
Cách Scrape TikTok để Lấy Thông tin Video?
Expert Network Defense Engineer
TikTok là một trong những nền tảng mạng xã hội hàng đầu với lưu lượng truy cập khổng lồ. Hãy tưởng tượng xem TikTok có thể cung cấp bao nhiêu dữ liệu giá trị!
Trong bài viết này, chúng ta sẽ giải thích cách thu thập thông tin video TikTok. Ngoài ra, chúng ta sẽ trình bày cách thu thập dữ liệu này thông qua API ẩn hoặc bộ dữ liệu JSON nhúng của TikTok. Hãy bắt đầu thôi!
Tại sao phải thu thập dữ liệu TikTok?
TikTok tự hào có sự tương tác xã hội khổng lồ, giúp thu thập được nhiều thông tin chi tiết cho các trường hợp sử dụng khác nhau:
Phân tích xu hướng
Xu hướng trên TikTok thay đổi nhanh chóng, khiến việc theo kịp sở thích mới nhất của người dùng trở nên khó khăn. Thu thập dữ liệu TikTok giúp nắm bắt hiệu quả những thay đổi xu hướng này và tác động của chúng, cho phép cải thiện chiến lược tiếp thị phù hợp với sở thích người dùng.
Tạo lead
Thu thập dữ liệu TikTok cho phép các doanh nghiệp xác định cơ hội tiếp thị và khách hàng mới. Điều này có thể đạt được bằng cách xác định những người có tầm ảnh hưởng mà nhóm người theo dõi phù hợp với các lĩnh vực kinh doanh có liên quan.
Phân tích cảm xúc
Thu thập dữ liệu web TikTok đóng vai trò là nguồn tuyệt vời để thu thập dữ liệu văn bản từ bình luận, có thể được phân tích thông qua các mô hình cảm xúc để thu thập ý kiến về các chủ đề cụ thể.
Thử thách khi thu thập dữ liệu TikTok
Thu thập dữ liệu TikTok đề cập đến quá trình trích xuất dữ liệu công khai từ TikTok. Mặc dù nó có thể liên quan đến cả hoạt động thủ công và tự động, nhưng nó thường là một quá trình tự động được thực hiện bởi các trình thu thập web hoặc các script tùy chỉnh tương tác với API (Giao diện lập trình ứng dụng) của TikTok.
Dữ liệu có thể bao gồm nhiều loại thông tin như:
- Hồ sơ người dùng: Thông tin về người dùng TikTok, bao gồm tên hồ sơ, tiểu sử và số lượng người theo dõi.
- Nhân khẩu học: Dữ liệu liên quan đến đặc điểm người dùng như tuổi tác, giới tính, địa điểm và sở thích.
- Video: Video ngắn do người dùng đăng tải, bao gồm chú thích, lượt thích, bình luận, chia sẻ và lượt xem.
