「n8nでScrapelessを使用してAI駆動のパイプラインを構築する方法は?」
n8n、Scrapeless、Claudeを使用したAI駆動のウェブデータパイプラインの構築

今日のデータ駆動型の状況において、組織はウェブコンテンツを抽出、処理、分析するための効率的な方法を必要としています。従来のウェブスクレイピングは、多くの課題に直面しています:ボット対策、複雑なJavaScriptレンダリング、そして常時メンテナンスの必要性があります。さらに、非構造化のウェブデータを理解するには洗練された処理が必要です。
このガイドでは、n8nワークフロー自動化、Scrapelessウェブスクレイピング、インテリジェント抽出のためのClaude AI、そしてセマンティックストレージのためのQdrantベクトルデータベースを使用した完全なウェブデータパイプラインの構築方法を示します。知識ベースを構築したり、市場調査を行ったり、AIアシスタントを開発したりする際に、このワークフローは強力な基盤を提供します。
私たちのn8nワークフローは、いくつかの最先端技術を組み合わせています:
このエンドツーエンドパイプラインは、混乱したウェブデータを構造化されたベクトル化情報に変換し、セマンティック検索やAIアプリケーションの準備が整います。
n8nはNode.js v18、v20、またはv22を必要とします。バージョンの互換性の問題が発生した場合:
# Node.jsのバージョンを確認
node -v
# 新しい非サポートバージョン(例:v23+)を持っている場合、nvmをインストール
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.5/install.sh | bash
