
Cách sử dụng Scrapeless để trích xuất dữ liệu từ kết quả tìm kiếm của Google Lens
Advanced Data Extraction Specialist
Google Lens là gì?
Google Lens là một ứng dụng dựa trên trí tuệ nhân tạo và công nghệ nhận dạng hình ảnh có thể xác định các vật thể, văn bản, địa danh và nội dung khác thông qua camera hoặc hình ảnh, và cung cấp thông tin liên quan.
Có hợp pháp khi thu thập dữ liệu từ Google Lens không?
Việc thu thập dữ liệu Google Lens không phải là bất hợp pháp, nhưng có nhiều hướng dẫn pháp lý và đạo đức cần được tuân theo. Người dùng phải hiểu Điều khoản dịch vụ của Google, luật bảo mật dữ liệu và quyền sở hữu trí tuệ để đảm bảo hoạt động của họ tuân thủ. Bằng cách tuân theo các thực tiễn tốt nhất và cập nhật thông tin về các diễn biến pháp lý, bạn có thể giảm thiểu rủi ro về các vấn đề pháp lý liên quan đến việc thu thập dữ liệu web.
Thách thức trong việc thu thập dữ liệu Google Lens
- Công nghệ chống bot tiên tiến: Google giám sát các mô hình lưu lượng truy cập mạng. Số lượng lớn các yêu cầu lặp đi lặp lại từ các trình thu thập dữ liệu có thể bị phát hiện nhanh chóng, dẫn đến việc bị cấm IP, làm dừng quá trình thu thập dữ liệu.
Đọc thêm: Chống Bot: Nó là gì và cách tránh nó - Nội dung được hiển thị bằng JavaScript: Phần lớn dữ liệu của Google Lens được tạo động bằng JavaScript, không thể truy cập được đối với các trình thu thập dữ liệu truyền thống, yêu cầu sử dụng các trình duyệt không có đầu như Puppeteer hoặc Selenium, nhưng điều này làm tăng độ phức tạp và tiêu thụ tài nguyên.
- Bảo vệ CAPTCHA: Google sử dụng CAPTCHA để xác thực người dùng. Trình thu thập dữ liệu có thể gặp phải các thách thức CAPTCHA khó giải quyết bằng lập trình.
- Cập nhật trang web thường xuyên: Google thường xuyên thay đổi cấu trúc và bố cục của Google Lens. Mã thu thập dữ liệu có thể nhanh chóng bị lỗi thời và các bộ chọn XPath hoặc CSS được sử dụng để trích xuất dữ liệu có thể ngừng hoạt động. Cần phải giám sát và cập nhật liên tục.
Hướng dẫn từng bước để thu thập dữ liệu Google Lens bằng Python
Bước 1. Cấu hình môi trường
- Python: Phần mềm là cốt lõi để chạy Python. Bạn có thể tải xuống phiên bản chúng ta cần từ trang web chính thức như hình dưới đây. Tuy nhiên, không nên tải xuống phiên bản mới nhất. Bạn có thể tải xuống 1.2 phiên bản trước phiên bản mới nhất.
