
Cách thu thập dữ liệu từ kết quả tìm kiếm công khai của Google Scholar
Advanced Data Extraction Specialist
Google Scholar là một công cụ quan trọng dành cho các nhà nghiên cứu học thuật trên toàn thế giới để tìm kiếm và thu thập tài liệu, bao gồm các bài báo, luận văn và bài báo hội nghị trong nhiều lĩnh vực khác nhau. Tuy nhiên, do cơ chế chống thu thập dữ liệu nghiêm ngặt, việc thu thập dữ liệu Google Scholar trực tiếp không dễ dàng, đặc biệt là đối với những người dùng cần thu thập dữ liệu quy mô lớn.
Trong bài viết này, chúng tôi sẽ giới thiệu hai phương pháp để thu thập dữ liệu Google Scholar: thu thập dữ liệu thủ công (Scrapy/Selenium) và Scrapeless API. Thu thập dữ liệu thủ công phù hợp với việc thu thập dữ liệu quy mô nhỏ, nhưng có thể gặp phải các vấn đề hạn chế IP và mã xác thực. Scrapeless API cung cấp một giải pháp ổn định và hiệu quả hơn, đặc biệt là đối với việc thu thập dữ liệu quy mô lớn, mà không cần phải duy trì các chiến lược chống phát hiện bổ sung.
Bằng cách so sánh ưu điểm và nhược điểm của hai phương pháp, bài viết này sẽ giúp bạn lựa chọn giải pháp phù hợp nhất để đạt được hiệu quả thu thập dữ liệu.
Google Scholar cung cấp các nguồn tài nguyên học thuật có giá trị, bao gồm các bài báo nghiên cứu, trích dẫn, hồ sơ tác giả, v.v. Bằng cách thu thập dữ liệu Google Scholar, bạn có thể:
- Thu thập các bài báo nghiên cứu về một chủ đề cụ thể.
- Trích xuất số lần trích dẫn để phân tích tác động học thuật.
- Truy xuất hồ sơ tác giả và các công trình đã xuất bản của họ.
- Tự động hóa các bài đánh giá tài liệu cho mục đích nghiên cứu.
Thách thức trong việc thu thập dữ liệu Google Scholar
Việc thu thập dữ liệu Google Scholar đi kèm với những thách thức như:
- CAPTCHA: Các yêu cầu thường xuyên có thể kích hoạt cơ chế bảo vệ chống bot của Google.
- Chặn IP: Google có thể chặn IP thực hiện các yêu cầu tự động lặp đi lặp lại.
- Nội dung động: Một số kết quả có thể được tải động thông qua JavaScript.
Để khắc phục những thách thức này, chúng tôi khuyên bạn nên sử dụng API chuyên dụng như Scrapeless API.
Phương pháp 1: Cách thu thập dữ liệu Google Scholar - Thu thập dữ liệu web truyền thống (Không khuyến nghị)
Việc thu thập dữ liệu Google Scholar thủ công bằng Python (ví dụ: BeautifulSoup, Selenium) rất khó khăn do các hạn chế của Google. Ví dụ sử dụng requests:
import requests
from bs4 import BeautifulSoup
url = "https://scholar.google.com/scholar?q=machine+learning"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
results = soup.find_all("div", class_="gs_r")
for result in results:
title = result.find("h3").text if result.find("h3") else "No Title"
print(title)📌 Nhược điểm:
- Dễ dàng kích hoạt cơ chế chống thu thập dữ liệu của Google, dẫn đến bị chặn IP hoặc gặp phải CAPTCHA.
- Cấu trúc dữ liệu phức tạp, cần phải phân tích cú pháp HTML và xử lý nội dung được tải động.
- Không phù hợp với việc thu thập dữ liệu quy mô lớn và có độ ổn định thấp.
Phương pháp này không đáng tin cậy do các biện pháp chống bot của Google. Thay vào đó, sử dụng API như Scrapeless API là giải pháp thay thế tốt nhất.
