
如何使用Scrapeless和Google Sheets构建自动化求职代理人
Advanced Data Extraction Specialist
保持最新的职位列表对求职者、招聘人员和科技爱好者至关重要。与其手动检查网站,您可以自动化整个过程——定期抓取职位网站并将结果保存到 Google Sheets 中以便于跟踪和分享。
本指南将向您展示如何使用 Scrapeless、n8n 和 Google Sheets 构建一个自动化的职位寻找代理。您将创建一个工作流,每6小时从 Y Combinator Jobs 页面抓取职位列表,提取结构化数据,并将其存储在电子表格中。
先决条件
在开始之前,请确保您具备以下条件:
- n8n:一个无代码自动化平台(自托管或云端)。
- Scrapeless API:从 Scrapeless 获取您的 API 密钥。
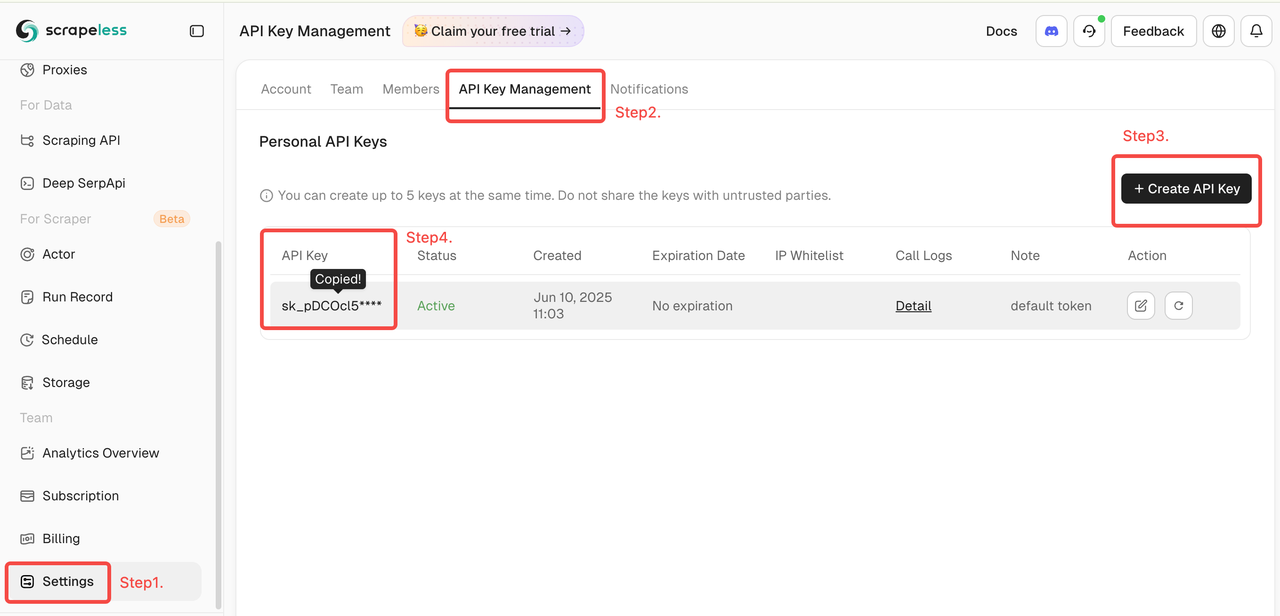