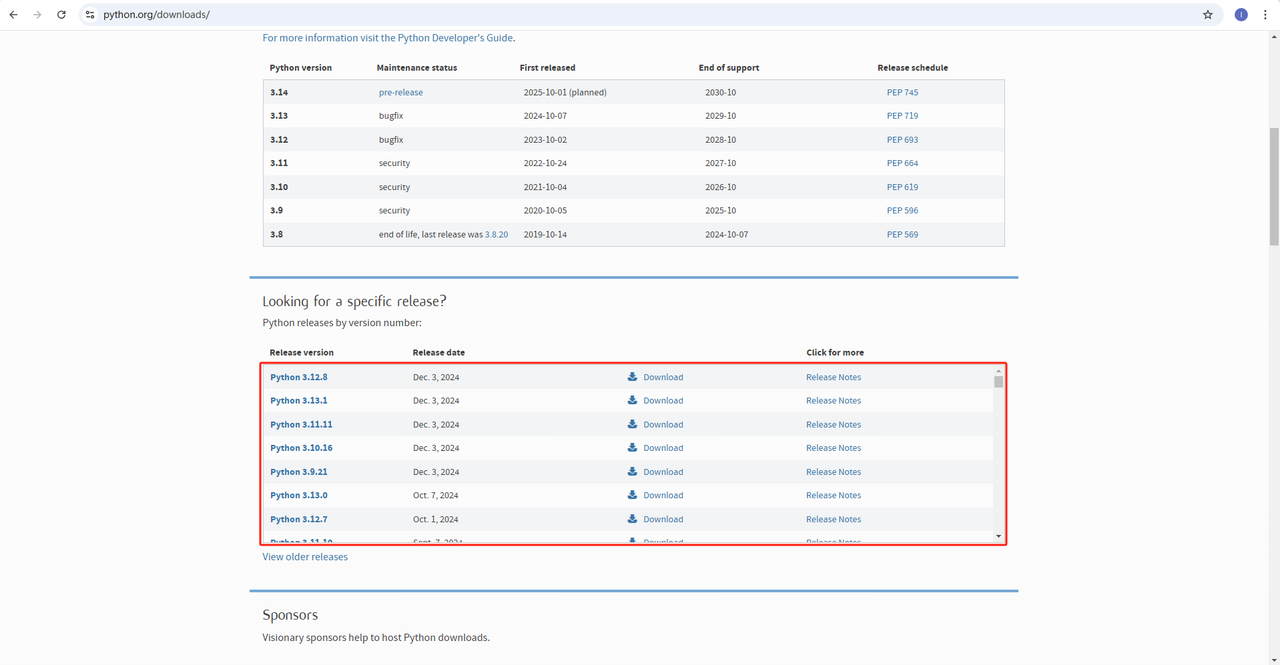
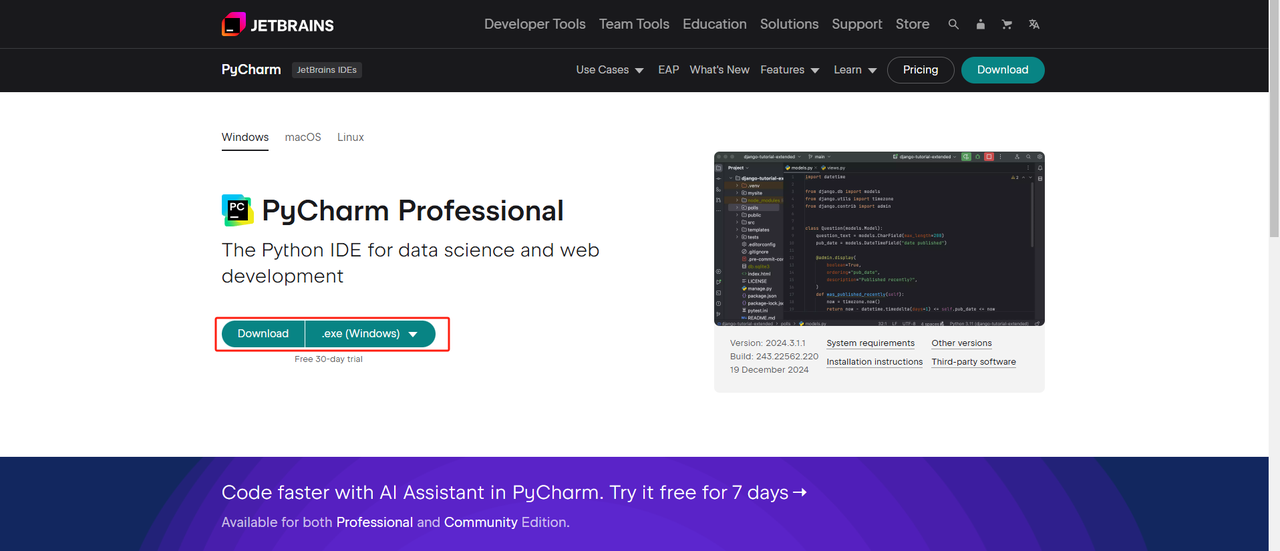
- Python IDE: Bất kỳ IDE nào hỗ trợ Python đều hoạt động, nhưng chúng tôi khuyên dùng PyCharm. Đây là một công cụ phát triển được thiết kế đặc biệt cho Python. Đối với phiên bản PyCharm, chúng tôi khuyên dùng PyCharm Community Edition miễn phí
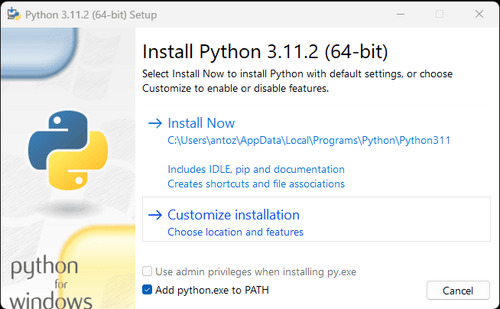
Lưu ý: Nếu bạn là người dùng Windows, đừng quên chọn tùy chọn "Thêm python.exe vào PATH" trong trình hướng dẫn cài đặt. Điều này sẽ cho phép Windows sử dụng Python và các lệnh trong thiết bị đầu cuối. Vì Python 3.4 trở lên đã bao gồm nó theo mặc định, bạn không cần phải cài đặt thủ công.
