
Scrapeless में Undetected ChromeDriver को सेटअप कैसे करें?
Advanced Data Extraction Specialist
अंडिटेक्टेड क्रोमड्राइवर कैसे एंटी-बॉट सिस्टम को बाईपास करने में सहायता करता है यह जानें वेब स्क्रैपिंग के लिए, साथ ही चरण-दर-चरण मार्गदर्शन, उन्नत विधियाँ और प्रमुख सीमाएँ। इसके अलावा, Scrapeless के बारे में जानें - पेशेवर स्क्रैपिंग आवश्यकताओं के लिए एक अधिक मजबूत विकल्प।
इस मार्गदर्शिका में आप सीखेंगे:
- अंडिटेक्टेड क्रोमड्राइवर क्या है और यह कैसे उपयोगी हो सकता है
- यह कैसे बॉट पहचान कम करता है
- इसे वेब स्क्रैपिंग के लिए पायथन के साथ उपयोग करना
- उन्नत उपयोग और विधियाँ
- इसकी प्रमुख सीमाएँ और नुकसान
- अनुशंसित विकल्प: Scrapeless
- एंटी-बॉट पहचान तंत्र का तकनीकी विश्लेषण
आइए डूबकी लगाते हैं!
अंडिटेक्टेड क्रोमड्राइवर क्या है?
अंडिटेक्टेड क्रोमड्राइवर एक पायथन लाइब्रेरी है जो सेलेनियम के क्रोमड्राइवर का ऑप्टिमाइज्ड संस्करण प्रदान करती है। इसे एंटी-बॉट सेवाओं द्वारा पहचान को सीमित करने के लिए पैच किया गया है जैसे कि:
- इंपर्वा
- डेटा डोम
- डिस्टिल नेटवर्क्स
- और भी बहुत कुछ ...
यह कुछ क्लाउडफ़्लेयर सुरक्षा को बाईपास करने में भी मदद कर सकता है, हालाँकि यह और अधिक चुनौतीपूर्ण हो सकता है।
यदि आपने कभी सेलेनियम जैसी ब्राउज़र ऑटोमेशन टूल का उपयोग किया है, तो आप जानते हैं कि वे आपको प्रोग्रामेटिक रूप से ब्राउज़र नियंत्रित करने की अनुमति देते हैं। इसे संभव बनाने के लिए, वे ब्राउज़रों को नियमित उपयोगकर्ता सेटअप से भिन्न तरीके से कॉन्फ़िगर करते हैं।
एंटी-बॉट सिस्टम उन भिन्नताओं, या "लीक," की तलाश करते हैं ताकि स्वचालित ब्राउज़र बॉट्स की पहचान की जा सके। अंडिटेक्टेड क्रोमड्राइवर क्रोम ड्राइवरों को पैच करता है ताकि इन पहचानने वाले संकेतों को कम किया जा सके, जिससे बॉट पहचान कम होती है। यह एंटी-स्क्रैपिंग उपायों से सुरक्षित साइटों के लिए वेब स्क्रैपिंग के लिए इसे आदर्श बनाता है!
अंडिटेक्टेड क्रोमड्राइवर कैसे काम करता है?
