
Scrapeless Tích hợp hoàn toàn Google AI Overviews, Chế độ AI và Gemini: Khung Tối ưu hóa Dữ liệu Tối ưu cho Kỷ nguyên GEO
Expert Network Defense Engineer
Từ Tổng quan AI của Google đến Gemini 3, từ các chuỗi lý luận của Chế độ AI đến việc trích xuất dữ liệu có cấu trúc—Scrapeless cung cấp một hệ thống phân tích và thu thập hoàn toàn tích hợp, tiết lộ cách mà Tìm kiếm AI thực sự hoạt động trong năm 2026 và chỉ cho bạn thấy những cơ hội thực sự nằm ở đâu.
Giới thiệu: Sự Chuyển biến Lớn trong Phân bổ Lưu lượng Tìm kiếm
Kể từ đầu năm 2025, Google đã tăng tốc mạnh mẽ sự hội tụ của Tìm kiếm và AI. Với việc triển khai Chế độ AI, mở rộng phạm vi của Tổng quan AI, và tích hợp sâu hơn của Gemini 2.5 Pro vào quy trình tìm kiếm, Google đã xây dựng nền tảng kỹ thuật cho GEO 2.0.
Đến tháng 11 năm 2025, sự ra mắt của Gemini 3 đánh dấu một điểm uốn lớn—điều này thay đổi cơ bản cách mà lưu lượng tìm kiếm được phân phối.
Đây không phải là một bản nâng cấp sản phẩm đơn giản. Đó là một cuộc cách mạng trong cách phân bổ sự hiển thị và lưu lượng tìm kiếm.
Thế Giới Cũ (SEO): Xếp hạng #1 = Nhiều Lưu lượng Nhất
Tìm kiếm Google trước đây như một bảng xếp hạng tĩnh. Mọi người đều thấy những liên kết màu xanh giống nhau, và thứ hạng quyết định mọi thứ.
Nhưng thời đại đó đã kết thúc.
Thời Đại GEO Khác Biệt
GEO (Tối ưu hóa Động cơ Tạo sinh) hoàn toàn thay đổi các quy tắc:
Lưu lượng không còn được xác định bởi thứ hạng. Nó được xác định bởi cách mà các mô hình AI diễn giải, chọn lọc và trích dẫn nội dung của bạn.
Các tóm tắt AI, chế độ tìm kiếm sâu, và các LLM tạo sinh bây giờ chọn những trang nào để tham khảo, kết hợp và trình bày. Lưu lượng của bạn giờ đây phụ thuộc vào:
- Liệu AI có thể nhìn thấy nội dung của bạn
- Liệu AI có thể hiểu nội dung của bạn
- Liệu AI quyết định trích dẫn nội dung của bạn
- Liệu nội dung của bạn có phù hợp với các cấu trúc và chuỗi lý luận ưa thích của mô hình không
Ví dụ, tìm kiếm “các công cụ xxxx tốt nhất” có thể giờ đây hiển thị ba kênh lái AI song song:
1. Tổng quan AI của Google
Một câu trả lời AI tổng hợp đứng đầu SERP trích dẫn 3–5 trang web bên ngoài.
2. Chế độ AI của Google
Một câu trả lời tạo sinh toàn trang với:
- chuỗi lý luận từng bước
- nguồn tham khảo
- các câu hỏi con mở rộng
3. Tìm kiếm Ứng dụng Gemini
Một phản hồi được cấu trúc, cá nhân hóa hơn sử dụng lý luận đa phương thức của Gemini.
Ba kênh này đồng thời tồn tại—nhưng mỗi kênh sử dụng các quy tắc khác nhau cho việc chọn nội dung:
| Kênh | Điều gì xác định liệu bạn có được trích dẫn |
|---|---|
| Tổng quan AI | Sự rõ ràng, cấu trúc, mật độ thông tin, khả năng trích xuất |
| Chế độ AI | Phạm vi của các câu hỏi phụ mở rộng; chiều sâu & bằng chứng |
| Tìm kiếm Gemini | Quyền lực, tính nhất quán trong lý luận, dữ liệu có cấu trúc |
Đây là thực tế khắc nghiệt của thời đại GEO.
Và mọi thứ đang phát triển từng quý.
