
Thuật toán Web Crawler bằng Python: Hướng dẫn từng bước năm 2025
Advanced Data Extraction Specialist
Với sự gia tăng mạnh mẽ lượng dữ liệu, Web Crawling đã trở thành một công cụ quan trọng trong các lĩnh vực như khoa học dữ liệu, nghiên cứu thị trường và phân tích cạnh tranh. Trong số các ngôn ngữ lập trình phổ biến, Python đã trở thành ngôn ngữ được ưa chuộng để phát triển các web crawler (Python web crawlers) nhờ cú pháp ngắn gọn và hỗ trợ thư viện mạnh mẽ. Cho dù là trích xuất dữ liệu từ nền tảng thương mại điện tử hay thu thập các bài báo mới nhất từ một trang web tin tức, web crawlers Python đều có thể hoàn thành nhiệm vụ một cách hiệu quả. Bài viết này sẽ cung cấp cho bạn một hướng dẫn từng bước phiên bản 2025 để giúp bạn thành thạo cách sử dụng Python để xây dựng một web crawler mạnh mẽ, từ kiến thức cơ bản đến các kỹ thuật nâng cao, để cải thiện toàn diện khả năng web crawling của bạn.
Web Crawler trong Python là gì và tại sao nó quan trọng đối với việc trích xuất dữ liệu
Web crawler là một chương trình tự động được thiết kế để thu thập thông tin từ Internet theo các quy tắc cụ thể. Nó truy cập các trang web bằng cách mô phỏng trình duyệt, trích xuất dữ liệu cần thiết và lưu trữ cục bộ. Quá trình này thường bao gồm việc chọn URL ban đầu, tải xuống nội dung trang web, phân tích cú pháp HTML, theo dõi các liên kết và lặp lại quá trình này để thu thập thêm dữ liệu. Vai trò của web crawlers trong việc trích xuất dữ liệu là rất quan trọng vì nó có thể thu thập thông tin hiệu quả từ một lượng lớn các trang web và hỗ trợ việc xây dựng chỉ mục công cụ tìm kiếm và các nhiệm vụ phân tích dữ liệu.
Ưu điểm của Web Crawler trong Python
Có nhiều ưu điểm khi viết web crawlers bằng Python, đặc biệt là về tính linh hoạt và dễ sử dụng. Thứ nhất, cú pháp của Python ngắn gọn và dễ học, cho phép các nhà phát triển nhanh chóng bắt đầu và triển khai logic crawling phức tạp. Thứ hai, Python có rất nhiều thư viện và framework, chẳng hạn như Scrapy và BeautifulSoup, giúp đơn giản hóa đáng kể quá trình phân tích cú pháp trang web và trích xuất dữ liệu. Ngoài ra, tính chất đa nền tảng của Python cho phép crawlers chạy trên các hệ điều hành khác nhau, do đó tăng tính linh hoạt trong việc phát triển và triển khai.
💡 Bài đọc liên quan: Web Scraping với Python năm 2025
Kỹ thuật nâng cao cho Web Crawling trong Python
Khi nói đến việc phát triển một web crawler Python, có một số kỹ thuật nâng cao có thể nâng cao khả năng web scraping của bạn, đặc biệt là khi xử lý nội dung động và các biện pháp chống scraping. Những chiến lược này rất quan trọng để khắc phục các thách thức như kết xuất JavaScript, giải quyết CAPTCHA và chặn IP, thường gặp khi xây dựng một web crawler Python. Dưới đây là một số chiến lược chính:
- Xử lý các trang web động:
- Sử dụng Selenium: Thư viện này cho phép bạn tự động hóa các hành động của trình duyệt, cho phép bạn chờ nội dung JavaScript tải xong trước khi trích xuất dữ liệu.
- Thực hiện các yêu cầu Ajax: Phân tích các yêu cầu mạng trong công cụ dành cho nhà phát triển của trình duyệt để xác định các điểm cuối API. Sử dụng thư viện requests trong Python để gửi các yêu cầu trực tiếp đến các điểm cuối này để lấy dữ liệu hiệu quả hơn.
- Bỏ qua các biện pháp chống Scraping:
- Sử dụng Proxy: Triển khai các IP proxy luân phiên để phân phối các yêu cầu trên nhiều địa chỉ IP, khiến các trang web khó phát hiện và chặn hoạt động scraping của bạn.
- Giả mạo User-Agent: Thay đổi chuỗi User-Agent trong tiêu đề yêu cầu của bạn để bắt chước các trình duyệt phổ biến. Điều này giúp giảm khả năng bị gắn cờ là bot.
- Nâng cao hiệu quả:
- Triển khai lập trình không đồng bộ: Sử dụng các thư viện như asyncio và aiohttp để thực hiện các yêu cầu đồng thời, tăng tốc độ quá trình trích xuất dữ liệu đáng kể.
