
Cách dùng Python để trích xuất dữ liệu từ Google Scholar?
Expert Network Defense Engineer
Google Scholar là công cụ tìm kiếm truy cập dữ liệu học thuật. Với Google Scholar, bạn có thể tìm kiếm các bài báo khoa học, bài nghiên cứu và luận văn. Tuy nhiên, nghiên cứu học thuật thường yêu cầu thu thập và phân tích một lượng lớn dữ liệu từ kết quả tìm kiếm Google Scholar.
Việc tìm kiếm thủ công qua vô số kết quả là một nhiệm vụ khó khăn. Đó là lý do tại sao một công cụ thu thập dữ liệu Google Scholar đáng tin cậy có thể giúp quá trình này bớt khó khăn hơn. Với tự động hóa, bạn có thể thu thập dữ liệu từ Google Scholar để trích xuất dữ liệu như tiêu đề, tác giả và trích dẫn từ mỗi kết quả trên trang Google Scholar chỉ trong vài giây.
Trong hướng dẫn này, bạn sẽ học cách xây dựng một công cụ thu thập dữ liệu Google Scholar hiệu quả bằng cách gửi yêu cầu HTTP sử dụng API Scrapeless Google Scholar và Python.
Hãy cuộn xuống để tìm hiểu thêm!
🎓 Công cụ thu thập dữ liệu Google Scholar là gì?
Công cụ thu thập dữ liệu Google Scholar là một công cụ được thiết kế để trích xuất dữ liệu học thuật công khai từ Google Scholar, chẳng hạn như bài nghiên cứu, trích dẫn, tác giả và thông tin xuất bản. Nó cho phép các nhà nghiên cứu, học giả và tổ chức thu thập những hiểu biết quý giá để phân tích, theo dõi xu hướng và nghiên cứu học thuật. Tuy nhiên, việc thu thập dữ liệu từ Google Scholar đi kèm với những thách thức đáng kể do các cơ chế chống thu thập dữ liệu mạnh mẽ của nó.
Tại sao dữ liệu trên Google Scholar có giá trị?
- Đánh giá và Nghiên cứu: Tìm các bài báo, bài viết, luận án và sách liên quan đến nghiên cứu hoặc dự án học thuật. So sánh các phương pháp và khung lý thuyết khác nhau.
- Phân tích Học thuật: Xác định các xu hướng và chủ đề mới nổi trong các ấn phẩm học thuật và tính toán các số liệu học thuật như chỉ số H và số lần trích dẫn.
- Hợp tác tiềm năng: Xác định các chuyên gia trong một lĩnh vực cụ thể để hợp tác tiềm năng, hội nghị hoặc đánh giá ngang hàng.
- Phát triển sản phẩm: Các chuyên gia R&D có thể thu thập dữ liệu từ Google Scholar để nghiên cứu chuyên sâu, đột phá và theo dõi các ấn phẩm của đối thủ cạnh tranh trong các lĩnh vực khoa học hoặc công nghệ liên quan.
Thách thức và giải pháp thu thập dữ liệu Google Scholar
Google Scholar là một công cụ tìm kiếm học thuật mạnh mẽ cung cấp một số lượng lớn bài báo học thuật, bằng sáng chế, sách và bài báo hội nghị. Tuy nhiên, việc thu thập dữ liệu Google Scholar gặp phải nhiều thách thức kỹ thuật và pháp lý. Dưới đây là những vấn đề chính bạn có thể gặp phải khi thu thập dữ liệu Google Scholar và giải pháp của chúng:
| Thách thức | Mô tả | Giải pháp |
|---|---|---|
| Chặn IP | Các yêu cầu thường xuyên sẽ gây ra việc chặn IP. | Sử dụng proxy. Xoay vòng nhiều địa chỉ IP để ngăn chặn IP chính bị chặn. |
| CAPTCHA | Google có thể yêu cầu người dùng nhập CAPTCHA để xác nhận họ là người. | Chọn một dịch vụ có thể tự động giải quyết CAPTCHA cho bạn. |
| Hạn chế tốc độ yêu cầu | Tốc độ yêu cầu quá cao sẽ bị phát hiện và chặn. | Thay đổi user agent và chờ vài giây giữa các yêu cầu để bắt chước hành vi của con người. |
| Tải nội dung động | Google Scholar sử dụng JavaScript để tải nội dung động. | Sử dụng trình duyệt không đầu như Puppeteer hoặc Selenium để hiển thị JavaScript và trích xuất nội dung. |
Ngoài ra, còn có những hạn chế về API để thu thập dữ liệu Google Scholar. Vì Google Scholar không có API chính thức, việc thu thập dữ liệu Google Scholar yêu cầu phân tích cú pháp các trang web trực tiếp, điều này làm tăng độ phức tạp và sự không ổn định.
May mắn thay, bạn có thể thử sử dụng các dịch vụ API của bên thứ ba mạnh mẽ. Chúng đảm bảo việc trích xuất dữ liệu thuận tiện, nhanh chóng và chính xác. Hơn nữa, trong số nhiều nhà cung cấp dịch vụ API, Scrapeless cũng có dịch vụ giải mã CAPTCHA tích hợp, proxy luân phiên và công cụ mở khóa web.