- 登录 Scrapeless 仪表板。
- 然后单击左侧的“设置” -> 选择“API 密钥管理” -> 单击“创建 API 密钥”。最后,单击您创建的 API 密钥以复制。
- Google Sheets 帐户:用于保存和查看职位数据。
- 目标网站:此示例使用 Y Combinator Jobs 页面。
如何使用 Scrapeless 和 Google Sheets 构建自动化的职位寻找代理
1. 调度触发器:每 6 小时运行一次
节点类型:调度触发器
设置:
- 时间间隔字段:
hours - 时间间隔值:
6
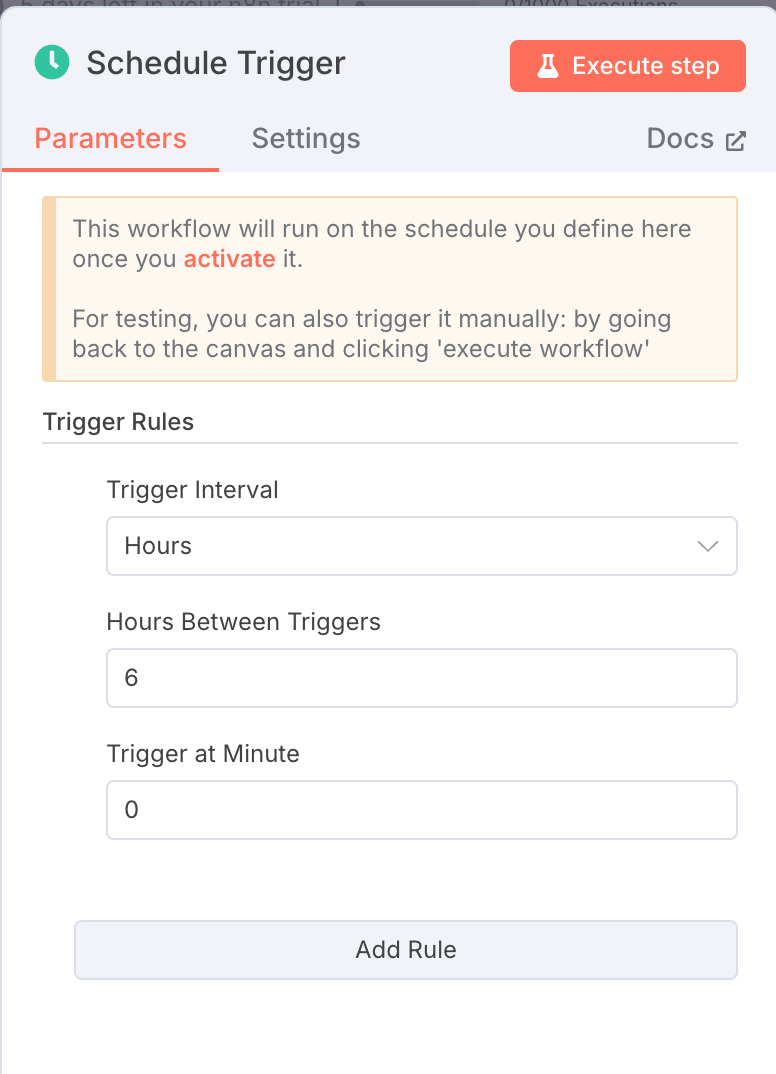
该节点确保您的工作流每6小时自动运行,无需手动输入。
2. Scrapeless 爬虫:抓取职位列表
节点类型:Scrapeless 节点
设置:
- 资源:
crawler - 操作:
crawl - URL:
