
如何使用Scrapeless和Google Gemini构建智能搜索分析
Advanced Data Extraction Specialist
在本教程中,我们将通过结合Scrapeless的网络抓取能力和Google Gemini的AI分析来构建一个强大的搜索分析系统。您将学习如何提取Google搜索数据并自动生成可操作的洞察。
先决条件
- Python 3.8+
- Scrapeless API密钥
- Google Gemini API密钥
- 基本的Python知识
第一步:设置环境
1. 创建Python虚拟环境
在安装软件包之前,建议创建一个虚拟环境来隔离您的项目依赖项:
在Windows上:
# 创建虚拟环境
python -m venv scrapeless-gemini-env
# 激活环境
scrapeless-gemini-env\Scripts\activate在macOS上:
# 创建虚拟环境
python3 -m venv scrapeless-gemini-env
# 激活环境
source scrapeless-gemini-env/bin/activate在Linux上:
# 创建虚拟环境
python3 -m venv scrapeless-gemini-env
# 激活环境
source scrapeless-gemini-env/bin/activate注意: 当虚拟环境激活时,您将在终端提示符中看到(scrapeless-gemini-env)。
2. 安装必需的包
一旦您的虚拟环境被激活,安装所需的包:
pip install requests google-generativeai python-dotenv pandas3. 环境配置
在您的项目目录中创建一个.env文件以存储您的API密钥:
SCRAPELESS_API_TOKEN=your_token_here
GEMINI_API_KEY=your_gemini_key_here4. 获取API密钥
对于Gemini API密钥:(AIzaSyBGhCVNdBsVVHlRNLEPEADGVQeKmDvDEfI)
访问Google AI Studio生成您的免费Gemini API密钥。只需用您的Google帐户登录并创建一个新的API密钥。
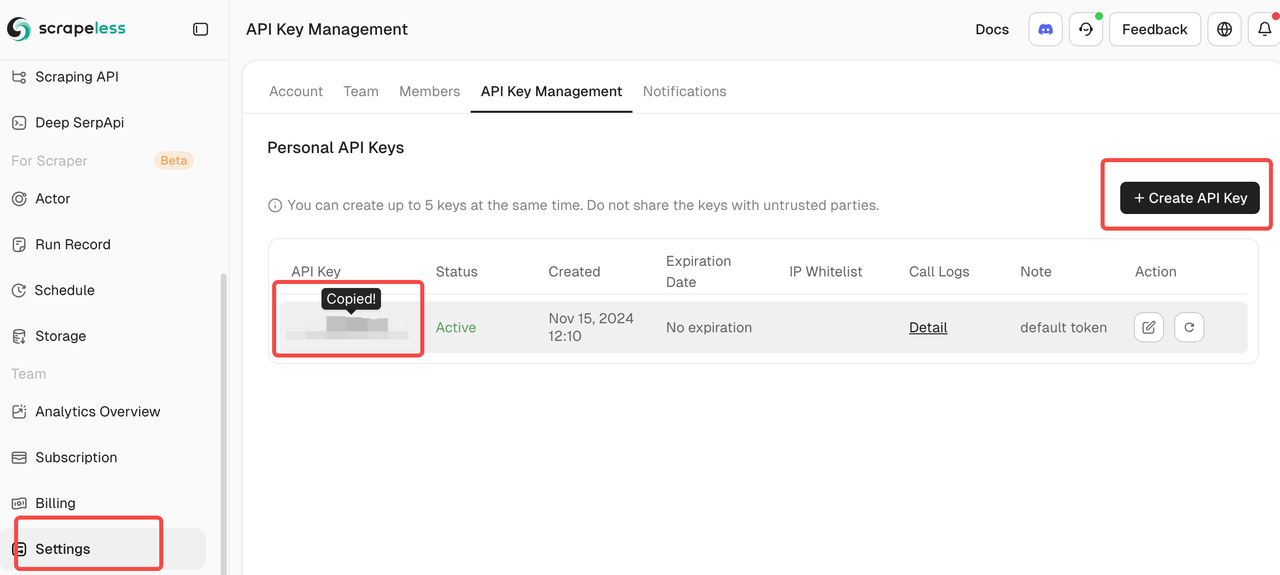
对于Scrapeless API令牌:
在Scrapeless注册以获取您的API令牌。该平台提供了慷慨的免费层,非常适合开始进行SERP数据收集。
第二步:创建Scrapeless客户端
让我们构建一个简单的客户端,以与Scrapeless的Google搜索API进行交互:
import json
import requests
import os
from dotenv import load_dotenv
load_dotenv()
class ScrapelessClient:
def __init__(self):
self.token = os.getenv('SCRAPELESS_API_TOKEN')
self.host = "api.scrapeless.com"
self.url = f"https://{self.host}/api/v1/scraper/request"
self.headers = {"x-api-token": self.token}
def search_google(self, query, **kwargs):
"""使用Scrapeless执行Google搜索"""
payload = {
"actor": "scraper.google.search",
"input": {
"q": query,
"gl": kwargs.get("gl", "us"),
"hl": kwargs.get("hl", "en"),
"google_domain": kwargs.get("google_domain", "google.com"),
"location": kwargs.get("location", ""),
"tbs": kwargs.get("tbs", ""),
"start": str(kwargs.get("start", 0)),
"num": str(kwargs.get("num", 10))
}
}
response = requests.post(
self.url,
headers=self.headers,
data=json.dumps(payload)
)
if response.status_code != 200:
print(f"错误: {response.status_code} - {response.text}")
return None
return response.json()第三步:整合Google Gemini进行分析
现在让我们为搜索结果添加AI驱动的分析:
import google.generativeai as genai
class SearchAnalyzer:
def __init__(self):
genai.configure(api_key=os.getenv('GEMINI_API_KEY'))
