
CAPTCHA hoạt động như thế nào?
Advanced Bot Mitigation Engineer
Tìm một người chưa từng phải chứng minh với máy móc rằng họ là con người sẽ rất khó. Có vẻ lạ khi dùng nắp cống để giải những câu đố kỳ lạ như một minh chứng cho sự nhận thức. Sau khi đọc bài luận này, nó sẽ không còn lạ nữa. Bạn sẽ sớm biết CAPTCHA hoạt động như thế nào và cách bạn đóng góp đáng kể vào việc đào tạo AI bằng cách giải chúng. Ngoài ra, bạn sẽ học cách reCAPTCHAs hoạt động.
Tại sao cần CAPTCHA?
Kiểm tra Turing hoàn toàn tự động để phân biệt máy tính và con người được biết đến với tên viết tắt CAPTCHA. Đôi khi nó còn được gọi là Chứng minh tương tác của con người (HIP). Mục đích của kiểm tra CAPTCHA là phân biệt giữa con người và bot. CAPTCHA truyền thống thách thức người dùng nhận biết văn bản bằng cách kéo căng và bóp méo chữ cái, chữ số và các ký tự khác. Mặc dù nhiệm vụ này có vẻ đơn giản đối với con người, nhưng robot lại khó hoàn thành.
Alan Turing, người đôi khi được gọi là người sáng lập ra máy tính hiện đại, đã công bố bài kiểm tra Turing vào năm 1950. Mục đích của đánh giá này là để chứng minh xem robot có thể bắt chước quá trình tư duy của con người hay không. Một người thẩm vấn đặt ra một loạt câu hỏi cho hai người tham gia trong quá trình kiểm tra. Có hai người tham gia: một người và một máy. Người thẩm vấn phải đưa ra giả định dựa trên phản hồi của họ, bởi vì họ không chắc ai là ai. Hệ thống vượt qua bài kiểm tra nếu người thẩm vấn không thể xác định người tham gia.
CAPTCHA truyền thống dựa trên bài kiểm tra Turing, như tên gọi của nó.
CAPTCHA hoạt động như thế nào?
Xác định con người từ bot là mục tiêu của CAPTCHA. Kiểm tra CAPTCHA làm điều này bằng cách hiển thị đồ họa khác nhau cho người dùng khác nhau. Để cung cấp nhiều phiên bản khác nhau nhất có thể, một cơ sở dữ liệu khổng lồ về CAPTCHA được duy trì. Một máy có thể bẻ khóa mã CAPTCHA trong thời gian ngắn nếu giải pháp luôn giống nhau hoặc nếu nó bị che giấu trong thông tin của hình ảnh.
Mặc dù CAPTCHA được thiết kế để con người hoàn thành, nhưng không phải ai cũng có thể hoàn thành nó ngay từ lần thử đầu tiên. Các chuyên gia ước tính rằng 80% CAPTCHA có thể được con người giải quyết, trong khi 0,01% có thể được máy tính hoàn thành.
Vì máy tính không giỏi phân tích dữ liệu hình ảnh như con người, nên phần lớn các bài kiểm tra CAPTCHA truyền thống dựa vào nhận thức thị giác. Hầu hết mọi người khá giỏi trong việc nhận biết các mẫu và thiết lập mối liên hệ giữa các chủ đề không liên quan. Pareidolia là khả năng nhận biết các mẫu đã được xác định trước đó khi chúng không xảy ra. Ví dụ, khi bộ não của chúng ta cố gắng liên kết thông tin với các mẫu, chúng ta có thể nhận biết các hình dạng dễ nhận biết trong đám mây.
Đối với những người bị khiếm thị, CAPTCHA được cung cấp ở định dạng âm thanh. Để ngăn chặn bot vượt qua các bài kiểm tra này, thường có một số tiếng ồn nền trong âm thanh.
Các loại CAPTCHA
Tùy thuộc vào loại tài liệu, có ba loại CAPTCHA: dựa trên văn bản, dựa trên hình ảnh và dựa trên âm thanh.
CAPTCHA dựa trên văn bản
Loại phổ biến nhất kết hợp một số lý lẽ hoặc biểu thức, ký tự và số.
Các ký tự có thể có nền có kết cấu và cách trình bày kỳ lạ, bị bóp méo, khiến phi nhân loại khó đọc hơn.

