
लॉगिन के पीछे की वेबसाइट को पाइथन के साथ कैसे स्क्रैप करें (2026)
Expert Network Defense Engineer
Here is the translation in Hindi:
वर्षों तक स्क्रैपर्स बनाने के बाद, लॉगिन दीवारें सबसे कठिन चुनौतियों में से एक बनी रहती हैं। यह गाइड वास्तविक परियोजनाओं में काम करने वाले व्यावहारिक तरीकों पर केंद्रित है: सरल फॉर्म लॉगिन से लेकर CSRF सुरक्षा और आधुनिक WAF और एंटी-बॉट सिस्टम द्वारा संरक्षित साइटों तक। उदाहरणों में संबंधित मामलों में पायथन का उपयोग किया गया है, और मैं सबसे कठिन सुरक्षा को संभालने के लिए एक दूरस्थ ब्राउज़र (Scrapeless Browser) का उपयोग करने का तरीका दिखाकर समाप्त करता हूं।
यह गाइड केवल शैक्षिक उपयोग के लिए है। साइट की सेवा की शर्तों और गोपनीयता नियमों का सम्मान करें (जैसे GDPR)। उस सामग्री को स्क्रैप न करें जिसे आप एक्सेस करने की अनुमति नहीं रखते हैं।
यह गाइड क्या कवर करती है
- ऐसी साइटों से डेटा स्क्रैप करना जो एक साधारण उपयोगकर्ता नाम और पासवर्ड की आवश्यकता होती हैं।
- उन पृष्ठों में लॉगिन करना जो CSRF टोकन की आवश्यकता होती हैं।
- बुनियादी WAF सुरक्षा के पीछे की सामग्री तक पहुंचना।
- Puppeteer के माध्यम से नियंत्रित एक दूरस्थ ब्राउज़र (Scrapeless Browser) का उपयोग कर उन्नत एंटी-बॉट सुरक्षा को संभालना।
क्या आप लॉगिन की आवश्यकता वाली साइटों को स्क्रैप कर सकते हैं?
हाँ — तकनीकी रूप से आप लॉगिन के पीछे के पृष्ठ प्राप्त कर सकते हैं। कि कहा जाए, कानूनी और नैतिक सीमाएँ लागू होती हैं। सामाजिक प्लेटफ़ॉर्म और व्यक्तिगत डेटा वाली साइटें विशेष रूप से संवेदनशील होती हैं। हमेशा लक्षित साइट की रोबोट नीति, सेवा की शर्तें, और लागू कानूनों की जाँच करें।
तकनीकी रूप से, कुंजी के चरण हैं:
- लॉगिन प्रवाह को समझें।
- आवश्यक अनुरोध (और टोकन) को प्रोग्रामेटिक रूप से पुन: उत्पन्न करें।
- प्रमाणित स्थिति (कुकीज़, सत्र) बनाए रखें।
- यदि आवश्यक हो तो क्लाइंट-साइड जांच संभालें।
1) साधारण उपयोगकर्ता नाम + पासवर्ड लॉगिन (Requests + BeautifulSoup)
अग्रिम निष्कर्ष: यदि लॉगिन एक बुनियादी HTTP फॉर्म है, तो एक सत्र का उपयोग करें और क्रेडेंशियल्स को POST करें।
लाइब्रेरी installieren करें:
bash
pip3 install requests beautifulsoup4उदाहरण स्क्रिप्ट:
python
import requests
from bs4 import BeautifulSoup
login_url = "https://www.example.com/login"
payload = {
"email": "admin@example.com",
