
Công cụ CLI Truy Vết Trình Duyệt: Truy Vết Web Đầu Tiên Qua Terminal cho Các Đại Lý & Nhà Phát Triển AI
Senior Web Scraping Engineer
Những điểm chính:
- Scraping Browser CLI cách mạng hóa việc trích xuất dữ liệu web bằng cách cung cấp tự động hóa trình duyệt đám mây trực tiếp từ terminal của bạn.
- Nó cung cấp các tính năng chống phát hiện mạnh mẽ, proxy dân cư toàn cầu và phiên làm việc liên tục, vượt qua những thách thức phổ biến trong việc scrap web.
- Tích hợp liền mạch với các tác nhân AI, cho phép họ thực hiện các tương tác web phức tạp và thu thập dữ liệu với độ chính xác giống như con người.
- Khám phá các kỹ thuật nâng cao cho việc xử lý nội dung động, tự động hóa biểu mẫu và xây dựng các pipeline dữ liệu tinh vi.
Giới thiệu: Sự phát triển của việc trích xuất dữ liệu web
Trong thế giới hiện nay, nơi dữ liệu là trung tâm, việc truy cập và tương tác với dữ liệu web cực kỳ quan trọng đối với các nhà phát triển, nhà khoa học dữ liệu và lĩnh vực AI đang phát triển. Tuy nhiên, bối cảnh của việc scrap web đã trở nên ngày càng phức tạp. Các trang web sử dụng các biện pháp chống bot tinh vi, việc tải nội dung động yêu cầu trình diễn nâng cao, và việc quản lý cài đặt tự động hóa trình duyệt cục bộ có thể tiêu tốn tài nguyên và dễ gặp sự cố. Những thách thức này thường biến nhiệm vụ thu thập dữ liệu đơn giản thành một rào cản kỹ thuật đáng kể.
Scraping Browser CLI, được cung cấp bởi Scrapeless, nổi lên như một giải pháp mạnh mẽ cho những vấn đề scrap web hiện đại này. Đây là một công cụ tự động hóa trình duyệt dựa trên đám mây hiện đại cho phép bạn dễ dàng scrap, tìm kiếm và tương tác với các trang web bằng cách sử dụng các lệnh terminal trực quan. Bằng cách chuyển giao việc thực thi trình duyệt cho một cơ sở hạ tầng đám mây mạnh mẽ, nó mang đến một trải nghiệm liền mạch, hiệu suất cao cho cả nhà phát triển con người và các tác nhân AI, đảm bảo trích xuất dữ liệu đáng tin cậy và hiệu quả mà không phải lo lắng về việc bảo trì địa phương hoặc tài nguyên hạ tầng.
Scraping Browser CLI là gì?
Scraping Browser CLI là một công cụ giao diện dòng lệnh tiên tiến được phát triển một cách tỉ mỉ cho việc tự động hóa trình duyệt đám mây và tích hợp sâu với tác nhân AI. Không giống như các khung tự động hóa trình duyệt cục bộ thông thường như Puppeteer hoặc Playwright, yêu cầu cài đặt Chrome hoặc Chromium cục bộ, CLI này hoạt động hoàn toàn trong cơ sở hạ tầng đám mây của Scrapeless. Sự khác biệt cơ bản này mang lại những lợi thế vô song về khả năng mở rộng, độ tin cậy và quản lý tài nguyên.
Cách tiếp cận dựa trên đám mây này có nghĩa là bạn có thể thực hiện các tương tác web mạnh mẽ, thực hiện việc scrapping dữ liệu quy mô lớn và tiến hành kiểm tra tự động mà không phải tiêu tốn tài nguyên tính toán của hệ thống cục bộ của bạn. Hơn nữa, các kỹ năng chuyên biệt được xây dựng dựa trên Scraping Browser CLI có thể cấp cho các tác nhân AI của bạn đầy đủ các khả năng trình duyệt đám mây. Điều này cho phép chúng duyệt các trang web, điền vào các biểu mẫu, nhấp vào các nút và trích xuất dữ liệu như một người dùng thực thụ, hoàn thành liền mạch nhiều nhiệm vụ tự động hóa web khác nhau.