- Tận dụng XPath hoặc Bộ chọn CSS: Các công cụ này cho phép nhắm mục tiêu chính xác các phần tử HTML, cải thiện độ chính xác và hiệu quả của việc trích xuất dữ liệu.
Cài đặt môi trường Python cho Web Crawling
Trước khi bắt đầu thiết lập môi trường Web Crawling, bạn cần chuẩn bị một số môi trường cơ bản:
- Python 3+: Tải trình cài đặt, nhấp đúp vào nó và làm theo trình hướng dẫn cài đặt.
- Python IDE: Visual Studio Code hoặc PyCharm với tiện ích mở rộng Python.
Sau đó, nhập lệnh sau vào terminal để khởi tạo một project có tên python-crawler:
mkdir python-crawler
cd python-crawler
python -m venv envKhi thực hiện web crawling, chúng ta cần sử dụng hai thư viện cho yêu cầu HTTP và phân tích cú pháp HTML. Hai thư viện phổ biến nhất trong Python là:
- requests: Một thư viện client HTTP mạnh mẽ có thể gửi yêu cầu HTTP và xử lý phản hồi.
- beautifulsoup4: Một trình phân tích cú pháp HTML và XML đầy đủ tính năng.
Nhập các lệnh sau vào terminal để cài đặt chúng:
pip install beautifulsoup4 requestsTrong thư mục project, tạo file crawler.py và import các phụ thuộc của project:
import requests
from bs4 import BeautifulSoupProject đã được xây dựng, hãy bắt đầu crawling web.
Cách Scrape dữ liệu Amazon bằng Python
Scraping dữ liệu từ Amazon có thể thu được nội dung về thông tin sản phẩm, đánh giá và xu hướng. Tuy nhiên, các biện pháp chống scraping của Amazon, chẳng hạn như CAPTCHA và giới hạn tốc độ IP, làm cho quá trình này trở nên khó khăn. Trong hướng dẫn này, chúng tôi sẽ hướng dẫn bạn cách scrape dữ liệu Amazon bằng Python.
Cách xây dựng một Web Crawler đơn giản trong Python
Sau khi thiết lập môi trường crawling trang web theo các bước trên, bạn cần làm theo các bước dưới đây để tạo một Simple Web Crawler trong Python.
Bước 1: Web Crawler cơ bản sử dụng Requests và BeautifulSoup
Ví dụ mã
import requests
from bs4 import BeautifulSoup
class SimpleWebCrawler:
def __init__(self, start_url):
self.start_url = start_url
self.visited_urls = set()
self.urls_to_visit = [start_url]
def crawl(self):
while self.urls_to_visit:
current_url = self.urls_to_visit.pop(0)
if current_url in self.visited_urls:
continue
print(f"Crawling: {current_url}")
response = requests.get(current_url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
self.visited_urls.add(current_url)
self.extract_links(soup)
def extract_links(self, soup):
for link in soup.find_all('a', href=True):
absolute_link = link['href']
if absolute_link not in self.visited_urls and absolute_link not in self.urls_to_visit:
self.urls_to_visit.append(absolute_link)
if __name__ == "__main__":
crawler = SimpleWebCrawler("https://example.com")
crawler.crawl()Giải thích
- Khởi tạo: Lớp SimpleWebCrawler được khởi tạo với một URL bắt đầu và đặt để theo dõi các URL đã truy cập và các URL cần truy cập.
- Logic crawling: Phương thức crawl xử lý các URL trong danh sách urls_to_visit, lấy nội dung của từng trang.
- Trích xuất liên kết: Phương thức extract_links tìm tất cả các siêu liên kết trên trang và thêm chúng vào danh sách các URL cần truy cập nếu chúng chưa được truy cập.
Bước 2: Sử dụng Scrapy cho Crawling phức tạp hơn
Nếu dự án của bạn yêu cầu các tính năng nâng cao hơn như xử lý nhiều yêu cầu đồng thời hoặc scraping các trang web lớn một cách hiệu quả, hãy xem xét sử dụng Scrapy.
Ví dụ Scrapy cơ bản
import scrapy
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = ['https://example.com']
def parse(self, response):
for link in response.css('a::attr(href)').getall():
yield response.follow(link, self.parse)Chạy Scrapy
Bạn có thể chạy spider Scrapy của mình bằng dòng lệnh:
scrapy crawl my_spiderCách Scrape dữ liệu Amazon bằng Python
Tiếp theo, phần này sẽ giới thiệu chi tiết cách sử dụng Python để crawl dữ liệu Amazon.