Bây giờ bạn có thể kiểm tra xem Python đã được cài đặt chưa bằng cách mở thiết bị đầu cuối hoặc dấu nhắc lệnh và nhập lệnh sau:
python --versionBước 2. Cài đặt các phụ thuộc
Nên tạo một môi trường ảo để quản lý các phụ thuộc của dự án và tránh xung đột với các dự án Python khác. Điều hướng đến thư mục dự án trong thiết bị đầu cuối và thực hiện lệnh sau để tạo một môi trường ảo có tên google_lens:
python -m venv google_lensKích hoạt môi trường ảo dựa trên hệ thống của bạn:
Windows:
google_lens_env\Scripts\activateMacOS/Linux:
source google_lens_env/bin/activateSau khi kích hoạt môi trường ảo, hãy cài đặt các thư viện Python cần thiết để thu thập dữ liệu web. Thư viện để gửi yêu cầu trong Python là requests, và thư viện chính để thu thập dữ liệu là BeautifulSoup4. Cài đặt chúng bằng các lệnh sau:
pip install requests
pip install beautifulsoup4
pip install playwrightBước 3. Thu thập dữ liệu
Mở Google lens(https://www.google.com/?olud) trong trình duyệt của bạn và tìm kiếm "https://i.imgur.com/HBrB8p0.png". Dưới đây là kết quả tìm kiếm:
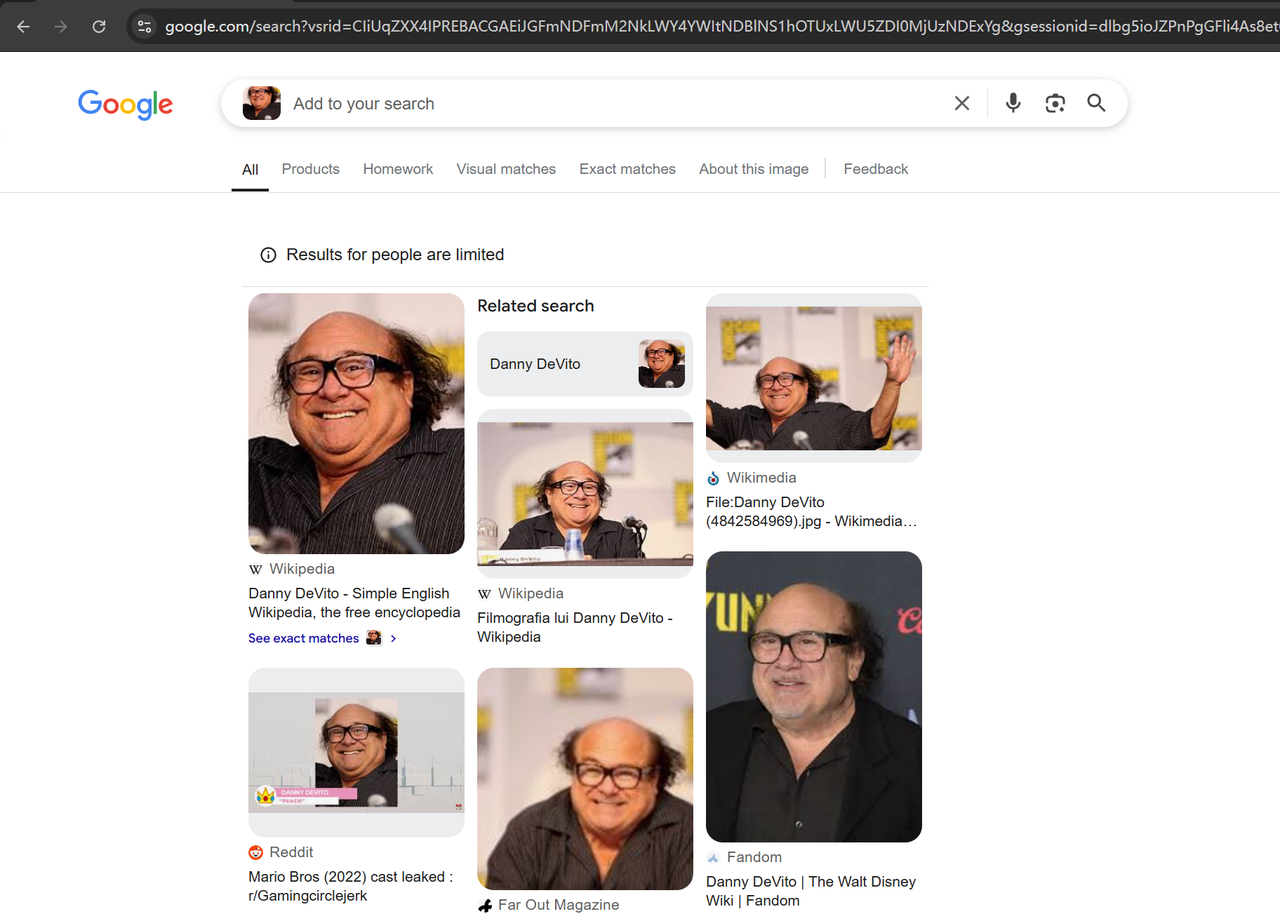
