
如何使用 n8n 和 Scrapeless 构建智能 B2B 潜在客户生成工作流程
Advanced Data Extraction Specialist
将您的销售前景转变为一个自动化工作流程,该流程使用Google搜索、爬虫和Claude AI分析来寻找、验证和丰富B2B潜在客户。本教程将向您展示如何使用n8n和Scrapeless创建一个强大的潜在客户生成系统。
我们将构建的内容
在本教程中,我们将创建一个智能的B2B潜在客户生成工作流程,该流程:
- 定期自动触发或手动触发
- 使用Scrapeless在Google中搜索您目标市场的公司
- 分别处理每个公司URL的项目列表
- 爬取公司网站以提取详细信息
- 使用Claude AI来验证和构建潜在客户数据
- 将合格的潜在客户存储在Google Sheets中
- 向Discord发送通知(可调节为Slack、电子邮件等)
先决条件
- 一个n8n实例(云或自托管)
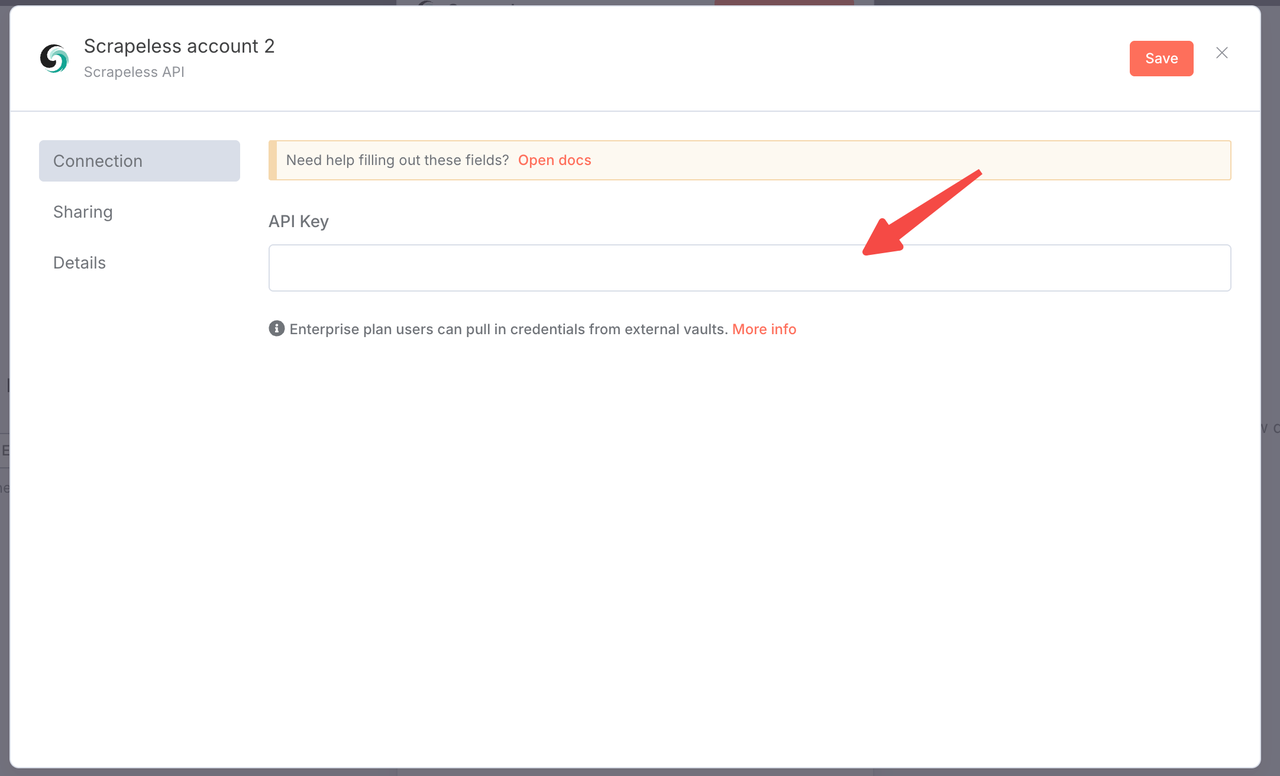
- 一个Scrapeless API密钥(在scrapeless.com获取)
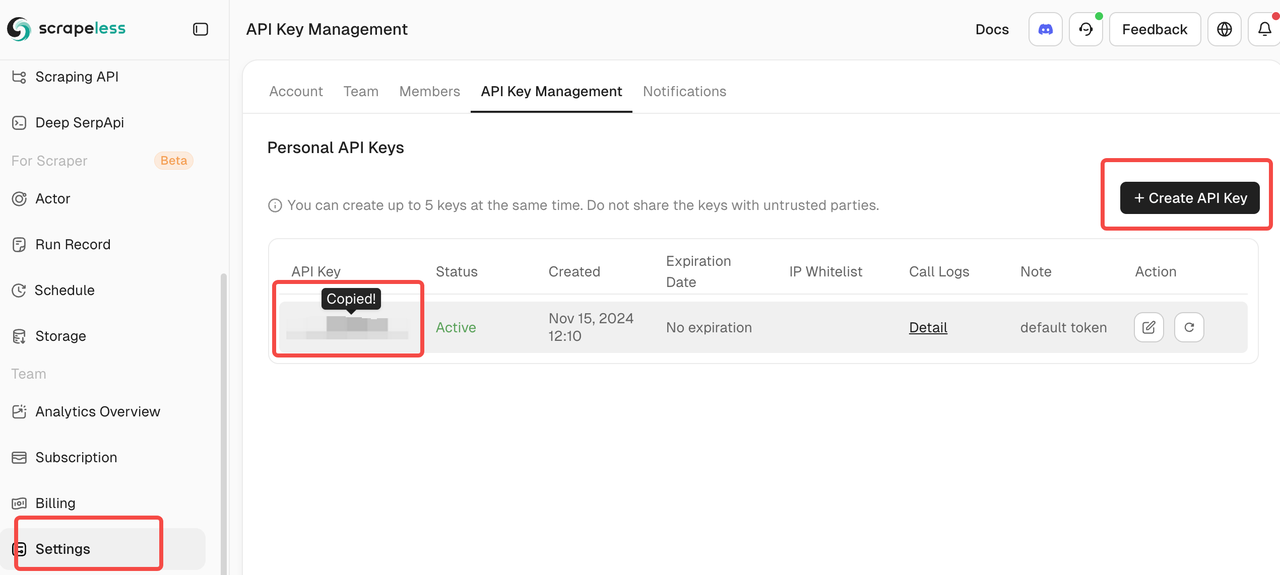
您只需登录Scrapeless仪表板并遵循下图获取您的API密钥。Scrapeless将为您提供免费试用配额。
- 来自Anthropic的Claude API密钥
- Google Sheets访问权限
- Discord webhook URL(或您偏好的通知服务)
- 基础的n8n工作流程理解
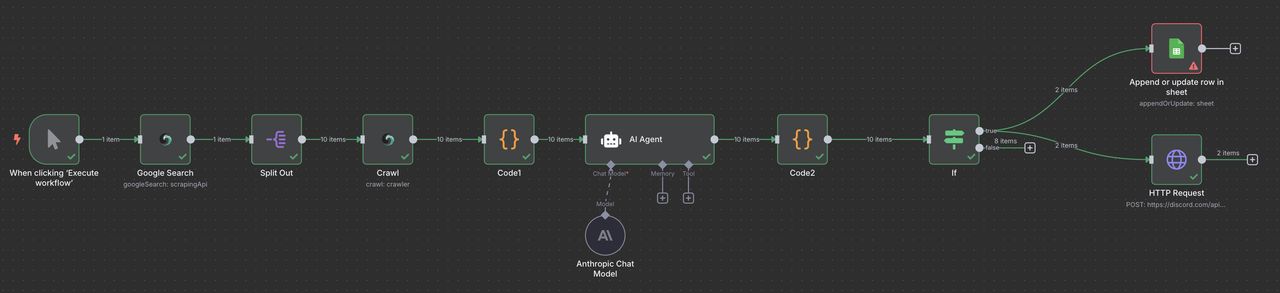
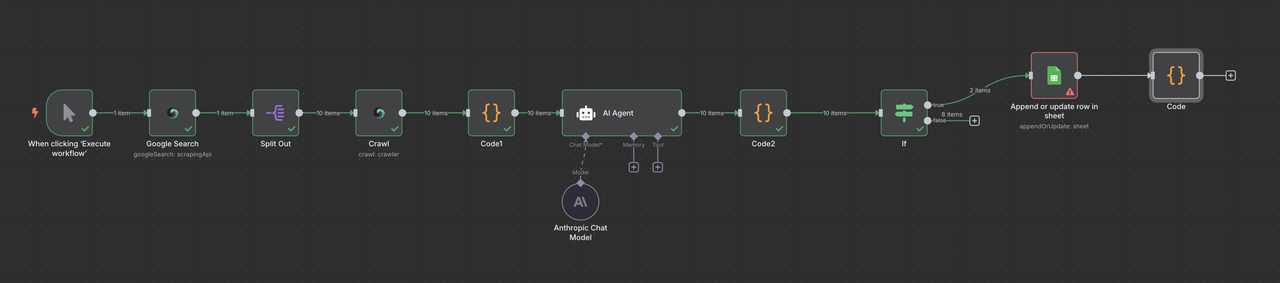
完整工作流程概述
您的最终n8n工作流程将如下所示:
手动触发 → Scrapeless Google搜索 → 项目列表 → Scrapeless爬虫 → 代码(数据处理) → Claude AI → 代码(响应解析器) → 筛选 → Google Sheets或/和Discord Webhook
第1步:设置手动触发器
我们将从手动触发器开始进行测试,然后稍后添加调度功能。
- 在n8n中创建一个新工作流程
- 添加一个手动触发器节点作为起点
- 这让您能够在自动化之前测试工作流程
为什么要手动开始?
