
Scrapeless hiện đã có sẵn trên Pipedream!
Senior Web Scraping Engineer
Chúng tôi rất vui mừng thông báo rằng Scrapeless hiện đã chính thức hoạt động trên Pipedream! 🎉
Điều này có nghĩa là bạn giờ đây có thể tận dụng khả năng thu thập dữ liệu mạnh mẽ của Scrapeless trong nền tảng tích hợp không máy chủ mạnh mẽ này để xây dựng quy trình tự động hóa thu thập dữ liệu — không còn những cấu hình thu thập dữ liệu lộn xộn hoặc cơn đau đầu về chống bot nữa.
Tại sao chọn Pipedream?
Pipedream là một nền tảng tự động hóa linh hoạt và hiệu quả, hỗ trợ kiến trúc dựa trên sự kiện và cho phép bạn tích hợp hàng trăm dịch vụ như Slack, Notion, GitHub, Google Sheets, và nhiều hơn nữa. Bạn có thể viết logic tùy chỉnh bằng JavaScript, Python, và các ngôn ngữ khác — mà không bao giờ phải quản lý máy chủ hoặc cơ sở hạ tầng.
Đây là môi trường hoàn hảo để xây dựng webhooks, đồng bộ hóa dữ liệu, tạo thông báo theo thời gian thực và tự động hóa bất cứ điều gì bạn cần — tinh giản phát triển và tiết kiệm thời gian.
Xây dựng quy trình Scrapeless đầu tiên của bạn trong Pipedream!
Các yêu cầu
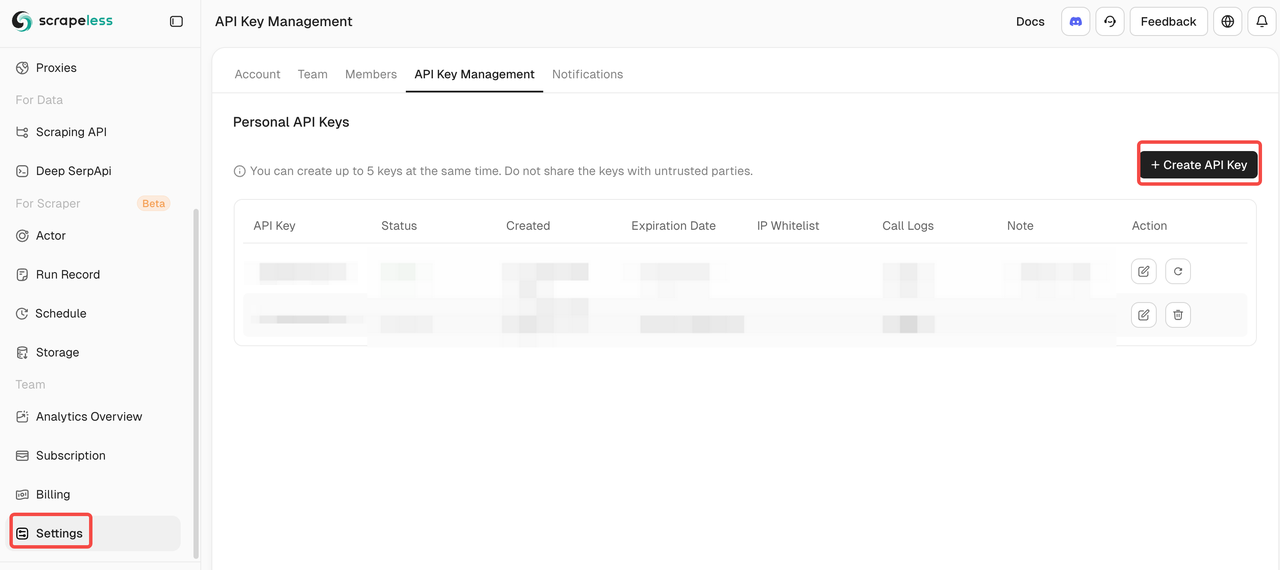
Bước 1. Lấy khóa API Scrapeless của bạn. Trước khi sử dụng Scrapeless trên Pipedream, hãy đảm bảo bạn đã có khóa API của mình:
- Đăng nhập vào Scrapeless
- Đi đến Quản lý API và tạo khóa của bạn
Bước 2. Tạo tài khoản Pipedream. Đăng ký trên Pipedream nếu bạn chưa có.