Gemini 3 đã vượt qua GPT-5 Pro trong các chỉ số cốt lõi chỉ vài ngày sau khi ra mắt. Với 650 triệu người dùng Gemini hàng tháng và chỉ số tìm kiếm lớn nhất thế giới, mỗi bản cập nhật của Google đều định hình lại toàn bộ hệ sinh thái tìm kiếm AI.
❓Vậy Làm Thế Nào Để Bạn Hiểu và Tối Ưu Hóa Cho Ba Kênh Này?
Câu trả lời—và mục đích của bài viết này—rõ ràng:
Sử dụng Trình duyệt Scrapeless để mở khóa toàn bộ quy trình Tìm kiếm AI của Google.
Phần 1: Logic Cốt lõi của GEO
Từ “Xếp Hạng #1” → “Có Cấu Trúc, Dễ Hiểu, và Có Thể Trích Dẫn Bởi AI”
SEO truyền thống là một chiều:
Xếp hạng cao hơn → nhiều lưu lượng hơn.
GEO là đa chiều. Với Gemini 3, Chế độ AI, và Tổng quan AI hoạt động song song, bạn đang cạnh tranh trên ba chiều đang phát triển:
Chiều 1: Khả Năng Lý Luận Sâu của Gemini 3
Gemini 3 đạt 37.4 trên chỉ số Bài Kiểm Tra Cuối Cùng của Nhân Loại—vượt qua GPT-5 Pro.
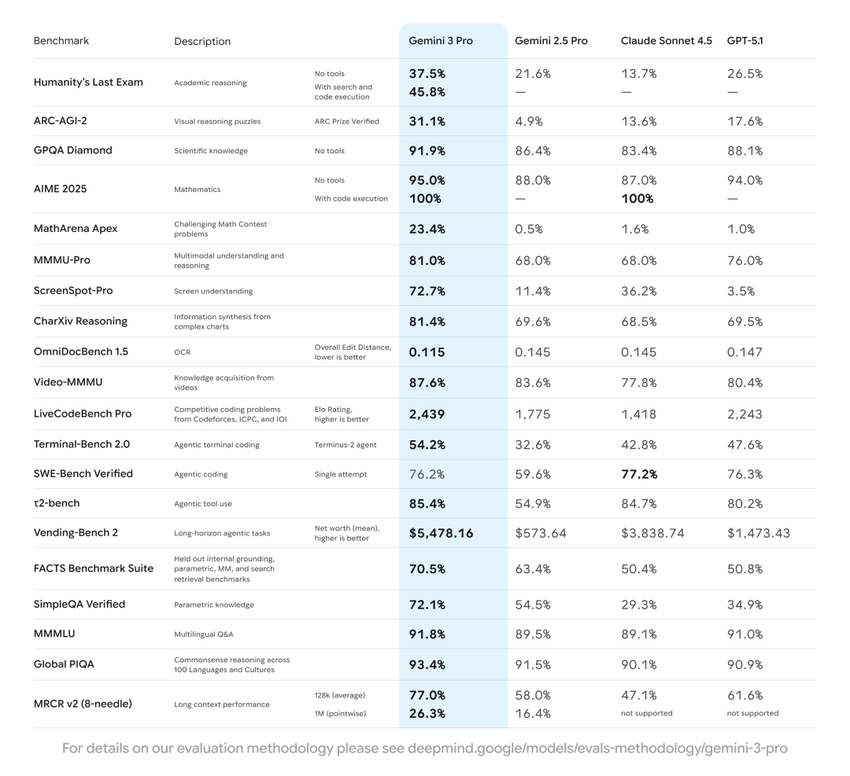
Nó giới thiệu:
- lý luận chuỗi rõ ràng
- tự phê bình
- đánh giá câu trả lời có trọng số bằng chứng
Điều này có nghĩa là Gemini liên tục hỏi:
“Câu trả lời này có được hỗ trợ bởi đủ bằng chứng không?”
Để được chọn, nội dung của bạn phải:
- trả lời các câu hỏi chính và ngụ ý phụ
- cung cấp dữ liệu và cơ sở thực tế
- bao gồm ví dụ và xác minh
- duy trì tính nhất quán logic nội bộ
Và quan trọng hơn:
Gemini ưu tiên nội dung có thẩm quyền cao đã được ghi nhớ từ kiến thức nội bộ của nó. Nó chỉ thực hiện tìm kiếm trên internet trực tiếp khi cần thiết.
Chiến lược GEO dài hạn là rõ ràng:
Hãy làm cho nội dung của bạn đủ thẩm quyền để bước vào dữ liệu đào tạo của các mô hình thế hệ tiếp theo.
