
कैसे Scrapeless के माध्यम से Amazon डेटा स्क्रैप करें?
Advanced Data Extraction Specialist
Amazon पर प्रतिस्पर्धात्मक लाभ प्राप्त करना चाहते हैं? चाहे आप कीमतों का पता लगा रहे हों, उत्पाद प्रवृत्तियों का विश्लेषण कर रहे हों या बाजार अनुसंधान कर रहे हों, आगे रहने की कुंजी प्रभावी रूप से Amazon डेटा को स्क्रैप करना है। लेकिन Amazon से उपयोगी जानकारी निकालना मुश्किल हो सकता है - विशेष रूप से साइट संरचना में बार-बार बदलाव, एंटी-बॉट उपायों और आईपी ब्लॉकिंग के साथ। यहीं पर Amazon Scraping API आता है। इस मार्गदर्शिका में, हम आपको दिखाएंगे कि पायथन का उपयोग करके Amazon उत्पाद डेटा को कैसे स्क्रैप करें, जिससे दुनिया के सबसे बड़े ई-कॉमर्स प्लेटफॉर्म से मूल्यवान डेटा और जानकारी एकत्र करना पहले से कहीं अधिक आसान हो जाएगा।
Amazon Scraping API क्या है?
Amazon वेब स्क्रैपिंग API एक दूरस्थ सर्वर जैसा है जो आपको Amazon डेटा एकत्र करने में मदद करता है। संचालन सरल है - आप लक्षित URL और भू-स्थिति जैसे अन्य पैरामेटर्स सहित API एंडपॉइंट पर एक अनुरोध भेजते हैं। फिर API आपके लिए वेबसाइट पर जाती है।
Amazon निम्नलिखित डेटा प्रकारों को क्रॉल करने का समर्थन करता है:
1. उत्पाद:
-
उत्पाद जानकारी: जिस सामग्री को क्रॉल किया जा सकता है, उसमें उत्पाद का नाम, विवरण, मूल्य, चित्र URL, ASIN (Amazon मानक पहचान संख्या), ब्रांड, आदि शामिल हैं।
-
बिक्री डेटा: जैसे उत्पाद रैंकिंग, बिक्री मात्रा और टिप्पणियाँ, आदि।
2. विक्रेता:
- विक्रेता जानकारी: आप विक्रेता का नाम, व्यापारी ID और उनके द्वारा बेचे जाने वाले उत्पादों से संबंधित जानकारी प्राप्त कर सकते हैं।
- विक्रेता रैंकिंग: विभिन्न विक्रेताओं से उत्पादों को क्रॉल करके, आप प्रत्येक विक्रेता का बाजार प्रदर्शन और विशिष्ट श्रेणी में उनकी प्रतिस्पर्धात्मकता का विश्लेषण कर सकते हैं।
3. कीवर्ड्स:
- कीवर्ड खोज परिणाम: आप विशिष्ट कीवर्ड (जैसे "लैपटॉप" या "एनिमे आंकड़ा") के आधार पर संबंधित उत्पाद सूचियों और उनकी विस्तृत जानकारी को क्रॉल कर सकते हैं।
Amazon स्क्रैपिंग के सामान्य उपयोग के मामले
Amazon स्क्रैपिंग विभिन्न उद्देश्यों के लिए व्यवसायों और विपणक के लिए कार्य करती है:
1. मूल्य निगरानी: उत्पाद कीमतों को स्क्रैप करके, व्यवसाय प्रतिस्पर्धी मूल्य निर्धारण को ट्रैक कर सकते हैं और अपनी खुद की रणनीति के अनुसार समायोजन कर सकते हैं।
2. उत्पाद अनुसंधान: समीक्षाएँ, रेटिंग और उत्पाद विवरण को स्क्रैप करना ट्रेंडिंग वस्तुओं की पहचान करने और ग्राहक प्राथमिकताओं को समझने में मदद करता है।
3. बिक्री अनुकूलन: विपणक उत्पाद विवरण और प्रचारों को स्क्रैप करके सामग्री में सुधार करते हैं और प्रभावी अभियानों का निर्माण करते हैं।
4. स्टॉक स्तर ट्रैकिंग: रियल-टाइम उत्पाद उपलब्धता डेटा को स्क्रैप करना व्यवसायों को इन्वेंटरी स्तरों और मांग पर नज़र रखने में मदद करता है।
5. ग्राहक भावनाएँ विश्लेषण: Amazon से स्क्रैप की गई समीक्षाएँ ग्राहक संतोष और सुधार के क्षेत्रों पर अंतर्दृष्टि प्रदान करती हैं।
संक्षेप में, Amazon स्क्रैपिंग प्रतिस्पर्धात्मक विश्लेषण, उत्पाद अनुसंधान और विपणन रणनीतियों को सरल बनाती है।