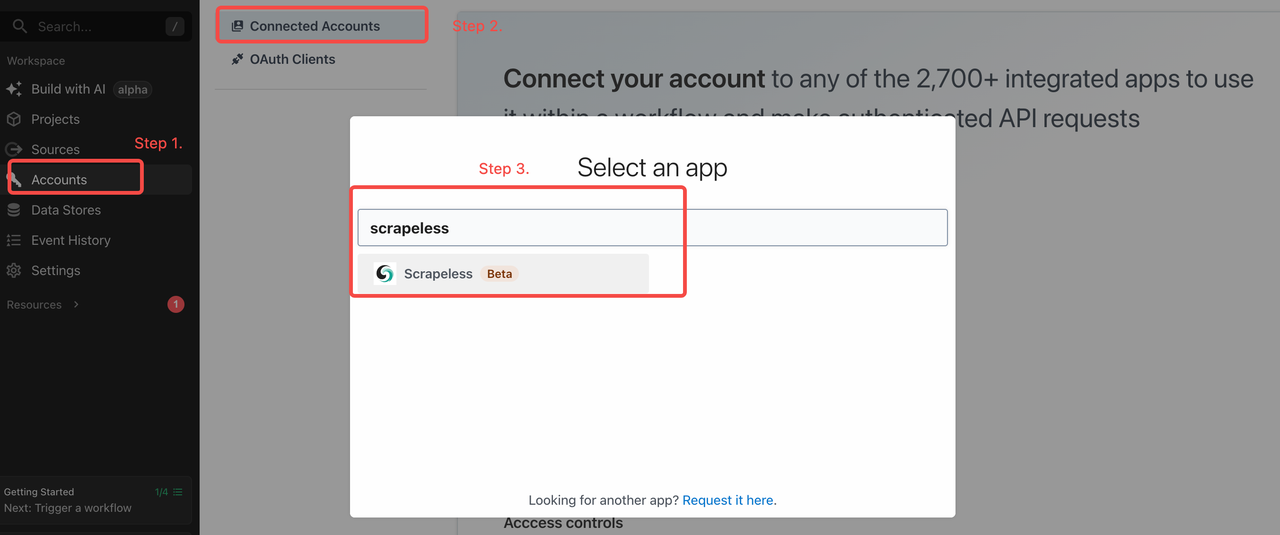
Đặt khóa API Scrapeless của bạn trên Pipedream
Khi bạn đã sẵn sàng, hãy đến tab “Tài khoản” trong Pipedream và thêm khóa API Scrapeless của bạn:
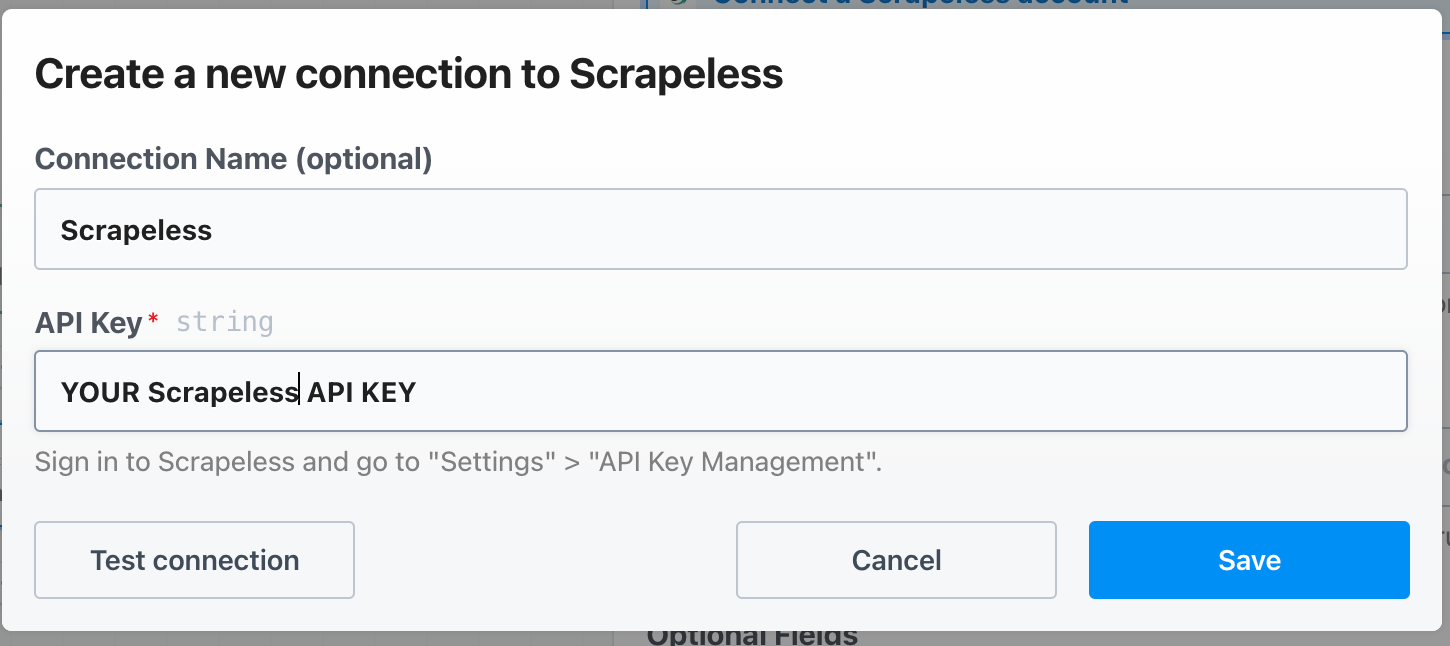
Thiết lập khóa API Scrapeless trên Pipedream như sau:
Scrapeless cung cấp ba mô-đun mạnh mẽ để giúp bạn xây dựng quy trình thu thập dữ liệu trong vài phút:
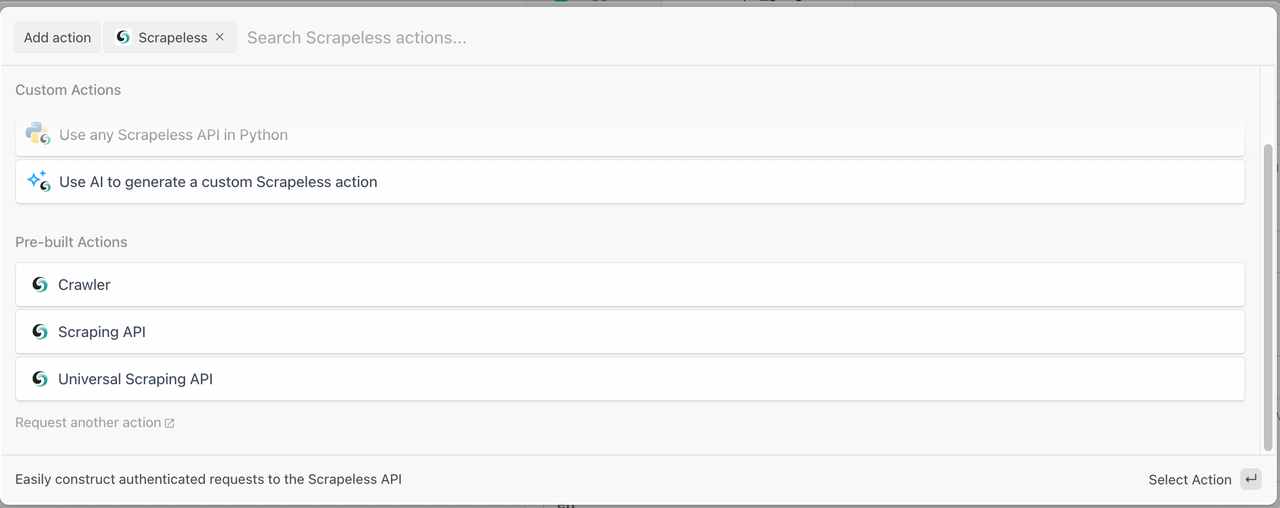
1. Mô-đun Crawler
- Crawler Crawl: Truy cập toàn bộ trang web, truy cập đệ quy các liên kết trong trang và thu thập dữ liệu hoàn chỉnh.
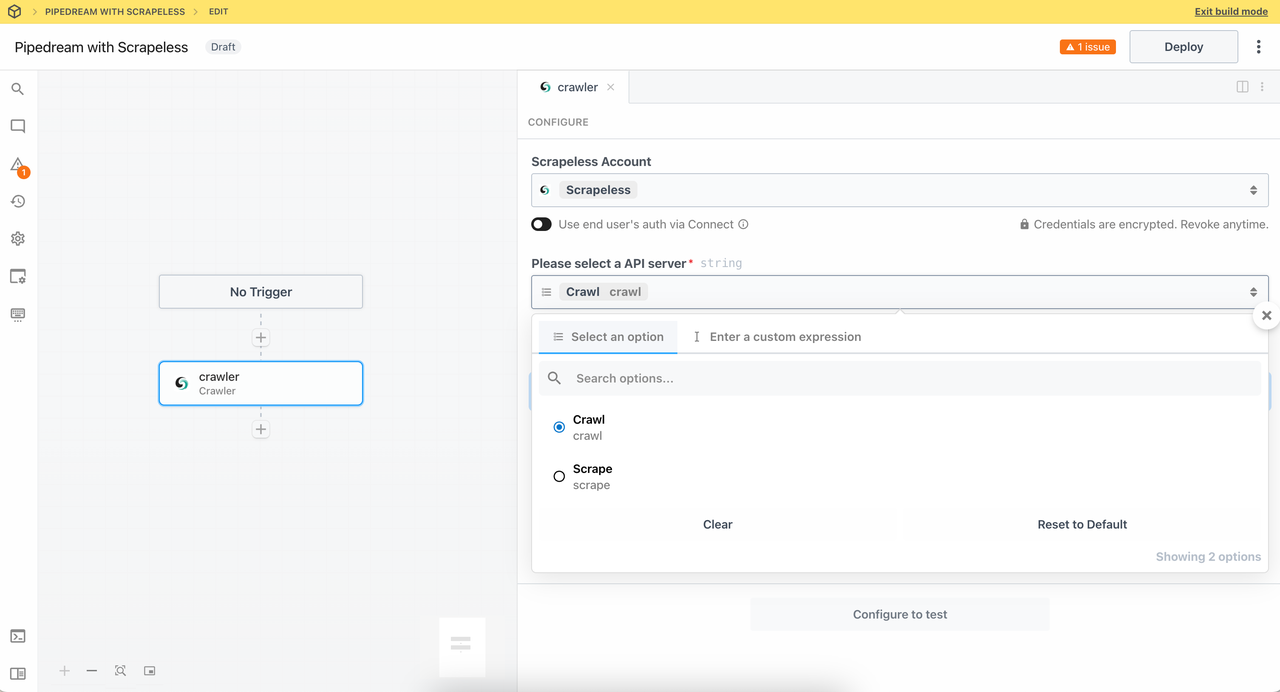
Node này sử dụng chức năng Crawler từ Crawl. Scrapeless cung cấp khả năng thu thập đệ quy thông minh để hoàn toàn nắm bắt tất cả các trang liên kết.