"password": "password",
}
with requests.Session() as session:
r = session.post(login_url, data=payload)
print("Status code:", r.status_code)
soup = BeautifulSoup(r.text, "html.parser")
print("Page title:", soup.title.string)नोट्स:
Session()का उपयोग करें ताकि कुकीज़ (सत्र आईडी) बाद के अनुरोधों के लिए स्थायी रहें।- सफल लॉगिन की पुष्टि के लिए प्रतिक्रिया कोड और बॉडी की जांच करें।
- यदि साइट रीडायरेक्ट का उपयोग करती है, तो
requestsइन्हें डिफ़ॉल्ट रूप से अनुसरण करता है; यदि आवश्यक हो तोr.historyकी जांच करें।
2) CSRF-सुरक्षित लॉगिन (टोकन प्राप्त करें, फिर पोस्ट करें)
अग्रिम निष्कर्ष: कई साइटों को CSRF टोकन की आवश्यकता होती है। पहले लॉगिन पृष्ठ को GET करें, टोकन को पार्स करें, फिर टोकन के साथ POST करें।
पैटर्न:
- लॉगिन पृष्ठ को GET करें।
- फॉर्म से छिपे हुए टोकन को पार्स करें।
- उसी सत्र का उपयोग करके क्रेडेंशियल्स + टोकन POST करें।
उदाहरण:
python
import requests
from bs4 import BeautifulSoup
login_url = "https://www.example.com/login/csrf"
with requests.Session() as session:
r = session.get(login_url)
soup = BeautifulSoup(r.text, "html.parser")
csrf_token = soup.find("input", {"name": "_token"})["value"]
payload = {
"_token": csrf_token,
"email": "admin@example.com",
"password": "password",
}
r2 = session.post(login_url, data=payload)
soup2 = BeautifulSoup(r2.text, "html.parser")
products = []
for item in soup2.find_all(class_="product-item"):
products.append({
"Name": item.find(class_="product-name").text.strip(),
"Price": item.find(class_="product-price").text.strip(),
})
print(products)टिप्स:
- कुछ ढांचे विभिन्न टोकन नामों का उपयोग करते हैं; सही इनपुट नाम खोजने के लिए फॉर्म की जांच करें।
- सामान्य ब्राउज़र की तरह दिखने के लिए उचित हेडर (User-Agent, Referer) भेजें।
3) बुनियादी WAF / बॉट जांच - जब Requests विफल हो तो एक हेडलेस ब्राउज़र का उपयोग करें
जब हेडर और टोकन पर्याप्त नहीं होते हैं, तो Selenium या एक हेडलेस ब्राउज़र के साथ एक वास्तविक ब्राउज़र का अनुकरण करें।
Selenium + Chrome कई बुनियादी सुरक्षा उपायों को पार कर सकते हैं क्योंकि यह JavaScript निष्पादित करता है और एक पूर्ण ब्राउज़र वातावरण चलाता है। यदि आप Selenium का उपयोग करते हैं, तो यथार्थवादी विलंब, माउस/कीबोर्ड क्रियाएँ और सामान्य ब्राउज़र हेडर जोड़ें।