Phương pháp 2: Thu thập dữ liệu Google Scholar với Scrapeless Scraping API (Khuyến nghị)
Scrapeless's Google Scholar API là một công cụ được thiết kế cho nghiên cứu học thuật và phân tích dữ liệu. Nó có thể tự động thu thập dữ liệu kết quả tìm kiếm Google Scholar để thu được các thông tin chính như tiêu đề bài báo, tác giả, ngày xuất bản và số lần trích dẫn. Nó phân tích SERP (trang kết quả công cụ tìm kiếm) của Google Scholar để cung cấp dữ liệu JSON có cấu trúc, tránh chặn IP và xác minh mã xác thực, đồng thời giúp người dùng không cần phải xử lý việc phát triển trình thu thập dữ liệu phức tạp.
Ngoài ra, Scrapeless cũng hỗ trợ tìm kiếm thời gian thực, truy vấn hàng loạt và lọc tham số tùy chỉnh, phù hợp với các nhà nghiên cứu, nhà phát triển và nhà phân tích dữ liệu.
Các tính năng chính của Scrapeless's Google Scholar API
- Phân tích cú pháp tự động: Không cần phải tự viết trình thu thập dữ liệu, trực tiếp lấy dữ liệu JSON có cấu trúc.
- Dữ liệu thời gian thực: Hỗ trợ truy vấn thời gian thực để đảm bảo rằng các kết quả Google Scholar thu được là mới nhất.
- Cơ chế chống thu thập dữ liệu: Tự động bỏ qua CAPTCHA và chặn IP của Google Scholar, mà không cần proxy hoặc cấu hình bổ sung.
- Các trường dữ liệu phong phú: Cung cấp dữ liệu chi tiết như tiêu đề bài báo, tác giả, ngày xuất bản, số lần trích dẫn, thông tin tạp chí, các bài báo liên quan, v.v.
- Hỗ trợ truy vấn hàng loạt: Bạn có thể lấy kết quả tìm kiếm cho nhiều từ khóa cùng một lúc để cải thiện hiệu quả thu thập dữ liệu.
- Tham số tìm kiếm tùy chỉnh: Hỗ trợ lọc dữ liệu theo thời gian, ngôn ngữ, loại tài liệu, v.v., và xác định chính xác thông tin mục tiêu.