Thiết lập số lượng trang phụ để thu thập lượng dữ liệu trang bạn cần. Bây giờ, hãy thử thu thập dữ liệu từ https://www.scrapeless.com/en:
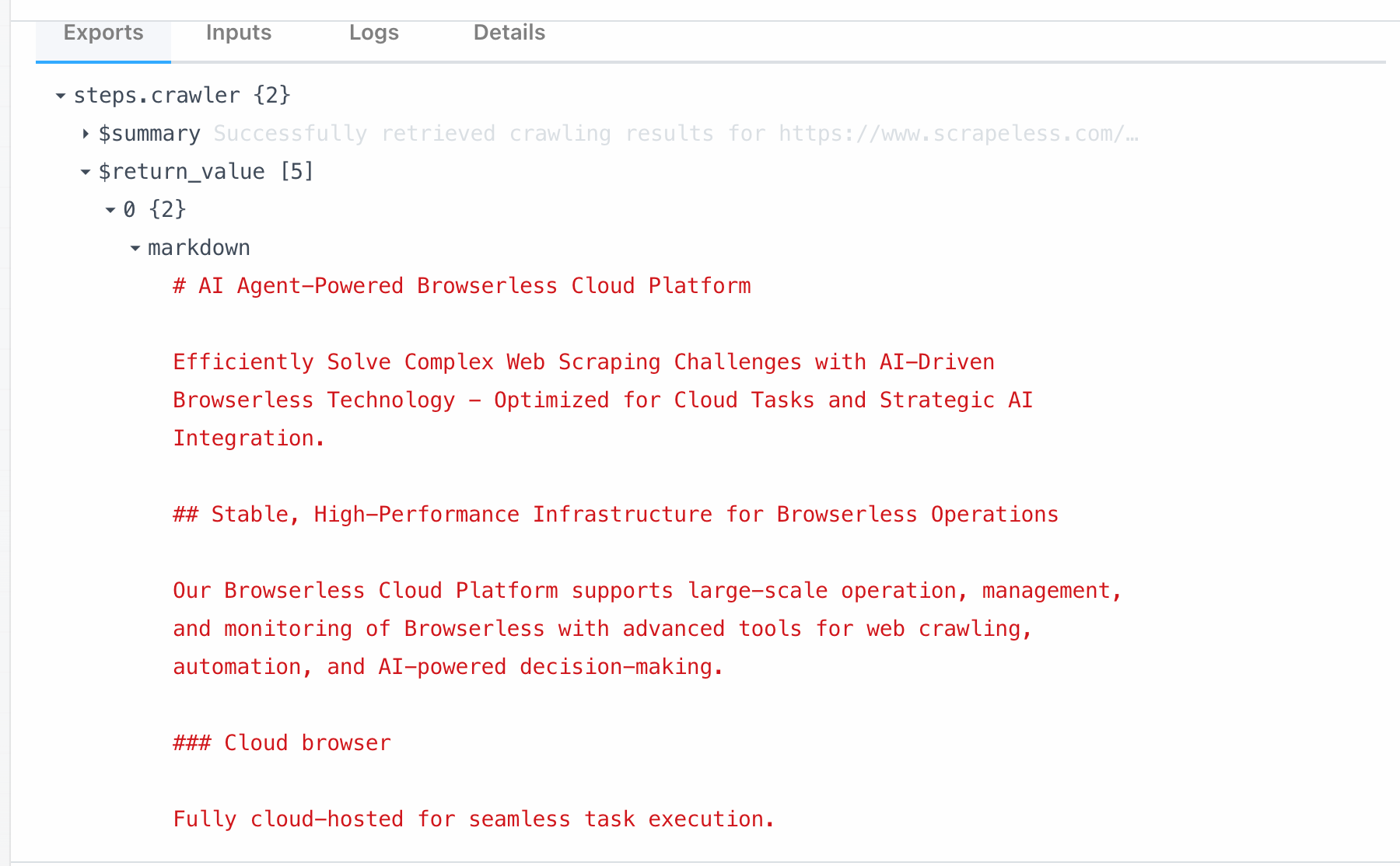
- Crawler Scrape: Sử dụng để thu thập nội dung của một trang web đơn lẻ và trích xuất dữ liệu có cấu trúc.