# Windowsの場合は、NVM for Windowsインストーラーを使用
# 互換性のあるNode.jsバージョンをインストール
nvm install 20
# インストールしたバージョンを使用
nvm use 20
# n8nをグローバルにインストール
npm install n8n -g
# n8nを実行
n8nn8nインスタンスは、http://localhost:5678で使用できるようになっているはずです。
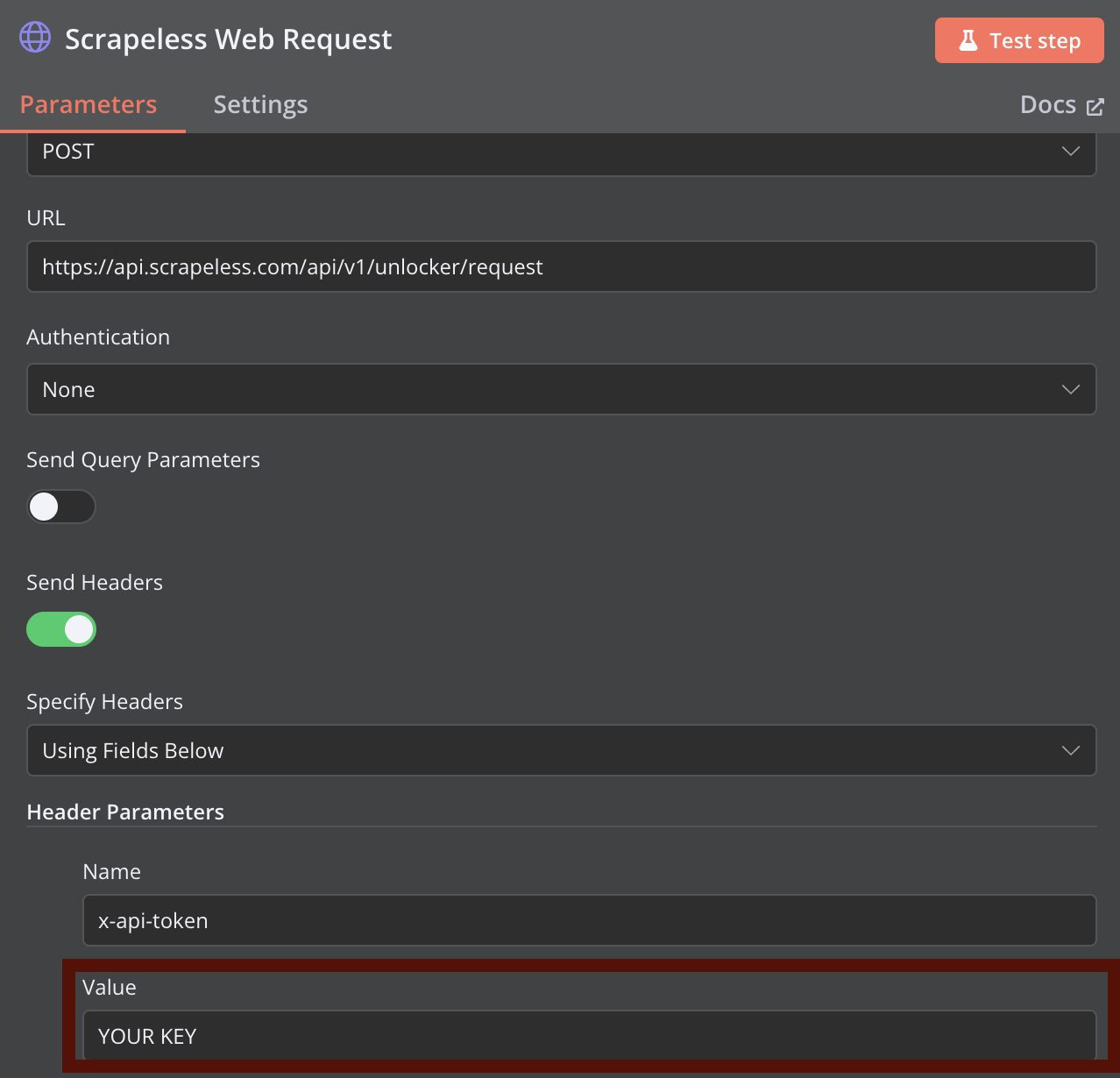
このcurlコマンドを使用してScrapelessのウェブスクレイピングリクエストをカスタマイズし、n8nのHTTPリクエストノードに直接インポートできます:
curl -X POST "https://api.scrapeless.com/api/v1/unlocker/request" \
-H "Content-Type: application/json" \
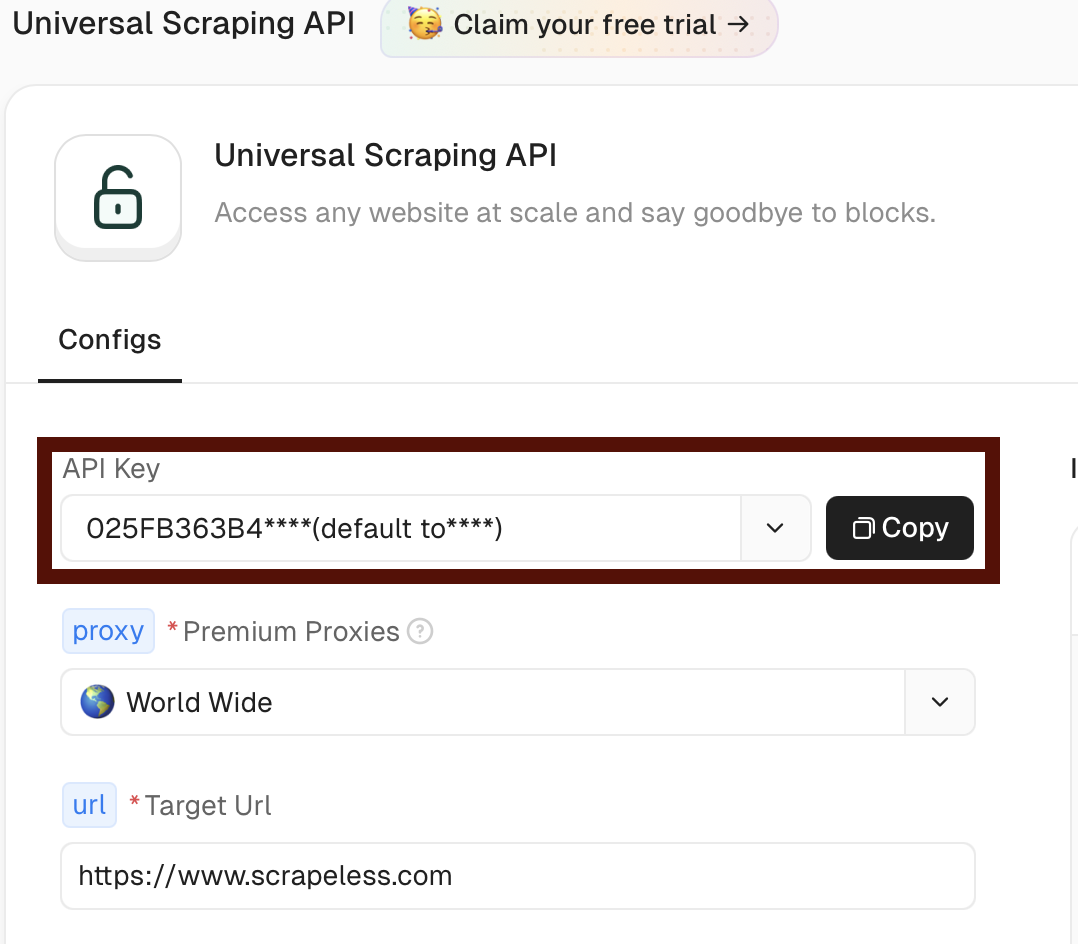
-H "x-api-token: scrapeless_api_key" \
-d '{
"actor": "unlocker.webunlocker",
"proxy": {
"country": "ANY"
},
"input": {
"url": "https://www.scrapeless.com",
"method": "GET",
"redirect": true,
"js_render": true,
"js_instructions": [{"wait":100}],
"block": {