Những lợi thế cốt lõi: Tại sao việc dựa trên đám mây lại quan trọng
Scraping Browser CLI mang đến nhiều lợi ích khác biệt, có tính cách mạng cho quy trình scrap web của bạn:
- Thực thi đám mây: Tất cả các hoạt động trình duyệt được thực hiện trong đám mây, hoàn toàn loại bỏ nhu cầu về các cài đặt trình duyệt cục bộ, quản lý driver và lượng tài nguyên tiêu tốn liên quan.
- Chống phát hiện thông minh: Nó có các cơ chế nhận diện ngón tay và chống bot tinh vi tích hợp sẵn. Điều này cho phép bạn điều hướng các hạn chế trang web và CAPTCHA một cách mượt mà, bắt chước hành vi của con người.
- Proxy toàn cầu: Hỗ trợ tích hợp các proxy dân cư toàn cầu cho phép bạn mô phỏng truy cập từ nhiều vị trí địa lý khác nhau, điều cần thiết cho việc trích xuất dữ liệu cục bộ và vượt qua các khóa địa lý.
- Khả năng duy trì phiên: Quản lý phiên nâng cao đảm bảo lưu giữ trạng thái qua nhiều tương tác, điều quan trọng cho các quy trình nhiều bước như đăng nhập và gửi biểu mẫu phức tạp.
- Thiết kế thân thiện với AI: CLI sử dụng một hệ thống tham chiếu phần tử trực quan (như @e1, @e2) để tạo điều kiện cho tương tác dễ dàng, mạnh mẽ cho các tác nhân AI, trừu tượng hóa các bộ chọn DOM phức tạp.
Để tìm hiểu thông tin chi tiết hơn, bạn có thể khám phá tài liệu chính thức hoặc truy cập kho GitHub.
Tính năng và khả năng: Sự tìm hiểu sâu
Scraping Browser CLI được trang bị nhiều tính năng được thiết kế để xử lý những thách thức scrap web hiện đại khó nhằn nhất. Dưới đây là phân tích toàn diện về các chức năng cốt lõi của nó:
| Danh mục tính năng | Mô tả |
|---|---|
| Tự động hóa trình duyệt đám mây | Thực hiện tất cả các hoạt động trong đám mây, không yêu cầu cài đặt trình duyệt cục bộ, đảm bảo hiệu suất cao và khả năng mở rộng. |
| Hỗ trợ proxy dân cư | Proxy dân cư toàn cầu tích hợp với mục tiêu định vị địa lý chính xác cho truy cập dữ liệu địa phương. |
| Nhận diện thông minh | Cơ chế nhận dạng và chống phát hiện tự động để vượt qua các hệ thống chống bot tinh vi. |
| Quản lý phiên | Hỗ trợ toàn diện cho việc tạo, quản lý và duy trì các phiên làm việc qua các quy trình phức tạp. |
| Tương tác Thân thiện với AI | Hệ thống tham chiếu phần tử (@e1, @e2) được thiết kế đặc biệt để tương thích liền mạch với đại lý AI. |
| Ảnh chụp màn hình & Trích xuất | Năng lực mạnh mẽ để chụp ảnh màn hình trang đầy đủ và trích xuất nội dung cụ thể, có cấu trúc. |
| Ghi lại phiên | Hỗ trợ ghi lại các phiên để gỡ lỗi, kiểm toán và phát lại. |
Các tính năng này làm cho nó trở thành một công cụ rất linh hoạt, so sánh với các giải pháp hàng đầu khác trong ngành, nhưng với sự nhấn mạnh rõ rệt vào tích hợp đại lý AI và thực thi liền mạch trên đám mây.
