
Truy cập Google Jobs để dễ dàng tạo danh sách việc làm bằng Scrapeless
Advanced Data Extraction Specialist
Tìm kiếm dữ liệu việc làm phù hợp một cách nhanh chóng có thể là một thách thức, nhưng với các công cụ phù hợp, nó trở nên dễ dàng. Thu thập dữ liệu việc làm từ Google Jobs có thể giúp các doanh nghiệp, các trang tìm việc và các nhà phát triển thu thập thông tin việc làm chính xác và cập nhật. Bằng cách tự động hóa quy trình, bạn có thể dễ dàng biên soạn danh sách việc làm toàn diện, lọc theo vị trí hoặc loại công việc và tích hợp dữ liệu này vào nền tảng của mình. Trong bài viết này, chúng tôi sẽ chỉ cho bạn cách thu thập dữ liệu Google Jobs hiệu quả và tạo danh sách việc làm vừa phù hợp vừa chính xác.
Google Jobs là gì?
Google Jobs là một công cụ tìm kiếm việc làm chuyên dụng do Google cung cấp, tổng hợp các tin tuyển dụng từ nhiều nguồn khác nhau, bao gồm các trang tìm việc, trang web của công ty và các công ty tuyển dụng. Ra mắt vào năm 2017, Google Jobs nhằm mục đích đơn giản hóa quy trình tìm kiếm việc làm bằng cách cung cấp một nền tảng tổng hợp cho người dùng khám phá các cơ hội việc làm trên khắp các ngành và địa điểm khác nhau.
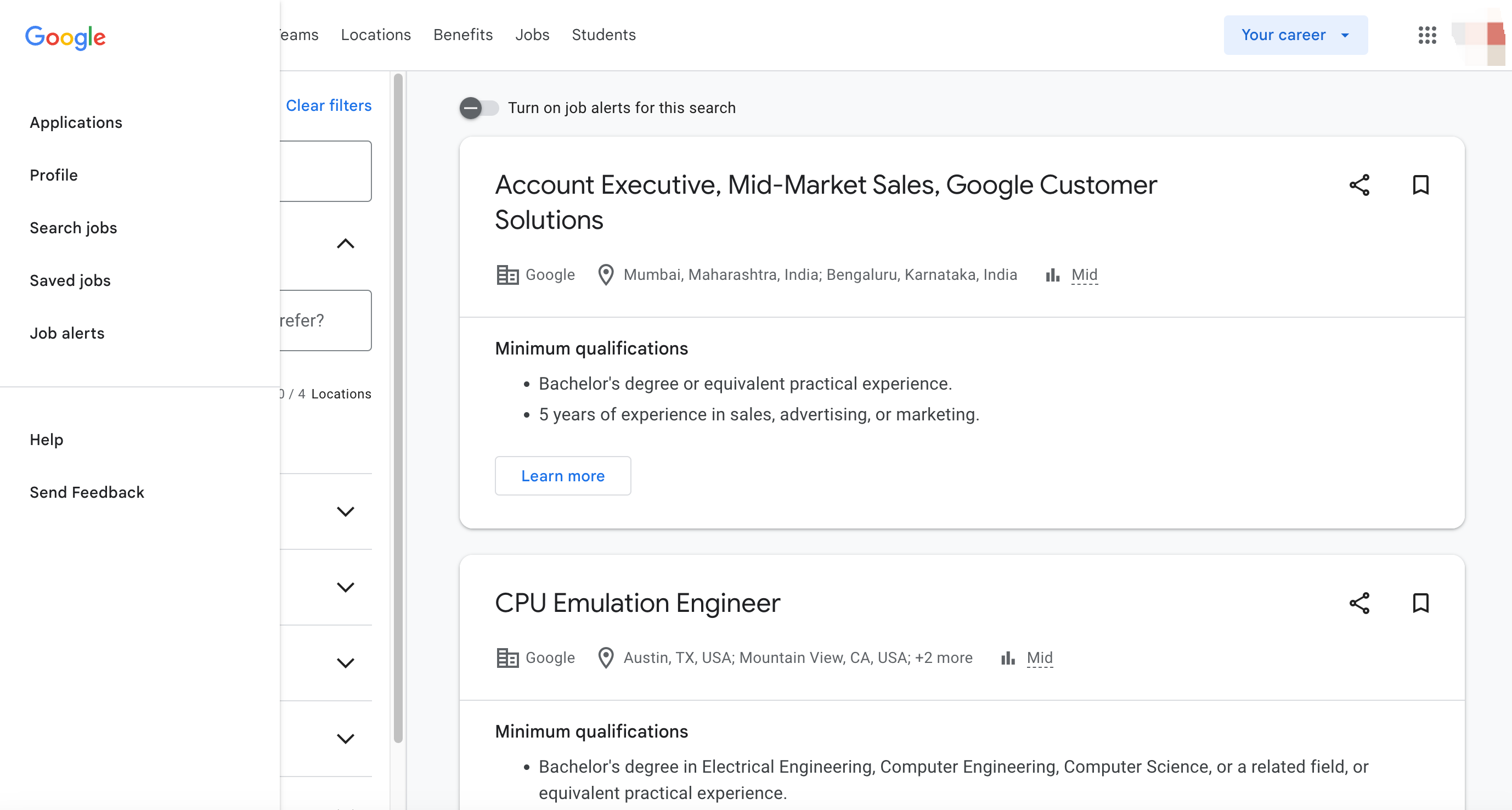
Tại sao nên thu thập dữ liệu Google Jobs?