Bước 1. Đầu tiên, chúng ta cần lấy trang sản phẩm và sử dụng phương thức get để thực hiện một yêu cầu:
url = "https://www.amazon.com/Breathable-Athletic-Sneakers-Comfortable-Lightweight/dp/B0CMTJ7JS7/?_encoding=UTF8&pd_rd_w=XsBL5&content-id=amzn1.sym.61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_p=61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_r=8M3TP83H0CZQD08XHGBR&pd_rd_wg=6d3lc&pd_rd_r=a6a366f4-4ec7-491f-87ec-67672fe48a55&ref_=pd_hp_d_btf_cr_simh&th=1"
response = requests.get(url)response.content chứa tài liệu HTML được máy chủ tạo ra. Điều này được đưa vào BeautifulSoup, và tùy chọn html.parser cho phép bạn chỉ định trình phân tích cú pháp mà thư viện sẽ sử dụng:
soup = BeautifulSoup(response.content, "html.parser")Bước 2. Tiếp theo, chúng ta cần lấy dữ liệu mà chúng ta muốn crawl. Chúng ta có thể sử dụng bộ chọn CSS để lấy các phần tử tương ứng.
BeautifulSoup cung cấp hai phương thức, select và select_one, cả hai đều hỗ trợ chiến lược bộ chọn CSS.
Trước khi viết mã, bạn có thể mở công cụ devtool để xem CSS của phần tử.
- Lấy tiêu đề sản phẩm:
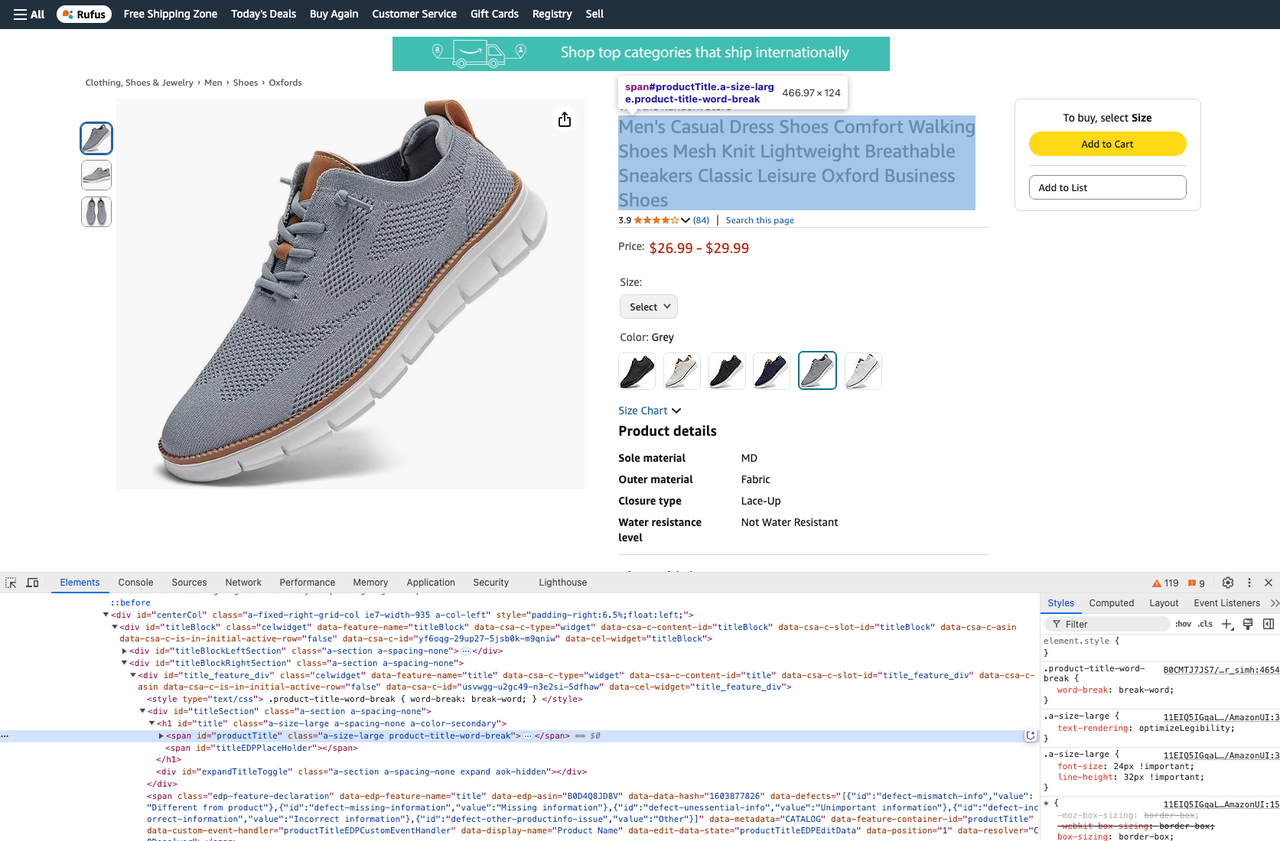
product_title = soup.select_one("#productTitle").text- Lấy mô tả sản phẩm:
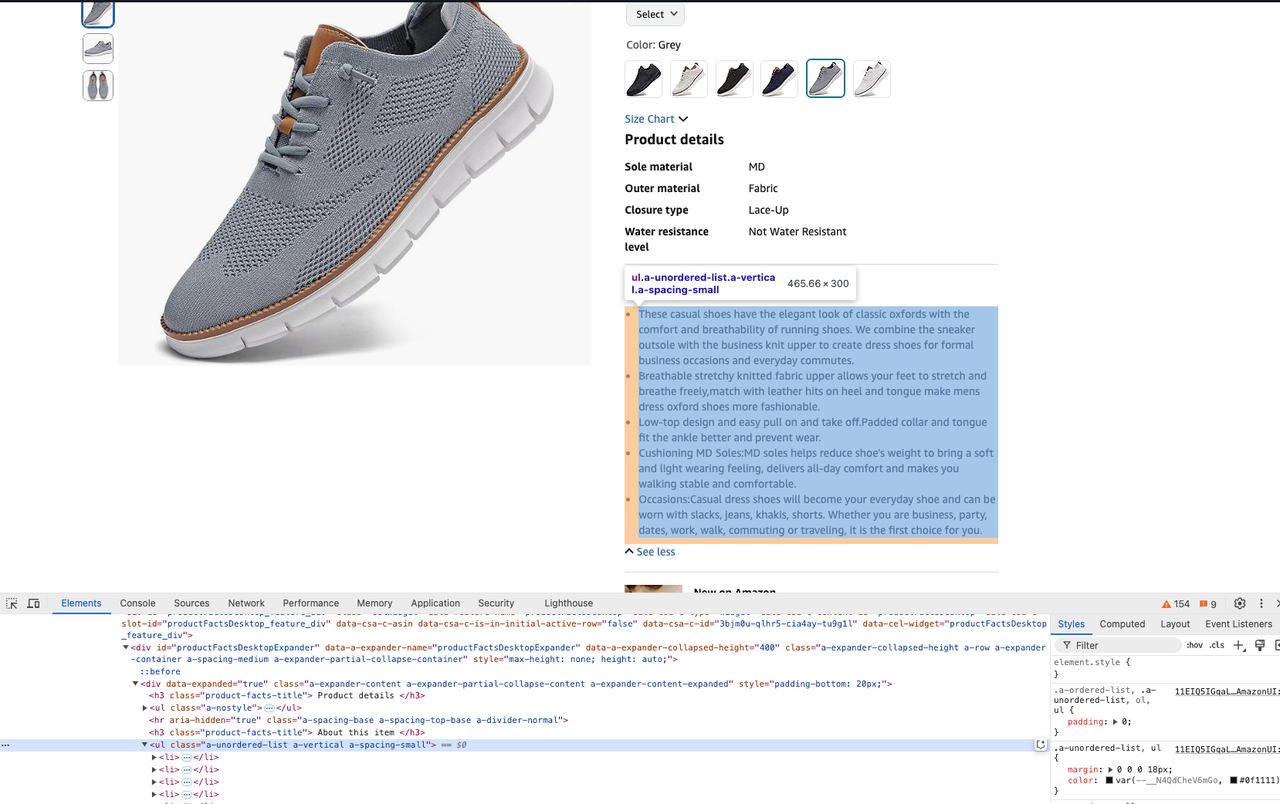
description = soup.select_one("#productFactsDesktopExpander ul.a-unordered-list").text- Lấy giá của một sản phẩm:
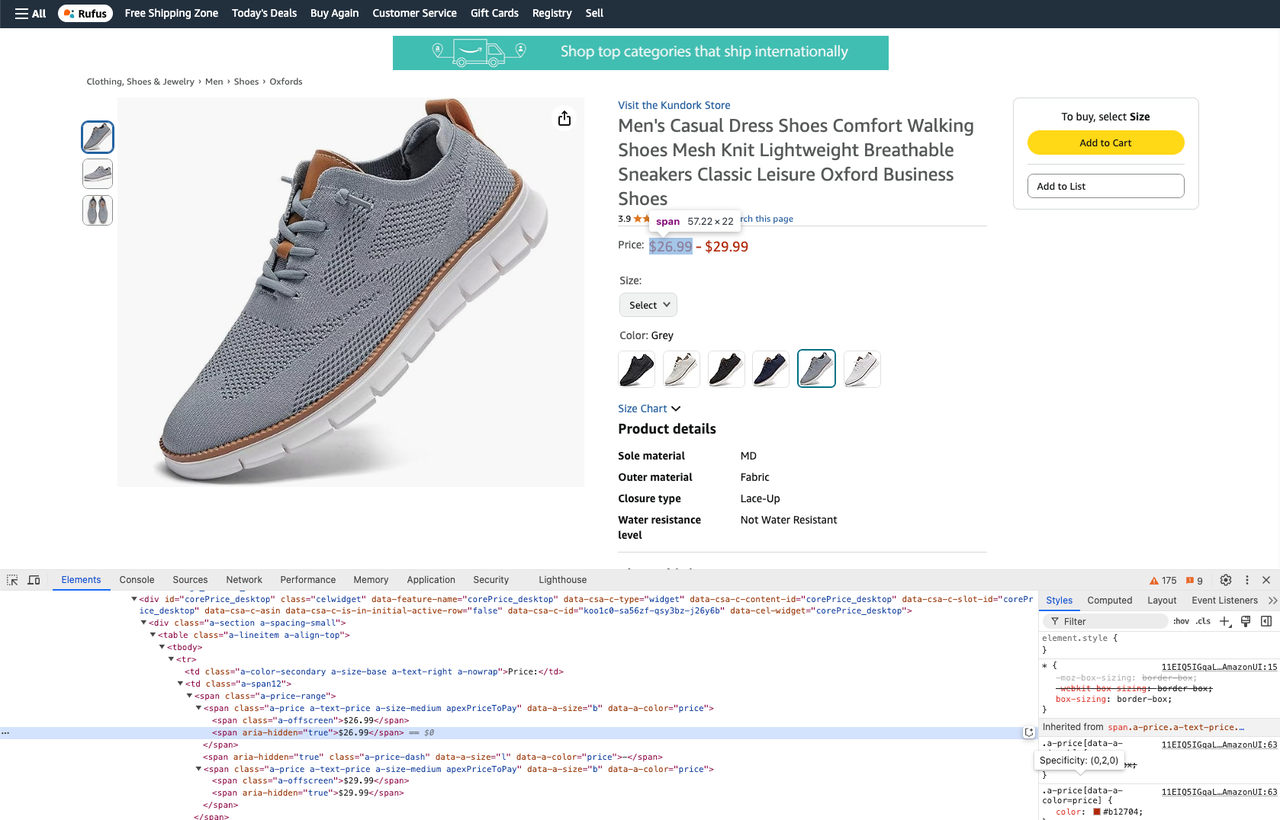
prices = soup.select_one(".a-price-range")
real_price = prices.select(".a-offscreen")
min_price = real_price[0].text
max_price = real_price[1].text- Lấy đánh giá sản phẩm:
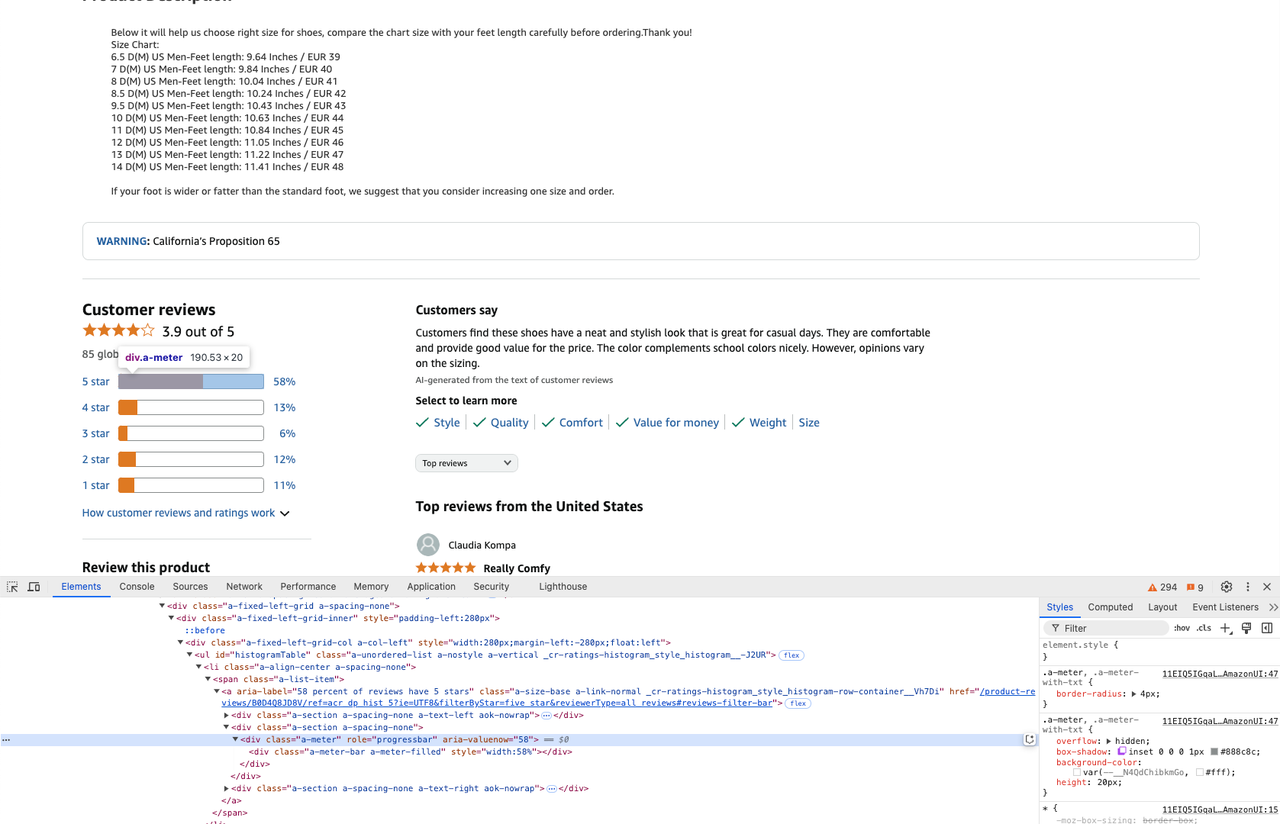
star_info = soup.select('.a-meter[role=progressbar]')
five_star = star_info[0].attrs['aria-valuenow'] + '%'
four_star = star_info[1].attrs['aria-valuenow'] + '%'Bước 3. Bây giờ chúng ta đã crawl trang web và lấy được dữ liệu mình muốn, chúng ta có thể trích xuất thông tin đã crawl vào một file csv.
Để làm điều này, hãy thêm đoạn sau vào đầu file:
import csvViết dữ liệu đã crawl vào một file csv:
with open("product.csv", "w") as csv_file:
writer = csv.writer(csv_file)
writer.writerow([
"product_title",
"description",
"min_price",
"max_price",
"five_star",
"four_star"
])
writer.writerow([
product_title,
description,
min_price,
max_price,
five_star,
four_star
])Chạy lệnh sau trong terminal để thực thi lệnh crawl:
python crawler.pyBước 4. Sau khi thực hiện xong, chúng ta có thể thấy file product.csv xuất hiện trong thư mục của bạn. Mở file này và chúng ta có thể thấy kết quả dữ liệu mà chúng ta đã crawl:

Mã hoàn chỉnh như sau:
import csv
import requests
from bs4 import BeautifulSoup
url = "https://www.amazon.com/Breathable-Athletic-Sneakers-Comfortable-Lightweight/dp/B0CMTJ7JS7/?_encoding=UTF8&pd_rd_w=XsBL5&content-id=amzn1.sym.61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_p=61d4ee60-9341-4d7a-912d-bc661951aa32&pf_rd_r=8M3TP83H0CZQD08XHGBR&pd_rd_wg=6d3lc&pd_rd_r=a6a366f4-4ec7-491f-87ec-67672fe48a55&ref_=pd_hp_d_btf_cr_simh&th=1"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
product_title = soup.select_one("#productTitle").text
description = soup.select_one("#productFactsDesktopExpander ul.a-unordered-list").text
prices = soup.select_one(".a-price-range")
real_price = prices.select(".a-offscreen")
min_price = real_price[0].text
max_price = real_price[1].text
star_info = soup.select('.a-meter[role=progressbar]')
five_star = star_info[0].attrs['aria-valuenow'] + '%'
four_star = star_info[1].attrs['aria-valuenow'] + '%'
with open("product.csv", "w") as csv_file:
writer = csv.writer(csv_file)