Tổng quan về Lệnh Chính: Bộ công cụ Tự động hóa của bạn
CLI cung cấp cú pháp đơn giản, trực quan để quản lý các phiên và tương tác với các trang web. Dưới đây là một số lệnh chính mà bạn sẽ sử dụng để điều phối tự động hóa của mình:
bash
# Quản lý Phiên
scrapeless-scraping-browser new-session # Tạo một phiên mới
scrapeless-scraping-browser sessions # Liệt kê tất cả các phiên đang hoạt động
scrapeless-scraping-browser stop <id> # Dừng một phiên cụ thể
# Điều hướng Trang
scrapeless-scraping-browser open <url> # Mở một trang web
scrapeless-scraping-browser close # Đóng phiên hiện tại
# Tương tác Trang
scrapeless-scraping-browser snapshot -i # Lấy các phần tử tương tác
scrapeless-scraping-browser click @e1 # Nhấp vào một phần tử cụ thể
scrapeless-scraping-browser fill @e2 "text" # Điền vào một trường biểu mẫu
# Trích xuất Dữ liệu
scrapeless-scraping-browser get text @e1 # Trích xuất văn bản từ một phần tử
scrapeless-scraping-browser screenshot # Chụp ảnh màn hình của một trangBắt đầu: Hướng dẫn Từng bước
Việc thiết lập CLI Scraping Browser là một quá trình nhanh chóng và đơn giản, được thiết kế để bạn có thể bắt đầu trích xuất nội dung trong vài phút.
Cài đặt
Phương pháp được khuyên dùng là cài đặt CLI toàn cầu bằng npm, đảm bảo nó có sẵn trên toàn hệ thống của bạn:
bash
npm install -g scrapeless-scraping-browserNgoài ra, bạn có thể chạy trực tiếp mà không cần cài đặt bằng cách sử dụng npx cho các tác vụ ngắn, không lặp lại:
bash
npx scrapeless-scraping-browser open https://example.comLấy Khóa API của bạn
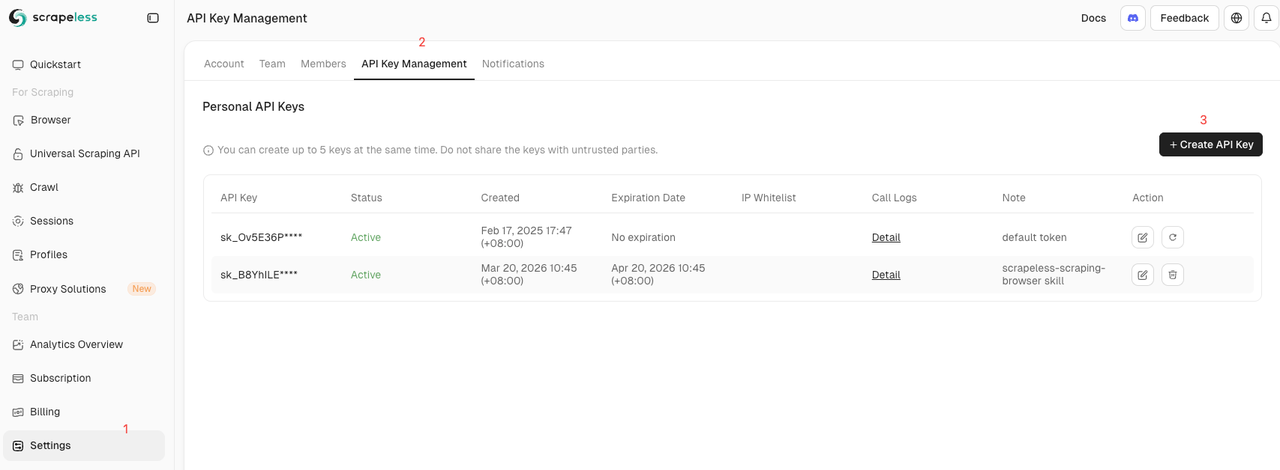
Để xác thực các yêu cầu của bạn và truy cập vào hạ tầng đám mây, bạn cần một khóa API Scrapeless:
- Truy cập vào Bảng điều khiển Scrapeless.