- Hashtag: Từ khóa hoặc cụm từ được sử dụng để phân loại nội dung TikTok.
- Bình luận: Phản hồi văn bản do người dùng gửi, bao gồm nội dung văn bản, dấu thời gian và số lượt thích.
- Chỉ số tương tác: Thông tin về cách người dùng tương tác với nội dung (thích, bình luận, chia sẻ, xem).
- Xu hướng: Dữ liệu về các chủ đề, chủ đề hoặc kiểu phổ biến trên TikTok.
Cách xây dựng công cụ thu thập dữ liệu TikTok của bạn?
Hãy đơn giản hóa mọi thứ! Bây giờ chúng ta chính thức bắt đầu quá trình từng bước thu thập dữ liệu video TikTok. Đã đến lúc trải nghiệm giá trị to lớn mà TikTok mang lại!
Trước khi bắt đầu quá trình thu thập dữ liệu thực tế, trước tiên hãy cùng xem xét cấu trúc nội dung video của TikTok. Điều này sẽ giúp chúng ta định vị thông tin cần thiết một cách hiệu quả hơn và hoàn thành việc trích xuất dữ liệu dễ dàng hơn.
Chúng ta có thể thu thập dữ liệu gì từ video?
- URL video
- Mô tả video
- Tên nhạc
- Ngày phát hành
- Thẻ
- Lượt xem
- Số lượt thích
- Số lượt bình luận
- Số lượt chia sẻ
- Số lượt lưu
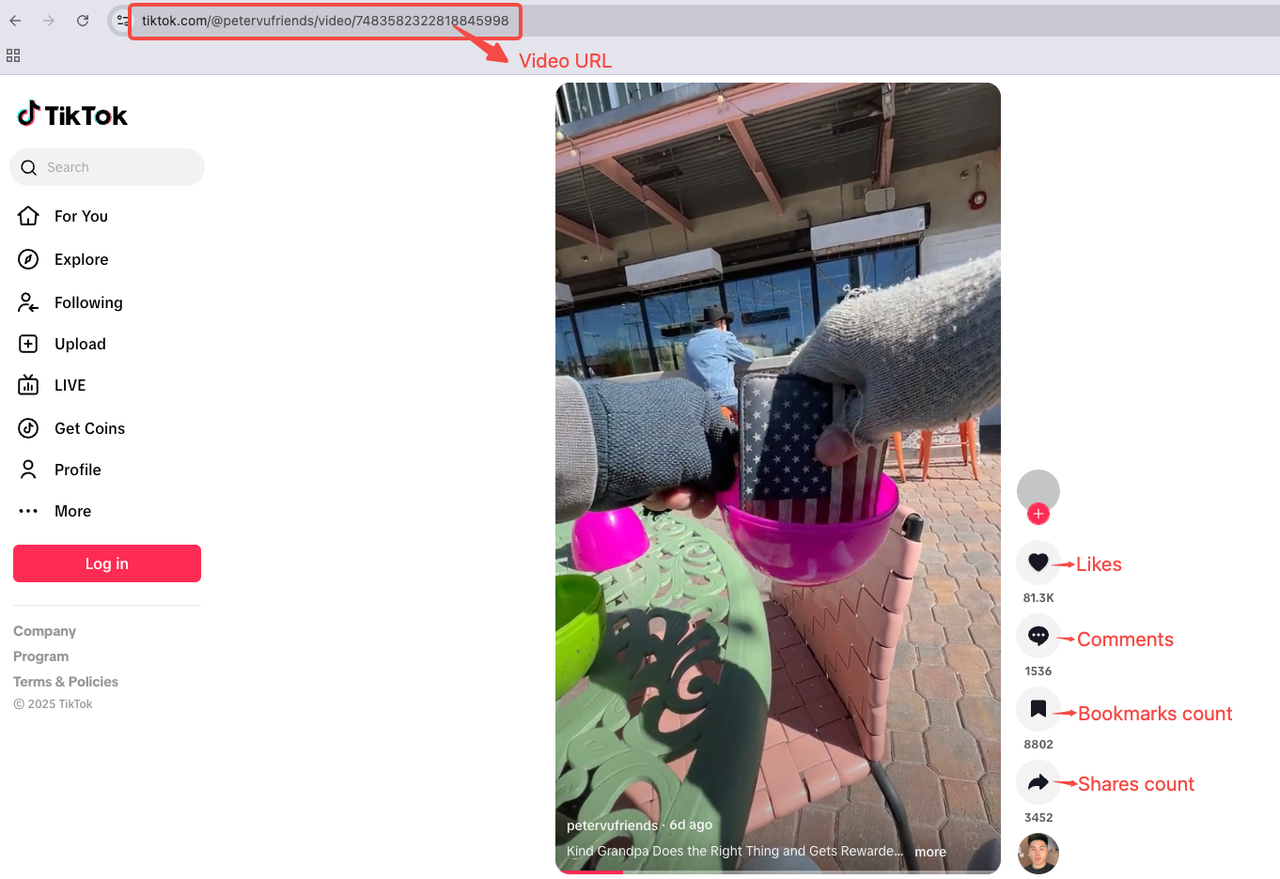
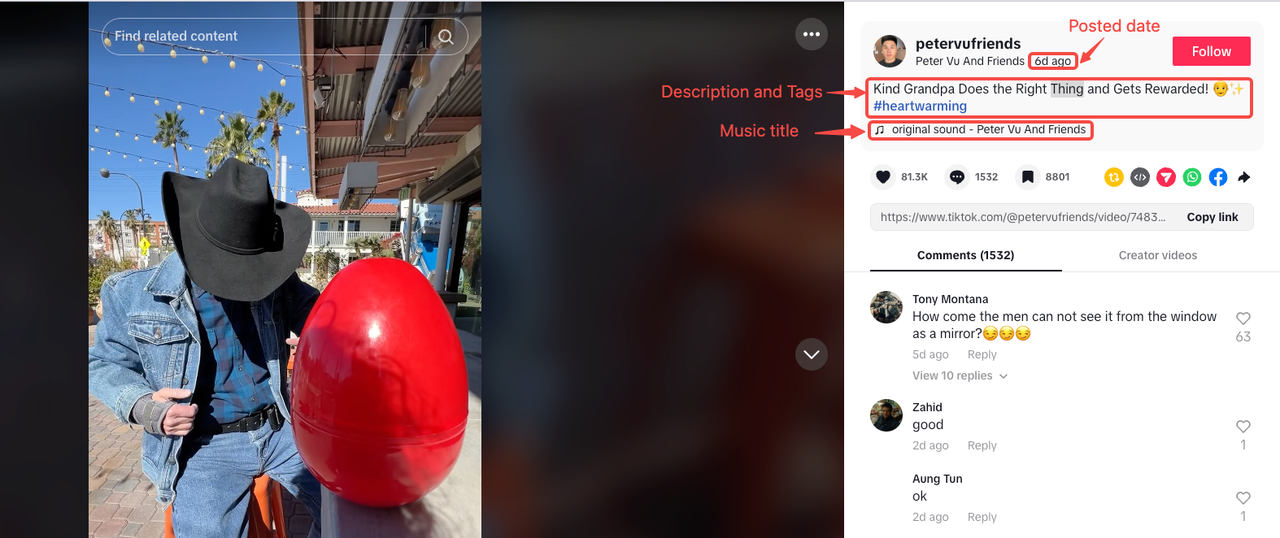
Phân tích trang video
Để việc thu thập dữ liệu trực quan hơn, chúng ta sẽ phân tích video sau đây làm tài liệu tham khảo: https://www.tiktok.com/@petervufriends/video/7476546872253893934.
Chúng tôi bảo vệ quyền riêng tư của trang web một cách nghiêm túc. Tất cả dữ liệu trong blog này đều công khai và chỉ được sử dụng để minh họa quá trình thu thập dữ liệu. Chúng tôi không lưu bất kỳ thông tin và dữ liệu nào.
Cách định vị dữ liệu cần thiết?
Hãy đi sâu vào cấu trúc HTML! Đây là những gì chúng ta cần trích xuất từ video này:
Lượt xem
Số lượt xem thường được hiển thị nổi bật trên trang video. Chỉ cần mở công cụ dành cho nhà phát triển và định vị thẻ có liên quan:
Python
<strong data-e2e="video-views" class="video-count css-dirst9-StrongVideoCount e148ts222">281.4K</strong>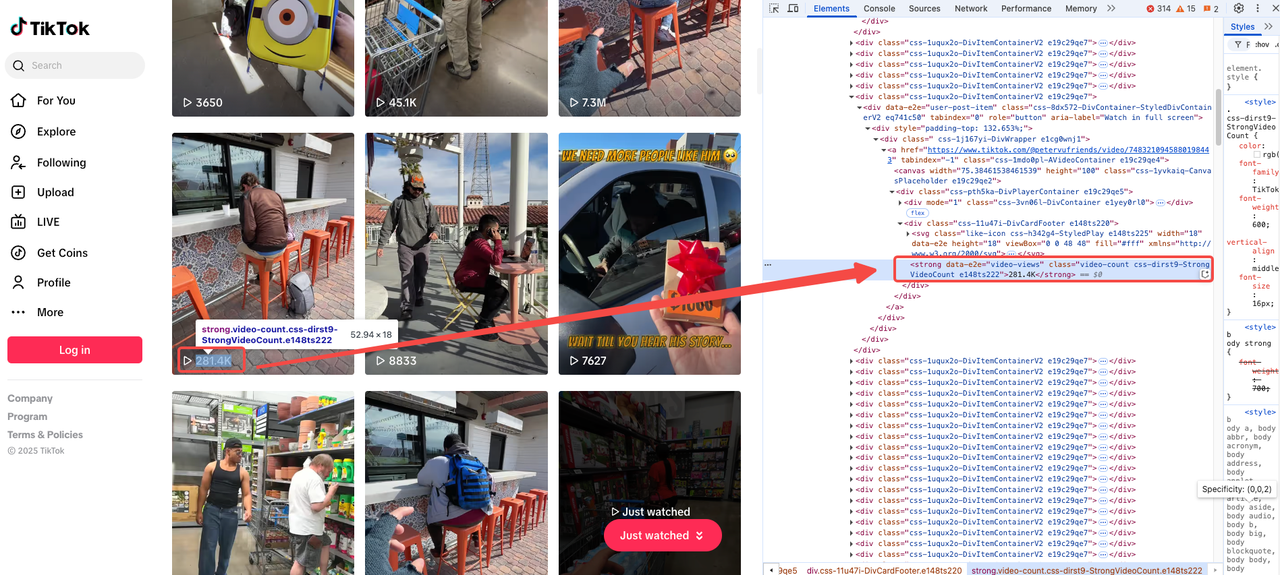
Mô tả video & Thẻ
Như chúng ta đã quan sát ban đầu, mô tả video và thẻ thường xuất hiện trong cùng một phần. Tuy nhiên, một số video có thể không có mô tả hoặc thẻ.