अंडिटेक्टेड क्रोमड्राइवर क्लाउडफ्लेयर, इंपर्वा, डेटा डोम और समान समाधान से पहचान को निम्नलिखित तकनीकों का उपयोग करके कम करता है:
- असली ब्राउज़रों द्वारा उपयोग किए जाने वाले नामों की नकल करने के लिए सेलेनियम वेरिएबल का नाम बदलना
- पहचान से बचने के लिए वैध, वास्तविक दुनिया के यूज़र-एजेंट स्ट्रिंग्स का उपयोग करना
- उपयोगकर्ता को प्राकृतिक मानव इंटरैक्शन का अनुकरण करने की अनुमति देना
- वेबसाइटों पर नेविगेट करते समय सही ढंग से कुकीज़ और सत्रों का प्रबंधन करना
- आईपी ब्लॉकिंग को बाईपास करने और दर सीमा को रोकने के लिए प्रॉक्सी का उपयोग सक्षम करना
ये विधियाँ लाइब्रेरी द्वारा नियंत्रित ब्राउज़र को प्रभावी ढंग से विभिन्न एंटी-स्क्रैपिंग रक्षा को बाईपास करने में मदद करती हैं।
वेब स्क्रैपिंग के लिए अंडिटेक्टेड क्रोमड्राइवर का उपयोग करना: चरण-दर-चरण मार्गदर्शिका
चरण #1: पूर्वापेक्षाएँ और परियोजना सेटअप
अंडिटेक्टेड क्रोमड्राइवर की निम्नलिखित पूर्वापेक्षाएँ हैं:
- क्रोम का नवीनतम संस्करण
- पायथन 3.6+: यदि आपके मशीन पर पायथन 3.6 या बाद का संस्करण स्थापित नहीं है, तो इसे आधिकारिक साइट से डाउनलोड करें और स्थापना निर्देशों का पालन करें।
नोट: लाइब्रेरी आपके लिए ड्राइवर बाइनरी को स्वचालित रूप से डाउनलोड और पैच कर देती है, इसलिए क्रोमड्राइवर को मैन्युअल रूप से डाउनलोड करने की कोई आवश्यकता नहीं है।
अपनी परियोजना के लिए एक निर्देशिका बनाएं:
language
mkdir undetected-chromedriver-scraper
cd undetected-chromedriver-scraper
python -m venv envवर्चुअल एनवायरनमेंट को सक्रिय करें:
language
# लिनक्स या macOS पर
source env/bin/activate
# विंडोज पर
env\Scripts\activateचरण #2: अंडिटेक्टेड क्रोमड्राइवर स्थापित करें
पिप पैकेज के माध्यम से अंडिटेक्टेड क्रोमड्राइवर स्थापित करें:
language
pip install undetected_chromedriverयह लाइब्रेरी स्वचालित रूप से सेलेनियम को स्थापित कर देगी, क्योंकि यह इसके एक निर्भरता है।
चरण #3: प्रारंभिक सेटअप
scraper.py फ़ाइल बनाएं और undetected_chromedriver आयात करें:
language
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
# एक क्रोम उदाहरण प्रारंभ करें
driver = uc.Chrome()
# लक्षित पृष्ठ से कनेक्ट करें
driver.get("https://scrapeless.com")
# स्क्रैपिंग लॉजिक...
# ब्राउज़र बंद करें
driver.quit()चरण #4: स्क्रैपिंग लॉजिक लागू करें
अब चलो एपल पृष्ठ से डेटा निकालने की लॉजिक जोड़ते हैं:
language
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
import time