- 测试和调试每一步
- 在自动化之前验证数据质量
- 根据初步结果调整参数
第2步:添加Scrapeless Google搜索
现在我们将添加Scrapeless Google搜索节点来寻找目标公司。
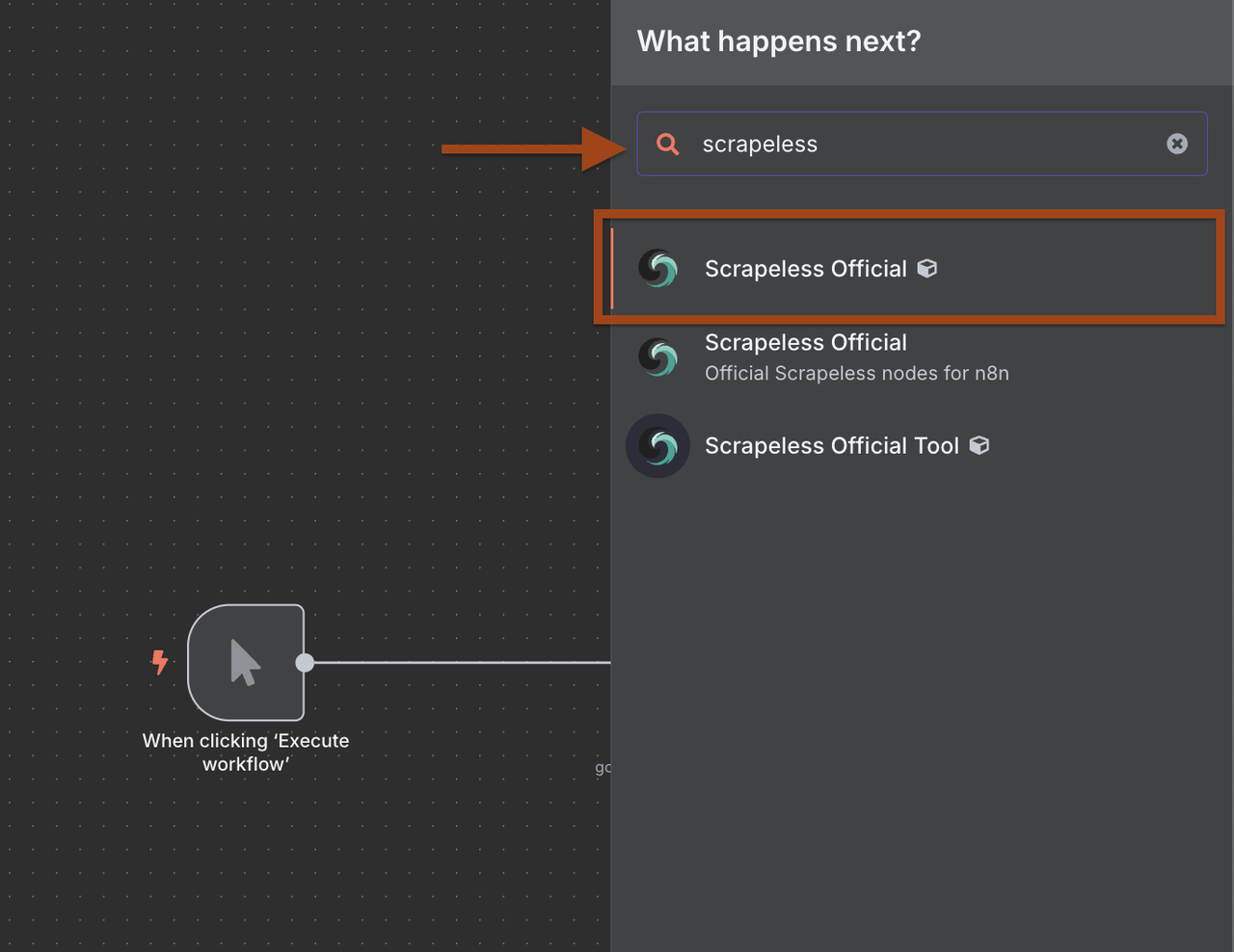
- 单击 + 在触发器后添加一个新节点
- 在节点库中搜索Scrapeless
- 选择Scrapeless并选择搜索Google操作
1. 为什么在n8n中使用Scrapeless?
将Scrapeless与n8n集成,可以让您创建高级、强大的网络抓取工具,而无需编写代码。
优势包括:
- 通过单个请求访问Deep SerpApi来获取和提取Google SERP数据。
- 使用通用抓取API绕过限制并访问任何网站。
- 使用爬虫抓取功能执行单页面的详细抓取。
- 使用爬虫爬行功能进行递归爬行并从所有链接页面检索数据。
这些功能允许您构建连接Scrapeless与350+个由n8n支持的服务(包括Google Sheets、Airtable、Notion、Slack等)的端到端数据流。
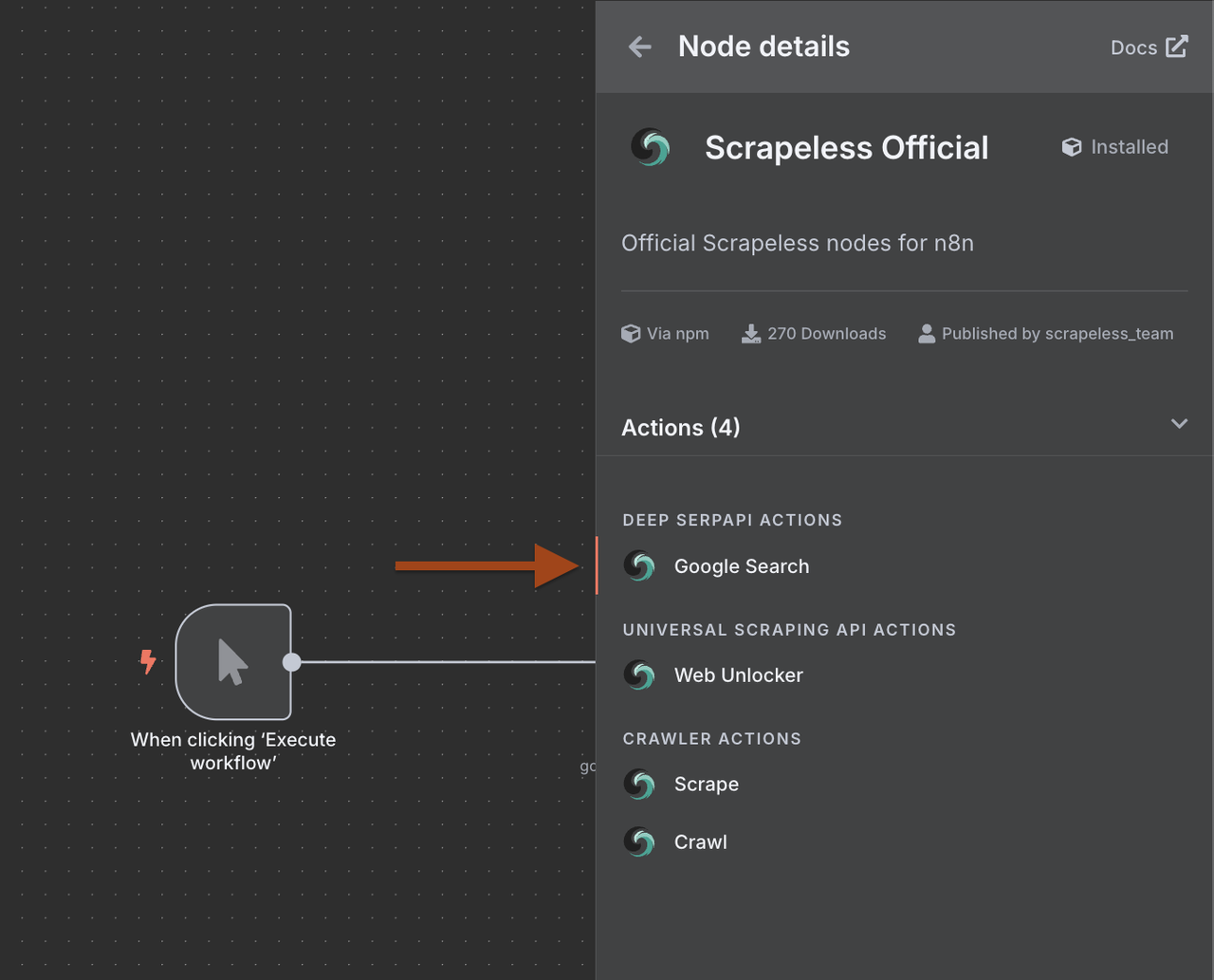
2. 配置Google搜索节点
接下来,我们需要配置Scrapeless Google搜索节点。
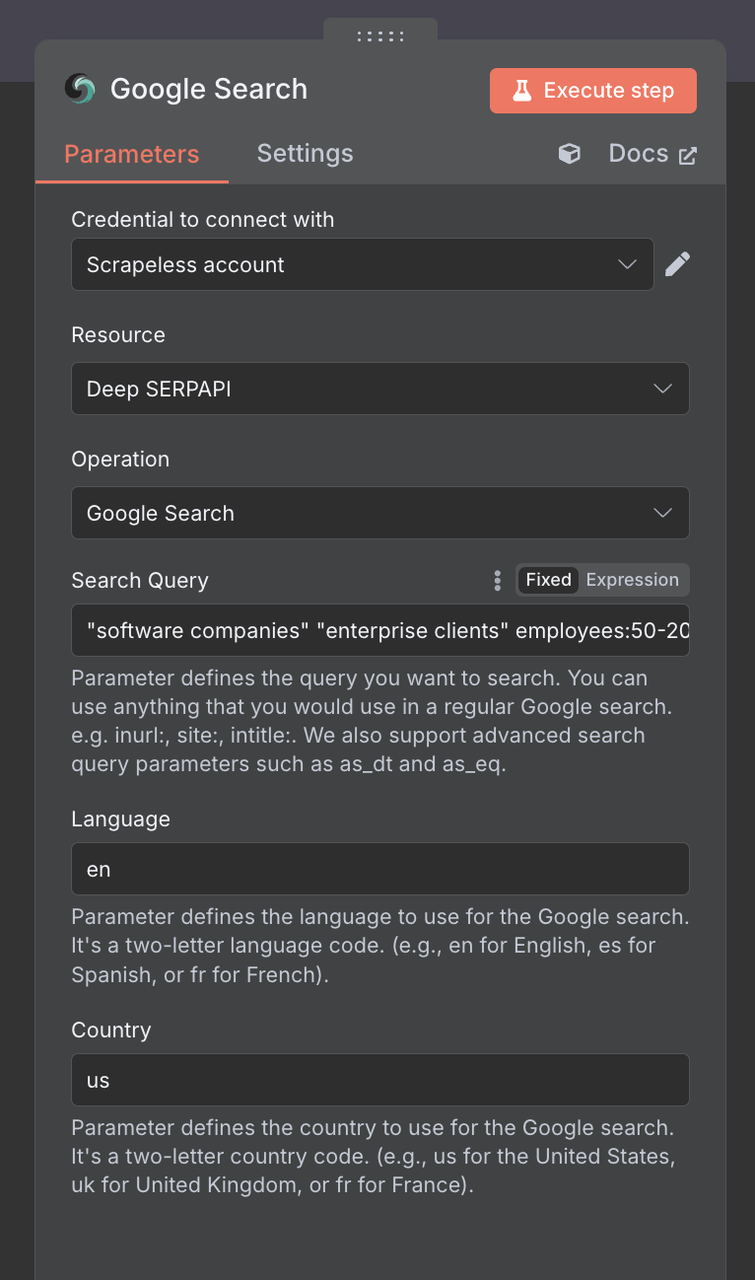
连接设置:
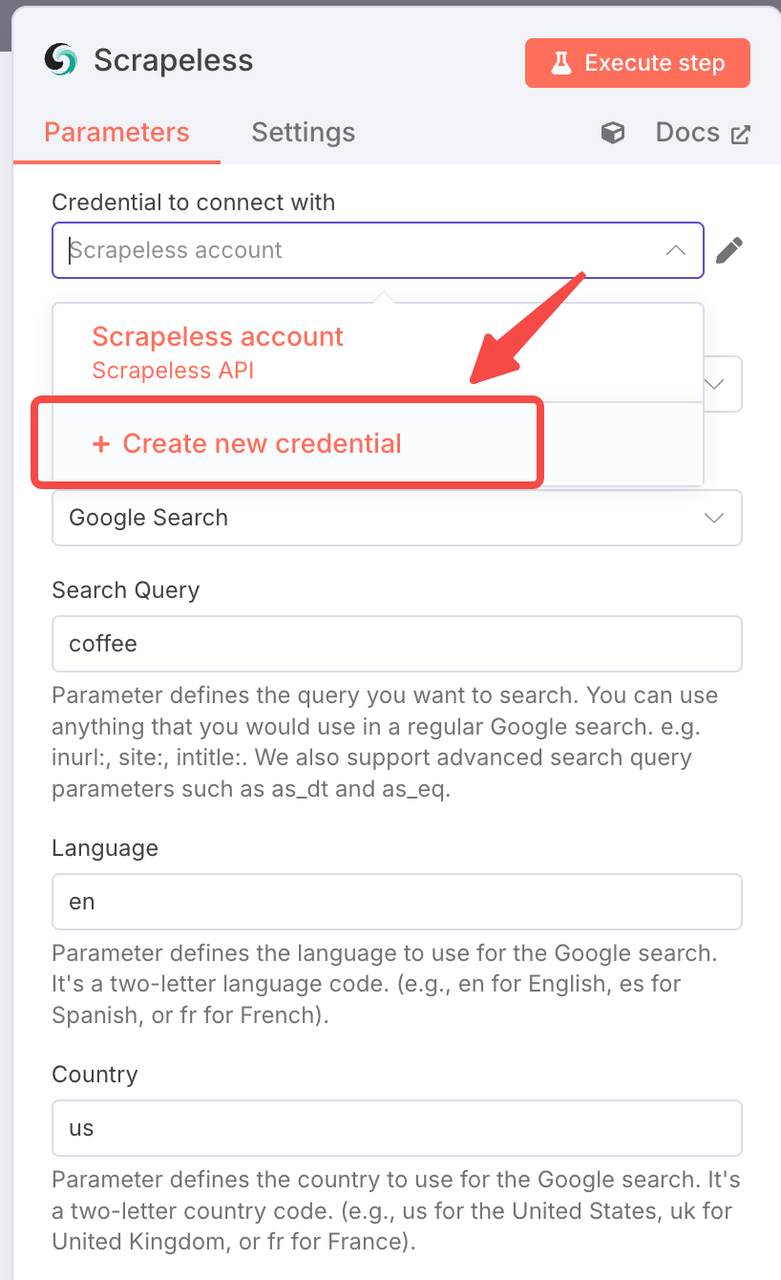
- 使用您的Scrapeless API密钥创建连接
- 单击“添加”,并输入您的凭据
搜索参数:
搜索查询:使用针对B2B的搜索词:
"软件公司" "企业客户" 员工:50-200
