牌数:根据您的需求为1000-4000
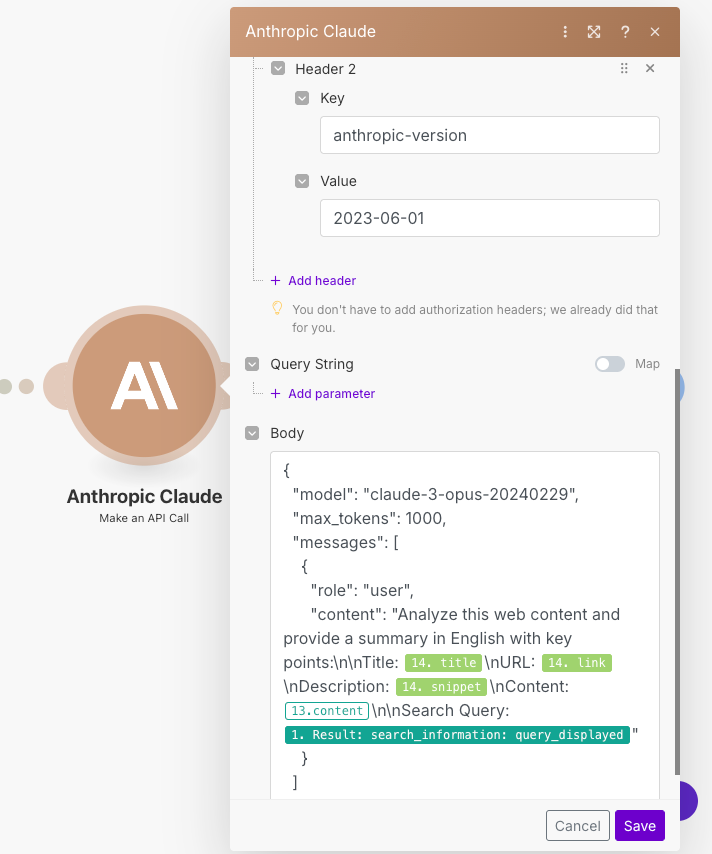
网址
/v1/messages标题 1
键 : Content-Type值 : application/json
标题 2
键 : anthropic-version值 : 2023-06-01
示例提示粘贴在主体中:
{
"model": "claude-3-sonnet-20240229",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": "分析此网络内容并用英文提供摘要,包括关键点:\n\n标题:{{14.title}}\n网址:{{14.link}}\n描述:{{14.snippet}}\n内容:{{13.content}}\n\n搜索查询:{{1.result.search_information.query_displayed}}"
}
]
}- 别忘了将数字
14替换为您的模块编号。
第 5 步:Webhook 集成
最后,将处理过的数据发送到您的 webhook 端点。
- 添加一个 HTTP 模块
- 配置它以发送 POST 请求到您的 webhook
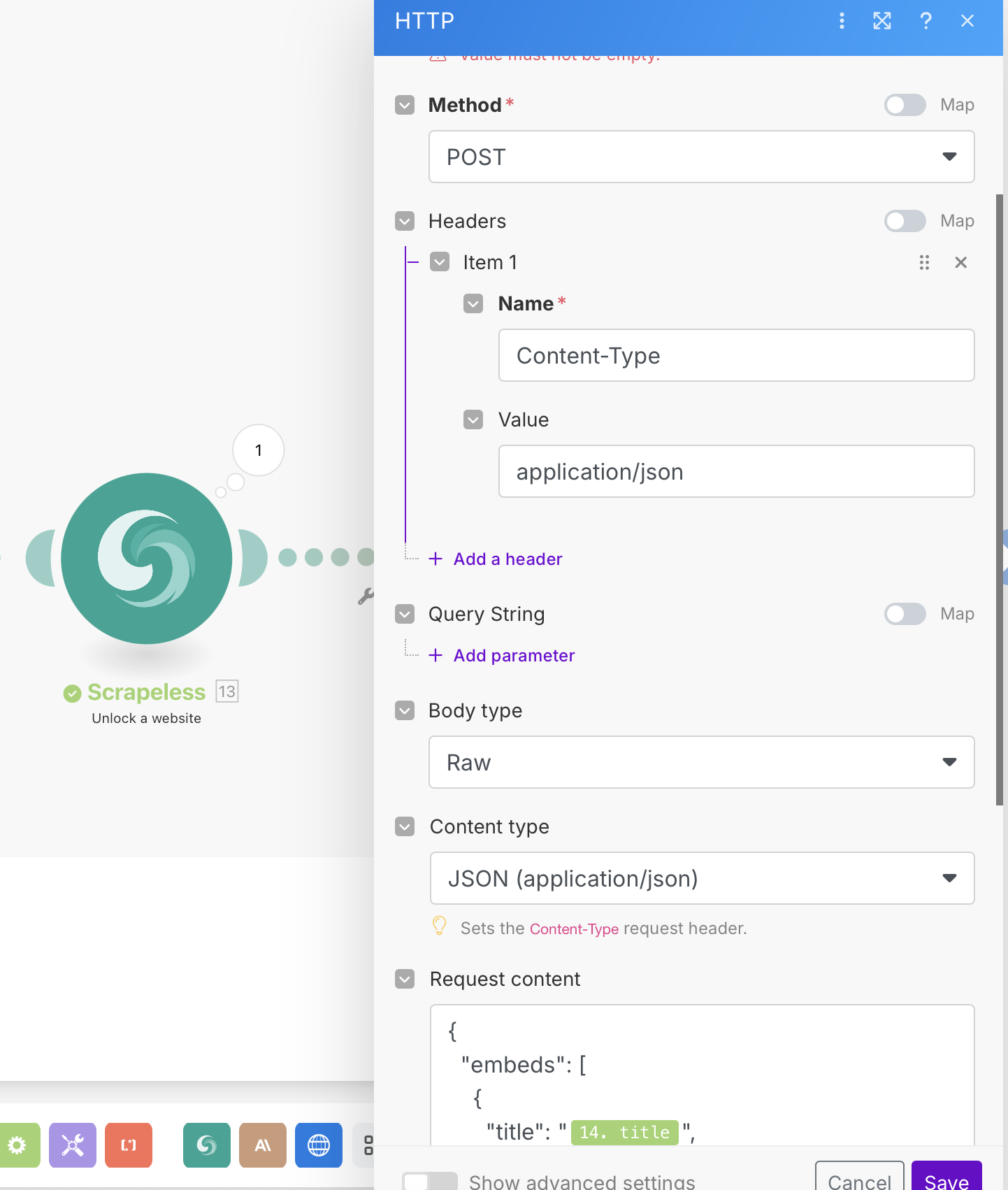
HTTP 配置:
- 网址:您的 webhook 端点(Discord,Slack,数据库等)
- 方法:POST
- 标头:
Content-Type: application/json - 主体类型:原始(JSON)
示例 Webhook 负载:
{
"embeds": [
{
"title": "{{14.title}}",
"description": "*{{15.body.content[0].text}}*",
"url": "{{14.link}}",
"color": 3447003,
"footer": {
"text": "分析完成"
}
}
]
}运行结果
模块参考和数据流
模块间的数据流:
- 模块 1(Scrapeless Google Search):返回
result.organic_results[] - 模块 14(迭代器):处理每个结果,输出单个项目