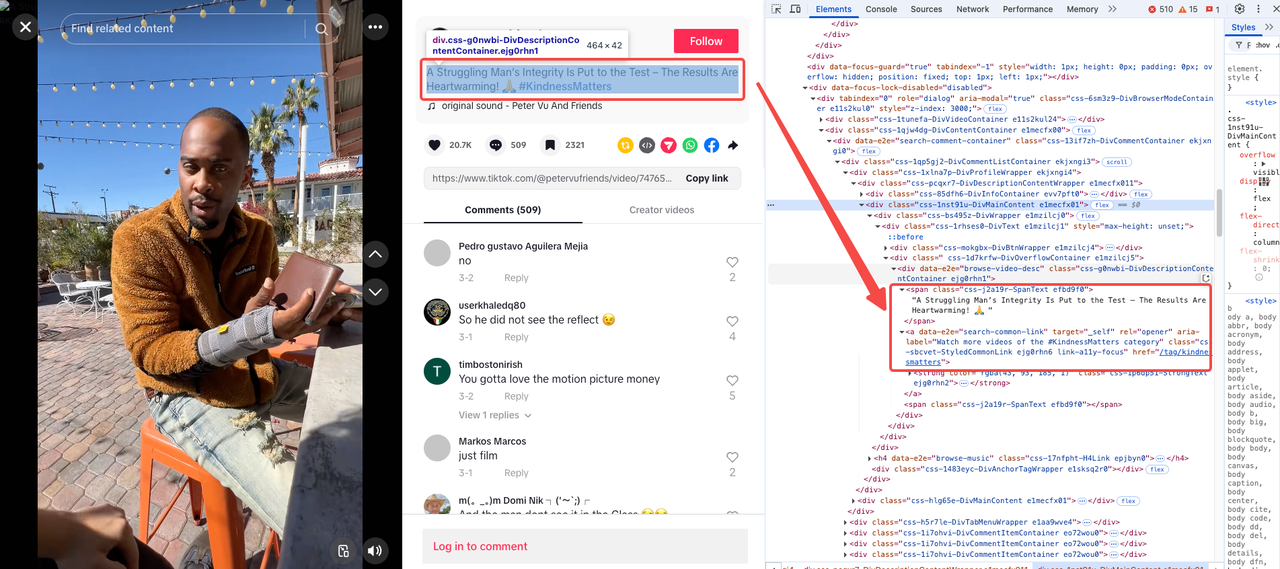
- Mô tả video nằm bên trong một
<span>với lớp có một định danh duy nhất:css-j2a19r-SpanText. - Thẻ video riêng biệt nhưng có cùng thuộc tính:
data-e2e="search-common-link".
Tiêu đề nhạc
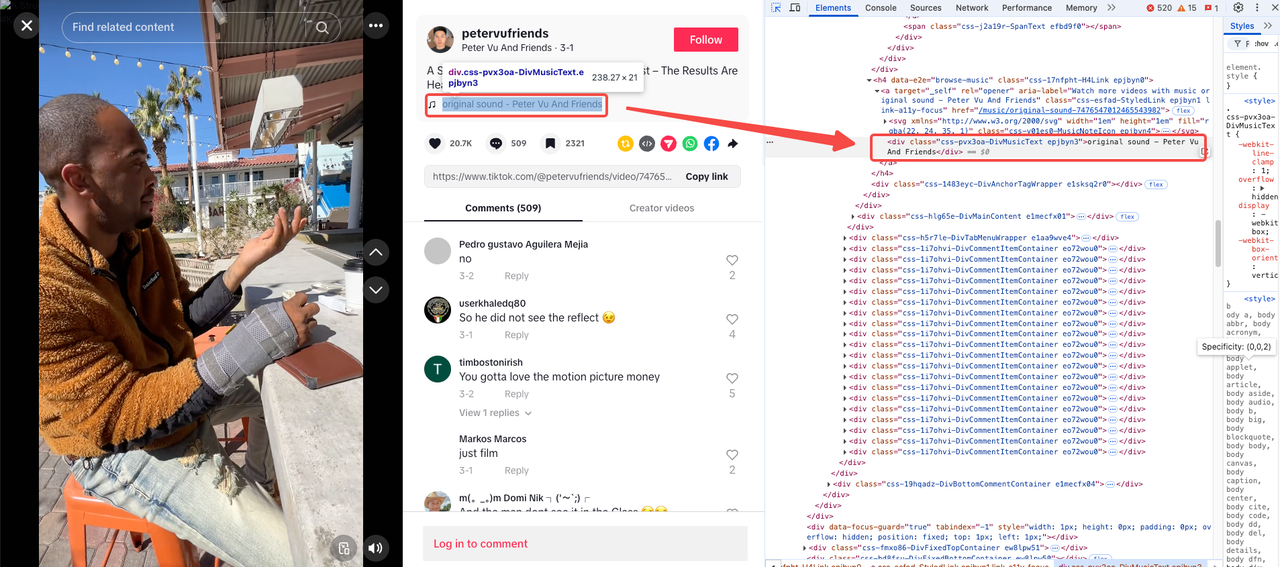
Ngày tải lên
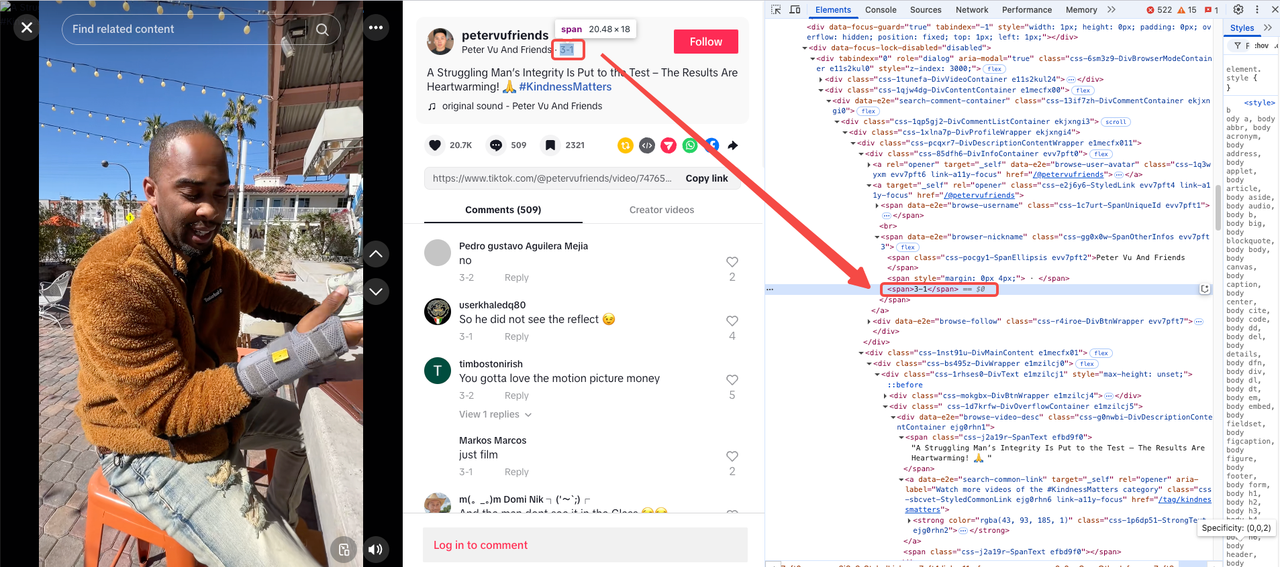
Ngày được phân lập là <span> cuối cùng trong một phần tử cha chứa thuộc tính: data-e2e="browser-nickname".