Từng bước: Xây dựng công cụ thu thập dữ liệu Google Scholar bằng Python
Tiếp theo, chúng ta sẽ bắt đầu thu thập dữ liệu Google Scholar bằng công cụ thu thập dữ liệu Google Scholar bằng Python. Bạn sẽ thấy cách lấy dữ liệu như tiêu đề bài báo, thông tin xuất bản và tiêu đề bài báo.
Bước 1. Cấu hình môi trường
Python: Phần mềm https://www.python.org/downloads/ là cốt lõi để chạy Python. Bạn có thể tải xuống phiên bản chúng ta cần từ trang web chính thức như được hiển thị bên dưới. Tuy nhiên, không nên tải xuống phiên bản mới nhất. Bạn có thể tải xuống 1.2 phiên bản trước phiên bản mới nhất.
Python IDE: Bất kỳ IDE nào hỗ trợ Python đều hoạt động, nhưng chúng tôi khuyên bạn nên sử dụng PyCharm. Đó là một công cụ phát triển được thiết kế đặc biệt cho Python. Đối với phiên bản PyCharm, chúng tôi khuyên bạn nên sử dụng PyCharm Community Edition miễn phí.
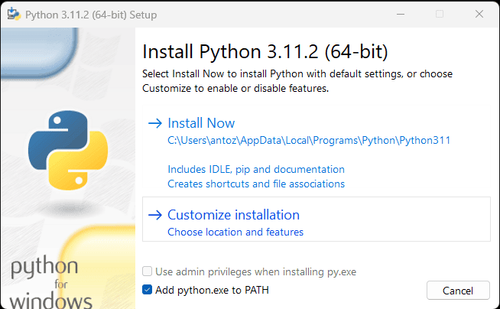
Lưu ý: Nếu bạn là người dùng Windows, đừng quên chọn tùy chọn "Thêm python.exe vào PATH" trong trình hướng dẫn cài đặt. Điều này sẽ cho phép Windows sử dụng Python và các lệnh trong thiết bị đầu cuối. Vì Python 3.4 trở lên đã bao gồm nó theo mặc định, bạn không cần phải cài đặt thủ công.
Bây giờ bạn có thể kiểm tra xem Python đã được cài đặt chưa bằng cách mở thiết bị đầu cuối hoặc dấu nhắc lệnh và nhập lệnh sau:
Bash
python --versionBước 2. Cài đặt các phụ thuộc
Nên tạo một môi trường ảo để quản lý các phụ thuộc của dự án và tránh xung đột với các dự án Python khác. Điều hướng đến thư mục dự án trong thiết bị đầu cuối và thực hiện lệnh sau để tạo một môi trường ảo có tên google_scholar_env:
Bash
python -m venv google_scholar_envKích hoạt môi trường ảo dựa trên hệ thống của bạn:
- Windows:
Bash
google_scholar_env\Scripts\activate- MacOS/Linux:
Bash
source google_scholar_env/bin/activateSau khi kích hoạt môi trường ảo, hãy cài đặt các thư viện Python cần thiết để thu thập dữ liệu trên web. Thư viện để gửi requests trong Python là requests, và thư viện chính để thu thập dữ liệu là BeautifulSoup4. Cài đặt chúng bằng các lệnh sau:
Bash
pip install requests
pip install beautifulsoup4Bước 3. Thu thập dữ liệu
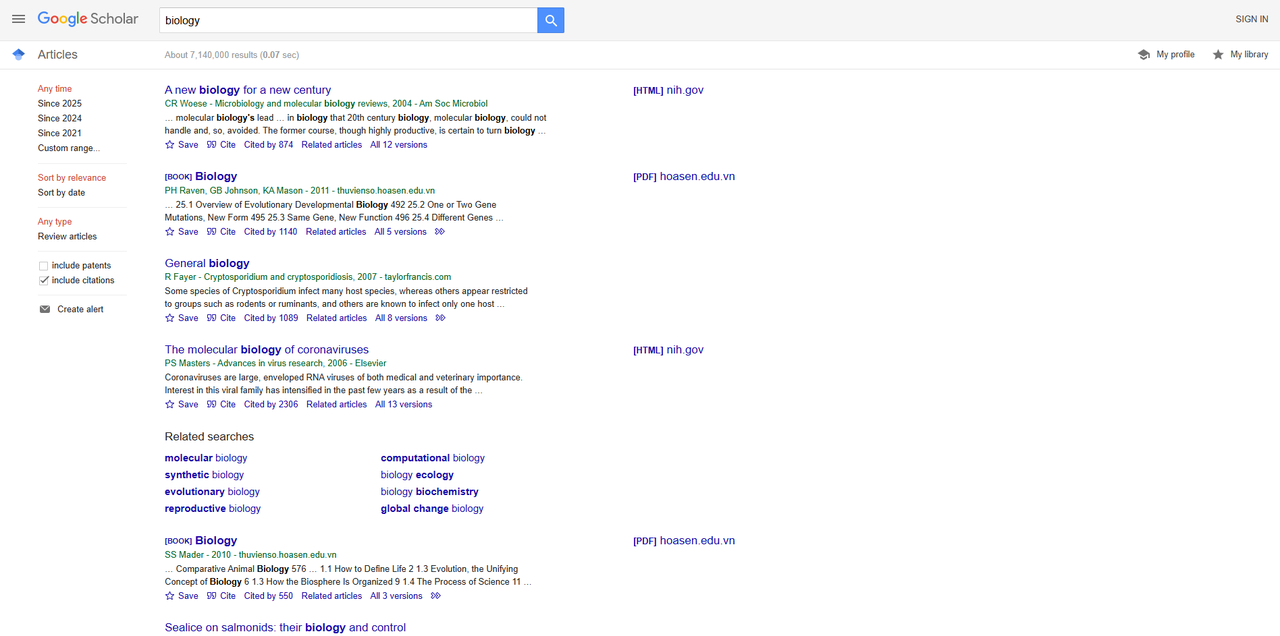