# एक क्रोम वेब ड्राइवर उदाहरण बनाएं
driver = uc.Chrome()
# ऐपल वेबसाइट से कनेक्ट करें
driver.get("https://www.apple.com/fr/")
# पृष्ठ को पूरी तरह से लोड होने का कुछ समय दें
time.sleep(3)
# उत्पाद जानकारी संग्रहीत करने के लिए शब्दकोष
apple_products = {}
try:
# उत्पाद अनुभागों को खोजें (प्रस्तुत HTML से वर्गों का उपयोग करते हुए)
product_sections = driver.find_elements(By.CSS_SELECTOR, ".homepage-section.collection-module .unit-wrapper")
for i, section in enumerate(product_sections):
try:
# उत्पाद का नाम निकालें (हेडलाइन)
headline = section.find_element(By.CSS_SELECTOR, ".headline, .logo-image").get_attribute("textContent").strip()
# विवरण निकालें (सबहेड)
hi
subhead_element = section.find_element(By.CSS_SELECTOR, ".subhead")
subhead = subhead_element.text
# लिंक प्राप्त करें यदि उपलब्ध हो
link = ""
try:
link_element = section.find_element(By.CSS_SELECTOR, ".unit-link")
link = link_element.get_attribute("href")
except:
pass
apple_products[f"product_{i+1}"] = {
"name": headline,
"description": subhead,
"link": link
}
except Exception as e:
print(f"भाग {i+1} प्रक्रिया में त्रुटि: {e}")
# स्क्रैप की गई डेटा को JSON में निर्यात करें
with open("apple_products.json", "w", encoding="utf-8") as json_file:
json.dump(apple_products, json_file, indent=4, ensure_ascii=False)
print(f"सफलतापूर्वक {len(apple_products)} सेब उत्पादों को स्क्रैप किया")
except Exception as e:
print(f"स्क्रैपिंग के दौरान त्रुटि: {e}")
finally:
# ब्राउज़र बंद करें और इसके संसाधनों को मुक्त करें
driver.quit()इसे चलाएँ:
language
python scraper.pyअनडिटेक्टेड क्रोमड्राइवर: उन्नत उपयोग
अब जब आप जानते हैं कि यह पुस्तकालय कैसे काम करता है, तो आप कुछ और उन्नत परिदृश्यों का पता लगाने के लिए तैयार हैं।
एक विशिष्ट क्रोम संस्करण चुनें
आप संस्करण_मुख्य तर्क सेट करके पुस्तकालय के लिए एक विशेष क्रोम संस्करण निर्दिष्ट कर सकते हैं:
language
import undetected_chromedriver as uc
# लक्षित क्रोम संस्करण निर्दिष्ट करें
driver = uc.Chrome(version_main=105)विथ सिंटैक्स
जब आपको अब ड्राइवर की आवश्यकता नहीं होती है, तो आप quit() विधि को मैन्युअल रूप से कॉल करने से बचने के लिए विथ सिंटैक्स का उपयोग कर सकते हैं:
language
import undetected_chromedriver as uc
with uc.Chrome() as driver:
driver.get("https://example.com")