Thu thập thông tin tiêu đề và hình ảnh
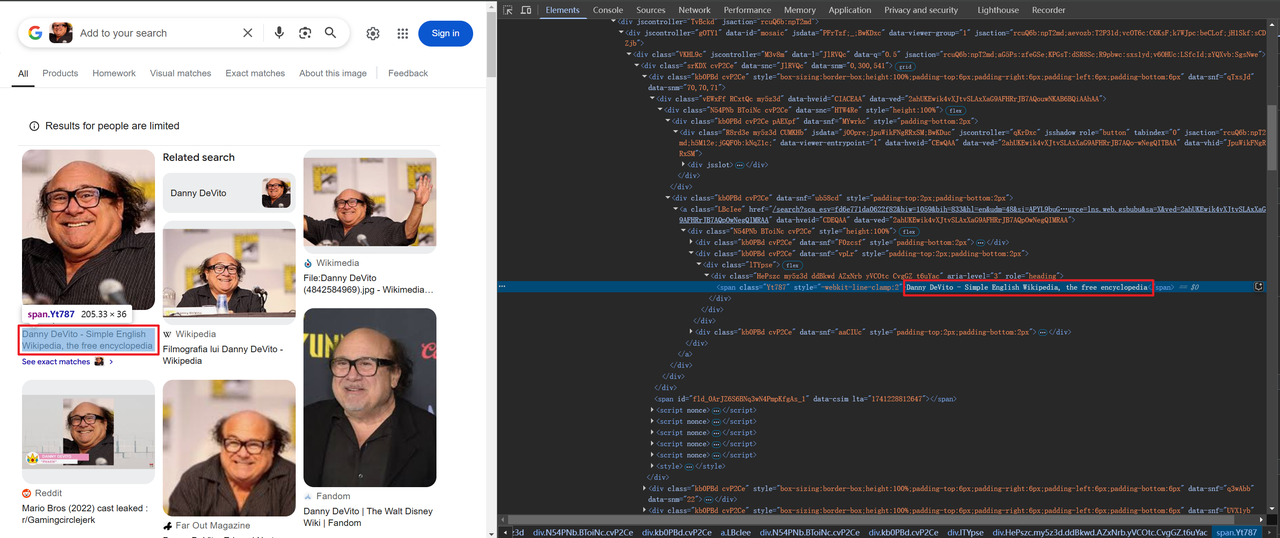
Một số hình ảnh được mã hóa ở dạng base64, trong khi những hình ảnh khác được liên kết thông qua HTTP,ví dụ:
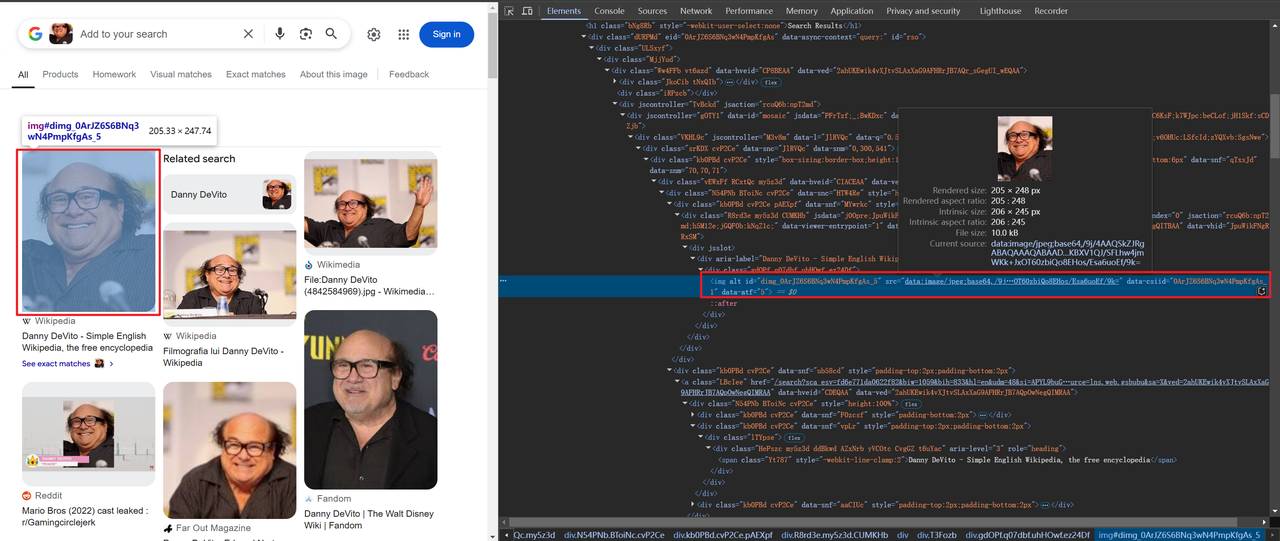
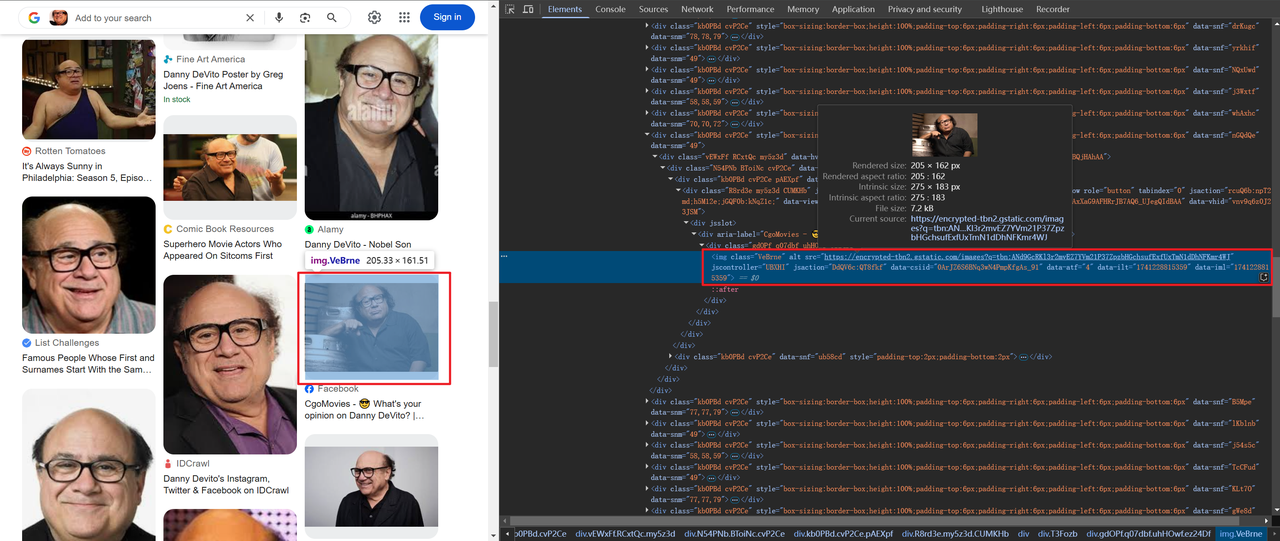
Mã để lấy thông tin tiêu đề và hình ảnh như sau:
# Lưu thông tin lens vào một từ điển
img_info = {
'title': item.find("span").text,
'thumbnail': item.find("img").attrs['src'],
}Vì chúng ta cần thu thập tất cả dữ liệu trên trang, không chỉ một, nên cần lặp lại và thu thập dữ liệu trên. Mã hoàn chỉnh như sau:
import json
from bs4 import BeautifulSoup
from playwright.sync_api import sync_playwright
def scrape(url: str) -> str:
with sync_playwright() as p:
# Khởi chạy trình duyệt và vô hiệu hóa một số tính năng có thể gây ra phát hiện
browser = p.chromium.launch(
headless=True,
args=[
"--disable-blink-features=AutomationControlled",
"--disable-dev-shm-usage",
"--disable-gpu",
"--disable-extensions",
],
)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
bypass_csp=True,
)