- Truy cập API ổn định: Dựa trên kiến trúc đám mây, nó đảm bảo sự ổn định và đáng tin cậy trong quá trình truy cập đồng thời cao.
Đăng ký miễn phí và bắt đầu thu thập dữ liệu kết quả tìm kiếm Google ngay bây giờ!
Đăng nhập vào Scrapeless ngay bây giờ để có cơ hội dùng thử miễn phí để dễ dàng thu thập dữ liệu từ công cụ tìm kiếm Google để hỗ trợ các dự án và phân tích của bạn. Các chức năng API mạnh mẽ có thể giúp bạn thu được thông tin tìm kiếm chính xác và cải thiện hiệu quả. Hãy đến và trải nghiệm nó!
📌 Các tính năng chính của khóa API Scrapeless:
| API | Chức năng | Trường hợp sử dụng |
|---|---|---|
| Author API | Truy xuất thông tin học giả (H-index, số lượng bài báo, v.v.) | Phân tích tác động học giả |
| Cite API | Truy xuất các định dạng trích dẫn bài báo (BibTeX, APA, v.v.) | Quản lý bài báo |
| Organic Results API | Truy xuất kết quả tìm kiếm Google Scholar | Nghiên cứu học thuật |
| Profiles API | Truy xuất dữ liệu hồ sơ học giả | Phân tích nghiên cứu hợp tác |
Cách sử dụng Scrapeless Google Scholar API
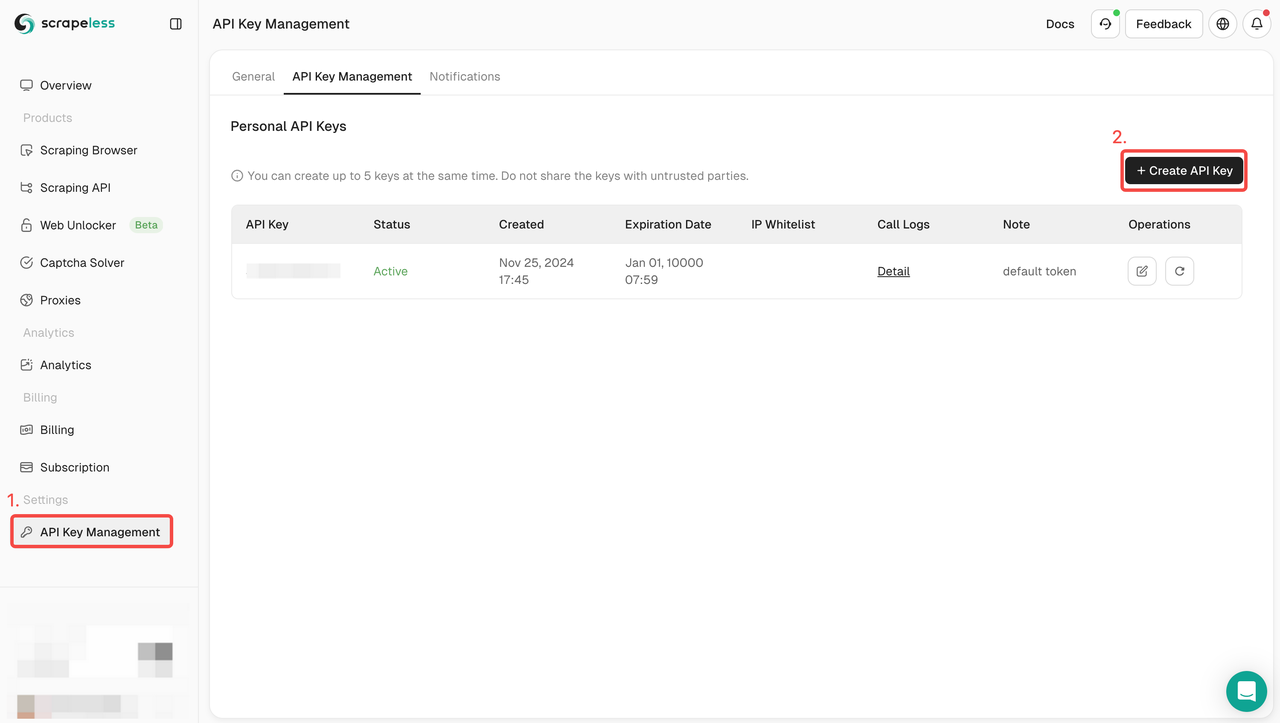
Bước 1. Lấy khóa API của bạn
Để bắt đầu, bạn cần lấy Khóa API của mình từ Bảng điều khiển Scrapeless:
- Đăng nhập vào Bảng điều khiển Scrapeless.
- Điều hướng đến Quản lý Khóa API.
- Nhấp vào Tạo để tạo Khóa API duy nhất của bạn.
- Sau khi tạo, chỉ cần nhấp vào Khóa API để sao chép nó.
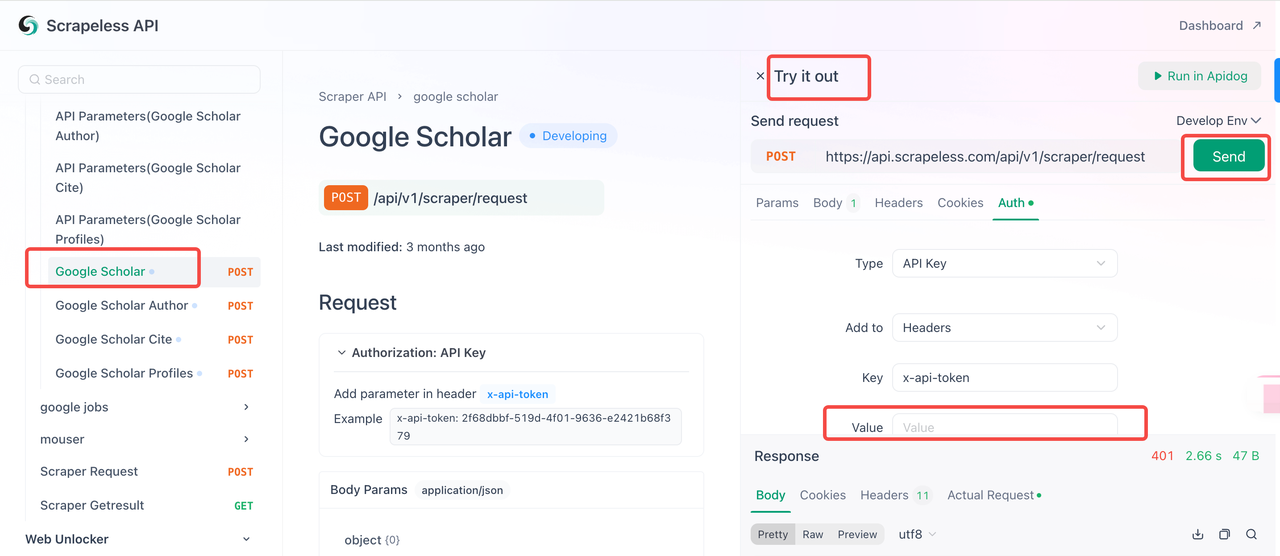
Bước 2: Sử dụng Khóa API của bạn trong mã
Bây giờ bạn có thể sử dụng Khóa API của mình để tích hợp Scrapeless vào dự án của mình. Làm theo các bước sau để kiểm tra và triển khai API:
- Truy cập Tài liệu API.
