スクレイプレス x アクティブピース
ScrapelessをActivepiecesと統合して、視覚的で自動化されたノーコードのデータワークフローを構築する方法を学びましょう。

Activepiecesは、オープンソースのAIファーストノーコードビジネス自動化プラットフォームで、基本的にはZapierの自己ホスト型代替品であり、強力なブラウザー自動化機能を備えています。
ScrapelessはActivepiecesで以下のモジュールを提供しています:
1. Google検索 – Googleからリッチな検索データにアクセスして取得します。
2. Googleトレンド - Googleトレンドデータを抽出し、キーワードの人気度や検索関心を追跡します。
3. ユニバーサルスクレイピング – 通常はボットをブロックするJSレンダリングウェブサイトからデータにアクセスして抽出します。
4. ウェブページデータのスクレイピング – 単一のウェブページから情報を抽出します。
5. すべてのページからデータをクロール – ウェブサイトとそのリンクページをクロールして包括的なデータを抽出します。
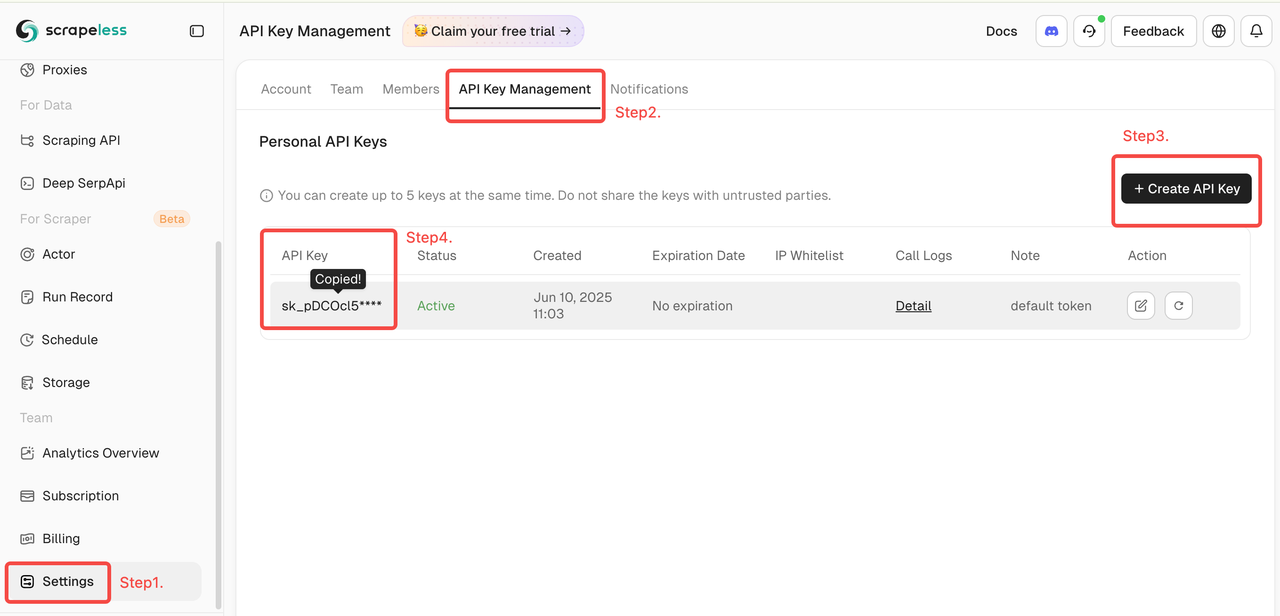
https://www.amazon.com/LK-Apple-Watch-Screen-Protector/dp/B0DFG31G1P/を使用します。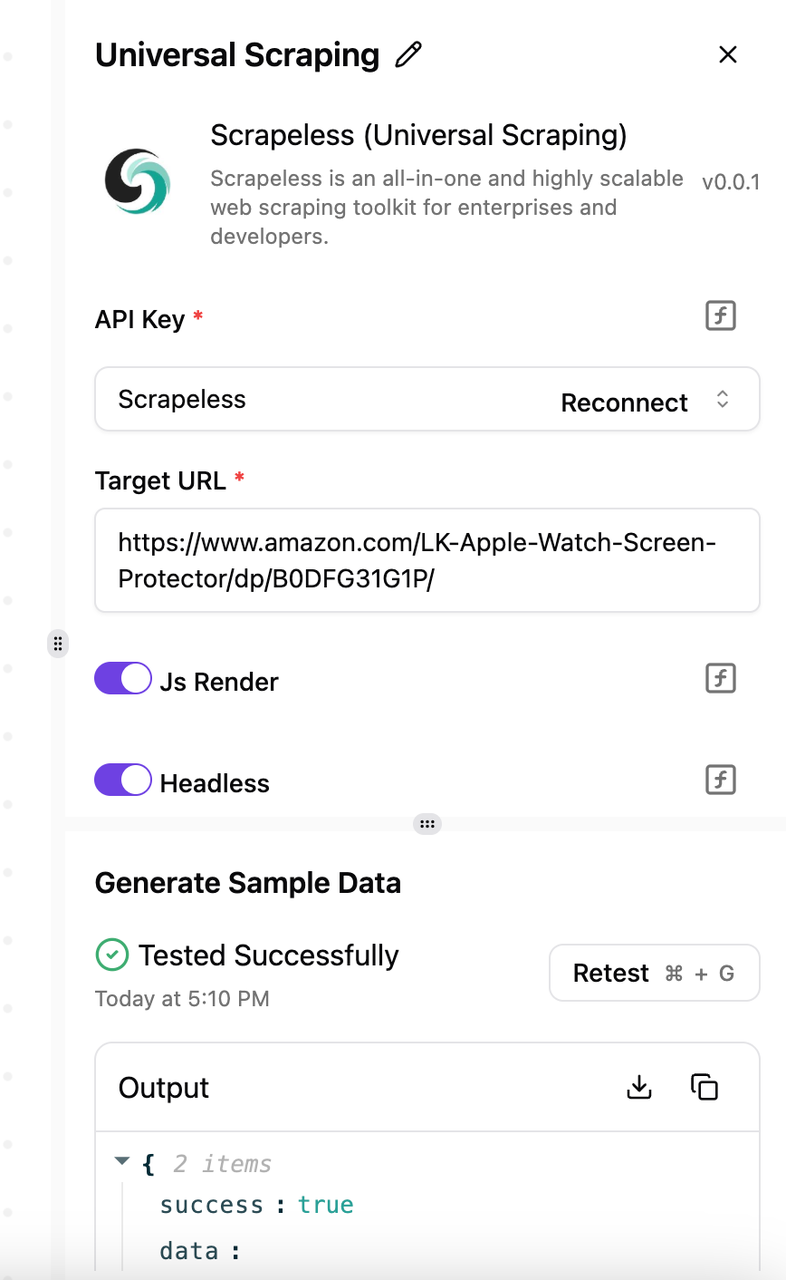
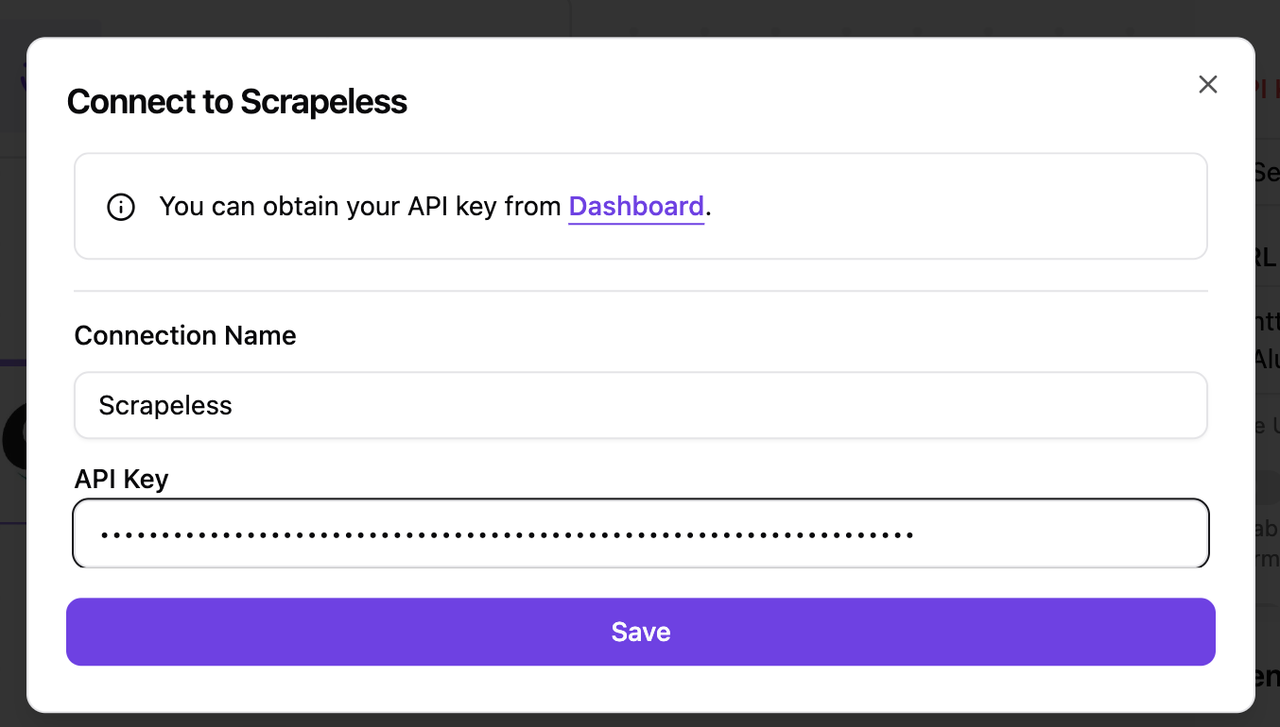
次に、前のステップでスクレイピングしたHTMLデータをクリーンにする必要があります。まず、inputsセクションでユニバーサルスクレイピングデータを選択します。コード構成は次のとおりです:
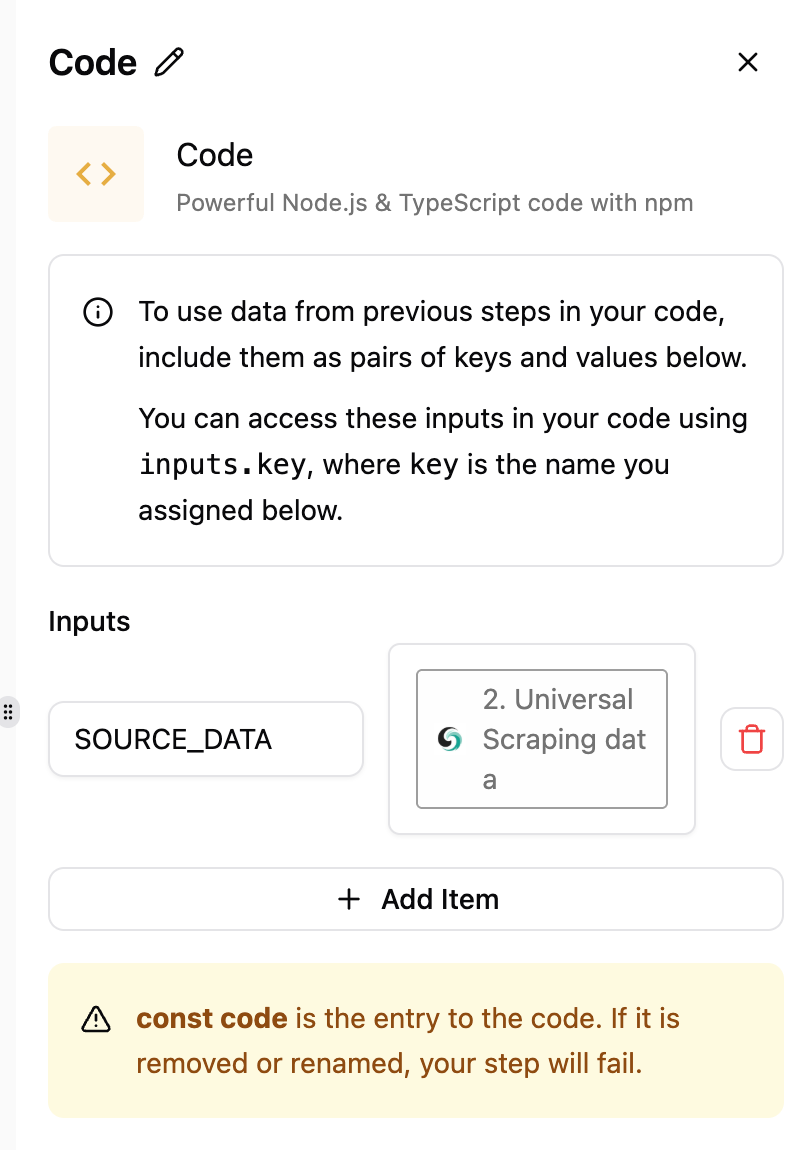