page = context.new_page()
page.goto(url)
page.wait_for_selector("body", state="attached")
# Chờ 2 giây để đảm bảo trang được tải đầy đủ hoặc được hiển thị
page.wait_for_timeout(2000)
html_content = page.content()
browser.close()
return html_content
def main():
url = "https://lens.google.com/uploadbyurl?url=https%3A%2F%2Fi.imgur.com%2FHBrB8p0.png"
html_content = scrape(url)
soup = BeautifulSoup(html_content, 'html.parser')
# Lấy dữ liệu chính của trang
items = soup.find('div', {'jscontroller': 'M3v8m'}).find("div")
# lắp ráp vòng tròn
assembly = lens_info(items)
# Lưu kết quả vào tệp JSON
with open('google_lens_data.json', 'w') as json_file:
json.dump(assembly, json_file, indent=4)
def lens_info(items):
lens_data = []
for item in items:
# Lưu thông tin lens vào một từ điển
img_info = {
'title': item.find("span").text,
'thumbnail': item.find("img").attrs['src'],
}
lens_data.append(img_info)
return lens_data
if __name__ == "__main__":
main()Bước 4. Kết quả đầu ra
Một tệp có tên google_lens_data.json sẽ được tạo trong thư mục PyCharm của bạn. Đầu ra như sau (Ví dụ một phần):