Mở Google Scholar trong trình duyệt của bạn và tìm kiếm "sinh học". Dưới đây là kết quả tìm kiếm:
- Thu thập tiêu đề:
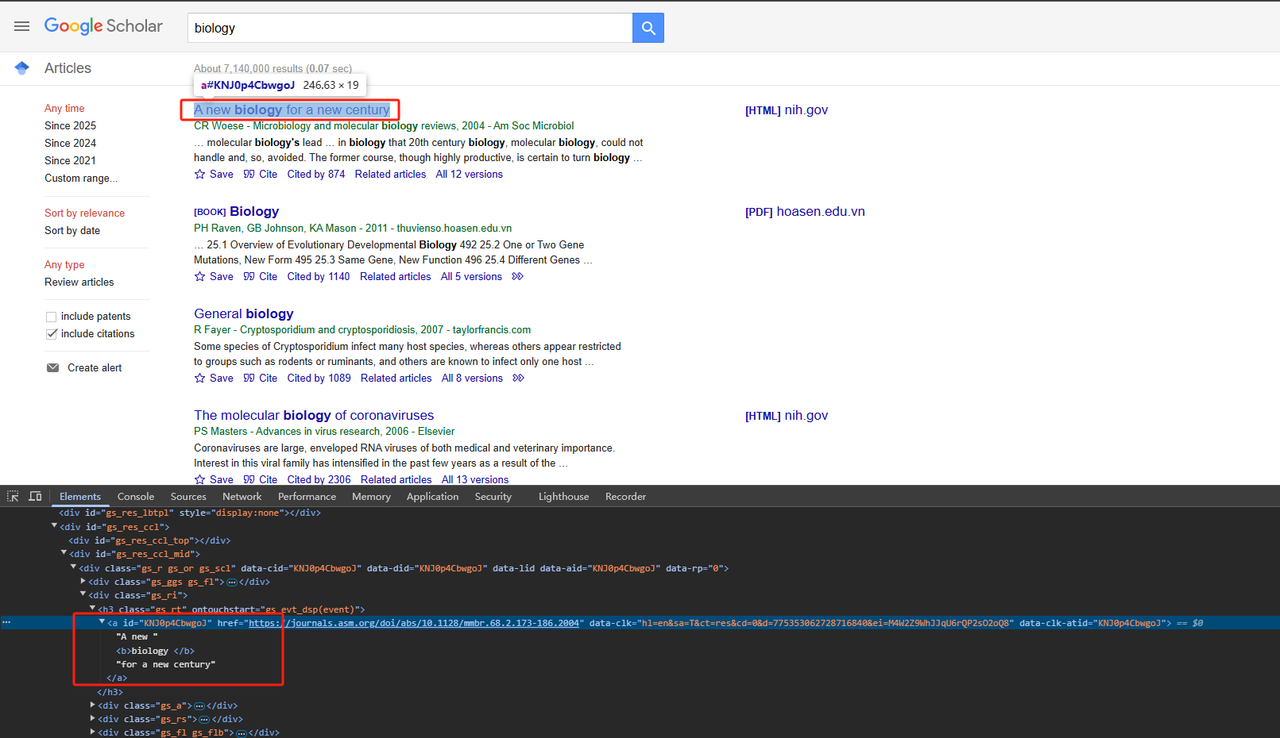
Phân tích các phần tử trang HTML có liên quan. Mã Python chi tiết như sau:
Python
def scrape_scholar_title(listing):
title_element = listing.select_one('h3.gs_rt a')
return title_element .text.strip()- Thu thập thông tin xuất bản:
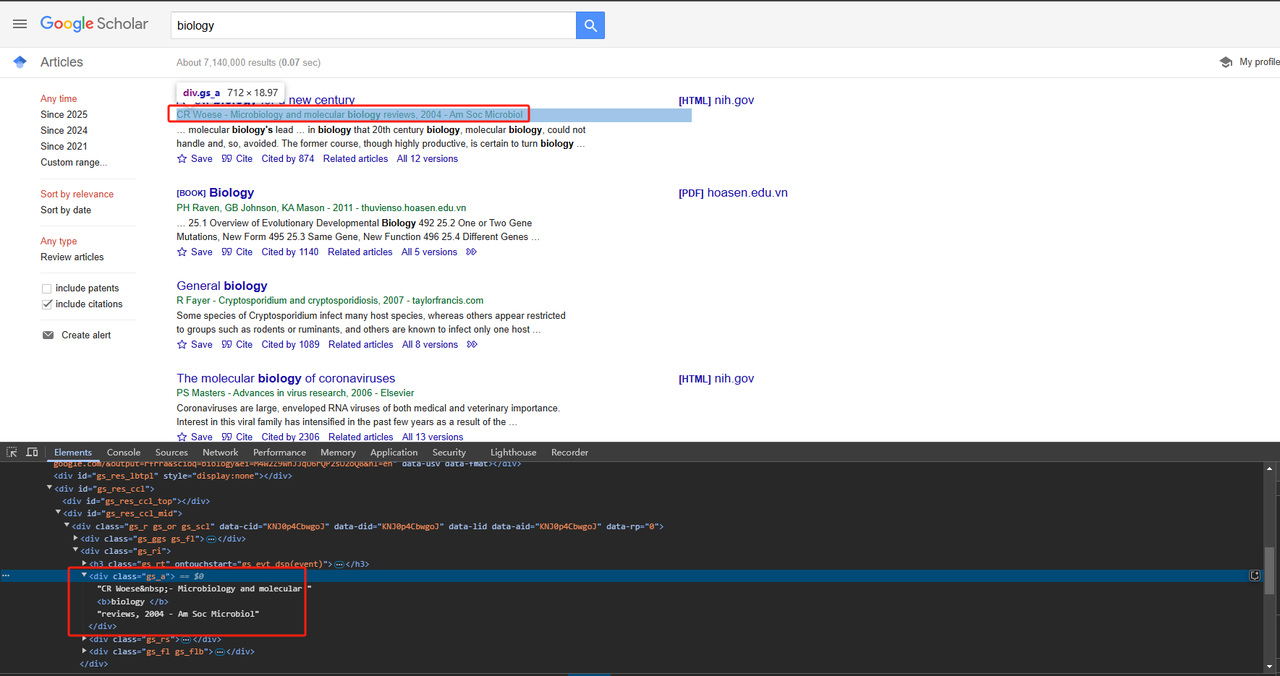
Thông tin xuất bản có thể được thu thập trực tiếp bằng thuộc tính lớp div. Mã Python chi tiết như sau:
Python
def scrape_scholar_publication_info(listing):
publication_info_element = listing.select_one('div.gs_a')
return publication_info_element .text.strip()- Thu thập đoạn trích bài viết:
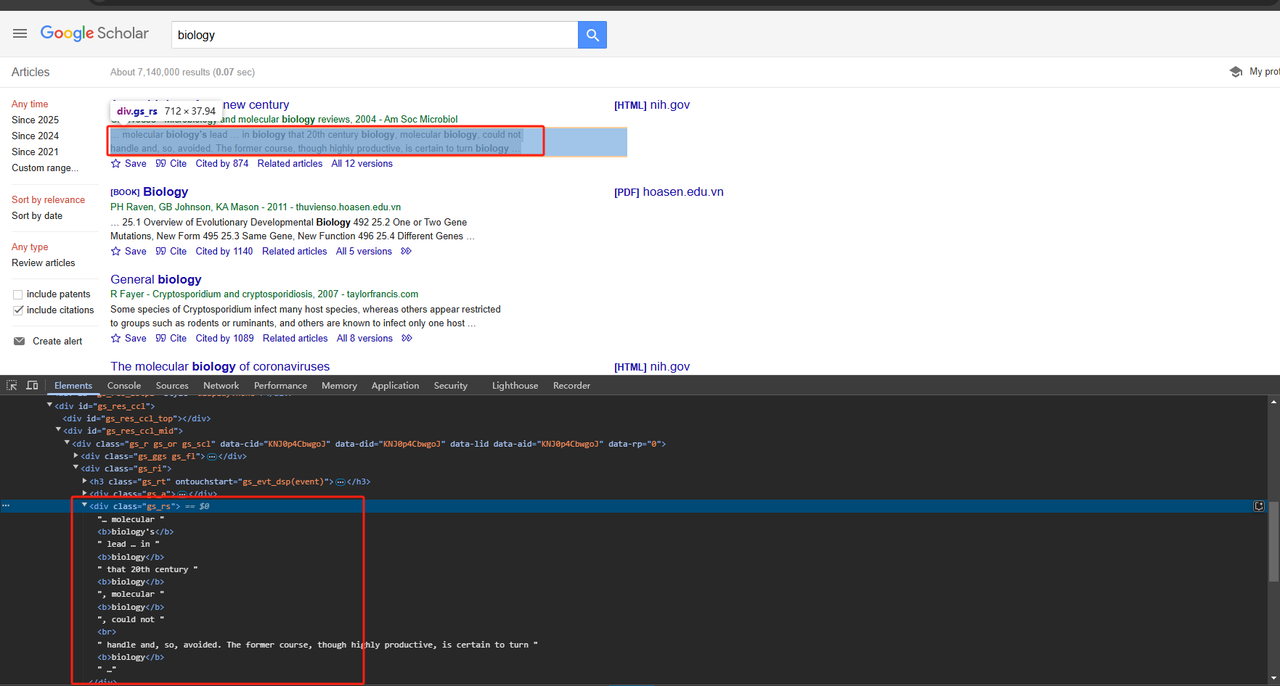
Đoạn trích bài viết cũng có thể được thu thập trực tiếp bằng thuộc tính lớp div. Mã Python chi tiết như sau:
Python
def scrape_scholar_snippet(listing):
snippet_element = listing.select_one('div.gs_rs')
return snippet_element .text.strip()Vì chúng ta cần thu thập tất cả dữ liệu trên trang, không chỉ một, nên chúng ta cần lặp lại và thu thập dữ liệu ở trên. Mã hoàn chỉnh như sau:
Python
# Import necessary libraries
import time
import requests
from bs4 import BeautifulSoup
import json
# Function to scrape listing elements from google_scholar
def scrape_listings(soup):
return soup.select('div.gs_r.gs_or.gs_scl')
# Function to scrape title from google_scholar
def scrape_scholar_title(listing):
title_element = listing.select_one('h3.gs_rt > a')
print(title_element.text)
return title_element.text.strip()
# Function to scrape publication_info from google_scholar
def scrape_scholar_publication_info(listing):
publication_info_element = listing.select_one('div.gs_a')
print(publication_info_element.text)
return publication_info_element.text.strip()
# Function to scrape snippet from google_scholar
def scrape_scholar_snippet(listing):
snippet_element = listing.select_one('div.gs_rs')
print(snippet_element.text)
return snippet_element.text.strip()
# Main function
def main():
# Make a request to google_scholar URL and parse HTML
url = 'https://scholar.google.com/scholar?hl=en&q=biology'