हालाँकि, कुछ WAFs स्वचालन का पता लगाते हैं navigator.webdriver या अन्य अनुमानों के माध्यम से। undetected-chromedriver जैसे उपकरण मदद करते हैं, लेकिन वे उन्नत जांचों के खिलाफ गारंटी नहीं दिए जाते हैं। इन्हें केवल वैध, अनुमत उपयोग के लिए उपयोग करें।
4) उन्नत एंटी-बॉट सुरक्षा - एक दूरस्थ वास्तविक ब्राउज़र सत्र का उपयोग करें (Scrapeless Browser)
अपना Scrapeless API कुंजी प्राप्त करें
Scrapeless में लॉग इन करें और अपनी API कुंजी प्राप्त करें।
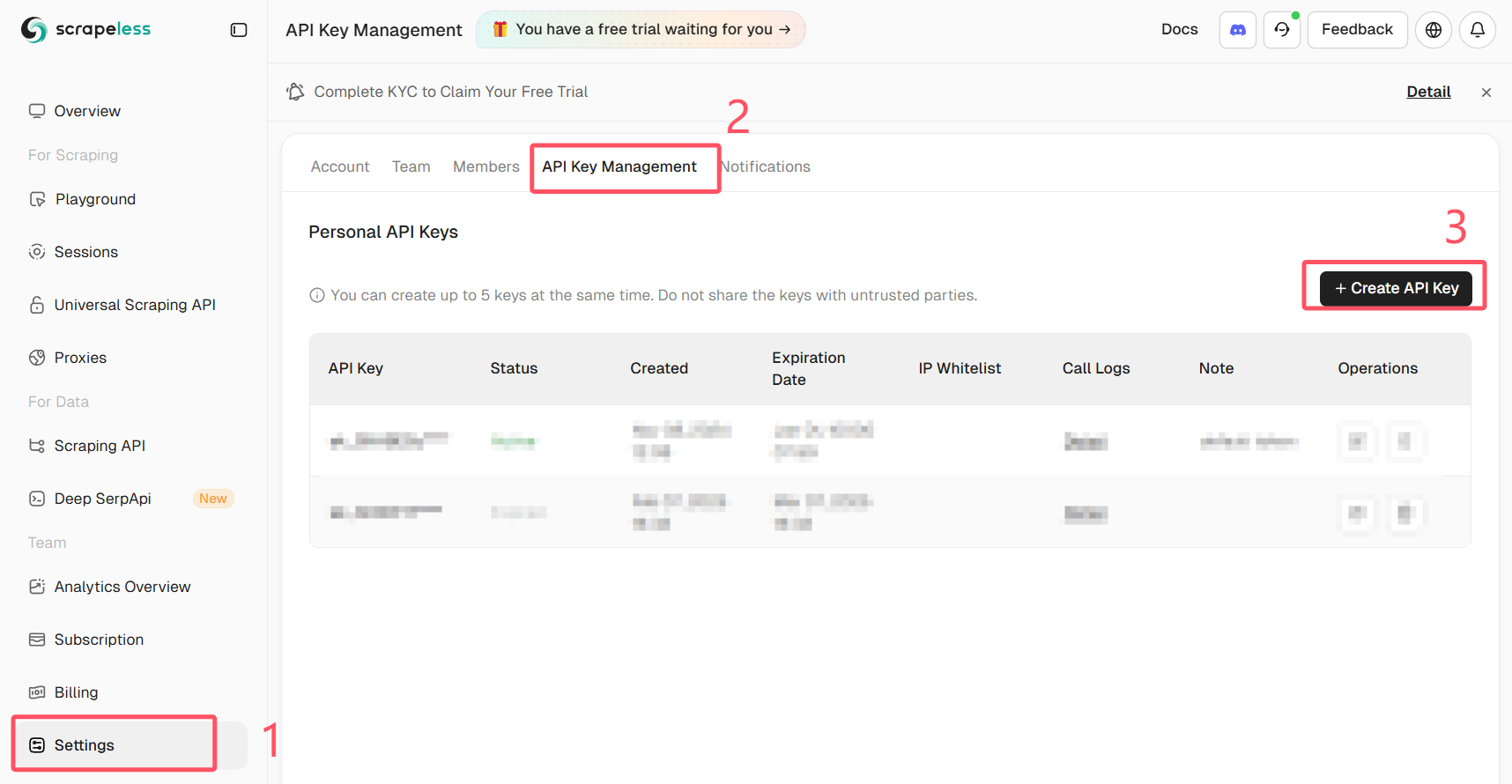
सबसे मजबूत दृष्टिकोण के लिए, एक वास्तविक ब्राउज़र को दूरस्थ रूप से चलाएँ (कोई स्थानीय हेडलेस उदाहरण नहीं) और इसे Puppeteer के माध्यम से नियंत्रित करें। Scrapeless Browser एक प्रबंधित ब्राउज़र अंत बिंदु प्रदान करता है जो पहचानने के जोखिम को कम करता है और प्रॉक्सी/JS रेंडरिंग जटिलता को कम करता है।
यह क्यों मदद करता है:
- ब्राउज़र एक प्रबंधित वातावरण में चलता है जो वास्तविक उपयोगकर्ता सत्रों की नकल करता है।
- JS वास्तविक उपयोगकर्ता ब्राउज़र में बिल्कुल उसी तरह कार्यान्वित होता है, इसलिए क्लाइंट-साइड चेक पास होते हैं।
- आप ज़रूरत अनुसार सत्र रिकॉर्ड कर सकते हैं और प्रॉक्सी राउटिंग का उपयोग कर सकते हैं।
नीचे एक उदाहरण दिया गया है जिसमें Puppeteer को Scrapeless ब्राउज़र से जोड़ने और स्वचालित लॉगिन करने का प्रदर्शन किया गया है। स्निपेट puppeteer-core का उपयोग करके Scrapeless WebSocket एंडपॉइंट से जुड़ता है। token, your_email@example.com और your_password को अपने मानों से बदलें और कभी भी क्रेडेंशियल्स को सार्वजनिक रूप से साझा न करें।
महत्वपूर्ण: कभी भी सार्वजनिक कोड में वास्तविक क्रेडेंशियल्स या एपीआई टोकन को कॉमिट न करें। गुप्त जानकारियों को सुरक्षित रूप से स्टोर करें (पर्यावरण चर या एक गुप्त प्रबंधक)।
import puppeteer from "puppeteer-core"
// 💡"Playground सेटिंग्स का उपयोग करें" सक्षम करना आपके प्लेग्राउंड कोड के कनेक्शन पैरामीटर को अधिलेखित कर देगा।
const query = new URLSearchParams({
token: "your-scrapeless-api-key",
proxyCountry: "ANY",
sessionRecording: true,
sessionTTL: 900,
sessionName: "Automatic Login",
})
const connectionURL = `wss://browser.scrapeless.com/api/v2/browser?${query.toString()}`
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
defaultViewport: null,