# आपका बाकी कोड...अनडिटेक्टेड क्रोमड्राइवर की सीमाएँ
हालांकि अनडिटेक्टेड_chromedriver एक शक्तिशाली पायथन पुस्तकालय है, लेकिन इसकी कुछ ज्ञात सीमाएँ हैं:
आईपी ब्लॉक्स
यह पुस्तकालय आपके आईपी पते को छिपाता नहीं है। यदि आप एक डाटासेंटर से स्क्रिप्ट चला रहे हैं, तो पहचान की संभावना बहुत अधिक है। इसी प्रकार, यदि आपका घरेलू आईपी खराब प्रतिष्ठा का है, तो आप भी ब्लॉक किए जा सकते हैं।
अपने आईपी को छिपाने के लिए, आपको नियंत्रित ब्राउज़र को प्रॉक्सी सर्वर के साथ एकीकृत करना होगा, जैसा कि पहले प्रदर्शित किया गया था।
GUI नेविगेशन के लिए कोई समर्थन नहीं
इस मॉड्यूल के आंतरिक कार्यान्वयन के कारण, आपको get() विधि का उपयोग करके प्रोग्रामेटिक रूप से ब्राउज़ करना चाहिए। मैन्युअल नेविगेशन के लिए ब्राउज़र GUI का उपयोग करने से बचें—कीबोर्ड या माउस के माध्यम से पृष्ठ के साथ बातचीत करने से पहचान का जोखिम बढ़ता है।
हेडलेस मोड के लिए सीमित समर्थन
आधिकारिक रूप से, हेडलेस मोड अनडिटेक्टेड_क्रोमड्राइवर पुस्तकालय द्वारा पूरी तरह से समर्थित नहीं है। हालाँकि, आप इसे प्रयोग कर सकते हैं:
language
driver = uc.Chrome(headless=True)स्थिरता समस्याएँ
परिणाम कई कारणों से भिन्न हो सकते हैं। पहचान एल्गोरिदम को समझने और उनका मुकाबला करने के लिए निरंतर प्रयासों के अलावा कोई गारंटी नहीं दी जाती है। एक स्क्रिप्ट जो आज एंटी-बॉट सिस्टम को चकमा देती है, कल विफल हो सकती है यदि सुरक्षा विधियों को अपडेट मिलें।
अनुशंसित विकल्प: स्क्रैपलेस
अनडिटेक्टेड क्रोमड्राइवर की सीमाओं को ध्यान में रखते हुए, स्क्रैपलेस बिना ब्लॉक किए वेब स्क्रैपिंग के लिए एक अधिक मजबूत और विश्वसनीय विकल्प प्रदान करता है।
हम वेबसाइट की गोपनीयता की दृढ़ता से रक्षा करते हैं। इस ब्लॉग में सभी डेटा सार्वजनिक हैं और इसे केवल क्रॉलिंग प्रक्रिया के प्रदर्शन के रूप में उपयोग किया जाता है। हम कोई जानकारी और डेटा संग्रहीत नहीं करते हैं।
स्क्रैपलेस क्यों बेहतर है
स्क्रैपलेस एक रिमोट ब्राउज़र सेवा है जो अनडिटेक्टेड क्रोमड्राइवर दृष्टिकोण की अंतर्निहित समस्याओं को हल करती है:
-
निरंतर अपडेट: अनडिटेक्टेड क्रोमड्राइवर के विपरीत, जो एंटी-बॉट सिस्टम अपडेट के बाद काम करना बंद कर सकता है, स्क्रैपलेस अपने टीम द्वारा निरंतर अपडेट किया जाता है।
-
अंतर्निहित आईपी रोटेशन: स्क्रैपलेस स्वचालित आईपी रोटेशन प्रदान करता है, जो अनडिटेक्टेड क्रोमड्राइवर की आईपी ब्लॉकिंग समस्या को समाप्त करता है।
-
ऑप्टिमाइज्ड कॉन्फ़िगरेशन: स्क्रैपलेस ब्राउज़र्स पहले से ही पहचान से बचने के लिए ऑप्टिमाइज़ किए गए हैं, जिससे प्रक्रिया को बहुत सरल बनाया जा सकता है।