- Đăng nhập hoặc đăng ký tài khoản mới.
- Điều hướng đến trang cài đặt API để tạo và sao chép an toàn Khóa API của bạn.
Cấu hình Xác thực
Bạn có thể cấu hình thông tin xác thực xác thực của mình bằng cách sử dụng một file cấu hình hoặc biến môi trường, mang lại sự linh hoạt cho các môi trường triển khai khác nhau.
Phương pháp 1: File Cấu hình (Khuyên dùng để duy trì)
bash
scrapeless-scraping-browser config set apiKey your_api_key_herePhương pháp 2: Biến Môi trường (Lý tưởng cho CI/CD pipelines)
bash
export SCRAPELESS_API_KEY=your_api_key_hereBạn có thể xác minh cấu hình của mình bằng cách chạy:
bash
scrapeless-scraping-browser config get apiKey
scrapeless-scraping-browser sessionsVí dụ Quy trình Cơ bản: Điều phối một Phiên
Dưới đây là một quy trình cơ bản đơn giản minh họa cách tạo một phiên, tương tác với một trang và đóng phiên gọn gàng:
bash
# Bước 1: Tạo một phiên và lưu ID Phiên
SESSION_ID=$(scrapeless-scraping-browser new-session --name "my-workflow" --ttl 3600 --json | jq -r '.taskId')
# Bước 2: Thực hiện các hoạt động trình duyệt bằng ID Phiên
scrapeless-scraping-browser --session-id $SESSION_ID open https://example.com
scrapeless-scraping-browser --session-id $SESSION_ID snapshot -i
scrapeless-scraping-browser --session-id $SESSION_ID click @e1
# Bước 3: Đóng phiên khi hoàn tất để giải phóng tài nguyên
scrapeless-scraping-browser --session-id $SESSION_ID close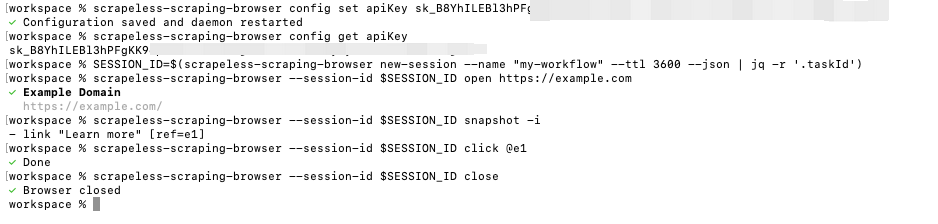
Trường hợp Sử dụng Thực tế: Từ Trích xuất Đơn giản đến Tự động hóa Phức tạp
CLI Scraping Browser xuất sắc trong nhiều kịch bản thực tế, từ việc trích xuất dữ liệu đơn giản đến việc điều phối các quy trình tự động hóa phức tạp, nhiều bước.