Amazon स्क्रैप करने में प्रमुख चुनौतियाँ (जैसे, CAPTCHA, रेट सीमाएँ)
- CAPTCHA चुनौतियाँ
Amazon स्वचालित क्रॉलिंग को रोकने के लिए CAPTCHA सत्यापन का उपयोग करता है, विशेष रूप से जब तेजी से अनुरोधों की बड़ी संख्या का पता लगाया जाता है। इस प्रकार के सत्यापन में उपयोगकर्ताओं को यह पुष्टि करने की आवश्यकता होती है कि वे मानव हैं, जिससे स्वचालित उपकरणों को सफलतापूर्वक डेटा प्राप्त करने से रोका जाता है।
Amazon के पास अनुरोध की आवृत्ति सीमा है। यदि आप इसकी वेबसाइट पर बहुत बार पहुँचते हैं, तो सिस्टम स्वचालित रूप से प्रतिक्रिया में देरी कर देगा या आगे के अनुरोधों को अस्थायी रूप से ब्लॉक कर देगा। इससे क्रॉलिंग प्रक्रिया धीमी और अस्थिर हो जाती है।
टिप्स: सबसे सामान्य उपयोगकर्ताओं के लिए, Amazon आमतौर पर प्रति मिनट десятों से सौ के बीच अनुरोध करने की अनुमति देता है। इस आवृत्ति को पार करने पर देरी या अस्थायी ब्लॉक होने की संभावना हो सकती है। Amazon लगातार क्रॉलिंग अनुरोधों के लिए सख्त सीमाएँ निर्धारित कर सकता है।
- आईपी ब्लॉकिंग
अत्यधिक तेजी से क्रॉलिंग के कारण Amazon अस्थायी रूप से आईपी पते को ब्लॉक कर सकता है। यदि आईपी पते को असामान्य स्रोत के रूप में चिह्नित किया जाता है, तो क्रॉलिंग ऑपरेशन पूरी तरह से ब्लॉक हो जाएगा, और आपको इस सीमा से बचने के लिए आईपी बदलने या प्रॉक्सी पूल का उपयोग करने की आवश्यकता होगी। सामान्य तौर पर, 5-10 अनुरोध प्रति सेकंड जोखिम उत्पन्न कर सकते हैं।