Thu thập dữ liệu Google Jobs mang lại nhiều lợi ích cho các doanh nghiệp, người tìm việc và các trang tìm việc. Dưới đây là một số lý do chính tại sao bạn nên xem xét thu thập dữ liệu Google Jobs:
1. Tin tuyển dụng toàn diện
Google Jobs tổng hợp tin tuyển dụng từ nhiều nguồn đáng tin cậy, biến nó thành một cửa hàng tổng hợp cho dữ liệu việc làm.
2. Tìm kiếm tùy chỉnh
Bạn có thể lọc kết quả tìm kiếm việc làm dựa trên các tiêu chí cụ thể như vị trí, tiêu đề công việc và phạm vi lương, điều này mang lại cho bạn kết quả phù hợp với đối tượng của mình.
3. Tự động hóa tiết kiệm thời gian
Bằng cách tự động hóa việc thu thập dữ liệu Google Jobs, bạn có thể đảm bảo rằng trang web hoặc ứng dụng của bạn luôn có các tin tuyển dụng cập nhật, loại bỏ sự cần thiết phải cập nhật thủ công.
4. Lợi thế cạnh tranh
Nếu bạn đang điều hành một trang tìm việc hoặc một trang web tuyển dụng, việc có quyền truy cập vào dữ liệu Google Jobs có thể mang lại lợi thế cạnh tranh bằng cách cung cấp các tin tuyển dụng toàn diện thu hút người tìm việc.
Thu thập dữ liệu Google Jobs để dễ dàng tạo danh sách việc làm bằng Python
Tìm việc làm phù hợp có thể là một nhiệm vụ khó khăn, nhưng với Scrapeless, bạn có thể nhanh chóng và hiệu quả thu thập các bài đăng việc làm từ Google Jobs và tích hợp chúng vào các công cụ của riêng bạn. Trong bài viết này, chúng tôi sẽ hướng dẫn bạn cách sử dụng API Scrapeless để thu thập dữ liệu việc làm và tạo danh sách việc làm của riêng bạn.
Scrapeless là một công cụ thu thập dữ liệu web mạnh mẽ và dễ sử dụng, cho phép bạn thu thập dữ liệu có cấu trúc từ nhiều nguồn khác nhau, bao gồm Google Jobs, mà không cần phải xử lý sự phức tạp của việc thu thập dữ liệu trên chính mình.

Ưu điểm của Scrapeless
-
Dữ liệu chính xác và toàn diện: Cung cấp thông tin việc làm chính xác, bao gồm các nội dung chính như tiêu đề công việc, tên công ty, địa điểm làm việc, phạm vi lương, mô tả công việc, v.v.
-
Hỗ trợ tùy chỉnh đa tham số: Cho phép các nhà phát triển sử dụng hơn 10 tham số tùy chỉnh, chẳng hạn như loại công việc (toàn thời gian, bán thời gian, v.v.), yêu cầu kinh nghiệm, lĩnh vực ngành, v.v., để lọc chính xác dữ liệu công việc mục tiêu.
-
Phạm vi phủ sóng đa khu vực: Có thể chụp ảnh kết quả tìm kiếm Google Jobs ở các quốc gia và khu vực khác nhau để đáp ứng nhu cầu mở rộng kinh doanh toàn cầu.
-
Đặc tả định dạng: Xuất dữ liệu ở định dạng JSON chuẩn, thuận tiện cho các nhà phát triển tích hợp và xử lý trong các hệ thống và chương trình khác nhau.
-
Dễ dàng tích hợp: Cung cấp giao diện API đơn giản, thuận tiện cho các nhà phát triển gọi và tích hợp bằng các ngôn ngữ lập trình phổ biến (như Python, Java, v.v.).
-
Cập nhật thời gian thực: Đảm bảo rằng dữ liệu việc làm thu được là thời gian thực và phản ánh thông tin tuyển dụng mới nhất một cách kịp thời.