-
स्वचालित CAPTCHA हल करना: स्क्रैपलेस स्वचालित रूप से CAPTCHAs को हल कर सकता है जो आपको सामना करना पड़ सकता है।
-
कई ढाँचों के साथ संगत: प्लेव्राइट, पपेटियर और अन्य स्वचालन उपकरणों के साथ काम करता है।
स्क्रैपलेस में साइन इन करें मुफ्त परीक्षण के लिए।
अनुशंसित पढ़ाई: पपेटियर के साथ क्लाउडफ्लेयर बाईपास कैसे करें
स्क्रैपलेस का उपयोग करके वेब स्क्रैप करने के लिए कैसे (बिना ब्लॉक किए)
यहाँ स्क्रैपलेस का उपयोग करके एक समान समाधान लागू करने का तरीका है:
चरण 1: स्क्रैपलेस के लिए पंजीकरण करें और लॉग इन करें
**चरण 2: Scrapeless API KEY प्राप्त करें**
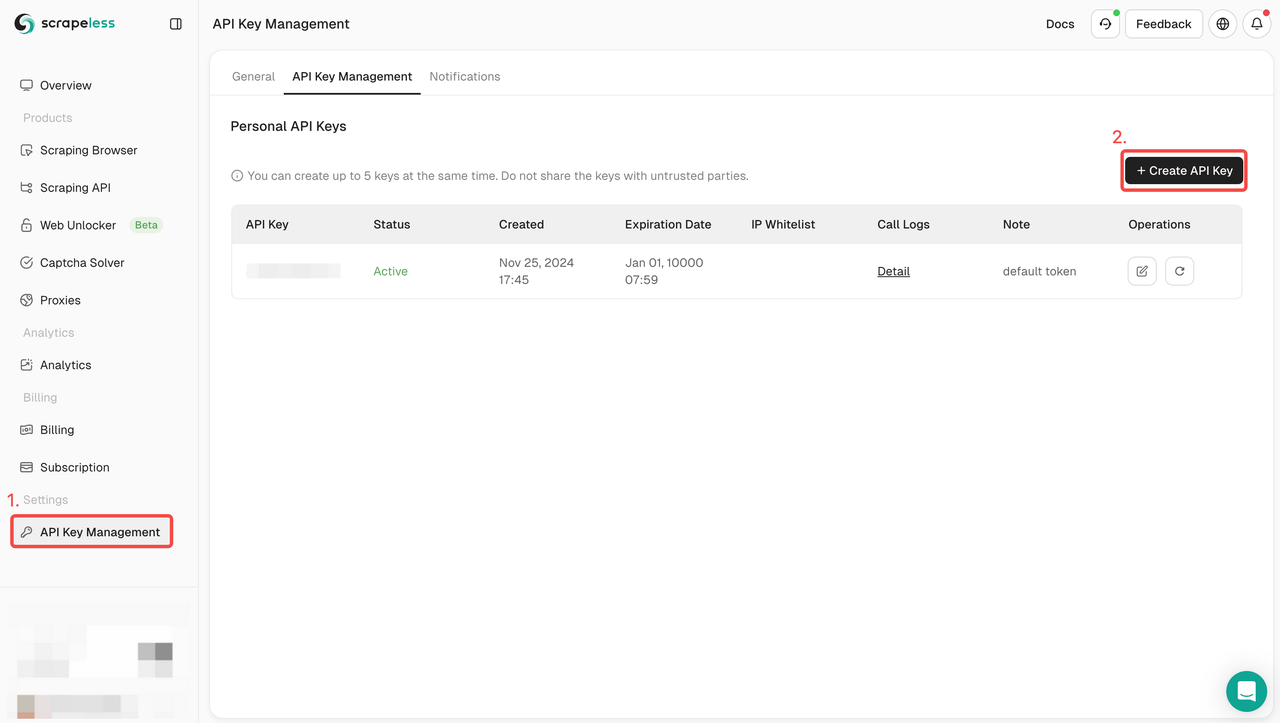
**चरण 3: आप निम्नलिखित कोड को अपने प्रोजेक्ट में एकीकृत कर सकते हैं**
```language
const {chromium} = require('playwright-core');
// Scrapeless कनेक्शन URL आपके टोकन के साथ
const connectionURL = 'wss://browser.scrapeless.com/browser?token=YOUR_TOKEN_HERE&session_ttl=180&proxy_country=ANY';
(async () => {
// दूरस्थ Scrapeless ब्राउज़र से कनेक्ट करें
const browser = await chromium.connectOverCDP(connectionURL);
try {
// एक नया पृष्ठ बनाएं
const page = await browser.newPage();
// एप्पल की वेबसाइट पर जाएं
console.log('एप्पल की वेबसाइट पर जा रहा हूं...');
await page.goto('https://www.apple.com/fr/', {
waitUntil: 'domcontentloaded',
timeout: 60000
});
console.log('पृष्ठ सफलतापूर्वक लोड हुआ');
// उत्पाद खंडों के उपलब्ध होने की प्रतीक्षा करें
await page.waitForSelector('.homepage-section.collection-module', { timeout: 10000 });
// होमपेज से विशेष उत्पाद प्राप्त करें
const products = await page.evaluate(() => {
const results = [];
// सभी उत्पाद खंडों को प्राप्त करें
const productSections = document.querySelectorAll('.homepage-section.collection-module .unit-wrapper');
productSections.forEach((section, index) => {
try {
// उत्पाद का नाम प्राप्त करें - यह .headline या .logo-image में हो सकता है
const headlineEl = section.querySelector('.headline') || section.querySelector('.logo-image');
const headline = headlineEl ? headlineEl.textContent.trim() : 'अज्ञात उत्पाद';
// उत्पाद का विवरण प्राप्त करें
const subheadEl = section.querySelector('.subhead');
const subhead = subheadEl ? subheadEl.textContent.trim() : '';
// उत्पाद का लिंक प्राप्त करें
const linkEl = section.querySelector('.unit-link');