CAPTCHA dựa trên hình ảnh
Thường là một lưới các hình ảnh vuông mô tả các vật thể phổ biến. Người dùng phải chọn những hình ảnh có các yếu tố cần thiết. Google thường yêu cầu Street View nhận biết các vật thể phổ biến như vạch kẻ đường và một số loại xe nhất định. Hầu hết khách truy cập hoàn thành CAPTCHA hình ảnh khá nhanh chóng. Tuy nhiên, để xác định một đối tượng, một bot sẽ phải thực hiện một phương pháp so sánh dài hơn, điều này sẽ cản trở tiến độ của nó hướng tới mục tiêu dự định. So với CAPTCHA dựa trên văn bản, CAPTCHA dựa trên hình ảnh là một chiến thuật chống bot được ưa chuộng hơn do sự phức tạp của việc kiểm tra dựa trên hình ảnh.
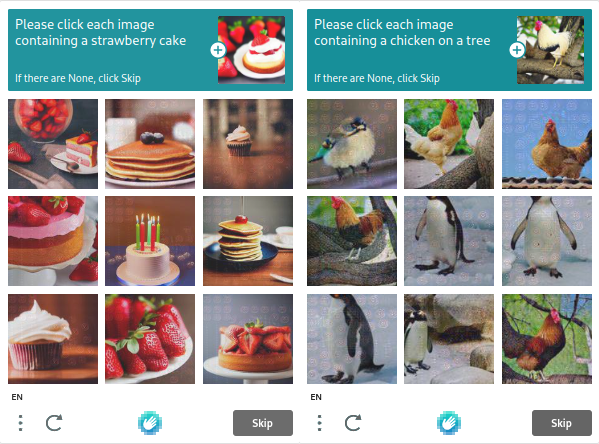
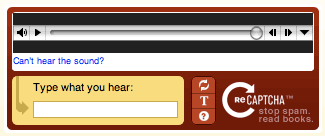
CAPTCHA dựa trên âm thanh
CAPTCHA dựa trên văn bản và hình ảnh thường được sử dụng kết hợp với CAPTCHA dựa trên âm thanh. Nhạc nền bao gồm tiếng ồn nền và một bản ghi âm giọng nói đánh vần các ký hiệu. Tiếng ồn, thường là một loạt tiếng ồn kỹ thuật như nhiễu tĩnh, đóng vai trò là hàng rào. Bot không thể phân biệt các ký hiệu được đánh dấu khỏi tiếng ồn nền trong CAPTCHA âm thanh.
reCAPTCHA: nó là gì?
Google cung cấp một công cụ được gọi là ReCAPTCHA phục vụ cùng mục đích với CAPTCHA tiêu chuẩn. Đây là một giải pháp bảo mật web miễn phí phổ biến cho các trang web. Bạn có thể đã từng thấy qua reCAPTCHAs nơi người dùng được yêu cầu tích vào một hộp thay vì giải quyết một vấn đề. Chúng tôi gọi những cái này là "noCAPTCHA reCAPTCHA". Nếu người dùng tích vào hộp và hệ thống vẫn chưa tin, họ sẽ được nhắc cung cấp bằng chứng nhận diện là người.
Chúng tôi sử dụng reCAPTCHAs như thế nào?
Ban đầu, sách được số hóa, ảnh tên đường phố được sử dụng, các đoạn văn bản báo chí được lấy, và người dùng được yêu cầu giải mã các từ hoặc kết hợp từ. Một người có thể dễ dàng diễn giải các từ từ một bức ảnh, nhưng một bot thấy khó để làm điều tương tự.
Khi máy tính trở nên tiên tiến hơn, reCAPTCHAs cũng trở nên phức tạp hơn. Theo thời gian, các loại reCAPTCHA khác đã được tạo ra; chúng bao gồm hộp kiểm tra, nhận dạng hình ảnh và đánh giá hành vi chung của người dùng không cần đầu vào của người dùng.
So sánh reCAPTCHA V2 và V3
ReCAPTCHA v3 không chỉ là một phiên bản nâng cao của reCAPTCHA v2, mặc dù có vẻ như là như vậy. Hai giải pháp thực sự đáp ứng các nhu cầu khác nhau và rất khác biệt với nhau.
reCAPTCHA v2 được định nghĩa là tích vào một hộp có nhãn "Tôi không phải là robot". Trong hầu hết các trường hợp, điều này đánh dấu kết thúc bài kiểm tra; nhưng, trong một số trường hợp hiếm hoi, người dùng có thể được yêu cầu làm bài kiểm tra bổ sung để xác minh danh tính của họ.