Đăng ký ngay và nhận $2 tín dụng miễn phí để dùng thử tất cả các tính năng mạnh mẽ của chúng tôi. Đừng bỏ lỡ
Bước 1: Xây dựng môi trường thu thập dữ liệu Google Job
Đầu tiên, chúng ta cần xây dựng một môi trường thu thập dữ liệu và chuẩn bị các công cụ sau:
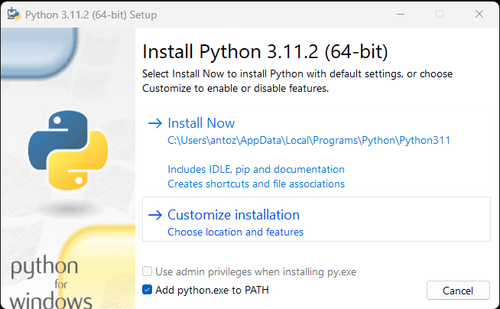
1. Python: Đây là phần mềm cốt lõi để chạy Python. Bạn có thể tải xuống phiên bản chúng ta cần từ liên kết trang web chính thức, như hình dưới đây, nhưng nên tránh tải xuống phiên bản mới nhất. Bạn có thể tải xuống 1-2 phiên bản trước phiên bản mới nhất.
2. Python IDE: Bất kỳ IDE nào hỗ trợ Python đều được, nhưng chúng tôi khuyên bạn nên dùng PyCharm, đây là một phần mềm công cụ phát triển IDE được thiết kế dành riêng cho Python. Về phiên bản PyCharm, chúng tôi khuyên bạn nên dùng PyCharm Community Edition miễn phí.
3. Pip: Bạn có thể sử dụng Python Package Index để cài đặt các thư viện bạn cần để chạy chương trình của mình chỉ với một lệnh duy nhất.