response = requests.get(url, verify=False)
time.sleep(2)
soup = BeautifulSoup(response.text, 'html.parser')
# Scrape scholar listings
listings = scrape_listings(soup)
print(listings)
# Iterate through each listing and extract scholar information
scholar_data = []
for listing in listings:
title = scrape_scholar_title(listing)
publication_info = scrape_scholar_publication_info(listing)
snippet = scrape_scholar_snippet(listing)
# Store scholar information in a dictionary
scholar_info = {
'title': title,
'publication_info': publication_info,
'snippet': snippet
}
scholar_data.append(scholar_info)
# Save results to a JSON file
with open('google_scholar_data.json', 'w') as json_file:
json.dump(scholar_data, json_file, indent=4)
if __name__ == "__main__":
main()Bước 4. Kết quả đầu ra
Một tệp có tên google_scholar_data.json sẽ được tạo trong thư mục PyCharm của bạn. Đầu ra như sau:
JSON
[
{
"title": "A new biology for a new century",
"publication_info": "CR Woese\u00a0- Microbiology and molecular biology reviews, 2004 - Am Soc Microbiol",
"snippet": "\u2026 molecular biology's lead \u2026 in biology that 20th century biology, molecular biology, could not \nhandle and, so, avoided. The former course, though highly productive, is certain to turn biology \u2026"
},
{
"title": "Biology",
"publication_info": "PH Raven, GB Johnson, KA Mason - 2011 - thuvienso.hoasen.edu.vn",
"snippet": "\u2026 25.1 Overview of Evolutionary Developmental Biology 492 25.2 One or Two Gene \nMutations, New Form 495 25.3 Same Gene, New Function 496 25.4 Different Genes\u00a0\u2026"
},
{
"title": "General biology",
"publication_info": "R Fayer\u00a0- Cryptosporidium and cryptosporidiosis, 2007 - taylorfrancis.com",
"snippet": "Some species of Cryptosporidium infect many host species, whereas others appear restricted \nto groups such as rodents or ruminants, and others are known to infect only one host \u2026"
},
{
"title": "The molecular biology of coronaviruses",
"publication_info": "PS Masters\u00a0- Advances in virus research, 2006 - Elsevier",
"snippet": "Coronaviruses are large, enveloped RNA viruses of both medical and veterinary importance. \nInterest in this viral family has intensified in the past few years as a result of the \u2026"