Trích xuất từ Bất kỳ Trang web Nào: Vượt qua các Căn bản
Bạn có thể dễ dàng trích xuất nội dung cụ thể từ bất kỳ trang web nào, ngay cả những trang có nội dung động:
bash
# Tạo phiên
SESSION_ID=$(scrapeless-scraping-browser new-session --name "scraping" --ttl 3600 --json | jq -r '.taskId')
# Truy cập trang web mục tiêu
scrapeless-scraping-browser --session-id $SESSION_ID open https://www.scrapeless.com
# Lấy tiêu đề trang
scrapeless-scraping-browser --session-id $SESSION_ID get title
# Lấy nội dung của một phần tử cụ thể
scrapeless-scraping-browser --session-id $SESSION_ID get text "h1"
# Đóng phiên
scrapeless-scraping-browser --session-id $SESSION_ID closeYêu Cầu Dựa Trên Địa Điểm: Truy Cập Dữ Liệu Địa Phương
Nếu bạn cần truy cập dữ liệu như nó xuất hiện ở một quốc gia cụ thể (ví dụ: Hoa Kỳ) cho nghiên cứu thị trường hoặc giá cả địa phương, bạn có thể cấu hình phiên làm việc cho phù hợp:
bash
# Tạo phiên làm việc với định vị địa lý
SESSION_ID=$(scrapeless-scraping-browser new-session \
--name "geo-us" \
--proxy-country US \
--ttl 3600 \
--json | jq -r '.taskId')
scrapeless-scraping-browser --session-id $SESSION_ID open https://api.iplook.io
scrapeless-scraping-browser --session-id $SESSION_ID get text "pre"
scrapeless-scraping-browser --session-id $SESSION_ID closeTự Động Điền Biểu Mẫu: Tối Ưu Hóa Tương Tác
Tự động hóa quá trình đăng nhập, đăng ký hoặc các biểu mẫu tìm kiếm phức tạp rất đơn giản với các lệnh tương tác mạnh mẽ của CLI:
bash
# Tạo phiên làm việc
SESSION_ID=$(scrapeless-scraping-browser new-session --name "form-fill" --ttl 3600 --json | jq -r '.taskId')
# Mở trang đăng nhập
scrapeless-scraping-browser --session-id $SESSION_ID open https://app.scrapeless.com/passport/login
# Lấy các yếu tố tương tác
scrapeless-scraping-browser --session-id $SESSION_ID snapshot -i
# Điền các trường biểu mẫu và gửi
scrapeless-scraping-browser --session-id $SESSION_ID fill @e2 "this_is_email"
scrapeless-scraping-browser --session-id $SESSION_ID fill @e3 "this_is_pwd"
scrapeless-scraping-browser --session-id $SESSION_ID click @e5Điều Khiển Phiên Trình Trình Duyệt và Ghi Âm: Dễ Dàng Gỡ Lỗi
Để gỡ lỗi các kịch bản phức tạp hoặc giám sát các tác vụ tự động, bạn có thể bật ghi âm phiên và tương tác với trang theo thời gian thực:
bash
# Tạo phiên làm việc và bật ghi âm
SESSION_ID=$(scrapeless-scraping-browser new-session \
--name "browser-control" \
--recording true \
--ttl 7200 \
--json | jq -r '.taskId')
# Mở trang
scrapeless-scraping-browser --session-id $SESSION_ID open https://www.scrapeless.com
# Lấy liên kết xem trước trực tiếp
scrapeless-scraping-browser --session-id $SESSION_ID live
# Thực hiện các thao tác trên trang
scrapeless-scraping-browser --session-id $SESSION_ID scroll down 500
scrapeless-scraping-browser --session-id $SESSION_ID screenshot page.pngChuỗi Lệnh Với Pip Unix: Xây Dựng Dòng Dữ Liệu
CLI tích hợp hoàn hảo với các công cụ Unix tiêu chuẩn, cho phép bạn xây dựng các dòng dữ liệu tinh vi, trơn tru trực tiếp trong terminal của mình:
bash
# Các thao tác chuỗi để thực hiện hiệu quả
scrapeless-scraping-browser open https://example.com \
&& scrapeless-scraping-browser wait --load networkidle \
&& scrapeless-scraping-browser snapshot -i
# Lưu ảnh chụp màn hình
scrapeless-scraping-browser screenshot screenshot.pngTùy Chỉnh Dấu Vân Tay Trình Duyệt: Tránh Phát Hiện Nâng Cao
Bạn có thể xác định các tác nhân người dùng tùy chỉnh và các tham số dấu vân tay khác để phù hợp với các yêu cầu thu hoạch dữ liệu và tránh bị phát hiện:
bash
SESSION_ID=$(scrapeless-scraping-browser new-session \
--name "customer-ua" \
--user-agent "custom_user_agent_string" \
--json | jq -r '.taskId')
scrapeless-scraping-browser --session-id $SESSION_ID open https://example.comThúc Đẩy Các Đại Lý AI: Tương Lai Của Tương Tác Web
Một trong những tính năng nổi bật, biến đổi của CLI Trình Duyệt Thu Hoạch Làm Rỗng là khả năng tích hợp liền mạch vào các khách hàng Đại Lý AI, cung cấp cho họ khả năng tương tác web chân thực, mạnh mẽ. Đây là một lợi thế đáng kể so với các công cụ truyền thống, phù hợp với sự chuyển dịch của ngành sang các quy trình làm việc tự động.
