Loading...
🎯 Trình duyệt đám mây tùy chỉnh, chống phát hiện được hỗ trợ bởi Chromium tự phát triển, thiết kế dành cho trình thu thập dữ liệu web và tác nhân AI. 👉Dùng thử ngay
Hướng dẫn toàn diện nhất, được tạo ra cho tất cả các nhà phát triển cào web.
Scrapless cung cấp các dịch vụ tự động hóa và tự động hóa web được cung cấp bởi AI, mạnh mẽ và có thể mở rộng được tin tưởng bởi các doanh nghiệp hàng đầu. Các giải pháp cấp doanh nghiệp của chúng tôi được thiết kế để đáp ứng nhu cầu dự án của bạn, với sự hỗ trợ kỹ thuật chuyên dụng trong suốt. Với một nhóm kỹ thuật mạnh mẽ và thời gian phân phối linh hoạt, chúng tôi chỉ tính phí cho dữ liệu thành công, cho phép trích xuất dữ liệu hiệu quả trong khi bỏ qua các giới hạn.
Liên hệ với chúng tôi ngay bây giờ để thúc đẩy sự phát triển kinh doanh của bạn.
Cung cấp chi tiết liên hệ của bạn và chúng tôi sẽ nhanh chóng liên hệ để cung cấp bản demo và giới thiệu sản phẩm. Chúng tôi đảm bảo thông tin của bạn vẫn được bảo mật, tuân thủ các tiêu chuẩn GDPR.
Bản dùng thử miễn phí của bạn đã sẵn sàng! Đăng ký một tài khoản không cần thiết miễn phí và bản dùng thử của bạn sẽ được kích hoạt ngay lập tức trong tài khoản của bạn.
Bảng chuẩn mã nguồn mở so sánh Trình duyệt Scraping Scrapeless với 4 công cụ chống phát hiện trên một thử thách Cloudflare trực tiếp. Xem tỷ lệ thành công trên các IP dân cư và trung tâm dữ liệu.

Tìm hiểu cách sử dụng gói Playwright stealth trong Python và Node.js để sửa đổi ngón tay cái của trình duyệt, quản lý proxy và vượt qua sự phát hiện bot cho việc thu thập dữ liệu web.

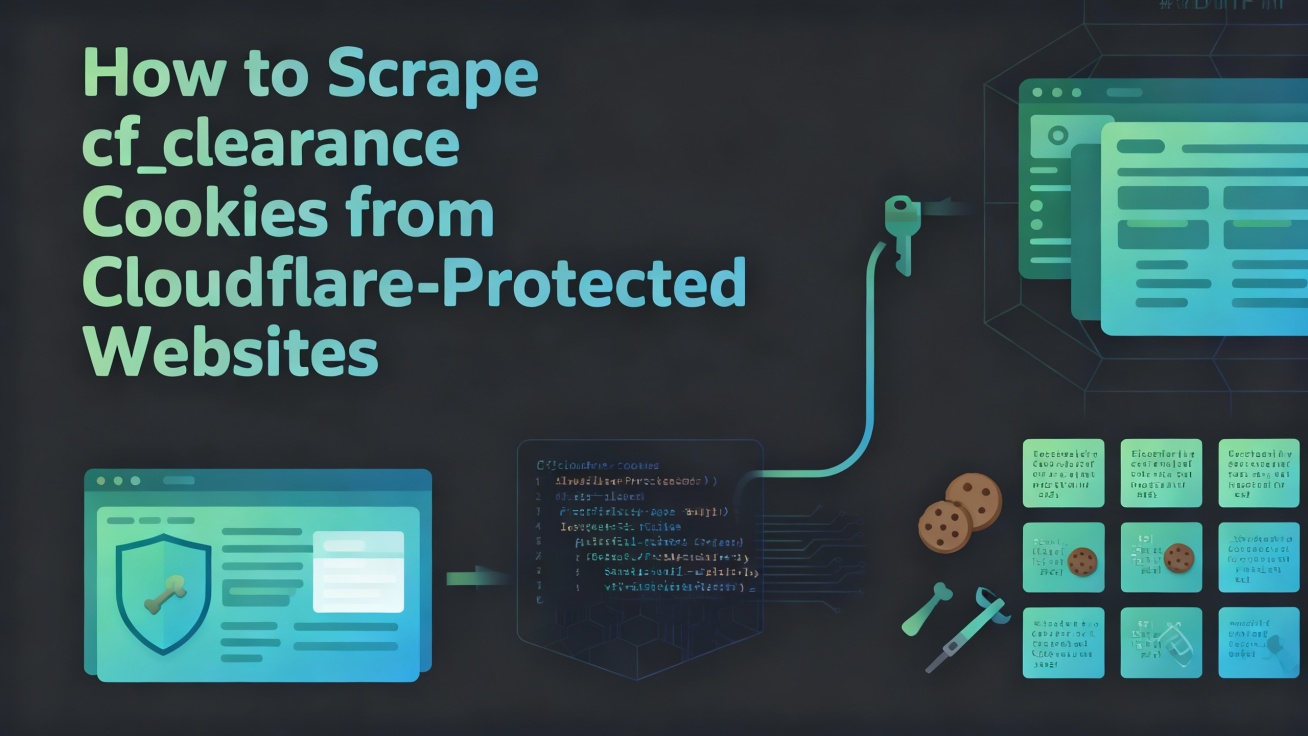
Tìm hiểu cách hoạt động của cookie cf_clearance của Cloudflare, các mức độ thông qua của nó, và cách duy trì các phiên quét dữ liệu liên tục mà không cần quản lý mã thông báo thủ công.
C++ là một trình phân tích cú pháp tuyệt vời và là một khách hàng thu thập dữ liệu khó khăn. Hãy để libcurl lấy dữ liệu thông qua API kết xuất và libxml2 phân tích – một dòng g++, 20 tiêu đề đã được phân tích, xác minh trực tiếp.

Một trình thu thập tin tức là hai vòng lặp sạch: phát hiện các liên kết bài viết, sau đó lấy và trích xuất từng câu chuyện. Phát hiện và một bài viết 40 đoạn được lấy thông tin xác minh trực tiếp.

Bốn loại phân trang, bốn điều kiện dừng. Theo các điều khiển tiếp theo/tải thêm của trang thay vì đoán URL — nút tiếp theo được xác minh tại 10 trang, 100 mục.

Instagram truy xuất từ các API JSON của riêng mình - vì vậy hãy gọi chúng trực tiếp từ một phiên đã được khởi động với tiêu đề x-ig-app-id. Việc trích xuất hồ sơ được xác minh trực tiếp.

Thuộc tính src là nơi ít đáng tin cậy nhất để tìm một hình ảnh. Cuộn trước, đọc currentSrc, giữ lại siêu dữ liệu và lấy byte thông qua phiên — 20 hình ảnh được xác thực trực tiếp.