https://www.ycombinator.com/jobs - 限制爬取页面数:2
- 凭证:
您的 Scrapeless API 密钥
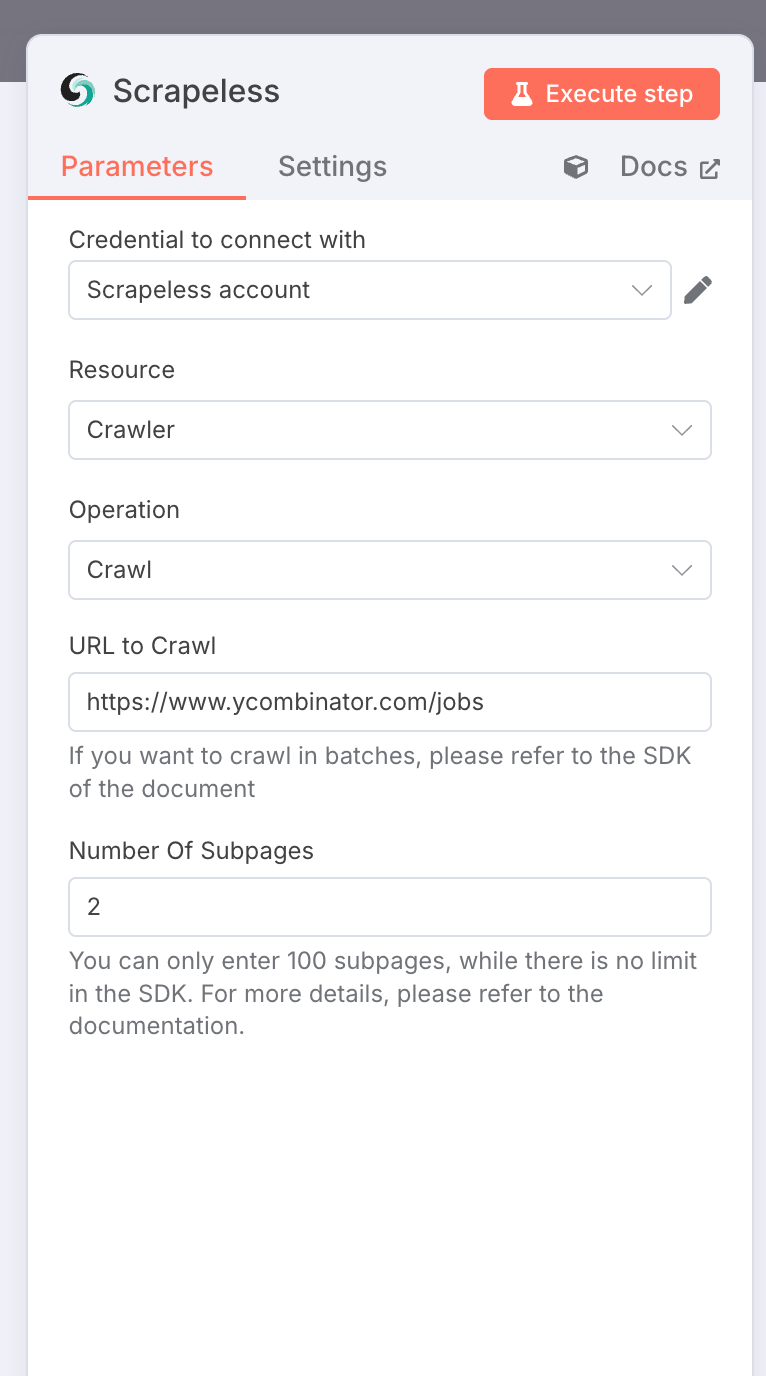
输出:包含丰富职位数据的 Markdown 格式对象数组。
3. 提取 Markdown 内容
节点类型:JavaScript 代码节点
目的:从原始抓取结果中仅提取 markdown 字段。
const raw = items[0].json;
const output = raw.map(obj => ({
json: {
markdown: obj.markdown,
}
}));
return output;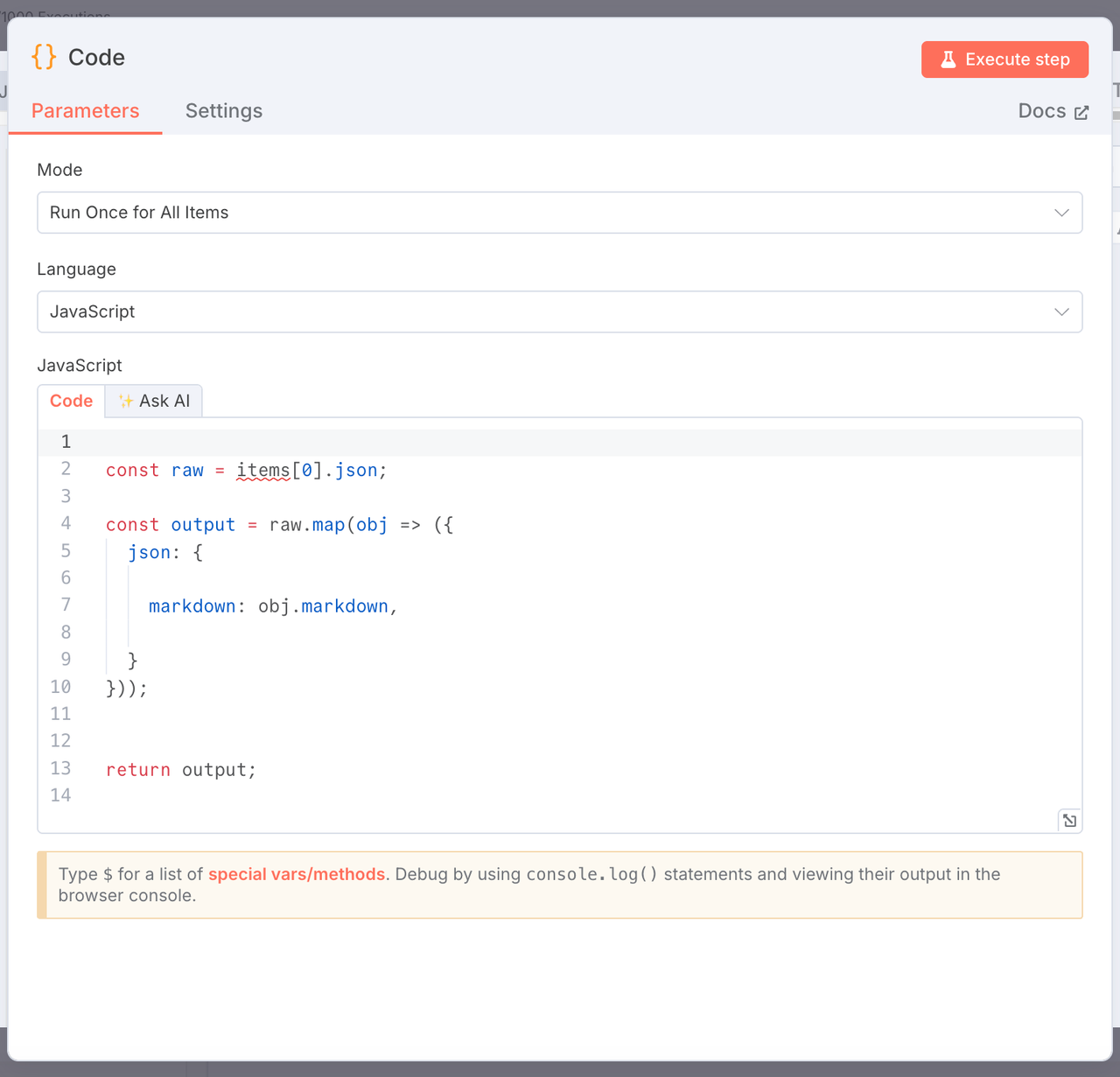
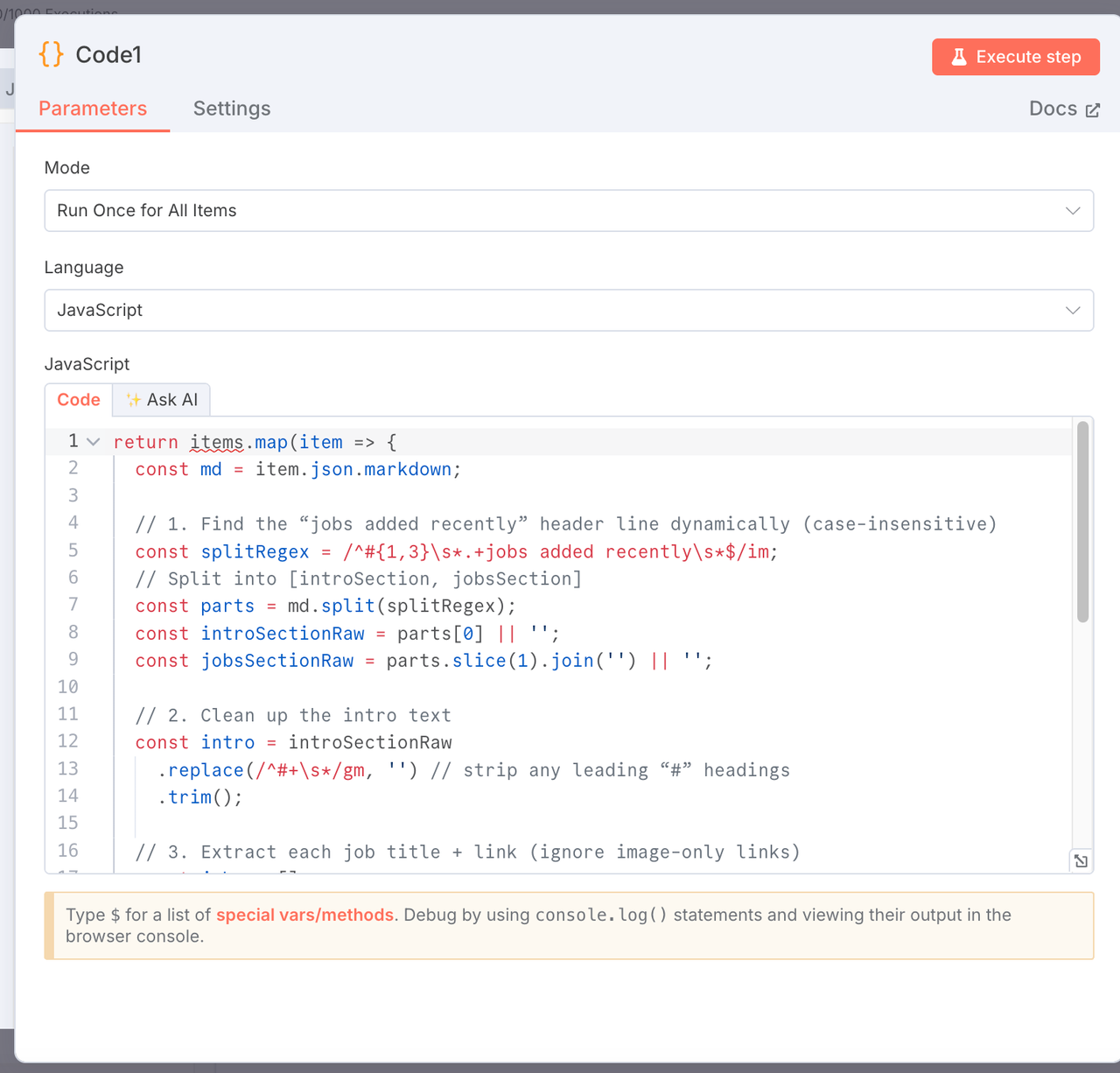
4. 解析 Markdown:提取简介和职位列表