Ví Dụ Tích Hợp: Ngôn Ngữ Tự Nhiên Đến Hành Động Web
Bạn có thể hướng dẫn Đại Lý AI của mình bằng các nhắc nhở ngôn ngữ tự nhiên và CLI chuyển đổi điều này thành các hành động web đáng tin cậy:
bash
USER_PROMPT="Sử dụng kỹ năng scrapeless-scraping-browser để tìm kiếm thông tin giá cả của 20 tai nghe không dây hàng đầu trên Amazon và cho tôi biết thương hiệu nào có giá trung bình thấp nhất."Các Đại Lý AI Hỗ Trợ
CLI được thiết kế để tương thích rộng rãi với nhiều đại lý AI hỗ trợ mở rộng kỹ năng, bao gồm:
- Claude Code
- Cursor
- CodeLlama
- OpenClaw
- Và nhiều framework AI mở rộng khác sử dụng các giao thức như MCP (Model Context Protocol).
Để tìm hiểu thêm về việc tích hợp các đại lý AI với Scrapeless và mở khóa các khả năng này, hãy xem hướng dẫn toàn diện của chúng tôi về Trình Duyệt Thu Hoạch Tốt Nhất Năm 2026: Kỹ Năng Trình Duyệt Thu Hoạch OpenClaw Được Phát Hành.
Tùy Chỉnh Tùy Chọn Cấu Hình Nâng Cao: Tùy Chỉnh Môi Trường Của Bạn
Đối với các nhiệm vụ thu thập dữ liệu phức tạp, quy mô doanh nghiệp, CLI cung cấp nhiều tham số cấu hình để tinh chỉnh môi trường của bạn.
Tùy chọn phiên
Bạn có thể cấu hình môi trường phiên của mình một cách tỉ mỉ với nhiều cờ để mô phỏng các hồ sơ người dùng cụ thể:
bash
scrapeless-scraping-browser new-session \
--name "advanced-session" \
--ttl 7200 \
--recording true \
--proxy-country US \
--proxy-state CA \
--platform macOS \
--screen-width 1440 \
--screen-height 900 \
--timezone "America/Los_Angeles" \
--languages "en,es"Quản lý Cấu hình
Quản lý cài đặt mặc định của bạn một cách dễ dàng để tối ưu hóa quy trình làm việc của bạn:
bash
# Đặt cấu hình
scrapeless-scraping-browser config set proxyCountry US
scrapeless-scraping-browser config set sessionTtl 3600
# Xem tất cả cấu hình
scrapeless-scraping-browser config list
# Lấy một cấu hình cụ thể
scrapeless-scraping-browser config get apiKeyTại sao chọn Scrapeless? Lợi thế cạnh tranh
Khi so sánh các công cụ CLI thu thập dữ liệu web, Scrapeless nổi bật với giải pháp toàn diện, tân tiến trên đám mây, ưu tiên tích hợp AI, chống phát hiện mạnh mẽ và trải nghiệm dành cho nhà phát triển. Cho dù bạn đang xây dựng một Công cụ thu thập dữ liệu Google Maps chuyên biệt, giám sát tính khả dụng của thương hiệu với một Công cụ thu thập dữ liệu Gemini, hay triển khai một Máy chủ MCP, Scraping Browser CLI cung cấp cơ sở hạ tầng có thể mở rộng, đáng tin cậy cần thiết cho thành công trong năm 2026 và hơn thế nữa.