self.model = genai.GenerativeModel('gemini-1.5-flash')
self.scraper = ScrapelessClient()
def analyze_topic(self, topic):
"""搜索并分析主题"""
# 第一步:获取搜索结果
print(f"搜索: {topic}")
search_results = self.scraper.search_google(topic, num=20)
if not search_results:
return None
# 第二步:提取关键信息
extracted_data = self._extract_results(search_results)
# 第三步:使用Gemini进行分析
prompt = f"""
分析关于"{topic}"的搜索结果:
{json.dumps(extracted_data, indent=2)}
提供:
1. 关键主题和趋势
2. 主要信息来源
3. 显著洞察
4. 推荐的行动
将您的响应格式化为清晰、可操作的报告。
"""
response = self.model.generate_content(prompt)
return {
"topic": topic,
"search_data": extracted_data,
"analysis": response.text
}
```python
def _extract_results(self, search_data):
"""从搜索结果中提取相关数据"""
results = []
if "organic_results" in search_data:
for item in search_data["organic_results"][:10]:
results.append({
"title": item.get("title", ""),
"snippet": item.get("snippet", ""),
"link": item.get("link", ""),
"source": item.get("displayed_link", "")
})
return results第4步:构建实际用例
用例1:竞争对手分析
重要提示:在运行竞争对手分析之前,请确保用您实际的公司和竞争对手替换下面代码中的示例公司名称。
class CompetitorMonitor:
def __init__(self):
self.analyzer = SearchAnalyzer()
def analyze_competitors(self, company_name, competitors):
"""分析一家公司与其竞争对手的情况"""
all_data = {}
# 搜索每家公司
for comp in [company_name] + competitors:
print(f"\n分析: {comp}")
# 搜索最新的新闻和更新
news_query = f"{comp} 最新新闻更新 2025"
data = self.analyzer.analyze_topic(news_query)
if data:
all_data[comp] = data
# 生成比较分析
comparative_prompt = f"""
基于以下数据比较 {company_name} 与竞争对手:
{json.dumps(all_data, indent=2)}
提供:
1. 竞争定位
2. 每家公司的独特优势
3. 市场机会
4. {company_name} 的战略建议
"""
response = self.analyzer.model.generate_content(comparative_prompt)
return {
"company": company_name,
"competitors": competitors,
"analysis": response.text,
"raw_data": all_data
}用例2:趋势监测
class TrendMonitor:
def __init__(self):
self.analyzer = SearchAnalyzer()
self.scraper = ScrapelessClient()
def monitor_trend(self, keyword, time_range="d"):
"""监测某一关键词的趋势"""
# 将时间范围映射到Google的tbs参数
time_map = {
"h": "qdr:h", # 过去一小时
"d": "qdr:d", # 过去一天
"w": "qdr:w", # 过去一周
"m": "qdr:m" # 过去一个月
}
# 使用时间过滤进行搜索
results = self.scraper.search_google(
keyword,
tbs=time_map.get(time_range, "qdr:d"),
num=30
)
if not results:
return None
# 分析趋势
prompt = f"""
基于最近的搜索结果分析 "{keyword}" 的趋势:
{json.dumps(results.get("organic_results", [])[:15], indent=2)}