"resources": ["image","font","script"],
"urls": ["https://example.com"]
}
}
}'
# Qdrantイメージをプル
docker pull qdrant/qdrant
# データ永続性を持つQdrantコンテナを実行
docker run -d \
--name qdrant-server \
-p 6333:6333 \
-p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage \
qdrant/qdrantQdrantが実行されていることを確認:
curl http://localhost:6333/healthzmacOS:
brew install ollamaLinux:
curl -fsSL https://ollama.com/install.sh | shWindows: Ollamaのウェブサイトからダウンロードしてインストールしてください。
Ollamaサーバーを起動:
ollama serve必要な埋め込みモデルをインストール:
ollama pull all-minilmモデルのインストールを確認:
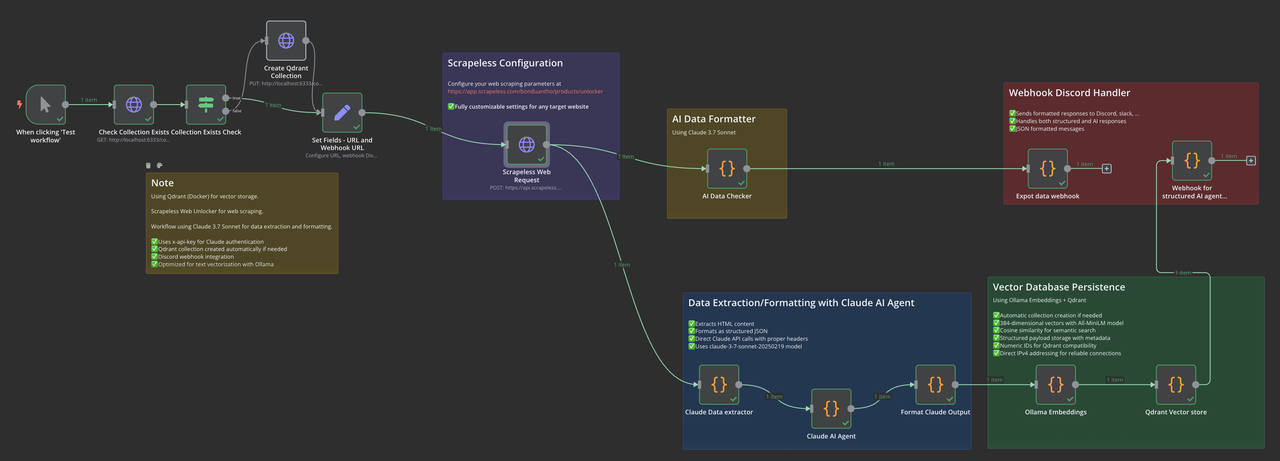
ollama list私たちのワークフローは、これらの主要なコンポーネントで構成されています:
手動トリガーノードを追加し、その後に HTTP リクエストノードを追加して、Qdrant コレクションが存在するかどうかを確認します。この初期ステップでコレクション名をカスタマイズできます。ワークフローは、存在しない場合に自動的にコレクションを作成します。