Lưu ý: Nếu bạn là người dùng Windows, đừng quên chọn tùy chọn "Thêm python.exe vào PATH" trong trình hướng dẫn cài đặt. Điều này sẽ cho phép Windows sử dụng Python và các lệnh trong thiết bị đầu cuối. Vì Python 3.4 trở lên đã bao gồm nó theo mặc định, bạn không cần phải cài đặt thủ công.
Thông qua các bước trên, môi trường để thu thập dữ liệu Google Job đã được thiết lập. Tiếp theo, bạn có thể sử dụng PyCharm đã tải xuống kết hợp với Scraperless để thu thập dữ liệu Google Job.
Bước 2: Sử dụng PyCharm và Scrapeless để thu thập dữ liệu Google Jobs
- Khởi chạy PyCharm và chọn File>New Project… từ thanh menu.
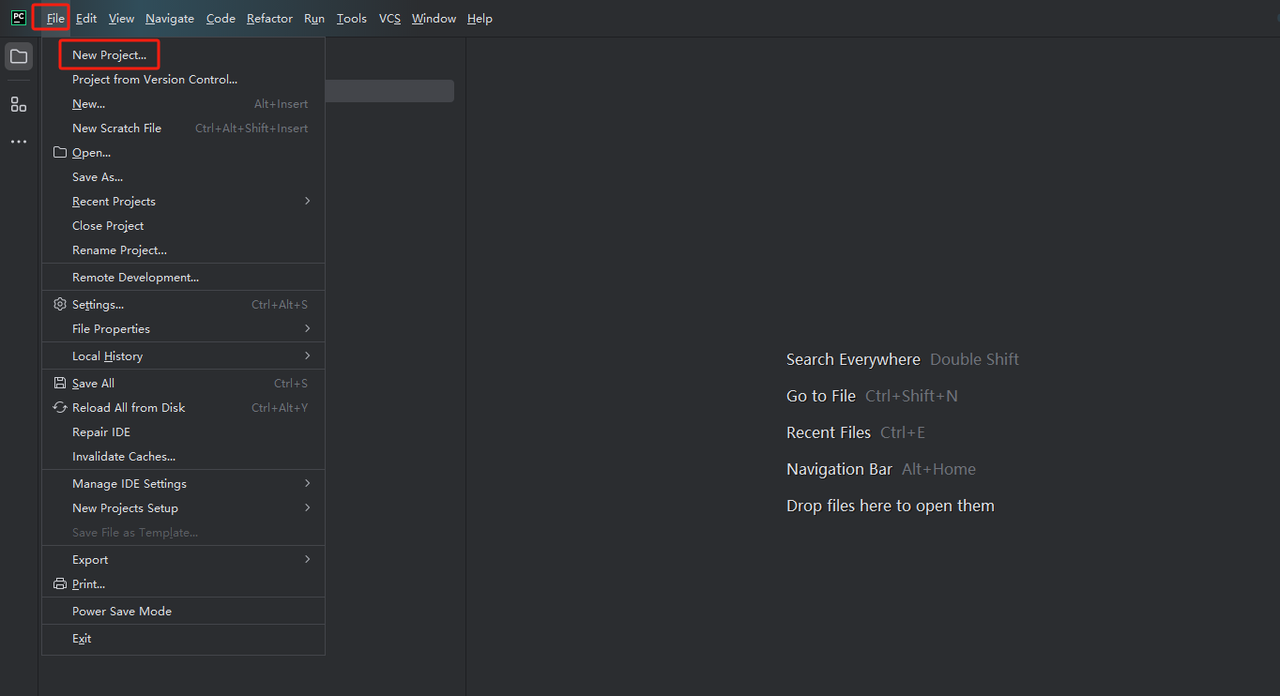
- Sau đó, trong cửa sổ bật lên, chọn Pure Python từ menu bên trái và thiết lập dự án của bạn như sau:
Lưu ý: Trong hộp màu đỏ bên dưới, hãy chọn đường dẫn cài đặt Python đã tải xuống ở bước đầu tiên của cấu hình môi trường
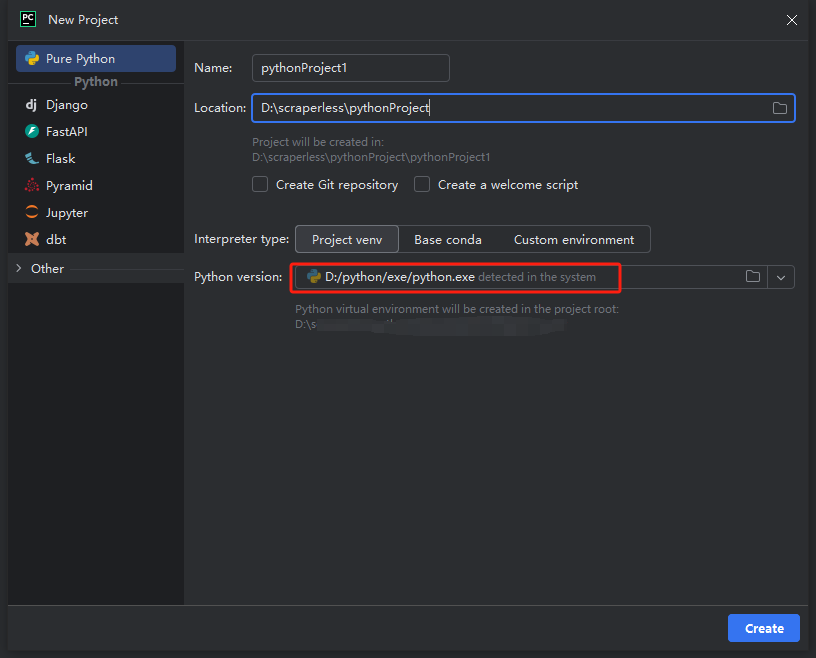
- Bạn có thể tạo một dự án có tên python-scraper, chọn tùy chọn "Tạo tập lệnh chào mừng main.py trong thư mục" và nhấp vào nút "Tạo". Sau khi PyCharm thiết lập dự án trong một thời gian, bạn sẽ thấy như sau:
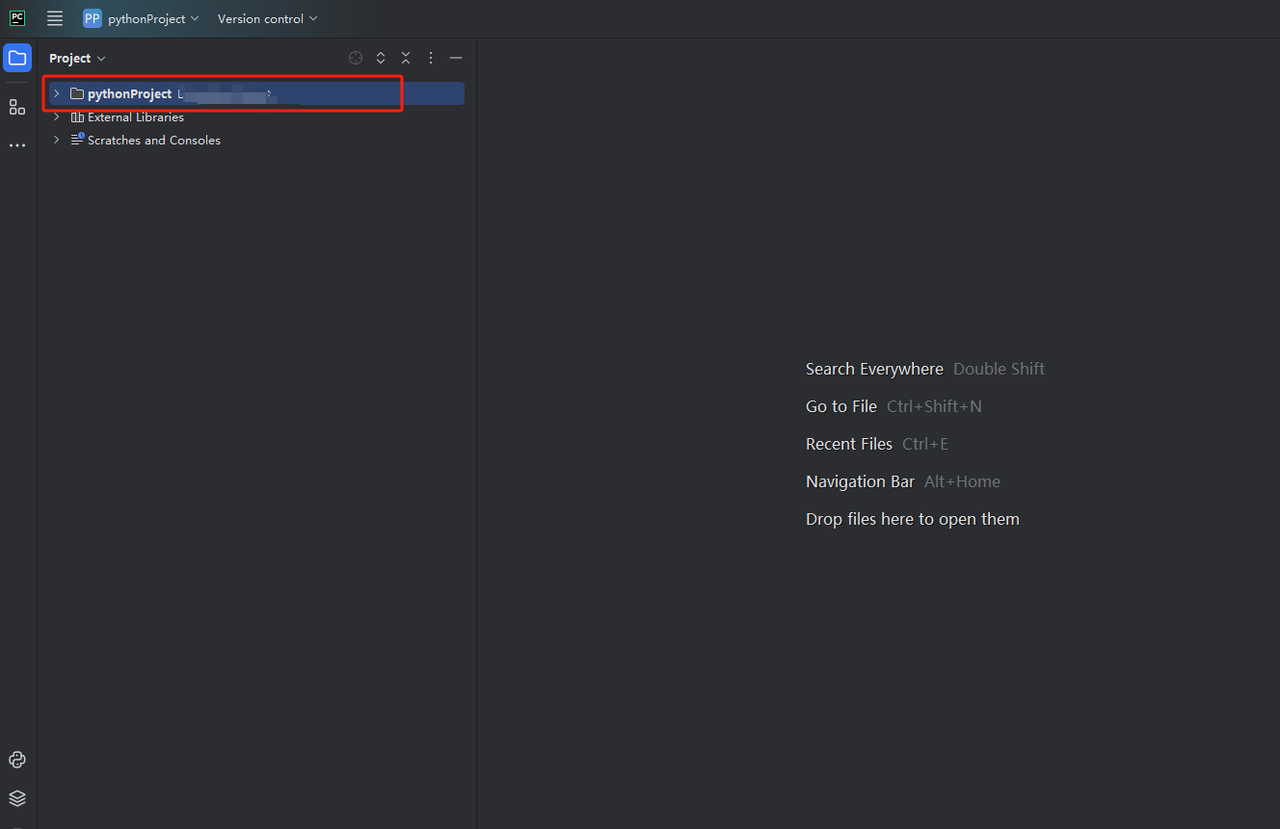
- Sau đó, nhấp chuột phải để tạo một tệp Python mới.