Bởi vì reCAPTCHA v3 hoạt động trong nền sử dụng phân tích rủi ro nâng cao và học máy, bạn có thể không nhận thức được sự tồn tại của nó. Một quản trị web nhận được điểm số từ ReCAPTCHA v3 dựa trên cách người dùng cư xử. Bạn được phân loại là bot hoặc người dựa trên điểm số của bạn. Khả năng là người tăng lên với điểm số. Một quản trị web đưa ra quyết định cuối cùng về việc chặn, tiếp tục kiểm tra hoặc cho phép qua.
V3 và V2 chỉ được sử dụng trong các tình huống cụ thể. ReCAPTCHA v2 phù hợp cho các trang web nhỏ hơn muốn hạn chế khách truy cập tự động. Một trang web có thể có v2 được thêm vào chỉ với hai dòng mã HTML.
Trí tuệ nhân tạo và Captcha
Huấn luyện trí tuệ nhân tạo (AI) được minh họa hoàn hảo bởi CAPTCHA và reCAPTCHAs. Như đã nêu trước đây, thuật toán xác định xem câu trả lời có chính xác hay không dựa trên phản hồi của các người dùng khác khi nó yêu cầu, ví dụ, nhấp vào mỗi con mèo trong các bức ảnh.
Ngoài ra, dữ liệu này cung cấp cho AI, cho phép máy tính nhận dạng ảnh chính xác hơn.
Máy tính gặp khó khăn trong việc nhận dạng hình ảnh. Ví dụ, khi một bức ảnh được chụp từ một góc nhìn khác, robot không thể tạo ra các liên kết tương tự như mắt người có thể. Nhưng với công nghệ tiên tiến nhất hiện nay, máy tính đang trở nên phức tạp hơn, và robot đang trở nên thông minh hơn nhờ học máy.
Có thể bỏ qua CAPTCHA không?
Bằng cách bỏ qua CAPTCHA, những bài kiểm tra này có thể được cải thiện hơn, và bước đầu tiên để cải thiện một giải pháp là tìm ra nơi nó thiếu sót. Mỗi lần một bot hoàn thành một CAPTCHA, nó sẽ tiến gần hơn một bước trong việc phát triển các bài kiểm tra tốt hơn. Tuy nhiên, bỏ qua CAPTCHA là một thách thức khó khăn.
Bị đưa vào danh sách đen hoặc nhận CAPTCHA là hai trong số các vấn đề thường gặp nhất gặp phải với việc thu thập dữ liệu trực tuyến. Những khó khăn này có thể khiến các nỗ lực thu thập dữ liệu công khai quy mô lớn bị gián đoạn. Một số doanh nghiệp như Scrapeless đã tìm ra cách để bỏ qua CAPTCHA.
Bạn có mệt mỏi với CAPTCHA và các khối thu thập dữ liệu web liên tục không?
Scrapeless: giải pháp thu thập dữ liệu trực tuyến tất cả trong một tốt nhất hiện có!
Sử dụng bộ công cụ mạnh mẽ của chúng tôi để khai thác hết tiềm năng của quá trình trích xuất dữ liệu của bạn:
Trình giải CAPTCHA tốt nhất
Giải quyết tự động các CAPTCHA phức tạp để đảm bảo thu thập dữ liệu liên tục và suôn sẻ.
Thử dùng miễn phí!
Tóm lại
Các trang web được bảo vệ khỏi thư rác và lạm dụng thông qua CAPTCHA. Bằng cách đưa ra một bài kiểm tra chỉ nên được hoàn thành bởi con người, CAPTCHA cố gắng phân biệt giữa người dùng là người và chương trình tự động. Bài kiểm tra Turing đã truyền cảm hứng cho CAPTCHA.
Google cung cấp một giải pháp CAPTCHA được gọi là ReCAPTCHAs. reCAPTCHA có nhiều hình thức khác nhau, và một số trong số chúng thậm chí không cần sự tham gia của con người. Nguyên nhân chính xác của reCAPTCHAs là không rõ, mặc dù các nguyên nhân tiềm ẩn bao gồm lịch sử trình duyệt, theo dõi cookie và tương tác trang web theo thời gian thực.
Vì mục tiêu chính của CAPTCHA là khó cho bot giải quyết, nên việc bỏ qua nó trên máy tính là khó khăn. Mặt khác, một số giải pháp - như Web Scraper API - cho phép thu thập dữ liệu web mà không bị giới hạn IP hoặc CAPTCHA.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