Chiều 2: Mở Rộng Truy Vấn Tự Động của Chế độ AI
Khi một người dùng đặt một câu hỏi, Chế độ AI tự động tạo ra:
➡️ 8–12 câu hỏi phụ
➡️ Tìm kiếm mỗi câu hỏi một cách độc lập
➡️ Chọn các trang web khác nhau cho mỗi câu trả lời
Xếp hạng #1 không đảm bảo được trích dẫn, vì đối thủ của bạn—xếp hạng #5—có thể hoàn toàn phù hợp với một câu hỏi phụ.

Điều này dẫn đến một kết luận mạnh mẽ:
Đừng viết một "hướng dẫn cuối cùng" dài 5.000 từ.
Hãy viết mười câu trả lời sâu sắc dài 500 từ, mỗi câu nhắm đến một câu hỏi cụ thể.
Kích thước 3: Các quy tắc trích xuất của Tóm tắt AI
Tóm tắt AI nhằm mục đích tạo ra một bản tóm tắt nhanh chóng và chính xác.
Để được trích dẫn, nội dung của bạn phải cung cấp:
✔️ Cấu trúc rõ ràng
Tiêu đề, tiểu đề và các đoạn văn độc lập.
✔️ Các tuyên bố dựa trên sự thật
Bảng biểu, số liệu, logic từng bước.
✔️ Câu trích xuất được
Câu ngắn gọn, chính xác, hoàn chỉnh về mặt logic.
✔️ Phạm vi bao quát
Để AI có thể rút ra nhiều đoạn từ trang của bạn.
Được trích dẫn không luôn có nghĩa là nhấp chuột—nhưng nó mang lại:
- Hiển thị thương hiệu
- Tăng cường quyền lực ở cấp độ mô hình
- Tăng khả năng được trích dẫn lâu dài
- Lưu lượng truy cập giới thiệu khi người dùng kiểm tra các nguồn đã được trích dẫn
Trong một câu:
Tóm tắt AI không phải là một cuộc cạnh tranh xếp hạng—nó là một cuộc cạnh tranh trích xuất.
Phần 2: Tại sao Trình duyệt Scrapeless là cần thiết cho việc thu thập dữ liệu GEO
Vấn đề Cơ bản: Ba Thất bại Lớn của Các Công cụ Crawlers Truyền Thống
Nhiều người hỏi:
“Tại sao không chỉ sử dụng Puppeteer hoặc Selenium để kết nối với một trình duyệt và thu thập trực tiếp?”
Câu trả lời nằm ở ba vấn đề cấu trúc mà các công cụ crawlers truyền thống không thể xử lý trong thời đại GEO.
Thách thức 1: Phát hiện IP và Chặn Nhanh Chóng
Vào giữa tháng 9 năm 2025, Google lặng lẽ gỡ bỏ một tham số đã tồn tại gần 20 năm: num=100.
Đây không chỉ là việc gỡ bỏ một tham số—theo đó, đánh dấu một nâng cấp lớn trong kiến trúc chống bot của Google.
Khi bạn gửi một số lượng lớn yêu cầu tìm kiếm thông qua một crawler truyền thống, Google sẽ ngay lập tức:
- Nhận diện IP của bạn
- Kích hoạt reCAPTCHA v3
- Nếu bạn tiếp tục, chặn IP của bạn trong 24–72 giờ
Điều này có ý nghĩa gì trên thực tế?
Nếu bạn cần theo dõi 100 từ khóa trong Tóm tắt AI của Google, một crawler truyền thống có thể yêu cầu 20–30 IP proxy luân phiên, vẫn với khả năng bị phát hiện cao.
Hệ thống phát hiện của Google đã phát triển vượt xa việc kiểm tra IP. Nó hiện đánh giá:
- Mẫu thời gian yêu cầu (quá đều = bot)
- Dấu vân tay trình duyệt (đây có phải là một trình duyệt thật không?)
- Mẫu tương tác (chuyển động chuột, độ trễ nhấp chuột, thời gian ở lại)
- Tính liên tục giữa các miền (điều này có giống như một phiên tìm kiếm của con người không?)
Các crawler truyền thống đơn giản không thể mô phỏng những hành vi này một cách đáng tin cậy.