节点类型:JavaScript 代码节点
目的:将 markdown 拆分为简介和结构化的职位名称及链接列表。
return items.map(item => {
const md = item.json.markdown;
const splitRegex = /^#{1,3}\s*.+jobs added recently\s*$/im;
const parts = md.split(splitRegex);
const introSectionRaw = parts[0] || '';
const jobsSectionRaw = parts.slice(1).join('') || '';
const intro = introSectionRaw.replace(/^#+\s*/gm, '').trim();
const jobs = [];
const re = /\-\s*\[(?!\!)([^\]]+)\]\((https?:\/\/[^\)]+)\)/g;
let match;
while ((match = re.exec(jobsSectionRaw))) {
jobs.push({
title: match[1].trim(),
link: match[2].trim(),
});
}
return {
json: {
intro,
jobs,
},
};
});
5. 扁平化职位以便导出
节点类型:JavaScript 代码节点
目的:将每个职位转换为单独的行以便于导出。
const output = [];
items.forEach(item => {
const intro = item.json.intro;
const jobs = item.json.jobs || [];
jobs.forEach(job => {
output.push({
json: {
intro,
jobTitle: job.title,
jobLink: job.link,
},
});
});
});
return output;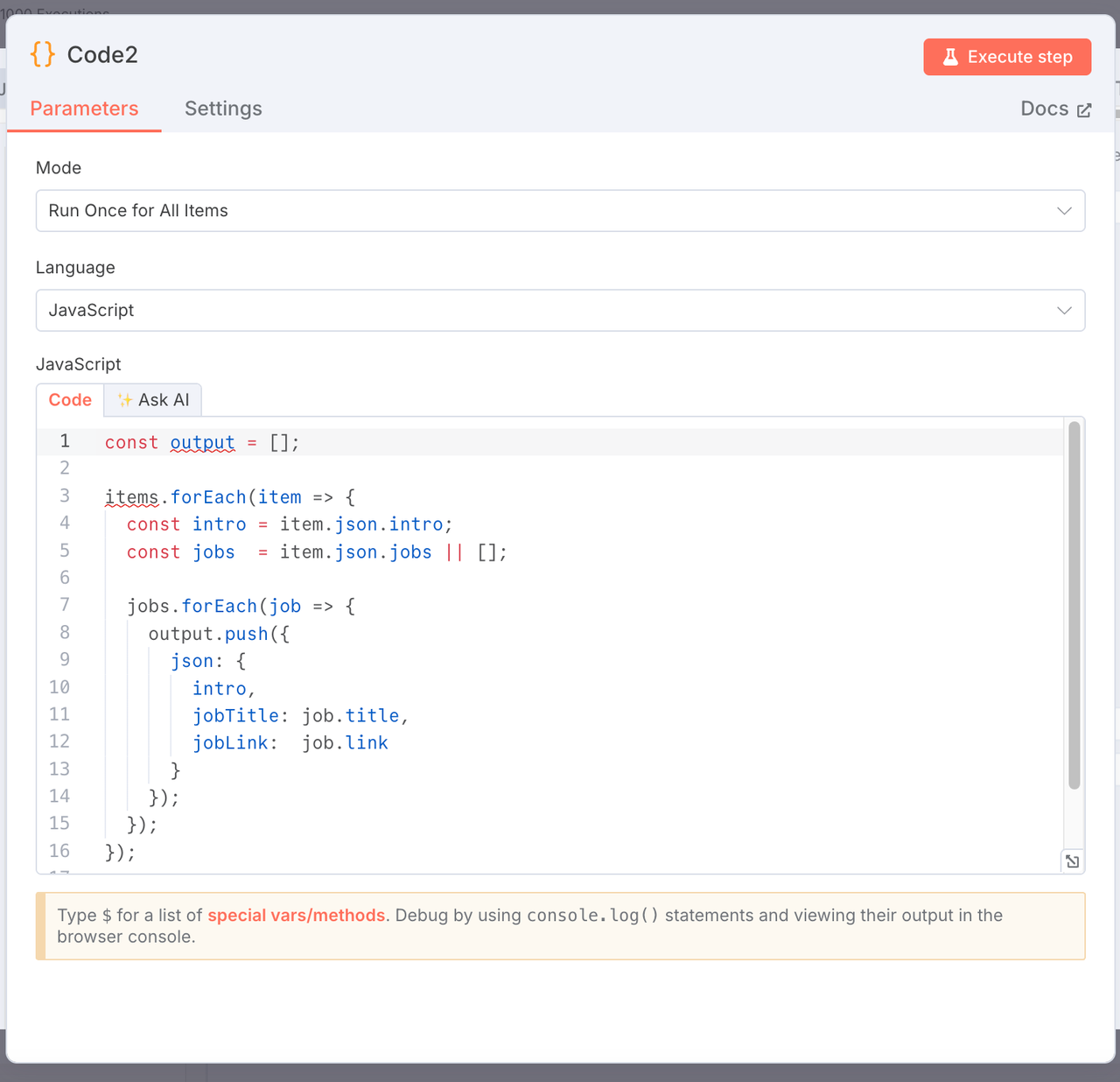
6. 附加到 Google Sheets
节点类型:Google Sheets 节点
设置:
- 操作:
append - 文档 URL:您也可以直接选择您创建的 Google 表格的名称(推荐方法)
- 表格名称:
Links(Tab ID:gid=0) - 列映射:
title←{{ $json.jobTitle }}link←{{ $json.jobLink }}
- 转换类型:
false - OAuth:连接您的 Google Sheets 帐户
最终数据将自动附加到您的表格中,以便于跟踪或进一步分析。
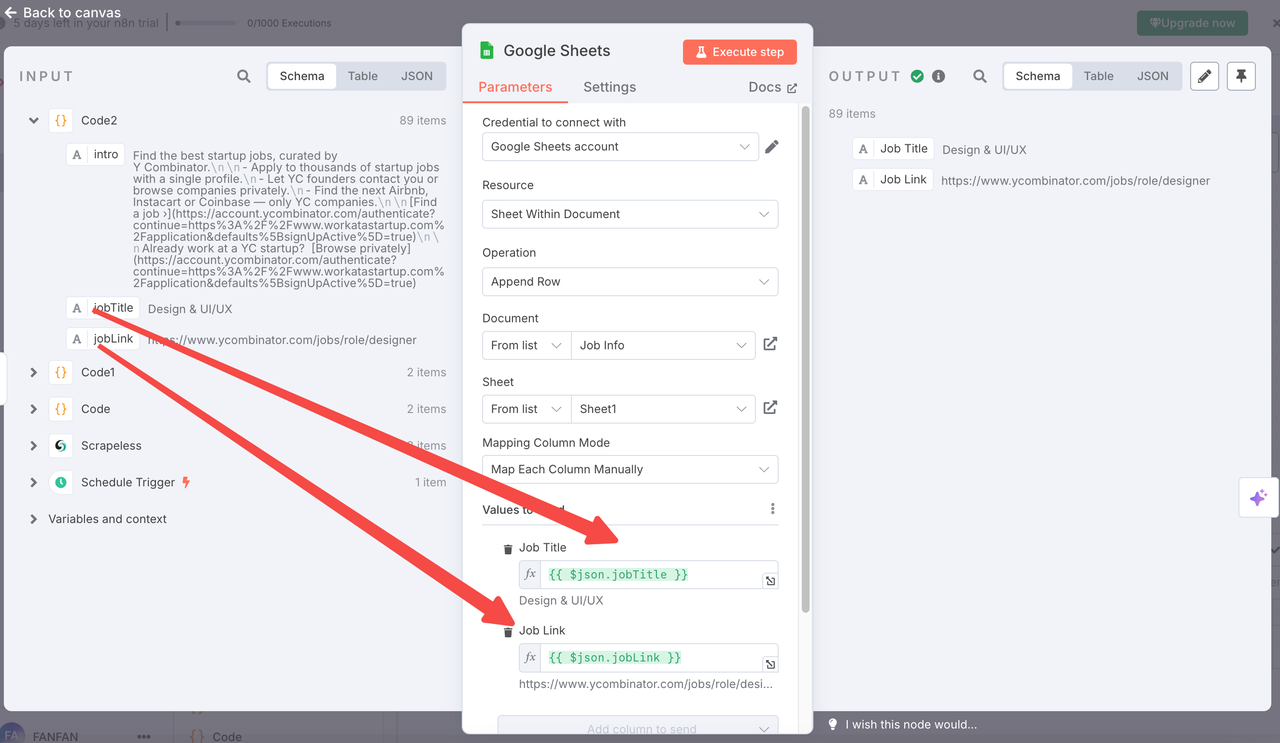
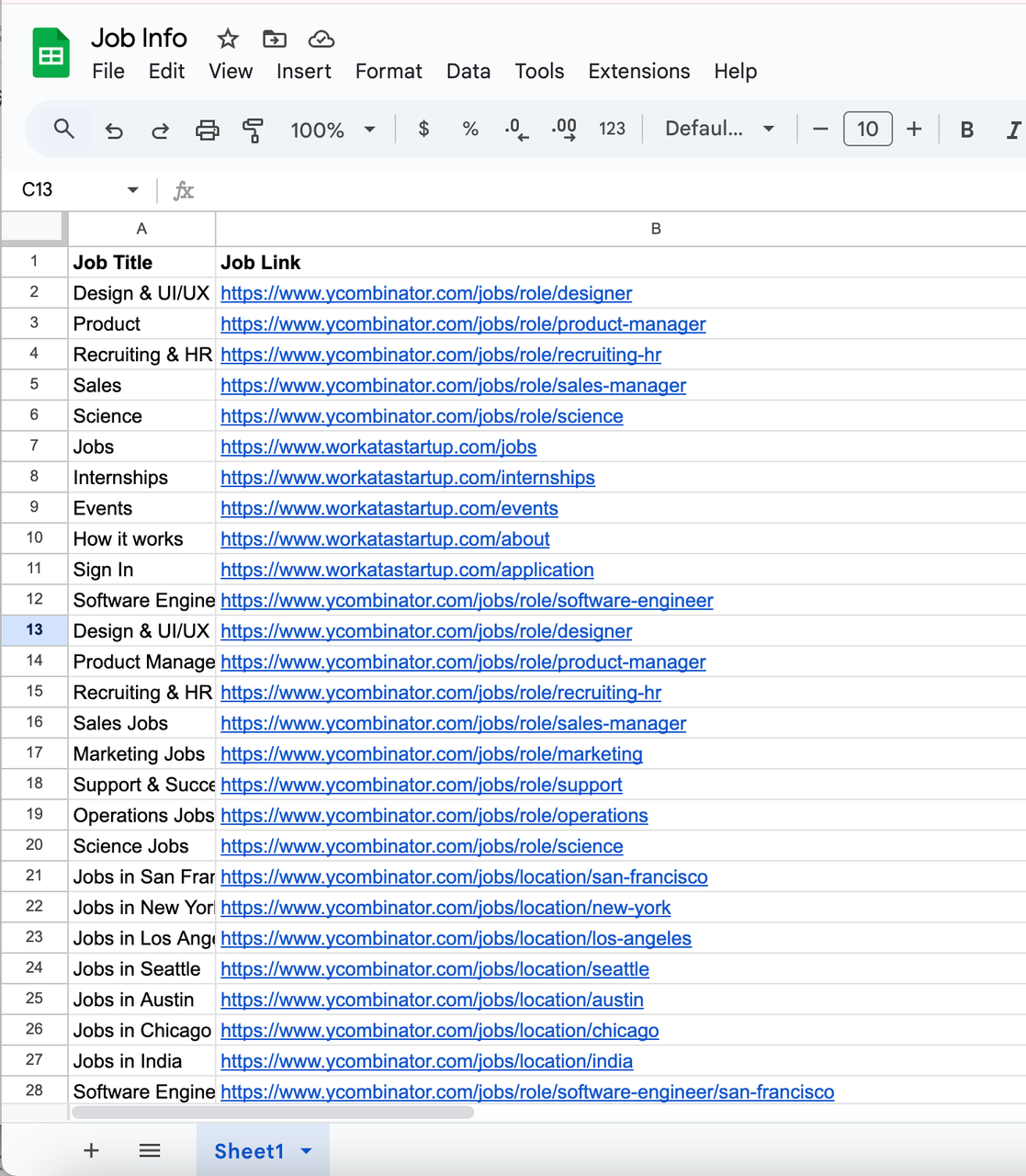
7. 输出结果示例