writer.writerow([
"product_title",
"description",
"min_price",
"max_price",
"five_star",
"four_star"
])
writer.writerow([
product_title,
description,
min_price,
max_price,
five_star,
four_star
])API Scraping Amazon của Scrapeless có thể đơn giản hóa các tác vụ Web Crawling của bạn như thế nào
API Scraping Amazon của Scrapeless được thiết kế để tự động hóa và đơn giản hóa quá trình trích xuất dữ liệu từ Amazon, làm cho nó trở thành một công cụ có giá trị đối với các nhà phát triển và doanh nghiệp. Không giống như việc sử dụng phương pháp web crawler Python, thường yêu cầu mã hóa thủ công rộng rãi và xử lý nhiều thách thức như luân phiên IP hoặc bỏ qua CAPTCHA, API Scrapeless hợp lý hóa quá trình này. Nó cung cấp một loạt các tính năng giúp tăng hiệu quả, cho phép người dùng dễ dàng thu thập dữ liệu như giá sản phẩm, đánh giá và mô tả mà không cần lập trình Python phức tạp.
Ngoài API Scraping Amazon, Scrapeless còn bao gồm API Scraping Shopee, API Scraping Lazada, API Scraping Xu hướng tìm kiếm Google, API Scraping Google Flights, API Scraping Tìm kiếm Google, API Scraping Airbnb, v.v., cung cấp một giải pháp toàn diện cho việc trích xuất dữ liệu web.