Thách thức 2: Kết xuất JavaScript Không Đầy Đủ
Tóm tắt AI, Chế độ AI và Gemini tất cả đều tạo ra câu trả lời của họ một cách động.
Nội dung này không có mặt trong HTML ban đầu. Nó được xây dựng qua nhiều lớp kết xuất JavaScript.
Nếu bạn chỉ chạy:
js
await page.goto(url);và thu thập ngay lập tức, bạn sẽ thường thấy:
- Container câu trả lời AI tồn tại, nhưng nội dung trống
- Danh sách trích dẫn chưa được tải
- Các bước lý luận trong Chế độ AI đang thiếu
Tại sao?
Bởi vì Google sử dụng một quy trình kết xuất bất đồng bộ nhiều bước:
- Tải khung cấu trúc
- Kích hoạt suy luận
- Kết xuất câu trả lời
- Kết xuất trích dẫn
- Kết xuất các yếu tố tương tác
Trừ khi trình duyệt của bạn chính xác chờ đợi mỗi giai đoạn, đầu ra của bạn sẽ không đầy đủ.
Thách thức 3: Nhận Dữ liệu Ổn định và Có Thể Tái Sản Xuất
Trong Chế độ AI và Gemini, bối cảnh cá nhân hóa có ảnh hưởng mạnh mẽ đến kết quả.
Google cá nhân hóa câu trả lời dựa trên:
- Lịch sử tìm kiếm
- Vị trí địa lý
- Đặc điểm thiết bị
- Hoạt động Gmail / YouTube
- Mẫu tương tác trước đó
Ví dụ:
Người dùng A (người đam mê thể dục) tìm kiếm “bữa sáng nhanh mới lành mạnh”
→ Chế độ AI gợi ý kế hoạch bữa ăn giàu protein
Người dùng B (người thích làm bánh) tìm kiếm cùng một thuật ngữ
→ Chế độ AI gợi ý công thức làm bánh
Nếu bạn thu thập dữ liệu bằng cách sử dụng một tài khoản người dùng thật, kết quả của bạn trở nên gắn bó sâu sắc với lịch sử của người dùng đó.
Điều này phá hủy khả năng tái sản xuất, điều này rất quan trọng đối với phân tích GEO.
Trình duyệt Scrapeless giải quyết vấn đề này bằng cách:
- Mô phỏng người dùng ma (không có lịch sử, không có sở thích, không có dữ liệu đăng nhập)
- Môi trường sạch, cách ly cho mỗi phiên
- Đầu ra nhất quán, có thể tái sản xuất qua tất cả các lần chạy
Điều này loại bỏ tiếng ồn cá nhân hóa và đảm bảo rằng dữ liệu đáng tin cậy cho phân tích.
Trình duyệt Scrapeless: Giải pháp Đặc biệt cho Việc Thu Thập Dữ liệu GEO
Trình duyệt Scrapeless được thiết kế đặc biệt để vượt qua cả ba thách thức trên.
Giải pháp 1: Trình duyệt đám mây + Luân phiên proxy thông minh
Scrapeless cung cấp không chỉ IP, mà còn các phiên trình duyệt đám mây đầy đủ.
Mỗi phiên bao gồm:
- Một quy trình trình duyệt tách biệt
- Các hồ sơ trình duyệt riêng biệt
- Các hồ bơi IP toàn cầu (hơn 195 quốc gia)
- Độ trễ mạng thực tế và các mẫu tương tác giống con người
- Tùy chỉnh dấu vân tay (ngẫu nhiên hoặc hoàn toàn kiểm soát)
Từ góc độ của Google, mỗi yêu cầu trông giống như một con người thật khác, với:
- Một vị trí khác
- Một thiết bị khác
- Một trình duyệt khác
- Hành vi duyệt tự nhiên
Ví dụ:
js
// Yêu cầu 1: Người dùng Chrome ở Tokyo
wss://browser.scrapeless.com/api/v2/browser?proxyCountry=JP&sessionName=User_Tokyo_001
// Yêu cầu 2: Người dùng Safari ở Singapore
wss://browser.scrapeless.com/api/v2/browser?proxyCountry=SG&sessionName=User_Singapore_001
// Yêu cầu 3: Người dùng Edge ở London
wss://browser.scrapeless.com/api/v2/browser?proxyCountry=GB&sessionName=User_London_001Điều này hoàn toàn không thể thực hiện được đối với các crawler truyền thống.