})
const page = await browser.newPage()
await page.goto("https://github.com/login")
await page.locator("input[name='login']").fill("your_email@example.com")
await page.locator("input[name='password']").fill("your_password")
await page.keyboard.press("Enter")उदाहरण पर नोट्स:
- यह उदाहरण
puppeteer-coreका उपयोग करके एक रिमोट ब्राउज़र से जुड़ता है। Scrapeless एक WebSocket एंडपॉइंट (browserWSEndpoint) प्रदान करता है जिसका Puppeteer उपयोग कर सकता है। - सत्र रिकॉर्डिंग और प्रॉक्सी विकल्प पूछताछ पैरामीटर में पास किए जाते हैं। अपने Scrapeless योजना और आवश्यकताओं के अनुसार समायोजित करें।
- प्रतीक्षा लॉजिक महत्वपूर्ण है: सुनिश्चित करें कि पृष्ठ पूरी तरह से लोड हो गया है, इसके लिए
waitUntil: "networkidle"या स्पष्टwaitForSelectorका उपयोग करें। - प्लेसहोल्डर टोकन को अपने पर्यावरण से एक सुरक्षित गुप्त के साथ बदलें।
व्यावहारिक सुझाव और एंटी-ब्लॉक चेकलिस्ट
- यदि साइट की एपीआई उपलब्ध है, तो उसका उपयोग करें। यह सुरक्षित और अधिक स्थिर है।
- तेजी से समानांतर अनुरोधों से बचें; अपने स्क्रैपर को थ्रॉटल करें।
- वैध और आवश्यक होने पर आईपी और सत्र फिंगरप्रिंट रोटेट करें। प्रतिष्ठित प्रॉक्सी प्रदाताओं का उपयोग करें।
- यथार्थवादी हेडर्स और कुकी प्रबंधन का उपयोग करें।
- robots.txt और साइट की शर्तों की जांच करें। यदि साइट स्क्रैपिंग की अनुमति नहीं देती है, तो अनुमति मांगने या आधिकारिक डेटा फ़ीड का उपयोग करने पर विचार करें।
- बेहतर डिबगिंग के लिए अपने स्क्रैपिंग के चरणों को लॉग करें (अनुरोध, प्रतिक्रिया कोड, रीडायरेक्ट)।
सारांश
आपने सीखा कि कैसे:
requestsके साथ सरल उपयोगकर्ता नाम/पासवर्ड स्वीकार करने वाले पृष्ठों में लॉगिन करना और स्क्रैप करना।- सुरक्षित रूप से प्रमाणीकरण के लिए CSRF टोकन निकालना और उपयोग करना।
- जब किसी साइट को पूर्ण JS रेंडरिंग की आवश्यकता होती है तो ब्राउज़र स्वचालन उपकरण का उपयोग करना।
- उन्नत क्लाइंट-साइड सुरक्षा को बायपास करने के लिए Puppeteer के माध्यम से एक रिमोट प्रबंधित ब्राउज़र (Scrapeless Browser) का उपयोग करना जबकि अपने वातावरण को सरल बनाए रखना।
जब सुरक्षा मजबूत होती है, तो प्रबंधित ब्राउज़र दृष्टिकोण अक्सर सबसे विश्वसनीय मार्ग होता है। इसका उपयोग जिम्मेदारी से करें और क्रेडेंशियल्स और एपीआई टोकन को सुरक्षित रखें।
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