"营销机构" "B2B服务" "数字化转型"
"SaaS初创公司" "A轮" "风险投资"
"制造公司" "数字解决方案" ISO国家:美国(或您的目标市场)
语言:英语
专业B2B搜索策略:
- 公司规模定位:员工:50-200,"中型市场"
- 融资阶段: "A轮","风险投资","自筹资金"
- 行业特定:"金融科技","健康科技","教育科技"
- 地理: "纽约", "旧金山", "伦敦"
第3步:处理结果与项目列表
谷歌搜索返回了一系列结果。我们需要逐个处理每家公司。
- 在谷歌搜索后添加一个项目列表节点
- 这将把搜索结果拆分成单独的项目
小贴士:运行谷歌搜索节点
1. 项目列表配置:
- 操作: "拆分项目"
- 拆分字段: organic_results - 链接
- 包含二进制数据: false
这为每个搜索结果创建一个单独的执行分支,允许并行处理。
第4步:添加Scrapeless爬虫
现在我们将爬取每个公司的网站以提取详细信息。
- 添加另一个Scrapeless节点
- 选择爬取操作(而非WebUnlocker)
使用爬虫进行递归爬取并从所有链接页面检索数据。
- 配置以提取公司数据
1. 爬虫配置
- 连接:使用相同的Scrapeless连接
- URL: {{ $json.link }}
- 爬取深度: 2(主页 + 一层深)
- 最大页面数: 5(限制以加快处理速度)
- 包含模式: about|contact|team|company|services
- 排除模式: blog|news|careers|privacy|terms
- 格式: markdown(更易于AI处理)
2. 为什么使用爬虫而非Web Unlocker?