},
{
"title": "Biology",
"publication_info": "SS Mader - 2010 - thuvienso.hoasen.edu.vn",
"snippet": "\u2026 Comparative Animal Biology 576 \u2026 1.1 How to Define Life 2 1.3 Evolution, the Unifying \nConcept of Biology 6 1.3 How the Biosphere Is Organized 9 1.4 The Process of Science 11\u00a0\u2026"
},
{
"title": "Sealice on salmonids: their biology and control",
"publication_info": "AW Pike, SL Wadsworth\u00a0- Advances in parasitology, 1999 - Elsevier",
"snippet": "\u2026 This review examines the voluminous literature on the biology and control of sealice and \nbrings together ideas for developing our knowledge of these organisms. Research on the \u2026"
},
{
"title": "Biology data book",
"publication_info": "PL Altman, DS Dittmer - 1972 - bionumbers.hms.harvard.edu",
"snippet": "Embryos were raised at constant temperature in circulating nalis\" u 10% smaller. For \nadditional information on salmowater, from three hours after fertilization. Age= time from nids, \u2026"
},
{
"title": "The biology of Pseudocalanus",
"publication_info": "CJ Corkett, IA McLaren\u00a0- Advances in marine biology, 1979 - Elsevier",
"snippet": "Publisher Summary Pseudocalanus is typical of most crustaceans in that after hatching at \nan early stage of development it adds successively new segments and appendages. \u2026"
},
{
"title": "Introduction to a submolecular biology",
"publication_info": "A Szent-Gyorgyi - 2012 - books.google.com",
"snippet": "\u2026 Biology is the science of the improbable and I think it is on principle that the body works \nonly with reactions which are statistically improbable. If metabolism were built of a series of \u2026"
},
{
"title": "The biology of mycorrhiza.",
"publication_info": "JL Harley - 1959 - cabidigitallibrary.org",
"snippet": "Since Dr. Rayner published her book on mycorrhiza in 1927 there has not been a comprehensive \naccount of this subject, although the need for a critical re-appraisal of the extensive \u2026"
}
]Triển khai API Scrapeless Google Scholar dễ dàng
Tại sao API Scrapeless Scholar lại quan trọng?