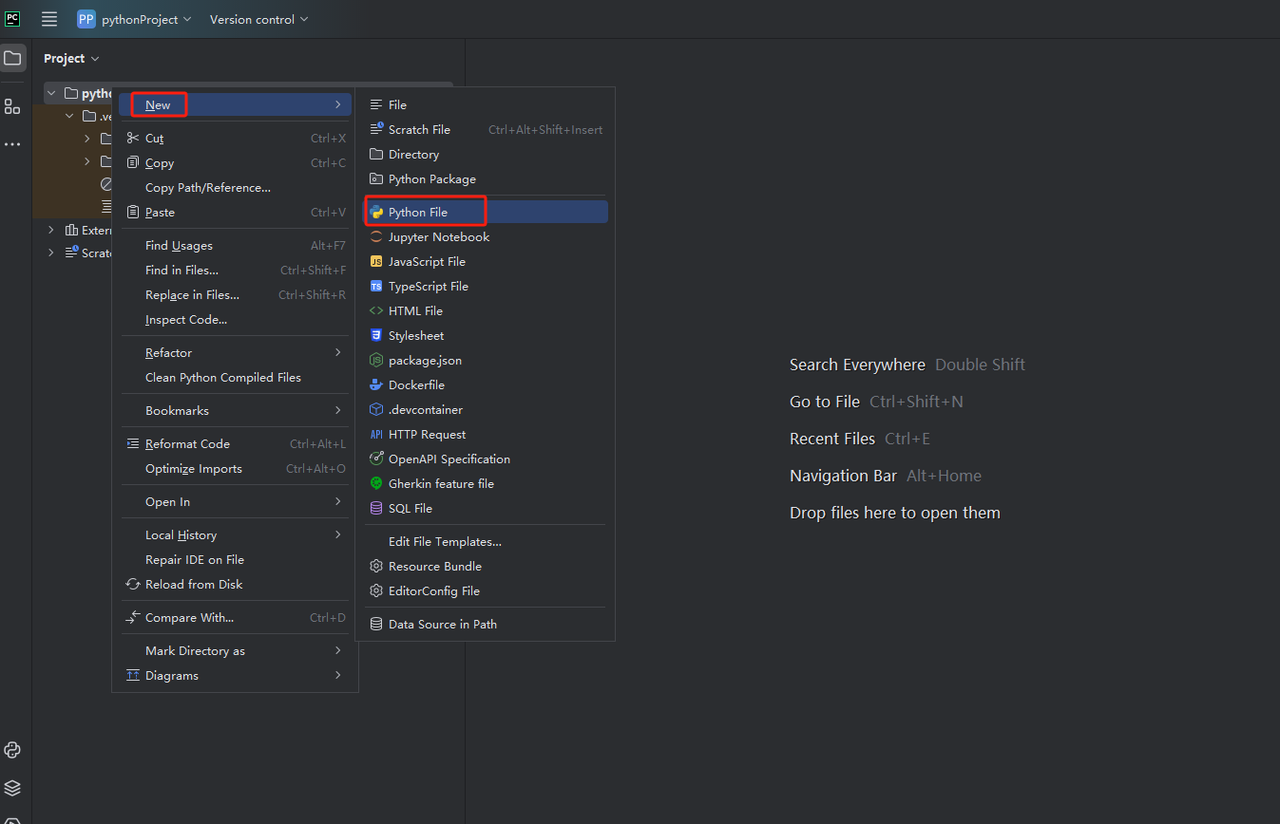
- Để xác minh rằng mọi thứ đều hoạt động chính xác, hãy mở tab Terminal ở cuối màn hình và nhập: python main.py. Sau khi khởi chạy lệnh này, bạn sẽ nhận được: Xin chào, PyCharm.