Sẵn sàng bắt đầu scraping dễ dàng?
Đăng ký Scrapeless ngay hôm nay và nhận bản dùng thử miễn phí để trải nghiệm sức mạnh của API của chúng tôi. Mở khóa việc trích xuất dữ liệu liền mạch từ các nền tảng thương mại điện tử hàng đầu như Amazon, Shopee, và hơn thế nữa. Đừng bỏ lỡ—hãy bắt đầu ngay bây giờ!
Ưu điểm so với web crawlers Python thủ công
1. Tự động hóa và hiệu quả
API Scraping Amazon tự động hóa toàn bộ quá trình trích xuất dữ liệu, đảm bảo rằng người dùng có thể nhanh chóng và chính xác thu thập một lượng lớn dữ liệu. Điều này loại bỏ việc mã hóa phức tạp thường được yêu cầu đối với web crawlers Python thủ công, thường liên quan đến việc xử lý các thách thức khác nhau như nội dung động và các biện pháp chống scraping.
2. Cơ sở hạ tầng tích hợp sẵn
Với API của Scrapeless, người dùng được hưởng lợi từ một cơ sở hạ tầng mạnh mẽ tự động xử lý quản lý proxy, luân phiên IP và giải quyết CAPTCHA. Ngược lại, web crawlers Python thủ công yêu cầu các nhà phát triển tự triển khai các tính năng này, điều này có thể tốn thời gian và dễ xảy ra lỗi.
3. Giao diện không cần mã
API cung cấp một giao diện không cần mã cho phép người dùng bắt đầu các tác vụ scraping bằng các cuộc gọi API đơn giản. Điều này dễ dàng hơn nhiều so với việc viết và gỡ lỗi mã cho một web crawler Python, vì vậy người dùng ở các cấp độ kỹ năng khác nhau đều có thể sử dụng nó.
Trích xuất dữ liệu Amazon hiệu quả thông qua API
Sử dụng API Scraping Amazon của Scrapeless, người dùng có thể dễ dàng trích xuất dữ liệu có cấu trúc bằng cách làm theo các bước sau:
-
Tạo khóa API: Đăng ký Scrapeless và tạo khóa API duy nhất của bạn.
-
Nhấp vào Scraping API và chọn Amazon.
-
Định nghĩa các yêu cầu của bạn: Chỉ định loại dữ liệu bạn muốn scrape (ví dụ: chi tiết sản phẩm, đánh giá).
-
Nhấp vào Bắt đầu Scraping: Yêu cầu dữ liệu từ Amazon bằng các cuộc gọi API đơn giản.
-
Nhận dữ liệu có cấu trúc: API Scrapeless cung cấp dữ liệu đã thu thập ở nhiều định dạng (ví dụ: JSON) để phân tích hoặc tích hợp vào hệ thống của bạn.
Bằng cách tận dụng API Scraping Amazon của Scrapeless, người dùng có thể đơn giản hóa đáng kể các tác vụ web scraping của mình, cho phép họ tập trung vào việc phân tích thông tin chi tiết hơn là quản lý sự phức tạp của web scraping. Công cụ mạnh mẽ này không chỉ cải thiện năng suất mà còn đảm bảo tuân thủ các quy định bảo vệ dữ liệu, làm cho nó trở nên lý tưởng cho các doanh nghiệp đang tìm cách có được lợi thế cạnh tranh trong nỗ lực nghiên cứu thị trường của họ.
Nếu bạn cần tích hợp Scrapeless vào dự án của riêng mình, bạn có thể tham khảo mã ví dụ của chúng tôi. Bạn cũng có thể nhấp vào đây để xem tài liệu đầy đủ.
Ví dụ yêu cầu - Sản phẩm
import requests
import json
url = "https://api.scrapeless.com/api/v1/scraper/request"
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "https://www.amazon.com/dp/B0BQXHK363",
"action": "product"
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Ví dụ yêu cầu - Người bán
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "",
"action": "seller"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Ví dụ yêu cầu - Từ khóa
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"action": "keywords",
"keywords": "iPhone 12",
"page": "5",
"domain": "com"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Tham gia cộng đồng Discord của Scrapeless ngay hôm nay!
Cập nhật thường xuyên với tin tức hàng tuần, cập nhật độc quyền và tham gia các sự kiện thú vị để có cơ hội giành được tín dụng. Đừng bỏ lỡ niềm vui—hãy tham gia hành động ngay bây giờ!
Câu hỏi thường gặp về web crawler python
Câu hỏi thường gặp #1: Sự khác biệt giữa web crawlers và web scrapers trong Python là gì?