- 爬虫获取多个页面和结构化数据
- 更适合B2B,因为联系信息可能在/about或/contact页面
- 更全面的公司信息
- 智能跟随网站结构
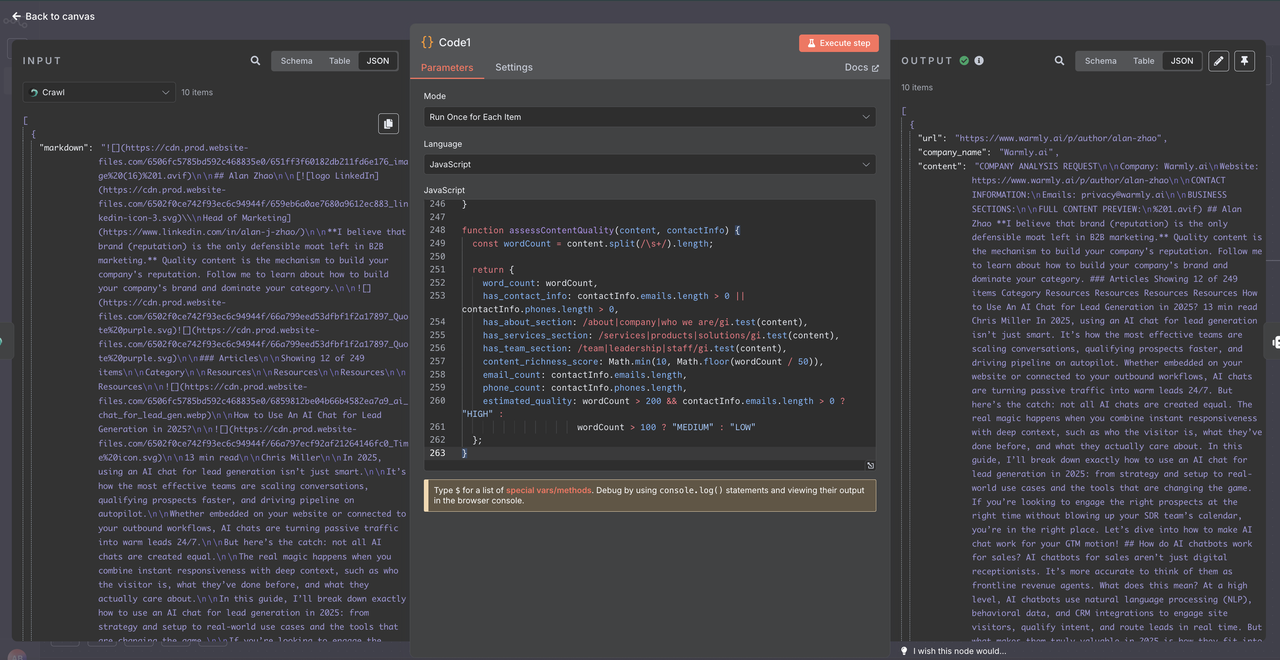
第5步:使用代码节点处理数据
在将爬取的数据发送给Claude AI之前,我们需要清理和正确结构化它。Scrapeless爬虫返回的数据是特定格式,需要仔细解析。
- 在Scrapeless爬虫后添加一个代码节点
- 使用JavaScript解析和清理原始爬取数据
- 这确保了AI分析的数据质量一致
1. 了解Scrapeless爬虫数据结构
Scrapeless爬虫返回的数据是一个对象数组,而不是单个对象:
[
{
"markdown": "# 公司主页\n\n欢迎来到我们的公司...",
"metadata": {
"title": "公司名称 - 主页",
"description": "公司描述",
"sourceURL": "https://company.com"
}
}
]2. 代码节点配置
console.log("=== 处理Scrapeless爬虫数据 ===");
try {
// 数据以数组形式到达
const crawlerDataArray = $json;
console.log("数据类型:", typeof crawlerDataArray);
console.log("是否为数组:", Array.isArray(crawlerDataArray));
console.log("数组长度:", crawlerDataArray?.length || 0);
// 检查数组是否为空
if (!Array.isArray(crawlerDataArray) || crawlerDataArray.length === 0) {
console.log("❌ 空或无效的爬虫数据");
return {
url: "未知",
company_name: "无数据",
content: "",
error: "空的爬虫响应",
processing_failed: true,
skip_reason: "爬虫未返回数据"
};
}
// 获取数组中的第一个元素
const crawlerResponse = crawlerDataArray[0];
// 提取Markdown内容
const markdownContent = crawlerResponse?.markdown || "";
// 提取元数据(如果可用)
const metadata = crawlerResponse?.metadata || {};
// 基本信息
const sourceURL = metadata.sourceURL || metadata.url || extractURLFromContent(markdownContent);
const companyName = metadata.title || metadata.ogTitle || extractCompanyFromContent(markdownContent);
const description = metadata.description || metadata.ogDescription || "";
console.log(`处理: ${companyName}`);
console.log(`URL: ${sourceURL}`);
console.log(`内容长度: ${markdownContent.length} 字符`);
// 内容质量验证
如果 (!markdownContent || markdownContent.length < 100) {
return {
url: sourceURL,
company_name: companyName,
content: "",
error: "爬虫内容不足",
processing_failed: true,
raw_content_length: markdownContent.length,
skip_reason: "内容过短或为空"
};
}
// 清理和结构化markdown内容
let cleanedContent = cleanMarkdownContent(markdownContent);
// 联系信息提取
const contactInfo = extractContactInformation(cleanedContent);
// 重要商业部分提取
const businessSections = extractBusinessSections(cleanedContent);
// 为Claude AI构建内容
const contentForAI = buildContentForAI({
companyName,
sourceURL,
description,
businessSections,
contactInfo,
cleanedContent
});
// 内容质量指标
const contentQuality = assessContentQuality(cleanedContent, contactInfo);
const result = {
url: sourceURL,
company_name: companyName,
content: contentForAI,
raw_content_length: markdownContent.length,
processed_content_length: contentForAI.length,
extracted_emails: contactInfo.emails,
extracted_phones: contactInfo.phones,
content_quality: contentQuality,
metadata_info: {
has_title: !!metadata.title,
has_description: !!metadata.description,
site_name: metadata.ogSiteName || "",
page_title: metadata.title || ""
},
processing_timestamp: new Date().toISOString(),
processing_status: "成功"
};
console.log(`✅ 成功处理 ${companyName}`);
return result;
} catch (error) {
console.error("❌ 处理爬虫数据时出错:", error);
return {
url: "未知",
company_name: "处理错误",
content: "",
error: error.message,
processing_failed: true,
processing_timestamp: new Date().toISOString()
};
}
// ========== 工具函数 ==========
function extractURLFromContent(content) {
// 尝试从markdown内容中提取URL
const urlMatch = content.match(/https?:\/\/[^\s\)]+/);
return urlMatch ? urlMatch[0] : "未知";
}
function extractCompanyFromContent(content) {
// 尝试从内容中提取公司名称
const titleMatch = content.match(/^#\s+(.+)$/m);
if (titleMatch) return titleMatch[1];
// 查找电子邮件以提取域名
const emailMatch = content.match(/@([a-zA-Z0-9.-]+\.[a-zA-Z]{2,})/);
if (emailMatch) {
const domain = emailMatch[1].replace('www.', '');
return domain.split('.')[0].charAt(0).toUpperCase() + domain.split('.')[0].slice(1);
}
return "未知公司";
}
function cleanMarkdownContent(markdown) {
return markdown
// 移除导航元素
.replace(/^\[跳至内容\].*$/gmi, '')
.replace(/^\[.*\]\(#.*\)$/gmi, '')
// 移除markdown链接但保留文本
.replace(/\[([^\]]+)\]\([^)]+\)/g, '$1')
// 移除图片和base64
.replace(/!\[([^\]]*)\]\([^)]*\)/g, '')
.replace(/<Base64图像已移除>/g, '')
// 移除cookie/隐私声明
.replace(/.*?(cookie|隐私政策|服务条款).*?\n/gi, '')
// 清除多余的空格
.replace(/\s+/g, ' ')
// 移除多余的空行
.replace(/\n\s*\n\s*\n/g, '\n\n')
.trim();
}
function extractContactInformation(content) {
// 电子邮件的正则表达式
const emailRegex = /[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}/g;
// 电话的正则表达式(支持国际)
const phoneRegex = /(?:\+\d{1,3}\s?)?\d{3}\s?\d{3}\s?\d{3,4}|\(\d{3}\)\s?\d{3}-?\d{4}/g;
const emails = [...new Set((content.match(emailRegex) || [])
.filter(email => !email.includes('example.com'))
.slice(0, 3))];
const phones = [...new Set((content.match(phoneRegex) || [])
.filter(phone => phone.replace(/\D/g, '').length >= 9)
.slice(0, 2))];
return { emails, phones };
}
function extractBusinessSections(content) {
const sections = {};
// 搜索重要部分
const lines = content.split('\n');
let currentSection = '';
let currentContent = '';
for (let i = 0; i < lines.length; i++) {
const line = lines[i].trim();
// 标题检测
if (line.startsWith('#')) {
// 保存之前的部分
if (currentSection && currentContent) {
sections[currentSection] = currentContent.trim().substring(0, 500);
}
// 新部分
const title = line.replace(/^#+\s*/, '').toLowerCase();
if (title.includes('关于') || title.includes('服务') ||
title.includes('联系') || title.includes('公司')) {
currentSection = title.includes('关于') ? '关于' :
title.includes('服务') ? '服务' :
title.includes('联系') ? '联系' : '公司';
currentContent = '';
} else {
currentSection = '';
}
} else if (currentSection && line) {
currentContent += line + '\n';
}
```zh
}
// 保存最后一个部分
if (currentSection && currentContent) {
sections[currentSection] = currentContent.trim().substring(0, 500);
}
return sections;
}
function buildContentForAI({ companyName, sourceURL, description, businessSections, contactInfo, cleanedContent }) {
let aiContent = `公司分析请求\n\n`;
aiContent += `公司: ${companyName}\n`;
aiContent += `网站: ${sourceURL}\n`;
if (description) {
aiContent += `描述: ${description}\n`;
}
aiContent += `\n联系信息:\n`;
if (contactInfo.emails.length > 0) {
aiContent += `电子邮件: ${contactInfo.emails.join(', ')}\n`;
}
if (contactInfo.phones.length > 0) {
aiContent += `电话: ${contactInfo.phones.join(', ')}\n`;
}
aiContent += `\n业务部分:\n`;
for (const [section, content] of Object.entries(businessSections)) {
if (content) {
aiContent += `\n${section.toUpperCase()}:\n${content}\n`;
}
}
// 添加主要内容(有限制)
aiContent += `\n完整内容预览:\n`;
aiContent += cleanedContent.substring(0, 2000);
// Claude API的最终限制
return aiContent.substring(0, 6000);
}
function assessContentQuality(content, contactInfo) {
const wordCount = content.split(/\s+/).length;
return {
word_count: wordCount,
has_contact_info: contactInfo.emails.length > 0 || contactInfo.phones.length > 0,
has_about_section: /about|company|who we are/gi.test(content),
has_services_section: /services|products|solutions/gi.test(content),
has_team_section: /team|leadership|staff/gi.test(content),
content_richness_score: Math.min(10, Math.floor(wordCount / 50)),
email_count: contactInfo.emails.length,
phone_count: contactInfo.phones.length,
estimated_quality: wordCount > 200 && contactInfo.emails.length > 0 ? "高" :
wordCount > 100 ? "中" : "低"
};
}3. 为什么添加代码处理步骤?