- Nhấp vào "Thử nghiệm" cho điểm cuối mong muốn.
- Nhập Khóa API của bạn vào trường "Xác thực".
- Nhấp vào "Gửi" để nhận phản hồi thu thập dữ liệu.
Dưới đây là một đoạn mã mẫu mà bạn có thể tích hợp trực tiếp vào Trình thu thập dữ liệu Google Scholar của mình:
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.google.scholar",
"input": {
"engine": "google_scholar",
"q": "biology"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))Ngoài ra, Scrapeless cũng hỗ trợ nhiều giải pháp API thu thập dữ liệu, chẳng hạn như: Amazon scraping API, Shopee Scraping API, Google Flights scraping API, Google Map scraping API, v.v.
Scrapeless Google Scholar API
Scrapeless's Google Scholar API là một công cụ mạnh mẽ có thể thu thập các bài báo học thuật, tạp chí, sách và các nguồn tài nguyên khác từ Google Scholar thông qua các yêu cầu API. Nó cho phép người dùng tìm kiếm theo từ khóa đã chỉ định và thu được thông tin chi tiết về các tài liệu liên quan, chẳng hạn như tiêu đề, thông tin xuất bản, số lần trích dẫn, v.v.
Tham số Google Scholar API
| Tham số | Bắt buộc | Mô tả |
|---|---|---|
| engine | TRUE | Đặt thành google_scholar để sử dụng API này. |
| q | TRUE | Truy vấn tìm kiếm (ví dụ: machine learning). |
| cites | FALSE | ID duy nhất để tìm các bài báo trích dẫn. |
| as_ylo | FALSE | Lọc kết quả từ một năm cụ thể. |
| as_yhi | FALSE | Lọc kết quả đến một năm cụ thể. |
| hl | FALSE | Cài đặt ngôn ngữ (mặc định: en). |
| num | FALSE | Số lượng kết quả (1-20, mặc định: 10). |
Ví dụ: Thu thập dữ liệu kết quả tìm kiếm Google Scholar
Mã yêu cầu:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_scholar",
"q": "biology"
}
payload = Payload("scraper.google.scholar", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Giải thích tham số:
- engine: Đặt thành google_scholar, cho biết việc sử dụng Google Scholar để tìm kiếm.
- q: Truy vấn tìm kiếm (ví dụ: machine learning).
- cites: Tùy chọn. Cung cấp ID của một bài báo (như KNJ0p4CbwgoJ) để tìm các bài báo trích dẫn nó.
- as_ylo: Tùy chọn. Năm bắt đầu (ví dụ: 2015) để lọc kết quả.
- as_yhi: Tùy chọn. Năm kết thúc (ví dụ: 2023) để lọc kết quả.
- hl: Tùy chọn. Cài đặt ngôn ngữ, mặc định là en cho tiếng Anh. Có thể được đặt thành các ngôn ngữ khác (ví dụ: zh cho tiếng Trung).
- num: Tùy chọn. Số lượng kết quả cần trả về, từ 1 đến 20. Mặc định là 10.