Lượt thích, bình luận và lượt lưu
Các số liệu này thường xuất hiện cùng nhau và bạn có thể tìm thấy chúng trong cùng một tập hợp:
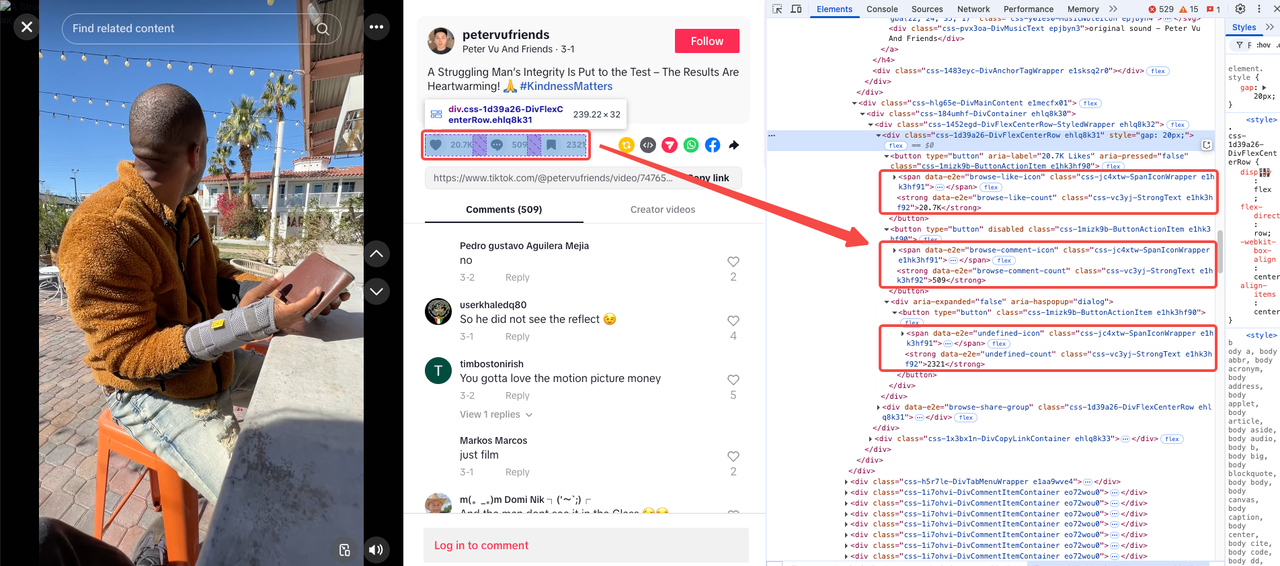
Để đơn giản hóa quá trình thu thập dữ liệu của bạn, đây là tóm tắt các bộ chọn cần thiết:
- URL video:
<meta property="og:url"> - Mô tả video:
['span.css-j2a19r-SpanText'] - Tiêu đề nhạc:
['.css-pvx3oa-DivMusicText'] - Ngày tải lên:
['span[data-e2e="browser-nickname"] span:last-child'] - Thẻ:
[data-e2e="search-common-link"] - Lượt xem:
[data-e2e="video-views"] - Lượt thích:
[data-e2e="like-count"] - Lượt bình luận:
[data-e2e="comment-count"] - Lượt chia sẻ:
[data-e2e="share-count"] - Lượt lưu:
[data-e2e="undefined-count"]
Chúc mừng! Bây giờ bạn đã hiểu đầy đủ cách định vị dữ liệu cần thiết. Tiếp theo, hãy chính thức xây dựng công cụ thu thập dữ liệu!
Mã thu thập dữ liệu hoàn chỉnh
Bỏ qua các lời giải thích không cần thiết — đây là mã thu thập dữ liệu sẵn sàng sử dụng để triển khai ngay lập tức:
Python
from playwright.async_api import async_playwright
import asyncio, random, json, logging, time, os, yt_dlp
from urllib.parse import urlparse
# Configure logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('tiktok_scraper.log'),
logging.StreamHandler()
]
)
class TikTokScraper:
def __init__(self):
self.DOWNLOAD_VIDEO = True
self.SAVE_DIR = "downloaded_videos"
self.USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
self.VIEWPORT = {'width': 1280, 'height': 720}
self.TIMEOUT = 300 # 5 minute timeout
async def random_sleep(self, min_seconds=1, max_seconds=3):
"""Random Delay"""
delay = random.uniform(min_seconds, max_seconds)
logging.info(f"Sleeping for {delay:.2f} seconds...")
await asyncio.sleep(delay)
async def handle_captcha(self, page):
"""Handling verification codes"""
try:
captcha_dialog = page.locator('div[role="dialog"]')
if await captcha_dialog.count() > 0 and await captcha_dialog.is_visible():
logging.warning("CAPTCHA detected. Please solve it manually.")
await page.wait_for_selector('div[role="dialog"]', state='detached', timeout=self.TIMEOUT*1000)
logging.info("CAPTCHA solved. Resuming...")