- 数据结构适应:将Scrapeless数组格式转换为Claude友好的结构。
- 内容优化:提取并优先处理与业务相关的部分。
- 联系发现:自动识别电子邮件和电话号码。
- 质量评估:评估内容的丰富性和完整性。
- 令牌效率:在保留重要信息的同时减少内容大小。
- 错误处理:优雅地管理爬取失败和内容不足情况。
- 调试支持:全面的日志记录以帮助故障排除。
4. 预期输出结构
处理后,每个线索将具有以下结构格式:
{
"url": "https://company.com",
"company_name": "公司名称",
"content": "公司分析请求\n\n公司: ...",
"raw_content_length": 50000,
"processed_content_length": 2500,
"extracted_emails": ["contact@company.com"],
"extracted_phones": ["+1-555-123-4567"],
"content_quality": {
"word_count": 5000,
"has_contact_info": true,
"estimated_quality": "高",
"content_richness_score": 10
},
"processing_status": "成功"
}
这有助于验证数据格式并排除任何处理问题。
5. 代码节点的好处
- 成本节约:更小、更干净的内容 = 更少的Claude API令牌。
- 更好的结果:聚焦内容提高了AI分析的准确性。
- 错误恢复:处理空响应和爬取失败。
- 灵活性:根据结果轻松调整解析逻辑。
- 质量指标:内置评估线索数据的完整性。
第6步:使用Claude进行AI驱动的线索资格认证
使用Claude AI从经过处理和结构化的爬取内容中提取和认证线索信息。
- 在代码节点后添加AI代理节点
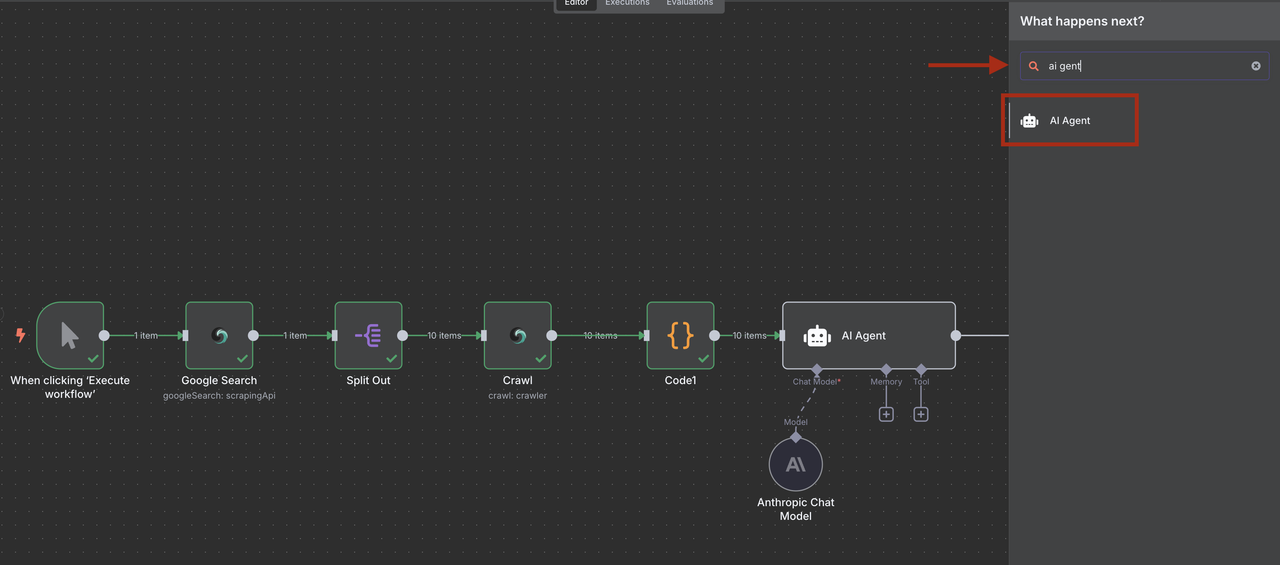
- 添加一个Anthropic Claude节点并配置以进行线索分析
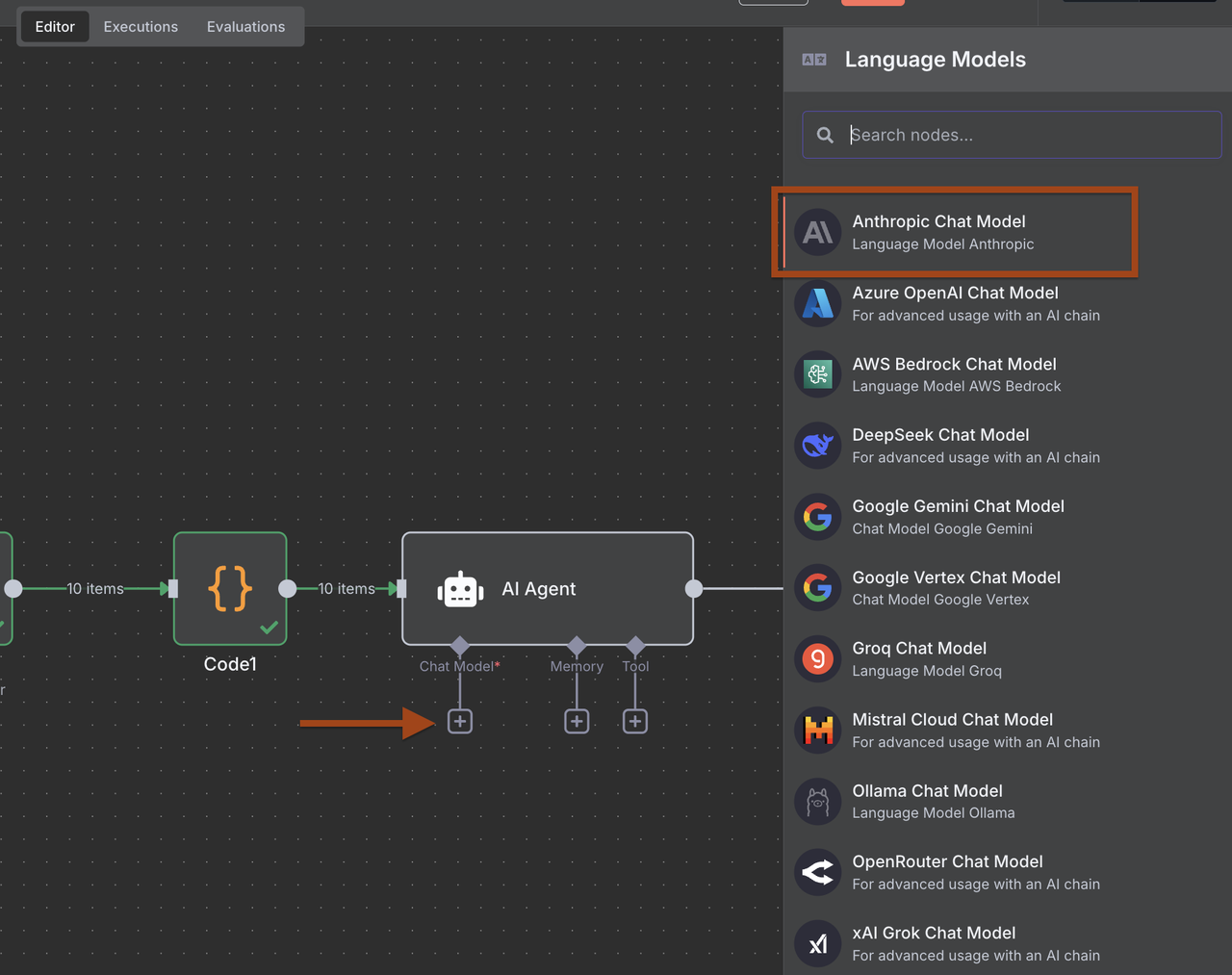
- 配置提示以提取结构化的B2B线索数据
点击AI代理 -> 添加选项 -> 系统消息并复制粘贴以下消息
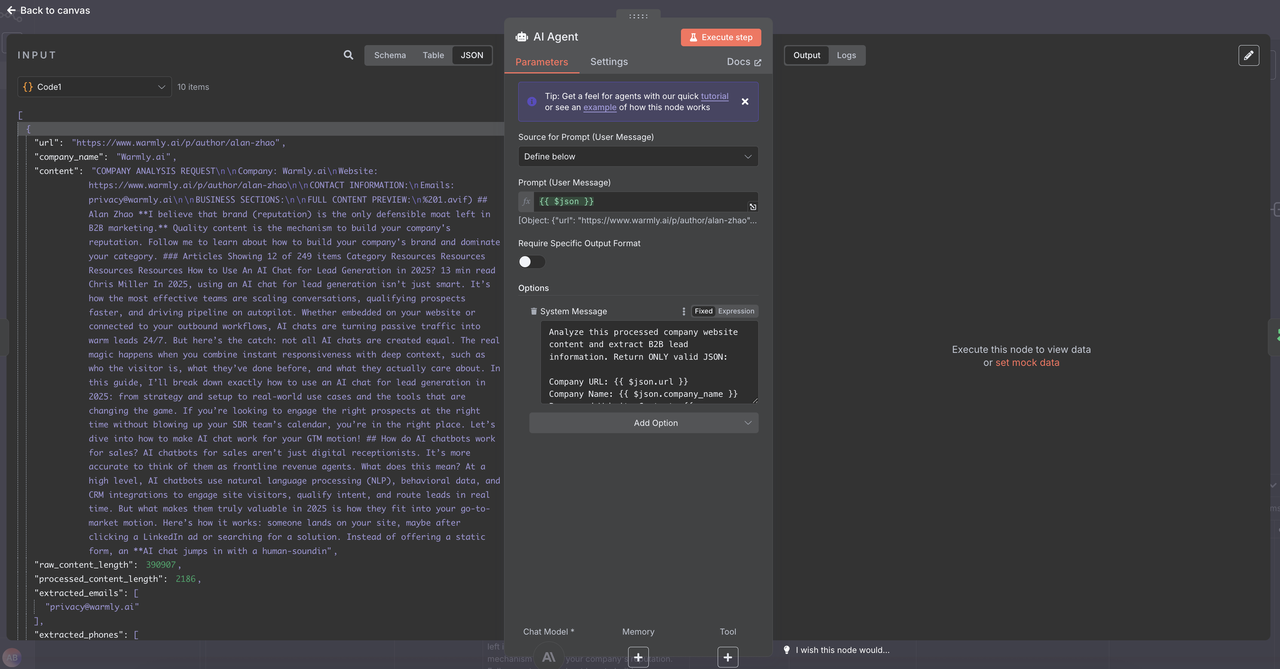
系统线索提取提示:
分析这个处理过的公司网站内容并提取B2B线索信息。仅返回有效的JSON:
公司网址: {{ $json.url }}
公司名称: {{ $json.company_name }}
处理过的网站内容: {{ $json.content }}
内容质量评估: {{ $json.content_quality }}
预提取的联系信息:
电子邮件: {{ $json.extracted_emails }}
电话: {{ $json.extracted_phones }}
元数据: {{ $json.metadata_info }}
处理细节:
原始内容长度:{{ $json.raw_content_length }} 字符
处理后内容长度:{{ $json.processed_content_length }} 字符
处理状态:{{ $json.processing_status }}
基于这些结构化数据,提取并评估这个 B2B 线索。仅返回有效的 JSON:
{
"company_name": "内容中的官方公司名称",
"industry": "识别出的主要行业/部门",
"company_size": "员工人数或规模类别(初创/中小型企业/中型市场/企业)",
"location": "总部位置或主要市场",
"contact_email": "提取的电子邮件中最好的通用或销售电子邮件",
"phone": "提取的电话中主要电话号码",
"key_services": ["根据内容提供的主要服务/产品"],
"target_market": "他们服务的对象(B2B/B2C,中小企业/企业,特定行业)",
"technologies": ["提到的技术栈、平台或工具"],
"funding_stage": "若提到的融资阶段(种子/系列 A/B/C/公开/私人)",
"business_model": "收入模型(SaaS/咨询/产品/市场)",
"social_presence": {
"linkedin": "如在内容中找到的 LinkedIn 公司 URL",
"twitter": "如找到的 Twitter 账号"
},
"lead_score": 8.5,
"qualification_reasons": ["此线索合格或不合格的具体原因"],
"decision_makers": ["找到的关键联系人的姓名和职位"],
"next_actions": ["基于公司概况的推荐后续策略"],
"content_insights": {
"website_quality": "根据内容丰富度评级(专业/基本/差)",
"recent_activity": "提到的任何近期新闻、融资或更新",
"competitive_positioning": "他们与竞争对手的定位"
}
}
增强评分标准(1-10):
9-10:完美的 ICP 适配 + 完整的联系信息 + 高增长信号 + 专业内容
7-8:良好的 ICP 适配 + 有一些联系信息 + 稳定的公司 + 高质量内容
5-6:适度匹配 + 联系信息有限 + 基本内容 + 需要研究
3-4:匹配差 + 信息极少 + 低质量内容 + 错误的目标市场
1-2:不合格 + 没有联系信息 + 处理失败 + 不相关
评分因素考虑:
内容质量得分:{{ $json.content_quality.content_richness_score }}/10
联系信息:{{ $json.content_quality.email_count }} 电子邮件,{{ $json.content_quality.phone_count }} 电话
内容完整性:{{ $json.content_quality.has_about_section }}, {{ $json.content_quality.has_services_section }}
处理成功:{{ $json.processing_status }}
内容量:{{ $json.content_quality.word_count }} 个词
指示:
仅使用从 extracted_emails 和 extracted_phones 提取的预提取联系信息
基于处理后的 company_name 字段确定 company_name,而不是原始内容
在确定 lead_score 时考虑内容质量指标
如果 processing_status 不是 “SUCCESS”,则显著降低分数
对于任何缺失的信息使用 null - 不要虚构数据
评分要保守 - 低估总比高估好
基于提供的结构化内容关注 B2B 相关性和 ICP 适配提示结构使筛选更加可靠,因为 Claude 现在接收一致的、结构化的输入。这导致更准确的线索评分和更好的资格评估决策在工作流程的下一步。
第7步:解析 Claude AI 响应
在筛选线索之前,我们需要正确解析 Claude 的 JSON 响应,该响应可能被包装在 markdown 格式中。
- 在 AI 代理(Claude)后添加代码节点
- 配置解析并清理 Claude 的 JSON 响应