重要な注意: デフォルトの「hacker-news」と異なるコレクション名を使用したい場合は、Qdrant を参照するすべてのノードで一貫して変更してください。
Scrapeless ウェブスクレイピング用の HTTP リクエストノードを追加します。以前提供された curl コマンドを参考にしてノードを設定し、YOUR_API_TOKEN を実際の Scrapeless API トークンに置き換えます。
Scrapeless Web Unlocker でより高度なスクレイピングパラメータを設定できます。
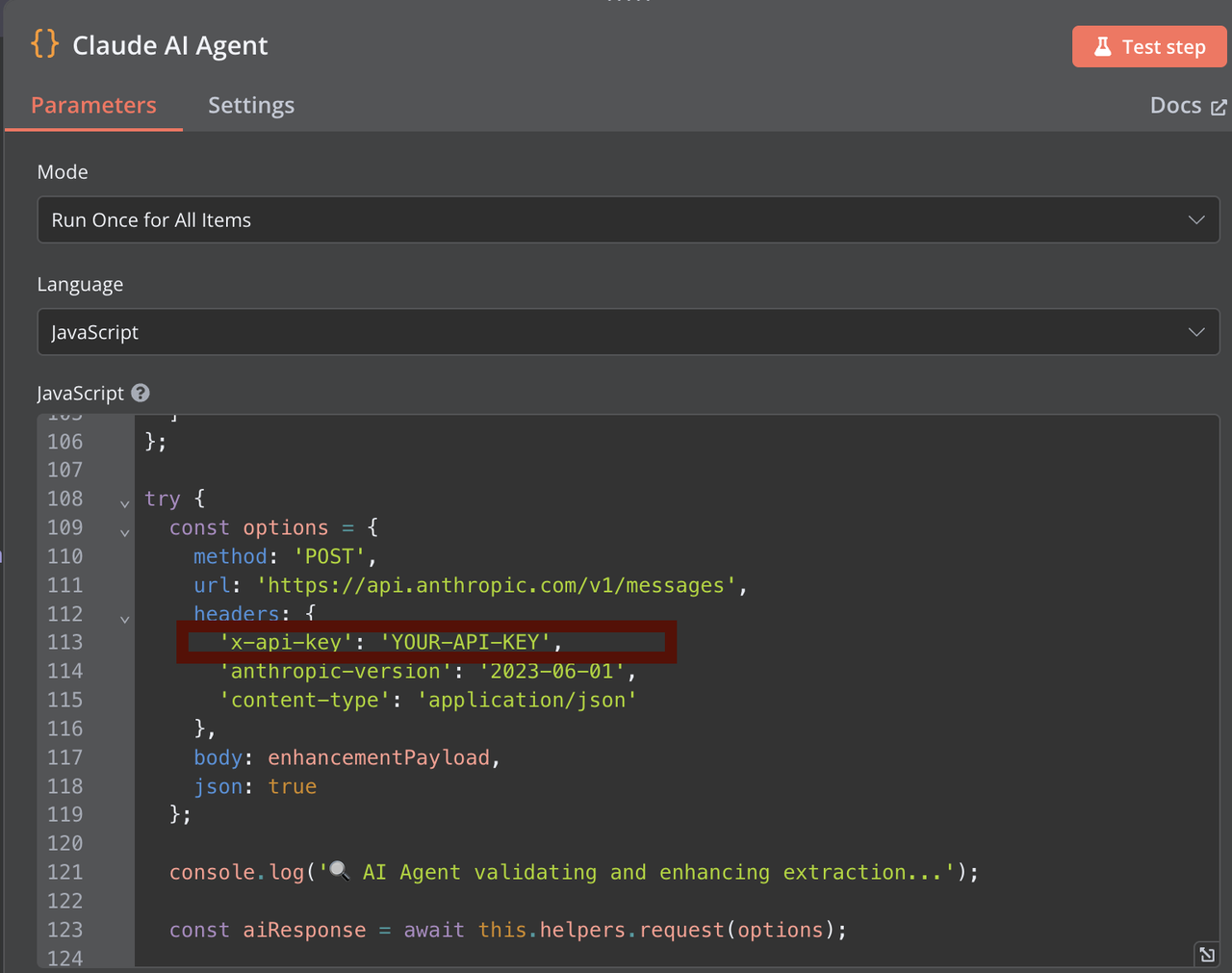
HTML コンテンツを処理するノードを追加します。認証のために Claude API キーを提供する必要があります。Claude エクストラクターは HTML コンテンツを分析し、JSON 形式で構造化データを返します。
このノードは Claude の応答を受け取り、関連情報を抽出して適切にフォーマットし、ベクトル化のために準備します。
このノードは構造化されたテキストを Ollama に送信して埋め込みを生成します。Ollama サーバーが実行中であり、all-minilm モデルがインストールされていることを確認してください。
このノードは生成された埋め込みを取得し、それを関連メタデータと共に Qdrant コレクションに保存します。
最終ノードは、構成された webhook を通じてワークフロー実行のステータスを通知します。
以下のようなエラーが表示された場合:
Your Node.js version X is currently not supported by n8n.