await self.random_sleep(0.5, 1)
except Exception as e:
logging.error(f"Error handling CAPTCHA: {str(e)}")
async def extract_video_info(self, page, video_url):
"""Extract video details"""
logging.info(f"Extracting info from: {video_url}")
try:
await page.goto(video_url, wait_until="networkidle")
await self.random_sleep(2, 4)
await self.handle_captcha(page)
# Waiting for key elements to load
await page.wait_for_selector('[data-e2e="like-count"]', timeout=10000)
video_info = await page.evaluate("""() => {
const getTextContent = (selectors) => {
for (let selector of selectors) {
const element = document.querySelector(selector);
if (element && element.textContent.trim()) {
return element.textContent.trim();
}
}
return 'N/A';
};
const getTags = () => {
const tagElements = document.querySelectorAll('a[data-e2e="search-common-link"]');
return Array.from(tagElements).map(el => el.textContent.trim());
};
return {
likes: getTextContent(['[data-e2e="like-count"]', '[data-e2e="browse-like-count"]']),
comments: getTextContent(['[data-e2e="comment-count"]', '[data-e2e="browse-comment-count"]']),
shares: getTextContent(['[data-e2e="share-count"]']),
bookmarks: getTextContent(['[data-e2e="undefined-count"]']),
views: getTextContent(['[data-e2e="video-views"]']),
description: getTextContent(['span.css-j2a19r-SpanText']),
musicTitle: getTextContent(['.css-pvx3oa-DivMusicText']),
date: getTextContent(['span[data-e2e="browser-nickname"] span:last-child']),
author: getTextContent(['a[data-e2e="browser-username"]']),
tags: getTags(),
videoUrl: window.location.href
};
}""")
logging.info(f"Successfully extracted info for: {video_url}")
return video_info
except Exception as e:
logging.error(f"Failed to extract info from {video_url}: {str(e)}")
return None
def download_video(self, video_url):
"""Download Video"""
if not os.path.exists(self.SAVE_DIR):
os.makedirs(self.SAVE_DIR)
ydl_opts = {
'outtmpl': os.path.join(self.SAVE_DIR, '%(id)s.%(ext)s'),
'format': 'best',
'quiet': False,
'no_warnings': False,
'ignoreerrors': True
}
try:
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(video_url, download=True)
filename = ydl.prepare_filename(info)
logging.info(f"Video successfully downloaded: {filename}")
return filename
except Exception as e:
logging.error(f"Error downloading video: {str(e)}")
return None
async def scrape_single_video(self, video_url):
"""Scrape the single short"""
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context(
viewport=self.VIEWPORT,
user_agent=self.USER_AGENT,
)
page = await context.new_page()
result = {}
try:
# Extract shorts information
video_info = await self.extract_video_info(page, video_url)
if not video_info:
raise Exception("Failed to extract video info")
result.update(video_info)
# Download TikTok shorts
if self.DOWNLOAD_VIDEO:
filename = self.download_video(video_url)
if filename:
result['local_path'] = filename
except Exception as e:
logging.error(f"Error scraping video: {str(e)}")
finally:
await browser.close()
return result
def save_results(self, data, filename="tiktok_video_data.json"):
"""Save the results to a JSON file"""
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, indent=2, ensure_ascii=False)
logging.info(f"Results saved to {filename}")
async def main():
# Initialize the crawler
scraper = TikTokScraper()
# Target TikTok short's URL
video_url = "https://www.tiktok.com/@petervufriends/video/7476546872253893934" # Just as an reference
# scrape the short
video_data = await scraper.scrape_single_video(video_url)
# save the scraping result
if video_data:
scraper.save_results(video_data)
logging.info("\nScraping completed. Results:")
for key, value in video_data.items():
logging.info(f"{key}: {value}")
else:
logging.error("Failed to scrape video data")
if __name__ == "__main__":
asyncio.run(main())Kết quả thu thập dữ liệu
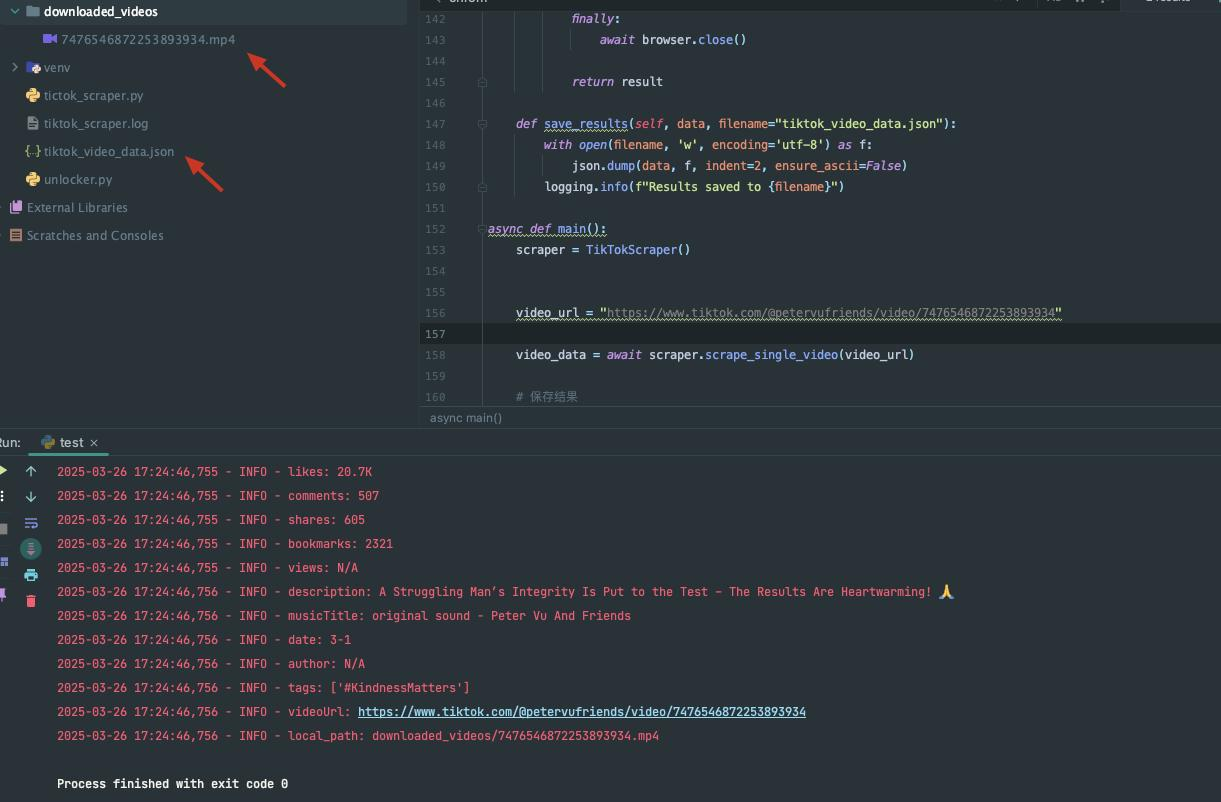
Rõ ràng, chúng ta cần lập trình và các biện pháp phức tạp: đặt độ trễ, bỏ qua CAPTCHA, v.v. để đạt được thu thập dữ liệu. Vậy làm thế nào để nhanh chóng thu thập dữ liệu TikTok? API thu thập dữ liệu của bên thứ ba mạnh mẽ là lựa chọn tốt nhất của bạn!
API thu thập dữ liệu: Thu thập dữ liệu TikTok dễ dàng
Tại sao sử dụng API để truy xuất chi tiết sản phẩm?
1. Hiệu quả được cải thiện
Tìm kiếm thủ công dữ liệu sản phẩm rất chậm và dễ xảy ra lỗi. API cho phép truy xuất tự động thông tin sản phẩm, đảm bảo thu thập dữ liệu nhanh chóng và nhất quán.