Chắc chắn rồi! Bạn chỉ cần một dịch vụ API có giá cả phải chăng, ổn định và an toàn. Tuy nhiên, việc tìm ra một dịch vụ đáp ứng tất cả các tiêu chí này là vô cùng khó khăn! May mắn thay, API Scrapeless Google Scholar nổi bật trong số nhiều sản phẩm API:
- 🔴 Tiết kiệm chi phí: API Google Scholar chỉ cần $0,80, và với gói đăng ký $49, bạn được giảm giá 10%!
- 🔴 Dữ liệu chính xác: Các nhà phát triển của chúng tôi liên tục phân tích các thuật toán và hạn chế thu thập dữ liệu của Google để đảm bảo API được cập nhật và tối ưu hóa.
- 🔴 Ổn định và tỷ lệ thành công cao: Scrapeless đảm bảo tỷ lệ thành công và độ tin cậy 99%. Sự ổn định và độ chính xác của việc thu thập dữ liệu Google Trends đã đạt gần 100%! Hiện tại, thời gian phản hồi trung bình khoảng 3 giây, nhanh hơn đáng kể so với hầu hết các nhà cung cấp API khác. Hơn nữa, dữ liệu được trả về ở định dạng JSON chuẩn, sẵn sàng để sử dụng ngay lập tức.
Scrapeless đã nhận được sự tin tưởng của hơn 2.000 người dùng doanh nghiệp! Tham gia Discord ngay bây giờ để nhận dùng thử miễn phí! Chỉ có 1.000 suất có sẵn trong thời gian giới hạn—hãy hành động nhanh!
Đọc thêm:
- Cách thu thập dữ liệu kết quả tìm kiếm Google?
- Cách thu thập dữ liệu Google Trends bằng Python?
- Tìm chuyến bay rẻ nhất với công cụ thu thập dữ liệu Google Flights!
Các bước sử dụng:
Bước 1. Lấy API Token
- Đăng nhập vào Bảng điều khiển.
- Điều hướng đến Quản lý Khóa API.
- Nhấp vào Tạo để tạo Khóa API duy nhất của bạn.
- Bạn chỉ cần nhấp vào Khóa API để sao chép nó.
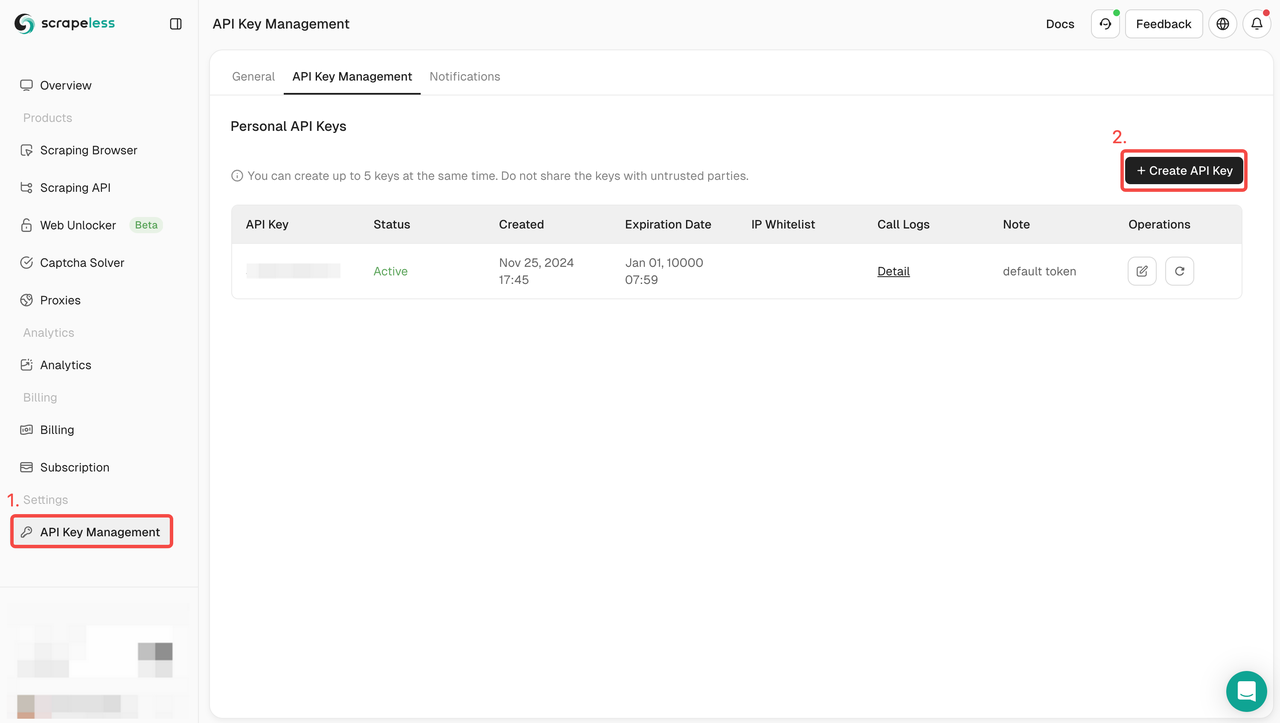
Bước 2: Sử dụng Khóa API của bạn trong mã
Bây giờ bạn chỉ cần cấu hình các tham số trong tài liệu API để thu thập dữ liệu Google Scholar cần thiết.