const link = linkEl ? linkEl.getAttribute('href') : '';
results.push({
name: headline,
description: subhead,
link: link
});
} catch (err) {
console.error(`खंड ${index} को संसाधित करने में त्रुटि: ${err.message}`);
}
});
return results;
});
// परिणामों को प्रदर्शित करें
console.log('एप्पल उत्पाद पाए गए:');
console.log(JSON.stringify(products, null, 2));
console.log(`कुल उत्पाद पाए गए: ${products.length}`);
} catch (error) {
console.error('एक त्रुटि हुई:', error);
} finally {
// ब्राउज़र बंद करें
await browser.close();
console.log('ब्राउज़र बंद कर दिया गया');
}
})();आप डेवलपर समर्थन कार्यक्रम में भाग लेने के लिए Scrapeless Discord भी जॉइन कर सकते हैं और निःशुल्क 500k SERP API उपयोग क्रेडिट प्राप्त कर सकते हैं।
विस्तारित तकनीकी विश्लेषण
बोट डिटेक्शन: यह कैसे काम करता है
एंटी-बॉट सिस्टम स्वचालन का पता लगाने के लिए कई तकनीकों का उपयोग करते हैं:
-
ब्राउज़र फिंगरप्रिंटिंग: ब्राउज़र के गुणों (फॉन्ट्स, कैनवास, वेबजीएल, आदि) को एक अद्वितीय हस्ताक्षर बनाने के लिए एकत्र करता है।
-
वेबड्राइवर डिटेक्शन: वेबड्राइवर API या इसकी कलाकृतियों की उपस्थिति की तलाश करता है।
-
व्यवहारात्मक विश्लेषण: माउस आंदोलनों, क्लिकों, टाइपिंग गति का विश्लेषण करता है जो मानवों और बॉट्स के बीच भिन्न होते हैं।
-
नेविगेशन विसंगति डिटेक्शन: संदिग्ध पैटर्न की पहचान करता है जैसे बहुत तेज़ अनुरोध या छवि/CSS लोडिंग की कमी।
अनुशंसित पढ़ाई: एंटी बॉट को बायपास करने के लिए कैसे
कैसे Undetected ChromeDriver डिटेक्शन को बायपास करता है
Undetected ChromeDriver इन पहचान को बायपास करता है:
-
वेबड्राइवर संकेतकों को हटाना:
navigator.webdriverप्रॉपर्टी और अन्य वेबड्राइवर ट्रेस को समाप्त करता है। -
Cdc_ को पैच करना: वेबड्राइवर के ज्ञात हस्ताक्षरों को संशोधित करने के लिए क्रोम ड्राइवर नियंत्रक चर को संशोधित करता है।
-
यथार्थवादी उपयोगकर्ता-एजेंट का उपयोग करना: डिफ़ॉल्ट उपयोगकर्ता-एजेंट को अप-टू-डेट स्ट्रिंग्स के साथ बदलता है।
-
कॉन्फ़िगरेशन परिवर्तनों को कम करना: क्रोम ब्राउज़र के डिफ़ॉल्ट व्यवहार में बदलावों को कम करता है।
Undetected ChromeDriver ड्राइवर को पैच करने का तकनीकी कोड दिखा रहा है:
language
Undetected ChromeDriver स्रोत कोड से सरलित अंश
def _patch_driver_executable():
"""
स्वचालन के स्पष्ट संकेतों को हटाने के लिए ChromeDriver बाइनरी को पैच करता है
"""
linect = 0
replacement = os.urandom(32).hex()