Giải pháp 2: Môi trường thực thi JavaScript đầy đủ và thực tế
Scrapeless không tải HTML tĩnh.
Nó tải trang như một trình duyệt thực, thực thi tất cả JavaScript cần thiết để tạo ra đầy đủ:
- Câu trả lời AI
- Tài liệu tham khảo
- Chuỗi lý luận
- Khối UI động
- Bất kỳ thành phần DOM nào được xây dựng sau khi tải trang
Ví dụ:
js
const geminiInput = await page.waitForSelector('div[role="textbox"]');
await geminiInput.type('công cụ quét shopee tốt nhất');
await geminiInput.press('Enter');
// Chờ câu trả lời AI hoàn thành việc tạo ra
await new Promise(resolve => setTimeout(resolve, 10000));Ưu điểm cốt lõi
- Bắt tất cả nội dung AI động - không chỉ DOM ban đầu
- Phản ánh chính xác kết quả nhìn thấy của con người
- Đảm bảo xuất dữ liệu câu trả lời đầy đủ, hoàn chỉnh
Giải pháp 3: Quản lý phiên làm việc và khả năng tái hiện
Lợi thế lớn nhất của Scrapeless Browser là kiến trúc phiên làm việc của nó.
Scrapeless cung cấp:
-
Phiên làm việc liên tục (sessionTTL):
Giữ cho cookies, localStorage và trạng thái môi trường nhất quán. -
Môi trường người dùng ma:
Không có lịch sử tìm kiếm, không có ngữ cảnh đã đăng nhập, không có cá nhân hóa.
Điều này đảm bảo:
- Kết quả ổn định
- Dữ liệu có thể tái hiện
- Không có thiên lệch cá nhân hóa
- Môi trường sạch sẽ phù hợp cho benchmark GEO
Phần 3: Tích hợp mã đầy đủ - Sử dụng Scrapeless để trích xuất dữ liệu từ cả ba nền tảng Google
Nền tảng 1: Giám sát Tóm tắt Google AI
Tóm tắt Google AI xuất hiện ở đầu trang kết quả tìm kiếm như một tóm tắt do AI tạo ra.
Giám sát điều này cho phép bạn hiểu:
- Các trang web nào mà Google đang trích dẫn
- Cách mà các trang web đó cấu trúc nội dung của họ
- Loại thông tin mà AI coi là “chất lượng cao”
Ví dụ mã đầy đủ
js
const puppeteer = require('puppeteer-core');
async function scrapeWithGoogle() {
const query = new URLSearchParams({
sessionTTL: 900,
sessionRecording: "true",
sessionName: "AskGemini",
proxyCountry: 'US',
token: "MÃ KHÓA API SCRAPELESS",
});
const browserWSEndpoint = `wss://browser.scrapeless.com/api/v2/browser?${query.toString()}`;
console.log('browserWSEndpoint: ', browserWSEndpoint);
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto("https://google.com");
// Chấp nhận cookies
const dialogButtons = await page.$$('[role="dialog"] div > button > div[role="none"]');
const agentButton = dialogButtons?.length ? dialogButtons[dialogButtons.length - 1] : null;
if (agentButton) {
await agentButton.click();
await new Promise((resolve) => setTimeout(resolve, 1500));
}
await page.waitForSelector("textarea");
await page.type("textarea", "công cụ quét shopee tốt nhất");
await page.keyboard.press("Enter");
// Chờ Tóm tắt AI tải
await new Promise((resolve) => setTimeout(resolve, 5000));
// Lưu đầu ra dưới dạng ảnh chụp màn hình
await page.screenshot({ path: 'result.png', fullPage: true });
} catch (err) {
console.error(err);
}
}
scrapeWithGoogle().then();Nền tảng 2: Theo dõi chuỗi lý luận trong Chế độ AI của Google
Chế độ AI của Google là chế độ tìm kiếm sâu nhất của Google. Nó tạo ra lý luận chi tiết, câu trả lời có cấu trúc và các nguồn tài liệu tham khảo có thể nhìn thấy.