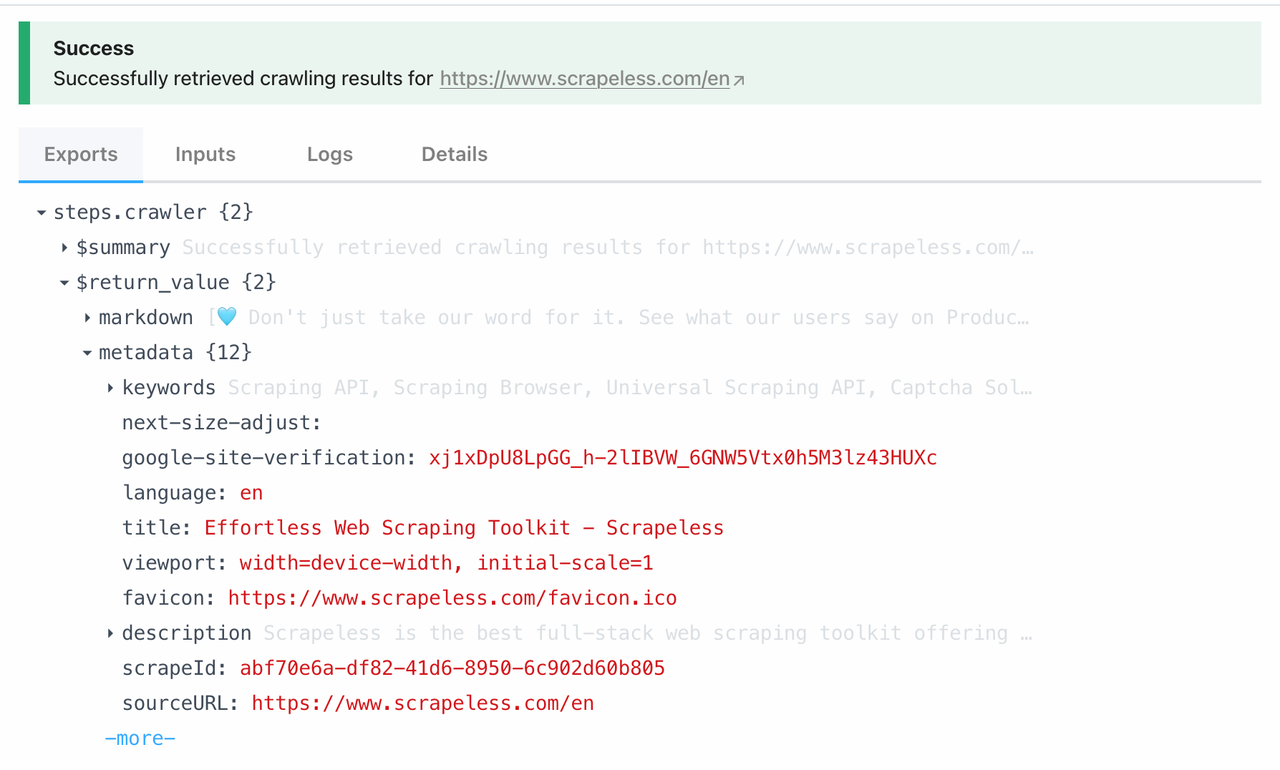
Node Scrape được liên kết trực tiếp với chức năng Scrape dưới Scrapeless Crawl. Bằng cách gọi mô-đun này, bạn có thể thu thập tất cả dữ liệu từ một trang duy nhất chỉ trong một cú nhấp chuột. Dưới đây là những gì chúng ta có thể thu thập từ https://www.scrapeless.com/en:
2. Mô-đun API Scraping
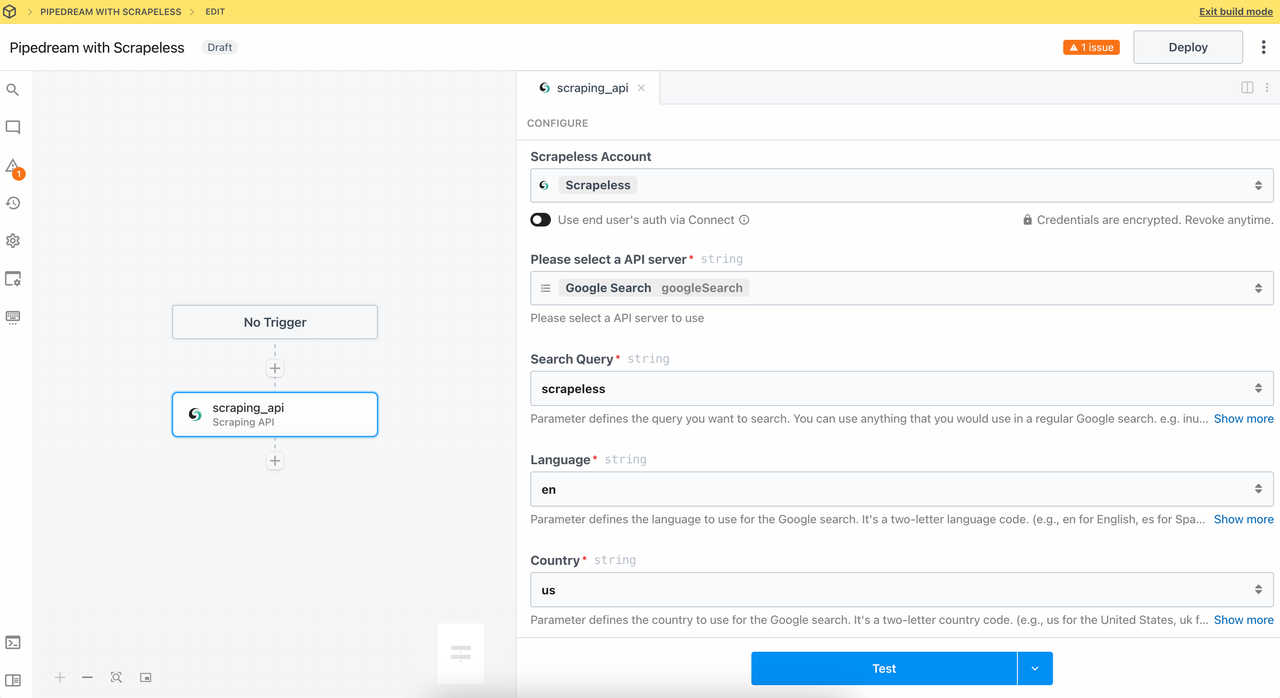
Gọi mô-đun API Scraping có thể truy cập các nguồn dữ liệu như Google