2. Dữ liệu chính xác, thời gian thực
API Scrapeless trích xuất dữ liệu trực tiếp từ các trang sản phẩm, đảm bảo thông tin được truy xuất cập nhật và chính xác. Điều này giúp ngăn ngừa lỗi do nhập thủ công bị chậm trễ hoặc nguồn dữ liệu lỗi thời.
3. Áp dụng được cho nhiều tình huống kinh doanh
- Giám sát giá cả: So sánh giá cả của đối thủ cạnh tranh và điều chỉnh chiến lược giá cả.
- Theo dõi hàng tồn kho: Kiểm tra tình trạng sẵn có của sản phẩm để tối ưu hóa quản lý chuỗi cung ứng.
- Phân tích đánh giá: Phân tích phản hồi của khách hàng để cải thiện sản phẩm và dịch vụ.
- Nghiên cứu thị trường: Xác định sản phẩm phổ biến và đưa ra quyết định kinh doanh sáng suốt.
Công cụ thu thập dữ liệu TikTok hoạt động như thế nào?
Công cụ thu thập dữ liệu TikTok này là một API TikTok không chính thức mạnh mẽ cung cấp cho bạn dữ liệu TikTok quy mô lớn cho các dự án dữ liệu của riêng bạn, báo cáo kinh doanh và làm cơ sở cho các ứng dụng mới. Với công cụ thu thập dữ liệu TikTok tốt nhất này, bạn có thể nhận được:
- Tất cả kết quả từ hashtag đã chọn bao gồm chi tiết: video phổ biến, dấu thời gian, lượt xem, lượt chia sẻ, bình luận và số lượng video, v.v.
- Tất cả bài đăng từ hồ sơ người dùng đã chọn bao gồm chi tiết: tên, biệt danh, ID, tiểu sử, người theo dõi/đang theo dõi, lượt xem, lượt chia sẻ và bình luận, v.v.
- Bài đăng video riêng lẻ với URL video cụ thể.
- Dữ liệu liên quan đến video và nhạc.
Thu thập dữ liệu TikTok bằng API
Bước 1. Tạo mã thông báo API của bạn
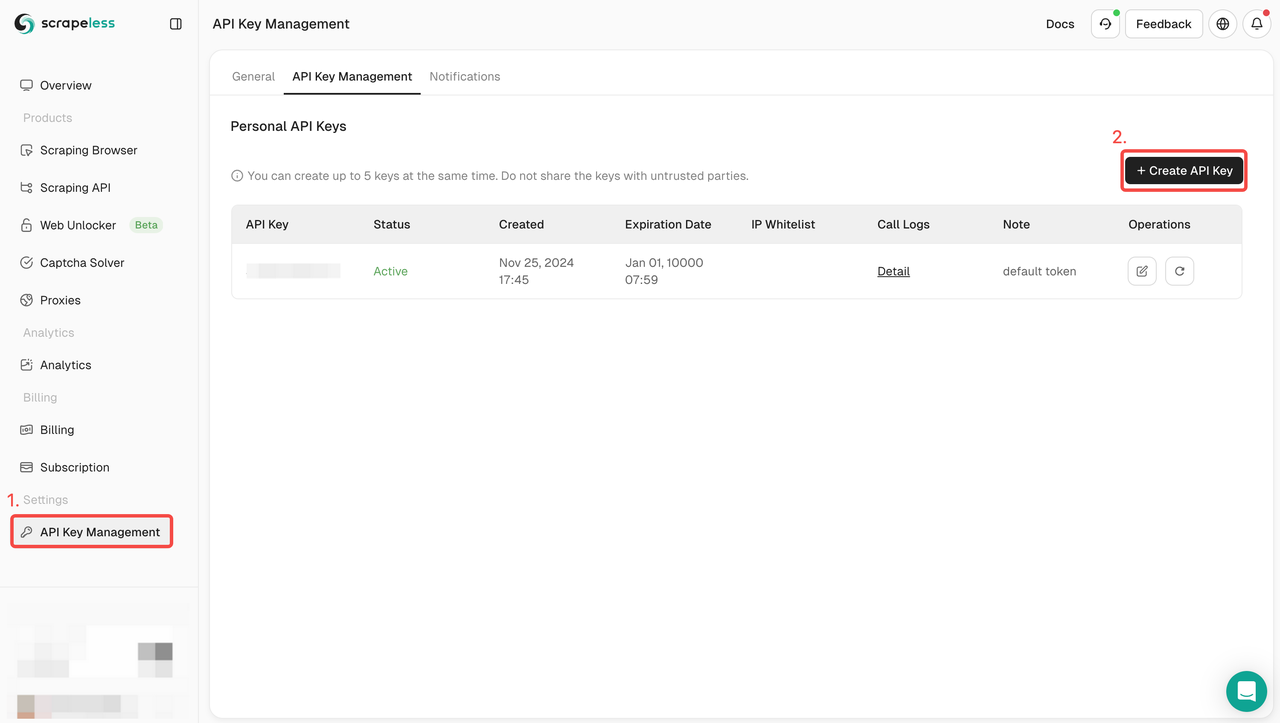
Để bắt đầu, bạn cần lấy API Key từ Bảng điều khiển Scrapeless:
- Đăng nhập vào Bảng điều khiển Scrapeless.
- Điều hướng đến Quản lý API Key.
- Nhấp vào Tạo để tạo API Key duy nhất của bạn.
- Sau khi tạo, chỉ cần nhấp vào API Key để sao chép nó.