Giám sát Chế độ AI giúp bạn:
- Hiểu câu trả lời tổng hợp của AI
- Xem các trang nào mà mô hình trích dẫn
- Theo dõi các bước lý luận và hệ thống thông tin của AI
Ví dụ mã đầy đủ
js
const puppeteer = require('puppeteer-core');
async function scrapeGemini() {
const query = new URLSearchParams({
sessionTTL: 900,
sessionRecording: "true",
sessionName: "GoogleAI",
proxyCountry: 'US',
token: "MÃ KHÓA API SCRAPELESS",
});
const browserWSEndpoint = `wss://browser.scrapeless.com/api/v2/browser?${query.toString()}`;
console.log('browserWSEndpoint: ', browserWSEndpoint);
try {
const browser = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
});
const page = await browser.newPage();
await page.goto('https://google.com/ai', { waitUntil: "domcontentloaded" });
// Nhập truy vấn
const textArea = await page.waitForSelector('textarea[placeholder="Hỏi bất kỳ điều gì"]');
vi
chờ textArea.gõ('công cụ lấy dữ liệu shopee tốt nhất');
chờ textArea.nhấn('Enter');
// Chờ lý do + câu trả lời
chờ một Promise((giải quyết) => setTimeout(giải quyết, 10000));
chờ trang.chụp màn hình({ đường dẫn: 'result.png', toàn bộ trang: true });
chờ trình duyệt.ngắt kết nối();
} bắt (lỗi) {
console.error(lỗi);
}
}
scrapeGemini().thì();Nền tảng 3: Giám sát Gemini (LLM Mạnh Nhất Của Google)
Gemini là LLM hàng đầu của Google, có khả năng suy luận tiên tiến và lựa chọn trích dẫn nghiêm ngặt.
Giám sát Gemini giúp bạn:
- Xem cách các truy vấn của bạn hoạt động dưới mô hình suy luận cao
- Quan sát cách mô hình tạo ra câu trả lời
- Nhận diện các nguồn mà Gemini tin tưởng và trích dẫn
Ví Dụ Mã Đầy Đủ
js
const puppeteer = require('puppeteer-core');
async function scrapeGemini() {
const truy vấn = new URLSearchParams({
sessionTTL: 900,
sessionRecording: "true",
sessionName: "AskGemini",
proxyCountry: 'US',
token: "KHÓA API SCRAPELESS", // XiaoLu
});
const browserWSEndpoint = `wss://browser.scrapeless.com/api/v2/browser?${truy vấn.toString()}`;
console.log('browserWSEndpoint: ', browserWSEndpoint);
cố gắng {
const trình duyệt = await puppeteer.connect({
browserWSEndpoint,
defaultViewport: null,
});
const trang = await trình duyệt.newPage();
await trang.goto('https://gemini.google.com/app', { timeout: 60000 });
// Nhập truy vấn vào Gemini
const geminiInput = await trang.waitForSelector('div[role="textbox"]');
await geminiInput.gõ('công cụ lấy dữ liệu shopee tốt nhất');
await geminiInput.nhấn('Enter');
// Chờ cho việc tạo câu trả lời của Gemini
await new Promise((giải quyết) => setTimeout(giải quyết, 10000));
await trang.chụp màn hình({ đường dẫn: 'result.png', toàn bộ trang: true });
await trình duyệt.ngắt kết nối();
} bắt (lỗi) {
console.error(lỗi);
}
}
scrapeGemini().thì();Phần 4: Từ Dữ Liệu Đến Hành Động - Cách Sử Dụng Những Thông Tin Này Để Cải Thiện Xếp Hạng Của Bạn
Bây giờ bạn đã có dữ liệu chi tiết từ cả ba nền tảng.
Câu hỏi quan trọng là: Làm thế nào để bạn sử dụng dữ liệu này để thực sự cải thiện xếp hạng sản phẩm hoặc nội dung của bạn?