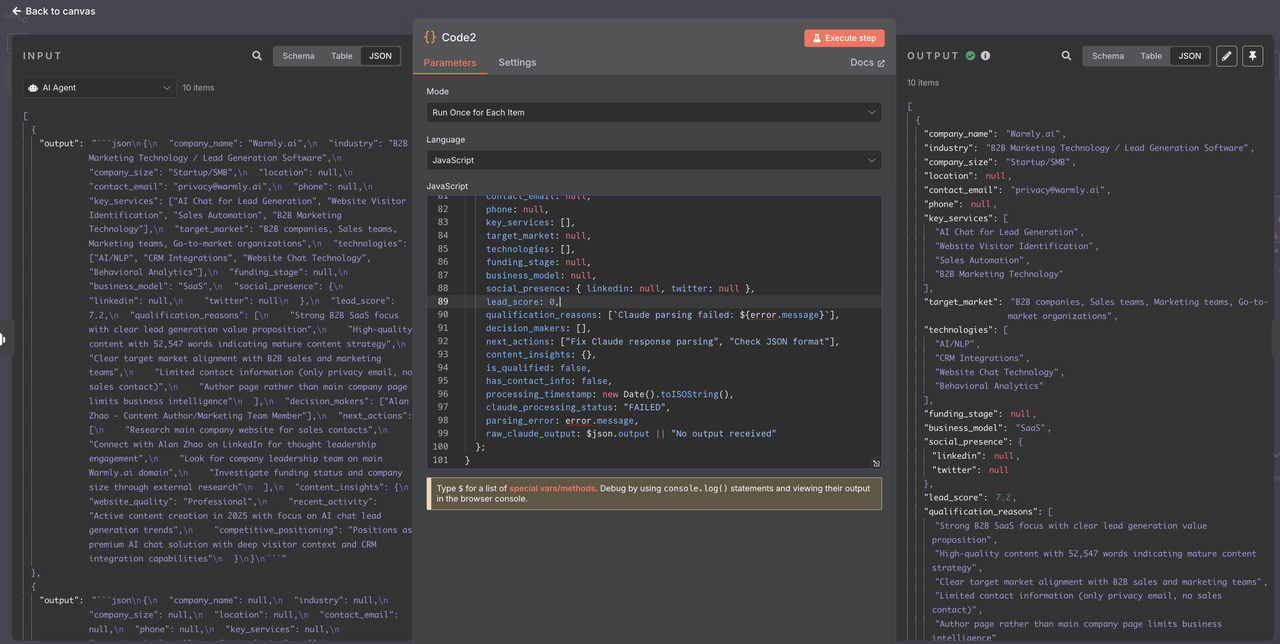
1. 代码节点配置
// 解析 Claude AI JSON 响应的代码
console.log("=== 正在解析 Claude AI 响应 ===");
try {
// Claude 的响应到达 "output" 字段
const claudeOutput = $json.output || "";
console.log("Claude 输出长度:", claudeOutput.length);
console.log("Claude 输出预览:", claudeOutput.substring(0, 200));
// 从 Claude 的 markdown 响应中提取 JSON
let jsonString = claudeOutput;
// 移除 markdown 反引号(如果存在)
if (jsonString.includes('json')) {
const jsonMatch = jsonString.match(/json\s*([\s\S]*?)\s*/);
if (jsonMatch && jsonMatch[1]) {
jsonString = jsonMatch[1].trim();
}
} else if (jsonString.includes('')) {
// 仅有的回退情况
const jsonMatch = jsonString.match(/\s*([\s\S]*?)\s*```/);
if (jsonMatch && jsonMatch[1]) {
jsonString = jsonMatch[1].trim();
}
}
// 额外清理
jsonString = jsonString.trim();
console.log("提取的 JSON 字符串:", jsonString.substring(0, 300));
// 解析 JSON
const leadData = JSON.parse(jsonString);
console.log("成功解析线索数据:", leadData.company_name);
console.log("线索评分:", leadData.lead_score);
javascript
console.log("联系邮箱:", leadData.contact_email);
// 验证和数据清理
const cleanedLead = {
company_name: leadData.company_name || "未知",
industry: leadData.industry || null,
company_size: leadData.company_size || null,
location: leadData.location || null,
contact_email: leadData.contact_email || null,
phone: leadData.phone || null,
key_services: Array.isArray(leadData.key_services) ? leadData.key_services : [],
target_market: leadData.target_market || null,
technologies: Array.isArray(leadData.technologies) ? leadData.technologies : [],
funding_stage: leadData.funding_stage || null,
business_model: leadData.business_model || null,
social_presence: leadData.social_presence || { linkedin: null, twitter: null },
lead_score: typeof leadData.lead_score === 'number' ? leadData.lead_score : 0,
qualification_reasons: Array.isArray(leadData.qualification_reasons) ? leadData.qualification_reasons : [],
decision_makers: Array.isArray(leadData.decision_makers) ? leadData.decision_makers : [],
next_actions: Array.isArray(leadData.next_actions) ? leadData.next_actions : [],
content_insights: leadData.content_insights || {},
// 过滤的元信息
is_qualified: leadData.lead_score >= 6 && leadData.contact_email !== null,
has_contact_info: !!(leadData.contact_email || leadData.phone),
processing_timestamp: new Date().toISOString(),
claude_processing_status: "成功"
};
console.log(`✅ 已处理潜在客户: ${cleanedLead.company_name} (分数: ${cleanedLead.lead_score}, 资格: ${cleanedLead.is_qualified})`);
return cleanedLead;
} catch (error) {
console.error("❌ 解析Claude响应时出错:", error);
console.error("原始输出:", $json.output);
// 结构化错误响应
return {
company_name: "Claude 解析错误",
industry: null,
company_size: null,
location: null,
contact_email: null,
phone: null,
key_services: [],
target_market: null,
technologies: [],
funding_stage: null,
business_model: null,
social_presence: { linkedin: null, twitter: null },
lead_score: 0,
qualification_reasons: [`Claude 解析失败: ${error.message}`],
decision_makers: [],
next_actions: ["修复Claude响应解析", "检查JSON格式"],
content_insights: {},
is_qualified: false,
has_contact_info: false,
processing_timestamp: new Date().toISOString(),
claude_processing_status: "失败",
parsing_error: error.message,
raw_claude_output: $json.output || "未收到输出"
};
}
// 2. 为什么要添加Claude响应解析?