- गतिशील सामग्री लोडिंग
Amazon पृष्ठ सामग्री आमतौर पर जावास्क्रिप्ट के माध्यम से गतिशील रूप से लोड की जाती है, जिससे स्क्रैपिंग के दौरान पृष्ठ रेंडरिंग प्रक्रिया की अतिरिक्त प्रसंस्करण की आवश्यकता होती है। पारंपरिक HTML स्क्रैपिंग विधियाँ अक्सर गतिशील रूप से लोड की गई डेटा को सीधे प्राप्त नहीं कर पाती हैं।
- बार-बार लेआउट परिवर्तन
Amazon वेबसाइट का पृष्ठ लेआउट बार-बार बदलता है, जिससे क्रॉलिंग स्क्रिप्ट के लिए चुनौतियाँ उत्पन्न होती हैं। क्रॉलिंग टूल को डेटा निकासी की सटीकता और स्थिरता सुनिश्चित करने के लिए, पृष्ठ के अपडेट और परिवर्तनों के अनुकूल बनाने के लिए लगातार अपडेट किया जाना चाहिए।
अपने पायथन वातावरण को स्थापित करना
आपको पायथन में कोड लिखना शुरू करने से पहले पहले अपने विकास परिवेश को सेटअप करना होगा। यह कदम यह सुनिश्चित करता है कि आपके पास पायथन कोड लिखने और निष्पादित करने के लिए आवश्यक सभी उपकरण और पुस्तकालय हैं। इस अनुभाग में, हम आपको पायथन स्थापित करने, एक वर्चुअल वातावरण सेटअप करने और एक समेकित विकास वातावरण (IDE) को कॉन्फ़िगर करने की प्रक्रिया से गुज़ारेंगे जिससे आपके कार्यप्रवाह को सुगम बनाया जा सकेगा।
पायथन का उपयोग करने के लिए, आपको निम्नलिखित कॉन्फ़िगरेशन डाउनलोड करने होंगे
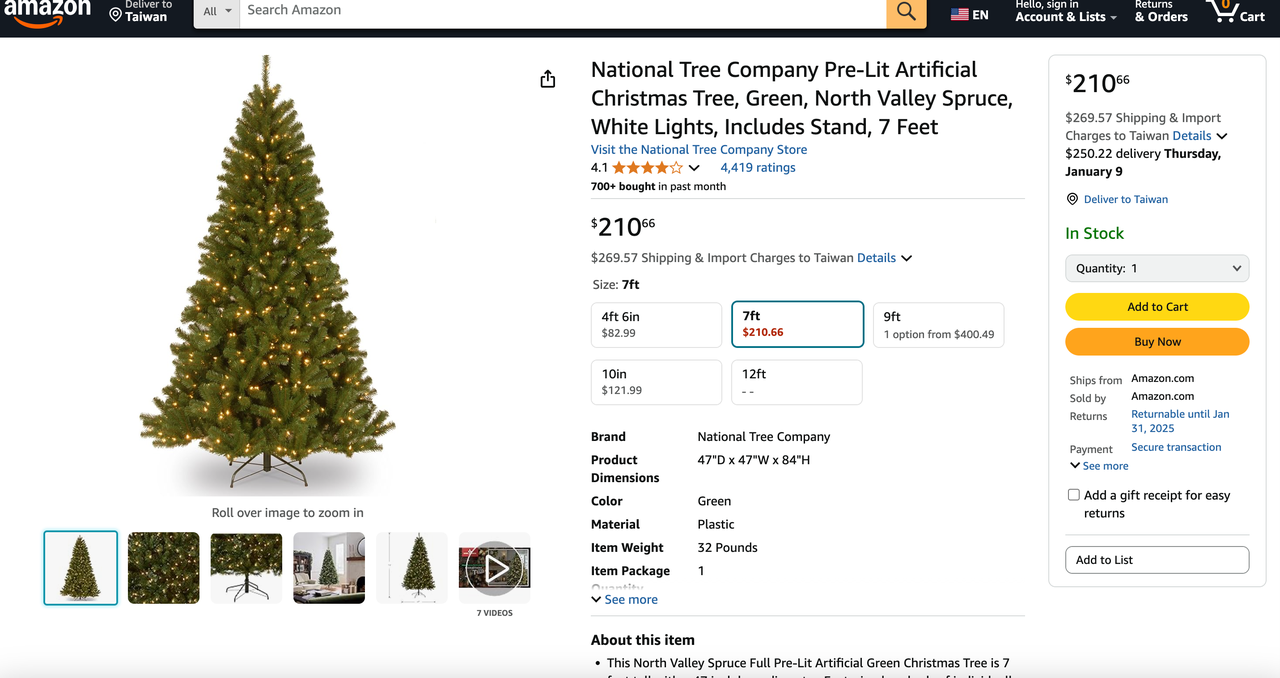
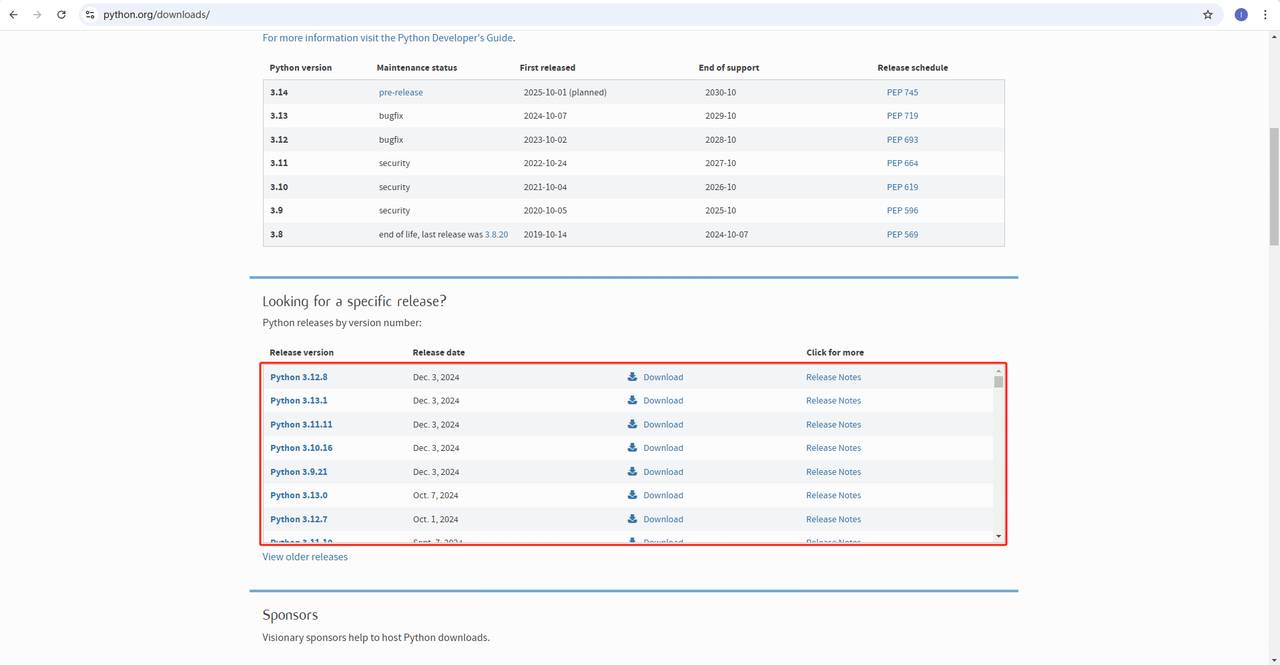
1. पायथन: https://www.python.org/downloads/ यह पायथन चलाने के लिए मूल सॉफ़्टवेयर है। आप आधिकारिक वेबसाइट से हमें आवश्यक संस्करण डाउनलोड कर सकते हैं जैसा कि नीचे दिखाया गया है, लेकिन नवीनतम संस्करण डाउनलोड करने की सिफारिश नहीं की जाती। आप नवीनतम संस्करण के पहले 1-2 संस्करण डाउनलोड कर सकते हैं।