Trường Hợp Sử Dụng 1: Xác Định "Sự Bao Phủ Câu Hỏi Phụ" Bị Thiếu
Nguồn Dữ Liệu:
Các trang web tham chiếu và câu hỏi phụ được tạo ra của Google AI Mode
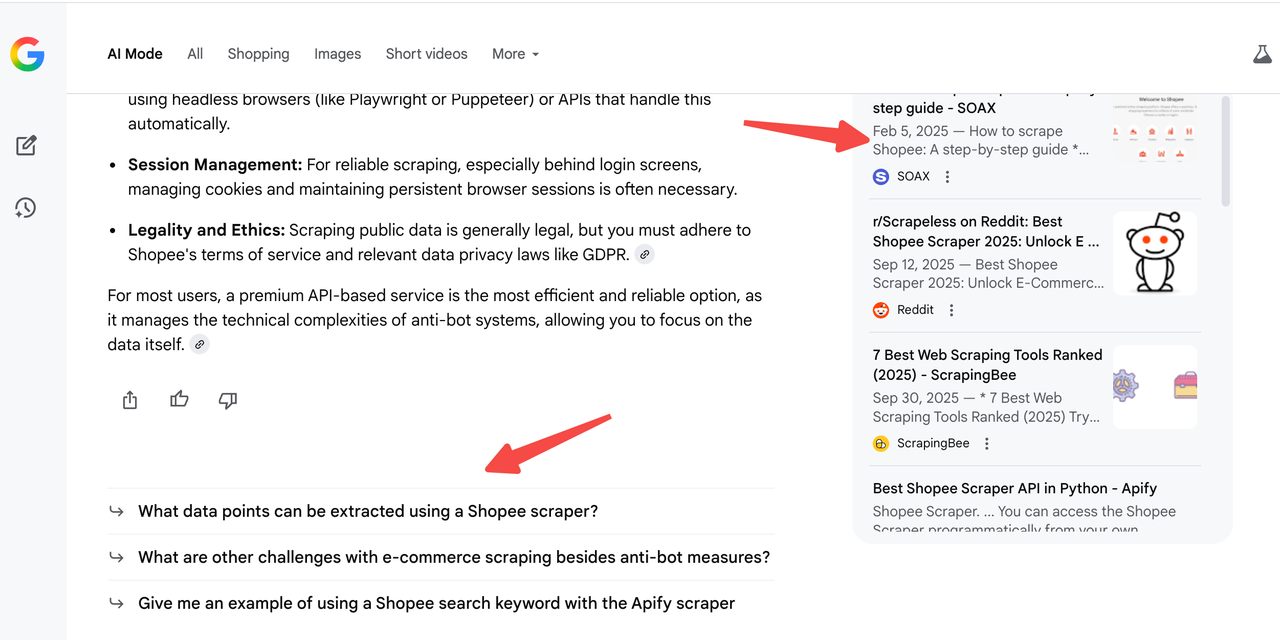
Khi bạn chạy trình thu thập dữ liệu AI Mode, bạn sẽ nhận được danh sách đầy đủ các câu hỏi phụ.
Ví dụ, nếu bạn truy vấn “công cụ lấy dữ liệu shopee tốt nhất”, AI Mode có thể tạo ra 10 câu hỏi phụ ở bảng bên phải - trong khi trang web của bạn chỉ bao phủ 3 trong số đó.
Kế Hoạch Hành Động
- Tạo một bài viết dài 500–800 từ cho mỗi câu hỏi phụ bị thiếu.
- Sử dụng câu hỏi phụ chính nó làm tiêu đề bài viết - không thay đổi hoặc đơn giản hóa.
- Bắt đầu bài viết với một thẻ H1 ngay lập tức trả lời câu hỏi phụ, tiếp theo là thông tin bổ sung.
Trường Hợp Sử Dụng 2: Học Từ Đối Thủ Có Nhiều Trích Dẫn AI Nhất
Nguồn Dữ Liệu:
Các trang web tham chiếu được trích xuất từ cả ba nền tảng
Nếu bạn nhận thấy một đối thủ được trích dẫn 7 lần trên 10 câu hỏi phụ trong khi bạn chỉ được trích dẫn 2 lần, điều đó có nghĩa là cấu trúc nội dung của họ phù hợp tốt hơn với kỳ vọng của AI.
Kế Hoạch Hành Động
-
Truy cập các trang đối thủ chính xác được trích dẫn.
-
Phân tích cấu trúc chung trên các trang đó:
- Họ có sử dụng tiêu đề phụ rõ ràng không?
- Họ có bao gồm các bảng so sánh không?
- Họ có cung cấp ví dụ hoặc dữ liệu thực không?
- Độ dài đoạn văn điển hình là bao nhiêu?
-
Viết lại hoặc cập nhật nội dung của bạn theo các mẫu cấu trúc đó.
Trường Hợp Sử Dụng 3: Theo Dõi Cập Nhật Kiến Thức Trong Mô Hình Gemini
Nguồn Dữ Liệu:
Câu trả lời và mô hình trích dẫn của Gemini
Gemini cập nhật hàng tháng. Một số chủ đề chuyển từ "cần tìm kiếm trực tiếp" thành "mô hình đã biết câu trả lời."