Bước 3: Nhận khóa API Scrapeless
Bây giờ bạn có thể trực tiếp sao chép mã Scrapeless vào PyCharm và chạy nó, để bạn có thể nhận được dữ liệu định dạng JSON của Google Job. Tuy nhiên, trước tiên bạn cần lấy khóa API Scrapeless. Các bước như sau:
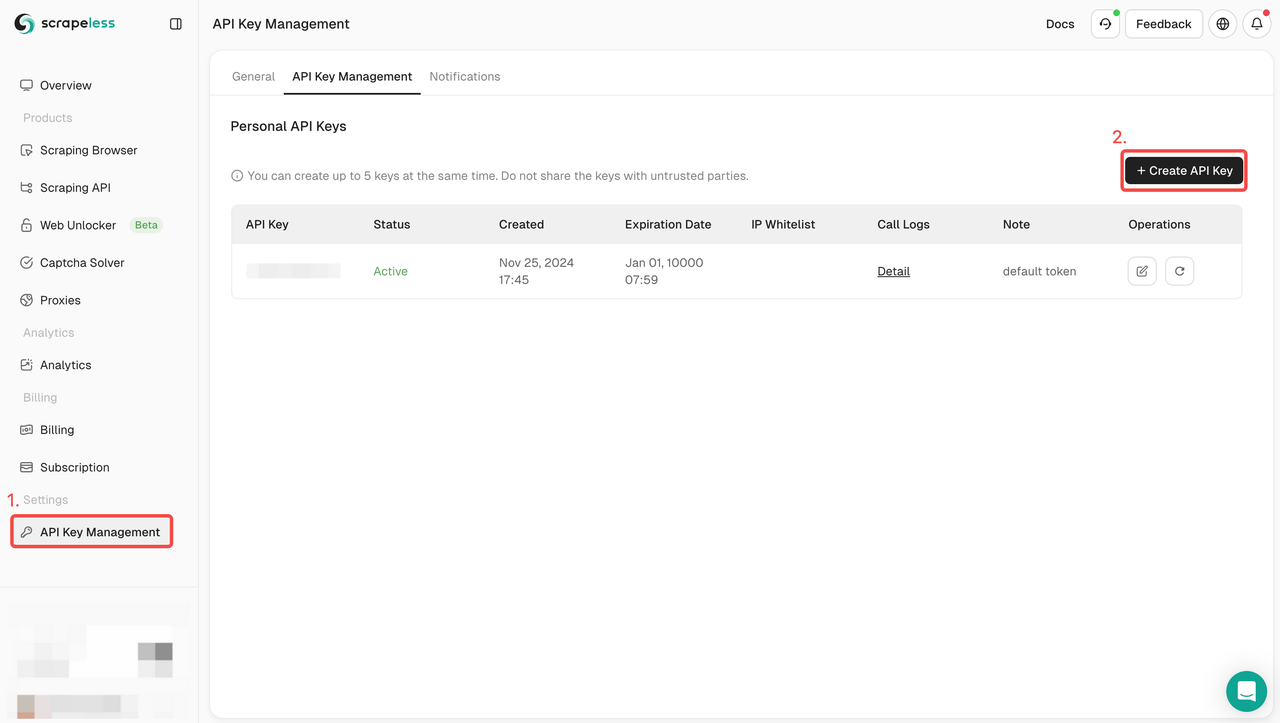
- Nếu bạn chưa có tài khoản, vui lòng đăng ký Scrapeless. Sau khi đăng ký, hãy đăng nhập vào bảng điều khiển của bạn.
- Trong bảng điều khiển Scrapeless của bạn, điều hướng đến Quản lý khóa API và nhấp vào Tạo khóa API. Bạn sẽ nhận được Khóa API của mình. Chỉ cần đặt chuột lên và nhấp vào nó để sao chép. Khóa này sẽ được sử dụng để xác thực yêu cầu của bạn khi gọi API Scrapeless.