2. पायथन IDE: कोई भी IDE जो पायथन का समर्थन करता है चलेगा, लेकिन हम PyCharm का उपयोग करने की सिफारिश करते हैं, जो विशेष रूप से पायथन के लिए डिज़ाइन किया गया एक IDE विकास उपकरण सॉफ़्टवेयर है। PyCharm के संस्करण के लिए, हम मुफ्त PyCharm Community Edition का उपयोग करने की सिफारिश करते हैं।
3. पिप: आप पुस्तकालयों को एकल कमांड के साथ स्थापित करने के लिए पायथन पैकेज अनुक्रमणिका (PyPi) का उपयोग कर सकते हैं।
नोट: यदि आप एक विंडोज़ उपयोगकर्ता हैं, तो इंस्टॉलेशन विज़ार्ड में "Add python.exe to PATH" विकल्प की जांच करना न भूलें। इस प्रकार, विंडोज़ टर्मिनल में पायथन और कमांड का उपयोग कर सकेगा। FYI: चूंकि पायथन 3.4 या बाद का संस्करण इसे डिफ़ॉल्ट रूप से शामिल करता है, इसलिए आपको इसे मैन्युअल रूप से स्थापित करने की आवश्यकता नहीं है।
एक पायथन प्रोजेक्ट को प्रारंभ करें
PyCharm लॉन्च करें और मेनू बार पर फ़ाइल > नया प्रोजेक्ट... विकल्प चुनें।

यह तब एक पॉपअप विंडो खोलेगा। बाईं मेनू से प्योर पायथन चुनें और फिर अपना प्रोजेक्ट निम्नानुसार सेट करें:
नोट: नीचे लाल बॉक्स में, उस इंस्टॉलेशन पथ का चयन करें जिसे हमने वातावरण कॉन्फ़िगरेशन के पहले चरण में डाउनलोड किया था।
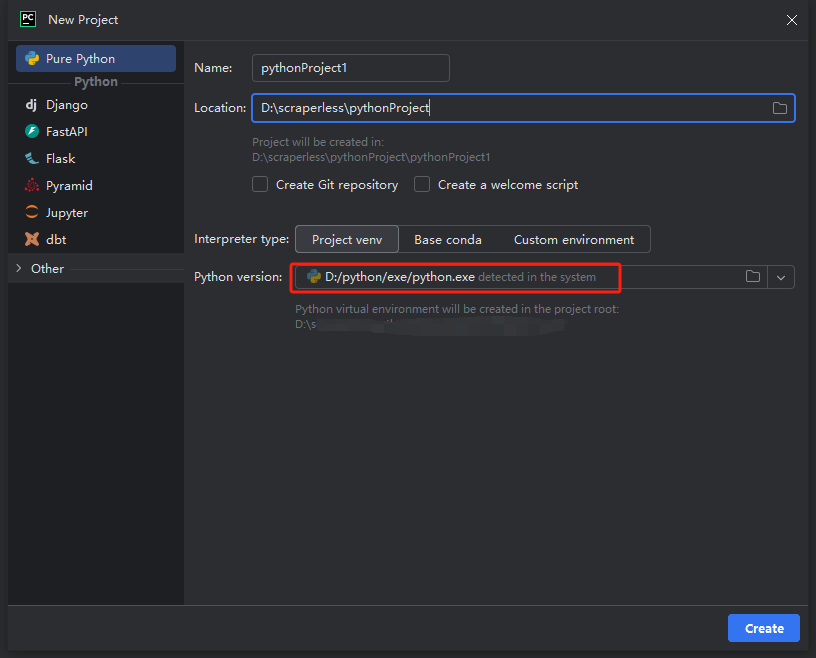
आप एक प्रोजेक्ट बना सकते हैं जिसका नाम python-scraper है, फ़ोल्डर में "Create a main.py welcome script option" को चेक करें, और Create बटन पर क्लिक करें।