// - Markdown处理: 移除Claude响应中的json格式
// - 数据验证: 确保所有字段具有正确的类型和默认值
// - 错误恢复: 优雅地处理JSON解析失败
// - 过滤准备: 为更简单的过滤添加计算字段
// - 调试支持: 记录全面的日志以便故障排除
## 第8步: 潜在客户过滤和质量控制
根据资格得分和数据完整性使用解析和验证过的数据过滤潜在客户。
1. 在Claude响应解析器之后添加IF节点
2. 设置增强的资格标准
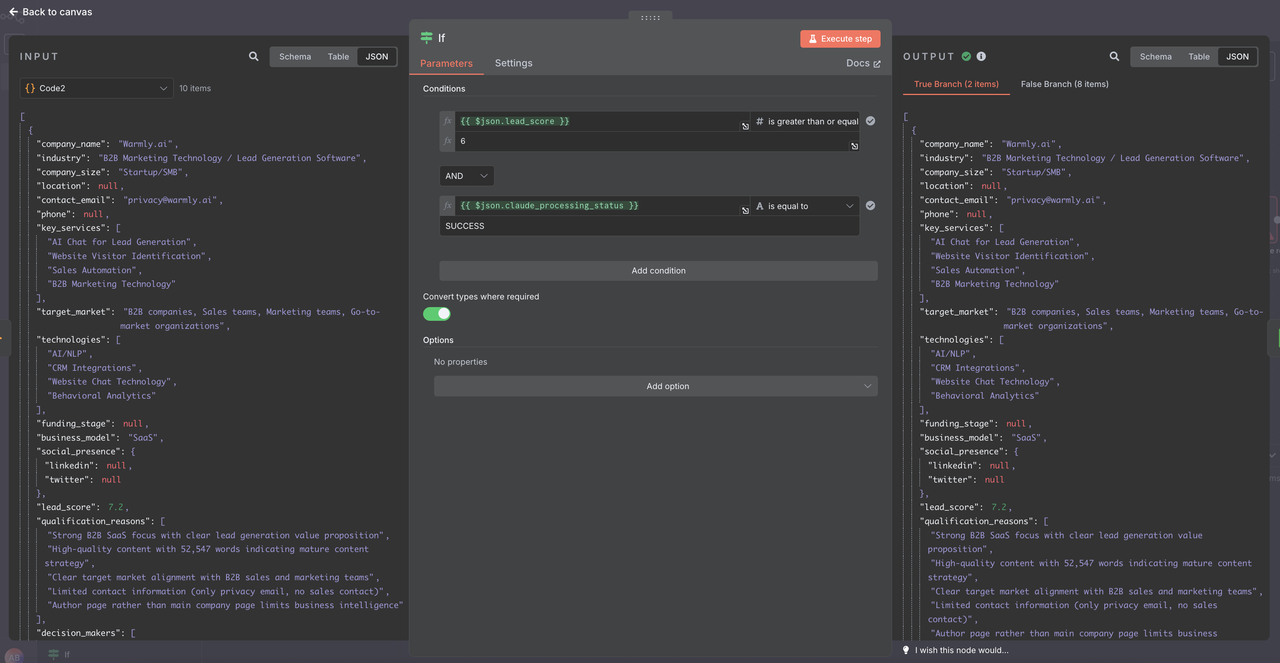
### 1. 新的IF节点配置
现在数据已经正确解析,在IF节点中使用以下条件:
**1: 添加多个条件**
**条件1:**
- 字段: {{ $json.lead_score }}
- 操作符: 大于或等于
- 值: 6
**条件2:**
- 字段: {{ $json.claude_processing_status }}
- 操作符: 等于
- 值: 成功
选项: 在需要时转换类型
- TRUE
### 2. 过滤的好处
- 质量保证: 只有合格的潜在客户才能转存
- 成本优化: 防止处理低质量潜在客户
- 数据完整性: 确保解析的数据在存储之前有效
- 调试能力: 失败的解析会被捕捉和记录
## 第9步: 将潜在客户存储到Google Sheets
将合格的潜在客户存储到Google Sheets数据库中,以便于访问和管理。
1. 在过滤器之后添加一个Google Sheets节点
2. 配置以附加新潜在客户
然而,您可以选择按您想要的方式管理数据。
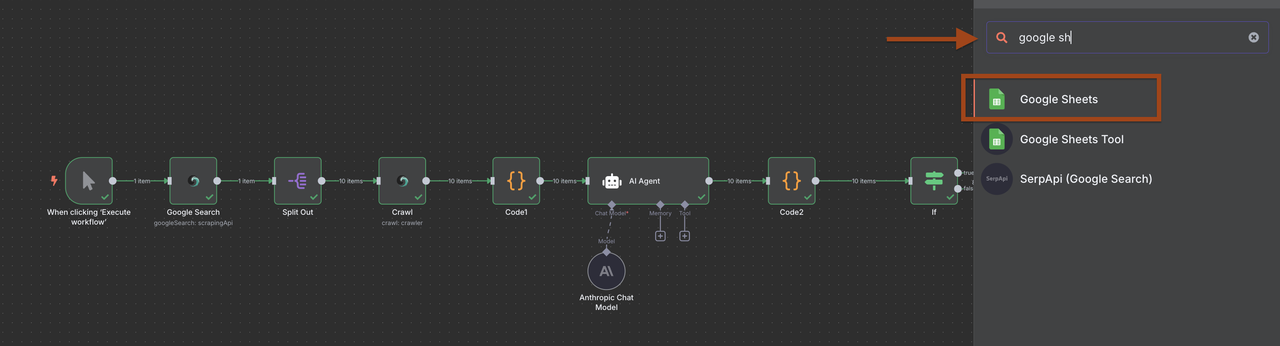
**Google Sheets设置:**- 创建一个名为“B2B潜在客户数据库”的电子表格
- 设置列:
- 公司名称
- 行业
- 公司规模
- 地点
- 联系邮箱
- 电话
- 网站
- 潜在客户评分
- 添加日期
- 资格备注
- 下一步行动
就我而言,我选择直接使用Discord webhook
第9-2步:Discord通知(可适配其他服务)
发送新合格潜在客户的实时通知。
- 为Discord webhook添加一个HTTP请求节点
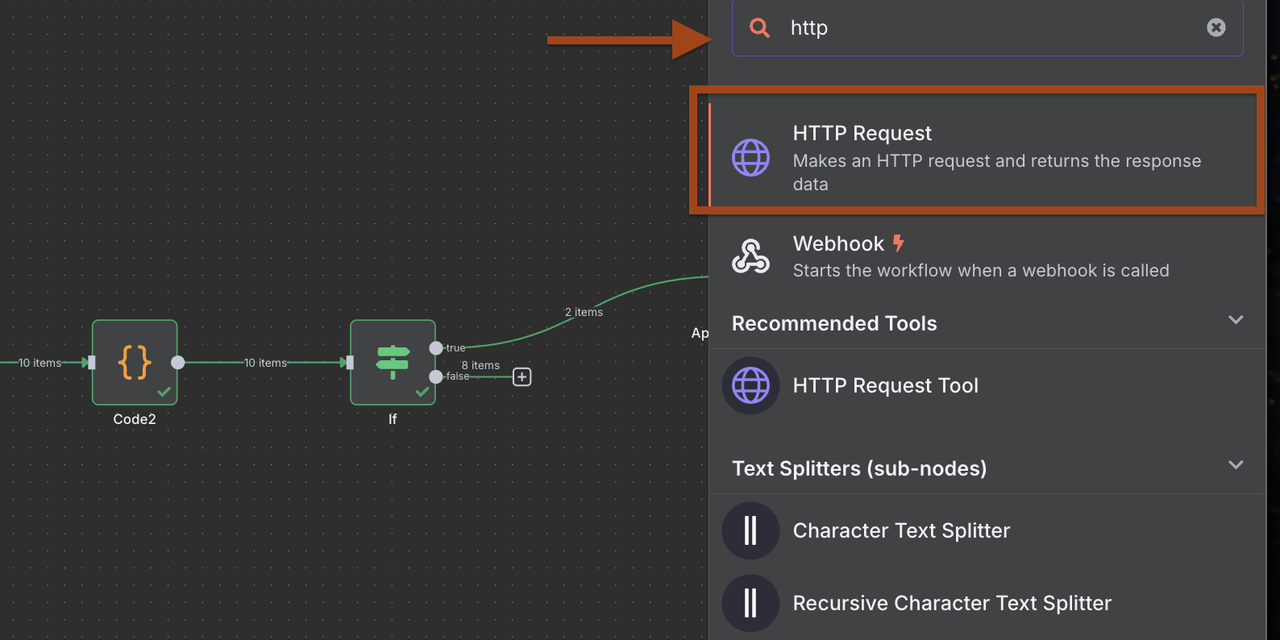
- 配置Discord特定的有效载荷格式
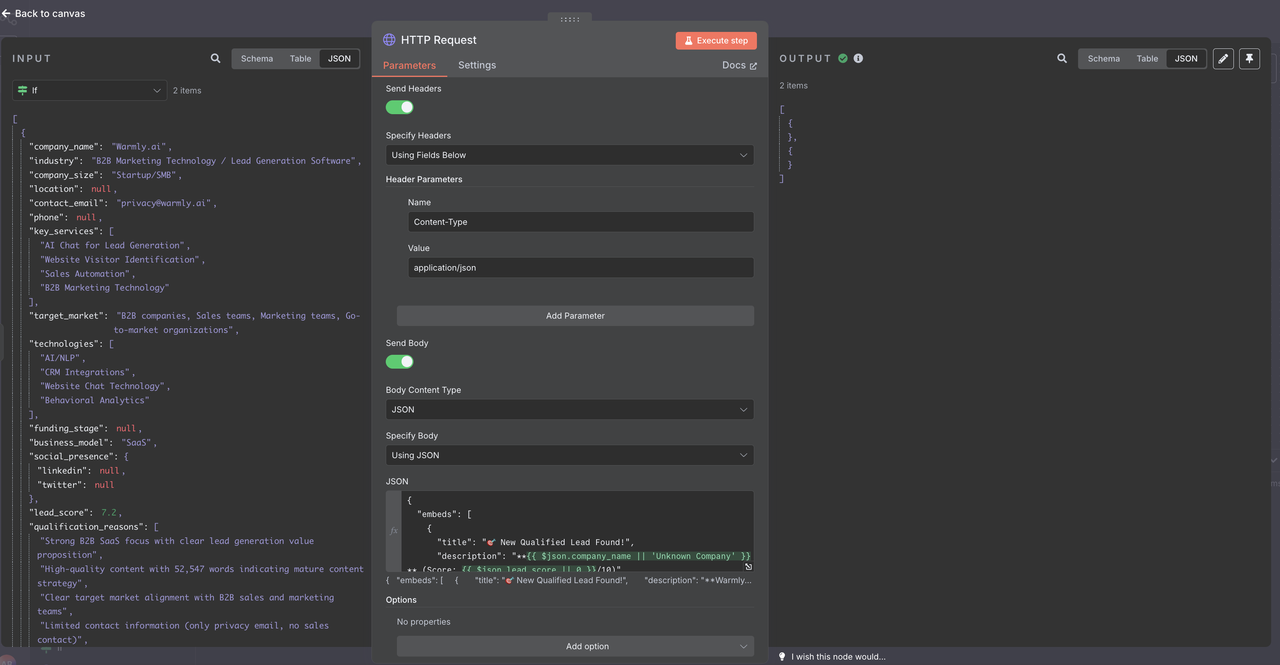
Discord Webhook配置:
- 方法:POST
- URL:您的Discord webhook URL
- 头部:Content-Type: application/json
Discord消息有效载荷:
{
"embeds": [
{
"title": "🎯 新合格潜在客户找到!",
"description": "**{{ $json.company_name || '未知公司' }}** (评分: {{ $json.lead_score || 0 }}/10)",
"color": 3066993,
"fields": [
{
"name": "行业",
"value": "{{ $json.industry || '未指定' }}",
"inline": true
},
{
"name": "规模",
"value": "{{ $json.company_size || '未指定' }}",
"inline": true
},
{
"name": "地点",
"value": "{{ $json.location || '未指定' }}",
"inline": true
},
{
"name": "联系",
"value": "{{ $json.contact_email || '未找到邮箱' }}",
"inline": false
},
{
"name": "电话",