Search và Google Trends chỉ với một cú nhấp chuột, và dễ dàng thu được kết quả tìm kiếm và dữ liệu xu hướng mà không cần phải viết các yêu cầu phức tạp hoặc xử lý phản hồi tự mình.
Hãy thiết lập:
- Truy vấn:
Scrapeless - Ngôn ngữ:
en - Quốc gia:
us
Để chờ kết quả của tác vụ không đồng bộ, chúng ta cần nhấp vào Tiếp tục sau khi gửi truy vấn:
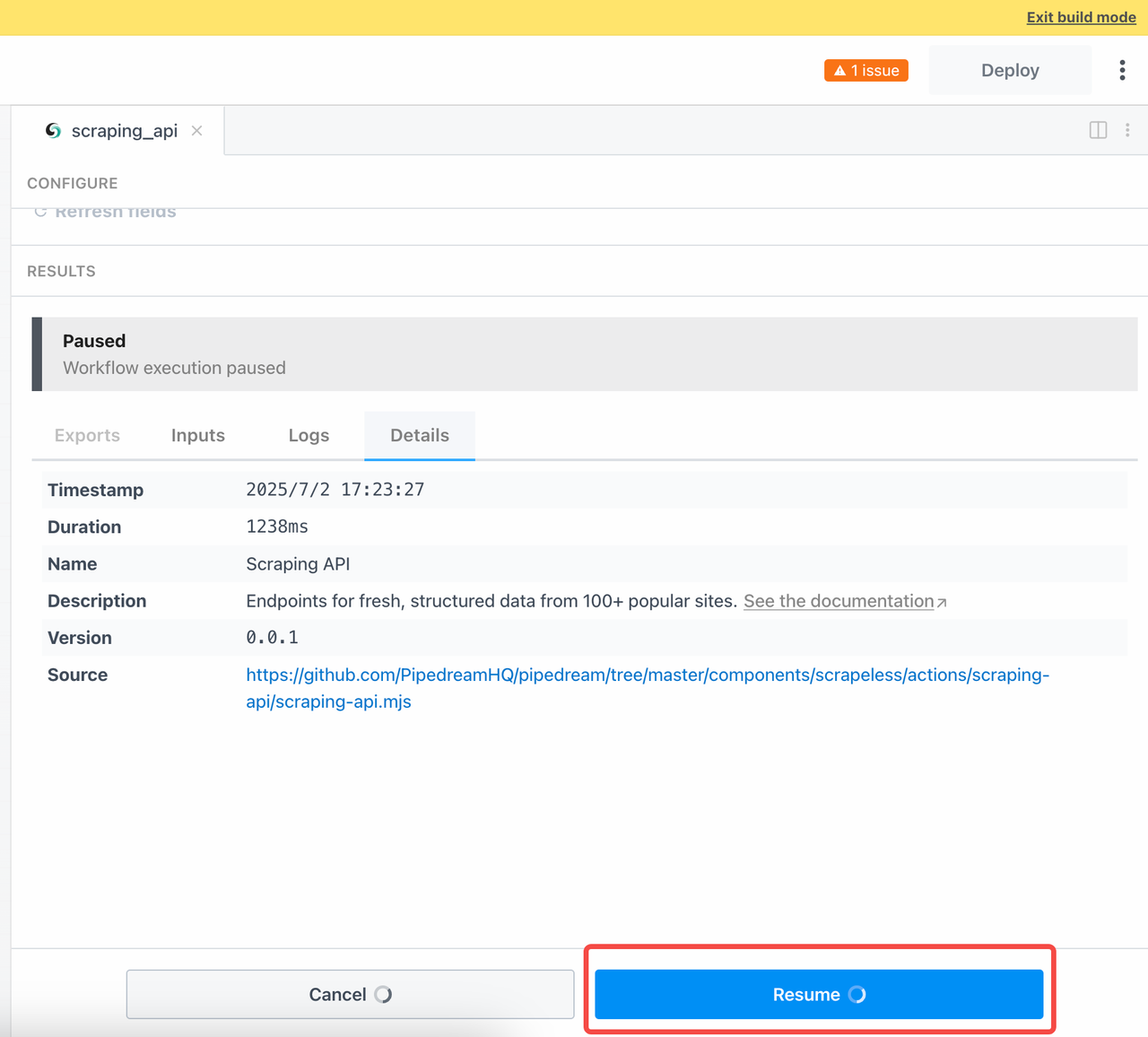
Bây giờ, hãy kiểm tra kết quả thu thập dữ liệu của chúng ta:
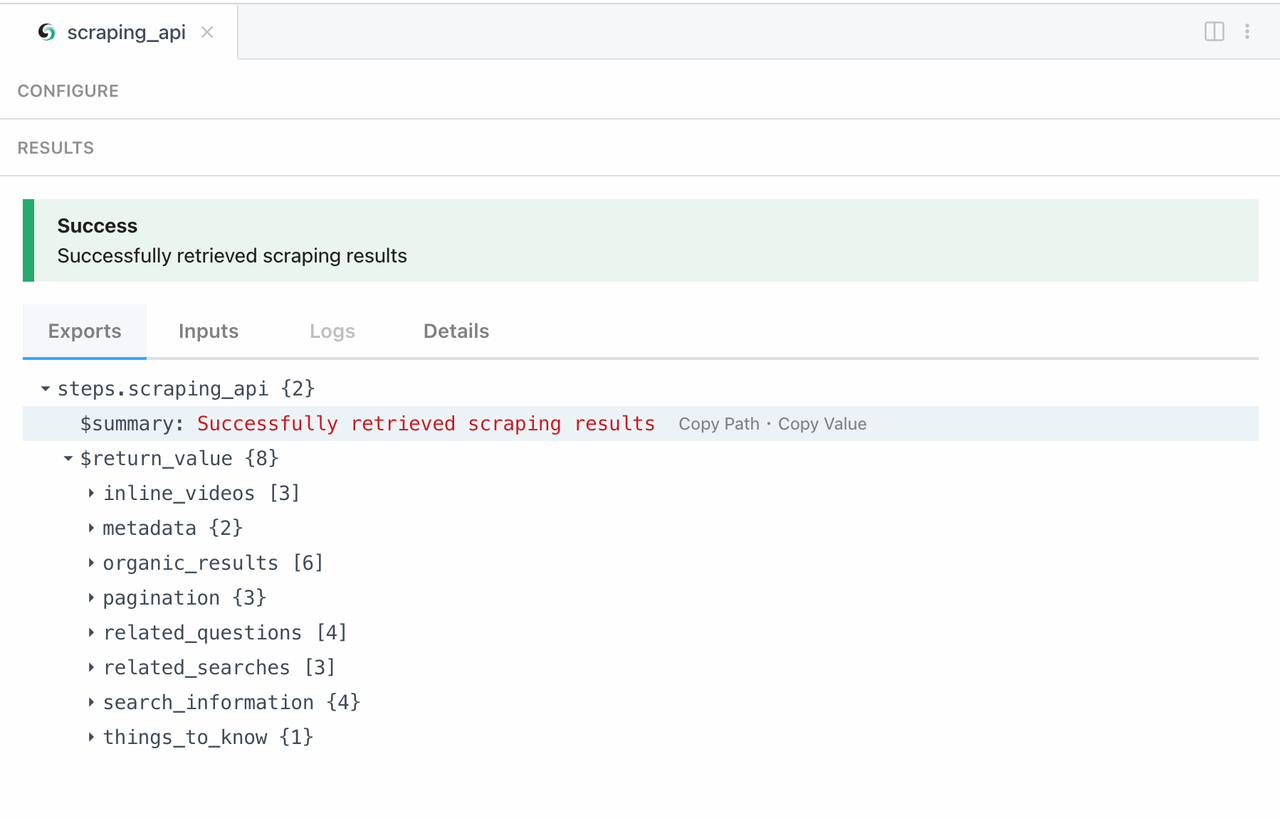
3. Mô-đun API Thu thập Dữ liệu Toàn cầu
Bằng cách thêm mô-đun Mở khóa trang web, bạn có thể gọi dịch vụ API Thu thập Dữ liệu Toàn cầu của Scrapeless một cách thành công. Đối diện với các trang phức tạp như trang r render JavaScript, xác minh đăng nhập, cơ chế chống thu thập dữ liệu, v.v., mô-đun này có thể tự động xử lý nhiều trở ngại và truy cập các trang và trích xuất dữ liệu như một trình duyệt.