Web crawlers và web scrapers có những mục đích sử dụng khác nhau trong lĩnh vực trích xuất dữ liệu. Web crawler chủ yếu tập trung vào việc khám phá; nó duyệt các trang web để tìm và lập chỉ mục URL, về cơ bản tạo ra một bản đồ của internet hoặc một trang web cụ thể. Kết quả đầu ra của một web crawler thường là một danh sách các URL. Ngược lại, web scraper trích xuất dữ liệu cụ thể từ các URL này, chẳng hạn như chi tiết sản phẩm hoặc thông tin giá cả. Mặc dù cả hai quá trình đều liên quan đến việc tải xuống nội dung HTML, nhưng mục tiêu của một crawler là thu thập các liên kết, trong khi mục tiêu của một scraper là lọc và trích xuất các điểm dữ liệu có liên quan từ các trang này.
Câu hỏi thường gặp #2: Cách xử lý CAPTCHA khi xây dựng web crawler bằng Python?
Xử lý CAPTCHA là một trong những khía cạnh khó khăn nhất của việc xây dựng một web crawler bằng Python, vì nó được thiết kế đặc biệt để ngăn chặn việc truy cập tự động. Dưới đây là một số chiến lược hiệu quả để xử lý CAPTCHA:
- Sử dụng trình duyệt không có đầu: Trình duyệt không có đầu kết hợp với các công cụ như Puppeteer hoặc Playwright có thể giúp bỏ qua CAPTCHA bằng cách bắt chước hành vi của trình duyệt thực.
- Tránh kích hoạt CAPTCHA:
2.1 Sử dụng dịch vụ proxy để luân phiên địa chỉ IP để tránh bị phát hiện.
2.2 Ngẫu nhiên hóa tiêu đề yêu cầu (ví dụ: user agent) và đưa ra độ trễ giữa các yêu cầu để bắt chước hoạt động của con người.
Mặc dù các phương pháp này có thể giúp bỏ qua CAPTCHA, nhưng luôn đảm bảo hành động của bạn tuân thủ các điều khoản dịch vụ và yêu cầu pháp lý của trang web.
Câu hỏi thường gặp #3: Việc scrape dữ liệu từ các trang web như Amazon bằng Python có hợp pháp không?
Tính hợp pháp của web scraping phụ thuộc vào nhiều yếu tố, đặc biệt là khi nhắm mục tiêu các nền tảng thương mại điện tử như Amazon. Dưới đây là một số điểm cần xem xét chính:
- Tuân thủ Robots.txt: Các trang web thường bao gồm một file nêu rõ các phần nào của trang có thể được scrape. Mặc dù việc bỏ qua nó không phải là bất hợp pháp, nhưng nó có thể được coi là không đạo đức hoặc trái với các thực tiễn tốt nhất.
- Sử dụng hợp lý và dữ liệu công khai: Nếu dữ liệu có thể truy cập công khai và được sử dụng cho mục đích phi thương mại (chẳng hạn như nghiên cứu học thuật), nó có thể thuộc phạm vi "sử dụng hợp lý" ở một số khu vực pháp lý. Tuy nhiên, điều này không được đảm bảo là đúng.
Để tránh các vấn đề pháp lý:
- Trước khi scrape dữ liệu, luôn kiểm tra các điều khoản dịch vụ của trang web.
- Nếu có thể, hãy xin phép.
- Sử dụng API scraping trang web hợp pháp, chẳng hạn như Scrapeless.
Kết luận
Trong bài viết này, chúng ta đã khám phá tầm quan trọng của Web Crawler trong Python, đặc biệt là ứng dụng rộng rãi của nó trong việc crawl dữ liệu thương mại điện tử. Là một ngôn ngữ lập trình linh hoạt và mạnh mẽ, Python cung cấp rất nhiều thư viện và công cụ có thể giúp các nhà phát triển crawl dữ liệu hiệu quả từ các nền tảng thương mại điện tử và thu được dữ liệu chính như thông tin sản phẩm, giá cả và bình luận. Tuy nhiên, việc viết và bảo trì Web Crawler thủ công thường cần rất nhiều thời gian và công sức, đặc biệt là khi phải đối mặt với các cơ chế chống crawler phức tạp.
Trong bối cảnh này, API Scraping Amazon của Scrapeless cung cấp một giải pháp thay thế hiệu quả. Đối với những người dùng cần crawl dữ liệu thương mại điện tử quy mô lớn dữ liệu thương mại điện tử, API Scrapeless không chỉ đơn giản hóa quá trình crawling mà còn tự động xử lý nhiều vấn đề phức tạp, giúp người dùng tiết kiệm thời gian và công sức và dễ dàng lấy được dữ liệu Amazon cần thiết. Cho dù đó là một doanh nghiệp nhỏ hay nhu cầu dữ liệu quy mô lớn, Scrapeless đều là một lựa chọn lý tưởng.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