Ví dụ phản hồi:
{
"search_information": {
"total_results": 5000000,
"time_taken_displayed": 0.05,
"query_displayed": "machine learning"
},
"organic_result": [
{
"position": 1,
"title": "A survey on machine learning methods",
"result_id": "KNJ0p4CbwgoJ",
"link": "https://example.com/article1",
"snippet": "This article provides a comprehensive survey of machine learning methods, including supervised and unsupervised learning.",
"publication_info": {
"summary": "Author1, Author2 - Journal of Machine Learning, 2020"
}
},
{
"position": 2,
"title": "Deep learning in artificial intelligence",
"result_id": "KNJ0p4CbwgoK",
"link": "https://example.com/article2",
"snippet": "This paper discusses the applications of deep learning in various fields, including computer vision and natural language processing.",
"publication_info": {
"summary": "Author3, Author4 - AI Journal, 2021"
}
}
]
}Cấu trúc phản hồi:
- search_information: Chứa chi tiết về truy vấn tìm kiếm:
- total_results: Tổng số kết quả.
- time_taken_displayed: Thời gian hiển thị kết quả.
- query_displayed: Truy vấn tìm kiếm đã nhập.
- organic_result: Danh sách các kết quả tìm kiếm, mỗi kết quả có:
- position: Thứ hạng của kết quả (ví dụ: thứ 1, thứ 2).
- title: Tiêu đề của bài báo.
- result_id: ID duy nhất của bài báo.
- link: URL đến bài báo.
- snippet: Tóm tắt ngắn gọn hoặc đoạn trích từ bài báo.
- publication_info: Chi tiết xuất bản.
Bằng cách điều chỉnh các tham số này, bạn có thể tinh chỉnh tìm kiếm của mình để có được kết quả phù hợp nhất từ Google Scholar, chẳng hạn như giới hạn kết quả theo năm, ngôn ngữ hoặc số lượng kết quả.
Muốn bắt đầu thu thập dữ liệu kết quả Google Scholar? Nhấp vào đây để xem chi tiết sản phẩm và đăng nhập ngay bây giờ để bắt đầu sử dụng Scrapeless Google Scholar API!
Scrapeless Google Scholar Author API
Scrapeless Google Scholar Author API là một công cụ mạnh mẽ để lấy thông tin tác giả học thuật trên Google Scholar. Nó có thể cung cấp thông tin cơ bản về tác giả, lĩnh vực nghiên cứu, danh sách bài báo và dữ liệu trích dẫn. API này đặc biệt phù hợp với các nhà nghiên cứu và nhà phát triển học thuật để trích xuất tài liệu học thuật, thực hiện phân tích dữ liệu hoặc tích hợp vào các ứng dụng khác.
Tham số Google Scholar Author API
| Tham số | Bắt buộc | Mô tả |
|---|---|---|
| engine | TRUE | Đặt thành google_scholar_author. |
| view_op | FALSE | Xem trích dẫn hoặc đồng tác giả. |
| sort | FALSE | Sắp xếp theo tiêu đề hoặc ngày xuất bản. |
| start | FALSE | Bù đắp cho phân trang. |
| num | FALSE | Số lượng kết quả (tối đa: 100). |
| "view_op false" | FALSE | Có hai tùy chọn: view_citation - Chọn để xem trích dẫn. citation_id là bắt buộc. list_colleagues - Chọn để xem tất cả đồng tác giả. |
| citation_id | FALSE | Là tham số bắt buộc khi chọn view_op=view_citation. Bạn có thể truy cập ID bên trong phản hồi JSON có cấu trúc của chúng tôi. |
Ví dụ: Lấy các ấn phẩm của tác giả
Đây là một ví dụ mã được viết bằng Python cho thấy cách sử dụng Scrapeless Google Scholar Author API để truy vấn thông tin về các tác giả học thuật:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_scholar_author",
"author_id": "LSsXyncAAAAJ"
}
payload = Payload("scraper.google.scholar", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Kết quả được trả về bởi yêu cầu API là một phản hồi được định dạng JSON chứa thông tin chi tiết về tác giả học thuật, chẳng hạn như tên, lĩnh vực học thuật, tổ chức, v.v. Dữ liệu được trả về cũng bao gồm danh sách các bài báo và trích dẫn của tác giả. Dưới đây là một ví dụ đơn giản cho thấy một số kết quả được trả về bởi API:
{
"name": "John Doe",
"institution": "Harvard University",
"research_areas": [
{
"title": "Epigenetics",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:epigenetics"
},
{
"title": "Gene Regulation",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:gene_regulation"
},
{
"title": "Genomics",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:genomics"
},
{
"title": "Transcription Factors",
"link": "https://scholar.google.com/citations?view_op=search_authors&hl=en&mauthors=label:transcription_factors"
}
...Dữ liệu phản hồi chứa thông tin tác giả chi tiết và kết quả nghiên cứu. Các trường kết quả cụ thể bao gồm:
- research_areas: Liệt kê các lĩnh vực nghiên cứu của tác giả, mỗi lĩnh vực đều có liên kết tương ứng trỏ đến kết quả tìm kiếm trên Google Scholar.