जब PyCharm आपके प्रोजेक्ट को सेटअप कर रहा हो, तो थोड़ी देर प्रतीक्षा करें, आपको निम्नलिखित दिखाई देना चाहिए:
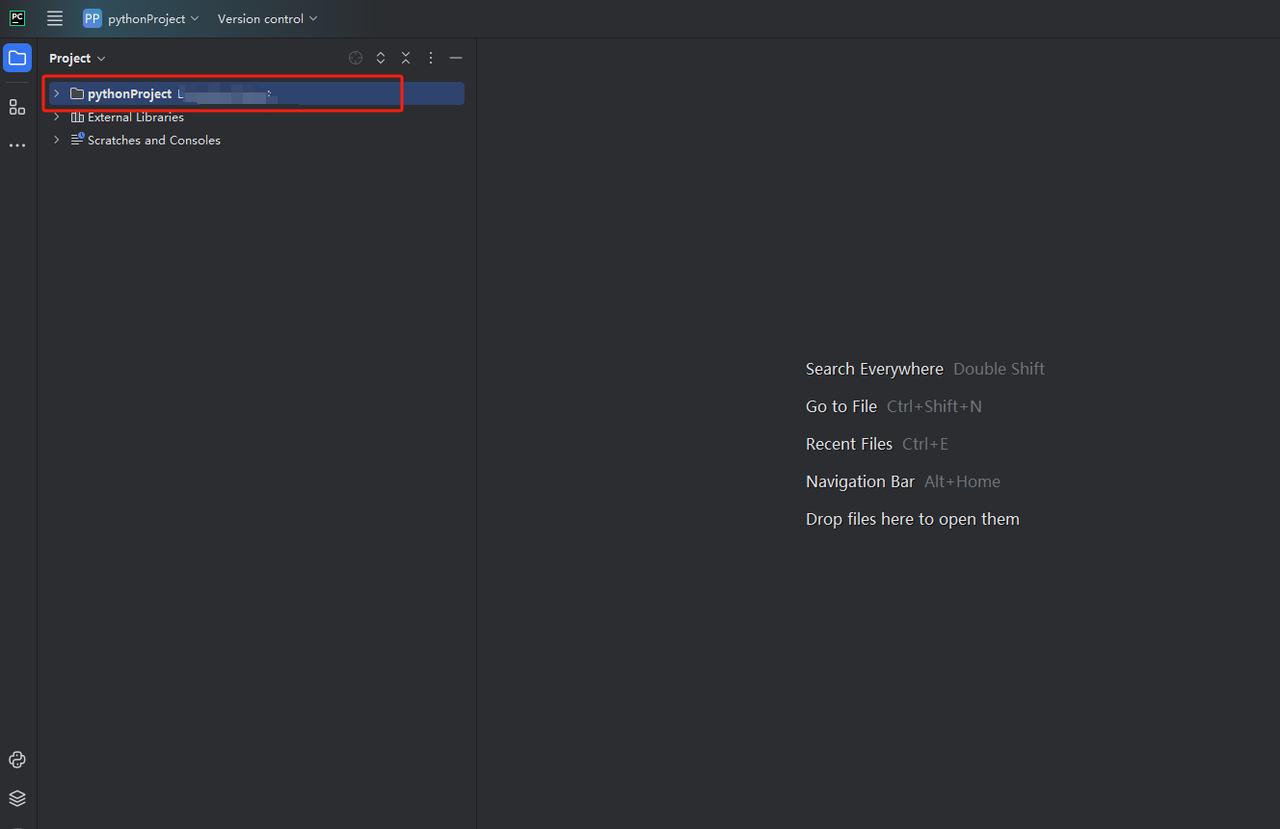
इसके बाद, नए पायथन फ़ाइल बनाने के लिए राइट क्लिक करें।
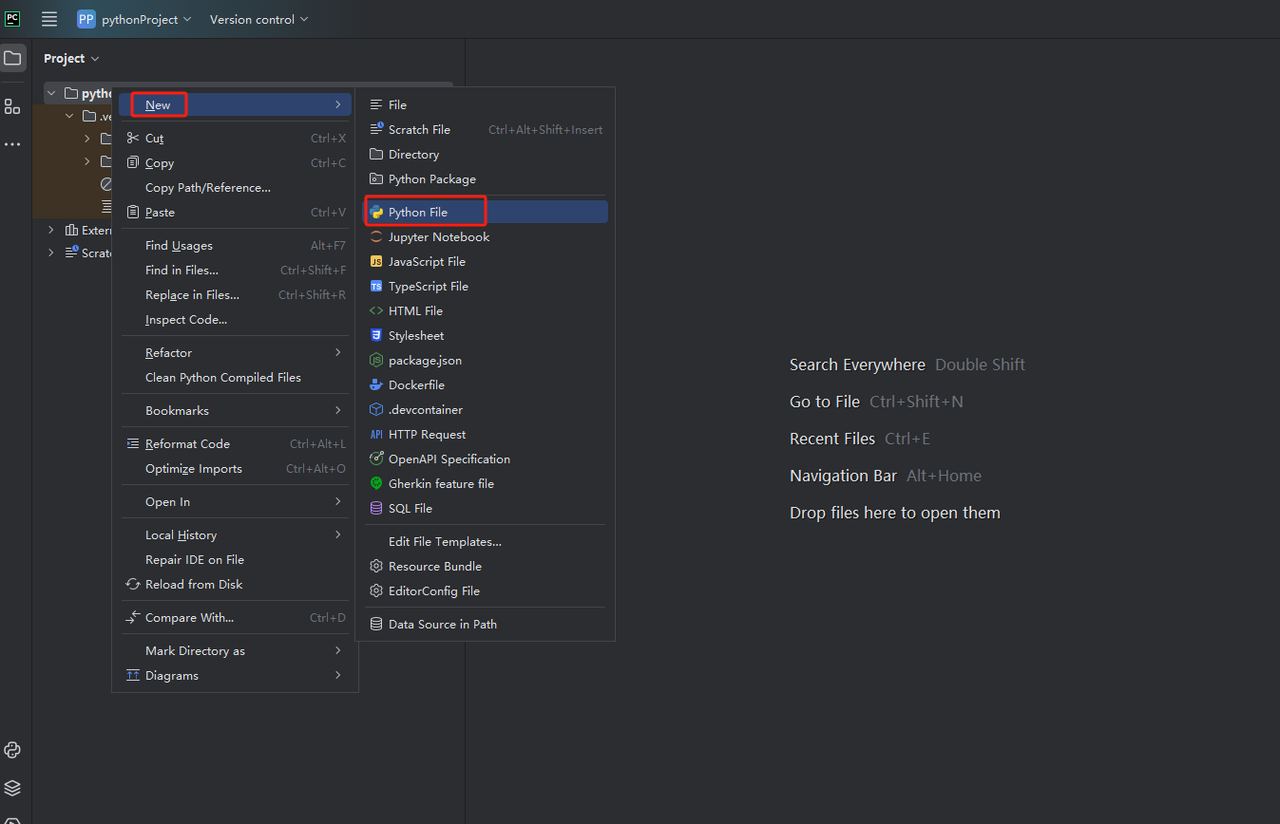
यह पुष्टि करने के लिए कि सब कुछ सही काम कर रहा है, स्क्रीन के नीचे टर्मिनल टैब खोलें और टाइप करें: python main.py। इस आदेश को लॉन्च करने के बाद, आपको मिलना चाहिए: Hi, PyCharm।
आप सीधे स्क्रैपलेस में कोड को PyCharm में कॉपी कर सकते हैं और इसे चला सकते हैं, ताकि हम अमेज़न उत्पादों के JSON प्रारूप डेटा प्राप्त कर सकें।
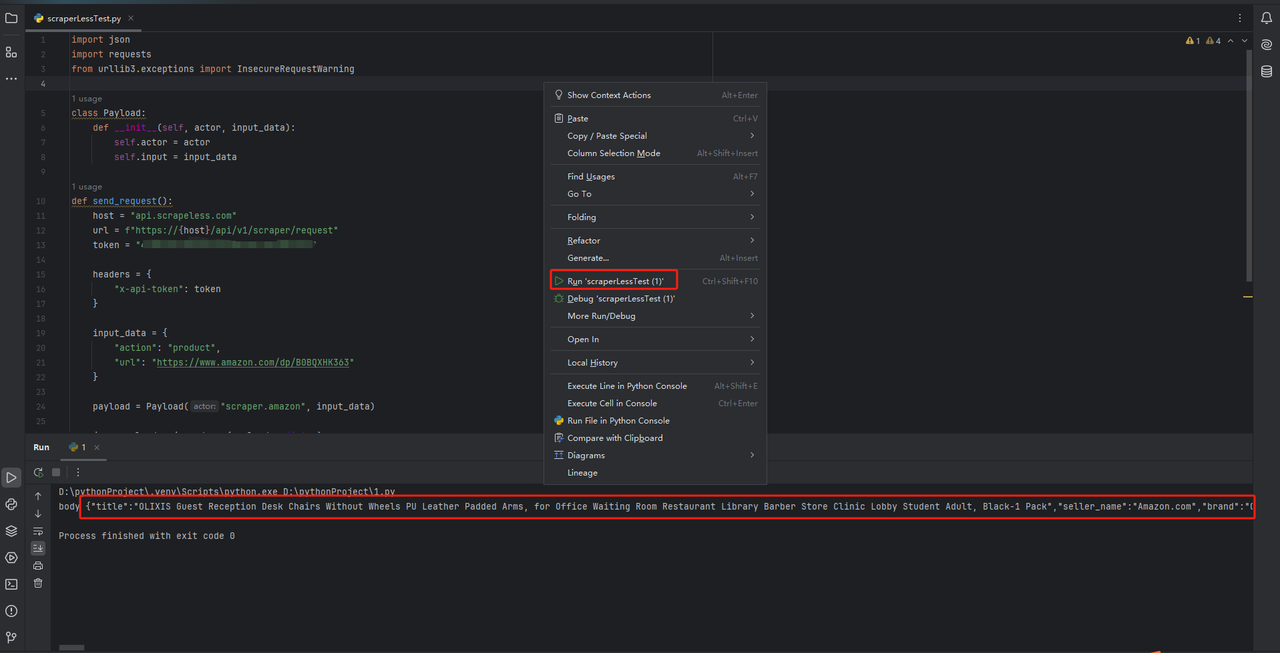
स्टेप-बाय-स्टेप गाइड: अमेज़न उत्पाद डेटा स्क्रैपिंग
जैसा कि हमने ऊपर उल्लेख किया, अमेज़न के लिए आवश्यक पर्यावरण को कॉन्फ़िगर करने के बाद, आप स्क्रैपलेस पायथन कोड को एकीकृत कर सकते हैं।
अमेज़न उत्पाद डेटा कैसे स्क्रैप करें
आप सीधे स्क्रैपलेस API दस्तावेज़ पर जा सकते हैं ताकि अधिक पूर्ण API कोड जानकारी प्राप्त कर सकें, और फिर अपने प्रोजेक्ट में स्क्रैपलेस पायथन कोड को एकीकृत करें।
अनुरोध नमूने - उत्पाद
python
import requests
import json
url = "https://api.scrapeless.com/api/v1/scraper/request"
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "https://www.amazon.com/dp/B0BQXHK363",
"action": "product"
}
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)अमेज़न विक्रेता जानकारी कैसे स्क्रैप करें