确定:
1. 新兴模式
2. 关键发展
3. 情感(正面/负面/中立)
4. 未来预测
5. 可操作的见解
"""
response = self.analyzer.model.generate_content(prompt)
return {
"keyword": keyword,
"time_range": time_range,
"analysis": response.text,
"result_count": len(results.get("organic_results", []))
}第5步:创建主应用程序
def main():
# 初始化组件
competitor_monitor = CompetitorMonitor()
trend_monitor = TrendMonitor()
# 示例1:竞争对手分析
# 重要提示:用您的实际公司和竞争对手替换这些示例公司
print("=== 竞争对手分析 ===")
analysis = competitor_monitor.analyze_competitors(
company_name="OpenAI", # 用您的公司名称替换
competitors=["Anthropic", "Google AI", "Meta AI"] # 用您的竞争对手替换
)
print("\n竞争分析结果:")
print(analysis["analysis"])
# 保存结果
with open("competitor_analysis.json", "w") as f:
json.dump(analysis, f, indent=2)
# 示例2:趋势监测
# 重要提示:用您行业的特定术语替换关键词
print("\n\n=== 趋势监测 ===")
trends = trend_monitor.monitor_trend(
keyword="人工智能监管", # 用您的关键词替换
time_range="w" # 过去一周
)
print("\n趋势分析结果:")
print(trends["analysis"])
# 示例3:多主题分析
# 重要提示:用您行业的特定主题替换这些主题
print("\n\n=== 多主题分析 ===")
topics = [
"生成式AI商业应用", # 用您的主题替换
"AI网络安全威胁","机器学习医疗保健"
如果没有搜索结果:
返回 None
# 第 2 步:提取关键信息
提取的数据 = self._extract_results(search_results)
# 第 3 步:与 Gemini 进行分析
提示 = f"""
分析关于“{topic}”的搜索结果:
{json.dumps(extracted_data, indent=2)}
提供:
1. 关键主题和趋势
2. 主要信息来源
3. 显著的见解
4. 建议的行动
将您的回复格式化为清晰、可操作的报告。
"""
响应 = self.model.generate_content(提示)
返回 {
"topic": topic,
"search_data": 提取的数据,
"analysis": 响应.text
}
def _extract_results(self, search_data):
"""从搜索结果中提取相关数据"""
结果 = []
如果 "organic_results" 在搜索数据中:
对于搜索数据["organic_results"][:10] 中的每个项目:
结果.append({
"title": item.get("title", ""),
"snippet": item.get("snippet", ""),
"link": item.get("link", ""),
"source": item.get("displayed_link", "")
})
返回 结果类 CompetitorMonitor:
def init(self):
self.analyzer = SearchAnalyzer()
def analyze_competitors(self, company_name, competitors):
"""分析公司与其竞争对手"""
所有数据 = {}
# 搜索每个公司
对于 [company_name] + competitors 中的竞争对手:
打印(f"\n分析:{comp}")
# 搜索最新新闻和更新
news_query = f"{comp} 最新新闻更新 2025"
数据 = self.analyzer.analyze_topic(news_query)
如果 数据:
所有数据[comp] = 数据
# 请求之间添加延迟
time.sleep(2)
# 生成比较分析
比较提示 = f"""
基于这些数据比较 {company_name} 和竞争对手:
{json.dumps(all_data, indent=2)}
提供:
1. 竞争定位
2. 每个公司的独特优势
3. 市场机会
4. 针对 {company_name} 的战略建议
"""
响应 = self.analyzer.model.generate_content(比较提示)
返回 {
"company": company_name,