Điều này tiết lộ thông tin nào đã nhập vào bộ dữ liệu đào tạo của mô hình.
Kế Hoạch Hành Động
-
Thực hiện một phiên giám sát hàng tháng và ghi lại cách câu trả lời của Gemini thay đổi cho các chủ đề chính của bạn.
-
Khi một câu hỏi trở thành thứ mà mô hình "đã trả lời tốt", không từ bỏ chủ đề đó. Thay vào đó, nâng cấp nội dung của bạn:
- Thêm thông tin cập nhật ở trình độ 2025 (ví dụ: “các công cụ được ra mắt vào cuối năm 2024”).
- Thêm ví dụ từ người dùng thực tế - mô hình không thể thu thập những điều này.
- So sánh với các đối thủ mới mà mô hình có thể chưa biết đến.
Trường Hợp Sử Dụng 4: Phát hiện Xu Hướng Quan Tâm của Người Dùng
Nguồn Dữ Liệu:
Từ khóa và phân tích câu hỏi từ Google AI Mode + Gemini
Câu trả lời do AI tạo ra phản ánh hành vi người dùng tổng hợp—các câu hỏi phụ và đoạn văn trả lời tiết lộ những điểm đau mà người dùng quan tâm nhất.
### **Kế Hoạch Hành Động**
1. So sánh câu trả lời của AI theo thời gian và theo dõi các từ khóa và câu hỏi phụ xuất hiện nhiều nhất.
2. Cập nhật nội dung của bạn và đẩy các chủ đề có sự quan tâm cao lên đầu trang.
3. Sử dụng các khối FAQ, tiêu đề H2/H3 và đánh dấu schema để tăng cường tính đồng nhất với mẫu tìm kiếm và trích dẫn AI.
---
# **Kết Luận**
Trong kỷ nguyên tìm kiếm sinh ra, tư duy SEO cũ của "xếp hạng trước tiên" đang bị thay thế.
Cuộc cạnh tranh thực sự không còn là về ai xếp hạng cao hơn trong SERP truyền thống—
mà là **nội dung nào mà AI chọn, tin tưởng và trích dẫn** trong câu trả lời.
Scrapeless cung cấp cho các công ty cái nhìn đầy đủ vào quy trình ra quyết định của AI và biến những hiểu biết đó thành chiến lược GEO có thể hành động.
---
# **Tại Sao Scrapeless Là Động Cơ Chính Cho GEO**
Trình duyệt Scrapeless cung cấp những lợi thế vô song:
* **Mạng Proxy Toàn Cầu**: Hơn 195 quốc gia để thu thập kết quả AI theo thị trường cụ thể
* **Mô Phỏng Giống Như Con Người**: Tự động xử lý các hệ thống chống bot, dấu vân tay trình duyệt, CAPTCHA
* **Trích Xuất Dữ Liệu Hoàn Chỉnh**: Câu trả lời AI, trích dẫn, cấu trúc HTML, và nhiều hơn nữa
* **Môi Trường Đám Mây Không Bảo Trì**: Không cần trình duyệt hoặc máy chủ cục bộ—giảm 95% chi phí vận hành
* **Bộ Công Cụ GEO Đầy Đủ**: Giám sát trích dẫn AI, phân tích nội dung có cấu trúc, thu thập dữ liệu toàn cầu
Tối ưu hóa động cơ sinh ra không còn là tùy chọn—nó là nền tảng của khả năng cạnh tranh nội dung doanh nghiệp.
Nếu bạn muốn giành được sự nhìn thấy chiến lược trong kỷ nguyên tìm kiếm AI, Scrapeless cung cấp giải pháp dữ liệu GEO đầy đủ nhất có sẵn.
Scrapeless không chỉ cung cấp tự động hóa GEO dựa trên trình duyệt, mà còn nhiều công cụ tiên tiến hơn và chiến lược dữ liệu để giúp bạn hiểu và tác động đến cơ chế trích dẫn AI một cách đầy đủ.
**Chúng tôi cũng đã ra mắt [truy cập API LLM đầy đủ](https://www.scrapeless.com/vi/blog/scrapeless-llm-chat-scraper)** (ChatGPT, Perplexity, Gemini, và nhiều hơn nữa).
Nếu bạn quan tâm, [liên hệ với chúng tôi](https://t.me/liam_scrapeless) để nhận **truy cập dùng thử miễn phí**.Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