- 模块 13(WebUnlocker):抓取
{{14.link}},返回内容 - 模块 15(Claude AI):分析
{{13.content}},返回摘要 - 模块 16(HTTP Webhook):发送最终结构化数据
关键映射:
- 迭代器数组:
{{1.result.organic_results}} - WebUnlocker 网址:
{{14.link}} - Claude 内容:
{{13.content}} - Webhook 数据:所有前面模块的组合
测试您的工作流程
- 运行一次 来测试完整场景
- 检查每个模块:
- Google 搜索返回有机结果
- 迭代器单独处理每个结果
- WebUnlocker 成功抓取内容
- Claude 提供有意义的分析
- Webhook 接收结构化数据
- 验证数据质量 在您的 webhook 目标
- 检查调度 - 确保按您的优选间隔运行
高级配置提示
错误处理
- 在每个模块后添加 错误处理 路由
- 使用 过滤器 跳过无效的网址或空内容
- 设置 重试 逻辑以应对临时故障
此工作流程的好处
- 完全自动化:无需人工干预,每天运行
- AI 增强:内容自动分析和总结
- 灵活输出:Webhook 可与任何系统集成
- 可扩展:高效处理多个网址
- 质量控制:多重过滤和验证步骤
- 实时通知:立即交付至您的优选平台
使用案例
非常适用于:
- 内容监控:跟踪品牌或竞争对手的提及
- 新闻聚合:自动生成特定主题的新闻摘要
- 市场研究:监控行业趋势和动态
- 潜在客户生成:查找和分析潜在商机
- SEO 监控:跟踪目标关键字的搜索结果变化
- 研究自动化:收集和总结学术或行业内容
结论
此自动化工作流程结合了 Scrapeless 的 Google 搜索 和 WebUnlocker 的强大功能,以及 Claude AI 的分析能力,所有这些都通过 Make 的可视化界面进行编排。最终结果是一个智能内容发现系统,能够自动运行并通过 webhook 将丰富、经过分析的数据直接交付给您首选的平台。
该工作流程将按您的日程运行,自动发现、抓取、分析并提供相关内容洞察,完全无需人工干预。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