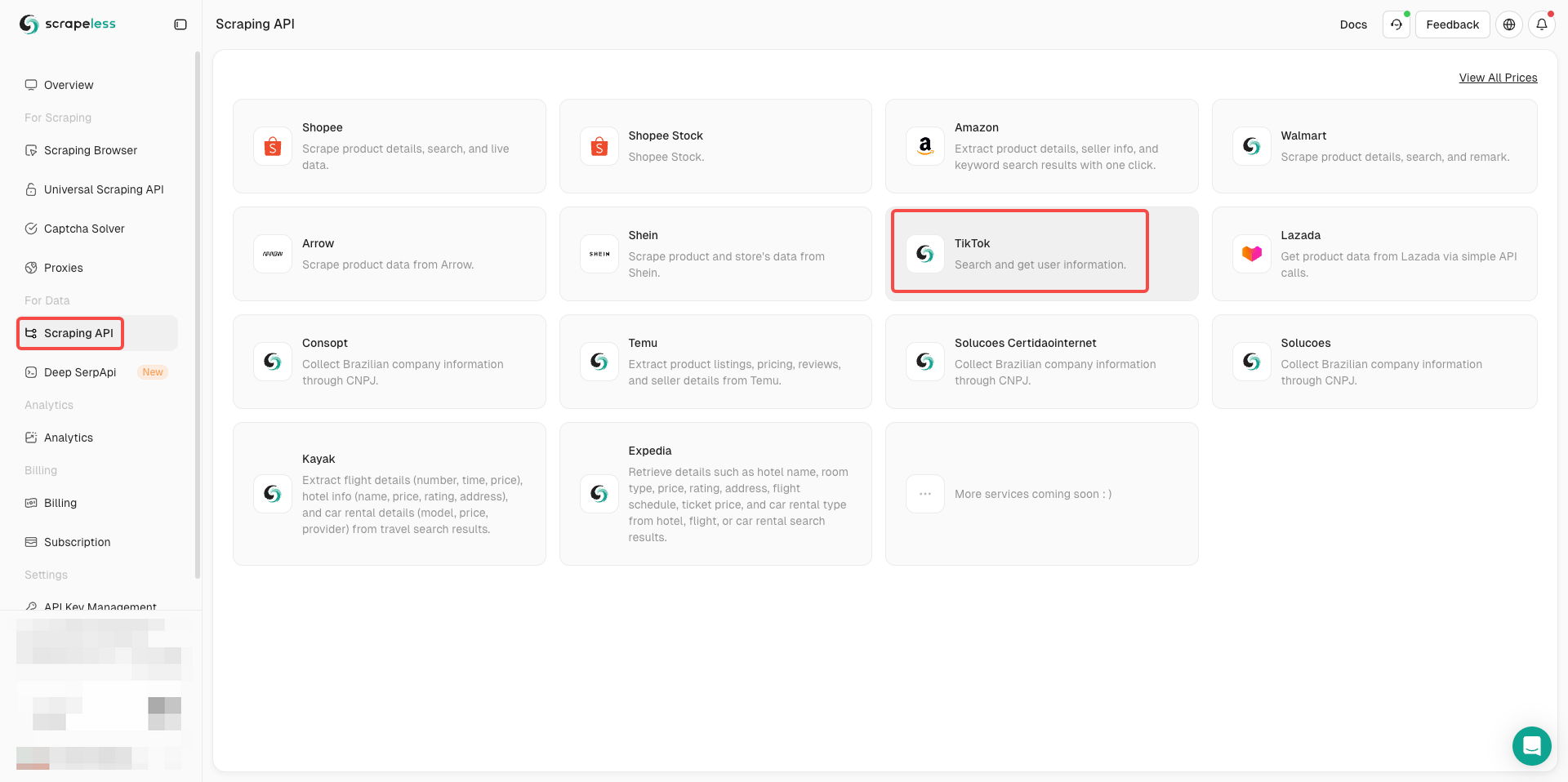
Bước 2. Nhập API TikTok
- Nhấp vào API thu thập dữ liệu trong phần Dành cho dữ liệu
- Tìm TikTok và nhập
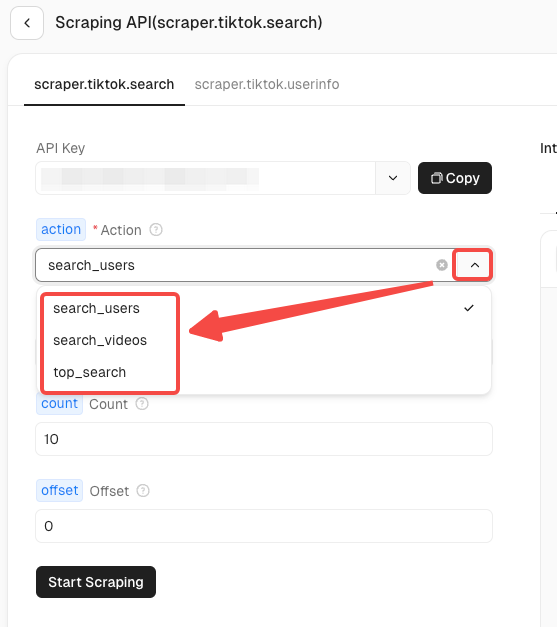
Bước 3. Cấu hình tham số yêu cầu
Hiện tại, actor TikTok có hai kịch bản thu thập dữ liệu:
- Thông tin tìm kiếm TikTok: Thu thập kết quả tìm kiếm video cho từ khóa cụ thể.
- Thông tin người dùng TikTok: Thu thập thông tin hồ sơ của người dùng đã chỉ định.
Sẽ có các yêu cầu hành động khác nhau trong mỗi kịch bản. Bạn có thể nhấp vào mũi tên gấp để tìm thông tin dữ liệu bạn cần thu thập chính xác. Lấy thông tin tìm kiếm TikTok làm ví dụ:
Bạn đã sẵn sàng chưa? Sau khi hiểu thông tin cơ bản, chúng ta có thể chính thức bắt đầu thu thập dữ liệu!
- Giờ đây bạn chỉ cần hoàn tất cấu hình tham số ở phía bên trái của actor theo nhu cầu của mình