Please use Node.js v18.17.0 (recommended), v20, or v22 instead!nvm をインストールし、設定セクションに記載された互換性のある Node.js バージョンを使用して修正します。
一般的なエラー: connect ECONNREFUSED ::1:11434
修正:
一度のワークフロー実行で複数の URL を処理するには:
スケジュールされた更新でベクトルデータベースを最新の状態に保ちます:
Claude の抽出をさまざまなコンテンツタイプに適応させます:
この n8n ワークフローは、Scrapeless ウェブスクレイピング、Claude AI 抽出、ベクトル埋め込み、および Qdrant ストレージの強みを組み合わせた強力なデータパイプラインを作成します。これらの複雑なプロセスを自動化することで、取得の技術的課題よりも抽出されたデータの利用に集中できます。
n8n のモジュラーな性質は、このワークフローを追加の処理ステップ、他のシステムとの統合、または特定のニーズに応じたカスタムロジックで拡張できることを可能にします。AI 知識ベースの構築、競合分析の実施、またはウェブコンテンツの監視を行う場合でも、このワークフローは堅固な基盤を提供します。
Scrapelessでは、適用される法律、規制、およびWebサイトのプライバシーポリシーを厳密に遵守しながら、公開されているデータのみにアクセスします。 このブログのコンテンツは、デモンストレーションのみを目的としており、違法または侵害の活動は含まれません。 このブログまたはサードパーティのリンクからの情報の使用に対するすべての責任を保証せず、放棄します。 スクレイピング活動に従事する前に、法律顧問に相談し、ターゲットウェブサイトの利用規約を確認するか、必要な許可を取得してください。