"competitors": competitors,
"analysis": 响应.text,
"raw_data": 所有数据
}类 TrendMonitor:
def init(self):
self.analyzer = SearchAnalyzer()
self.scraper = ScrapelessClient()
def monitor_trend(self, keyword, time_range="d"):
"""监控关键词的趋势"""
# 将时间范围映射到 Google 的 tbs 参数
时间映射 = {
"h": "qdr:h", # 最近一小时
"d": "qdr:d", # 最近一天
"w": "qdr:w", # 最近一周
"m": "qdr:m" # 最近一个月
}
# 使用时间过滤器进行搜索
结果 = self.scraper.search_google(
keyword,
tbs=时间映射.get(time_range, "qdr:d"),
num=30
)
如果没有结果:
返回 None
# 分析趋势
提示 = f"""
基于最近的搜索结果分析“{keyword}”的趋势:
{json.dumps(results.get("organic_results", [])[:15], indent=2)}
确定:
1. 新兴模式
2. 关键发展
3. 情绪(积极/消极/中立)
4. 未来预测
5. 可操作的见解
"""
响应 = self.analyzer.model.generate_content(提示)
返回 {
"keyword": keyword,
"time_range": time_range,
"analysis": 响应.text,
"result_count": len(results.get("organic_results", []))
}类 DataExporter:
@staticmethod
def export_to_csv(data, filename=None):
"""将搜索结果导出到 CSV"""
如果 filename 是 None:
filename = f"search_results_{datetime.now().strftime('%Y%m%d_%H%M%S')}.csv"
# 扁平化数据结构
行 = []
对于 数据中的每个项目:
如果 isinstance(item, dict) 且 "search_data" 在 item 中:
对于 item["search_data"] 中的每个结果:
行.append({
"topic": item.get("topic", ""),
"title": result.get("title", ""),
"snippet": result.get("snippet", ""),
"link": result.get("link", ""),
"source": result.get("source", "")
})
df = pd.DataFrame(行)
zh
df.to_csv(filename, index=False)
print(f"数据导出到 {filename}")
return filename
@staticmethod
def create_html_report(analysis_data, filename="report.html"):
"""根据分析数据创建HTML报告"""
html = f"""
<!DOCTYPE html>
<html>
<head>
<title>搜索分析报告</title>
<style>
body {{ font-family: Arial, sans-serif; margin: 40px; }}
.section {{ margin-bottom: 30px; padding: 20px;
background-color: #f5f5f5; border-radius: 8px; }}
h1 {{ color: #333; }}
h2 {{ color: #666; }}
pre {{ white-space: pre-wrap; word-wrap: break-word; }}
</style>
</head>
<body>
<h1>搜索分析报告</h1>
<p>生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}</p>
<div class="section">
<h2>分析结果</h2>
<pre>{analysis_data.get('analysis', '没有可用的分析')}</pre>
</div>
<div class="section">
<h2>数据摘要</h2>
<p>主题: {analysis_data.get('topic', 'N/A')}</p>
<p>分析结果数量: {len(analysis_data.get('search_data', []))}</p>
</div>
</body>
</html>
"""
with open(filename, 'w') as f:
f.write(html)
print(f"HTML报告已创建: {filename}")
def main():