export const code = async (inputs) => {
const html = inputs.SOURCE_DATA
const titleMatch = html.match(/id=['"]productTitle['"][^>]*>([^<]+)</i);
const title = titleMatch ? titleMatch[1].trim() : "";
const priceMatch = html.match(/class=['"]a-offscreen['"][^>]*>\$?([\d.,]+)/i);
const price = priceMatch ? priceMatch[1].trim() : "";
const ratingMatch = html.match(/class=['"]a-icon-alt['"][^>]*>([^<]+)</i);
const rating = ratingMatch ? ratingMatch[1].trim() : "";
return [
{
json: {
title,
price,
rating
},
},
];
};次に、クリーンで構造化されたデータをGoogle Sheetsに出力することができます。Google Sheetsノードを追加し、Google Sheets接続を構成します。
注意:事前にGoogleシートを作成しておいてください。
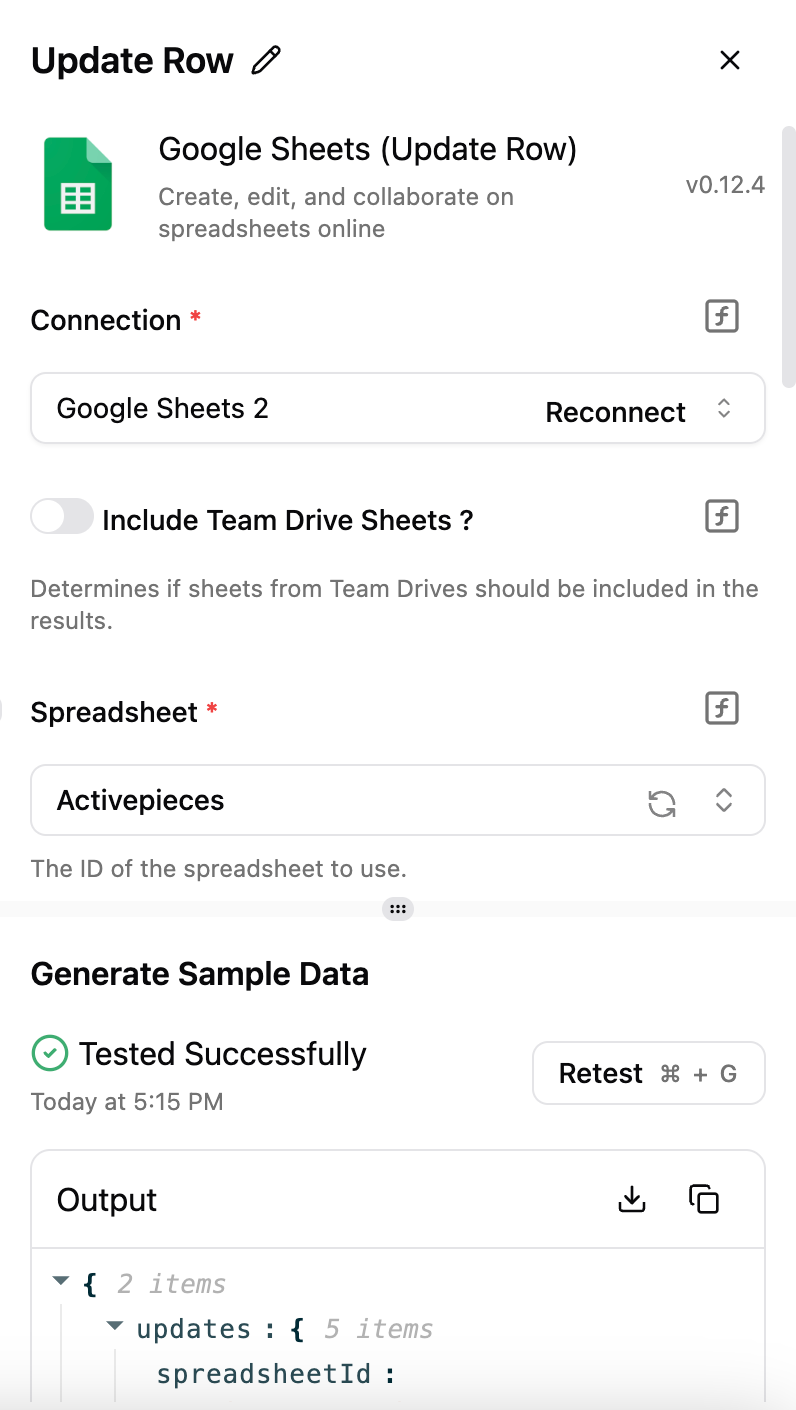

これでScrapelessのセットアップと使用方法に関する簡単なチュートリアルが終了です。質問がある場合は、Scrapeless Discordでお気軽に話し合ってください。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。