[
{
"title": "Danny DeVito - Wikipedia",
"thumbnail": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBxAQEhAQEBAQEB
},
{
"title": "Devito Danny Royalty-Free Images, Stock Photos & Pictures | Shutterstock",
"thumbnail": "https://encrypted-tbn1.gstatic.com/images?q=tbn:ANd9GcSO6Pkv_UmXiianiCh52nD5s89d7KrlgQQox-f-K9FtXVILvHh_"
},
{
"title": "DATA | Celebrity Stats | Page 62",
"thumbnail": "https://encrypted-tbn3.gstatic.com/images?q=tbn:ANd9GcQ9juRVpW6sjE3OANTKIJzGEkiwUpjCI20Z1ydvJBCEDf3-NcQE"
},
{
"title": "Danny DeVito, Grand opening of Buca di Beppo italian restaurant on Universal City Walk Universal City, California - 28.01.09 Stock Photo - Alamy",
"thumbnail": "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcQq_07f-Unr7Y5BXjSJ224RlAidV9pzccqjucD4VF7VkJEJJqBk"
}
]Công cụ hiệu quả hơn: Cách thu thập dữ liệu kết quả Google Lens bằng Scrapeless
Scrapeless cung cấp một công cụ mạnh mẽ giúp các nhà phát triển dễ dàng thu thập dữ liệu kết quả tìm kiếm Google Lens mà không cần viết mã phức tạp. Dưới đây là các bước chi tiết để tích hợp API Scrapeless vào công cụ thu thập dữ liệu Python của bạn:
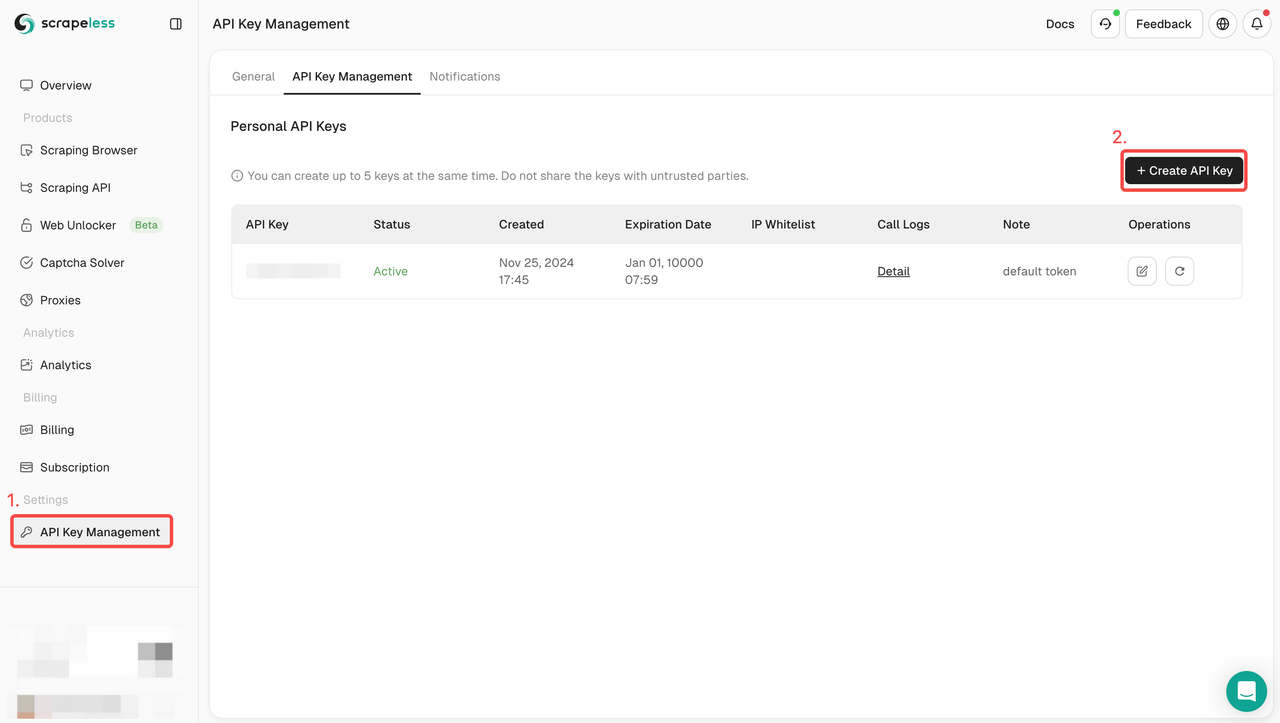
Bước 1: Đăng ký Scrapeless và lấy khóa API
- Nếu bạn chưa có tài khoản Scrapeless, hãy truy cập trang web Scrapeless và đăng ký.
- Sau khi đăng ký, hãy đăng nhập vào bảng điều khiển của bạn.
- Trong bảng điều khiển, điều hướng đến Quản lý Khóa API và nhấp vào Tạo Khóa API. Sao chép khóa API được tạo, đây sẽ là thông tin xác thực của bạn khi gọi API Scrapeless.
Bước 2: Viết một script Python để tích hợp API Scrapeless
Dưới đây là một mã mẫu để thu thập dữ liệu kết quả Google Lens bằng API Scrapeless:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
engine: "google_lens",
hl: "en",
country: "jp",
url: "https://s3.zoommer.ge/zoommer-images/thumbs/0170510_apple-macbook-pro-13-inch-2022-mneh3lla-m2-chip-8gb256gb-ssd-space-grey-apple-m25nm-apple-8-core-gpu_550.jpeg",
}
payload = Payload("scraper.google.lens", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Lưu ý
Bảo mật khóa API: Hãy đảm bảo không để lộ khóa API của bạn trong kho lưu trữ mã công khai.