- thumbnail: URL của ảnh đại diện của tác giả.
- articles: Chứa các bài báo học thuật chính của tác giả. Thông tin của mỗi bài báo bao gồm tiêu đề, liên kết, tác giả, tạp chí xuất bản, số lần trích dẫn, v.v.
Ví dụ, thông tin chi tiết của một bài báo như sau:
- title: Tiêu đề bài báo
- link: Liên kết bài báo, trỏ đến trang trích dẫn chi tiết trên Google Scholar
- citation_id: ID trích dẫn duy nhất của bài báo trong Google Scholar
- authors: Danh sách tất cả các tác giả tham gia
- publication: Tạp chí mà bài báo được xuất bản và số tập và số phát hành của nó
- cited_by: Số lần bài báo được trích dẫn, và cung cấp liên kết đến trang trích dẫn
Thông tin này rất hữu ích cho các nhà nghiên cứu và nhà phát triển học thuật để phân tích đóng góp học thuật của tác giả.
Scrapeless Google Scholar Cite API
Scrapeless's Google Scholar Cite API là một công cụ mạnh mẽ cho phép người dùng trích xuất thông tin trích dẫn cho các bài báo học thuật trực tiếp từ Google Scholar. Nó có thể truy xuất các trích dẫn được định dạng ở nhiều định dạng, bao gồm MLA, APA, Chicago, Harvard và Vancouver, mang lại sự tiện lợi cho các nhà nghiên cứu, sinh viên và nhà phát triển.
Ngoài ra, Scrapeless's Google Scholar Cite API cũng cung cấp các liên kết xuất cho các công cụ quản lý trích dẫn khác nhau (chẳng hạn như BibTeX, EndNote, RefMan và RefWorks), cho phép tích hợp liền mạch với quy trình làm việc tham khảo. Với khả năng truy xuất dữ liệu thời gian thực và đầu ra JSON có cấu trúc, Scrapeless's Google Scholar Cite API đơn giản hóa quá trình trích dẫn và cải thiện hiệu quả nghiên cứu học thuật.
Tham số Google Scholar Cite API
| Tham số | Bắt buộc | Mô tả |
|---|---|---|
| engine | TRUE | Đặt thành google_scholar_cite. |
| q | TRUE | ID của bài báo để truy xuất trích dẫn. |
| hl | FALSE | Cài đặt ngôn ngữ (mặc định: en). |
Ví dụ: Trích xuất chi tiết trích dẫn
Đây là một ví dụ mã Python minh họa cách thực hiện yêu cầu đối với Scrapeless Google Scholar Cite API.
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_scholar_cite",
"q": "s1QWFy06YAYJ"
}
payload = Payload("scraper.google.scholar", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Ví dụ mã kết quả
API trả lời bằng một đối tượng JSON chứa chi tiết trích dẫn ở nhiều định dạng:
{
"citations": [
{
"title": "MLA",
"snippet": "Masters, Paul S. \"The molecular biology of coronaviruses.\" Advances in virus research 66 (2006): 193-292."
},
{
"title": "APA",
"snippet": "Masters, P. S. (2006). The molecular biology of coronaviruses. Advances in virus research, 66, 193-292."
},
{
"title": "Chicago",
"snippet": "Masters, Paul S. \"The molecular biology of coronaviruses.\" Advances in virus research 66 (2006): 193-292."