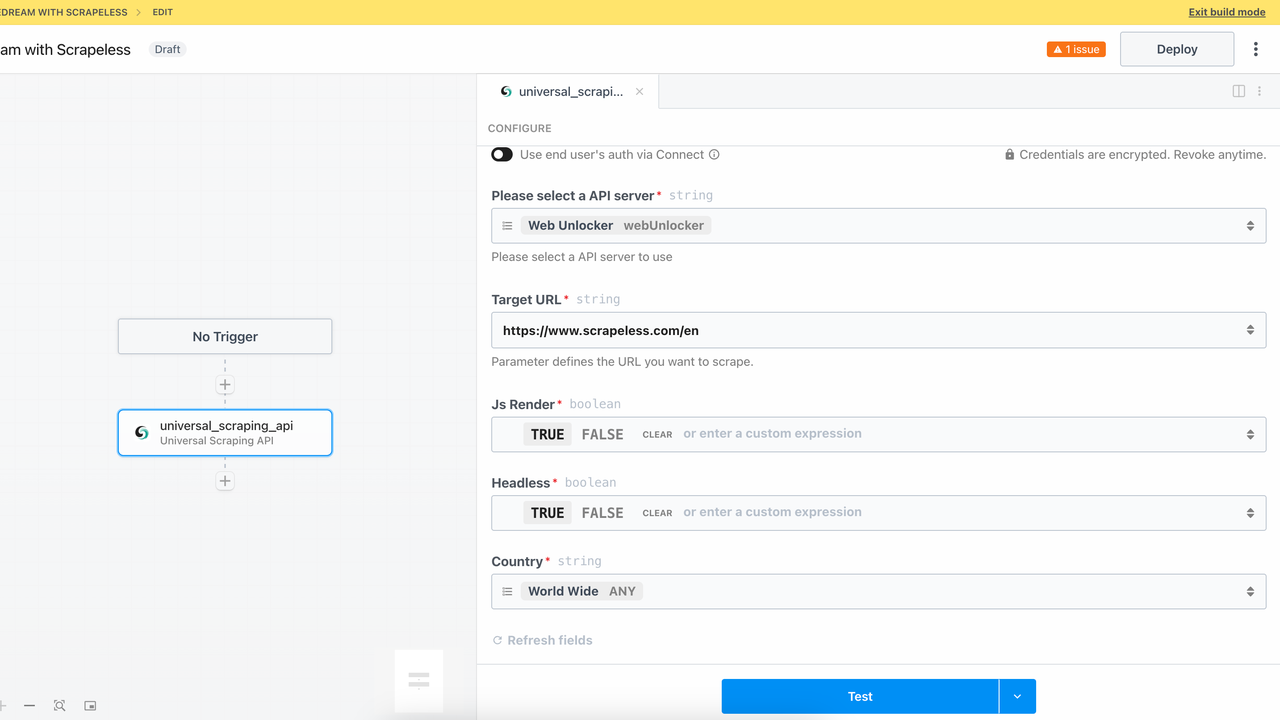
Dưới đây là kết quả HTML được trả về:
Bắt đầu nào!
Dù bạn muốn thu thập dữ liệu từ các trang web công khai, trích xuất xu hướng tìm kiếm, hay truy cập các trang động có bảo vệ cao, Scrapeless + Pipedream cho phép bạn hoàn thành những tác vụ tự động hóa dữ liệu phức tạp nhất với mã code tối thiểu.
🔗 Thử ngay -> Scrapeless trên Pipedream
Đọc thêm
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