"value": "{{ $json.phone || '未找到电话' }}",
"inline": false
},
{
"name": "服务",
"value": "{{ $json.key_services && $json.key_services.length > 0 ? $json.key_services.slice(0, 3).join(', ') : '未指定' }}",
"inline": false
},
{
"name": "网站",
"value": "[访问网站]({{ $node['Code2'].json.url || '#' }})",
"inline": false
},
{
"name": "合格原因",
"value": "{{ $json.qualification_reasons && $json.qualification_reasons.length > 0 ? $json.qualification_reasons.slice(0, 2).join(' • ') : '符合标准资格标准' }}",
"inline": false
}
],
"footer": {
"text": "由n8n潜在客户生成工作流生成"
},
"timestamp": ""
}
]
}结果
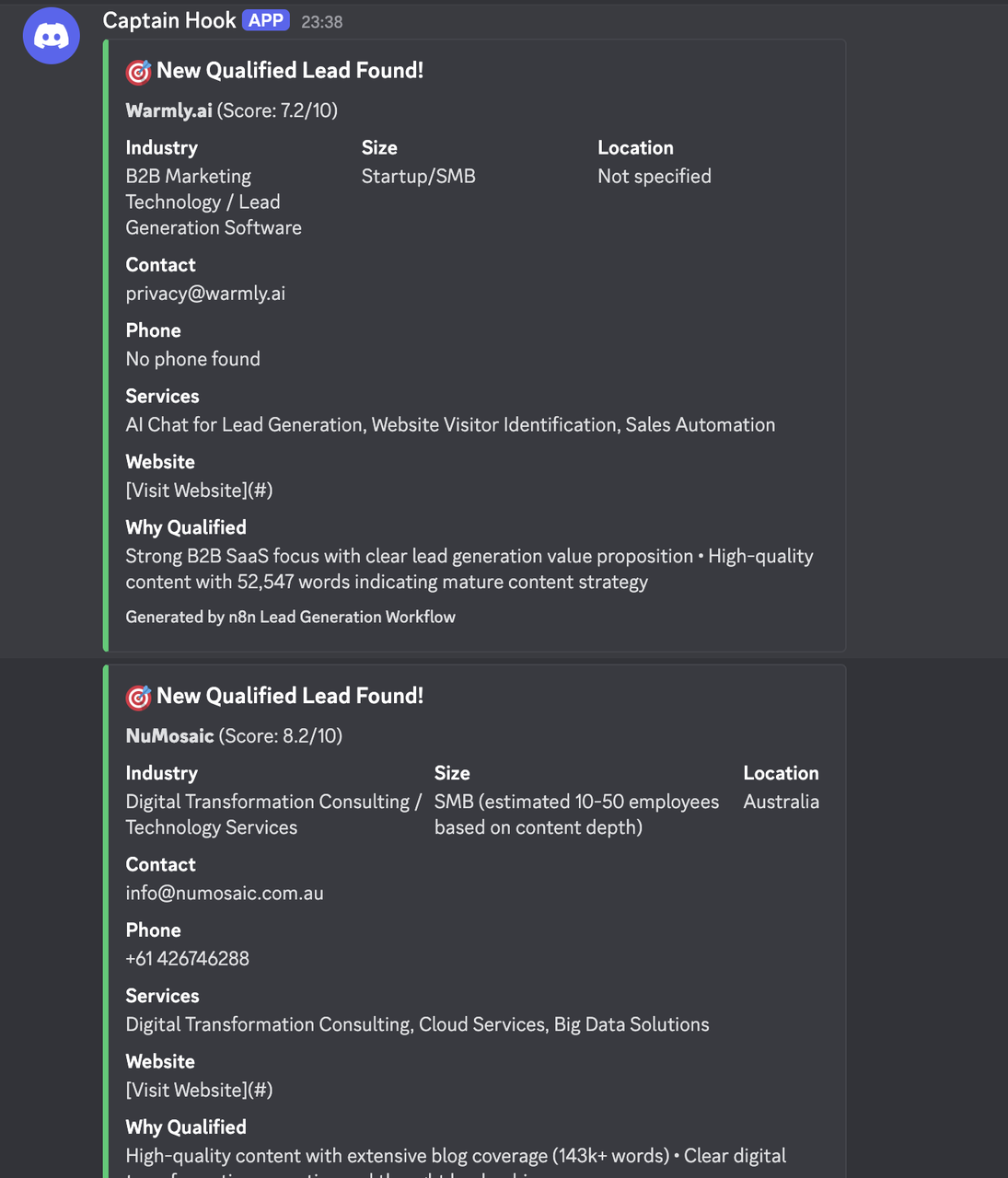
行业特定配置
SaaS/软件公司
搜索查询:
"软件即服务公司" "B2B软件" "企业软件"
"云软件" "API" "开发者" "订阅模式"
"服务平台" "集成"资格标准:
- 员工人数:20-500
- 使用现代技术栈
- 拥有API文档
- 在GitHub/技术内容上活跃
营销代理机构
搜索查询:
"数字营销代理" "B2B营销" "企业客户"
"营销自动化" "需求生成" "潜在客户生成"
"内容营销代理" "增长营销" "绩效营销"资格标准:
- 有客户案例研究
- 团队规模:10-100
- 专注于B2B
- 活跃的内容营销
电子商务/零售
搜索查询:
"电子商务公司" "在线零售" "D2C品牌"
"Shopify商店" "WooCommerce" "电子商务平台"
"在线市场" "数字商业" "零售技术"资格标准:
- 收入指标
- 多渠道存在
- 提到技术平台
- 增长轨迹信号
数据管理与分析
潜在客户数据库架构
为最大限度地提高实用性构建您的Google Sheets:
核心潜在客户信息:
- 公司名称、行业、规模、地点
- 联系邮箱、电话、网站
- 潜在客户评分、添加日期、来源查询
资格数据:
- 资格原因、决策者
- 下一步行动、跟进日期
- 分配的销售代表、潜在客户状态
丰富字段:
- LinkedIn URL、社交媒体存在
- 使用的技术、融资阶段
- 竞争对手、最近新闻
分析与报告
通过额外的表跟踪工作流表现:
每日摘要表:
- 每日产生的潜在客户
- 平均潜在客户评分
- 发现的顶级行业
- 转化率
搜索性能:
- 表现最佳的查询
- 地理分布
- 公司规模细分
- 按行业的成功率
投资回报率跟踪:
- 每潜在客户成本(API成本)
- 联系时间
- 转化为机会
- 收入归属
结论
这个智能B2B潜在客户生成工作流程通过自动化潜在客户的发现、资格评估和组织,转变了您的销售前景。通过将谷歌搜索与智能爬取和人工智能分析相结合,您可以建立一种系统的方法来构建您的销售管道。
该工作流程适应您的特定行业、目标公司规模和资格标准,同时通过人工智能驱动的分析保持高数据质量。通过正确的设置和监控,该系统成为您销售团队持续的合格潜在客户来源。
与Google Sheets的集成为销售团队提供了一个可访问的数据库,而Discord通知确保立即了解高价值潜在客户。模块化设计允许轻松适应不同的通知服务、CRM系统和数据存储解决方案。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