},
{
"title": "Harvard",
"snippet": "Masters, P.S., 2006. The molecular biology of coronaviruses. Advances in virus research, 66, pp.193-292."
},
{
"title": "Vancouver",
...
]
}Scrapeless Google Scholar Cite API trả về một cấu trúc JSON chứa hai phần chính: citations (thông tin trích dẫn) và links (liên kết xuất định dạng trích dẫn). Dưới đây là phân tích chi tiết từng trường:
1. Citations
Trường này là một mảng, trong đó mỗi phần tử đại diện cho một định dạng trích dẫn khác nhau, bao gồm MLA, APA, Chicago, Harvard và Vancouver. Mỗi định dạng bao gồm các trường sau:
| Tên trường | Kiểu dữ liệu | Mô tả |
|---|---|---|
| title | String | Tên của định dạng trích dẫn, chẳng hạn như "MLA" hoặc "APA" |
| snippet | String | Văn bản trích dẫn theo định dạng tương ứng, bao gồm tiêu đề bài báo, tác giả, thông tin tạp chí, v.v. |
Ví dụ dữ liệu:
"citations": [
{
"title": "MLA",
"snippet": "Masters, Paul S. \"The molecular biology of coronaviruses.\" Advances in virus research 66 (2006): 193-292."
},
{
"title": "APA",
"snippet": "Masters, P. S. (2006). The molecular biology of coronaviruses. Advances in virus research, 66, 193-292."
}
]Phân tích dữ liệu:
- title: "MLA" cho biết mục nhập này tuân theo định dạng trích dẫn MLA.
- snippet: Văn bản trích dẫn bao gồm tác giả Paul S. Masters, tiêu đề bài báo The molecular biology of coronaviruses, tạp chí Advances in Virus Research, tập 66 và trang 193-292.
2. Links (Liên kết xuất trích dẫn)
Trường này là một mảng, trong đó mỗi phần tử cung cấp một liên kết để xuất trích dẫn ở các định dạng khác nhau như BibTeX, EndNote, RefMan và RefWorks. Mỗi định dạng bao gồm các trường sau:
| Tên trường | Kiểu dữ liệu | Mô tả |
|---|---|---|
| name | String | Tên của định dạng trích dẫn, chẳng hạn như "BibTeX" hoặc "EndNote" |
| link | String | URL cho phép người dùng tải xuống trích dẫn trực tiếp ở định dạng được chỉ định |
Ví dụ dữ liệu:
"links": [
{
"name": "BibTeX",
"link": "https://scholar.googleusercontent.com/scholar.bib?q=info:s1QWFy06YAYJ..."
},
{
"name": "EndNote",
"link": "https://scholar.googleusercontent.com/scholar.enw?q=info:s1QWFy06YAYJ..."
}
]Phân tích dữ liệu:
- name: "BibTeX" cho biết mục nhập này là một liên kết xuất trích dẫn BibTeX.
- link: "https://scholar.googleusercontent.com/scholar.bib?q=info:s1QWFy06YAYJ..." là URL trực tiếp để truy cập trích dẫn BibTeX, có thể được sử dụng trong LaTeX hoặc các công cụ quản lý tham khảo khác.
Scrapeless Google Scholar Profiles API
Scrapeless Google Scholar Profiles API cho phép người dùng tìm kiếm hồ sơ Google Scholar dựa trên tên tác giả và lấy thông tin chi tiết, bao gồm trích dẫn, sở thích, chi nhánh và hơn thế nữa. Dưới đây là tổng quan về cách sử dụng API, các tham số liên quan và cách diễn giải kết quả.
Tham số Google Scholar Profiles API
| Tham số | Bắt buộc | Mô tả |
|---|---|---|
| engine | TRUE | Đặt thành google_scholar_profiles. |
| mauthors | TRUE | Tên tác giả để tìm kiếm hồ sơ. |
| hl | FALSE | Cài đặt ngôn ngữ (mặc định: en). |
| after_author | FALSE | Token cho phân trang. |
Ví dụ: Tìm kiếm hồ sơ tác giả
Mã Python sau đây minh họa cách thực hiện yêu cầu API bằng dịch vụ Scrapeless:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
```vi
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_scholar_profiles",
"mauthors": "Mike"
}
payload = Payload("scraper.google.scholar", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