工作流图
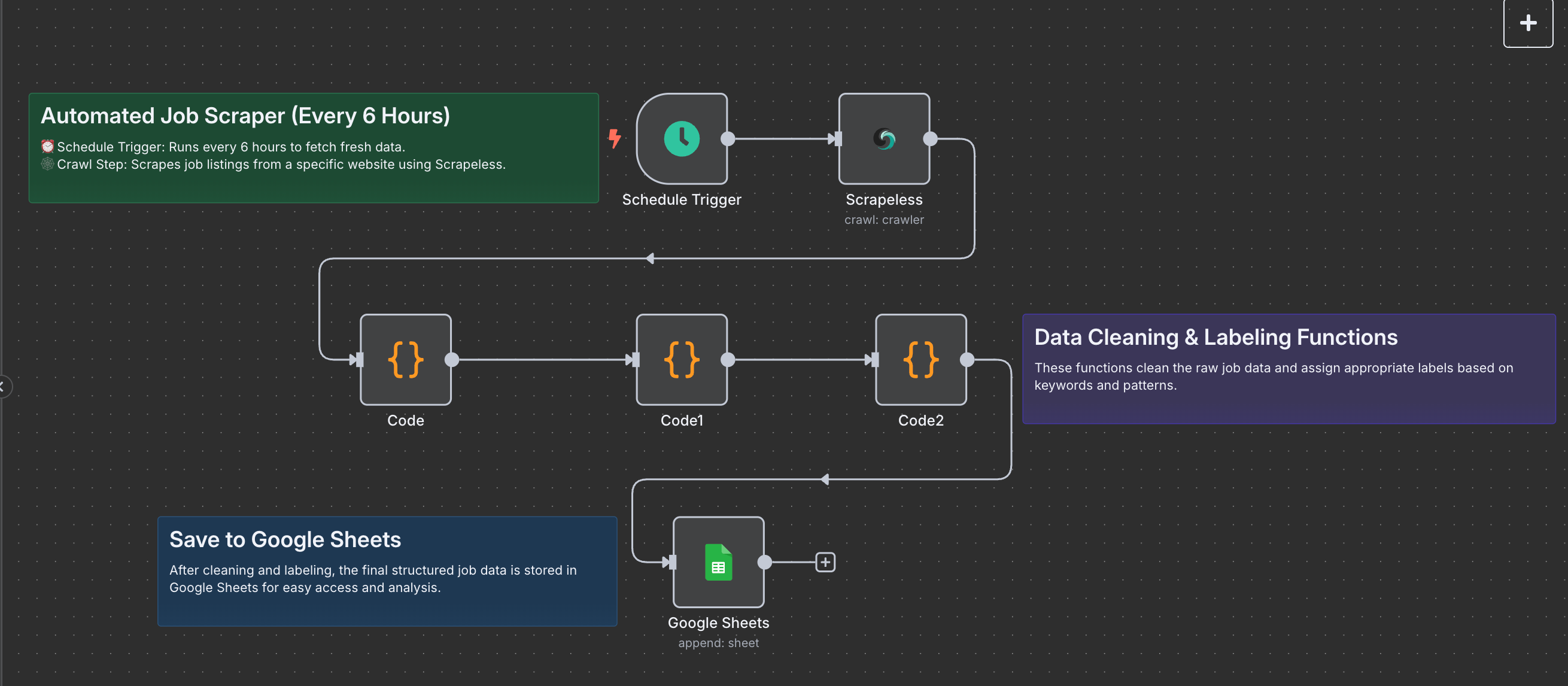
每个节点都是模块化和可自定义的。您可以根据需要更改网站、抓取频率或数据格式化逻辑。
自定义想法
- 抓取更多网站:用LinkedIn、AngelList或其他求职网站替换网址。
- 添加通知:将工作更新发送到Slack、Discord或电子邮件。
- 引入AI:使用GPT节点生成工作摘要或关键词标签。
适用的商业用例
该自动化求职代理可以应用于各种商业场景,包括:
- 招聘机构: 持续监控专业招聘网站和公司职业页面,为其人才库发掘新职位。
- 初创公司孵化器和加速器: 跟踪投资组合公司(如Y Combinator初创企业)的招聘活动,并保持对市场需求的了解。
- 人力资源和人才团队: 通过跟踪竞争对手公司或行业领导者的职位发布来自动化竞争情报。
- 求职聚合平台: 从多个来源汇总职位信息,简化发布到自己平台的流程,无需手动抓取。
- 自由职业者和远程工作社区: 为面向特定受众的新闻通讯、社区论坛或求职网站策划新鲜的工作列表。
- 市场研究团队: 分析各行业的招聘趋势,以获取市场增长、需求技术栈或新兴角色的见解。
该工作流程特别适合需要定期、结构化和可扩展的就业市场情报的公司,节省无数小时的手动工作,并确保数据的准确性。
自动化求职代理工作流程
结论
通过Scrapeless、n8n和Google Sheets,您可以轻松构建一个完全自动化的求职代理,抓取职位信息、清理数据并保存到电子表格中。该设置灵活、成本高效,非常适合希望实时监控职位而无需手动操作的个人、招聘人员或团队。
在Scrapeless,我们仅访问公开可用的数据,并严格遵循适用的法律、法规和网站隐私政策。本博客中的内容仅供演示之用,不涉及任何非法或侵权活动。我们对使用本博客或第三方链接中的信息不做任何保证,并免除所有责任。在进行任何抓取活动之前,请咨询您的法律顾问,并审查目标网站的服务条款或获取必要的许可。