Bước 4: Hiểu các tham số API Scrapeless
API Scrapeless cung cấp nhiều tham số mà bạn có thể sử dụng để lọc và tinh chỉnh dữ liệu bạn muốn truy xuất. Dưới đây là các tham số API chính để thu thập thông tin Google Job:
| Tham số | Bắt buộc | Mô tả |
|---|---|---|
| engine | TRUE | Đặt tham số thành google_jobs để sử dụng công cụ API Google Jobs. |
| q | TRUE | Tham số xác định truy vấn bạn muốn tìm kiếm. |
| uule | FALSE | Tham số là vị trí được mã hóa của Google mà bạn muốn sử dụng cho tìm kiếm. Tham số uule và location không thể được sử dụng cùng nhau. |
| google_domain | FALSE | Tham số xác định miền Google cần sử dụng. Mặc định là google.com. Truy cập trang miền Google để xem danh sách đầy đủ các miền Google được hỗ trợ. |
| gl | FALSE | Tham số xác định quốc gia cần sử dụng cho tìm kiếm Google. Đó là mã quốc gia hai chữ cái (ví dụ: us cho Hoa Kỳ, uk cho Vương quốc Anh, fr cho Pháp). Truy cập trang quốc gia Google để xem danh sách đầy đủ các quốc gia Google được hỗ trợ. |
| hl | FALSE | Tham số xác định ngôn ngữ cần sử dụng cho tìm kiếm Google Jobs. Đó là mã ngôn ngữ hai chữ cái (ví dụ: en cho tiếng Anh, es cho tiếng Tây Ban Nha, fr cho tiếng Pháp). Truy cập trang ngôn ngữ Google để xem danh sách đầy đủ các ngôn ngữ Google được hỗ trợ. |
| next_page_token | FALSE | Tham số xác định mã thông báo trang tiếp theo. Nó được sử dụng để truy xuất trang kết quả tiếp theo. Có tối đa 10 kết quả được trả về mỗi trang. Mã thông báo trang tiếp theo có thể được tìm thấy trong phản hồi JSON của SerpApi: pagination -> next_page_token. |
| lrad | TRUE | Xác định bán kính tìm kiếm tính bằng kilômét. Không giới hạn bán kính một cách nghiêm ngặt. |
| ltype | TRUE | Tham số sẽ lọc kết quả theo công việc tại nhà. |
| uds | TRUE | Tham số cho phép lọc tìm kiếm. Đó là một chuỗi được Google cung cấp làm bộ lọc. Giá trị uds được cung cấp trong phần: bộ lọc có uds, giá trị q và link được cung cấp cho mỗi bộ lọc. |
Bước 5: Cách tích hợp API Scrapeless vào công cụ thu thập dữ liệu của bạn
Sau khi có khóa API, bạn có thể bắt đầu tích hợp API Scrapeless vào công cụ thu thập dữ liệu của riêng mình. Dưới đây là một ví dụ về cách gọi API Scrapeless và truy xuất dữ liệu bằng Python và requests.
Mã mẫu để thu thập thông tin Google Job bằng API Scrapeless:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_jobs",
"q": "barista new york",
}
payload = Payload("scraper.google.jobs", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Bước 6: Phân tích dữ liệu kết quả
Dữ liệu kết quả của API Scrapeless sẽ chứa thông tin chi tiết ở định dạng JSON. Dưới đây là một ví dụ một phần về dữ liệu kết quả. Thông tin cụ thể có thể được xem trong tài liệu API.
{
"filters": [
{
"name": "Salary",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=Barista+new+york+salary&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQIDRAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J",
"q": "Barista new york salary"
}
},
{
"name": "Remote",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista%2Bnew%2Byork+remote&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQICxAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU",
"q": "barista+new+york remote"
}
},
{
"name": "Date posted",
"options": [
{
"name": "Yesterday",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york since yesterday&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAC",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw",
"q": "barista new york since yesterday"
}
},
{
"name": "Last 3 days",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last 3 days&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAD",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg",
"q": "barista new york in the last 3 days"
}
},
{
"name": "Last week",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last Các trường chính trong kết quả:
- title: tiêu đề công việc.
- company: công ty cung cấp công việc
- link: liên kết đến bài đăng việc làm
- location: vị trí công việc
- date_posted: ngày đăng bài việc làm
Bây giờ bạn có thể sử dụng dữ liệu này để xây dựng một trang tìm việc, gửi thông báo hoặc tích hợp dữ liệu việc làm vào trang web hoặc ứng dụng hiện có của bạn.
Bạn đang tìm cách dễ dàng thu thập danh sách việc làm?
Bắt đầu sử dụng API Google Jobs của Scrapeless ngay hôm nay! Nhận dữ liệu việc làm chính xác, cập nhật theo thời gian thực một cách dễ dàng và sắp xếp hợp lý quy trình tìm kiếm việc làm của bạn. Thử ngay và xem sự khác biệt!
Khám phá các nguồn dữ liệu phổ biến khác để tuyển dụng và phân tích thị trường việc làm
Ngoài Google Jobs, nhiều nền tảng khác cũng cung cấp dữ liệu tuyển dụng và xu hướng ngành có giá trị, phù hợp cho việc phân tích dữ liệu tuyển dụng rộng hơn. Ví dụ: Crunchbase, Indeed và LinkedIn đều là những nguồn dữ liệu quan trọng cho việc tuyển dụng và phân tích thị trường nhân tài.
- Crunchbase cung cấp thông tin chi tiết về các công ty khởi nghiệp, tài trợ doanh nghiệp, xu hướng ngành, v.v., rất hữu ích cho việc nghiên cứu nhu cầu tuyển dụng của công ty và xu hướng thị trường.
- Indeed là một trong những nền tảng tuyển dụng lớn nhất thế giới, với thông tin việc làm phong phú, dữ liệu lương và xu hướng ngành, phù hợp cho việc phân tích công việc, dự báo lương và nghiên cứu thị trường nhân tài.
- LinkedIn cung cấp mạng xã hội chuyên nghiệp toàn cầu và dữ liệu tuyển dụng, có thể giúp phân tích dòng chảy nhân tài, yêu cầu kỹ năng và xu hướng phát triển công việc.