इसी प्रकार, सिर्फ स्क्रैपलेस API कोड को अपने स्क्रैपिंग सेटअप में एकीकृत करके, आप अमेज़न की स्क्रैपिंग बाधाओं को दरकिनार कर सकते हैं और अमेज़न विक्रेता जानकारी को स्क्रैप कर सकते हैं।
अनुरोध नमूने - विक्रेता
python
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"url": "",
"action": "seller"
}
})
headers = {'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))
## कैसे अमेज़न कीवर्ड खोज परिणामों को स्क्रैप करें
अपने प्रोजेक्ट में कीवर्ड के लिए अनुरोध नमूनों को शामिल करने के लिए ऊपर दिए गए चरणों का पालन करें ताकि आप अमेज़न कीवर्ड खोज परिणाम प्राप्त कर सकें।
**अनुरोध नमूने - कीवर्ड्स**
```import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "scraper.amazon",
"input": {
"action": "keywords",
"keywords": "iPhone 12",
"page": "5",
"domain": "com"
}
})
headers = {
'Content-Type': 'application/json'
}
conn.request("POST", "/api/v1/scraper/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))सरल एकीकरण और कॉन्फ़िगरेशन के माध्यम से, Scrapeless आपको अमेज़न डेटा प्राप्त करने में अधिक कुशलता से सहायता करता है। आप आसानी से अमेज़न प्लेटफॉर्म पर उत्पाद, विक्रेता और कीवर्ड जानकारी जैसे प्रमुख डेटा को स्क्रॉल कर सकते हैं, जिससे डेटा विश्लेषण की सटीकता और वास्तविक समय की प्रकृति में सुधार होता है।
अमेज़न डेटा स्क्रैपिंग के बारे में अक्सर पूछे जाने वाले प्रश्न
1. क्या अमेज़न डेटा को स्क्रैप करना वैध है?