with io.open(self.executable_path, "r+b") as fh:
for line in iter(lambda: fh.readline(), b""):
if b"cdc_" in line.lower():
fh.seek(-len(line), 1)
newline = re.sub(
b"cdc_.{22}", b"cdc_" + replacement.encode(), line
)
fh.write(newline)
linect += 1
return linectक्यों Scrapeless अधिक प्रभावी है
स्क्रैपलेस एक अलग दृष्टिकोण अपनाता है:
-
पूर्व-संरचित वातावरण: मानव उपयोगकर्ताओं की नकल करने के लिए पहले से अनुकूलित ब्राउज़रों का उपयोग करना।
-
क्लाउड-आधारित बुनियादी ढांचा: सही फिंगरप्रिंटिंग के साथ क्लाउड में ब्राउज़रों को चलाना।
-
बुद्धिमान प्रॉक्सी रोटेशन: लक्षित साइट के आधार पर स्वचालित रूप से आईपी घूमाना।
-
उन्नत फिंगरप्रिंट प्रबंधन: सत्र के दौरान अनवरत ब्राउज़र फिंगरप्रिंट बनाए रखना।
-
वेबआरटीसी, कैनवास, और प्लगइन दमन: सामान्य फिंगरप्रिंटिंग तकनीकों को ब्लॉक करना।
स्क्रैपलेस में साइन इन करें एक मुफ्त परीक्षण के लिए।
निष्कर्ष
इस लेख में, आपने बिना ब्लॉक किए वेब स्क्रैपिंग के लिए अंडिटेक्टेड क्रोमड्राइवर का उपयोग करके बॉट पहचान से निपटने के तरीके सीखे हैं। यह पुस्तकालय स्क्रैपिंग के लिए एक पैच किया हुआ क्रोमड्राइवर प्रदान करता है।
चुनौती यह है कि क्लाउडफ्लेयर जैसी उन्नत एंटी-बॉट तकनीकें अभी भी आपके स्क्रिप्ट को पहचानने और ब्लॉक करने में सक्षम होंगी। undetected_chromedriver जैसी पुस्तकालयें अस्थिर हैं—हालांकि वे आज काम कर सकती हैं, वे कल काम नहीं कर सकतीं।
व्यावसायिक स्क्रैपिंग आवश्यकताओं के लिए, क्लाउड-आधारित समाधान जैसे स्क्रैपलेस एक अधिक मजबूत विकल्प प्रदान करते हैं। वे एंटी-बॉट उपायों को बायपास करने के लिए विशेष रूप से डिज़ाइन किए गए पूर्व-निर्धारित दूरस्थ ब्राउज़र प्रदान करते हैं, जिसमें आईपी रोटेशन और कैप्चा हल करने जैसी अतिरिक्त सुविधाएँ होती हैं।
अंडिटेक्टेड क्रोमड्राइवर और स्क्रैपलेस के बीच का चुनाव आपकी विशिष्ट आवश्यकताओं पर निर्भर करता है:
- अंडिटेक्टेड क्रोमड्राइवर: छोटे प्रोजेक्ट्स के लिए अच्छा, मुफ्त और ओपन-सोर्स, लेकिन अधिक रखरखाव की आवश्यकता होती है और यह कम विश्वसनीय हो सकता है।
- स्क्रैपलेस: व्यावसायिक स्क्रैपिंग आवश्यकताओं के लिए बेहतर, अधिक विश्वसनीय, लगातार अपडेट किया जाता है, लेकिन इसके लिए सदस्यता लागत आती है।
इन एंटी-बॉट बायपास तकनीकों के कार्य करने के तरीके को समझकर, आप अपने वेब स्क्रैपिंग प्रोजेक्ट्स के लिए सही उपकरण चुन सकते हैं और स्वचालित डेटा संग्रह के सामान्य pitfalls से बच सकते हैं।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