- Truy cập Tài liệu API.
- Nhấp vào "Thử ngay" đối với điểm cuối mong muốn.
- Cấu hình các tham số bạn cần trong thân mã.
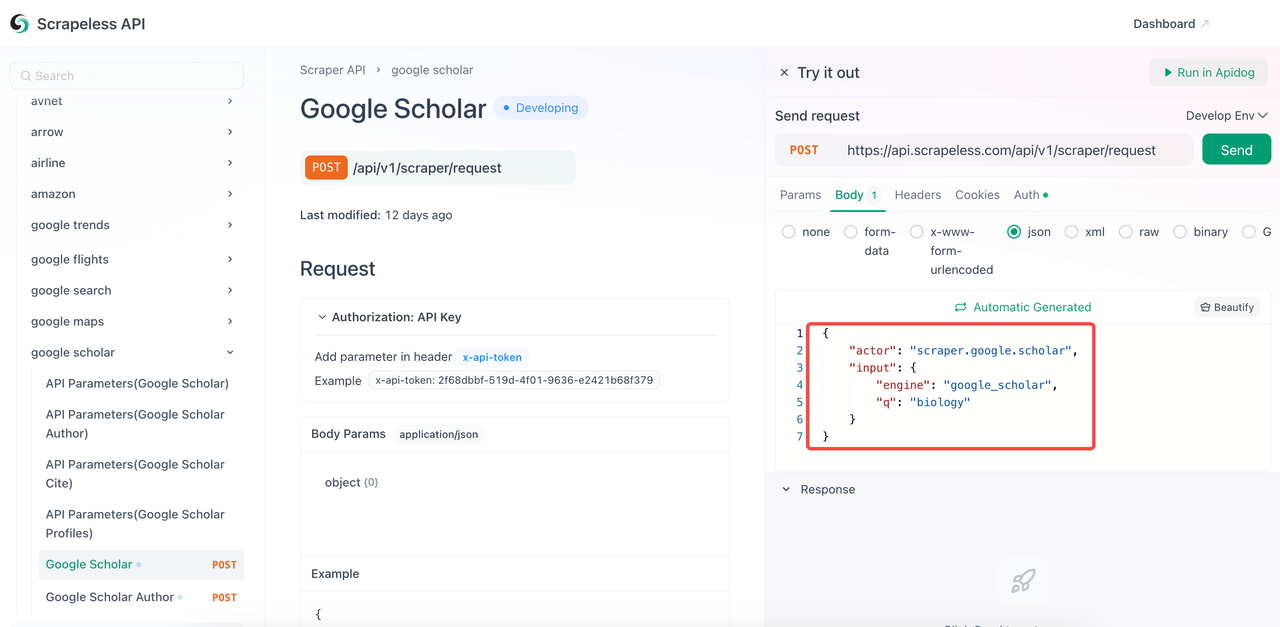
- Thay thế từ khóa
qbằng từ khóa bạn muốn truy vấn. - Tham số
enginelà bắt buộc và giá trị của nó phải làgoogle_scholar. Tuy nhiên, bạn có thể thêm nhiều tham số cụ thể hơn, chẳng hạn nhưgoogle_scholar_author. - Các tham số phổ biến:
| Tham số | Bắt buộc | Mô tả |
|---|---|---|
engine |
TRUE | Đặt thành google_scholar để sử dụng API này. |
q |
TRUE | Truy vấn tìm kiếm (ví dụ: "machine learning"). |
cites |
FALSE | ID duy nhất để tìm các bài báo trích dẫn. |
as_ylo |
FALSE | Lọc kết quả từ một năm cụ thể. |
as_yhi |
FALSE | Lọc kết quả đến một năm cụ thể. |
hl |
FALSE | Cài đặt ngôn ngữ (mặc định: en). |
num |
FALSE | Số lượng kết quả (1-20, mặc định: 10). |
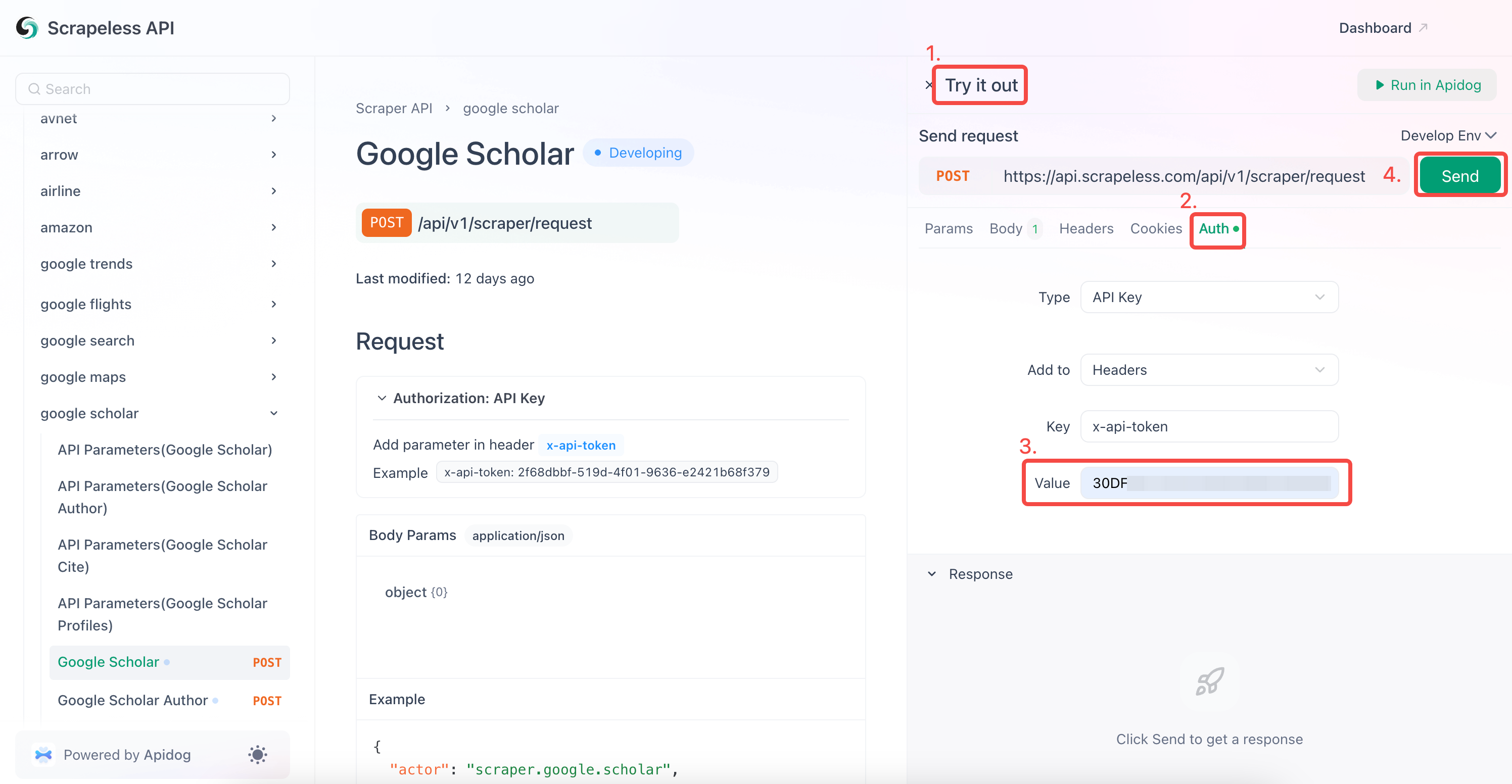
- Nhập Khóa API của bạn vào trường "Auth".
- Nhấp vào "Gửi" để nhận phản hồi thu thập dữ liệu.
Scrapeless Google Scholar cũng hỗ trợ thu thập dữ liệu:
- Tác giả Google Scholar
- Trích dẫn Google Scholar
- Hồ sơ Google Scholar
Bạn cũng có thể tích hợp trực tiếp mã tham khảo của chúng tôi vào chương trình của mình. Chỉ cần thay thế your_token bằng token bạn đã đăng ký:
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = your_token ## replace with your API Token
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_scholar",
"q": "biology",
}
payload = Payload("scraper.google.scholar", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Xây dựng công cụ thu thập dữ liệu Google Scholar của bạn ngay bây giờ!
Thu thập dữ liệu Google Scholar là một cách tuyệt vời để trích xuất thông tin học thuật. Cho dù bạn đang tìm kiếm các cách lập trình hoặc không lập trình để thu thập dữ liệu Google Scholar hoặc các công cụ tìm kiếm khác, chúng tôi đều có giải pháp đơn giản và nhanh chóng dành cho bạn.
Scrapeless cung cấp dùng thử miễn phí một tháng, nơi bạn có thể tận hưởng tất cả các dịch vụ để thu thập dữ liệu. Làm thế nào để tìm dữ liệu chi tiết từ Google Scholar? Bạn có thể thu thập rất nhiều dữ liệu trong thời gian rất ngắn với Scrapeless.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