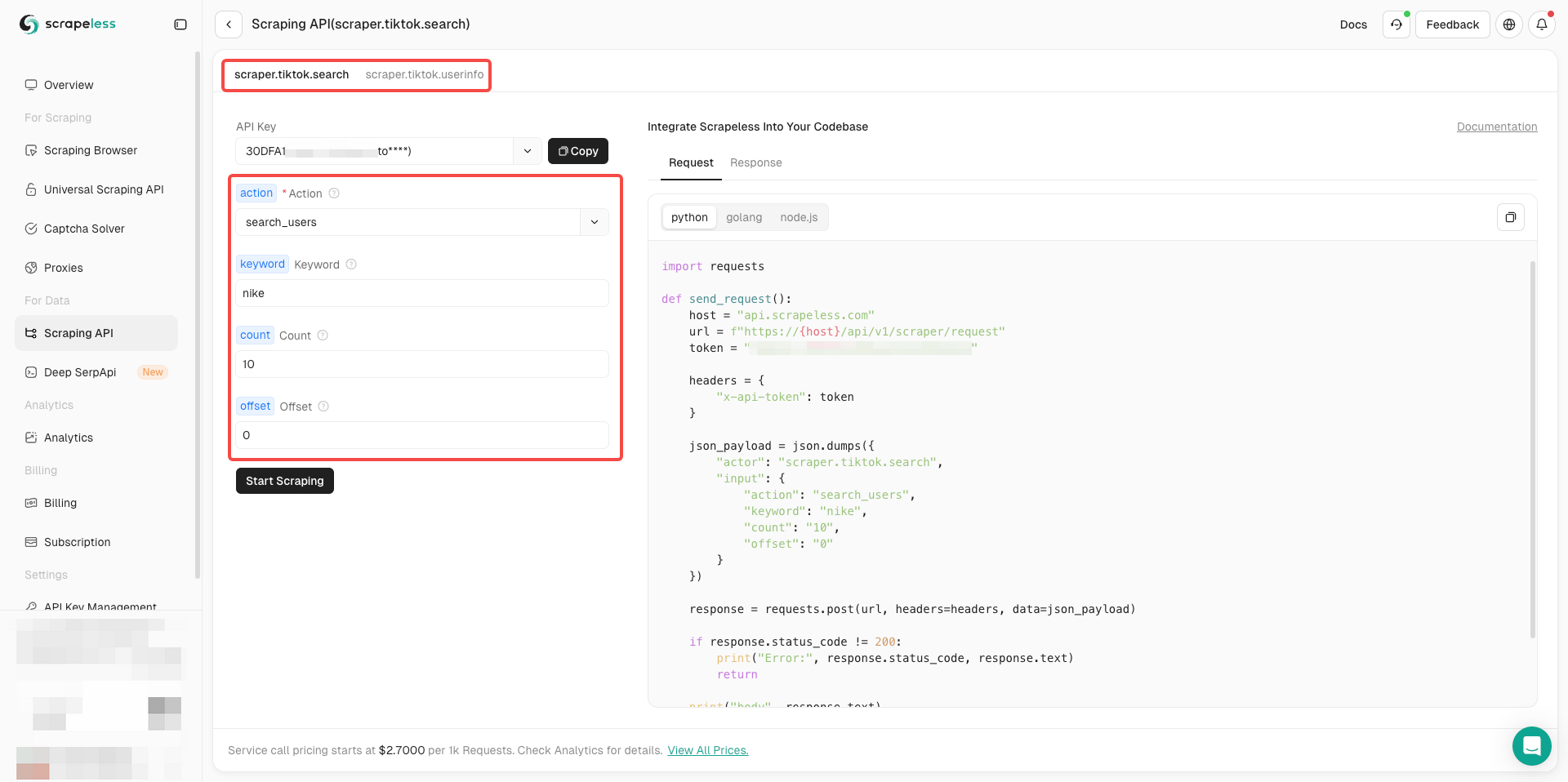
- Sau khi xác nhận mọi thứ đều chính xác, chỉ cần nhấp vào Bắt đầu thu thập để dễ dàng nhận được kết quả thu thập dữ liệu.
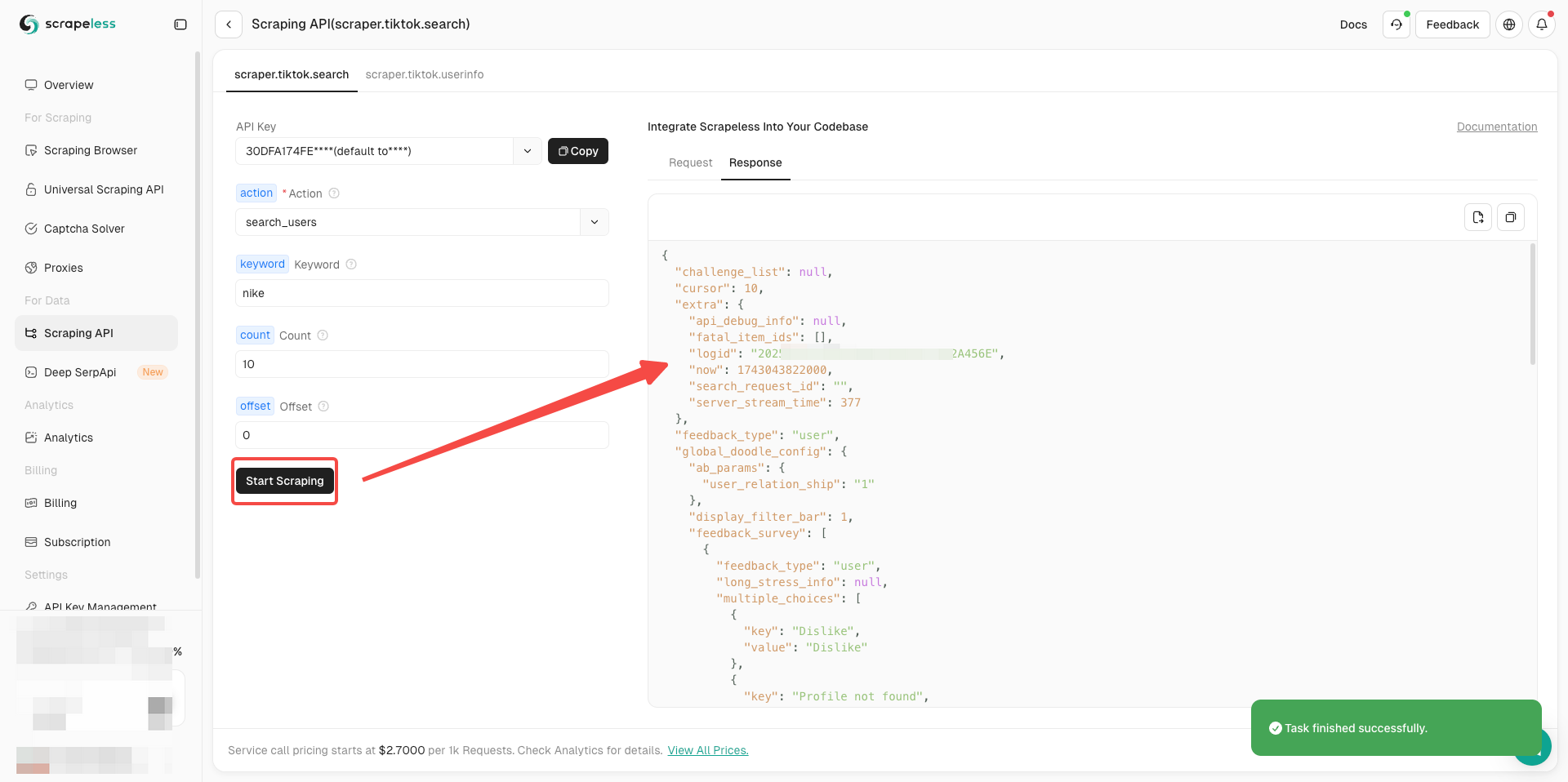
Nhận dữ liệu video TikTok ngay bây giờ!
Từ bây giờ, bạn nên có một công cụ thu thập dữ liệu hoạt động có thể trích xuất dữ liệu từ TikTok. Đây là một khởi đầu tuyệt vời, nhưng bạn chắc chắn có thể đi xa hơn nữa.
Cho dù bạn đang phân tích xu hướng TikTok, thực hiện nghiên cứu hay thỏa mãn trí tò mò về dữ liệu của mình, giờ đây bạn đã có những công cụ mạnh mẽ để khám phá kho dữ liệu TikTok mà không gặp nhiều khó khăn.
API thu thập dữ liệu Scrapeless giúp bạn khỏi phải loay hoay với mã phức tạp. Chỉ cần cấu hình một vài tham số để nhận dữ liệu mới nhất ngay lập tức.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