सार्वजनिक उत्पाद जानकारी को स्क्रैप करना (जैसे शीर्षक, विवरण, मूल्य और रेटिंग) वैध है, जबकि निजी खाता डेटा को स्क्रैप करने से गोपनीयता के मुद्दे उठ सकते हैं। इसके अलावा, बाजार अनुसंधान या प्रतिस्पर्धात्मक विश्लेषण के लिए स्क्रैप किए गए डेटा का उपयोग आमतौर पर "fair use" माना जाता है।
2. अमेज़न से कौन सा डेटा स्क्रैप किया जा सकता है?
अमेज़न स्क्रैपिंग API का उपयोग करके, आप उत्पादों, विक्रेताओं, समीक्षाओं आदि से संबंधित डेटा निकाल सकते हैं। इसमें उत्पाद का नाम, मूल्य, ASIN (अमेज़न स्टैंडर्ड आइडेंटिफ़िकेशन नंबर), ब्रांड, विवरण, विशिष्टताएँ, श्रेणी, उपयोगकर्ता समीक्षाएँ और उनकी रेटिंग शामिल हैं।
3. अमेज़न डेटा को प्रभावी ढंग से कैसे स्क्रॉल करें?
अमेज़न डेटा को स्क्रॉल करने के प्रभावी तरीके में स्वचालित स्क्रिप्ट या API का उपयोग करना और अमेज़न की सेवा की शर्तों का पालन करना शामिल है। ब्लॉक होने से बचने के लिए, अनुरोध की आवृत्ति को कम करना और लोड को उचित रूप से नियंत्रित करने की सिफारिश की जाती है। इसके अतिरिक्त, कैप्चा समाधान का उपयोग करने से स्क्रैपिंग की सफलता की दर बढ़ सकती है।
निष्कर्ष: सर्वश्रेष्ठ अमेज़न स्क्रैपिंग API प्रदाता
इस लेख की प्रस्तुति के माध्यम से, आपने सीखा कि पायथन का उपयोग करके अमेज़न पर उत्पाद डेटा को प्रभावी रूप से कैसे स्क्रैप करना है। चाहे वह उत्पाद विवरण, मूल्य जानकारी, या समीक्षा डेटा प्राप्त करना हो, पायथन की शक्ति और लचीलापन स्वचालित स्क्रैपिंग को आसान और अधिक कुशल बनाता है। हालाँकि, बड़े पैमाने पर डेटा स्क्रैप करने पर, आपको एंटी-स्क्रैपर तंत्र के साथ चुनौतियों का सामना करना पड़ सकता है। इस समय, Scrapeless, एक बुद्धिमान वेब स्क्रैपिंग समाधान के रूप में, आपको इन बाधाओं को पार करने में मदद कर सकता है और एक सुगम और अधिक कुशल स्क्रैपिंग प्रक्रिया सुनिश्चित कर सकता है। यदि आप डेटा स्क्रैपिंग की गति और स्थिरता में सुधार करना चाहते हैं, तो आप अपने स्क्रैपिंग कार्यप्रवाह को आगे अनुकूलित करने के लिए Scrapeless का उपयोग करने का प्रयास कर सकते हैं।
Scrapeless Discord Community में शामिल हों! 🚀 डेटा उत्साही लोगों के साथ जुड़ें, तेजी से और स्मार्ट रूप से स्क्रैपिंग करने के लिए विशेष सुझाव प्राप्त करें, और हमारे नवीनतम फीचर्स के बारे में अपडेट रहें। चाहे आप एक शुरुआत हो या एक पेशेवर, आपके लिए यहाँ एक जगह है। लिंक पर क्लिक करें और आज ही जुड़ें! 👾 अभी जुड़ें
स्क्रैपलेस में, हम केवल सार्वजनिक रूप से उपलब्ध डेटा का उपयोग करते हैं, जबकि लागू कानूनों, विनियमों और वेबसाइट गोपनीयता नीतियों का सख्ती से अनुपालन करते हैं। इस ब्लॉग में सामग्री केवल प्रदर्शन उद्देश्यों के लिए है और इसमें कोई अवैध या उल्लंघन करने वाली गतिविधियों को शामिल नहीं किया गया है। हम इस ब्लॉग या तृतीय-पक्ष लिंक से जानकारी के उपयोग के लिए सभी देयता को कोई गारंटी नहीं देते हैं और सभी देयता का खुलासा करते हैं। किसी भी स्क्रैपिंग गतिविधियों में संलग्न होने से पहले, अपने कानूनी सलाहकार से परामर्श करें और लक्ष्य वेबसाइट की सेवा की शर्तों की समीक्षा करें या आवश्यक अनुमतियाँ प्राप्त करें।