Tối ưu hóa truy vấn: Điều chỉnh các tham số truy vấn theo nhu cầu của bạn để có được kết quả chính xác hơn. Để biết thêm thông tin về các tham số API, bạn có thể kiểm tra tài liệu API chính thức của Scrapeless
Tại sao chọn Scrapeless để thu thập dữ liệu Google Lens
Scrapeless là một công cụ thu thập dữ liệu web mạnh mẽ do AI điều khiển được thiết kế để thu thập dữ liệu web hiệu quả và ổn định.
1. Dữ liệu thời gian thực và kết quả chất lượng cao
Scrapeless cung cấp kết quả tìm kiếm Google Lens thời gian thực và có thể trả về kết quả tìm kiếm Google Lens trong vòng 1-2 giây. Đảm bảo rằng dữ liệu người dùng nhận được luôn được cập nhật.
2. Giá cả phải chăng
Giá cả của Scrapeless rất cạnh tranh, với giá chỉ từ 0,1 đô la cho 1.000 truy vấn.
3. Hỗ trợ chức năng mạnh mẽ
Scrapeless hỗ trợ nhiều loại tìm kiếm, bao gồm hơn 20 trường hợp tìm kiếm kết quả Google. Nó có thể trả về dữ liệu có cấu trúc ở định dạng JSON, thuận tiện cho người dùng nhanh chóng phân tích cú pháp và sử dụng.
Scrapeless Deep SerpAPI: Giải pháp dữ liệu tìm kiếm thời gian thực mạnh mẽ
Scrapeless Deep SerpApi là một nền tảng dữ liệu tìm kiếm thời gian thực được thiết kế cho các ứng dụng AI và các mô hình tạo ra được tăng cường bằng việc truy xuất (RAG). Nó cung cấp dữ liệu kết quả tìm kiếm Google thời gian thực, chính xác và có cấu trúc, hỗ trợ hơn 20 loại SERP của Google, bao gồm Tìm kiếm Google, Xu hướng Google, Google Shopping, Google Flights, Google Hotels, Google Maps, v.v.

Tính năng cốt lõi
- Cập nhật dữ liệu thời gian thực: dựa trên dữ liệu được cập nhật trong 24 giờ qua, đảm bảo tính kịp thời và chính xác của thông tin.
- Hỗ trợ đa ngôn ngữ và vị trí địa lý: hỗ trợ đa ngôn ngữ và vị trí địa lý, và có thể tùy chỉnh kết quả tìm kiếm dựa trên vị trí, loại thiết bị và ngôn ngữ của người dùng.
- Phản hồi nhanh: Thời gian phản hồi trung bình chỉ 1-2 giây, phù hợp với việc truy xuất dữ liệu tần suất cao và quy mô lớn.
- Tích hợp liền mạch: tương thích với các ngôn ngữ lập trình chính như Python, Node.js, Golang, v.v., dễ dàng tích hợp vào các dự án hiện có.
- Hiệu quả về chi phí: Với giá chỉ từ 0,1 đô la cho 1.000 truy vấn, đây là giải pháp SERP hiệu quả nhất trên thị trường.
Ưu đãi đặc biệt
- Phiên bản dùng thử miễn phí: Có phiên bản dùng thử miễn phí và người dùng có thể trải nghiệm tất cả các tính năng.
- Chương trình hỗ trợ nhà phát triển: 100 người dùng đầu tiên có thể nhận được hạn ngạch gọi API miễn phí trị giá 50 đô la (500.000 truy vấn), phù hợp với các dự án thử nghiệm và mở rộng.
Nếu bạn có bất kỳ câu hỏi hoặc yêu cầu tùy chỉnh nào, bạn có thể liên hệ với Liam bằng cách nhấp vào liên kết Discord.
Kết luận
Trong bài viết này, chúng tôi đã trình bày chi tiết cách sử dụng Scrapeless để thu thập dữ liệu kết quả tìm kiếm Google Lens. Với API mạnh mẽ do Scrapeless cung cấp, các nhà phát triển và nhà nghiên cứu có thể dễ dàng lấy dữ liệu hình ảnh thời gian thực, chất lượng cao mà không cần viết mã phức tạp hoặc lo lắng về các cơ chế chống thu thập dữ liệu. Hiệu quả và tính linh hoạt của Scrapeless làm cho nó trở thành một công cụ lý tưởng để xử lý dữ liệu Google Lens.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.



{kind=link}