Kết luận: Nâng cao Tự động hóa Web của Bạn
Scraping Browser CLI là một công cụ tự động hóa trình duyệt đám mây mạnh mẽ, thay đổi cục diện, trang bị cho các nhà phát triển và AI Agents khả năng tương tác web đơn giản nhưng mạnh mẽ. Từ việc trích xuất dữ liệu đơn giản và thử nghiệm tự động đến giám sát web phức tạp và quy trình làm việc có tác động, nó xử lý các nhiệm vụ yêu cầu một cách dễ dàng và đáng tin cậy chưa từng thấy.
Sẵn sàng xây dựng Pipelines dữ liệu AI của bạn?
Tham gia cộng đồng năng động của chúng tôi để nhận gói miễn phí và kết nối với các nhà đổi mới khác:
Discord
Telegram
Câu hỏi thường gặp
Q: Tôi có cần cài đặt trình duyệt địa phương không?
A: Không. Scraping Browser CLI hoàn toàn hoạt động trên đám mây, thực hiện tất cả các thao tác trình duyệt trên cơ sở hạ tầng Scrapeless an toàn, hiệu suất cao.
Q: Nó xử lý các cơ chế chống thu thập dữ liệu của website như thế nào?
A: CLI có tính năng nhận diện trình duyệt nâng cao và các cơ chế chống phát hiện tích hợp. Kết hợp với mạng lưới proxy dân cư rộng lớn của chúng tôi, nó có thể vượt qua hầu hết các hạn chế chống thu thập dữ liệu và CAPTCHA.
Q: Một phiên kéo dài bao lâu?
A: Thời gian chờ phiên mặc định là 180 giây (3 phút). Bạn có thể dễ dàng tùy chỉnh thời gian này bằng cách sử dụng tham số --ttl để phù hợp với quy trình làm việc lâu hơn.
Q: Làm thế nào tôi có thể lưu ảnh chụp màn hình?
A: Sử dụng lệnh chụp màn hình để lưu hình ảnh. Nó hỗ trợ cả hình ảnh chụp toàn trang và khu vực cụ thể, hoàn hảo cho việc xác minh hình ảnh.
Q: Những thao tác nào của trình duyệt được hỗ trợ?
A: Nó hỗ trợ một loạt các thao tác thông dụng như điều hướng trang, nhấp vào phần tử, điền form, cuộn, chờ và chụp ảnh màn hình, đáp ứng hầu hết các nhu cầu tương tác.
Q: Có sẵn API lập trình không?
A: Có, ngoài các lệnh CLI, Scrapeless cung cấp một API khách hàng TypeScript/Node.js mạnh mẽ để tích hợp liền mạch vào mã nguồn của ứng dụng bạn.
Để tìm hiểu thêm về thu thập dữ liệu web, tự động hóa AI và các kỹ thuật nâng cao, hãy khám phá Blog Scrapeless.
Tại Scrapless, chúng tôi chỉ truy cập dữ liệu có sẵn công khai trong khi tuân thủ nghiêm ngặt các luật, quy định và chính sách bảo mật trang web hiện hành. Nội dung trong blog này chỉ nhằm mục đích trình diễn và không liên quan đến bất kỳ hoạt động bất hợp pháp hoặc vi phạm nào. Chúng tôi không đảm bảo và từ chối mọi trách nhiệm đối với việc sử dụng thông tin từ blog này hoặc các liên kết của bên thứ ba. Trước khi tham gia vào bất kỳ hoạt động cạo nào, hãy tham khảo ý kiến cố vấn pháp lý của bạn và xem xét các điều khoản dịch vụ của trang web mục tiêu hoặc có được các quyền cần thiết.