# 初始化组件
competitor_monitor = CompetitorMonitor()
trend_monitor = TrendMonitor()
exporter = DataExporter()
# 示例 1: 竞争对手分析
print("=== 竞争对手分析 ===")
analysis = competitor_monitor.analyze_competitors(
company_name="OpenAI",
competitors=["Anthropic", "Google AI", "Meta AI"]
)
print("\n竞争分析结果:")
print(analysis["analysis"])
# 保存结果
with open("competitor_analysis.json", "w") as f:
json.dump(analysis, f, indent=2)
# 示例 2: 趋势监测
print("\n\n=== 趋势监测 ===")
trends = trend_monitor.monitor_trend(
keyword="人工智能监管",
time_range="w" # 过去一周
)
print("\n趋势分析结果:")
print(trends["analysis"])
# 示例 3: 多主题分析
print("\n\n=== 多主题分析 ===")
topics = [
"生成型AI商业应用",
"AI网络安全威胁",
"医疗中的机器学习"
]
analyzer = SearchAnalyzer()
all_results = []
for topic in topics:
print(f"\n分析主题: {topic}")
result = analyzer.analyze_topic(topic)
if result:
all_results.append(result)
# 保存单项分析
filename = f"{topic.replace(' ', '_')}_analysis.txt"
with open(filename, "w") as f:
f.write(result["analysis"])
print(f"分析结果已保存到 {filename}")
# 请求之间的延迟
time.sleep(2)
# 将所有结果导出为CSV
if all_results:
csv_file = exporter.export_to_csv(all_results)
print(f"\n所有结果已导出到: {csv_file}")
# 为第一个结果创建HTML报告
if all_results[0]:
exporter.create_html_report(all_results[0])
if __name__ == "__main__":
main()结论
恭喜你!你成功构建了一个全面的搜索分析系统,该系统结合了Scrapeless的企业级网页抓取能力与Google Gemini的先进AI分析。这一智能解决方案自动将原始搜索数据转化为可操作的商业洞察。
你所取得的成就
通过本教程,你创建了一个模块化、生产就绪的系统,包括:
- 自动数据收集:通过Scrapeless API实时获取Google搜索结果
- AI驱动的分析:使用Google Gemini生成智能洞察
- 竞争对手情报:全面监测竞争格局
- 趋势检测:实时市场趋势识别与分析
- 多格式报告:CSV导出和HTML报告,用于共享给利益相关者
- 可扩展的架构:模块化设计,以便于自定义和扩展
对你商业的主要好处
战略决策:将搜索数据转化为战略洞察,以推动明智的商业决策和竞争定位。
时间效率:将数小时的人工研究转化为几分钟的自动分析,让团队可以专注于更高价值的战略工作。
市场意识:通过实时监控能力,领先于行业趋势、竞争对手动态和新兴机会。
具性价比的智能:以传统市场研究解决方案成本的一小部分利用企业级工具。
扩展您的系统
模块化架构使扩展功能变得简单:
- 额外数据源:集成社交媒体API、新闻源或行业数据库
- 高级分析:增加情感分析、实体识别或预测建模
- 可视化:使用Streamlit或Dash等工具创建互动仪表板
- 警报:实施市场重大变化的实时通知
- 多语言支持:通过本地化搜索扩展对全球市场的监控
成功的最佳实践
- 从小开始:从聚焦的关键字开始,逐步扩展您的监控范围
- 迭代提示:根据输出质量不断优化您的AI提示
- 验证结果:最初将AI洞察与人工验证交叉参考
- 定期更新:保持竞争对手列表和关键字的最新
- 利益相关者反馈:收集最终用户的意见以提高报告的相关性
最后思考
该搜索分析系统代表了迈向数据驱动商业智能的重要一步。通过将Scrapeless的可靠数据收集与Gemini的分析能力结合,您创建了一个强大的工具,能够适应几乎任何行业或用例。
投资构建该系统将通过提高市场意识、竞争情报和战略决策能力带来回报。随着您继续优化和扩展该系统,您将发现利用搜索数据实现业务增长的新机会。
请记住,成功的实施不仅依赖于技术,还取决于您将这些洞察有效地融入到业务流程和决策工作流中的程度。
有关更多资源、高级功能和API文档,请访问 Scrapeless 文档。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