Nếu doanh nghiệp của bạn không chỉ giới hạn ở việc thu thập dữ liệu Google Jobs, bạn cũng có thể xem xét sử dụng các công cụ như Scrapeless để lấy dữ liệu tuyển dụng từ các nền tảng này để làm phong phú thêm việc phân tích tuyển dụng và nghiên cứu thị trường của bạn.
Nếu bạn có nhu cầu thu thập dữ liệu tương tự, hoặc muốn tìm hiểu cách sử dụng công cụ Scrapeless để thu thập dữ liệu từ Crunchbase, Indeed, LinkedIn và các nền tảng khác, vui lòng liên hệ với chúng tôi. Chúng tôi sẽ cung cấp các giải pháp tùy chỉnh để giúp bạn hoàn thành việc thu thập và phân tích dữ liệu một cách hiệu quả.
Scrapeless Deep SerpApi: Công cụ API Google SERP mạnh mẽ của bạn
Deep SerpApi là một API công cụ tìm kiếm chuyên dụng được thiết kế dành riêng cho các mô hình ngôn ngữ lớn (LLM) và các tác nhân AI. Nó cung cấp thông tin chính xác, khách quan và cập nhật theo thời gian thực, cho phép các ứng dụng AI truy xuất và xử lý dữ liệu từ Google và hơn thế nữa một cách hiệu quả.
✅ Giao diện bao phủ dữ liệu toàn diện: bao gồm hơn 20 kịch bản Google SERP và các công cụ tìm kiếm phổ biến.
✅ Tiết kiệm chi phí: Deep SerpApi cung cấp giá từ 0,10 đô la cho mỗi nghìn truy vấn, với thời gian phản hồi 1-2 giây, cho phép các nhà phát triển và doanh nghiệp lấy dữ liệu hiệu quả và với chi phí thấp.
✅ Khả năng tích hợp dữ liệu nâng cao: có thể tích hợp thông tin từ tất cả các kênh trực tuyến và công cụ tìm kiếm hiện có.
✅ Nhận cập nhật thời gian thực với dữ liệu được làm mới trong 24 giờ qua.
Là một phần của lộ trình trong tương lai, chúng tôi hoàn toàn cam kết đáp ứng nhu cầu của các nhà phát triển AI bằng cách đơn giản hóa việc tích hợp thông tin web động vào các giải pháp do AI điều khiển. Mục tiêu là cung cấp một API ALL-in-One cho phép tìm kiếm và trích xuất dữ liệu liền mạch chỉ với một cuộc gọi duy nhất.
🎺🎺Thông báo thú vị!
Chương trình hỗ trợ nhà phát triển: Tích hợp Scrapeless Deep SerpApi vào các công cụ, ứng dụng hoặc dự án AI của bạn. [Chúng tôi đã hỗ trợ Dify và sẽ sớm hỗ trợ Langchain, Langflow, FlowiseAI và các framework khác]. Sau đó, chia sẻ kết quả của bạn trên GitHub hoặc phương tiện truyền thông xã hội, và bạn sẽ nhận được hỗ trợ nhà phát triển miễn phí trong 1-12 tháng, lên tới 500 đô la mỗi tháng.
Câu hỏi thường gặp
Câu 1: Làm thế nào để tôi có được khóa API cho Scrapeless?
Đăng ký tại scrapeless.com, đăng nhập vào bảng điều khiển của bạn và tạo khóa API trong phần Quản lý khóa API.
Câu 2: Tôi có thể thu thập dữ liệu việc làm từ các trang web khác không?
Có, Scrapeless hỗ trợ thu thập dữ liệu từ nhiều trang đăng tuyển dụng và nhiều loại dữ liệu khác. API Google Jobs chỉ là một ví dụ.
Câu 3: Tôi có thể thu thập dữ liệu Google Jobs miễn phí không?
Scrapeless cung cấp bản dùng thử miễn phí giới hạn. Để tiếp tục, bạn sẽ cần một gói trả phí, cung cấp cho bạn quyền truy cập vào giới hạn cao hơn và các tính năng nâng cao hơn.
Câu 4: Scrapeless còn cung cấp gì khác?
Ngoài Google Jobs, Scrapeless có thể thu thập nhiều loại dữ liệu, bao gồm Google Maps, Google Flights, Google Trends, v.v.
Kết luận
Thu thập dữ liệu Google Jobs bằng API Scrapeless là một cách mạnh mẽ và dễ dàng để thu thập bài đăng việc làm cho các dự án của riêng bạn. Chỉ với một vài dòng mã, bạn có thể tích hợp Scrapeless vào trình thu thập dữ liệu của mình và tự động hóa quy trình trích xuất dữ liệu việc làm.
Bằng cách tận dụng khả năng của Scrapeless, bạn có thể nhanh chóng tạo ra các bài đăng việc làm từ công cụ tìm kiếm việc làm của Google, tiết kiệm thời gian và tập trung vào việc xây dựng trang tìm việc hoặc ứng dụng của mình.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


